
Mengikis Zillow dengan Python dapat berguna karena berbagai alasan. Ini dapat membantu agen real estate dan investor mengikuti tren pasar saat ini, dengan cepat mengidentifikasi properti potensial, menganalisis data dari listing, dan tetap mengetahui aktivitas listing lokal. Selain itu, scraping adalah cara efisien untuk menemukan properti yang didiskon atau diremehkan, yang dapat memberikan peluang besar bagi mereka yang mencarinya untuk diri sendiri atau bisnis.
Artikel kami membahas dasar-dasar apa yang diperlukan untuk mengambil data dari situs web, termasuk menggunakan paket seperti BeautifulSoup dan Selenium untuk mendapatkan data yang Anda perlukan. Terakhir, artikel ini menjelaskan beberapa tips tentang cara menghapus Zillow secara lebih efektif dengan menghindari deteksi atau pemblokiran karena permintaan yang berlebihan.
Daftar Isi
Cara mengikis data properti Zillow
Ada beberapa cara untuk mendapatkan data real estat dari Zillow. Kami memberikan opsi tanpa kode dan contoh penulisan scraper Anda sendiri. Perlu juga disebutkan bahwa Zillow memiliki API ekstraksi datanya sendiri.
Menggunakan API Zillow
Zillow saat ini menawarkan 22 antarmuka pemrograman aplikasi (API) yang berbeda. Ini dirancang untuk mengumpulkan berbagai data: termasuk pencatatan dan penilaian, perkiraan properti, sewa dan penyitaan.
Akses ke beberapa layanan yang disediakan melalui API dikenakan biaya tergantung pada tingkat penggunaan. Selain itu, Zillow mengalihkan operasi datanya ke Bridge Interactive, sebuah perusahaan yang berfokus pada informasi dan broker MLS. Untuk menggunakan Bridge, pengguna harus mendapatkan persetujuan sistem sebelum menggunakan titik akhirnya - termasuk orang yang sebelumnya pernah menggunakan API Zillow.
Untuk mempelajari lebih lanjut dan mencoba Zillow API, kunjungi situs web resmi pengembang API.
Cara menggunakan scraper Zillow tanpa kode
Cara paling mudah adalah dengan menggunakan scraper tanpa kode siap pakai yang ditulis khusus untuk Zillow.
Untuk menggunakannya, masuk ke Scrape-It.Cloud dan buka halaman scraper tanpa kode. Anda dapat menemukan scraper Zillow yang sudah jadi di kategori “Real Estat” di sini.
Di sini Anda dapat menyesuaikan semua aspek pencarian properti Anda: jumlah baris, wilayah dan jenis (dijual, disewakan, dijual). Selain itu, Anda juga dapat menerima daftar real estat terperinci yang menyertakan tautan URL ke setiap daftar, gambar (jika tersedia), label harga, deskripsi agen atau agen yang berlaku, nama dan informasi kontak agen atau agensi yang bersangkutan. mereka berafiliasi dll.
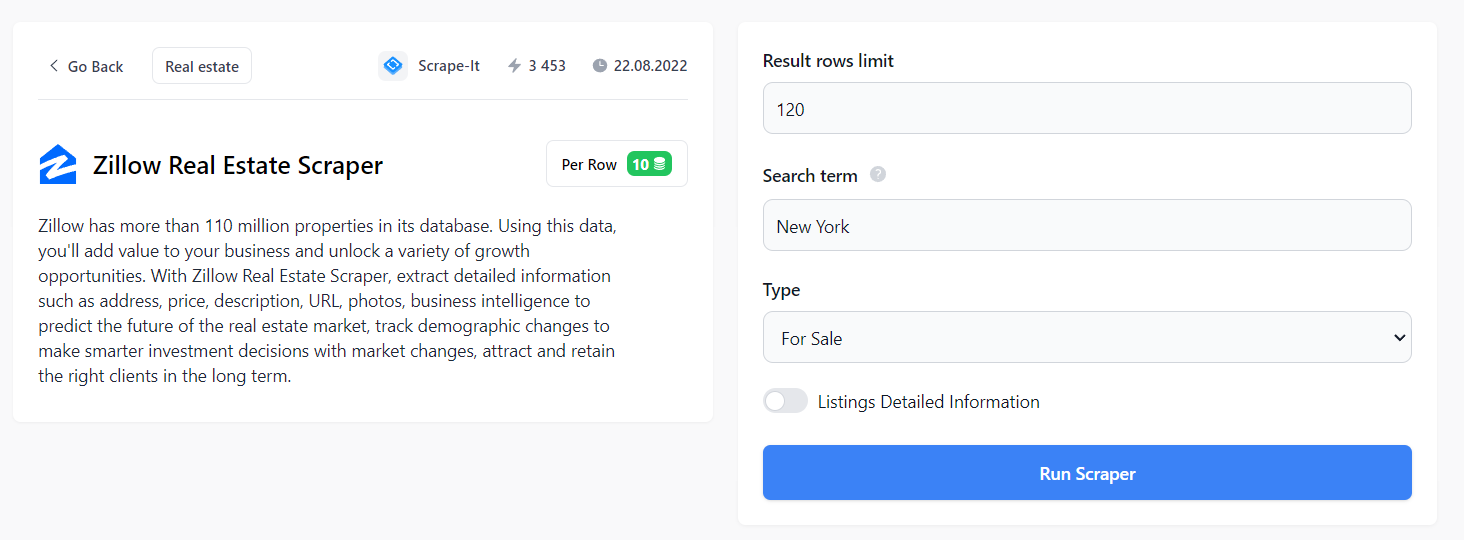
Data yang dihasilkan dapat dimuat dalam format CSV, JSON atau XSLX.

Data yang dihasilkan mudah diproses dan tidak diperlukan pengetahuan bahasa pemrograman untuk menggunakan scraper. Selain itu, Anda tidak perlu khawatir tentang cara menghindari penyumbatan.
Buat alat pengikis web Zillow Anda sendiri
Pengikisan data dari Zillow dapat dilakukan dengan menggunakan berbagai bahasa pemrograman. Opsi populer untuk menyalin situs web termasuk Python dan NodeJS. Tergantung pada kompleksitas tugas yang diperlukan untuk mengakses informasi yang diinginkan, setiap bahasa mungkin memiliki kelebihan atau kekurangan dalam hal kecepatan, akurasi, skalabilitas, dan kemampuan analitis.
Pilihan bahasa pemrograman untuk web scraping Zillow sangat bergantung pada kebutuhan dan preferensi spesifik pengguna. Kedua bahasa tersebut memiliki kelebihan dan kekurangan masing-masing tergantung pada tugas apa yang harus diselesaikan selama periode ekstraksi.
NodeJS menyediakan lingkungan asinkron di mana halaman web dapat di-scrap menggunakan kode JavaScript. NodeJS menawarkan skalabilitas yang sangat baik karena arsitektur berbasis peristiwanya, memungkinkan banyak permintaan secara bersamaan sambil mempertahankan penggunaan CPU yang rendah.
Di sisi lain, Python adalah bahasa pemrograman kuat yang telah digunakan untuk web scraping selama bertahun-tahun. Mudah dipelajari dan menawarkan berbagai perpustakaan dan kerangka kerja yang dapat digunakan untuk analisis, visualisasi, dan analisis data. Karena fleksibilitasnya, Python dapat mengekstrak informasi terstruktur dari sebagian besar halaman web dengan andal.
Mengikis Zillow dengan Python
Mari kita lihat langkah demi langkah cara menulis scraper Zillow dengan Python. Di akhir artikel, kami juga memberikan rekomendasi tambahan untuk menghindari pemblokiran dan membuat pengikisan lebih aman.
Menginstal perpustakaan
Pertama, mari kita pilih perpustakaan. Ada dua kemungkinan:
- Menggunakan perpustakaan kueri (Permintaan, UrlLib atau lainnya) dan perpustakaan analisis (BeautifulSoup, Lxml).
- Menggunakan perpustakaan lengkap atau kerangka scraping (Scrapy, Selenium, Pyppeteer).
Opsi pertama lebih mudah bagi pemula, tetapi opsi kedua lebih aman. Jadi mari kita mulai dengan menulis scraper sederhana yang menggunakan pustaka Requests dan BeautifulSoup untuk mengambil dan menganalisis data. Kami kemudian memberikan contoh scraper yang menggunakan selenium.
Pertama instal penerjemah Python. Untuk memeriksa atau memastikan sudah terinstal, masukkan pada baris perintah:
python -VJika penerjemah sudah terinstal, versinya akan ditampilkan. Untuk menginstal perpustakaan, masukkan yang berikut ini pada baris perintah:
pip install requests
pip install beautifulsoup4
pip install seleniumSelenium juga memerlukan driver web dan browser Chrome dengan versi yang sama.
Analisis Halaman Zillow
Mari menganalisis halaman untuk menemukan tag yang berisi data yang diperlukan. Ayo buka website Zillow ke bagian pembelian. Dalam tutorial ini, kami akan mengumpulkan data tentang real estate di Portland.
Sekarang mari kita lihat kode HTML halaman untuk menentukan elemen yang ingin kita hapus.
Untuk membuka kode halaman HTML, buka DevTools (tekan F12 atau klik kanan pada ruang kosong di halaman dan buka Inspect).
Mari kita tentukan elemen yang akan dikikis:
1. Alamat. Datanya sudah masuk <address data-test="property-card-addr">...</address> Label.
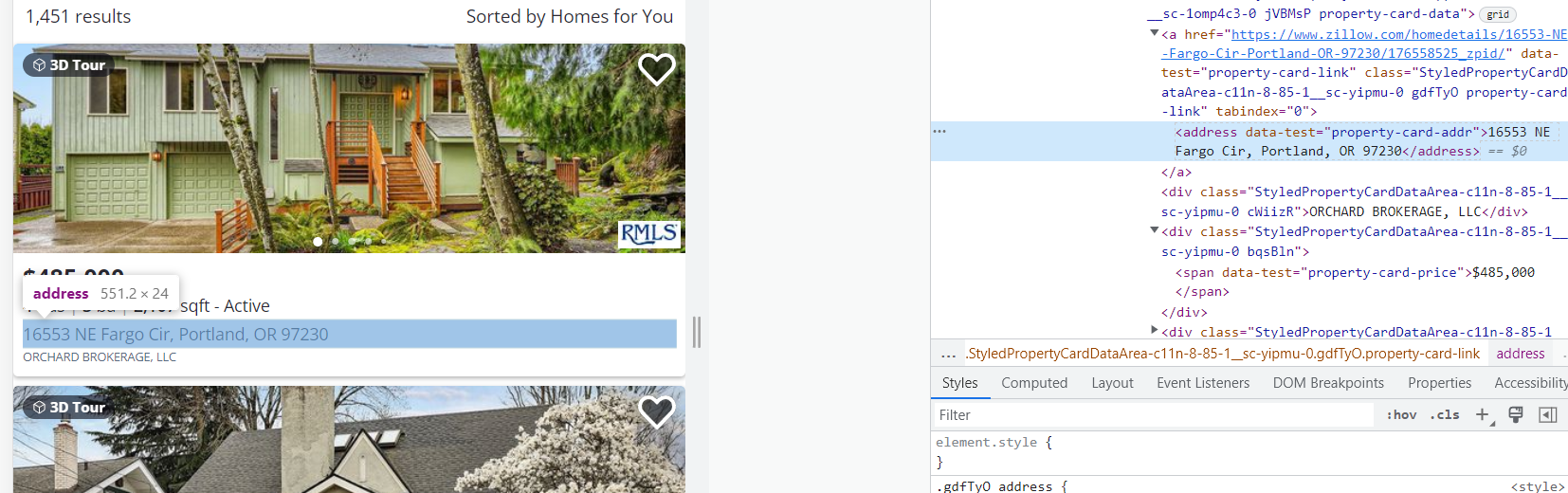
hadiah ke-2. Datanya ada di sana <span data-test="property-card-price">…</span> Label.

3. Penjual atau perantara. Datanya sudah masuk <div class= "cWiizR">…</div> Label.

Tag serupa untuk semua kartu lainnya.
Sekarang mari kita mulai menulis scraper berdasarkan informasi yang telah kita kumpulkan.
Buat pengikis web
Buat file dengan ekstensi *.py dan tambahkan perpustakaan yang diperlukan:
import requests
from bs4 import BeautifulSoupMari buat permintaan dan simpan seluruh kode halaman dalam sebuah variabel.
data = requests.get('https://www.zillow.com/portland-or/')Memproses data menggunakan perpustakaan BS4.
soup = BeautifulSoup(data.text, "lxml")Buat variabel alamat, harga, Dan Pramuniagadi mana kami memasukkan data yang dieksekusi berdasarkan informasi yang dikumpulkan sebelumnya.
address = soup.find_all('address', {'data-test':'property-card-addr'})
price = soup.find_all('span', {'data-test':'property-card-price'})
seller = soup.find_all('div', {'class':'cWiizR'})Sayangnya, saat kami mencoba melihat konten variabel ini, kami mendapatkan kesalahan karena Zillow mengembalikan captcha dan bukan kode halaman.
Untuk menghindari hal ini, tambahkan header ke isi permintaan:
header = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36',
'referer':'https://www.zillow.com/homes/Missoula,-MT_rb/'}
data = requests.get('https://www.zillow.com/portland-or/', headers=header)Sekarang mari kita coba menampilkan hasilnya di layar:
print(address)
print(price)
print(seller)Hasil dari skrip tersebut adalah sebagai berikut:
(<address data-test="property-card-addr">3142 NE Wasco St, Portland, ATAU 97232</address>, <address data-test="property-card-addr">4801 SW Caldew St, Portland, ATAU 97219</address>, <address data-test="property-card-addr">16553 NE Fargo Cir, Portland, ATAU 97230</address>, <address data-test="property-card-addr">3064 NW 132nd Ave, Portland, ATAU 97229</address>, <address data-test="property-card-addr">3739 SW Pomona St, Portland, ATAU 97219</address>, <address data-test="property-card-addr">1440 NW Jenne Ave, Portland, ATAU 97229</address>, <address data-test="property-card-addr">3435 SW 11th Ave, Portland, ATAU 97239</address>, <address data-test="property-card-addr">8023 N Princeton St, Portland, ATAU 97203</address>, <address data-test="property-card-addr">2456 NW Raleigh St, Portland, ATAU 97210</address>)
(<span data-test="property-card-price">$595,000</span>, <span data-test="property-card-price">$395,000</span>, <spanspan data-test="property-card-price">$485,000</span>, <span data-test="property-card-price">$1,185,000</span>, <span data-test="property-card-price">$349,900</span>, <span data-test="property-card-price">$599,900</span>, <span data-test="property-card-price">$575,000<span>, <span data-test="property-card-price">$425,000</span>, <span data-test="property-card-price">$1,195,000</span>)
(<div class="StyledPropertyCardDataArea-c11n-8-85-1__sc-yipmu-0 cWiizR">REALTI INTERNASIONAL CASCADE HASSON SOTHEBY</div>, <div class="StyledPropertyCardDataArea-c11n-8-85-1__sc-yipmu-0 cWiizR">REALTOR KREATIF PORTLAND</div>, <div class="StyledPropertyCardDataArea-c11n-8-85-1__sc-yipmu-0 cWiizR">BROKER ORCHARD, LLC</div>, <div class="StyledPropertyCardDataArea-c11n-8-85-1__sc-yipmu-0 cWiizR">ELEETE REAL ESTATE</div>, <div class="StyledPropertyCardDataArea-c11n-8-85-1__sc-yipmu-0 cWiizR">REALTIS SARANG PERKOTAAN</div>, <div class="StyledPropertyCardDataArea-c11n-8-85-1__sc-yipmu-0 cWiizR">KELLER WILLIAMS PROFESIONAL REALTI<div>, <div class="StyledPropertyCardDataArea-c11n-8-85-1__sc-yipmu-0 cWiizR">KELLER WILLIAMS PDX PUSAT<div>, <div class="StyledPropertyCardDataArea-c11n-8-85-1__sc-yipmu-0 cWiizR">EXP REALTI, LLC</div>, <divdiv class="StyledPropertyCardDataArea-c11n-8-85-1__sc-yipmu-0 cWiizR">REALTI INTERNASIONAL CASCADE HASSON SOTHEBY</div>)</spanspan>Mari buat variabel tambahan dan masukkan ke dalamnya hanya teks daftar properti dari data yang diterima:
adr=()
pr=()
sl=()
for result in address:
adr.append(result.text)
for result in price:
pr.append(result.text)
for results in seller:
sl.append(result.text)
print(adr)
print(pr)
print(sl)Hasil:
('16553 NE Fargo Cir, Portland, OR 97230', '3142 NE Wasco St, Portland, OR 97232', '8023 N Princeton St, Portland, OR 97203', '3064 NW 132nd Ave, Portland, OR 97229', '1440 NW Jenne Ave, Portland, OR 97229', '10223 NW Alder Grove Ln, Portland, OR 97229', '5302 SW 53rd Ct, Portland, OR 97221', '3435 SW 11th Ave, Portland, OR 97239', '3739 SW Pomona St, Portland, OR 97219')
('$485,000', '$595,000', '$425,000', '$1,185,000', '$599,900', '$425,000', '$499,000', '$575,000', '$349,900')
('ORCHARD BROKERAGE, LLC', 'CASCADE HASSON SOTHEBY'S INTERNATIONAL REALTY', 'EXP REALTY, LLC', 'ELEETE REAL ESTATE', 'KELLER WILLIAMS REALTY PROFESSIONALS', 'ELEETE REAL ESTATE', 'REDFIN', 'KELLER WILLIAMS PDX CENTRAL', 'URBAN NEST REALTY')Kode skrip lengkap:
import requests
from bs4 import BeautifulSoup
header = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36',
'referer':'https://www.zillow.com/homes/Missoula,-MT_rb/'}
data = requests.get('https://www.zillow.com/portland-or/', headers=header)
soup = BeautifulSoup(data.text, 'lxml')
address = soup.find_all('address', {'data-test':'property-card-addr'})
price = soup.find_all('span', {'data-test':'property-card-price'})
seller =soup.find_all('div', {'class':'cWiizR'})
adr=()
pr=()
sl=()
for result in address:
adr.append(result.text)
for result in price:
pr.append(result.text)
for results in seller:
sl.append(result.text)
print(adr)
print(pr)
print(sl)Sekarang datanya dalam format yang mudah digunakan dan Anda dapat terus mengerjakannya.
menyimpan data
Supaya kita tidak perlu copy sendiri datanya ke dalam file, kita simpan di file CSV. Untuk melakukan ini, kita membuat file dan memasukkan nama kolom di dalamnya:
with open("zillow.csv", "w") as f:
f.write("Address; Price; Seller\n")Surat "w“ menunjukkan bahwa file bernama zillow.csv akan dibuat jika tidak ada. Jika file seperti itu ada, maka akan dihapus dan dibuat ulang. Anda dapat menggunakan opsi “.a" atribut untuk menghindari penimpaan konten setiap kali Anda menjalankan skrip.
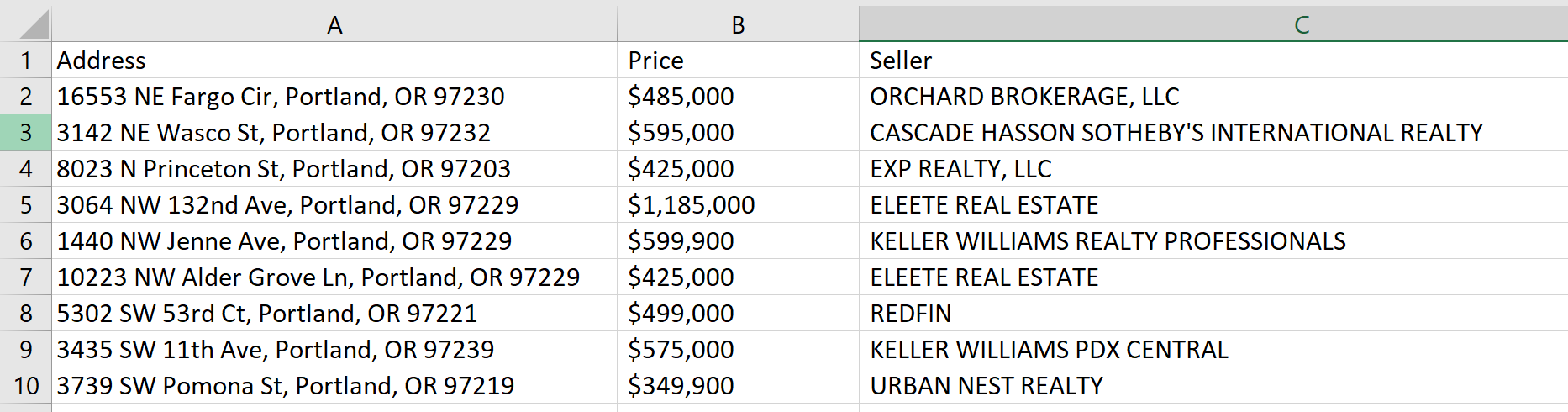
Telusuri item-itemnya dan catat dalam tabel:
for i in range(len(adr)):
with open("zillow.csv", "a") as f:
f.write(str(adr(i))+"; "+str(pr(i))+"; "+str(sl(i))+"\n")Hasilnya, kami mendapatkan tabel berikut:
Kode skrip lengkap:
import requests
from bs4 import BeautifulSoup
header = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36',
'referer':'https://www.zillow.com/homes/Missoula,-MT_rb/'}
data = requests.get('https://www.zillow.com/portland-or/', headers=header)
soup = BeautifulSoup(data.text, 'lxml')
address = soup.find_all('address', {'data-test':'property-card-addr'})
price = soup.find_all('span', {'data-test':'property-card-price'})
seller =soup.find_all('div', {'class':'cWiizR'})
adr=()
pr=()
sl=()
for result in address:
adr.append(result.text)
for result in price:
pr.append(result.text)
for results in seller:
sl.append(result.text)
with open("zillow.csv", "w") as f:
f.write("Address; Price; Seller\n")
for i in range(len(adr)):
with open("zillow.csv", "a") as f:
f.write(str(adr(i))+"; "+str(pr(i))+"; "+str(sl(i))+"\n")Jadi kami membuat scraper Zillow sederhana dengan Python.
Cara Menggaruk Zillow Tanpa Terblokir
Zillow melarang keras penggunaan scraper dan bot untuk mengumpulkan data di situsnya. Mereka memantau secara ketat dan mengambil tindakan terhadap segala upaya pengumpulan data menggunakan metode ini.
Mari kita lihat sekilas bagaimana kita dapat memodifikasi atau meningkatkan kode yang dihasilkan untuk mengurangi risiko pemblokiran.
Penggunaan proxy
Cara termudah adalah dengan menggunakan proxy. Kami telah menulis tentang proxy dan di mana Anda bisa mendapatkan proxy gratis.
Mari buat file proxy dan letakkan beberapa proxy yang berfungsi di dalamnya. Kemudian sambungkan file proxy ke scraper:
with open('proxies.txt', 'r') as f:
proxies = f.read().splitlines()Untuk memilih proxy secara acak, kami menghubungkan secara acak Perpustakaan untuk proyek ini:
import randomSekarang tulis nilai acak dari daftar proksi ke variabel proksi dan tambahkan proksi ke badan permintaan:
proxy = random.choice(proxies)
data = requests.get('https://www.zillow.com/portland-or/', headers=header, proxies={"http": proxy})Hal ini mengurangi jumlah kesalahan dan membantu menghindari penyumbatan.
Menggunakan browser tanpa kepala
Cara lain untuk menghindari pemblokiran adalah dengan menggunakan browser tanpa kepala. Perpustakaan yang paling nyaman untuk ini adalah Selenium.
Buat file baru dengan ekstensi *.py, impor perpustakaan dan modul yang diperlukan, serta driver web:
from selenium import webdriver
from selenium.webdriver.common.by import By
DRIVER_PATH = 'C:\chromedriver.exe'
driver = webdriver.Chrome(executable_path=DRIVER_PATH)Untuk membuat contoh lebih lengkap, kami menggunakan XPath untuk mengeksekusi data yang diperlukan:
address = driver.find_elements(By.XPATH,'//address')
price = driver.find_elements(By.XPATH,'//article/div/div/div(2)/span')
seller = driver.find_elements(By.XPATH,'//div(contains(@class, "cWiizR"))')Sekarang gunakan beberapa kode dari contoh terakhir dan tambahkan data simpanan ke file:
adr=()
pr=()
sl=()
for result in address:
adr.append(result.text)
for result in price:
pr.append(result.text)
for results in seller:
sl.append(result.text)
with open("zillow.csv", "w") as f:
f.write("Address; Price; Seller\n")
for i in range(len(adr)):
with open("zillow.csv", "a") as f:
f.write(str(adr(i))+"; "+str(pr(i))+"; "+str(sl(i))+"\n")Terakhir, tutup webdriver:
driver.quit()Kode lengkap:
from selenium import webdriver
from selenium.webdriver.common.by import By
DRIVER_PATH = 'C:\chromedriver.exe'
driver = webdriver.Chrome(executable_path=DRIVER_PATH)
driver.get('https://www.zillow.com/portland-or/')
address = driver.find_elements(By.XPATH,'//address')
price = driver.find_elements(By.XPATH,'//article/div/div/div(2)/span')
seller = driver.find_elements(By.XPATH,'//div(contains(@class, "cWiizR"))')
adr=()
pr=()
sl=()
for result in address:
adr.append(result.text)
for result in price:
pr.append(result.text)
for results in seller:
sl.append(result.text)
with open("zillow.csv", "w") as f:
f.write("Address; Price; Seller\n")
for i in range(len(adr)):
with open("zillow.csv", "a") as f:
f.write(str(adr(i))+"; "+str(pr(i))+"; "+str(sl(i))+"\n")
driver.quit()Setelah memulai, Chromium akan terbuka dengan halaman yang kami tentukan. Ketika halaman dimuat sepenuhnya, data yang diperlukan dikumpulkan dan disimpan ke file. Driver web kemudian ditutup.
Isi berkas:
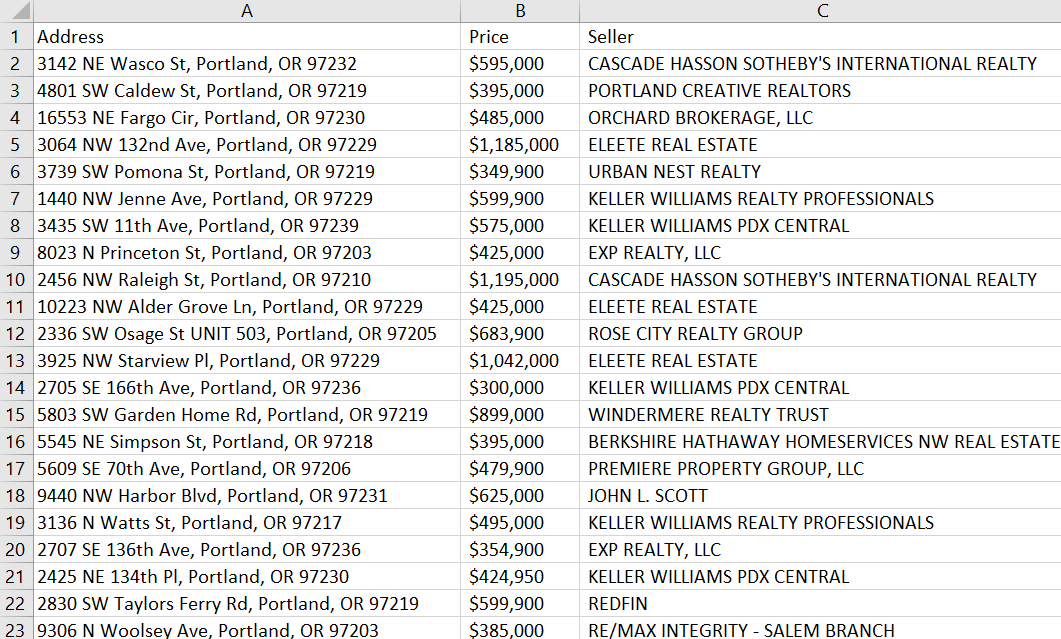
Ini berarti kami telah meningkatkan keamanan scraper kami.
Menggunakan API pengikisan web
Menggunakan API web scraping adalah pilihan terbaik karena menggabungkan penggunaan browser tanpa kepala, rotasi proxy otomatis, dan cara lain untuk melewati pemblokiran.
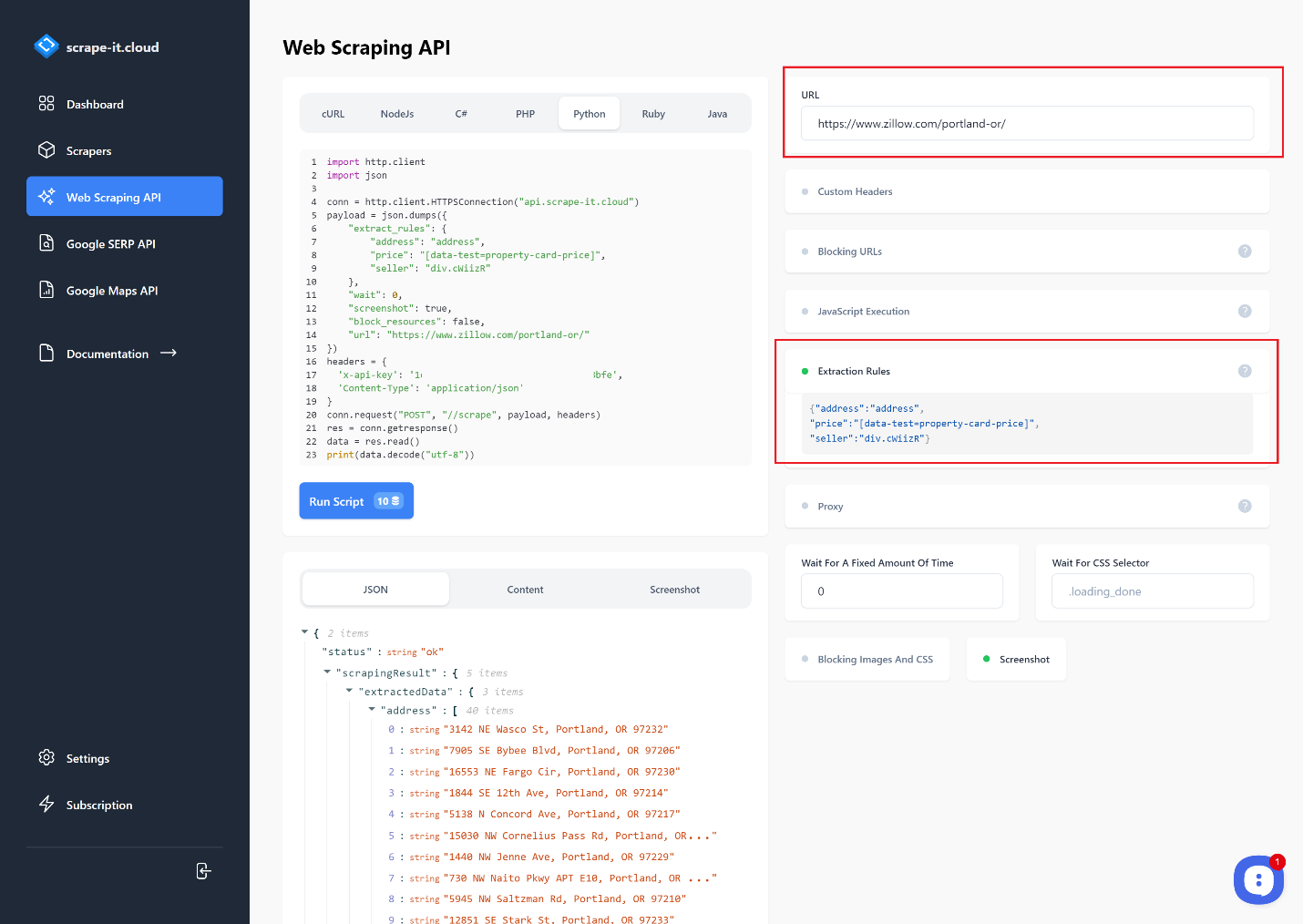
Kami menggunakan Scrape-It.Cloud untuk tugas ini. Daftar dan verifikasi alamat email Anda untuk mendapatkan 1000 kredit gratis. Lalu buka halaman Web Scraping API dan masukkan link tempat Anda ingin mengekstrak data. Anda dapat memilih bahasa pemrograman dan menyesuaikan permintaan.
Mari gunakan aturan ekstraksi untuk mendapatkan alamat, harga, dan penjual saja:
Tergantung pada tujuannya, data yang dihasilkan dapat segera disalin dan diproses lebih lanjut atau digunakan. Untuk kenyamanan, kami akan membuat skrip dan, berdasarkan permintaan yang dihasilkan, membuat scraper yang menyertakan fungsi untuk menyimpan data ke file CSV. Untuk membuat contoh lebih lengkap, kami menggunakan Permintaan Perpustakaan dan tulis ulang permintaan:
import requests
import json
url = "https://api.scrape-it.cloud/scrape"
payload = json.dumps({
"extract_rules": {
"address": "address",
"price": "(data-test=property-card-price)",
"seller": "div.cWiizR"
},
"wait": 0,
"screenshot": True,
"block_resources": False,
"url": "https://www.zillow.com/portland-or/"
})
headers = {
'x-api-key': 'YOUR-API-KEY',
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)Sekarang mari kita ubah jawabannya ke dalam bentuk yang lebih nyaman untuk bekerja dengan struktur:
data = json.loads(response.text)Buat variabel alamat, Harga, Dan Pramuniagadi mana kita memasukkan data dari kueri:
address = ()
price = ()
seller = ()
for item in data("scrapingResult")("extractedData")("address"):
address.append(item)
for item in data("scrapingResult")("extractedData")("price"):
price.append(item)
for item in data("scrapingResult")("extractedData")("seller"):
seller.append(item)Sekarang mari kita simpan data ke file:
with open("result.csv", "w") as f:
f.write("Address; Price; Seller\n")
for i in range(len(address)):
with open("result.csv", "a") as f:
f.write(str(address(i))+"; "+str(price(i))+"; "+str(seller(i))+"\n")Hasilnya, kita mendapatkan file *.csv yang sama seperti sebelumnya, namun sekarang kita tidak perlu menggunakan browser headless, proxy, atau layanan koneksi untuk menyelesaikan captcha. Semua fungsi ini sudah dijalankan di situs Scrape-It.Cloud.
Baca juga tentang itu keriting Python
Kesimpulan dan temuan
Mengikis Zillow dengan Python memiliki potensi besar untuk mendapatkan wawasan berharga tentang pasar real estat. Ini adalah cara efisien untuk mengumpulkan data tentang listingan, harga, lingkungan sekitar, dan banyak lagi. Dengan kueri dan kode yang dirancang dengan baik yang memanfaatkan pustaka Python seperti Beautiful Soup atau Selenium, siapa pun dapat menggunakan situs web Zillow untuk mengakses data ini dan menganalisis tren pasar lokal atau regional mereka.
Namun perlu diingat bahwa struktur atau nama kelas dapat diubah di website. Sebelum menggunakan contoh kami, Anda harus memastikan bahwa datanya masih terkini.
Jika Anda masih merasa kesulitan untuk menulis scraper itu sendiri, coba gunakan scraper tanpa kode. Scraper tanpa kode kami relatif cepat dan mudah diatur tanpa pengalaman atau pengetahuan pemrograman apa pun.