
Ada beberapa opsi berbeda untuk pengumpulan data. Salah satu metode yang paling umum adalah web scraping menggunakan pemilih CSS.
Setiap situs web memiliki strukturnya sendiri yang serupa di semua halaman. Dan setiap elemen HTML di situs ini memiliki alamatnya masing-masing. Selector, pada gilirannya, memungkinkan Anda memilih aturan yang akan digunakan untuk memilih konten HTML dari sekelompok elemen.
Daftar Isi
Berbagai jenis pemilih CSS dan penggunaannya dalam web scraping
Ada beberapa jenis pemilih CSS, dibagi menjadi beberapa kelompok tergantung pada tujuannya. Daftar pilihan CSS utama berisi:
Penyeleksi universal
Mereka ditandai dengan tanda * dan berarti semua elemen HTML. Contoh pemilih CSS universal:
* {
font-family: Arial, Verdana, sans-serif;
} Pemilih tag
Mengizinkan aturan tertentu diterapkan ke semua elemen yang terletak dalam tag HTML tertentu. Contoh pemilihan tag:
p {
padding-bottom: 15px;
}Pemilih kelas
Menerapkan aturan yang ditentukan ke semua elemen dengan atribut kelas. Contoh pemilih kelas:
.center {
text-align: center;
}pemilih ID
Menerapkan aturan ke semua elemen yang memiliki atribut ID yang ditentukan oleh aturan. Misalnya:
#footer {
margin-top: 50 px;
}Pemilih atribut
Mereka digunakan untuk memilih atribut berdasarkan nama atau nilai atribut tertentu. Ada jenis penyeleksi atribut berikut:
(attr)– Memilih elemen berdasarkan nama atribut.(attr=value)– Pemilihan berdasarkan nama atribut dan nilainya.(attr^=value)– Pemilihan berdasarkan nama atribut dan nilai untuk memulai.(attr|=value)– Pemilihan berdasarkan nama atribut dan nilainya, yang ada di dalam tanda kurung.(attr$=value)– Seleksi berdasarkan nama atribut dan nilai akhir.(attr*=value)– Pemilihan berdasarkan atribut tertentu yang berisi nilai dalam tanda kurung.(attr~=value)– memilih berdasarkan atribut tertentu yang berisi nilai yang dipisahkan spasi.
Dengan bantuan pemilih CSS tersebut, Anda dapat dengan cepat menyusun daftar nama atau menemukan data untuk parameter yang ditentukan secara ketat dari semua produk. Contoh sederhana dari pemilih tersebut menggunakan atribut href:
(href*="google.com") {
background-color: green;
}Pemilih turunan atau pemilih konteks
Digunakan untuk pemilih CSS bersarang, misalnya:
.wraping p {
padding: 30px;
}Lebih jauh lagi, dalam hal ini tidak menjadi masalah apakah elemen dengan atribut p adalah elemen anak pertama di kelas tersebut .wrapping atau tidak. Dengan kata lain, itu bisa disarangkan di dalam elemen lainnya.
Pemilih anak
Perbedaan utama mereka adalah hanya keturunan tingkat pertama yang dihitung.
.wraping>p {
padding: 35px;
}Pemilih saudara atau yang berdekatan (terletak pada tingkat yang sama)
Membantu menemukan elemen pertama yang cocok pada lapisan yang sama. Mereka tidak harus mengikuti satu sama lain. Mereka yang paling dekat satu sama lain dipilih.
h2 + p {
padding-bottom: 10px;
}Penyeleksi kelas semu (pemilih negara bagian)
Tambahkan pemilih CSS yang bekerja dengan kelas semu dan jelaskan tindakan spesifik yang dilakukan pada objek (arahkan kursor, klik mouse, dll.). Misalnya:
a:hover {
text-decoration: none;
}Biasanya, Anda hanya menggunakan salah satu pemilih CSS dasar untuk mengikis situs web: #id (untuk mencari item berdasarkan ID), element (untuk mencari berdasarkan nama elemen), .class (untuk mencari elemen kelas yang berbeda), (attribute) (untuk mencari atribut) dan * (untuk memilih semua elemen).
Jadi, dengan penyeleksi Anda dapat memilih elemen dengan jenis yang sama di semua halaman situs web: tautan, gambar, harga, dll. Ini berarti Anda dapat dengan cepat mengumpulkan data yang Anda perlukan menggunakan informasi yang terdapat dalam penyeleksi CSS.
Pilih pemilih CSS yang tepat dengan Inspect
Cara paling umum untuk memilih pemilih CSS yang tepat adalah dengan memeriksa situs web menggunakan alat pengembang browser. Pertama, Anda harus membuka DevTools menggunakan tombol F12 atau klik kanan pada halaman dan pilih “Inspeksi”.
Alat Inspeksi kemudian terbuka, di mana Anda dapat melihat struktur HTML halaman. Saat Anda mengarahkan kursor ke sebaris kode, elemen terkait akan disorot.
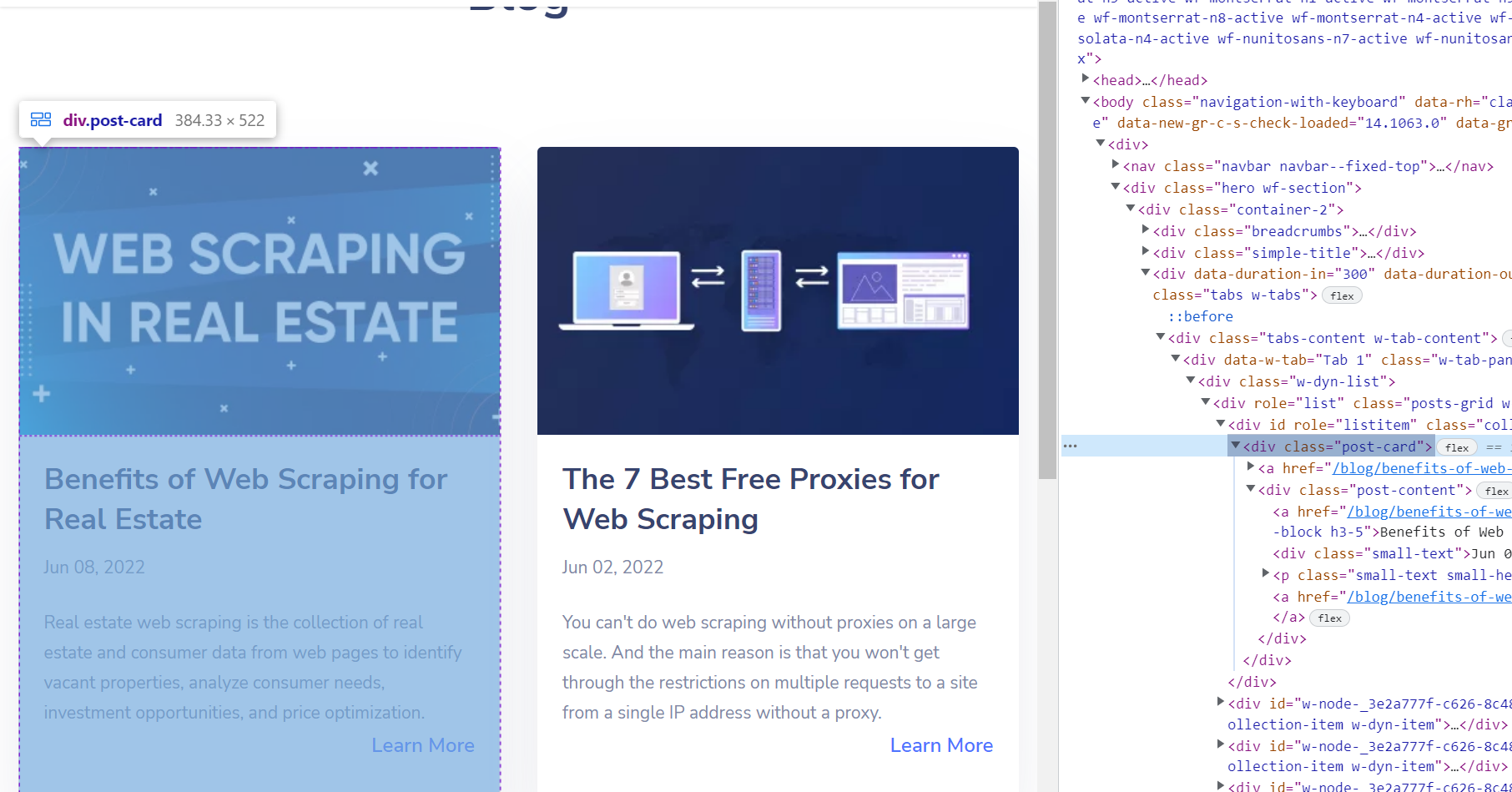
Ini juga bekerja dalam urutan terbalik. Jadi Anda dapat memilih elemen apa pun di situs web dan menampilkan kodenya menggunakan fungsi khusus atau menggunakan pintasan keyboard Ctrl+Sial+C.
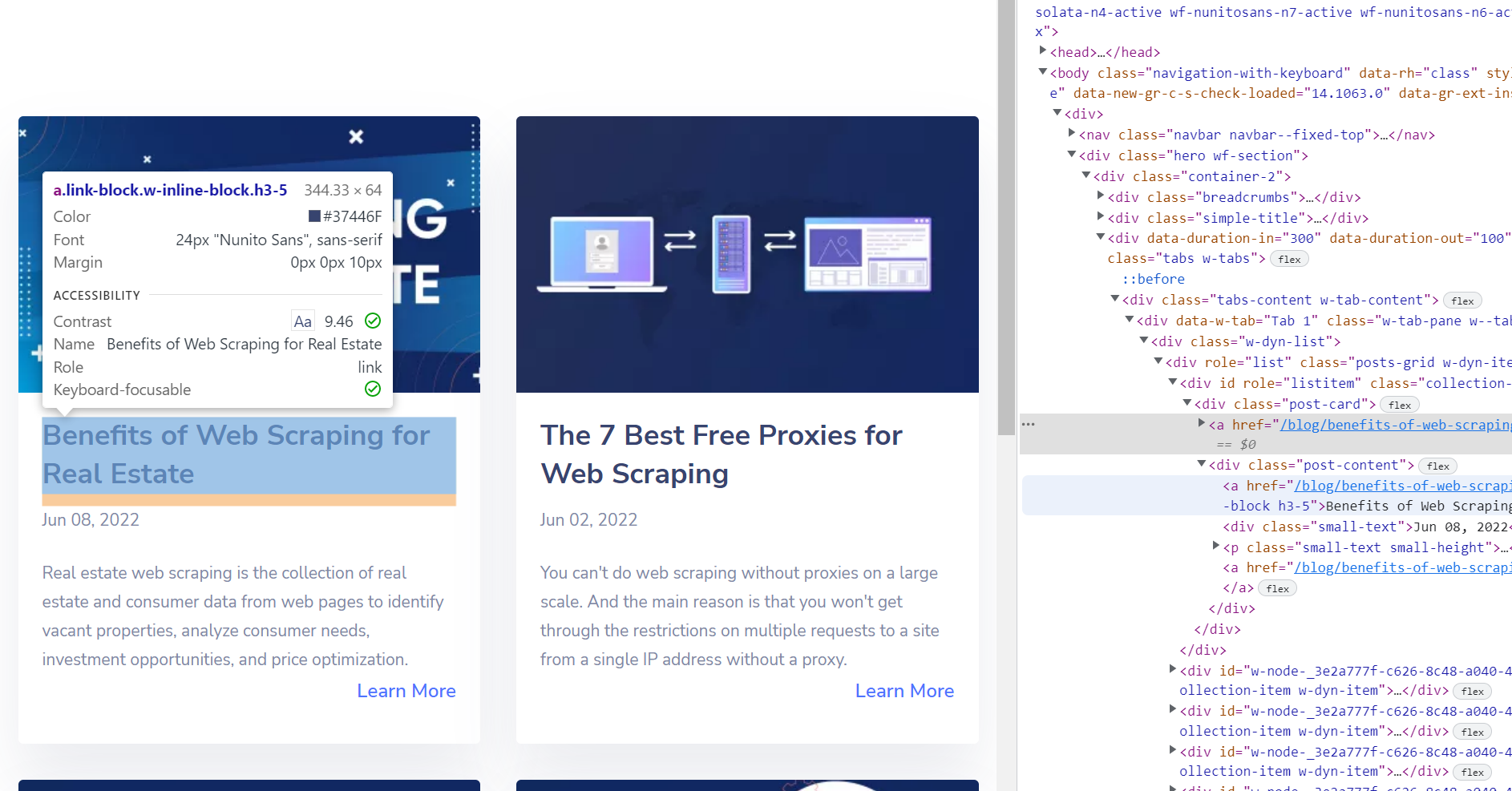
Dengan cara ini seseorang dapat menemukan kode elemen yang diperlukan dan menggunakan salah satu web scraper untuk mengumpulkan semua elemen serupa. Misalnya, Anda harus menemukan semua judul di halaman. Dengan mencari kode elemen, seseorang dapat mengetahui judulnya <a> Label.
Namun, ini bukanlah pemilih yang baik. Jika Anda akan menggunakannya <a> Menggunakan tag untuk pengikisan judul, parser HTML akan menghasilkan banyak noise. Misalnya, ada juga tombol “Pelajari lebih lanjut”. <a> Label.
Dalam hal ini merupakan ide bagus untuk menggunakan penyeleksi CSS. Anda bisa menggunakannya a.link-block.w-inline-block.h3-5 Pemilih untuk web menggores semua judul dari situs web.
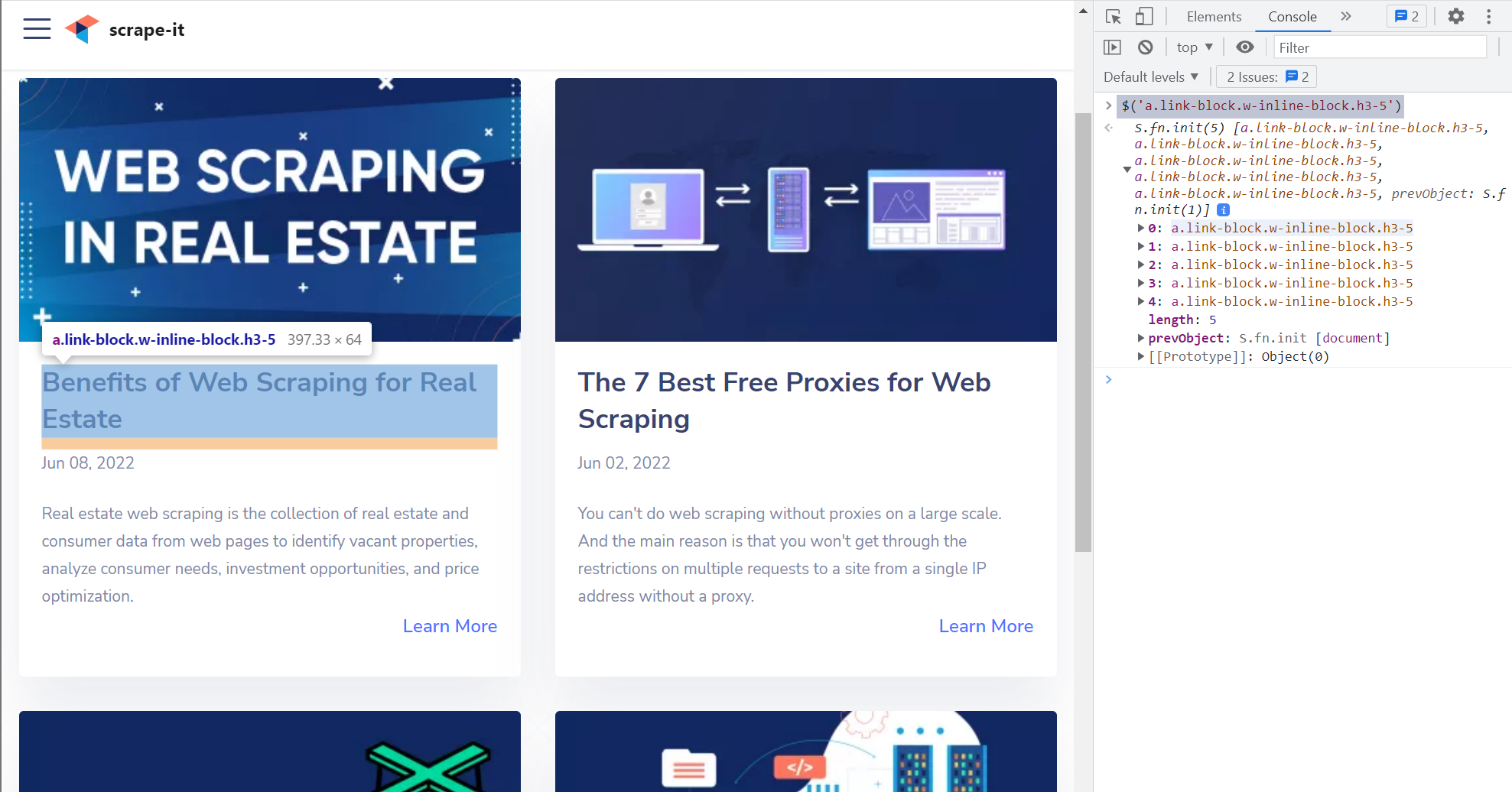
Menulis (...$('a.link-block.w-inline-block.h3-5')).map(i => i.innerText) untuk mendapatkan judul semua link postingan.
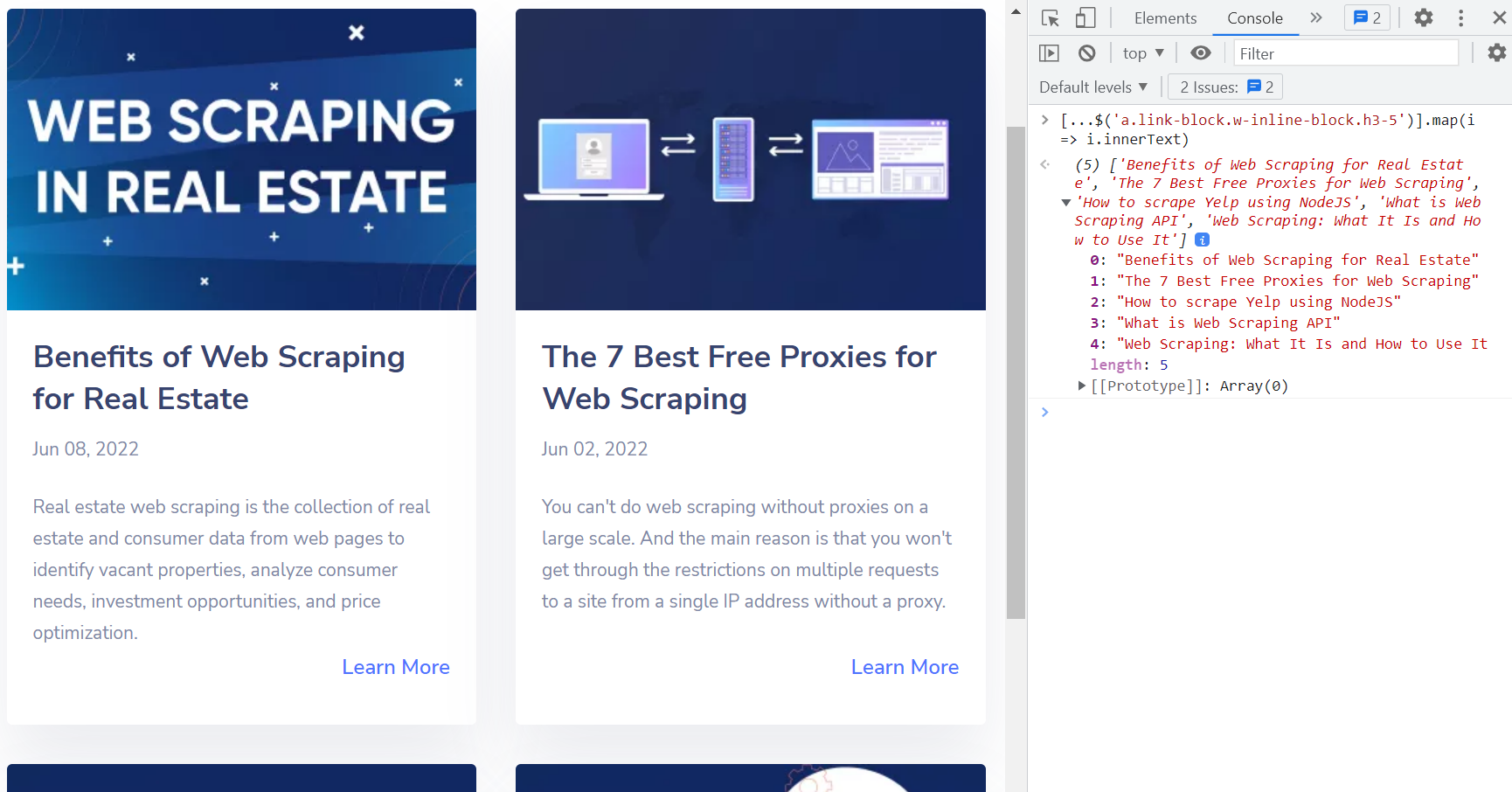
Dengan cara ini, tidak sulit membuat metode untuk mengurai dokumen HTML yang diunggah dan kemudian mengekstrak data dari elemen HTML yang diperlukan pada halaman web.
Cara menggunakan pemilih CSS untuk web scraping
Jika Anda mengetahui pemilih CSS yang berisi informasi yang diperlukan, Anda bisa dengan cepat mendapatkan data ini. Misalnya dari pemilih a.snippet-cell(href)scraper dapat mengambil referensi yang disimpan di href, yang terletak di pemilih kelas .snippet-cell dalam elemen a.
Katakanlah seseorang perlu mengambil semua nama produk di halaman menggunakan pemilih CSS. Dia tahu itu tercantum dalam nama produk <h4> hari di <title> Atribut. Sebagai tambahan <title> atribut, itu <h4> Tag juga berisi informasi lain, seperti:
<h4 href= "https://scrape-it.cloud/product/11" title="Pena">Pena</a>Nama itu disimpan di h4(title). Selain itu, Anda dapat menggunakannya untuk melihat nama semua produk di semua halaman website h4(title) pemilih.
Selector dapat dikelompokkan, ditambah, dan dijelaskan secara lebih rinci untuk menangkap hal-hal yang lebih kompleks.
Misalnya, Anda harus mencari item pertama di setiap kategori produk. Pemilihnya adalah sebagai berikut:
#set_1 > div:nth-child(1) > div > div.title > aJika jumlah elemen terus berubah, elemen tersebut tidak memiliki kelas unik dan Anda memerlukan elemen unik, Anda dapat menggunakan pemilih CSS tingkat lanjut seperti: :not, :eq(), :last.
Untuk memilih elemen yang tidak mengandung pemilih, gunakan :not (selector). Ini adalah kelas semu negatif. Katakanlah Anda perlu memilih bagian yang tidak memiliki kelas .classy:
p:not(.classy)Pemilih CSS ini memilih elemen di <p> tag, kecuali yang memiliki kelas .classy.
Untuk memilih elemen yang berada dalam urutan tertentu, dapat digunakan :eq(number). Hitung mundur dimulai dari nol. Misalnya :eq(0) memilih elemen pertama, :eq(1) memilih yang kedua, dan :eq(10) akan memilih yang kesembilan.
Jika tidak diketahui elemen mana yang OK, namun diketahui elemen terakhir, maka dapat digunakan :last. Hanya elemen terakhir yang dikembalikan, berapapun jumlah total elemennya.
Siapa pun dapat memeriksa sendiri di situs web apakah pemilih CSS mereka ditulis dengan benar. Untuk melakukan ini, buka konsol pengembang (F12) dan tulis $('selector')Misalnya, $('h4(title)') dan jika semuanya ditulis dengan benar, situs tersebut kembali <h4 title= "Pena">.
Pemilih CSS vs. XPath
Pemilih CSS memungkinkan Anda memilih elemen yang diperlukan. Sedangkan XPath adalah bahasa query khusus yang dapat digunakan untuk mengekstrak data dari tag atau atribut pada alamatnya di kode HTML sumber halaman web.
Pemilih CSS dibuat untuk kode sumber HTML, sedangkan XPath dibuat untuk mencari dokumen XML. Jadi untuk CSS, nama dan ID adalah atribut khusus yang digunakan untuk pencarian selanjutnya dalam dokumen HTML. Dari perspektif XPath, ini hanyalah “atribut saja” yang tidak berpengaruh pada pencarian. Hal ini karena pencarian tidak dilakukan melalui tabel indeks, tetapi di seluruh pohon DOM.
CSS dan XPath memiliki kelebihan dan kekurangan, beberapa di antaranya tercantum dalam tabel.
| CSS | XPath | |
|---|---|---|
| Kemampuan untuk mencari pohon DOM | – | + |
| Kemampuan untuk menggunakan subkueri | – | + |
| Kecepatan pencarian di Chrome | tinggi | rendah |
| Kecepatan pencarian di Firefox | tinggi | rendah |
| Kecepatan pencarian di Internet Explorer | rendah | tinggi |
Ejaan singkat dan sederhana tidak disertakan dalam tabel, karena berbeda untuk setiap orang. Namun, sebagai perbandingan, ada contoh sintaksis yang akan membantu semua orang menentukan metode mana yang lebih baik bagi mereka.
| Contoh | CSS | Contoh XPath |
|---|---|---|
| Semua elemen | * | //* |
| Semua -Elemen | dari a | //A |
| Semua anak-anak | sebuah>* | //A/* |
| Cari berdasarkan ID | #Footer | //*(@id='footer') |
| Cari berdasarkan kelas | . Nobel | //*(berisi(@kelas,'berkelas')) |
| Cari berdasarkan atribut | *(Judul) | //*(@Judul) |
| Anak pertama dari semuanya | a>*:anak pertama | //sebuah/*(0) |
| Semua -Elemen dengan seorang anak | -tidak dapat ditemukan- | //sebuah(p) |
| Barang berikutnya | hal + * | /p/mengikuti-saudara::*(0) |
| Barang sebelumnya | T/A | // p/saudara-sebelumnya::*(0) |
Kesimpulan dan temuan
Setiap situs memiliki strukturnya sendiri yang mengandung elemen dengan tipe yang sama. Pemilih CSS berguna untuk web scraping. Mereka digunakan untuk memilih elemen dengan tipe yang sama di seluruh halaman situs web.
Ini menghemat waktu karena semua informasi yang diperlukan dari semua situs web dapat dikumpulkan dengan cepat dan disusun untuk diproses lebih lanjut.