
Es gibt verschiedene Möglichkeiten für das Daten-Scraping. Eine der häufigsten Methoden ist Web Scraping mithilfe von CSS-Selektoren.
Jede Website hat ihre eigene Struktur, die auf allen Seiten ähnlich ist. Und jedes HTML-Element auf dieser Site hat seine eigene Adresse. Selektoren wiederum ermöglichen die Auswahl der Regeln, die zur Auswahl des HTML-Inhalts einer Gruppe von Elementen verwendet werden.
Verschiedene Arten von CSS-Selektoren und ihre Verwendung beim Web Scraping
Es gibt einige CSS-Selektortypen, die je nach Zweck in Gruppen unterteilt werden. Die Haupt-CSS-Auswahlliste enthält:
Universelle Selektoren
Sie sind mit dem *-Zeichen gekennzeichnet und bedeuten alle HTML-Elemente. Ein Beispiel für einen universellen CSS-Selektor:
* {
font-family: Arial, Verdana, sans-serif;
} Tag-Selektoren
Ermöglicht die Anwendung der angegebenen Regel auf alle Elemente, die sich innerhalb des angegebenen HTML-Tags befinden. Beispiel für eine Tag-Auswahl:
p {
padding-bottom: 15px;
}Klassenselektoren
Wendet die angegebene Regel auf alle Elemente mit Klassenattribut an. Beispiel für einen Klassenselektor:
.center {
text-align: center;
}ID-Selektoren
Wendet die Regel auf alle Elemente an, die über das von der Regel angegebene ID-Attribut verfügen. Zum Beispiel:
#footer {
margin-top: 50 px;
}Attributselektoren
Sie werden verwendet, um Attribute nach Namen oder Wert eines bestimmten Attributs auszuwählen. Es gibt folgende Arten von Attributselektoren:
(attr)– Auswahl von Elementen anhand des Attributnamens.(attr=value)– Auswahl basierend auf dem Attributnamen und seinem Wert.(attr^=value)– Auswahl basierend auf dem Attributnamen und dem Wert, mit dem begonnen werden soll.(attr|=value)– Auswahl nach Attributname und seinem Wert, der in Klammern steht.(attr$=value)– Auswahl basierend auf dem Attributnamen und dem Endwert.(attr*=value)– Auswahl basierend auf dem angegebenen Attribut, das den Wert in Klammern enthält.(attr~=value)– wählt nach dem angegebenen Attribut aus, das den durch Leerzeichen getrennten Wert enthält.
Mit Hilfe solcher CSS-Selektoren kann man schnell eine Liste mit Namen zusammenstellen oder Daten für streng definierte Parameter aller Produkte finden. Einfaches Beispiel für einen solchen Selektor, der das href-Attribut verwendet:
(href*="google.com") {
background-color: green;
}Nachkommenselektoren oder Kontextselektoren
Wird für verschachtelte CSS-Selektoren verwendet, zum Beispiel:
.wraping p {
padding: 30px;
}Darüber hinaus spielt es in diesem Fall keine Rolle, ob das Element mit dem p-Attribut das erste untergeordnete Element in der Klasse war .wrapping oder nicht. Mit anderen Worten: Es kann in jedem anderen Element verschachtelt werden.
Untergeordnete Selektoren
Ihr Hauptunterschied besteht darin, dass nur Nachkommen der ersten Ebene gezählt werden.
.wraping>p {
padding: 35px;
}Schwesterselektoren oder benachbart (auf derselben Ebene gelegen)
Hilft dabei, das erste passende Element auf derselben Ebene zu finden. Sie müssen einander nicht folgen. Es werden diejenigen ausgewählt, die einander am nächsten liegen.
h2 + p {
padding-bottom: 10px;
}Pseudoklassenselektoren (Zustandsselektoren)
Fügen Sie CSS-Selektoren hinzu, die mit Pseudoklassen arbeiten und bestimmte Aktionen beschreiben, die am Objekt ausgeführt werden (Hover, Mausklick usw.). Zum Beispiel:
a:hover {
text-decoration: none;
}In der Regel verwendet man zum Scrapen von Webseiten nur einen der grundlegenden CSS-Selektoren: #id (zum Suchen von Elementen nach ID), element (für die Suche nach Elementnamen), .class (für die Suche nach Elementen verschiedener Klassen), (attribute) (für die Suche nach Attributen) und * (zur Auswahl aller Elemente).
Mit Selektoren kann man also Elemente des gleichen Typs auf allen Seiten der Website auswählen: Links, Bilder, Preise usw. Das bedeutet, dass man mithilfe der in den CSS-Selektoren enthaltenen Informationen schnell die benötigten Daten sammeln kann.
Mit Inspect die richtigen CSS-Selektoren auswählen
Der gängigste Weg, die richtigen CSS-Selektoren auszuwählen, besteht darin, die Website mit dem Entwicklertool des Browsers zu überprüfen. Zuerst muss man entweder mit der Taste F12 zu DevTools gehen oder mit der rechten Maustaste auf die Seite klicken und „Inspizieren“ auswählen.
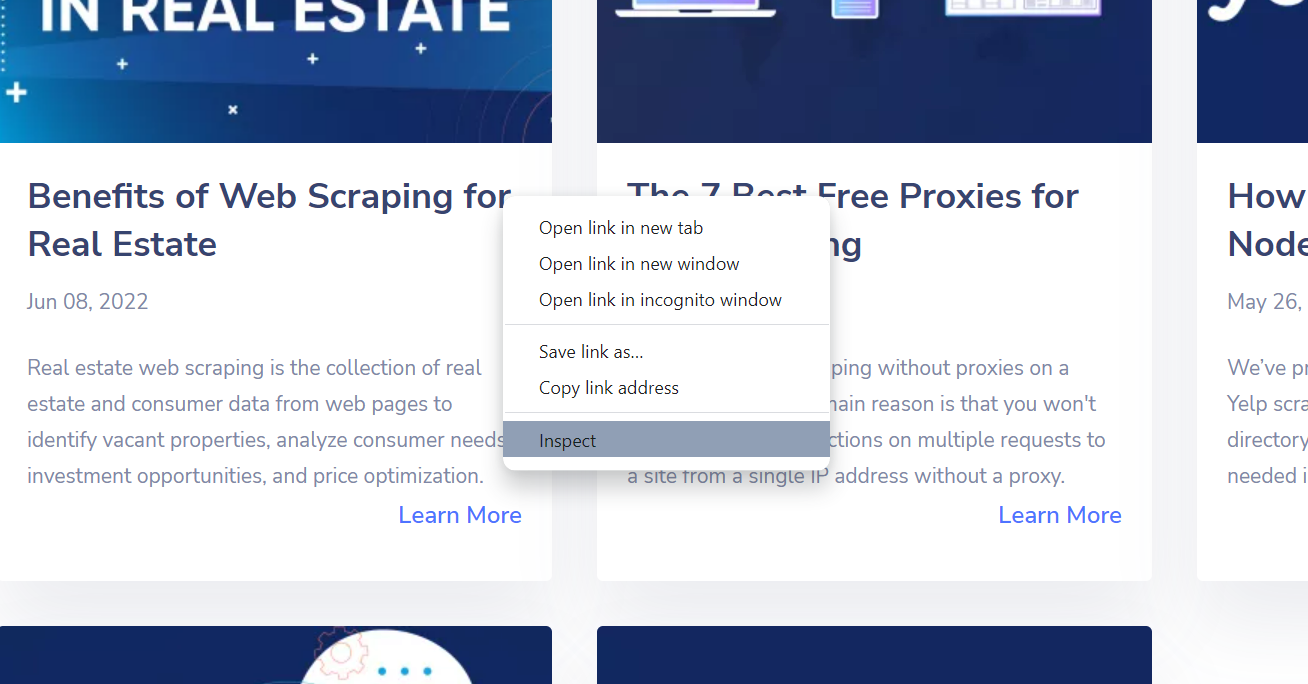
Danach öffnen sich die Inspect-Tools, in denen man die HTML-Struktur der Seite sehen kann. Wenn man mit der Maus über eine Codezeile fährt, wird das entsprechende Element hervorgehoben.
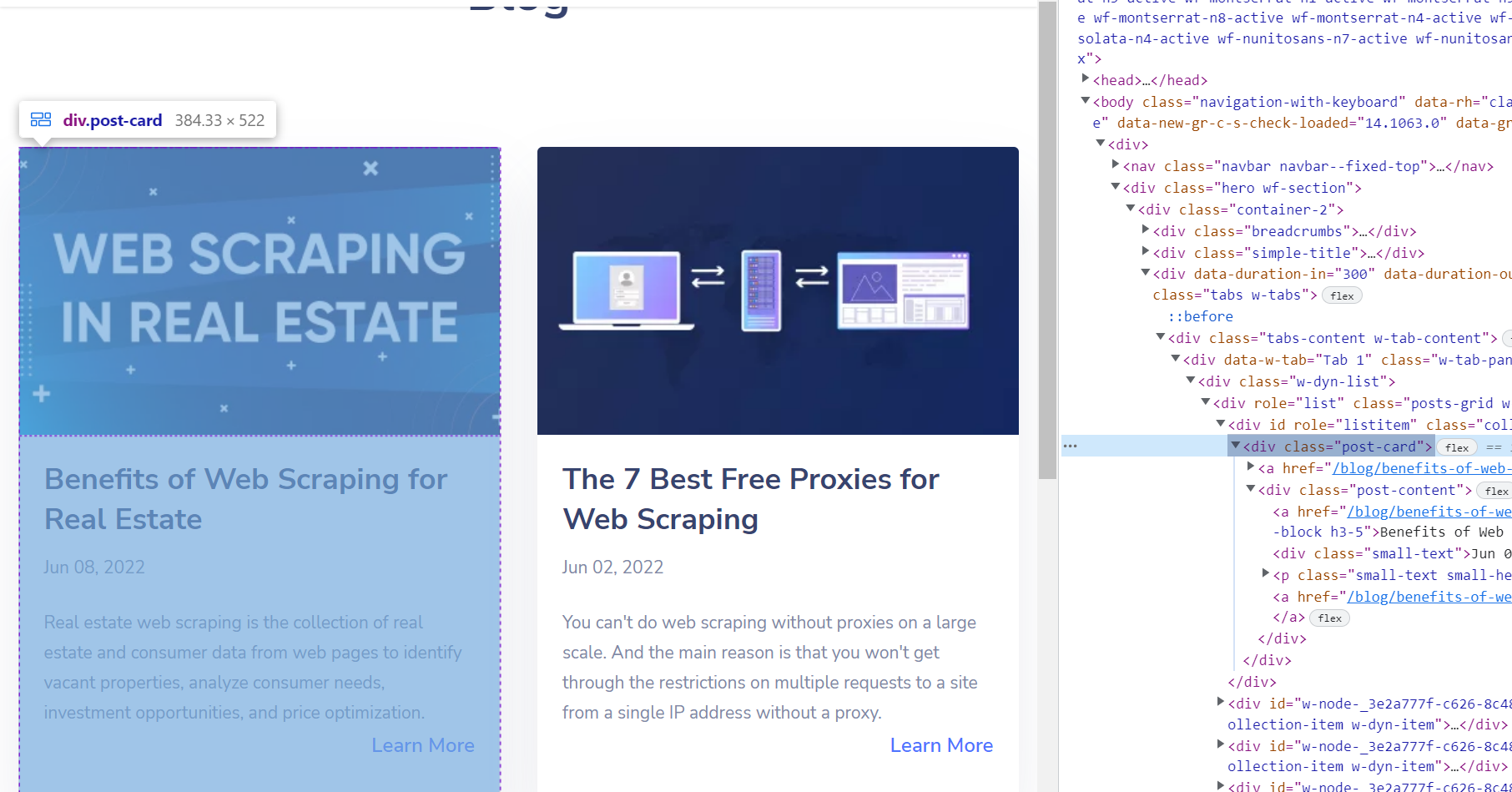
Es funktioniert auch in umgekehrter Reihenfolge. Man kann also jedes Element auf der Webseite auswählen und seinen Code mit einer speziellen Funktion oder mit den Tastenkombinationen Strg+Shit+C anzeigen.
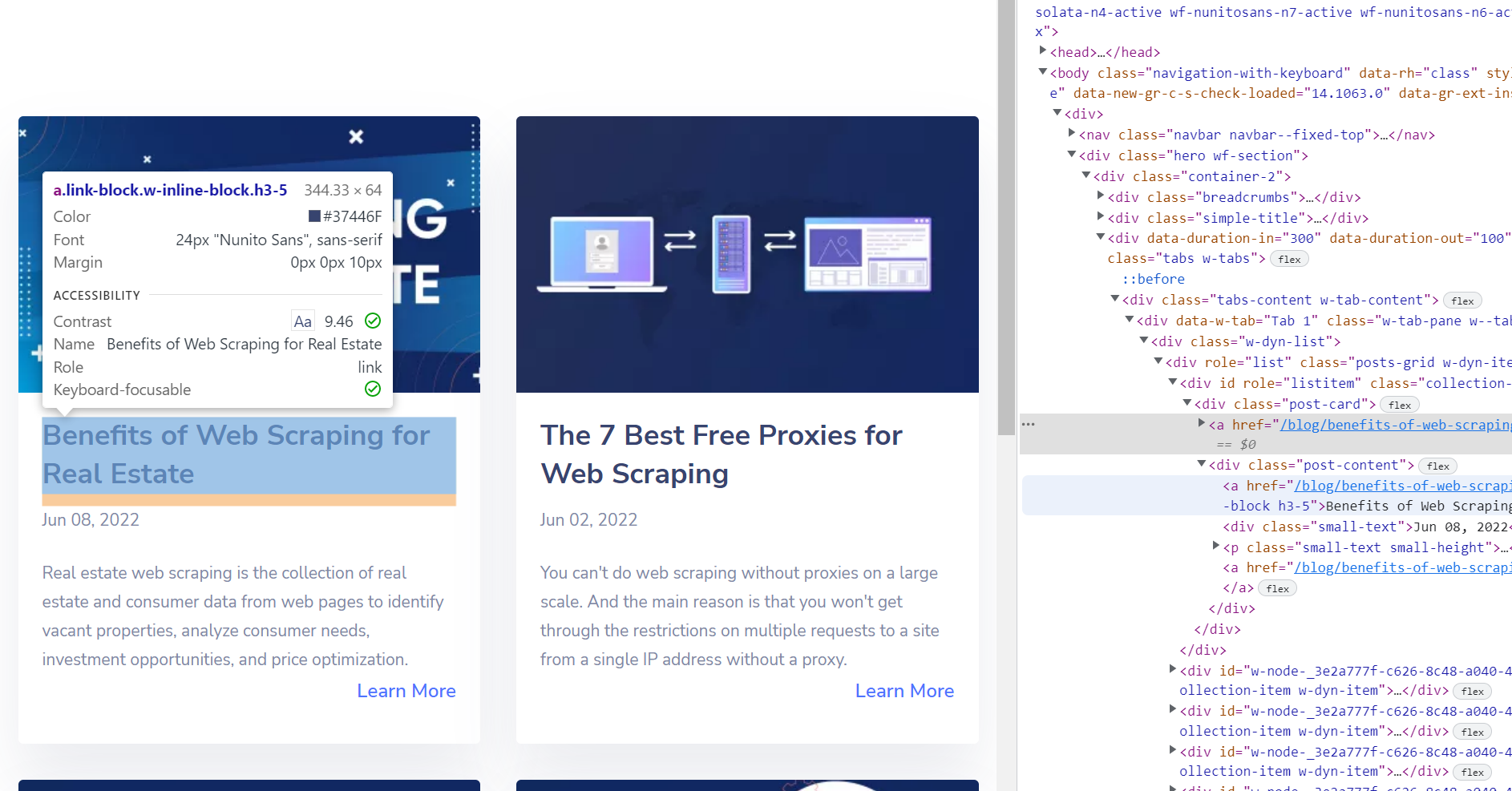
Auf diese Weise kann man den Code des erforderlichen Elements finden und einen der Web-Scraper verwenden, um alle ähnlichen Elemente zu sammeln. Beispielsweise muss man alle Titel auf der Seite finden. Indem man den Code nach Elementen durchsucht, kann man herausfinden, welchen Titel es hat <a> Etikett.
Allerdings ist es kein guter Selektor. Wenn man es benutzen wird <a> Tag für Titel-Scraping verwenden, wird der HTML-Parser viel Rauschen zurückgeben. Beispielsweise gibt es auch die Schaltfläche „Mehr erfahren“. <a> Etikett.
In diesem Fall ist es eine gute Idee, CSS-Selektoren zu verwenden. Kann man nutzen a.link-block.w-inline-block.h3-5 Selektor zum Web-Scraping aller Titel von der Webseite.
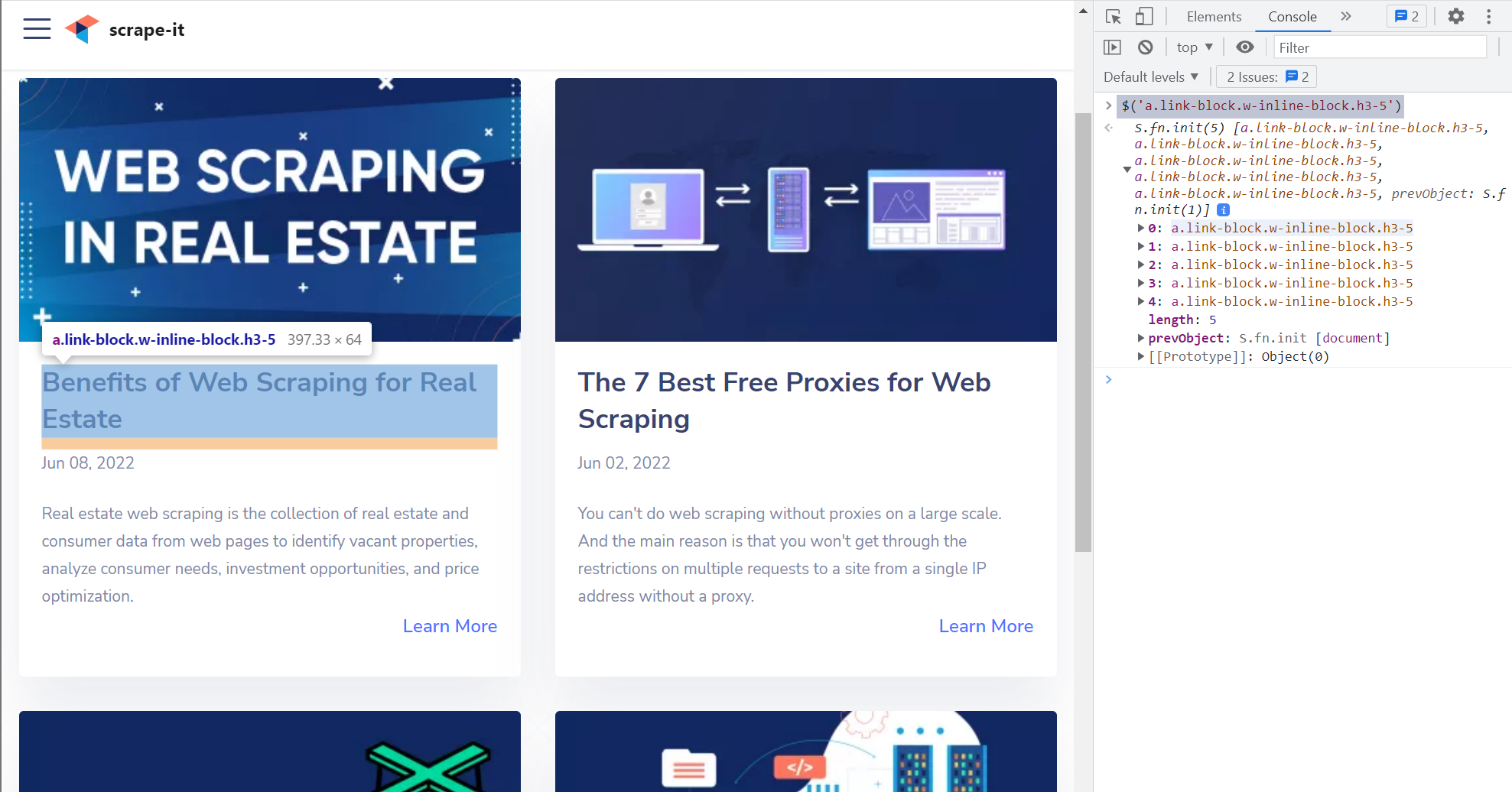
Schreiben (...$('a.link-block.w-inline-block.h3-5')).map(i => i.innerText) um die Titel aller Post-Links zu erhalten.
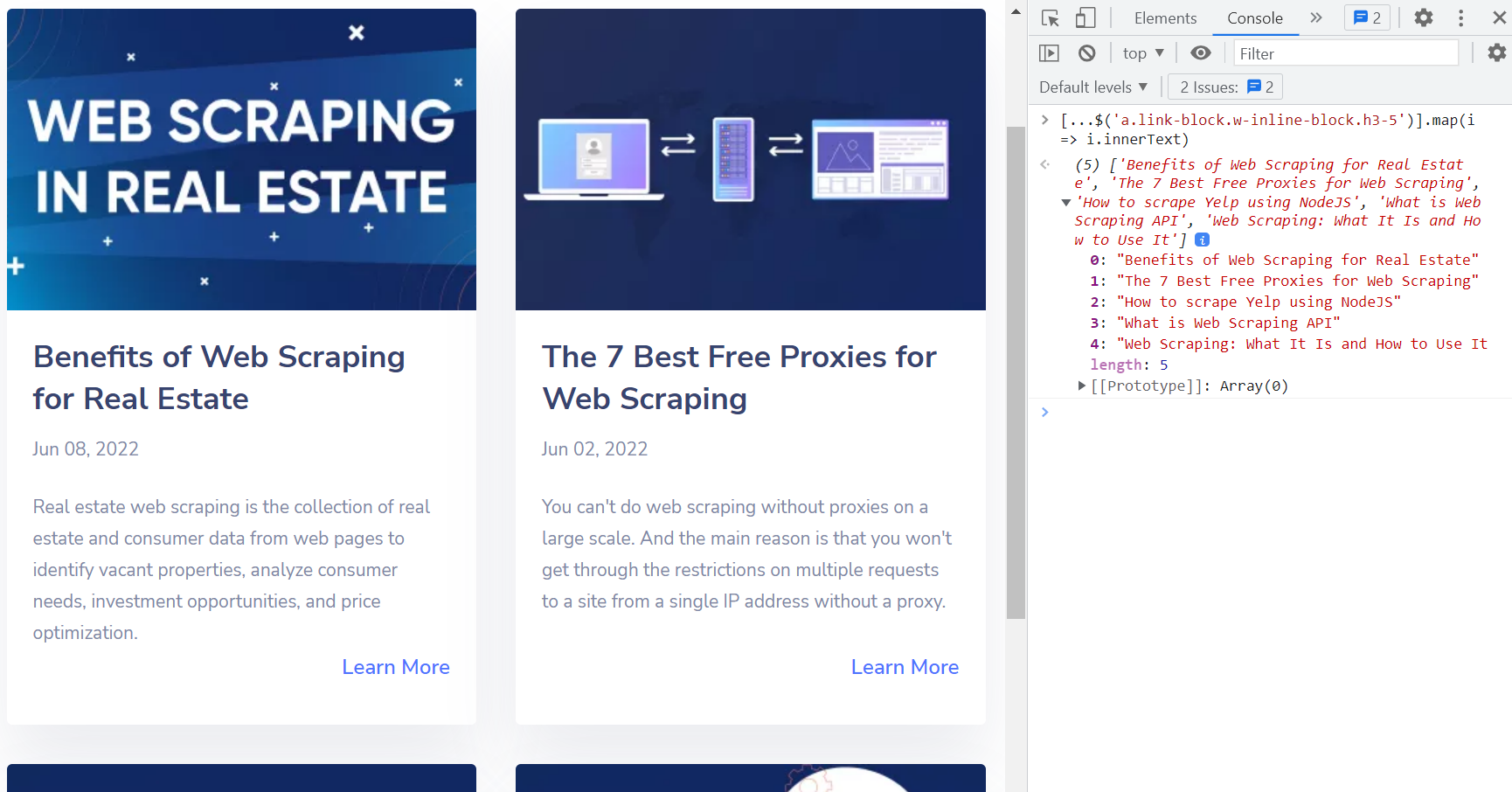
Auf diese Weise ist es nicht schwierig, eine Methode zum Parsen des hochgeladenen HTML-Dokuments zu erstellen und dann Daten aus den benötigten HTML-Elementen der Webseite zu extrahieren.
So verwenden Sie CSS-Selektoren für Web Scraping
Wenn man den CSS-Selektor kennt, der die notwendigen Informationen enthält, kann man diese Daten schnell erhalten. Zum Beispiel aus dem Selektor a.snippet-cell(href)kann der Scraper eine in href gespeicherte Referenz abrufen, die sich im Klassenselektor befindet .snippet-cell im a-Element.
Nehmen wir an, jemand muss mithilfe von CSS-Selektoren alle Produktnamen auf einer Seite abrufen. Er weiß, dass in der Produktbezeichnung angegeben ist <h4> Tag in der <title> Attribut. In Ergänzung zu <title> Attribut, das <h4> Tag enthält auch andere Informationen, wie zum Beispiel:
<h4 href= "https://scrape-it.cloud/product/11" title="Pen">Pen</a>Der Name wird in gespeichert h4(title). Darüber hinaus kann man mit dem die Namen aller Produkte auf allen Seiten der Website abrufen h4(title) Wähler.
Selektoren können gruppiert, ergänzt und detaillierter beschrieben werden, um komplexere Dinge zu erfassen.
Beispielsweise muss man in jeder Produktkategorie den ersten Artikel finden. Der Selektor wird der Folgende sein:
#set_1 > div:nth-child(1) > div > div.title > aWenn sich die Anzahl der Elemente ständig ändert, sie keine eindeutigen Klassen haben und man ein eindeutiges Element benötigt, kann man erweiterte CSS-Selektoren verwenden, z :not, :eq(), :last.
Um Elemente auszuwählen, die keinen Selektor enthalten, verwenden Sie :not (selector). Es ist eine negative Pseudoklasse. Nehmen wir an, man muss Teile auswählen, die keine Klasse haben .classy:
p:not(.classy)Dieser CSS-Selektor wählt Elemente in aus <p> Tag, außer denen, die die Klasse .classy haben.
Um ein Element auszuwählen, das in einer bestimmten Reihenfolge steht, kann man verwenden :eq(number). Der Countdown beginnt bei Null. Zum Beispiel :eq(0) wählt das erste Element aus, :eq(1) wählt die zweite aus, und :eq(10) wird den neunten auswählen.
Wenn nicht bekannt ist, welches Element in Ordnung ist, aber bekannt ist, dass es das letzte ist, kann man es verwenden :last. Es wird ausschließlich das letzte Element zurückgegeben, unabhängig von der Gesamtzahl der Elemente.
Jeder kann auf der Website selbst überprüfen, ob sein CSS-Selektor richtig geschrieben ist. Gehen Sie dazu zur Entwicklerkonsole (F12) und schreiben Sie $('selector')Zum Beispiel, $('h4(title)') und wenn alles richtig geschrieben ist, kehrt die Site zurück <h4 title= "Pen">.
CSS-Selektor vs. XPath
Der CSS-Selektor ermöglicht die Auswahl des erforderlichen Elements. Während XPath eine spezielle Abfragesprache ist, die zum Extrahieren von Daten aus Tags oder Attributen an ihrer Adresse im Quell-HTML-Code von Webseiten verwendet werden kann.
CSS-Selektoren wurden für HTML-Quellcode erstellt, während XPath für die Suche nach XML-Dokumenten erstellt wurde. Für CSS sind Name und ID also spezielle Attribute, die für zukünftige Suchen in HTML-Dokumenten verwendet werden. Aus XPath-Sicht handelt es sich hierbei um „nur Attribute“, die keinen Einfluss auf die Suche haben. Dies liegt daran, dass die Suche nicht über die Indextabelle, sondern über den gesamten DOM-Baum erfolgt.
CSS und XPath haben sowohl Vor- als auch Nachteile, von denen einige in der Tabelle aufgeführt sind.
| CSS | XPath | |
|---|---|---|
| Möglichkeit, den DOM-Baum zu durchsuchen | – | + |
| Möglichkeit zur Verwendung von Unterabfragen | – | + |
| Die Suchgeschwindigkeit in Chrome | hoch | niedrig |
| Die Suchgeschwindigkeit in Firefox | hoch | niedrig |
| Die Suchgeschwindigkeit im Internet Explorer | niedrig | hoch |
Die lakonische und einfache Schreibweise wurde nicht in die Tabelle aufgenommen, da sie für alle unterschiedlich ist. Zum Vergleich gibt es jedoch Syntaxbeispiele, anhand derer jeder feststellen kann, welche der Methoden für ihn besser ist.
| Beispiel | CSS | XPATH-Beispiel |
|---|---|---|
| Alle Elemente | * | //* |
| Alle -Elemente | von einem | //A |
| Alle untergeordneten Elemente | a>* | //A/* |
| Suche nach ID | #Fusszeile | //*(@id=’footer‘) |
| Suche nach Klasse | . nobel | //*(enthält(@class,’classy‘)) |
| Suche nach Attribut | *(Titel) | //*(@Titel) |
| Erstes Kind von allen | a>*:erstes Kind | //a/*(0) |
| Alle -Elemente mit einem untergeordneten | -kann nicht gefunden werden- | //a(p) |
| Nächstes Element | p + * | /p/following-sibling::*(0) |
| Vorheriges Element | N / A | // p/preceding-sibling::*(0) |
Fazit und Erkenntnisse
Jede Site hat ihre eigene Struktur, die Elemente des gleichen Typs enthält. Für ihr Web Scraping sind CSS-Selektoren nützlich. Sie werden zur Auswahl von Elementen desselben Typs auf allen Seiten der Website verwendet.
Auf diese Weise wird Zeit gespart, da alle erforderlichen Informationen von allen Webseiten schnell gesammelt und für die weitere Verarbeitung strukturiert werden können.
