
Java adalah salah satu bahasa pemrograman paling populer, jadi wajar jika Anda bertanya-tanya apakah itu pilihan yang tepat Pengikisan web adalah. Meskipun Java dapat digunakan untuk mengikis data, Java mungkin bukan pilihan optimal untuk proyek kecil yang mengutamakan kecepatan. Di sisi lain, Java bisa menjadi pilihan tepat untuk proyek besar atau skalabel yang memerlukan multithreading untuk pengumpulan dan pemrosesan data.
Dalam artikel ini, kami memberikan tutorial komprehensif tentang pro dan kontra menggunakan Java untuk web scraping, kapan memilih Java untuk scraping, cara menginstal dan mengkonfigurasi komponen yang diperlukan, dan cara membuat scraper pertama Anda. Kami juga membahas teknik yang lebih canggih, seperti membuat perayap lengkap untuk merayapi semua halaman situs web, prinsip konkurensi dan konkurensi, dan menggunakan browser tanpa kepala di Java.
Daftar Isi
Menggunakan Java untuk Pengikisan Web
Java adalah salah satu bahasa pemrograman paling populer dan tertua. Ini adalah bahasa serbaguna yang dapat digunakan untuk mengembangkan berbagai aplikasi termasuk web scraping.
| Keuntungan Java untuk Web Scraping | Kekurangan Java untuk Web Scraping |
|---|---|
| Komunitas besar dan aktif | Bahasa yang relatif rumit |
| Ekosistem dan perpustakaan yang luas (misalnya Jsoup, HtmlUnit) | Memerlukan deklarasi tipe data secara eksplisit (pengetikan statis) |
| Dokumentasi, tutorial, dan forum yang luas | Menyertakan kode boilerplate, membuatnya lebih bertele-tele |
| Pendekatan “Tulis sekali, jalankan di mana saja”. | Aplikasi mungkin lebih lambat dibandingkan aplikasi dalam bahasa lain |
| Dukungan yang andal untuk pemrograman paralel | Kompilasi ke bytecode menambahkan langkah ekstra untuk pengembangan |
Tabel ini memberikan gambaran umum tentang kelebihan dan kekurangan web scraping di Java. Sekarang kita akan membahasnya lebih detail.
Keuntungan Java untuk Web Scraping
Java memiliki komunitas yang besar dan aktif, ekosistem yang kaya, dan banyak perpustakaan yang mempermudah web scraping, seperti: B.Jsoup dan HtmlUnit. Jika Anda memiliki pertanyaan atau kesulitan, Anda selalu dapat menghubungi komunitas besar dan aktif, yang menyediakan dokumentasi, tutorial, dan forum yang ekstensif. Dukungan tersebut memudahkan pengembang untuk menemukan solusi masalah dan berbagi pengalaman.
Pendekatan Java “tulis sekali, jalankan di mana saja” memungkinkan pengembang untuk mengembangkan dan menyebarkan aplikasi web scraping di berbagai platform tanpa modifikasi. Selain itu, dukungan Java yang andal untuk pemrograman paralel membuatnya cocok untuk menyelesaikan tugas web scraping skala besar, sehingga meningkatkan efisiensi dan kinerja.
Kekurangan Java untuk Web Scraping
Java adalah bahasa pemrograman yang kuat dan serbaguna dengan beragam aplikasi. Namun, bahasa ini juga memiliki beberapa kelemahan yang harus dipertimbangkan sebelum memilihnya sebagai bahasa pembelajaran.
Salah satu tantangan terbesar dalam mempelajari Java adalah bahasanya yang relatif kompleks. Ini karena ini adalah bahasa yang diketik secara statis, yang berarti tipe data variabel dan ekspresi harus dideklarasikan secara eksplisit. Hal ini dapat membuatnya lebih sulit untuk dipelajari dibandingkan bahasa yang diketik secara dinamis seperti Python.
Tantangan lain dari Java adalah ia menggunakan banyak kode boilerplate. Kode boilerplate digunakan berulang kali, mis. B. Kode untuk membuat objek atau mengakses sumber daya. Hal ini memungkinkan kode Java menjadi lebih bertele-tele dibandingkan kode yang ditulis dalam bahasa lain.
Terakhir, aplikasi Java bisa lebih lambat dibandingkan aplikasi yang ditulis dalam bahasa lain. Kode Java harus dikompilasi menjadi bytecode sebelum dapat dieksekusi. Hal ini dapat menambah langkah tambahan pada proses pengembangan dan menyebabkan masalah kinerja.
Persyaratan untuk web scraping dengan Java
Sebelum Anda mulai mengembangkan web scraper di Java, Anda perlu menyiapkan lingkungan pengembangan Java. Ini termasuk yang berikut:
- Jawa LTS. Disarankan untuk menggunakan versi stabil terbaru dari situs resminya. Tanpa ini Anda tidak dapat membuat proyek Java.
- Membangun sistem. Sistem build seperti Maven dan Gradle memungkinkan Anda mengkompilasi dan menjalankan proyek di satu mesin. Kita akan membahas instalasinya nanti.
- IDE Jawa. Ini tidak wajib tetapi sangat disarankan. IDE memudahkan pengembangan dan menjalankan proyek. IDE yang paling populer adalah IntelliJ IDEA, yang memungkinkan Anda mengkompilasi proyek menggunakan Gradle atau Maven dan sistem buildnya sendiri. Ini adalah metode yang direkomendasikan untuk pemula.
Setelah Anda memiliki komponen ini, Anda dapat membuat scraper web Java Anda.
Cara menginstal dan menggunakan Java Build Systems
Pilihan sistem build ada di tangan Anda, namun jika Anda seorang pemula, kami sarankan untuk menggunakan IntelliJ IDEA dan sistem build bawaannya. Maven dan Gradle dapat digunakan melalui baris perintah tanpa IDE.
Maven
Untuk menginstal Maven, unduh versi terbaru dari situs resminya dan ekstrak arsipnya ke drive C:. Kemudian tambahkan direktori bin dari folder Maven yang diekstraksi ke variabel lingkungan PATH sistem Anda.
Untuk memverifikasi bahwa paket dikonfigurasi dengan benar, jalankan perintah berikut di Command Prompt:
mvn -versionJika Maven diinstal dengan benar, Anda akan melihat informasi versi Maven dan detail terkait.

Untuk membuat proyek dengan Maven, Anda memerlukan baris perintah. Navigasikan ke direktori proyek Anda dan jalankan perintah berikut untuk membangun proyek:
mvn clean installPerintah ini membuat dan menginstal proyek ke repositori Maven lokal Anda. Setelah build berhasil, jalankan perintah berikut untuk menjalankan aplikasi:
java -cp target/project_name.jar MainClassNamePerhatikan bahwa Anda harus menentukan nama kelas utama yang akan menjadi titik masuk untuk aplikasi Anda.
Gradle
Selain itu, untuk menggunakan Gradle, Anda perlu mengunduh arsip dari situs resmi dan menambahkan jalur ke direktori bin dari arsip yang diekstraksi ke variabel lingkungan Anda.
Setelah Anda selesai melakukannya, Anda dapat memverifikasi instalasi dengan menjalankan perintah berikut di terminal:
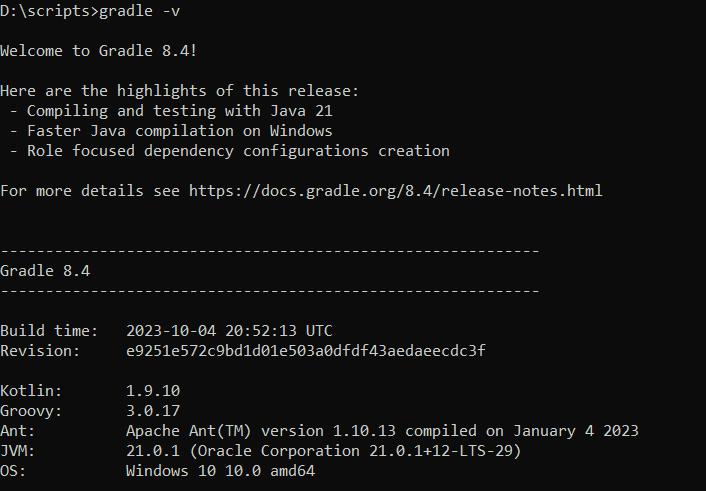
gradle -vJika Gradle diinstal dengan benar, Anda akan melihat output seperti berikut:
Untuk menginstal Gradle menggunakan SDKMAN, jalankan perintah berikut:
sdk install gradle 8.4Untuk membuat proyek, buka prompt perintah dan navigasikan ke direktori proyek. Kemudian jalankan perintah build di command prompt:
gradlew buildSetelah build berhasil, jalankan perintah untuk memulai aplikasi:
java -jar build/libs/your-project.jarSeperti yang Anda lihat, penggunaan Maven dan Gradle sangat mirip. Anda juga dapat menggunakannya untuk membangun dari baris perintah dan melalui IntelliJ, yang akan kami bahas di bawah.
IDE IntelliJ
Untuk menggunakan sistem build IntelliJ, Anda perlu mengunduh dan menginstal IntelliJ IDEA dari situs resminya. Setelah instalasi, saat membuat proyek baru, Anda dapat memilih bahasa pemrograman yang Anda inginkan dan membuat sistem.
Setelah itu, Anda dapat memulai proyek kapan saja menggunakan tombol yang sesuai di atas.
Perpustakaan untuk web scraping di Java
Java memiliki dua perpustakaan yang paling umum digunakan untuk web scraping: Jsoup dan HtmlUnit. Keduanya cocok untuk web scraping dan parsing HTML, namun memiliki tujuan, kelebihan dan kelemahan yang berbeda. Mari kita lihat kedua perpustakaan Java dan pilih yang lebih sesuai untuk contoh kita di bawah ini.
Hanya saja
Jsoup adalah perpustakaan Java sederhana dan ringan untuk bekerja dengan HTML dan DOM. Ini adalah pilihan yang baik untuk pemula dan menyediakan API yang nyaman untuk mengekstraksi dan memanipulasi data dari dokumen HTML.
Jsoup menggunakan pemilih CSS untuk menanyakan dan memilih elemen HTML, yang membuatnya lebih mudah untuk dipahami. Meskipun penggunaan pemilih CSS menawarkan kumpulan fitur yang lebih kecil dibandingkan XPath, ini lebih populer karena kesederhanaannya.
Sayangnya, perpustakaan ini tidak dapat mengumpulkan dan memproses data dari halaman web dinamis yang memuat konten menggunakan JavaScript. Itu juga tidak dapat mensimulasikan perilaku pengguna sebenarnya yang menggunakan browser tanpa kepala.
HtmlUnit
Pustaka HtmlUnit, di sisi lain, mengatasi kekurangan Jsoup namun kurang ringan dan ramah pengguna. Ini menyediakan browser tanpa kepala yang memungkinkan Anda berinteraksi dengan situs web seperti browser sebenarnya, mensimulasikan perilaku pengguna sebenarnya.
Selain itu, HtmlUnit memiliki mesin JavaScript yang memungkinkan Anda menjalankan JavaScript di halaman web. Anda dapat berinteraksi dengan situs web dengan mengirimkan formulir, mengikuti tautan, dan menavigasi halaman.
Jsoup vs HtmlUnit
Berdasarkan pengalaman kami, kami merekomendasikan penggunaan perpustakaan Jsoup untuk menggores halaman sederhana dan HtmlUnit jika Anda perlu menggunakan browser tanpa kepala. Namun, perpustakaan mana yang terbaik untuk kebutuhan Anda bergantung pada keahlian, tujuan spesifik, dan persyaratan Anda. Untuk menyederhanakan proses pemilihan, kami telah membuat tabel yang mencantumkan kondisi di mana Anda harus memilih satu atau beberapa perpustakaan.
| Hanya saja | HtmlUnit |
|---|---|
| Cocok untuk mengurai dokumen HTML statis. | Terbatas dibandingkan HtmlUnit, bukan fokus utamanya. |
| Dukungan terbatas untuk konten dinamis yang dirender oleh JavaScript. | Dapat mengekstrak konten dinamis. |
| Tidak dirancang untuk mensimulasikan interaksi pengguna di halaman web. | Cocok untuk mensimulasikan tindakan browser, pengiriman formulir, dan mengklik tautan. |
| Tidak menjalankan JavaScript. | Memiliki mesin JavaScript bawaan untuk menjalankan JavaScript di halaman web. |
| Tidak ada dukungan untuk menavigasi halaman seperti di browser. | Menyediakan fungsionalitas browser tanpa kepala untuk navigasi dan interaksi. |
| Lebih cocok untuk tugas parsing sederhana. | Sangat cocok untuk skenario pengujian yang memerlukan interaksi browser. |
| Perpustakaan ringan dengan tapak lebih kecil. | Jejak yang lebih besar karena fitur browser tanpa kepala. |
| API sederhana dan ramah pengguna. | Ini lebih kompleks karena fitur simulasi browser tambahan. |
Pengikisan Web dengan Java dengan Jsoup
Seperti disebutkan sebelumnya, Jsoup adalah pilihan yang baik untuk menggores halaman sederhana dan untuk pemula. Oleh karena itu, kami akan menggunakannya sebagai contoh utama kami. Kita akan membahas HtmlUnit nanti saat kita membahas teknik lanjutan dan browser tanpa kepala.
Impor perpustakaan ke proyek Java
Cara menghubungkan perpustakaan mungkin berbeda tergantung pada sistem build yang digunakan. Gradle dan Maven memerlukan penjelasan proyek dan dependensinya dalam file XML, sedangkan IntelliJ memerlukan impor langsung file JAR perpustakaan melalui antarmuka IntelliJ IDEA.
Untuk menggunakan Maven, Anda perlu membuat file pom.xml yang menentukan perpustakaan Jsoup terbaru sebagai ketergantungan:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>web-scraper</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.16.2</version>
</dependency>
</dependencies>
</project>Untuk menambahkan perpustakaan ke proyek Anda di IntelliJ IDEA, unduh file JAR perpustakaan dan tambahkan ke proyek dengan menavigasi ke File > Struktur Proyek > Perpustakaan > Tambahkan.
Anda kemudian dapat mengimpor modul perpustakaan yang diperlukan ke dalam proyek Anda:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;Selain itu, kita perlu mengimpor modul input/output untuk menampilkan data output di layar di masa mendatang.
import java.io.IOException;Modul-modul ini sekarang memungkinkan kita mengekstrak data apa pun.
Buat permintaan untuk mendapatkan HTML
Untuk mengikis situs web, pertama-tama kita perlu menentukan struktur proyek kita. Ini termasuk kelas utama yang memulai inisialisasi proyek dan fungsi yang melakukan pengikisan.
public class Main {
public static void main(String() args) {
// Here will be code
}
}Untuk mendemonstrasikan proses scraping di Java, kami akan menggunakan halaman demo OpenCart tempat kami mengumpulkan produk. Untuk menemukan pemilih CSS yang mendeskripsikan judul dan tautan, buka DevTools (F12 atau klik kanan dan buka Inspect) dan pilih elemen yang diinginkan.
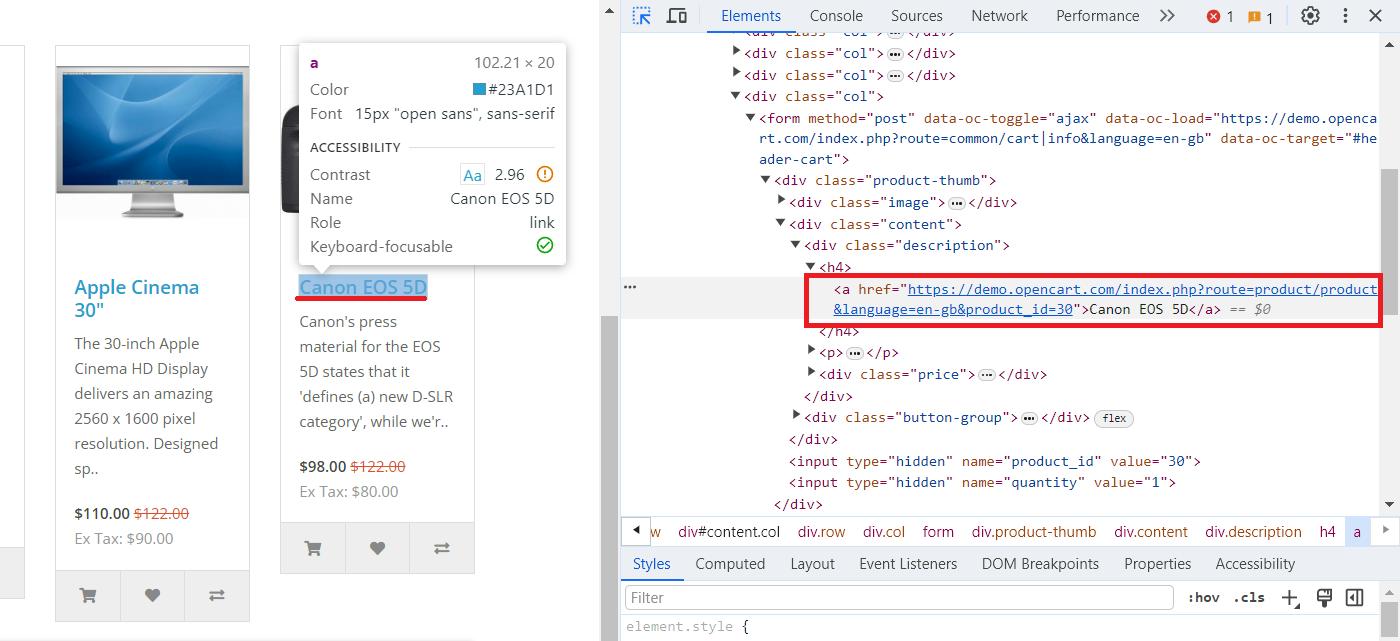
Sekarang mari kembali ke proyek kita dan dapatkan kode HTML untuk halaman ini:
Document document = null;
try {
document = Jsoup.connect("https://demo.opencart.com/").get();
} catch (IOException e) {
throw new RuntimeException(e);
}Kami menggunakan blok coba-tangkap untuk mencegah skrip kami mogok dan menerima informasi kesalahan jika permintaan gagal. Mari beralih ke bagian selanjutnya dan mengekstrak semua judul dan tautan.
Sekarang mari kita periksa struktur website yang kita ulas sebelumnya dan menganalisis struktur HTML yang kita peroleh. Untuk melakukan ini, kami memilih elemen yang diperlukan:
Elements links = document.select("a(href)");Kemudian Anda menelusuri semua elemen yang ditemukan, menampilkan judul dan mengaitkan data dengan layar:
for (Element link : links) {
System.out.println("Title: " + link.text());
System.out.println("Link: " + link.attr("href"));
}Mulai proyek dan lihat hasilnya:
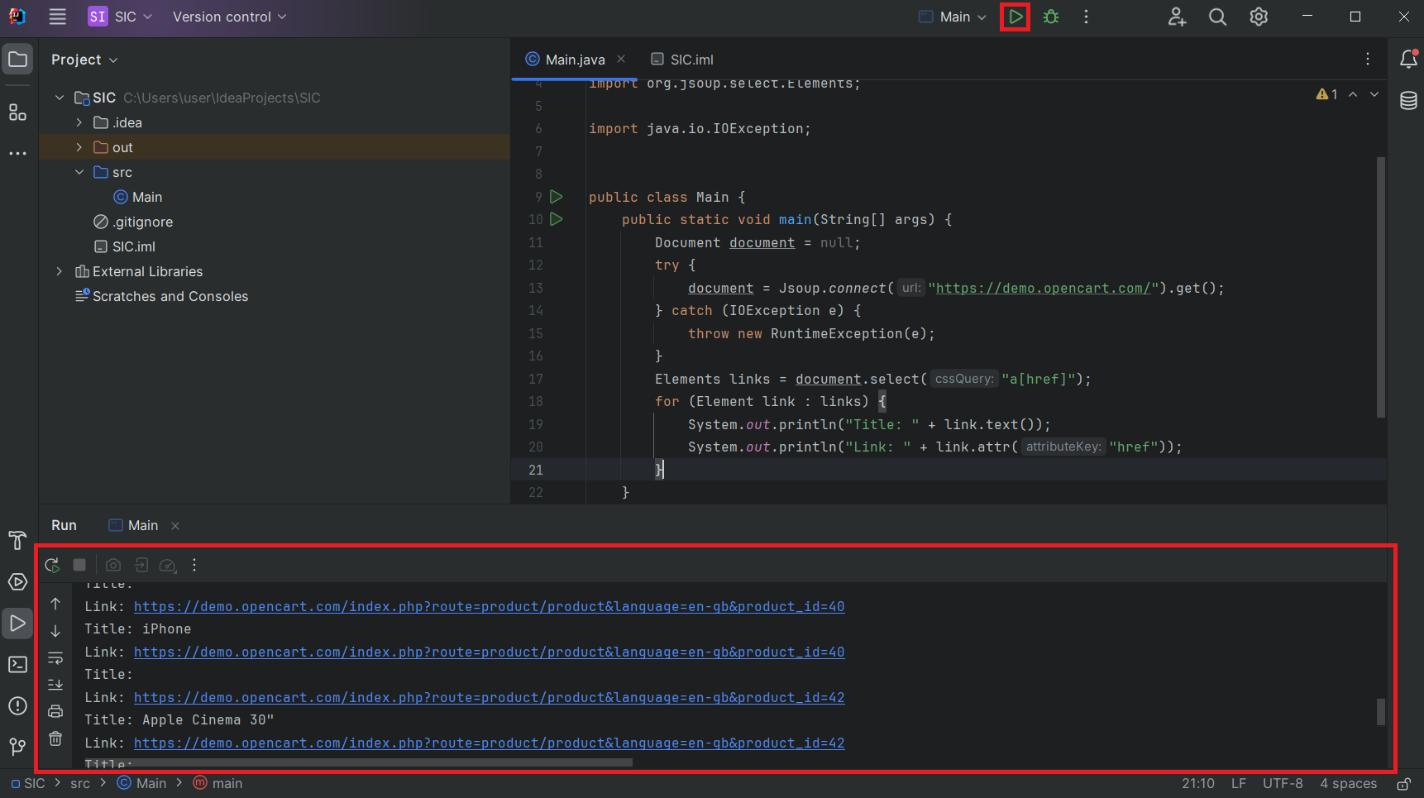
Meskipun menampilkan data di layar merupakan pilihan yang mudah selama pengembangan dan pengujian, hal ini tidak terlalu praktis untuk penyimpanan data. Oleh karena itu, mari pertimbangkan cara menyimpan data dalam CSV dan JSON.
Ekspor sebagai CSV
Untuk menggunakan CSV, Anda harus mengunduh perpustakaan opencsv dan mengimpornya ke proyek Anda. Anda dapat melakukan ini dengan cara yang sama seperti Anda mengimpor Jsoup sebelumnya. Dalam kode Anda, Anda perlu mengimpor modul berikut:
import com.opencsv.CSVWriter;Selain itu, untuk bekerja dengan daftar, kita perlu menggunakan perpustakaan untuk menyimpan informasi tentang semua elemen di halaman:
import java.util.ArrayList;
import java.util.List;Selanjutnya, di fungsi utama, kita menambahkan variabel untuk menyimpan array elemen. Untuk menentukan judul kolom dalam file, pertama-tama masukkan namanya:
List<String()> dataList = new ArrayList<>();
dataList.add(new String(){"Title", "Link"});Dalam perulangan for, kita menambahkan kode untuk menyimpan elemen dalam variabel alih-alih mencetaknya ke layar:
for (Element link : links) {
String title = link.text();
String linkUrl = link.attr("href");
dataList.add(new String(){title, linkUrl});
}Simpan data yang dikumpulkan ke file CSV:
try (CSVWriter writer = new CSVWriter(new FileWriter("data.csv"))) {
writer.writeAll(dataList);
} catch (IOException e) {
e.printStackTrace();
}Menjalankan proyek yang dihasilkan akan menghasilkan file data.csv di folder proyek bersama file proyek lainnya:
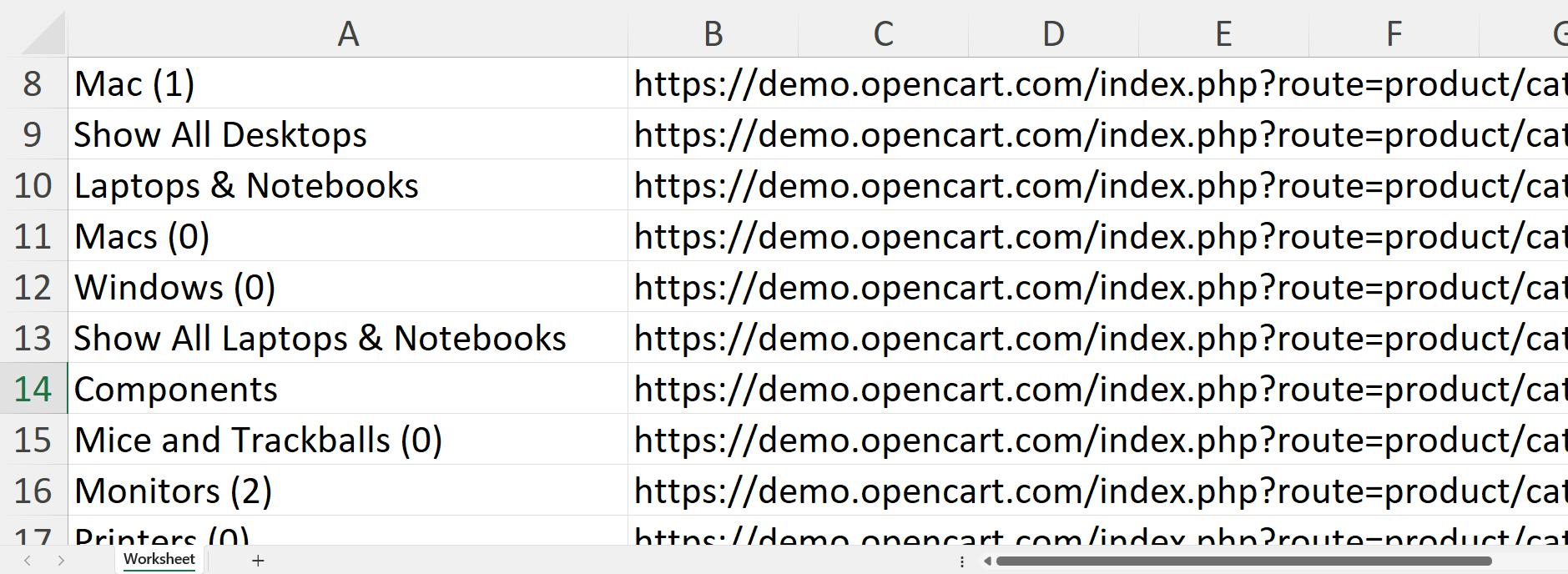
Anda sekarang dapat dengan cepat memproses data dalam sebuah file. Namun, CSV bukanlah format yang baik untuk transfer data. JSON adalah format yang lebih baik, jadi mari kita lihat opsi ekspor lainnya.
Ekspor ke JSON
Untuk bekerja dengan JSON, Anda memerlukan perpustakaan GSON. Impor modul yang diperlukan ke dalam proyek:
import com.google.gson.Gson;Sebagai sumber data kita akan menggunakan daftar yang kita buat pada contoh untuk menyimpan file CSV. Pertama kita perlu membuat objek GSON baru dan mengonversi data dari daftar menjadi string JSON:
Gson gson = new Gson();
String json = gson.toJson(dataList);Kemudian simpan data dalam format JSON:
try (FileWriter writer = new FileWriter("data.json")) {
writer.write(json);
} catch (IOException e) {
e.printStackTrace();
}Anda dapat menggunakan data yang Anda terima untuk mengekspornya ke program lain atau meneruskannya ke program lain.
Topik lanjutan dalam pengikisan web Java
Contoh yang kami pertimbangkan cukup sederhana dan hanya menggunakan fungsi yang relatif sederhana yang bahkan dapat digunakan oleh pemula. Namun, bahasa pemrograman Java memungkinkan lebih banyak hal. Misalnya, Anda dapat menggunakan keterampilan yang Anda pelajari untuk menulis perayap lengkap yang membuat peta situs dan merayapi semua laman.
Katakanlah Anda ingin mempelajari teknik lebih lanjut. Dalam hal ini, kami akan memberi tahu Anda mana yang paling berguna: penggunaan konkurensi dan konkurensi untuk meningkatkan kinerja dan penggunaan browser tanpa kepala untuk mensimulasikan perilaku pengguna guna mengontrol elemen pada halaman dan menghindari pemblokiran.
Strategi perayapan web
Pada artikel sebelumnya kita telah membahas perbedaan antara web crawling dan web scraping. Kami juga membahas cara membuat perayap web dengan Python. Pada artikel ini, kami akan membuat web crawler yang tepat di Java menggunakan keterampilan dan pengetahuan yang telah Anda pelajari. Pertama kita perlu mengimpor modul yang diperlukan dan perpustakaan web scraping Java.
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
import java.util.HashSet;
import java.util.LinkedList;
import java.util.Queue;
import java.util.Set;Selanjutnya, kita membuat kelas dasar dan fungsi serta menentukan URL awal dari mana kita mulai merayapi situs web.
public class WebCrawler {
public static void main(String() args) {
String startUrl = "https://demo.opencart.com/";
//Here will be code
}
}Kami kemudian menentukan variabel untuk melacak URL yang dikunjungi, menambahkan URL baru ke antrean, dan menyimpan alamat unik halaman yang dikunjungi.
Set<String> visitedUrls = new HashSet<>();
Queue<String> queue = new LinkedList<>();
queue.add(startUrl);
Set<String> allVisitedPages = new HashSet<>();Setelah itu, kita membuat loop untuk melintasi antrian alamat.
while (!queue.isEmpty()) {
//Here will be code
}Saat kami mengunjungi suatu halaman, kami menghapusnya dari antrian.
String currentUrl = queue.poll();Jika URL sudah pernah dikunjungi, kita lewati saja.
if (visitedUrls.contains(currentUrl)) {
continue;
}Kami akan menempatkan permintaan dan pengumpulan data di blok coba/tangkap.
try {
Document document = Jsoup.connect(currentUrl).get();
//Here will be code
} catch (IOException e) {
visitedUrls.add(currentUrl);
System.err.println("Error fetching URL: " + currentUrl);
e.printStackTrace();
}Kami menambahkan halaman saat ini ke daftar halaman yang dikunjungi, menemukan semua link di halaman tersebut, dan menambahkan link unik ke antrean untuk kunjungan berikutnya.
allVisitedPages.add(currentUrl);
Elements links = document.select("a(href)");
for (Element link : links) {
String linkText = link.text();
String linkUrl = link.absUrl("href");
if (!visitedUrls.contains(linkUrl)) {
queue.add(linkUrl);
}
}
visitedUrls.add(currentUrl);Terakhir, kami mencetak daftar semua halaman yang dikunjungi.
System.out.println("\nAll Visited Pages:");
for (String page : allVisitedPages) {
System.out.println(page);
}Perayap ini dapat menyelesaikan sebagian besar tugas, dan Anda dapat dengan mudah mengembangkannya dengan fungsionalitas yang diperlukan jika diperlukan.
Paralelisme dan konkurensi
Konkurensi dan konkurensi adalah konsep yang berhubungan dengan pelaksanaan banyak tugas atau proses dalam lingkungan komputasi. Meskipun konsep-konsep ini sering digunakan secara bergantian, keduanya menggambarkan aspek multitasking yang berbeda.
Paralelisme menggambarkan kemampuan untuk melakukan banyak tugas pada waktu yang bersamaan. Namun, karena tugas tidak perlu dilakukan pada waktu yang sama, hal ini dapat dicapai dengan beralih antar tugas secara cepat.
Paralelisme, di sisi lain, menyiratkan pelaksanaan fisik beberapa tugas pada waktu yang sama. Setiap tugas dipecah menjadi subtugas yang lebih kecil dan dijalankan secara bersamaan. Hal ini biasanya diterapkan dengan mendistribusikan data ke beberapa prosesor atau inti.
Untuk memanfaatkan paralelisme, Anda perlu mendefinisikan tugas-tugas tersebut di kelas Thread terpisah, misalnya:
public class MyThread extends Thread {
public void run() {
// Do something
}
}Setelah itu, Anda dapat memanggil thread tertentu di fungsi utama:
MyThread thread1 = new MyThread();
MyThread thread2 = new MyThread();
thread1.start();
thread2.start();Untuk memanfaatkan prinsip konkurensi, Anda memerlukan Fork/Join Framework untuk membuat objek terpisah untuk eksekusi tugas paralel:
ForkJoinPool forkJoinPool = new ForkJoinPool();
ForkJoinTask<Integer> task = new MyForkJoinTask();
forkJoinPool.submit(task);Mempelajari pendekatan ini akan meningkatkan kinerja web scraper Java Anda dan meningkatkan kecepatan pemrosesan data.
Browser tanpa kepala di Java
Browser tanpa kepala sangat penting untuk menyalin situs web dengan keamanan yang lebih kompleks atau yang memerlukan tindakan khusus untuk mendapatkan data. Misalnya, jika Anda perlu login sebelum dapat mengekstrak data, atau jika data di situs web dimuat menggunakan JavaScript. Selain itu, penggunaan browser tanpa kepala dapat membantu mengurangi risiko pemblokiran, misalnya dengan menyimulasikan perilaku pengguna sebenarnya.
HtmlUnit
Seperti disebutkan sebelumnya, HtmlUnit adalah pustaka browser web tanpa kepala yang menawarkan berbagai fitur untuk web scraping. Untuk menggunakannya, Anda perlu mengunduh file JAR perpustakaan dan mengimpor modul yang diperlukan ke proyek Anda.
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import com.gargoylesoftware.htmlunit.html.HtmlAnchor;Setelah Anda mengimpor perpustakaan, Anda dapat membuat kelas dan fungsi untuk menangani tugas pengikisan Anda.
public class HtmlUnitHeadlessExample {
public static void main(String() args) {
// Here will be code
}
}Untuk membuka halaman web di browser tanpa kepala, Anda perlu membuat instance baru dari kelas WebDriver dan mengonfigurasi pengaturan tambahan seperti: B. mode operasi dan parameter tampilan.
WebClient webClient = new WebClient(BrowserVersion.CHROME);
webClient.getOptions().setCssEnabled(false); Setelah halaman web terbuka, Anda dapat menggunakan objek WebDriver untuk berinteraksi dengan halaman tersebut, seperti: B. mengklik link, mengisi formulir dan menganalisis kode HTML.
try {
HtmlPage page = webClient.getPage("https://demo.opencart.com/");
java.util.List<HtmlAnchor> anchors = page.getByXPath("//a");
for (HtmlAnchor anchor : anchors) {
System.out.println("Title: " + anchor.asText());
System.out.println("Link: " + anchor.getHrefAttribute());
}
} catch (Exception e) {
e.printStackTrace();
}Setelah selesai menyalin halaman, Anda harus menutup objek WebDriver untuk mengosongkan sumber daya.
finally {
webClient.close();
}Menggunakan browser tanpa kepala adalah pilihan yang baik untuk menyalin situs web yang tidak memerlukan antarmuka pengguna grafis. Ini bisa lebih cepat dan efisien dibandingkan browser web tradisional, dan juga lebih mudah untuk mengotomatisasi tugas.
Selenium WebDriver
Selenium adalah kerangka kerja lintas platform yang mendukung sebagian besar bahasa pemrograman, termasuk Java. Kita sudah membahas penggunaan dan pengaturannya di Python, jadi mari kita lihat cara menggunakannya di Java.
Untuk menggunakan Selenium Anda memerlukan dua hal:
- Perpustakaan Selenium. Impor ke proyek Anda seperti perpustakaan lainnya.
- Seorang pengemudi web. Versinya harus sama dengan browser yang Anda instal. Anda dapat mengunduh WebDriver yang diperlukan dari situs resmi Chrome, Firefox, dan Edge.
Anda harus mengimpor modul yang diperlukan ke proyek Anda untuk menggunakan Selenium dengan Java.
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;Selanjutnya, buat kelas utama dan fungsinya. Kemudian tentukan jalur ke file WebDriver dan atur pengaturan dan parameter yang diinginkan.
public class SeleniumExample {
public static void main(String() args) {
System.setProperty("webdriver.chrome.driver", "path/chromedriver");
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless");
WebDriver driver = new ChromeDriver(options);
// Extract data
}
}Jangan lupa untuk menutup instance WebDriver setelah selesai.
driver.quit();Selenium adalah perpustakaan yang menarik untuk tugas pengikisan dan otomatisasi. Ini mendukung berbagai fungsi untuk mencari dan berinteraksi dengan elemen, menjadikannya alat serbaguna untuk banyak aplikasi.
Tantangan Web Scraping dengan Java
Pengikisan web adalah salah satu tugas pengumpulan data otomatis yang paling umum. Namun, proses ini juga mempunyai beberapa tantangan. Itu Tantangan dalam web scraping di Java dapat dibagi menjadi dua jenis:
- Tantangan yang terkait dengan melewati perlindungan situs web. Ini adalah tantangan umum web scraping yang tidak spesifik untuk Java. Untuk mengatasinya, Anda dapat menggunakan metode berikut: proxy, browser tanpa kepala, atau API web scraping bawaan yang menangani tantangan ini untuk Anda.
- Tantangan terkait Java. Tantangan tersebut antara lain kekurangan bahasa itu sendiri yang telah kita bahas di awal artikel. Ini termasuk kesulitan mempelajari Java dan beratnya program web scraping yang dihasilkan. Seperti disebutkan sebelumnya, Java bukanlah pilihan yang baik untuk proyek kecil, namun bisa menjadi pilihan yang baik untuk web scraper yang besar atau skalabel.
Oleh karena itu, sebelum membuat web scraper di Java, Anda perlu memastikan bahwa itu adalah solusi terbaik untuk proyek Anda dan Anda dapat mengatasi semua tantangan yang terkait dengannya. Jika Anda ingin menyederhanakan tugas dan mempercepat kinerja program Anda, pertimbangkan untuk menggunakan API web scraping siap pakai yang akan melakukan pengumpulan data untuk Anda.
Kesimpulan dan eksplorasi lebih lanjut
Dalam panduan komprehensif ini, kami telah menjawab semua pertanyaan yang kami ajukan di awal artikel. Kami juga menunjukkan cara menginstal komponen Java dan membuat scraper dan crawler. Selain itu, kami menunjukkan cara mengambil data yang diperlukan dan menyimpannya dalam format yang sesuai.
Kami berharap tutorial web scraping Java ini bermanfaat baik bagi pemula maupun programmer Java berpengalaman. Bahkan pemrogram berpengalaman pun mungkin menemukan sesuatu yang menarik di bagian teknik lanjutan.
Dengan menggunakan keterampilan yang telah Anda pelajari di artikel ini, Anda dapat dengan mudah membuat scraper untuk mengumpulkan data secara otomatis dari situs web, mengoptimalkannya, dan bahkan mensimulasikan perilaku pengguna sebenarnya menggunakan browser tanpa kepala.