
Dalam tutorial ini, Anda akan mempelajari apa itu web scraping dan bagaimana Anda dapat melakukannya menggunakan PHP. Kami mengekstrak 250 film IMDB berperingkat teratas menggunakan PHP. Di akhir artikel ini, Anda akan memiliki pengetahuan tentang cara melakukan web scraping dengan PHP dan memahami keterbatasan pengumpulan data skala besar dan apa pilihan Anda jika Anda memiliki kebutuhan tersebut.
Daftar Isi
Apa itu pengikisan web?
Kami menjelajahi Internet setiap hari untuk mencari informasi yang kami perlukan untuk menyelesaikan suatu pekerjaan atau sekadar untuk mengkonfirmasi asumsi tertentu. Terkadang Anda mungkin perlu menyalin beberapa data atau konten ini dari situs web dan menyimpannya ke folder untuk digunakan nanti. Jika Anda sudah melakukannya, selamat, Anda pada dasarnya telah melakukan web scraping. Selamat bergabung!
Namun, ketika Anda membutuhkan data dalam jumlah besar, metode salin dan tempel yang umum terbukti membosankan. Data sebagai komoditas hanya masuk akal jika Anda mengekstraknya dalam konteks berskala besar.
Pengikisan web atau ekstraksi data adalah proses pengumpulan data dari berbagai sumber di web dan menyimpannya dalam format yang dapat dibaca.
Data sudah menjadi sebuah mata uang saat ini, dan perusahaan semakin berupaya untuk menjadi berbasis data.
Namun tanpa kerangka kerja yang tepat dan protokol pengelolaan data yang mencakup seluruh siklus hidup data, mata uang abad ke-21 ini akan menjadi seperti kupon yang sudah kadaluarsa. Kami selalu menegaskan bahwa data yang buruk tidak lebih baik daripada tidak ada data. Baca selengkapnya tentang lima karakteristik utama data berkualitas tinggi di sini:
Tujuan utama artikel ini adalah untuk memperkenalkan Anda pada dunia ekstraksi data menggunakan PHP, salah satu bahasa skrip sisi server paling populer untuk situs web.
Kami akan menggunakan skrip PHP sederhana untuk mengekstrak 250 film teratas dari IMDB dan menyajikannya dalam file CSV yang dapat dibaca. Karena PHP adalah salah satu bahasa pemrograman yang paling ditakuti, Anda harus melihatnya lebih dekat. Tingkat kesulitan web scraping dengan PHP hanya bergantung pada perspektif.
Dasar-dasar PHP untuk web scraping
Teknologi yang menciptakan koneksi antara browser web Anda dan banyak situs web di Internet sangatlah rumit dan rumit.
Sekitar 40 % web didasarkan pada PHP, yang selalu dianggap berantakan karena alasan logis dan sintaksis.
PHP adalah bahasa pemrograman berorientasi objek. Ini mendukung semua fitur penting dari pemrograman berorientasi objek seperti abstraksi dan pewarisan, yang paling cocok untuk tujuan scraping jangka panjang.
Meskipun ekstraksi data relatif lebih mudah dengan bahasa pemrograman lain, sebagian besar situs web saat ini memiliki lebih dari sekadar petunjuk tentang PHP, sehingga memudahkan untuk menulis crawler dan mengintegrasikannya ke dalam situs web dengan lebih cepat.
Sebelum melanjutkan, mari kita uraikan secara singkat isi artikel ini:
- persyaratan
- Definisi
- Mempersiapkan
- Membuat pengikis
- Membuat CSV
- kata-kata terakhir
Pertama kita perlu mendefinisikan apa yang kita lakukan dan apa yang akan kita gunakan untuk tutorial scraping ini. Alur kerja umum kami terdiri dari menyiapkan direktori proyek dan menginstal alat yang diperlukan untuk ekstraksi data.
Kebanyakan dari mereka tidak bergantung pada platform dan dapat berjalan di sistem operasi apa pun pilihan Anda.
Kami kemudian akan membahas setiap langkah penulisan scraper di PHP menggunakan perpustakaan yang disebutkan dan menjelaskan fungsi setiap baris.
Terakhir, kita akan membahas batasan crawling dan apa yang harus dilakukan saat melakukan crawling dalam skala besar.
Artikel tersebut membahas kesalahan yang mungkin Anda lakukan tanpa disadari. Kami juga akan menyarankan Anda solusi yang lebih sesuai.
Definisi untuk membantu Anda memulai web scraping PHP
Sebelum kita membahas lebih dalam, mari kita bahas beberapa istilah dasar yang akan Anda temui saat membaca artikel ini. Untuk menyederhanakan demonstrasi, semua istilah teknis didefinisikan di sini.
1. Manajer paket
Manajer paket membantu Anda menginstal paket penting dari toko distribusi pusat. Ini pada dasarnya adalah repositori perangkat lunak yang menyediakan format standar untuk mengelola dependensi perangkat lunak dan perpustakaan PHP.
Meskipun tidak terbatas pada mengelola pustaka PHP, pengelola paket juga dapat mengelola semua perangkat lunak yang diinstal di komputer kita seperti toko aplikasi, tetapi lebih khusus lagi pada kodenya.
Beberapa contoh pengelola paket adalah: Composer (untuk PHP), npm (untuk JavaScript), apt (untuk turunan Ubuntu Linux), Brew (untuk MacOS), Winget (untuk Windows), dll.
2. Konsol Pengembang
Ini adalah bagian dari browser web yang berisi berbagai alat untuk pengembang web. Ini juga merupakan salah satu area browser yang paling sering digunakan ketika kita ingin mulai mengambil data dari situs web.
Konsol ini memungkinkan Anda menentukan tugas apa yang dilakukan browser web saat berinteraksi dengan situs web yang diamatinya. Meskipun ada banyak bagian yang bisa dipilih, pada artikel ini kita hanya akan menggunakan bagian Item, Jaringan, dan Aplikasi.
3. tag HTML
Tag adalah instruksi khusus dalam teks biasa yang diapit tanda kurung segitiga (lebih besar dari/kurang dari karakter).
Contoh:
<html> … </html>
Mereka digunakan untuk memberikan instruksi kepada browser web tentang cara menampilkan halaman web dengan cara yang ramah pengguna.
4. Model Objek Dokumen (DOM)
DOM terdiri dari struktur logis dokumen dan cara mereka diakses dan dimanipulasi.
Sederhananya, DOM adalah model yang dihasilkan dari respon HTML dan dapat direferensikan dengan query sederhana tanpa memerlukan pemrosesan yang rumit.
Contoh yang bagus adalah buku interaktif di mana setiap kata kompleks dihubungkan dengan maknanya saat Anda mengklik kata tersebut.
5. membuang waktu/membuang waktuhttp
Ini adalah paket eksternal yang digunakan oleh scraper kami untuk mengirim permintaan ke dan dari server web, mirip dengan browser web. Mekanisme ini sering disebut jabat tangan HTTP, di mana kode kita mengirimkan permintaan (disebut permintaan GET) ke server IMDB.
Sebagai respons, server mengirimkan kepada kami isi respons, yang terdiri dari serangkaian instruksi dengan isi respons yang benar, cookie (terkadang) dan perintah lain yang dijalankan di browser web.
Karena kode kami berjalan dalam bentuk berurutan (proses demi proses), kami tidak memproses instruksi lain yang disediakan oleh server IMDB. Kita hanya fokus pada teks jawaban. Dokumentasi untuk paket ini dapat ditemukan di sini.
6. Paket/php-html-parser
Seperti guzzle, ini juga merupakan paket eksternal yang digunakan untuk mengubah respons mentah halaman web yang diterima dari klien guzzle menjadi DOM yang tepat.
Dengan mengonversi ke DOM, kita dapat dengan mudah mereferensikan bagian dokumen yang diterima dan mengakses setiap bagian dokumen yang ingin kita cari. Kode sumber dan dokumentasi untuk paket ini dapat ditemukan di sini.
7. URL Dasar
URL Dasar adalah URL situs web yang mengarah ke direktori root server web.
Anda dapat lebih memahami URL dasar dengan melihat cara kerja struktur folder di sistem komputer.
Ambil folder bernama "Dokumen" di komputer. Inilah yang dipaparkan server web ke Internet. Itu dapat diakses oleh setiap pengguna yang meminta tanggapan dari situs web.
Kita dapat membuka folder baru apa pun di folder Dokumen. Menavigasi ke folder baru hanyalah masalah menelusurinya Documents/newfolder/path.
Mirip dengan bagaimana halaman web dikelola berdasarkan hierarki, URL dasar adalah akar dari seluruh dokumen web halaman web, dan semua halaman baru hanyalah "folder" di dalam folder URL dasar tersebut.
Header adalah instruksi untuk server web dan bukan untuk sistem klien kami. Mereka menyediakan kumpulan sederhana definisi yang telah ditentukan sebelumnya yang memungkinkan server web memecahkan kode tanggapan klien secara akurat.
Contoh sederhananya adalah halaman download Windows, misalnya di Microsoft.com.
Berdasarkan header Agen Pengguna, server web dapat dengan mudah menyimpulkan bahwa permintaan yang dikirim ke servernya berasal dari PC Windows. Oleh karena itu, perlu mengirimkan informasi yang relevan dengan platform. Logika yang sama berlaku untuk perbedaan bahasa antar situs web.
9. Pemilih CSS
Pemilih CSS hanyalah kumpulan sintaksis teks yang dapat menemukan lokasi dokumen di DOM tanpa menghabiskan sumber daya pemrosesan yang besar.
Mirip dengan bagian daftar isi pada buku fisik. Dengan melihat daftar isi, pembaca bisa sampai ke bagian yang mereka minati.
Namun tidak seperti TOC, pemilih CSS dapat menerima lebih banyak filter dan menggunakannya untuk mengurangi noise (data tidak penting) dari data aktual yang perlu kita cari di DOM.
Mereka sebagian besar digunakan dalam desain web tetapi sangat membantu dalam web scraping.
Mulai saat ini, artikel ini mengasumsikan bahwa Anda memiliki pengetahuan dasar tentang pemrograman berorientasi objek dan PHP. Anda seharusnya membaca sekilas definisi yang disajikan pada bagian di atas.
Ini akan memberi Anda pengetahuan dasar yang Anda perlukan untuk melanjutkan tutorial di bagian berikut. Sekarang kita akan melihat cara membuat crawler.
komposer
Pertama kita menginstal manajer paket (1) disebut Komposer melalui manajer paket untuk sistem Anda. Untuk varian Linux caranya mudah Sudo apt Instal Komposer (Ubuntu) atau dengan manajer paket apa pun di komputer kita. Informasi lebih lanjut tentang langkah-langkah menginstal Composer dapat ditemukan di sini.
Visual Studio Code (atau editor teks apa pun; bahkan Notepad pun bisa)
Ini untuk menulis scraper yang sebenarnya. Visual Studio Code memiliki beberapa ekstensi untuk membantu Anda mengembangkan program dalam berbagai bahasa pemrograman.
Namun, ini bukan satu-satunya cara untuk mengikuti tutorial ini. Editor teks apa pun, bahkan yang sederhana sekalipun, dapat digunakan untuk menulis scraper.
Kami sangat merekomendasikan IDE karena penyorotan sintaksis otomatis dan fitur dasar lainnya. Itu dapat diinstal melalui toko platform individual.
Di Linux, instalasi melalui manajer paket atau Snap atau Flatpaks jauh lebih mudah. Informasi tentang instalasi Windows dan MacOS dapat ditemukan di sini.
Sekarang kita memiliki semua yang kita perlukan untuk menulis scraper untuk mengekstrak rincian dari 250 film berperingkat teratas di IMDB, kita dapat melanjutkan ke penulisan skrip sebenarnya.
Membuat pengikis web
Dengan menggunakan tautan ini, kami ingin menelusuri 250 film berperingkat teratas di IMDB sejauh ini untuk rincian berikut:
- pangkat
- judul
- Direktur
- Memimpin
- URL
- URL gambar
- Evaluasi
- Jumlah Ulasan
- Tahun penerbitan
Tapi ada sedikit kendala. Situs web tidak menampilkan semua informasi yang kami perlukan.
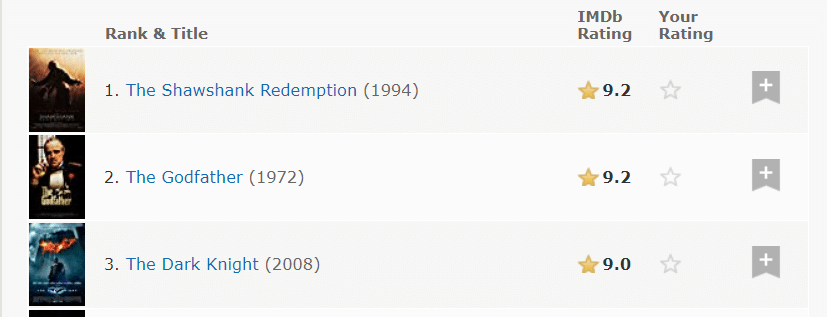
Hanya pangkat, gelar, tahun, rating dan gambar yang terlihat langsung.
Langkah pertama dalam web scraping adalah mencari tahu apa yang disembunyikan situs web tersebut dari kita.
Anda dapat menganggap situs web sebagai dinding teks yang dikirim dari server web. Saat dibaca oleh web browser, website mungkin menampilkan struktur yang berbeda-beda tergantung instruksi pada dinding teks yang dikirimkan oleh web server.
Setiap hover pada setiap elemen situs web hanyalah sebuah instruksi kepada browser web untuk mengikuti dan bertindak berdasarkan respons teks yang diterima dari server.
Sebagai pengikis, tugas kita adalah memanipulasi teks yang diterima ini dan mengekstrak semua informasi yang ingin disembunyikan situs web dari kita kecuali kita mengeklik opsi yang diinginkan.
Langkah 1:
Buka alat pengembang (2) di browser untuk memeriksa apa yang disembunyikan situs web dari kami. Untuk membuka konsol pengembang, tekan F12 pada keyboard atau Ctrl+Shift+I (Command+Shift+I for Mac). Setelah Anda membuka konsol pengembang, Anda akan disambut dengan layar berikut.
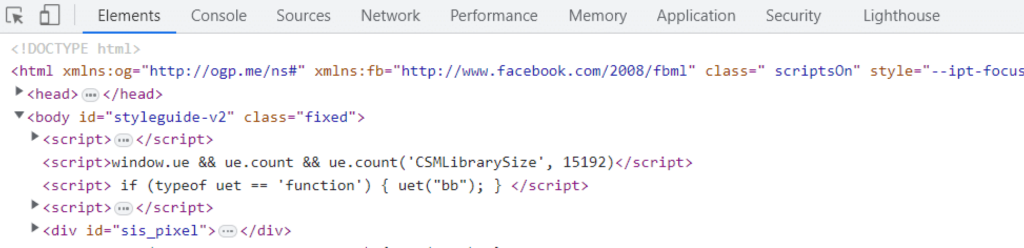
Ini pada dasarnya adalah apa yang dikirimkan situs web saat ini ke sistem kami untuk menampilkan situs web di kanvas browser web.
Langkah 2:
Sekarang klik tombol “Periksa” (tombol panah kiri atas) untuk memulai mode pemeriksaan situs web.
Mode ini adalah mode pengembang yang digunakan untuk berinteraksi dengan halaman web seolah-olah kita mencoba menelusuri elemen interaktif di situs web ke sumber instruksi sebenarnya di dinding teks (disebut respons) yang dikirim oleh server web IMDB menjadi .
Sekarang kita cukup mengklik salah satu nama film dan di konsol kita dapat melihat respon teks sebenarnya.
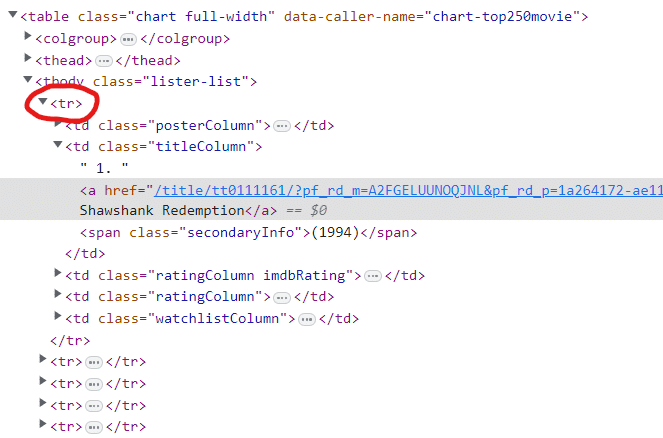
Pada gambar di atas kita melihat ada 250 tr Kata kunci (3). Tag dalam HTML hanyalah instruksi agar halaman web menampilkan informasi dalam format yang lebih menarik.
Informasi ini akan berguna nantinya.
Mari kita fokus pada yang pertama dulu tr Anggota sebagai balasan. Maksimalkan semuanya td elemen kita dapat melihat lebih banyak informasi tentang setiap entri film daripada yang terlihat sebelumnya di situs web.
Dengan informasi ini saja, kita sekarang dapat menggunakan respon halaman dalam kode PHP kita untuk mentransfer semua informasi acak pada halaman ini ke dalam format tabel yang sesuai sehingga kita dapat menghasilkan data yang dapat ditindaklanjuti darinya.
Dengan pengetahuan ini, sekarang kita dapat beralih ke pemrograman sebenarnya.
Langkah 3:
Buat direktori proyek.
Beri nama foldernya 'imdb_com' untuk lebih mudah digunakan dan referensi. Buka folder menggunakan editor teks dan jalankan terminal (command prompt) di dalamnya.
Setelah jendela terminal terbuka, ketik:
composer init
Perintah ini memanggil Komposer untuk memulai proyek di folder yang sedang aktif.
Dalam kasus kami ini adalah folder yang baru saja kami buat yaitu imdb_com. Komposer akan menanyakan informasi lebih lanjut kepada kami. Cukup telusuri prosesnya dan tambahkan paket berikut ketika diminta oleh prompt Composer selama pengaturan awal.

Langkah 4:
Pada layar yang ditunjukkan di atas, masukkan yang berikut ini:
guzzlehttp/guzzle
Tekan Enter lalu tempel paket terakhir yang kita perlukan:
paquettg/php-html-parser
Setelah pengunduhan paket selesai, kita akan memiliki direktori untuk proyek tersebut seperti yang ditunjukkan di bawah ini:
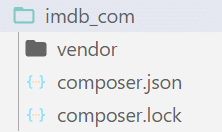
Langkah 5:
Sekarang buat file baru dan beri nama “imdb.php' di direktori root yang sama dengan Komposer.json Mengajukan. Kami akan mengerjakan file ini selama sisa tutorial.
Untuk memulai scraper kita perlu mendefinisikan apa itu file PHP. Dimulai dari <?php di baris pertama adalah awal yang baik.
Impor fungsi autoload dengan kata kunci ini:
require_once "vendor/autoload.php";
Baris ini memuat file ke folder vendor di direktori root. Ini memuat semua file yang baru saja kita instal menggunakan Komposer pada tahap awal scraper kita.
use GuzzleHttpClient;
use PHPHtmlParserDom;
Crawler sekarang dapat mulai menggunakan paket yang kita unduh. Pertanyaannya sekarang adalah: mengapa menggunakan keduanya? require_once dan skrip di atas secara bersamaan?
Jawabannya: Require_once menyediakan direktori yang berisi file-file yang diperlukan untuk menggunakan paket-paket yang kita download menggunakan Composer. Kata kunci “use” meminta program untuk memuat klien dan anggota dom dari masing-masing kelas sehingga kita dapat menggunakan fungsi ini di crawler kita.
Langkah 6:
Tentukan objek untuk GuzzleHttpClient and PHPHtmlParserDom.
$client = new Client((
'base_uri' => 'https://www.imdb.com',
'headers' => (
'user-agent' => 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36',
'accept' => 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8',
'accept-language' => 'en-US,en;q=0.8'
),
));Kode ini mendefinisikan URL dasar (7) dan header (8) untuk situs web yang kami jelajahi.
$dom = new Dom();
Hal yang sama berlaku untuk perpustakaan lain yang baru saja kita definisikan pada tahap awal crawler.
Langkah 7:
Sekarang semua alat kita dimuat ke dalam crawler, kita bisa masuk ke inti program.
Kirim permintaan “GET” ke situs web ini.
Perhatikan bahwa kami telah menetapkan https://www.imdb.com sebagai URL dasar untuk perayap kami. Jadi jalur dokumen kita yang sebenarnya adalah chart/top/?ref_=nv_mp_mv250dan untuk mengirim permintaan kita harus menulis:
$response = $client->request('GET', '/chart/top/?ref_=nv_mp_mv250');
Karena kami sudah mendapatkan respons yang dikirim oleh server web, kami memuat respons ini ke dalam variabel teks dan mengirimkannya ke parser DOM kami untuk menghasilkan DOM, sehingga mereferensikan bagian dokumen menjadi lebih cepat dan mudah.
$dom->loadStr($response->getBody());
Langkah 8:
Kami mengunjungi kembali konsol pengembang browser web dengan informasi yang kami kumpulkan sebelumnya, yaitu tag 250 tr yang berisi semua data yang kami butuhkan tentang film tersebut.
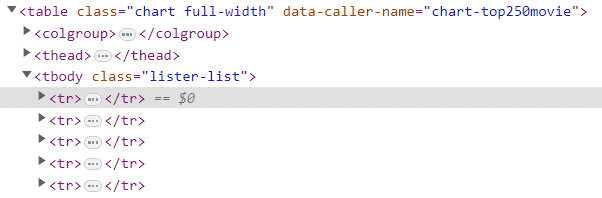
tbody Label. Kami melihat bahwa semua data film yang kami perlukan disertakan tbody Label. Itu tbody Tag tersebut pada gilirannya berada dalam cakupan tag tabel.
Daripada memproses seluruh dokumen karena kita telah membuat elemen DOM menggunakan perpustakaan eksternal, kita cukup mereferensikan bagian tabel dokumen menggunakan pemilih CSS (9).
$movies = $dom->find('table(data-caller-name="chart-top250movie") > tbody > tr');
Sekarang kita mencari seluruh DOM untuk tabel yang atributnya adalah nama-pemanggil data chart-top250movie. Setelah hal itu ditemukan, kita melangkah lebih dalam dan menemukan segalanya tbody Kata kunci.
Kemudian kita menemukan semua tag tr dengan menyelami level lebih dalam lagi tbody tag dan terakhir kembalikan semua tag ini dan anggotanya (data) dan simpan dalam variabel film.
Untuk informasi lebih lanjut tentang berbagai sintaks penyeleksi CSS, lihat tautan ini.
Setelah ini selesai, semua informasi film kita akan disimpan dalam variabel film. Menelusuri setiap film kini menghasilkan data kami dengan 250 informasi film yang disusun dalam format yang lebih sesuai.
Anda dapat menelusuri film menggunakan:
foreach ($movies as $mId => $movie) {
}Langkah 9:
Sebelum kita mengerjakan masing-masing bidang, kita dapat memperkenalkan konsep baru untuk mengesampingkan elemen DOM.
Karena variabel Movies sudah berisi semua informasi tentang semua film yang diperlukan, penggunaan kembali objek DOM yang memuat seluruh respons dari server web lebih merupakan teknik pengoptimalan yang digunakan untuk mengurangi jejak memori crawler.
Oleh karena itu, untuk menggunakannya kembali, kami mengganti seluruh dokumen dengan sebagian kecil saja dari dokumen tersebut.
Kami akan membahas konsep lain secara lebih rinci setelah perjalanan singkat Segway. Kita tahu bahwa tr Tag berisi semua informasi tentang film.
Salin satu tr Jika kami menyorot semua anggota dan memperluasnya, kami mendapatkan informasi berikut tentang setiap film (dalam hal ini, hanya film pertama).
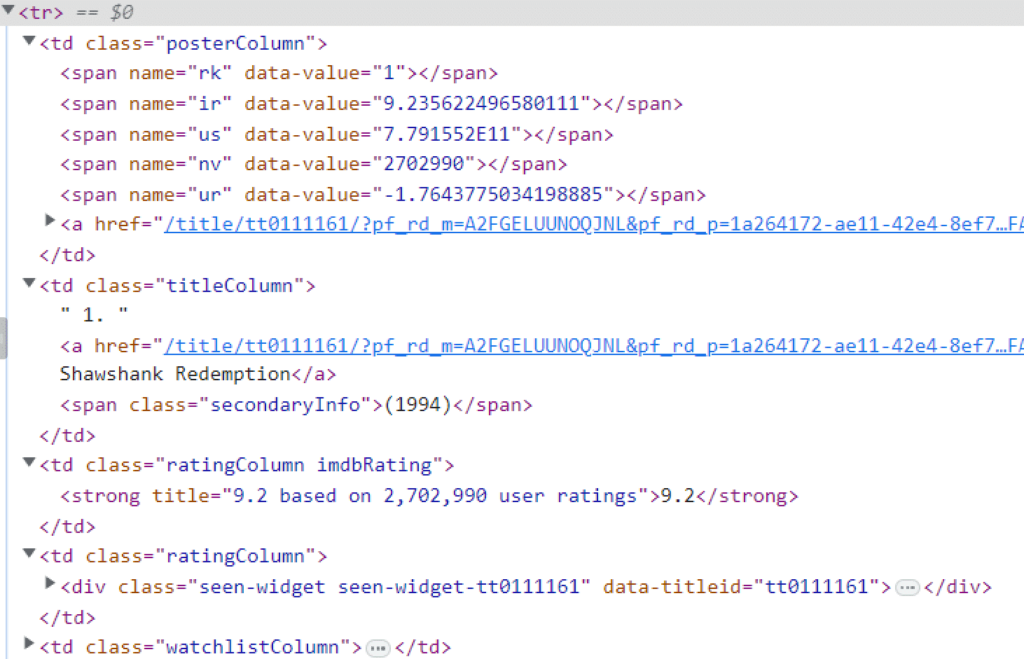
td Elemen. Semua informasi yang kita butuhkan ada di elemen td yang disarangkan. Sekarang kita bisa menerapkan konsep penggunaan kembali. Karena kita tidak lagi memerlukan seluruh dokumen, kita cukup mengganti informasi tentang film yang terdapat dalam tag tr di objek DOM sehingga kita dapat menggunakan metode find() yang sama untuk mengekstrak informasi benar yang kita perlukan. Kita dapat melakukannya dengan menggunakan:
$dom->loadStr($movie);
Langkah 10:
Mulailah mengisi array dengan indeks kunci dan nilai yang benar.
Karena kita mengganti objek DOM dalam banyak langkah perulangan, disarankan untuk menempatkan semua anggota DOM terlebih dahulu dalam variabel terpisah yang tidak dapat diganti.
$posterColumn = $dom->find('td.posterColumn');
$titleColumn = $dom->find('td.titleColumn');
$ratingColumn = $dom->find('td.ratingColumn.imdbRating');Seperti yang bisa kita lihat, rank tersebut hadir pada anggota utama td Tandai dengan nama kelas titleColumn. Untuk mengekstrak ranknya, tuliskan kode berikut:
$arr('Rank') = $dom->find('td.titleColumn')->text;
Jika Anda hanya menggunakan kode di atas, mungkin akan menimbulkan masalah kecil td Daftar yang baru saja kita gulir tidak hanya berisi peringkat tetapi juga judul filmnya.
Tarik semuanya td tag sebagai teks juga mengambil semua anggota elemen yang tidak dikelilingi oleh tag. Jadi kami menggunakan fungsi PHP untuk membagi semua teks dot (.) dan ekstrak hanya data pertama dari array yang dihasilkan dari pemisahan.
$arr('Rank') = array_shift(explode('.', $dom->find('td.titleColumn')->text));
Sekarang, karena kita tidak tahu apakah teks yang kita gores mengandung spasi yang tidak terlihat, mengapitnya dengan trim akan menghilangkan spasi yang tidak diinginkan, sehingga menghasilkan hasil numerik. arr(‘Rank’);
$arr('Rank') = trim(array_shift(explode('.', $dom->find('td.titleColumn')->text)));Untuk mengekstrak atribut dari tag, gunakan getAttributes() Metode:
$arr('ImageURL') = $dom->loadStr($posterColumn)->find('img')->getAttributes()('src');Di Sini, getAttributes menghasilkan array pasangan kunci-nilai, di mana nama atribut adalah kuncinya dan nilai atribut adalah nilainya. Memanggil nama atribut individual, mis. Misalnya memanggil anggota array menggunakan indeks akan mengembalikan nilai yang diperlukan.
Demikian pula, mengisi semua nilai kunci array akan memberi Anda semua informasi yang Anda perlukan tentang film pertama. Melanjutkan perulangan untuk masing-masing 250 film menyebabkan perayap kami memilah semua data yang diperlukan tentang 250 film tersebut.
Dan wah, scraper kita hampir selesai!
Membuat CSV
Kini setelah kita membuat scraper, saatnya memasukkan data ke dalam format yang sesuai untuk mengekstrak wawasan yang dapat ditindaklanjuti dari data tersebut. Untuk melakukan ini, kami membuat dokumen CSV. Karena pembuat CSV sudah ada di perpustakaan PHP, kita tidak memerlukan alat atau perpustakaan eksternal apa pun.
Buka aliran file di direktori mana pun dan gunakan fputcsv di setiap loop scraper yang kita buat. Di akhir program kami, file CSV dibuat secara efektif.
$file = fopen("./test.csv", "w");
foreach ($movies as $mId => $movie) {
fputcsv($file, $arr);
}Setelah menjalankan program ini, kita dapat melihat bahwa file CSV yang kita hasilkan tidak berisi header kolom apa pun. Untuk memperbaikinya, kami menetapkan kondisi untuk membuang kunci array yang kami hasilkan selama pengikisan di loop tepat di atas fputcsv Garis.
foreach ($movies as $mId => $movie) {
if ($mId == 0) {
fputcsv($file, array_keys($arr));
}
fputcsv($file, $arr);
}Dengan cara ini, pada awal setiap loop, hanya film pertama yang akan menggunakan kunci array ini untuk menampilkan file header di awal file CSV.
Seluruh kode terlihat seperti ini:
<?php
require_once "vendor/autoload.php";
use GuzzleHttpClient;
use PHPHtmlParserDom;
$fieldsRequired = (
'Rank', 'Title', 'Director', 'Leads', 'URL', 'ImageURL', 'Rating', 'NoOfReview', 'ReleaseYear'
);
$baseUrl="https://www.imdb.com";
$pageUrl="/chart/top/?ref_=nv_mp_mv250";
$headers = (
'user-agent' => 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36',
'accept' => 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8',
'accept-language' => 'en-US,en;q=0.8'
);
$file = fopen("./test.csv", "w");
$client = new Client(
'base_uri' => $baseUrl,
'headers' => $headers,
));
$response = $client->request('GET', $pageUrl);
$dom = new Dom();
$dom->loadStr($response->getBody());
$movies = $dom->find('table(data-caller-name="chart-top250movie") > tbody > tr');
foreach ($movies as $mId => $movie) {
$dom->loadStr($movie);
$posterColumn = $dom->find('td.posterColumn');
$titleColumn = $dom->find('td.titleColumn');
$ratingColumn = $dom->find('td.ratingColumn.imdbRating');
$arr = ();
$arr('Rank') = trim(array_shift(explode('.', $titleColumn->text)));
$arr('Title') = $dom->loadStr($titleColumn)->find('a')->text;
$names = $dom->loadStr($titleColumn)->find('a')->getAttributes()('title');
$arr('Director') = array_shift(explode(" (dir.), ", $names));
$arr('Leads') = array_pop(explode(" (dir.), ", $names));
$arr('URL') = $baseUrl.$dom->loadStr($titleColumn)->find('a')->getAttributes()('href');
$arr('ImageURL') = $dom->loadStr($posterColumn)->find('img')->getAttributes()('src');
$arr('Rating') = $dom->loadStr($ratingColumn)->find('strong')->text;
$ratingText = $dom->loadStr($ratingColumn)->find('strong')->getAttributes()('title');
preg_match_all("/(0-9,)+/", $ratingText, $reviews);
$arr('NoOfReviews') = str_replace(",", "", array_pop($reviews(0)));
$arr('ReleaseYear') = str_replace(("(", ")"), "", $dom->loadStr($titleColumn)->find('span')->text);
if ($mId == 0) {
fputcsv($file, array_keys($arr));
}
fputcsv($file, $arr);
}Sebagai hasil kerja keras kami, kami mendapatkan kumpulan data berikut yang berisi semua film yang kami cari. Unduh daftarnya di sini.
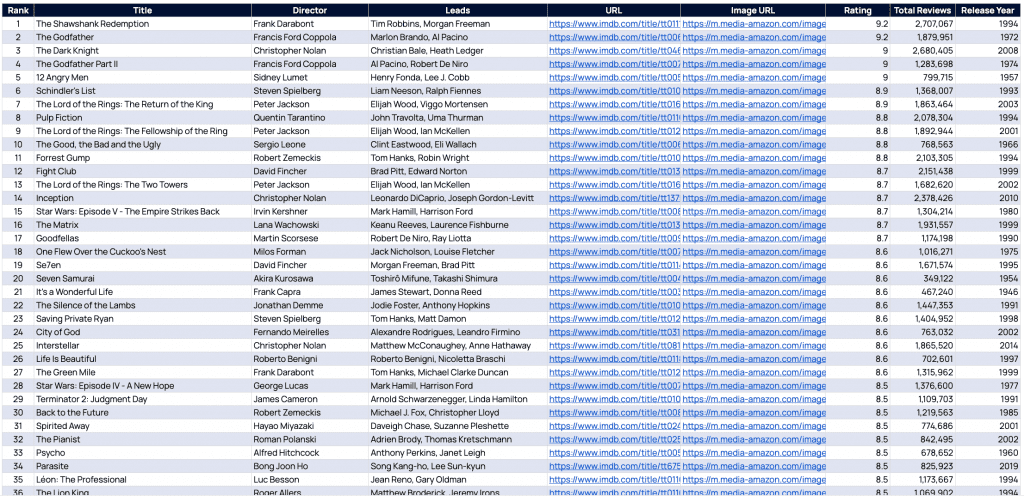
Pengikisan web dengan PHP itu mudah (atau tidak!)
Fiuh! Kita membahas cukup banyak materi di sana, bukan? Pada dasarnya itulah cara membuat crawler, namun kita perlu memahami bahwa pemrosesan web dirancang untuk pengguna, bukan crawler.
Ketika ekstraksi data dilakukan secara sembarangan, server web akan kehilangan waktu pemrosesan yang mahal dan merugikan bisnis mereka karena pengguna sebenarnya tidak menerima layanan tersebut.
Hal ini menyebabkan situs web sumber menggunakan berbagai teknik pemblokiran untuk mencegah crawler mengirimkan permintaan ke server mereka.
Untuk proyek yang lebih kecil, Anda juga dapat menulis crawlernya sendiri. Namun, seiring dengan meningkatnya cakupan proyek, komplikasi yang timbul mungkin terlalu besar untuk ditangani oleh tim kecil, apalagi individu.
Grepsr, dengan pengalaman bertahun-tahun dalam ekstraksi data, berspesialisasi dalam mengekstraksi informasi dari web tanpa mempengaruhi fungsi server web. Baca tentang legalitas web scraping di sini:
Kami harap Anda sekarang memiliki pengetahuan dasar untuk membuat web scraper menggunakan PHP. Jika Anda merasa perlu memperluas upaya ekstraksi data, jangan ragu untuk menghubungi kami. Kami di sini untuk membantu.
Bacaan Terkait: