
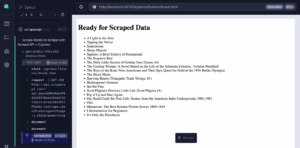
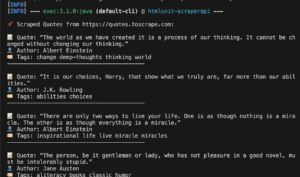
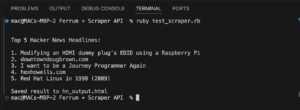

So verwenden Sie Scraperapi mit Dramatikern Erste Schritte Integrationsmethoden Best Practices Führen Sie den Code aus:
Scraperapi ist ein zuverlässiges Tool, das Proxies, Browser und Captchas während des Schabrierens von Webseiten übernimmt. Diese Anleitung zeigt, wie...

So verwenden Sie Scraperapi mit Chromedp für Web -Scraping in Go Erste Schritte: Chromedp ohne Schaber -API -Integrationsmethoden Führen Sie den Code aus
Scraperapi hilft Ihnen, Websites zu kratzen, ohne blockiert zu werden. Es kümmert sich um Proxys, Captchas und kopflose Browser, sodass...

Dramatiker gegen Puppenspieler im Jahr 2025: Welches Browser -Automatisierungswerkzeug ist für Sie geeignet?
Wenn Sie mit kopflosen Browsern arbeiten, werden Sie sich wahrscheinlich vor einer wichtigen Entscheidung stellen: Dramatiker oder Puppenspieler? Beide sind...

Erstellen Sie ein Tiktok-Brand-Influencer-Scouting-Tool mit dem Scraperapi-Langchain-Agenten, Qwen3 und Streamlit
Erstellen Sie ein benutzerdefiniertes Tiktok -Influencer -Scouting -Tool, mit dem Sie die Ersteller nach Land, Follower -Anzahl und mehr filtern,...

So kratzen Sie geo-beschränkte Daten, ohne verboten zu werden
Während das Internet oft als kostenlos und offen für alle angesehen wird, werden auf einigen Websites immer noch geografische Beschränkungen...

Langchain -Integration
Das Langchain Scraperapi-Paket ermöglicht es KI-Agenten, im Internet zu durchsuchen und auf Echtzeitinformationen zuzugreifen, ohne von Detektoren blockiert zu werden....

Beschleunigen Sie das Abkratzen von Web -Threads mit den gleichzeitigen Threads
Wenn Sie jemals einen Web -Schaber erstellt haben, kennen Sie den Schmerz. Sie bauen einen Schaber, und es funktioniert großartig...

Python Pyppeteer Scraperapi -Integration
In dieser Anleitung zeige ich Ihnen, wie Sie mit Pythons Pyppeteer -Bibliothek für Kopflosen Browser -Automatisierung problemlos Scraperapi verwenden können....

Integration von Scraperapi in Datenreinigungsleitungen
Das Sammeln von sauberen, verwendbaren Daten ist die Grundlage für ein erfolgreiches Web -Scraping -Projekt. Webdaten werden jedoch häufig mit...

Erstellen Sie ein Walmart -Bewertungs -Analyse -Tool mit Scraperapi, Vader, Gemini und Streamlit
Kundenbewertungen sind mehr als nur Feedback. Sie sind eine reiche, oft ungenutzte Quelle von Business Intelligence. Wenn Sie genau aufmerksam...

Retry-Logik & Fehlerhandling beim Scraping
Retry-Logik & Fehlerhandling beim Scraping – so geh ich damit um Ausgangspunkt Selbst bei stabilen Proxys und guten Headern...

User-Agents beim Scraping
Mobile User-Agents beim Scraping – warum sie oft besser funktionieren Ausgangspunkt Bei einigen Webseiten wurden meine Requests regelmäßig umgeleitet...

Cookies beim Scraping
Cookies beim Scraping speichern und wiederverwenden – so klappt’s Ausgangspunkt Bei manchen Webseiten reicht es nicht, nur einen guten...

User-Agent-Rotation beim Scraping
User-Agent-Rotation beim Scraping – so hab ich’s gelöst Ausgangspunkt Bei mehreren Requests auf dieselbe Domain kam es regelmäßig zu...

JSON-Daten aus XHR-Requests extrahieren
JSON-Daten aus XHR-Requests extrahieren – mein Praxisbeispiel Ausgangspunkt Ich wollte Produktdaten von einer E-Commerce-Seite extrahieren – Preis, Name,...

Cloudflare umgehen mit Puppeteer – mein Setup
Cloudflare umgehen mit Puppeteer Ausgangspunkt Ich wollte eine Seite scrapen, die von Cloudflare geschützt wird. Ohne Proxy, ohne...

Proxy-Pools: Struktur, Typen, Zugriff
Was ist ein Proxy-Pool? Ein Proxy-Pool ist die Bezeichnung für eine große Menge an IP-Adressen, die ein Proxy-Anbieter gleichzeitig zur...

Rotating Proxys einfach erklärt
Rotating Proxys einfach erklärt Was sind Rotating Proxys? Rotating Proxys – auch bekannt als rotierende oder dynamische Proxys –...

Static Proxys einfach erklärt
Static Proxys einfach erklärt Was sind statische Proxys? Statische Proxys sind Proxy-Server, bei denen die zugewiesene IP-Adresse über die...

IPv4-Proxys einfach erklärt
Was sind IPv4-Proxys? IPv4-Proxys sind Proxyserver, die IP-Adressen aus dem klassischen IPv4-Adressraum nutzen – also im bekannten Format 123.45.67.89. Sie...