
WordPress, ditambah dengan plugin WooCommerce, adalah pilihan yang populer dan praktis untuk menciptakan pasar online. Ini menawarkan platform yang ramah pengguna untuk membangun toko eCommerce yang indah dan fungsional dengan sedikit usaha.
WooCommerce Web Scraping adalah metode ekstraksi data otomatis dari toko WooCommerce. Metode ini memungkinkan berbagai tujuan termasuk pemantauan harga dan penetapan harga dinamis, melacak harga produk pesaing, dan memperbarui harga produk secara otomatis agar tetap kompetitif. Hal ini juga memungkinkan otomatisasi tugas rutin seperti mengambil deskripsi dan spesifikasi produk, memperbarui informasi produk secara otomatis, dan mengumpulkan ulasan produk.
Oleh karena itu, scraper WooCommerce tidak hanya mempermudah pekerjaan pemilik toko dengan memberi mereka akses cepat ke informasi kompetitif yang penting, namun juga membantu mereka mengelola bisnis secara lebih efektif dengan membuat keputusan berdasarkan data.
Artikel ini akan mengeksplorasi berbagai jenis scraper dan memandu Anda dalam menciptakan solusi universal untuk melakukan scraping pada sebagian besar toko WooCommerce menggunakan Python. Kami menyediakan skrip siap pakai yang dapat digunakan siapa saja, bahkan dengan pengetahuan pemrograman minimal. Namun, jika Anda tertarik untuk melakukan scraping tetapi tidak memiliki pengalaman pemrograman, kami sarankan membaca artikel kami tentang web scraping dengan Google Sheets. Pada artikel ini, kami telah menjelaskan proses menggunakan toko WooCommerce sebagai contoh.
Daftar Isi
Jenis Scraper WooCommerce
Scraper WooCommerce adalah alat untuk mengekstraksi data dari toko online berbasis WooCommerce. Pencakar ini hadir dalam desain yang berbeda tergantung pada fungsi, kompleksitas dan tujuan. Berikut adalah beberapa jenis scraper WooCommerce yang umum:
- Pengikis produk. Kumpulkan informasi produk seperti nama, deskripsi, harga, gambar, kategori dan SKU.
- Pengikis harga. Lacak perubahan harga, diskon, penawaran khusus, dan biaya pengiriman.
- Pengikis peringkat. Kumpulkan umpan balik pelanggan, ulasan, komentar, dan informasi bermanfaat lainnya.
Meskipun mengkategorikan web scraper ke dalam jenis yang berbeda dapat membantu saat memilih alat yang sudah dibuat sebelumnya, perlu diingat bahwa membuat scraper sendiri memberi Anda kendali penuh atas informasi yang Anda terima. Salah satu keuntungan utama dari scraper khusus adalah kemampuan untuk mengekstrak semua informasi yang diperlukan tanpa batasan apa pun.
Saat membuat scraper, Anda dapat menentukan dengan tepat data yang Anda perlukan dan mengonfigurasi scraper yang sesuai. Anda tidak dibatasi oleh jenis scraper yang telah ditentukan sebelumnya atau batasan oleh alat pihak ketiga.
Selain itu, membuat scraper sendiri memberi Anda fleksibilitas untuk menyesuaikannya guna memenuhi kebutuhan unik proyek Anda. Anda dapat menambahkan fitur baru, meningkatkan kinerja, dan secara fleksibel menyesuaikan scraper dengan perubahan di situs web atau kebutuhan bisnis Anda.
Cara membuat pengikis WooCommerce
Sebelum Anda mulai menghapus WooCommerce, penting untuk memutuskan pendekatannya. Ada dua pendekatan utama:
- Hapus data dari halaman produk. Metode ini mengekstrak informasi produk langsung dari halaman penyajiannya. Dengan pendekatan ini kita bisa mendapatkan informasi dasar seperti nama produk, harga dan foto. Namun, kami tidak dapat memperoleh ulasan, deskripsi, atau informasi detail lainnya dari halaman produk secara umum.
- Gunakan Peta Situs untuk mendapatkan daftar produk dan kemudian mencarinya. Opsi kedua adalah mengakses Peta Situs situs, yang mencantumkan semua halaman produk. Anda kemudian dapat membuka halaman-halaman ini dan mengumpulkan informasi tentang setiap produk. Keuntungannya adalah kita bisa mendapatkan semua informasi yang tersedia untuk setiap produk, dan kerugiannya adalah kita harus membuat permintaan ke semua situs, yang bisa memakan lebih banyak waktu dan sumber daya.
Kedua pendekatan tersebut mempunyai kelebihan dan kekurangan dan pilihannya bergantung pada kebutuhan spesifik proyek. Pada artikel ini, kita akan melihat kedua metode tersebut, menjelaskan fitur-fiturnya, dan menyediakan skrip siap pakai yang dapat langsung Anda gunakan untuk mengikis data dari WooCommerce.
Mengikis data produk dari halaman pencarian
Mari kita mulai dengan pendekatan paling sederhana: menganalisis halaman produk, mengidentifikasi pemilih elemen, dan mengekstraknya. Untuk membuat contoh lebih beragam, kami mendapatkan kode halaman secara berbeda, menggunakan perpustakaan Permintaan dan BeautifulSoup dan opsi yang lebih kompleks menggunakan API web scraping.
Identifikasi data sasaran
Pertama-tama mari kita tentukan elemen target menggunakan salah satu situs sebagai contoh. Untuk melakukannya, buka halaman produk situs WooCommerce yang terlihat seperti ini: “https://example.com/shop” dan buka DevTools (F12 atau klik kanan dan “Inspeksi”).
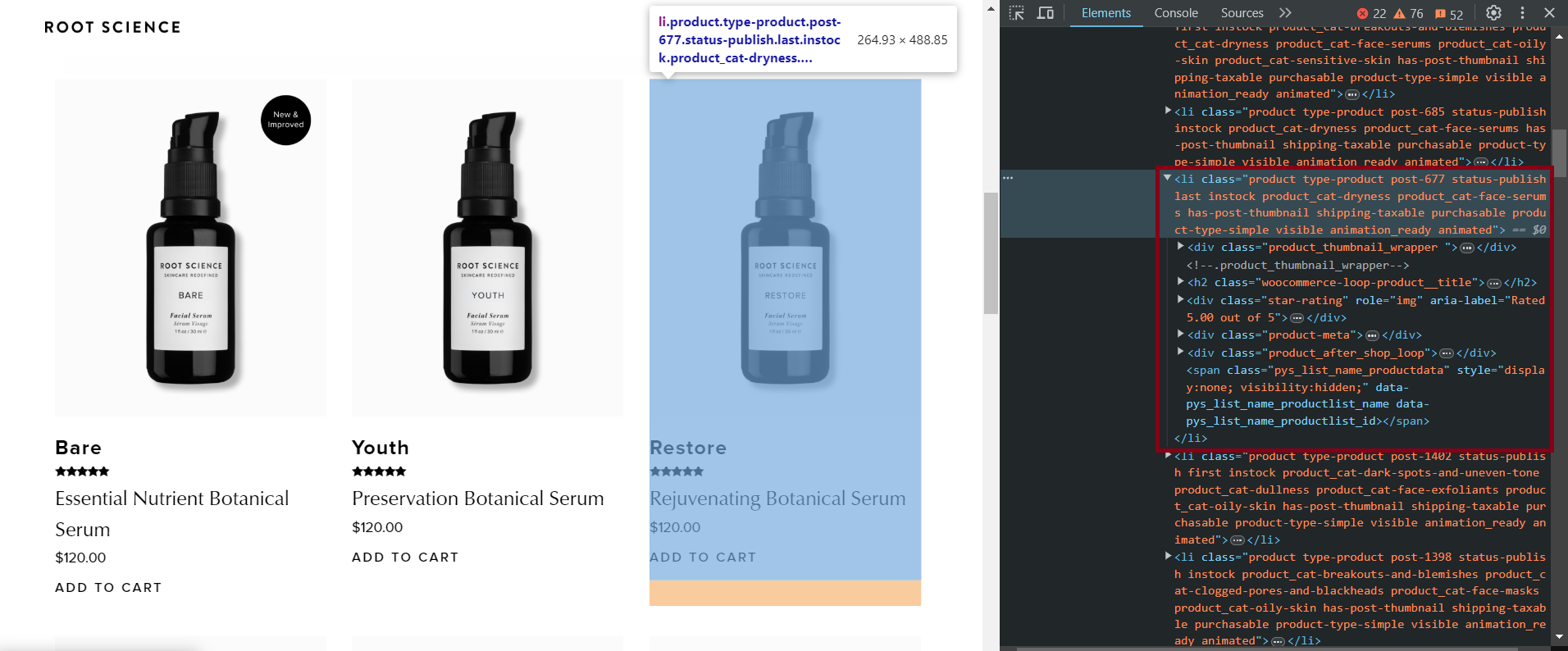
Berikut adalah pemilih CSS untuk berbagai elemen yang dapat mengekstrak semua informasi produk yang tersedia:
- judul:
h2.woocommerce-loop-product__title - Evaluasi:
.star-rating - Keterangan:
.product-meta - Harga:
.price .woocommerce-Price-amount - Tautan gambar:
img - Tautan ke halaman produk:
.woocommerce-LoopProduct-link
Penyeleksi ini telah diuji di beberapa situs web WooCommerce dan terbukti berfungsi di sebagian besar situs web. Namun, beberapa sumber daya mungkin tidak memiliki elemen tertentu, seperti: B.Deskripsi produk.
Pengikisan statis
Kami akan menggunakan Python untuk skrip, tapi jangan khawatir jika Anda tidak memiliki pengalaman pemrograman. Kami memilih Python karena sederhana, fungsional, dan memungkinkan kami berbagi skrip yang telah ditulis sebelumnya dengan mudah melalui Google Colaboratory yang dapat Anda jalankan dan gunakan segera.
Anda dapat menemukan dan menggunakan skrip yang sudah selesai di sini. Untuk menggunakannya, cukup ganti URL website dengan URL yang ingin Anda pindai lalu jalankan setiap blok kode satu per satu.
Untuk menjalankan skrip di PC Anda (bukan di Colaboratory), Anda memerlukan Python versi 3.10 atau lebih tinggi. Untuk instruksi tentang menyiapkan lingkungan Anda dan membuat scraper, lihat artikel pengantar scraping Python kami.
Buat file *.py baru dan impor perpustakaan yang diperlukan:
import requests
from bs4 import BeautifulSoupTentukan variabel untuk menyimpan URL situs web WooCommerce dan tambahkan bagian “Toko” tempat semua produk berada.
base_url = "https://www.shoprootscience.com/"
url = base_url + "shop"Buat variabel untuk menyimpan produk:
all_products = ()Kirim permintaan GET ke URL dan dapatkan HTML seluruh halaman:
response = requests.get(url)Periksa apakah kode status respons adalah 200, yang menunjukkan respons berhasil:
if response.status_code == 200:Buat objek BeautifulSoup dan parsing halaman untuk mempermudah navigasi dan pengambilan item:
soup = BeautifulSoup(response.content, 'html.parser')Identifikasi pemilih yang paling tepat untuk menemukan elemen produk. Berdasarkan observasi dari beberapa situs WooCommerce, produk kemungkinan disimpan dalam tag "li" atau "div" dengan kelas "produk":
products = soup.find_all(('li', 'div'), class_='product')Telusuri semua produk yang ditemukan satu per satu:
for product in products:Ekstrak semua data yang tersedia:
# Extract product title
title_elem = product.find('h2', class_='woocommerce-loop-product__title')
title_text = title_elem.text.strip() if title_elem else '-'
# Extract product rating
rating_elem = product.find('div', class_='star-rating')
rating_text = rating_elem('aria-label') if rating_elem else '-'
# Extract product description
description_elem = product.find('div', class_='product-meta')
description_text = description_elem.text.strip() if description_elem else '-'
# Extract product price
price_elem = product.find('span', class_='price')
price_text = price_elem.text.strip() if price_elem else '-'
# Extract product image link
image_elem = product.find('img')
image_src = image_elem('src') if image_elem else '-'
# Extract product page link
product_link_elem = product.find('a', class_='woocommerce-LoopProduct-link')
product_link = product_link_elem('href') if product_link_elem else '-'Dalam kode ini kami mengatasi kemungkinan hilangnya data produk. Daripada menampilkan nilai, kita cukup menyisipkan “-” sebagai gantinya. Pendekatan ini tidak hanya membantu kita mengatur keluaran tetapi juga menghindari kesalahan ketika ada elemen yang hilang.
Cetak daftar produk dengan semua data yang dikumpulkan:
print(f"Title: {title_text}")
print(f"Rating: {rating_text}")
print(f"Description: {description_text}")
print(f"Price: {price_text}")
print(f"Image Link: {image_src}")
print(f"Product Page Link: {product_link}")
print('-' * 50)Simpan data produk ke variabel untuk penyimpanan nanti:
all_products.append((title_text, rating_text, description_text, price_text, image_src, product_link))Tangani kesalahan ketika kode status bukan 200:
else:
print("Error fetching page:", response.status_code)Kode ini mengambil daftar produk dengan semua data yang kami kumpulkan:
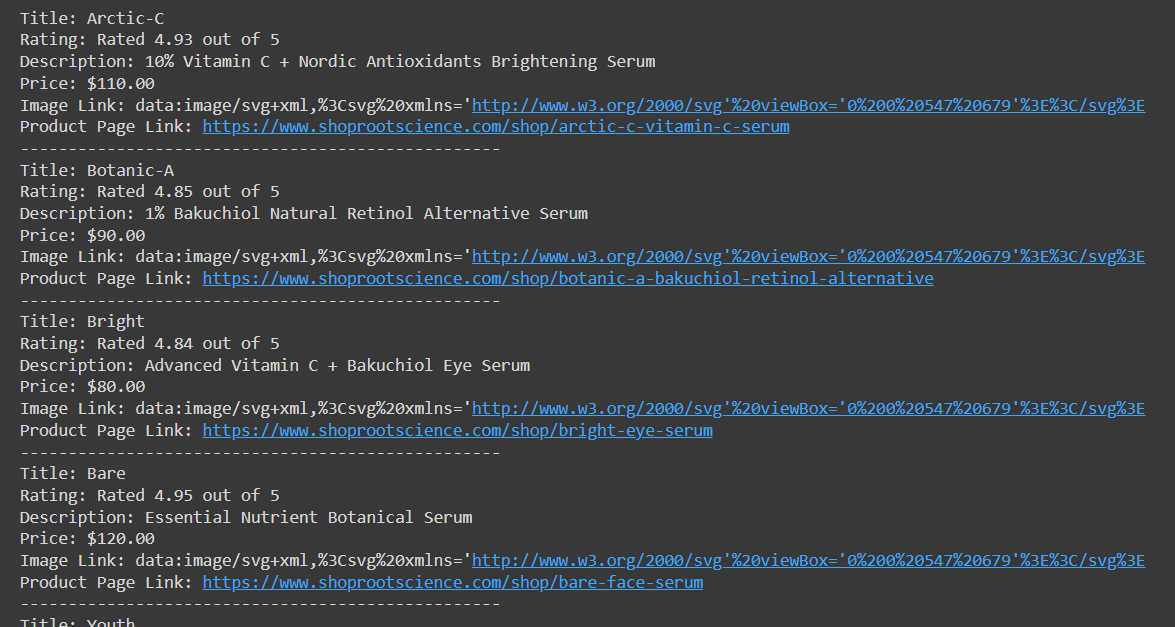
Nanti kita akan membahas tentang menyimpan data dalam CSV, namun pertama-tama mari kita bahas tentang kekurangan metode pengumpulan data ini. Meskipun kami berhasil mengekstrak data dengan cara ini, beberapa situs dengan mudah mengenali skrip seperti bot dan memblokir aksesnya ke sumber daya.
Misalnya, Anda dapat melihat ini jika Anda mencoba memindai situs web WooCommerce lain dengan perlindungan seperti ini. Jika Anda mencoba mengumpulkan data menggunakan skrip yang Anda buat sebelumnya, Anda akan mendapatkan kode status “403 Forbidden”. Namun jangan khawatir, masalah ini dapat diatasi dengan mudah dengan dua cara:
- Gunakan perpustakaan Selenium, Pyppeteer, atau PlayWright untuk mengikis dengan browser tanpa kepala untuk mensimulasikan perilaku pengguna sebenarnya. Anda juga perlu menghubungkan proxy untuk melindungi diri Anda dan mencapai anonimitas yang lebih baik, serta layanan penyelesaian captcha yang akan berguna saat proxy tersebut muncul.
- Gunakan API Pengikisan Web. Sumber daya pihak ketiga ini sudah menggunakan proxy, melewati captcha, dan meminta halaman arahan. Dalam hal ini, yang Anda dapatkan hanyalah halaman HTML situs web dan Anda tidak memerlukan apa pun lagi.
Kami akan menggunakan opsi kedua karena lebih sederhana dan juga dapat digunakan di Google Colaboratory, tidak seperti browser tanpa kepala.
Mengikis dengan API
Seperti disebutkan sebelumnya, tidak semua situs web merespons positif penggunaan perpustakaan Permintaan. Oleh karena itu, mari pertimbangkan untuk menggunakan web scraping API Hasdata. Untuk menggunakannya, yang perlu Anda lakukan hanyalah mendaftar di situs web dan masuk ke akun pribadi Anda untuk menemukan kunci API Anda.
Anda juga dapat menemukannya skrip yang sudah selesai di Colab Researchdan untuk menggunakannya, Anda hanya perlu memasukkan kunci API dan URL situs WooCommerce yang ingin Anda jelajahi.
Sekarang mari kita lihat langkah demi langkah cara membuat skrip seperti itu. Pertama, buat file baru dengan ekstensi *.py dan impor perpustakaan yang diperlukan:
import requests
from bs4 import BeautifulSoup
import csv
import jsonSeperti yang Anda lihat, kami juga mengimpor perpustakaan JSON di sini karena Web Scraping API mengembalikan data dalam format JSON.
Kami kemudian membuat variabel dan menentukan kunci API, URL situs web yang akan diambil, dan titik akhir API:
api_key = "YOUR-API-KEY"
base_url = "https://bloomscape.com/"
url = base_url + "shop"
base_api_url = "https://api.scrape-it.cloud/scrape/web"
all_products = ()Sekarang mari kita tentukan isi permintaan dan header untuk API. Di sini Anda dapat menentukan jenis dan negara proxy yang diinginkan, apakah akan mengambil tangkapan layar halaman, mengekstrak email, dan banyak lagi. Daftar lengkap parameter dapat ditemukan di halaman dokumentasi.
payload = json.dumps({
"url": url,
"js_rendering": True,
"proxy_type": "datacenter",
"proxy_country": "US"
})
headers = {
"x-api-key": api_key,
"Content-Type": "application/json"
}Buat sebuah permintaan:
response = requests.request("POST", base_api_url, headers=headers, data=payload)Maka skripnya identik dengan contoh sebelumnya, hanya saja kita mendapatkan HTML halaman tersebut dari respons JSON API web scraping:
if response.status_code == 200:
data = json.loads(response.text)
html_content = data("content")
soup = BeautifulSoup(html_content, 'html.parser')
products = soup.find_all(('li', 'div'), class_='product')
for product in products:
title_elem = product.find('h2', class_='woocommerce-loop-product__title')
title_text = title_elem.text.strip() if title_elem else '-'
rating_elem = product.find('div', class_='star-rating')
rating_text = rating_elem('aria-label') if rating_elem else '-'
description_elem = product.find('div', class_='product-meta')
description_text = description_elem.text.strip() if description_elem else '-'
price_elem = product.find(('span','div'), class_='price')
price_text = price_elem.text.strip() if price_elem else '-'
image_elem = product.find('img')
image_src = image_elem('src') if image_elem else '-'
product_link_elem = product.find('a', class_='woocommerce-LoopProduct-link')
product_link = product_link_elem('href') if product_link_elem else '-'
print(f"Title: {title_text}")
print(f"Rating: {rating_text}")
print(f"Description: {description_text}")
print(f"Price: {price_text}")
print(f"Image Link: {image_src}")
print(f"Product Page Link: {product_link}")
print('-' * 50)
all_products.append((title_text, rating_text, description_text, price_text, image_src, product_link))
else:
print("Error fetching data from the API:", response.status_code)Pendekatan ini memungkinkan akses ke data yang sebelumnya tidak tersedia:
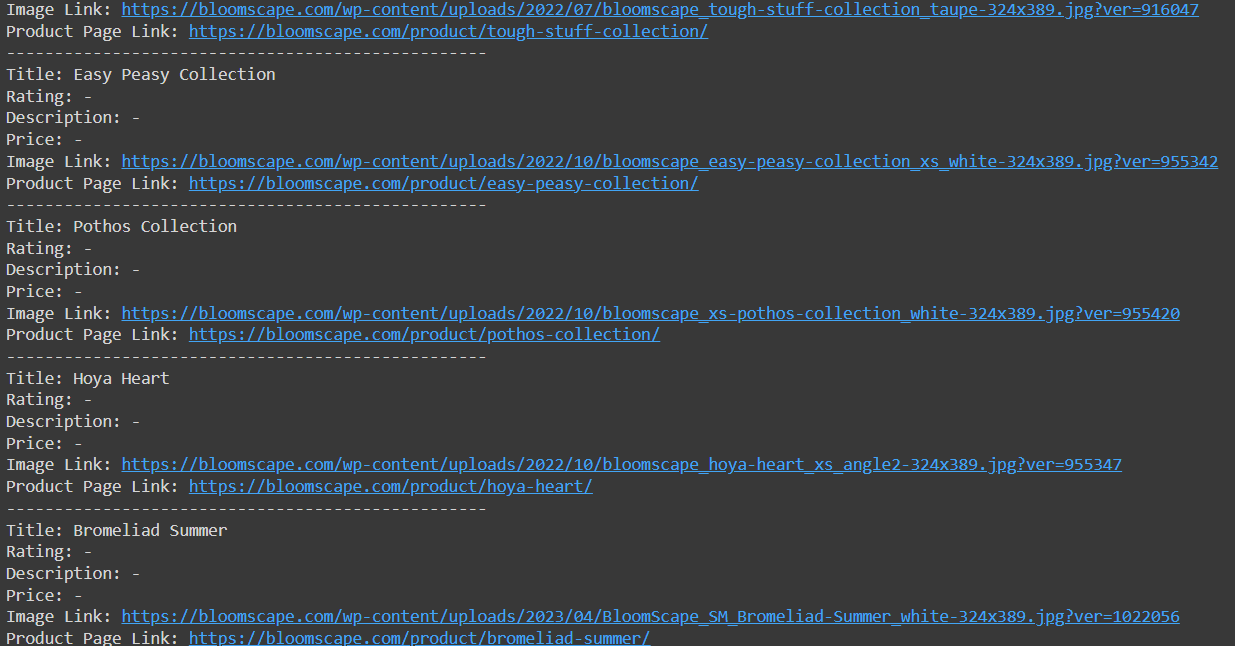
Sekarang yang harus kita lakukan hanyalah menyimpan data yang sudah kita kumpulkan.
Simpan data yang tergores
Untuk menyimpan data ke file CSV dengan Python, kami menggunakan perpustakaan CSV dan data dari variabel all_products. Buat objek CSVWriter menggunakan csv.writer() Fungsi. Kemudian tentukan nama file termasuk ekstensi *.csv, buka dalam mode tulis ('w') dan tulis judul kolomnya writerow() metode dan tulis baris data menggunakan writerows() Metode. Lewati itu all_products Variabel sebagai argumen:
with open('products.csv', 'w', newline="", encoding='utf-8') as csvfile:
csvwriter = csv.writer(csvfile)
csvwriter.writerow(('Title', 'Rating', 'Description', 'Price', 'Image Link', 'Product Page Link'))
csvwriter.writerows(all_products)Anda dapat memilih nama file yang berbeda tergantung kebutuhan Anda. Misalnya, jika Anda memiliki data dari beberapa situs web, Anda dapat menggunakan nama situs web sebagai nama file. Anda juga dapat memasukkan tanggal saat ini dalam nama file untuk melacak kesegaran data.
Menghapus tautan produk dan data dari peta situs
Sebagian besar situs web yang dibangun di WordPress dengan plugin WooCommerce memiliki struktur halaman HTML dan peta situs yang serupa. Hal ini memungkinkan kami dengan cepat mendapatkan tautan ke semua halaman produk, menjelajahinya, dan mengumpulkan informasi lengkap tentang semua produk di situs. Meskipun strukturnya mungkin sedikit berbeda tergantung topiknya, kami akan mempertimbangkan skenario yang paling umum.
Jika Anda menginginkan skrip yang sudah jadi, buka halaman skrip Google Colaboratory, atur parameter Anda dan dapatkan semua informasi yang Anda butuhkan.
Dapatkan file XML peta situs
Pertama, mari buat skrip untuk mengumpulkan tautan halaman produk dari berbagai situs web WooCommerce. Untuk melakukan ini, kami menavigasi ke halaman peta situs dan memeriksa strukturnya. Kebanyakan peta situs mengikuti format ini:
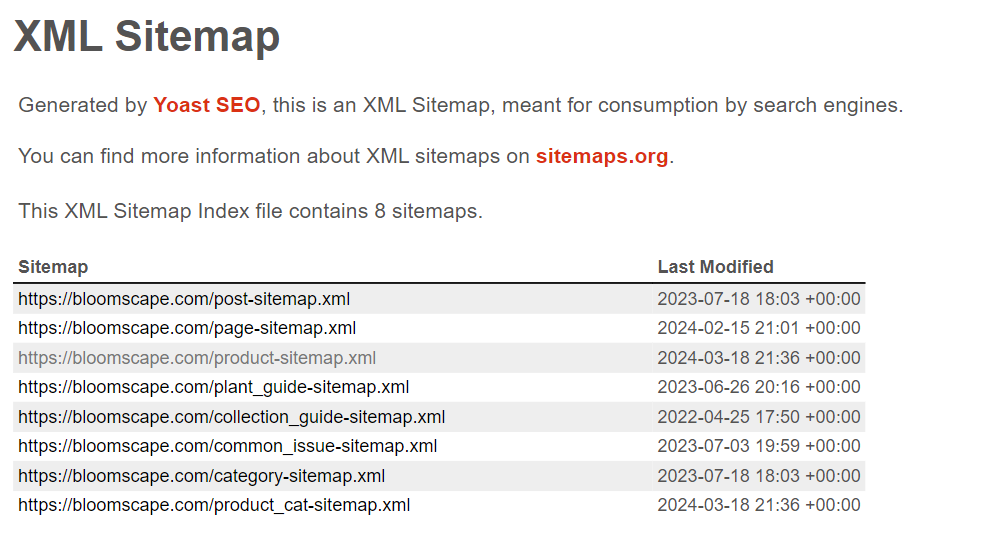
Beberapa detail mungkin berbeda tergantung pada tema yang diinstal. Namun yang terpenting adalah mencari daftar link produk product-sitemap.xml Halaman.

Untuk mendapatkan konten halaman ini, kita memerlukan perpustakaan Permintaan yang telah dibahas sebelumnya untuk mengirim permintaan dan perpustakaan LXML untuk memproses data XML halaman tersebut. Mari buat file baru dan impor perpustakaan yang diperlukan:
import requests
from lxml import etreeUntuk mengambil konten halaman kita dapat menggunakan perpustakaan Permintaan seperti sebelumnya:
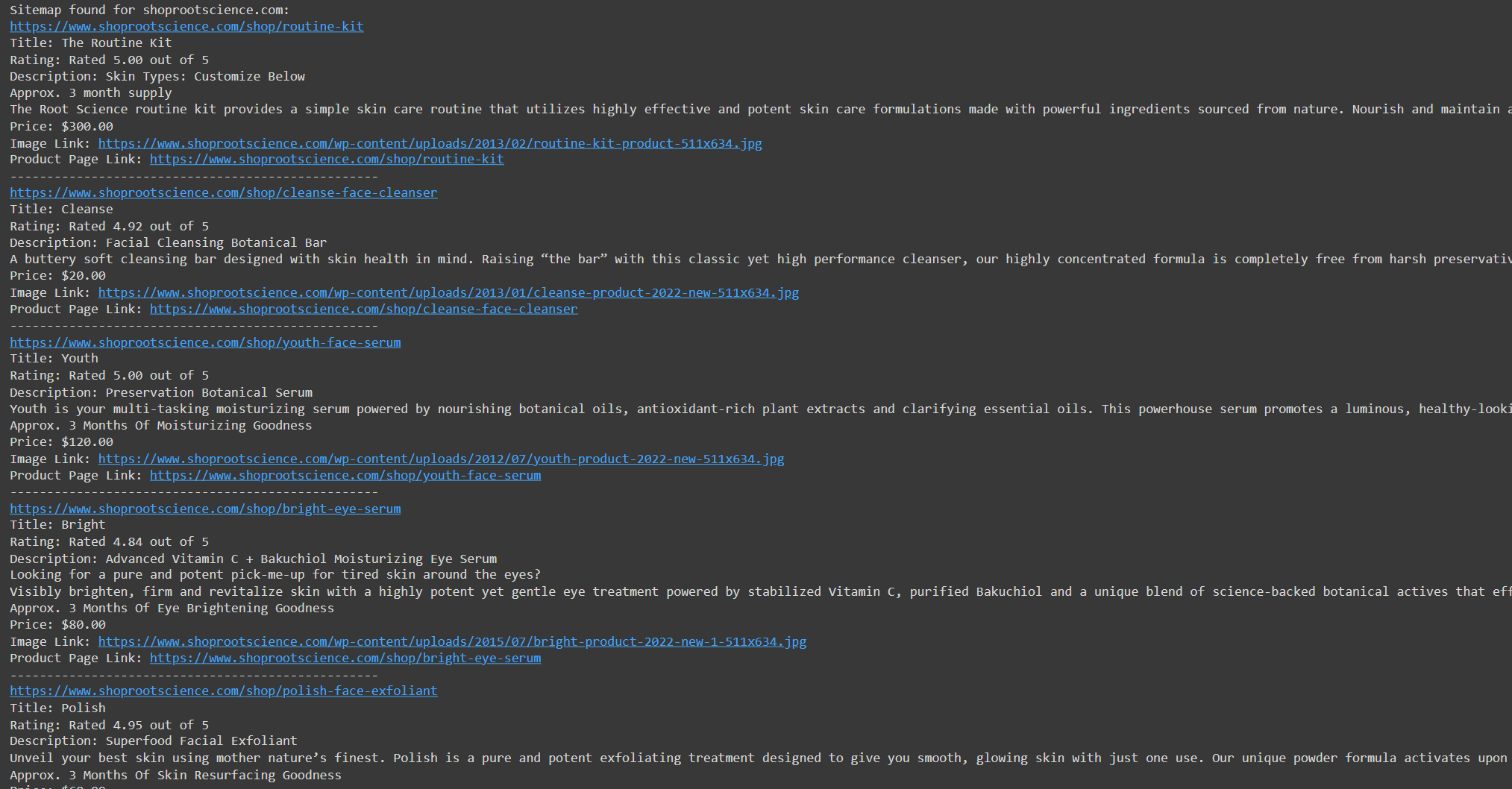
domain = "shoprootscience.com"
sitemap_url = f"https://{domain}/product-sitemap.xml"
response = requests.get(sitemap_url)Setelah berhasil mengambil konten halaman XML, yang perlu kita lakukan hanyalah menguraikannya untuk mengekstrak link yang diperlukan.
Mari kita mulai dari contoh sebelumnya dan periksa apakah kita menerima kode status 200:
if response.status_code == 200:Jika demikian, kami menyimpan semua tautan yang ditemukan dalam sebuah variabel:
sitemap_content = response.content
root = etree.fromstring(sitemap_content)
urls = ()
for child in root:
for sub_child in child:
urls.append(sub_child.text)
if urls:
print(f"Sitemap found for {domain}:")
for url in urls:
if domain in url:
print(url)
else:
print(f"No URLs found in the sitemap for {domain}.")Jika tidak, cetak pemberitahuan:
else:
print(f"No sitemap found for {domain}.")Jika Anda hanya perlu mengumpulkan tautan produk dari situs WooCommerce, Anda dapat menggunakan skrip Penelitian Colab kami.
Jelajahi semua halaman produk
Mari tingkatkan lebih lanjut skrip kita dengan mengikuti tautan alih-alih menampilkannya di layar dan mengumpulkan semua data yang diperlukan tentang setiap produk.
Buat variabel terpisah tempat kita akan menyimpan data produk.
all_products = ()Impor perpustakaan BeautifulSoup untuk dapat menganalisis data di halaman:
from bs4 import BeautifulSoupSekarang mari beralih ke bagian di mana kita menelusuri tautan yang dikumpulkan dan menampilkannya di layar. Anda mungkin telah memperhatikan bahwa saat mengambil link dari peta situs, link pertama selalu mengarah ke halaman semua produk dan diakhiri dengan “Toko”. Jadi mari kita tambahkan tanda centang untuk memastikan itu bukan URL saat ini:
if domain in url and not url.endswith("shop"):Selebihnya sama dengan yang telah kami lakukan, hanya saja kami menggunakan pemilih yang sedikit berbeda yang sesuai untuk halaman produk:
response_product = requests.get(url)
if response_product.status_code == 200:
soup = BeautifulSoup(response_product.content, 'html.parser')
title_elem = soup.find('h1', class_='product_title')
title_text = title_elem.text.strip() if title_elem else '-'
rating_elem = soup.find('div', class_='star-rating')
rating_text = rating_elem('aria-label') if rating_elem else '-'
description_elem = soup.find('div', class_='woocommerce-product-details__short-description')
description_text = description_elem.text.strip() if description_elem else '-'
price_elem = soup.find(('div', 'span'), class_='woocommerce-Price-amount')
price_text = price_elem.text.strip() if price_elem else '-'
product = soup.find(('li', 'div'), class_='product')
image_elem = product.find('img')
image_src = image_elem('src') if image_elem else '-'
product_link = urlTampilkan data di layar dan simpan dalam variabel untuk kemudian disimpan ke file:
print(f"Title: {title_text}")
print(f"Rating: {rating_text}")
print(f"Description: {description_text}")
print(f"Price: {price_text}")
print(f"Image Link: {image_src}")
print(f"Product Page Link: {product_link}")
print('-' * 50)
all_products.append((title_text, rating_text, description_text, price_text, image_src, product_link))Mari jalankan kodenya dan periksa fungsinya:
Sekarang mari kita simpan data yang diekstraksi dalam format berbeda.
Simpan data dalam CSV, JSON atau DB
Format penyimpanan data yang paling umum adalah CSV dan JSON. Kami juga menunjukkan cara menyimpan data dalam database. Kami memilih opsi paling sederhana dan menggunakan perpustakaan SQLite3 untuk menulis data ke file DB. Kami akan menggunakan perpustakaan lain, Pandas, untuk menyimpan data dalam JSON dan CSV karena lebih mudah diterapkan.
Mari impor perpustakaan:
import pandas as pd
import sqlite3Di akhir skrip, kami menerapkan penyimpanan data ke file CSV menggunakan perpustakaan Pandas:
df = pd.DataFrame(all_products, columns=('Title', 'Rating', 'Description', 'Price', 'Image Link', 'Product Page Link'))
df.to_csv('products.csv', index=False)Kami akan menggunakan bingkai data yang sama dan menyimpan data di JSON:
df.to_json('products.json', orient="records")Terakhir, kita membuat koneksi ke file database, memasukkan data dan menutup koneksi:
conn = sqlite3.connect('products.db')
df.to_sql('products', conn, if_exists="replace", index=False)
conn.close()Seperti yang Anda lihat, Pandas memungkinkan Anda menyimpan data dengan cukup cepat berkat bingkai data. Perpustakaan ini mendukung lebih banyak opsi penyimpanan daripada yang dipertimbangkan. Untuk informasi lebih lanjut tentang perpustakaan ini dan fitur-fiturnya, lihat dokumentasi resmi.
Uji scraper di berbagai situs WooCommerce
Mari kita uji skrip ini di tiga situs web WooCommerce untuk memastikan keserbagunaannya. Kami memodifikasi skrip untuk melintasi beberapa situs web, bukan hanya satu situs web, dan menyimpan data yang diekstraksi ke file CSV.
Anda dapat menemukan skripnya di Google Colaboratory. Disini kami hanya menampilkan hasil pelaksanaannya di berbagai situs:
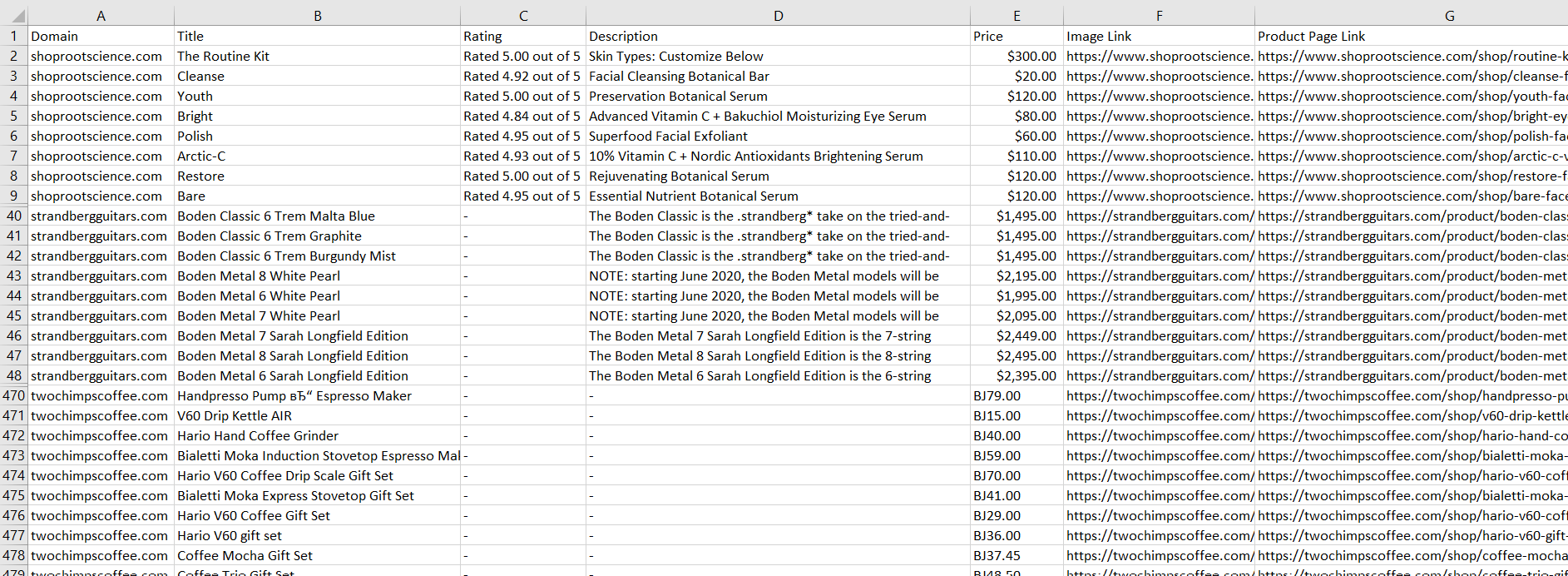
Seperti yang Anda lihat dari tangkapan layar, karena struktur semua halaman WooCommerce yang serupa, kami dapat dengan mudah mengekstrak data yang diperlukan menggunakan alat universal.
Kesimpulan dan temuan
Panduan ini memberikan gambaran umum tentang cara membuat scraper WooCommerce untuk mengakses data produk dan elemen penting lainnya dari toko online. Kami melihat dua metode utama: mengambil halaman produk secara langsung dan menggunakan Peta Situs untuk daftar produk. Skrip yang disediakan dapat beradaptasi dengan sebagian besar situs web WooCommerce karena strukturnya yang serupa.
Saat menggores halaman produk, kami mendemonstrasikan penggunaan Python dan BeautifulSoup untuk mengekstrak detail penting produk seperti judul, harga, deskripsi, dan gambar. Alternatifnya, kami mendemonstrasikan cara mengekstrak URL produk dan informasi relevan dengan menguraikan Peta Situs dengan Python dan lxml.
Meskipun scraping menimbulkan tantangan seperti perlindungan bot atau keterbatasan teknis, API web scraping dapat memberikan solusi yang lebih efisien dan andal. Anda dapat menggunakan skrip yang disediakan sebelumnya, yang tidak memerlukan melewati blok atau menyelesaikan CAPTCHA; itu hanya menggunakan API web scraping.
Singkatnya, membangun scraper WooCommerce memungkinkan bisnis memperoleh keunggulan kompetitif. Karena penyeleksinya tetap sama, penyesuaian tidak diperlukan saat menyalin situs WooCommerce lainnya. Memanfaatkan kekuatan scraping dan otomatisasi dapat membuka jalan baru menuju pertumbuhan dan kesuksesan.