
Mempelajari web scraping PHP bermanfaat di berbagai bidang. Baik Anda seorang pemasar atau peneliti SEO, akses ke data terkini selalu penting dan pengumpulan data manual dapat memakan waktu. Di sinilah web scraping berperan. Ini dapat membantu dalam banyak bidang, mulai dari optimasi mesin pencari dan pemasaran SEO hingga analisis data besar.
Daftar Isi
Mengapa mengikis dengan PHP?
PHP adalah bahasa pemrograman berorientasi objek kuat yang dirancang khusus untuk pengembangan web. Berkat sintaksisnya yang ramah pengguna, mudah dipelajari dan dipahami bahkan untuk pemula. Selain ramah pengguna, PHP juga memiliki performa luar biasa sehingga skrip PHP dapat dijalankan dengan cepat dan efisien.
Dukungan kuat dari komunitas PHP memastikan Anda memiliki akses ke berbagai sumber daya, tutorial, dan forum tempat Anda dapat menerima panduan dan berbagi pengetahuan. Secara keseluruhan, PHP menawarkan kombinasi sempurna antara kesederhanaan, kecepatan, dan keserbagunaan, menjadikannya bahasa pemrograman yang sangat baik untuk web scraping.
Menyiapkan lingkungan untuk web scraping dengan PHP
Untuk membuat scraper PHP, kita perlu menyiapkan PHP dan mengunduh perpustakaan yang nantinya akan kita sertakan dalam proyek kita. Namun, ada dua cara yang bisa kita lakukan. Anda dapat mengunduh semua perpustakaan secara manual dan mengonfigurasi file inisialisasi atau mengotomatiskannya menggunakan Komposer.
Karena tujuan kami adalah menyederhanakan skrip sebanyak mungkin dan menunjukkan cara melakukannya, kami akan menginstal Composer dan memandu Anda cara menggunakannya.
Pemasangan komponen
Pertama, unduh PHP dari situs resminya. Jika Anda menggunakan Windows, unduh versi stabil terbaru sebagai arsip zip. Kemudian unzip ke lokasi yang mudah diingat, seperti folder “PHP” di drive C Anda.
Jika Anda menggunakan Windows, Anda perlu mengatur jalur ke file PHP di sistem Anda. Untuk melakukan ini, buka folder mana pun di komputer Anda dan buka Pengaturan Sistem (klik kanan pada PC ini dan buka Properti).
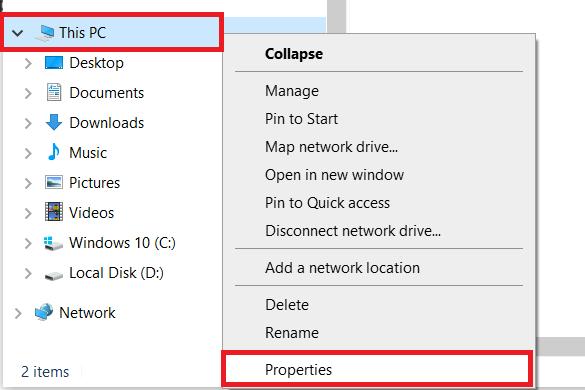
Di halaman tersebut, cari opsi “Pengaturan Sistem Lanjutan” dan klik di atasnya.
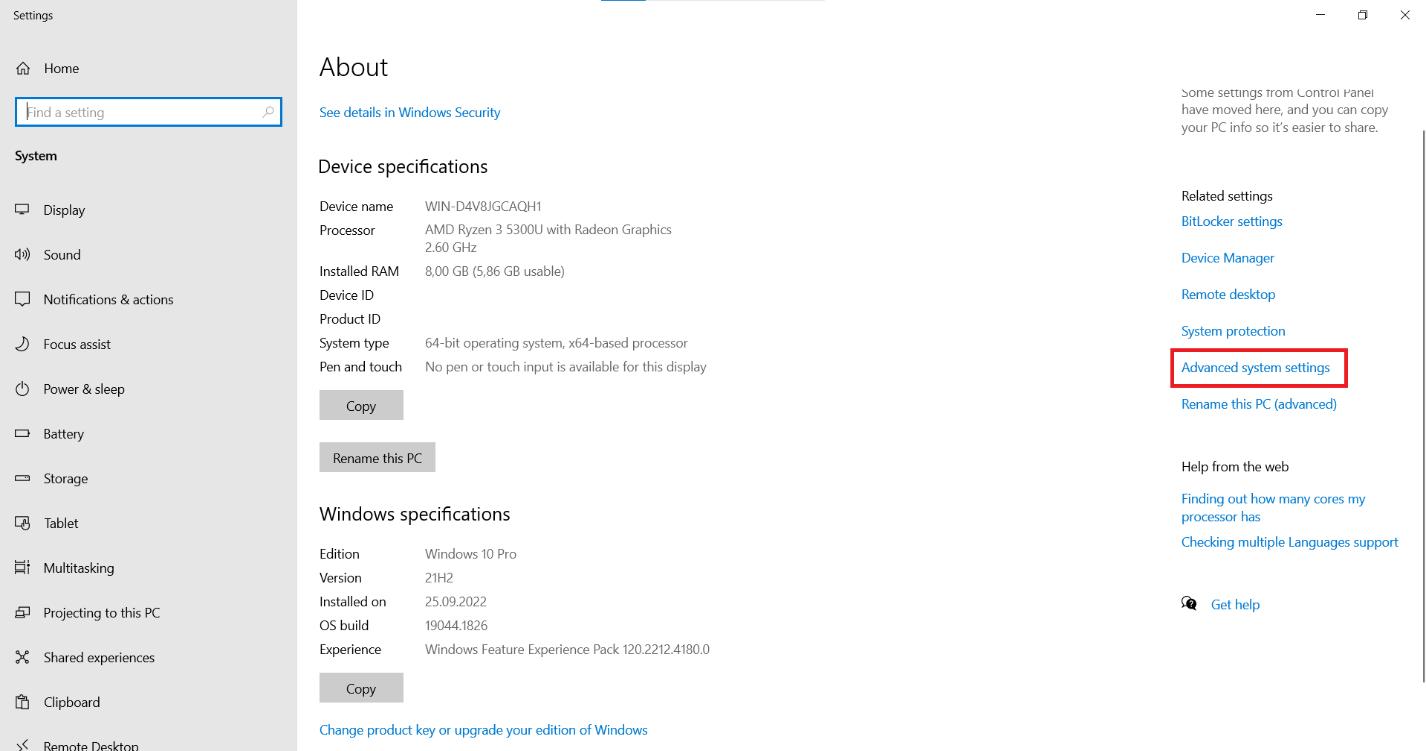
Pada tab Advanced, cari tombol Environment Variables dan klik.
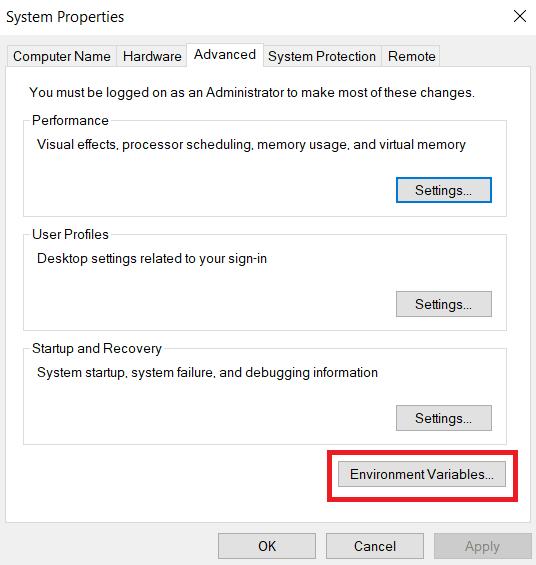
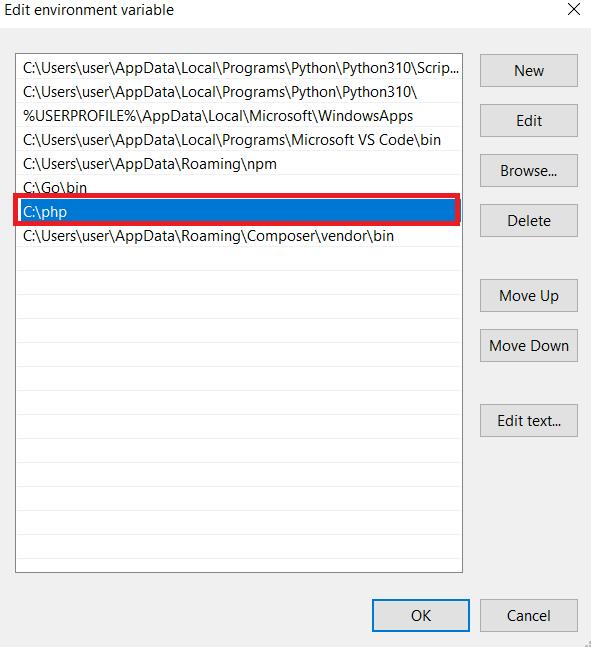
Di bagian “Variabel Pengguna untuk Pengguna”, temukan variabel “Jalur” dan klik tombol “Edit”.
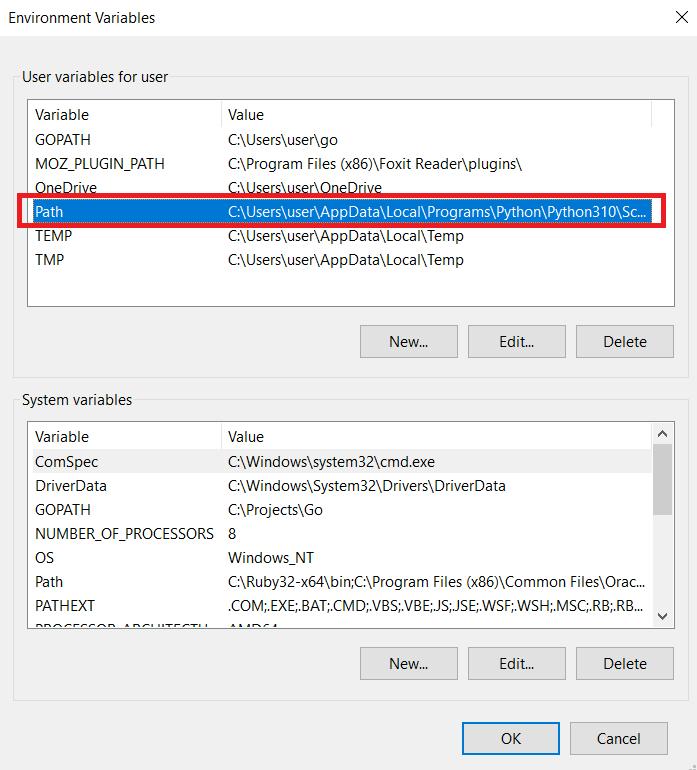
Jendela baru akan terbuka di mana Anda dapat mengedit nilai variabel “Path”. Tambahkan path ke file PHP di akhir nilai yang ada. Klik tombol OK untuk menyimpan perubahan. Jika Anda masih memiliki pertanyaan, Anda dapat membaca dokumentasinya.
Sekarang mari kita instal Composer, manajer ketergantungan untuk PHP yang memudahkan pengelolaan dan instalasi perpustakaan pihak ketiga di proyek Anda. Anda dapat mengunduh semua paket dari github.com, tetapi menurut pengalaman kami, Komposer lebih nyaman.
Pertama, buka situs resminya dan unduh Composer. Kemudian ikuti petunjuk di file instalasi. Anda juga perlu menentukan jalur dimana PHP berada. Jadi pastikan sudah diatur dengan benar.
Buat file baru bernama “composer.json” di root proyek Anda. File ini berisi informasi tentang dependensi proyek Anda. Kami telah menyiapkan satu file yang berisi semua perpustakaan yang digunakan dalam tutorial hari ini sehingga Anda dapat menyalin pengaturan kami.
{
"require": {
"fabpot/goutte": "^4.0",
"facebook/webdriver": "^1.1",
"guzzlehttp/guzzle": "^7.7",
"imangazaliev/didom": "^2.0",
"j4mie/idiorm": "^1.5",
"jaeger/querylist": "^4.2",
"kriswallsmith/buzz": "^0.15.0",
"nategood/httpful": "^0.3.2",
"php-webdriver/webdriver": "^1.1",
"querypath/querypath": "^3.0",
"sunra/php-simple-html-dom-parser": "^1.5",
"symfony/browser-kit": "^6.3",
"symfony/dom-crawler": "^6.3"
},
"config": {
"platform": {
"php": "8.2.7"
},
"preferred-install": {
"*": "dist"
},
"minimum-stability": "stable",
"prefer-stable": true,
"sort-packages": true
}
}Pertama, pada baris perintah, navigasikan ke direktori yang berisi file composer.json dan jalankan perintah berikut:
composer install Komposer mengunduh dependensi yang ditentukan dan memasangnya ke direktori vendor proyek Anda.
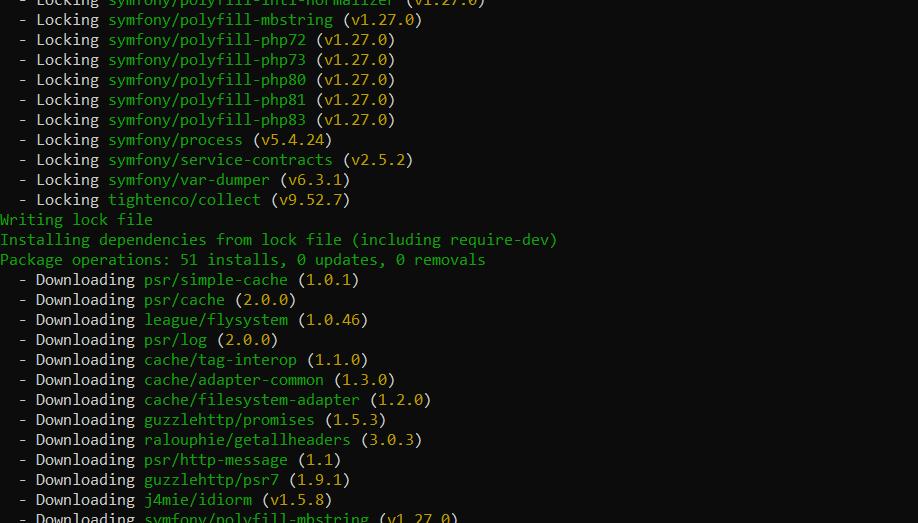
Anda sekarang dapat mengimpor perpustakaan ini ke proyek Anda menggunakan perintah di file dengan kode Anda.
require 'vendor/autoload.php';Sekarang Anda dapat menggunakan kelas dari perpustakaan yang diinstal hanya dengan memanggilnya dalam kode Anda.
Analisis halaman
Sekarang kita sudah menyiapkan lingkungan dan menyiapkan semua komponen, mari kita analisa website yang akan kita jelajahi. Kami akan menggunakan situs demo ini sebagai contoh. Buka situs web dan buka konsol pengembang (F12 atau klik kanan dan buka Inspeksi).
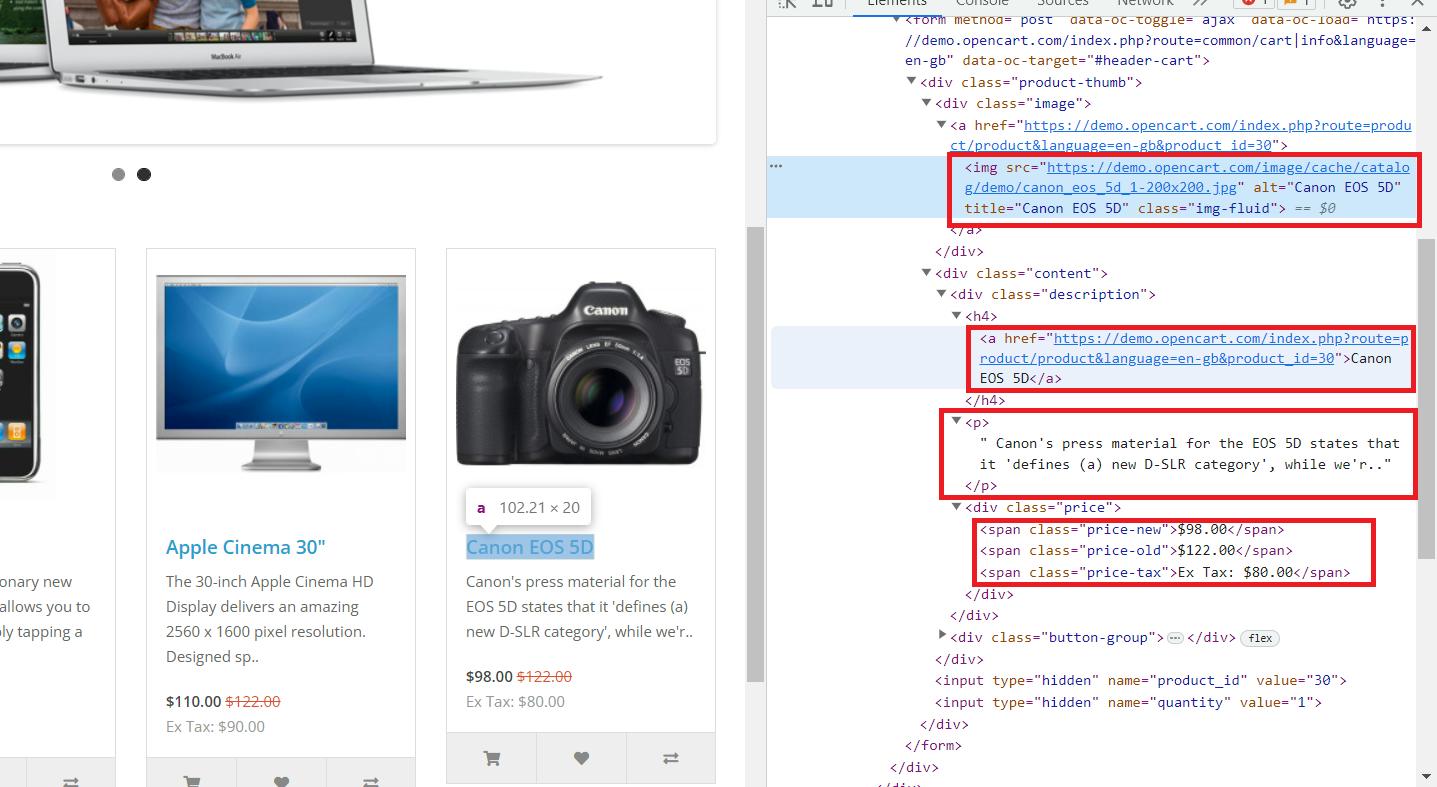
Di sini kita melihat bahwa semua data yang diperlukan disimpan dalam tag induk “div” dengan nama kelas “col”, yang berisi semua produk di halaman. Ini berisi informasi berikut:
- Tag “img” berisi link ke gambar produk di atribut “src”.
- Tag “a” berisi link produk di atribut “href”.
- Tag “h4” berisi judul produk.
- Tag “p” berisi deskripsi produk.
- Harga disimpan dalam tag span dengan kelas yang berbeda:
5.1. “Harga lama” dengan harga aslinya.
5.2. “Harga baru” dengan harga lebih murah.
5.3. “Pajak harga” untuk pajak.
Sekarang kita tahu di mana informasi yang kita butuhkan disimpan, kita bisa mulai melakukan scraping.
10 Perpustakaan Scraping Web PHP Terbaik
Ada begitu banyak perpustakaan di PHP sehingga sulit untuk mencakup semuanya secara komprehensif. Namun, kami telah memilih yang paling populer dan umum digunakan dan sekarang akan mempertimbangkannya satu per satu.
Makan
Kami memulai koleksi kami dengan Perpustakaan Guzzle. Satu-satunya hal yang dapat dilakukan perpustakaan ini adalah memproses permintaan, tetapi ia melakukannya dengan sangat baik.
Kelebihan dan kekurangan perpustakaan
Seperti disebutkan, Guzzle adalah perpustakaan untuk membuat permintaan. Meskipun dapat memperoleh kode seluruh halaman, ia tidak dapat memproses dan mengekstrak data yang diperlukan. Namun, daftar kami juga menyertakan perpustakaan yang bagus untuk parsing tetapi tidak dapat melakukan kueri. Oleh karena itu, Guzzle sangat penting untuk mengikis.
Contoh aplikasi
Mari buat file baru dengan ekstensi *.php dan impor perpustakaan kita. Kami telah menggunakan perintah ini ketika kami menginstal perpustakaan web scraping PHP.
<?php
require 'vendor/autoload.php';
// Here will be code
?>Sekarang kita dapat membuat klien Guzzle.
use GuzzleHttp\Client;
$client = new Client();Namun, banyak orang mengalami masalah dengan sertifikat SSL. Jika Anda bekerja di lingkungan pengembangan lokal, Anda dapat menonaktifkan sementara verifikasi sertifikat SSL untuk melanjutkan pekerjaan Anda. Hal ini tidak disarankan dalam lingkungan produksi, namun dapat menjadi solusi sementara untuk tujuan pengembangan dan pengujian.
$client = new Client(('verify' => false));Sekarang tentukan URL halaman yang ingin kita scrap.
$url="https://demo.opencart.com/";Sekarang yang harus kita lakukan adalah mengirimkan permintaan ke website target dan menampilkan hasilnya di layar. Namun, kesalahan sering terjadi pada tahap ini, jadi kami menggabungkan blok kode ini dalam pernyataan try…catch() untuk menyelesaikan kemungkinan masalah tanpa menghentikan skrip.
try {
$response = $client->request('GET', $url);
$body = $response->getBody()->getContents();
echo $body;
} catch (Exception $e) {
echo 'Error: ' . $e->getMessage();Kita dapat mengambil data dari halaman ini menggunakan ekspresi reguler, namun cara ini tidak akan mudah karena kita memerlukan data dalam jumlah besar. Kode lengkap:
<?php
require 'vendor/autoload.php';
use GuzzleHttp\Client;
$client = new Client(('verify' => false));
$url="https://demo.opencart.com/";
try {
$response = $client->request('GET', $url);
$body = $response->getBody()->getContents();
echo $body;
} catch (Exception $e) {
echo 'Error: ' . $e->getMessage();
}
?>Sekarang mari kita beralih ke perpustakaan berikutnya.
HTTP penuh
HTTPful adalah pustaka kueri lain yang fungsional dan berguna. Ini mendukung semua permintaan termasuk POST, GET, DELETE dan PUT.
Kelebihan dan kekurangan perpustakaan
Perpustakaannya sederhana dan mudah digunakan, tetapi memiliki komunitas yang lebih kecil daripada Guzzle. Sayangnya, fungsinya kurang dan kurang populer meskipun sederhana. Apalagi sudah lama tidak diupdate sehingga mungkin ada masalah saat menggunakannya.
Contoh aplikasi
Karena ini adalah pustaka kueri, kami akan memberikan contoh kecil tentang cara melakukan kueri, karena kami harus menggunakan pustaka lain untuk menguraikannya:
<?php
require 'vendor/autoload.php';
use Httpful\Request;
$response = Request::get('https://demo.opencart.com/')->send();
$html = $response->body;
?>Jadi Anda dapat menggunakannya dalam proyek scraping Anda, tapi kami menyarankan Anda menggunakan yang lain.
simfoni
Symfony adalah framework yang berisi banyak komponen untuk scraping. Ini mendukung berbagai cara untuk memproses dokumen HTML dan mengeksekusi kueri.
Kelebihan dan kekurangan perpustakaan
Symfony memungkinkan Anda mengekstrak data arbitrer dari struktur HTML dan menggunakan pemilih CSS dan XPath. Terlepas dari ukuran halamannya, pemrosesannya cukup cepat.
Meskipun Symfony dapat digunakan sebagai alat pengikis yang berdiri sendiri, ini adalah kerangka kerja yang sangat besar dan berat. Oleh karena itu, merupakan praktik umum untuk tidak menggunakan keseluruhan kerangka kerja, namun hanya komponen tertentu saja.
Contoh aplikasi
Jadi mari kita gunakan crawler untuk memproses halaman dan perpustakaan Guzzle yang telah dibahas sebelumnya untuk membuat permintaan. Kami tidak akan membahasnya lagi dan melihat cara membuat klien dan menjalankan kueri.
Tambahkan "use" yang mengatakan kita akan menggunakan crawler perpustakaan Symfony.
use Symfony\Component\DomCrawler\Crawler;Selanjutnya, perbaiki kode yang kita tulis di blok try{…}. Kami akan memproses permintaan dan mengambil semua elemen dengan kelas “.col”.
$body = $response->getBody()->getContents();
$crawler->addHtmlContent($body);
$elements = $crawler->filter('.col');Sekarang yang harus kita lakukan adalah memeriksa setiap item yang dikumpulkan dan memilih informasi yang kita inginkan. Untuk melakukan ini, kami menggunakan XPath dari elemen yang kami perhitungkan saat menganalisis halaman.
Namun, Anda mungkin memperhatikan bahwa tidak semua barang memiliki harga lama. Karena item dengan kelas ".price-old" mungkin tidak ada, kami menampilkannya di skrip dan menggunakan "-" sebagai pengganti harga.
foreach ($elements as $element) {
$image = $crawler->filterXPath('.//img', $element)->attr('src');
$title = $crawler->filterXPath('.//h4', $element)->text();
$link = $crawler->filterXPath('.//h4/a', $element)->attr('href');
$desc = $crawler->filterXPath('.//p', $element)->text();
$old_p_element = $crawler->filterXPath('.//span.price-old', $element);
$old_p = $old_p_element->count() ? $old_p_element->text() : '-';
$new_p = $crawler->filterXPath('.//span.price-new', $element)->text();
$tax = $crawler->filterXPath('.//span.price-tax', $element)->text();
// Here will be code
}Dan terakhir kita tinggal menampilkan semua data yang dikumpulkan di layar:
echo 'Image: ' . $image . "\n";
echo 'Title: ' . $title . "\n";
echo 'Link: ' . $link . "\n";
echo 'Description: ' . $desc . "\n";
echo 'Old Price: ' . $old_p . "\n";
echo 'New Price: ' . $new_p . "\n";
echo 'Tax: ' . $tax . "\n";
echo "\n";Jadi kami memasukkan semua data ke konsol:
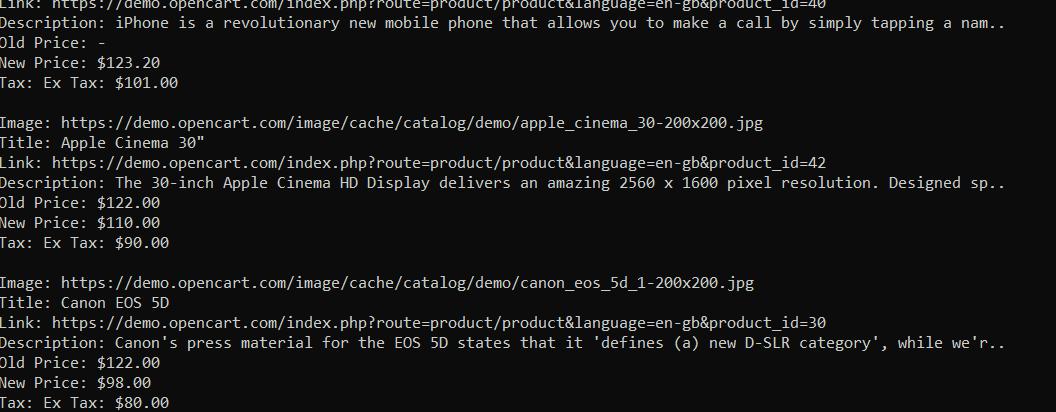
Jika Anda tertarik dengan kode terakhir atau tersesat selama tutorial, Anda dapat menemukan skrip lengkapnya di sini:
<?php
require 'vendor/autoload.php';
use GuzzleHttp\Client;
use Symfony\Component\DomCrawler\Crawler;
$client = new Client((
'verify' => false
));
$crawler = new Crawler();
$url="https://demo.opencart.com/";
try {
$response = $client->request('GET', $url);
$body = $response->getBody()->getContents();
$crawler->addHtmlContent($body);
$elements = $crawler->filter('.col');
foreach ($elements as $element) {
$image = $crawler->filterXPath('.//img', $element)->attr('src');
$title = $crawler->filterXPath('.//h4', $element)->text();
$link = $crawler->filterXPath('.//h4/a', $element)->attr('href');
$desc = $crawler->filterXPath('.//p', $element)->text();
$old_p_element = $crawler->filterXPath('.//span.price-old', $element);
$old_p = $old_p_element->count() ? $old_p_element->text() : '-';
$new_p = $crawler->filterXPath('.//span.price-new', $element)->text();
$tax = $crawler->filterXPath('.//span.price-tax', $element)->text();
echo 'Image: ' . $image . "\n";
echo 'Title: ' . $title . "\n";
echo 'Link: ' . $link . "\n";
echo 'Description: ' . $desc . "\n";
echo 'Old Price: ' . $old_p . "\n";
echo 'New Price: ' . $new_p . "\n";
echo 'Tax: ' . $tax . "\n";
echo "\n";
}
} catch (Exception $e) {
echo 'Error: ' . $e->getMessage();
}
?>Jika Anda hanya ingin menggunakan framework Symfony, Anda dapat menggunakan komponen Panther-nya. Kami tidak akan membahas penggunaan Panther selangkah demi selangkah, tetapi akan memberi Anda contoh yang menyediakan data yang sama:
<?php
require 'vendor/autoload.php';
use Symfony\Component\Panther\Panther;
$client = Panther::createChromeClient();
$crawler = $client->request('GET', 'https://demo.opencart.com/');
$elements = $crawler->filter('.col');
$elements->each(function ($element) {
$image = $element->filter('img')->attr('src');
$title = $element->filter('h4')->text();
$link = $element->filter('h4 > a')->attr('href');
$desc = $element->filter('p')->text();
$old_p_element = $element->filter('span.price-old');
$old_p = $old_p_element->count() > 0 ? $old_p_element->text() : '-';
$new_p = $element->filter('span.price-new')->text();
$tax = $element->filter('span.price-tax')->text();
echo 'Image: ' . $image . "\n";
echo 'Title: ' . $title . "\n";
echo 'Link: ' . $link . "\n";
echo 'Description: ' . $desc . "\n";
echo 'Old Price: ' . $old_p . "\n";
echo 'New Price: ' . $new_p . "\n";
echo 'Tax: ' . $tax . "\n";
echo "\n";
});
$client->quit();
?> Sekarang mari kita beralih ke perpustakaan yang dapat menggantikan dua hal yang dibahas.
Asam urat
Goutte adalah perpustakaan PHP yang menyediakan cara mudah untuk mengikis situs web. Ini didasarkan pada komponen Symfony seperti DomCrawler dan BrowserKit dan menggunakan Guzzle sebagai klien HTTP. Oleh karena itu, menggabungkan keunggulan kedua perpustakaan ini.
Kelebihan dan kekurangan perpustakaan
Goutte memiliki fungsi sederhana yang membuat pengikisan situs web menjadi mudah bagi pemula. Ini juga mendukung penyeleksi CSS dan XPath.
Meskipun Goutte adalah perpustakaan yang kuat dan nyaman untuk web scraping di PHP, ia memiliki beberapa keterbatasan dan kekurangan. Itu tidak memiliki dukungan bawaan untuk menjalankan JavaScript di halaman. Jika laman landas sangat bergantung pada JavaScript untuk menampilkan atau memuat data, Goutte mungkin bukan pilihan terbaik.
Contoh aplikasi
Mengingat perpustakaan Guotte didasarkan pada Guzzle dan Symfony, penggunaannya konsisten dengan apa yang telah kita bahas. Di sini juga kami menggunakan metode seperti filter() dan attr() atau text() untuk mengekstrak data yang diperlukan, seperti gambar, judul, atau tautan:
<?php
require 'vendor/autoload.php';
$guzzleClient = new \GuzzleHttp\Client((
'verify' => false
));
$client = new \Goutte\Client();
$client->setClient($guzzleClient);
try {
$crawler = $client->request('GET', 'https://demo.opencart.com/');
$elements = $crawler->filter('.col');
$elements->each(function ($element) {
$image = $element->filter('img')->attr('src');
$title = $element->filter('h4')->text();
$link = $element->filter('h4 > a')->attr('href');
$desc = $element->filter('p')->text();
$old_p_element = $element->filter('span.price-old');
$old_p = $old_p_element->count() ? $old_p_element->text() : '-';
$new_p = $element->filter('span.price-new')->text();
$tax = $element->filter('span.price-tax')->text();
echo 'Image: ' . $image . "\n";
echo 'Title: ' . $title . "\n";
echo 'Link: ' . $link . "\n";
echo 'Description: ' . $desc . "\n";
echo 'Old Price: ' . $old_p . "\n";
echo 'New Price: ' . $new_p . "\n";
echo 'Tax: ' . $tax . "\n";
echo "\n";
});
} catch (Exception $e) {
echo 'Error: ' . $e->getMessage();
}
?>Jadi kami mendapat data yang sama tetapi dengan perpustakaan berbeda:
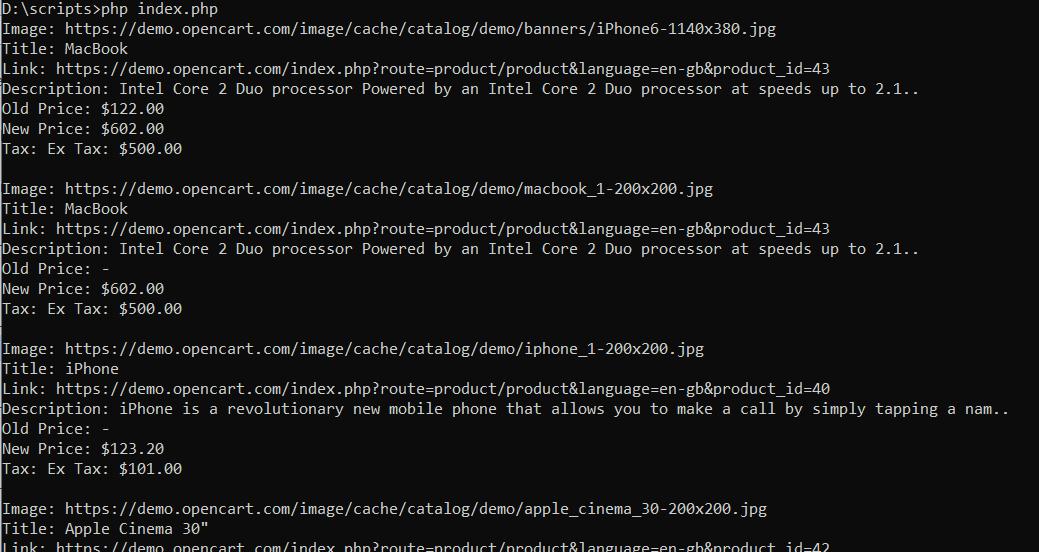
Seperti yang Anda lihat, Goutte adalah pustaka web scraping PHP yang cukup berguna.
Scrape-It.Cloud API
Scrape-It.Cloud API adalah antarmuka khusus yang kami kembangkan untuk menyederhanakan proses pengikisan. Saat mengumpulkan data, pengembang sering kali menghadapi beberapa tantangan seperti: Misalnya rendering JavaScript, captcha, pemblokiran, dll. Namun, dengan menggunakan API kami, Anda dapat mengatasi masalah ini dan fokus pada pemrosesan data yang telah Anda terima.
Kelebihan dan kekurangan perpustakaan
Seperti disebutkan sebelumnya, API web scraping kami akan membantu Anda menghindari banyak tantangan saat mengembangkan scraper Anda. Selain itu, Anda menghemat uang. Kami telah membahas 10 penyedia proxy teratas dan membandingkan biaya pembelian proxy bergilir dan langganan kami.
Selain itu, jika Anda memerlukan data dan tidak ingin mengembangkan scraper, Anda dapat menggunakan scraper tanpa kode kami untuk situs web paling populer. Jika Anda ragu dan ingin mencobanya, daftar di situs web kami dan dapatkan kredit gratis sebagai bagian dari uji coba.
Contoh aplikasi
Untuk menggunakan API kita perlu membuat permintaan. Kami akan menggunakan perpustakaan Guzzle yang telah kami bahas. Mari kita sambungkan dan atur tautan API.
require 'vendor/autoload.php';
use GuzzleHttp\Client;
$apiUrl="https://api.scrape-it.cloud/scrape";Sekarang kita perlu membuat permintaan dengan dua bagian – header permintaan dan isi permintaan. Pertama, atur headernya:
$headers = (
'x-api-key' => 'YOUR-API-KEY',
'Content-Type' => 'application/json',
);Anda harus mengganti “KUNCI API ANDA” dengan kunci unik Anda, yang dapat Anda temukan di akun Anda setelah masuk ke situs web kami.
Kemudian kita perlu menyetel isi permintaan untuk memberi tahu API data apa yang kita perlukan. Di sini Anda dapat menentukan aturan ekstraksi data, proksi dan jenis proksi yang ingin Anda gunakan, skrip yang akan diekstraksi, tautan ke sumber daya, dan banyak lagi. Untuk daftar parameter lengkap, lihat dokumentasi kami.
$data = (
'extract_rules' => (
'Image' => 'img @src',
'Title' => 'h4',
'Link' => 'h4 > a @href',
'Description' => 'p',
'Old Price' => 'span.price-old',
'New Price' => 'span.price-new',
'Tax' => 'span.price-tax',
),
'wait' => 0,
'screenshot' => true,
'block_resources' => false,
'url' => 'https://demo.opencart.com/',
);Kami menggunakan aturan ekstraksi untuk mendapatkan data yang kami inginkan saja. API mengembalikan respons dalam format JSON, yang memungkinkan kita mengekstrak hanya aturan ekstraksi dari respons.
$data = json_decode($response->getBody(), true);
if ($data('status') === 'ok') {
$extractionData = $data('scrapingResult')('extractedData');
foreach ($extractionData as $key => $value) {
echo $key . ": " . json_encode($value) . "\n\n";
}
} else {
echo "An error occurred: " . $data('message');
}Kami mendapatkan informasi yang kami inginkan dengan menjalankan skrip yang kami buat. Bagian terbaiknya adalah skrip ini berfungsi apa pun situs web yang ingin Anda jelajahi. Yang perlu Anda lakukan hanyalah mengubah aturan ekstraksi dan memberikan tautan ke sumber daya target.
Kode lengkap:
<?php
require 'vendor/autoload.php';
use GuzzleHttp\Client;
$apiUrl="https://api.scrape-it.cloud/scrape";
$headers = (
'x-api-key' => 'YOUR-API-KEY',
'Content-Type' => 'application/json',
);
$data = (
'extract_rules' => (
'Image' => 'img @src',
'Title' => 'h4',
'Link' => 'h4 > a @href',
'Description' => 'p',
'Old Price' => 'span.price-old',
'New Price' => 'span.price-new',
'Tax' => 'span.price-tax',
),
'wait' => 0,
'screenshot' => true,
'block_resources' => false,
'url' => 'https://demo.opencart.com/',
);
$client = new Client(('verify' => false));
$response = $client->post($apiUrl, (
'headers' => $headers,
'json' => $data,
));
$data = json_decode($response->getBody(), true);
if ($data('status') === 'ok') {
$extractionData = $data('scrapingResult')('extractedData');
foreach ($extractionData as $key => $value) {
echo $key . ": " . json_encode($value) . "\n\n";
}
} else {
echo "An error occurred: " . $data('message');
}
?>Hasilnya adalah:
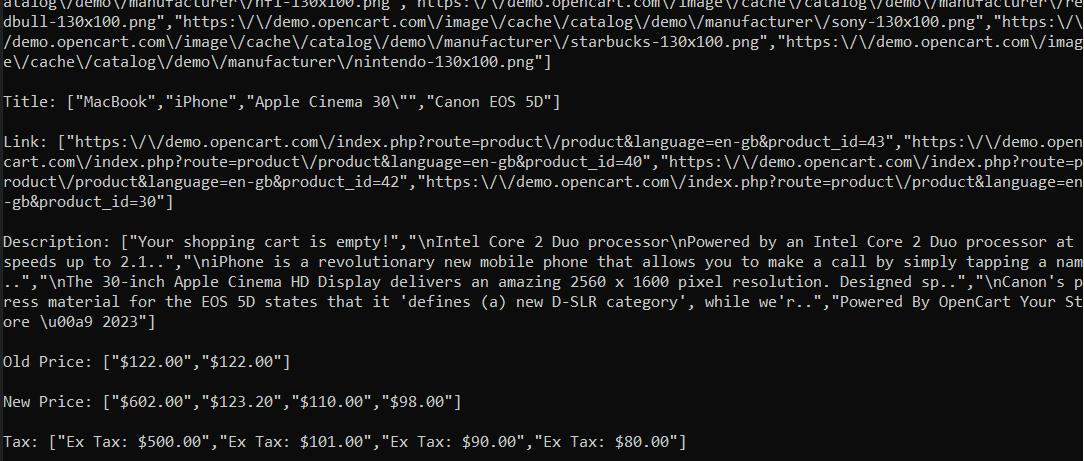
Dengan API pengikisan web kami, Anda bisa mendapatkan hasil dari situs web mana pun, terlepas dari apakah situs tersebut dapat diakses di negara Anda atau kontennya dibuat secara dinamis.
DOM HTML sederhana
Pustaka DOM HTML sederhana adalah salah satu pustaka PHP DOM yang paling sederhana. Ini bagus untuk pemula, memiliki perpustakaan scraping yang lengkap, dan sangat mudah digunakan.
Kelebihan dan kekurangan perpustakaan
Pustaka ini sangat mudah digunakan dan sempurna untuk menggores halaman sederhana. Namun, Anda tidak dapat mengumpulkan data dari halaman yang dibuat secara dinamis. Selain itu, perpustakaan ini hanya mengizinkan penggunaan pemilih CSS dan tidak mendukung XPath.
Contoh aplikasi
Mari kita lihat dengan contoh bahwa ini sangat mudah digunakan. Pertama, sambungkan dependensi dan tentukan situs tempat kita ingin mengekstrak data.
require 'vendor/autoload.php';
use Sunra\PhpSimple\HtmlDomParser;
$html = HtmlDomParser::file_get_html('https://demo.opencart.com/');Sekarang temukan semua produk menggunakan fungsi find() dan pemilih CSS.
$elements = $html->find('.col');Sekarang mari kita periksa semua item yang dikumpulkan dan pilih data yang kita butuhkan. Kita harus menentukan apa yang ingin kita ekstrak. Kita perlu menentukan nama atribut jika itu adalah nilai atribut. Jika kita ingin mengekstrak konten teks dari sebuah tag, kita menggunakan “Plaintext”. Seperti sebelumnya, mari kita langsung menampilkan teks di layar.
foreach ($elements as $element) {
$image = $element->find('img', 0)->src;
$title = $element->find('h4', 0)->plaintext;
$link = $element->find('h4 > a', 0)->href;
$desc = $element->find('p', 0)->plaintext;
$old_p_element = $element->find('span.price-old', 0);
$old_p = $old_p_element ? $old_p_element->plaintext : '-';
$new_p = $element->find('span.price-new', 0)->plaintext;
$tax = $element->find('span.price-tax', 0)->plaintext;
echo 'Image: ' . $image . "\n";
echo 'Title: ' . $title . "\n";
echo 'Link: ' . $link . "\n";
echo 'Description: ' . $desc . "\n";
echo 'Old Price: ' . $old_p . "\n";
echo 'New Price: ' . $new_p . "\n";
echo 'Tax: ' . $tax . "\n";
echo "\n";
}Setelah itu, yang harus kita lakukan hanyalah melepaskan sumber daya dan keluar dari skrip.
$html->clear();Kode lengkap:
<?php
require 'vendor/autoload.php';
use Sunra\PhpSimple\HtmlDomParser;
$html = HtmlDomParser::file_get_html('https://demo.opencart.com/');
$elements = $html->find('.col');
foreach ($elements as $element) {
$image = $element->find('img', 0)->src;
$title = $element->find('h4', 0)->plaintext;
$link = $element->find('h4 > a', 0)->href;
$desc = $element->find('p', 0)->plaintext;
$old_p_element = $element->find('span.price-old', 0);
$old_p = $old_p_element ? $old_p_element->plaintext : '-';
$new_p = $element->find('span.price-new', 0)->plaintext;
$tax = $element->find('span.price-tax', 0)->plaintext;
echo 'Image: ' . $image . "\n";
echo 'Title: ' . $title . "\n";
echo 'Link: ' . $link . "\n";
echo 'Description: ' . $desc . "\n";
echo 'Old Price: ' . $old_p . "\n";
echo 'New Price: ' . $new_p . "\n";
echo 'Tax: ' . $tax . "\n";
echo "\n";
}
$html->clear();
?>Hasilnya datanya sama seperti contoh sebelumnya, namun hanya berupa beberapa baris kode saja.
selenium
Kami sudah sering menulis tentang Selenium di koleksi bahasa pemrograman lain seperti Python, R, Ruby dan C#. Kami ingin meninjau perpustakaan ini lagi karena sangat nyaman. Ini memiliki dokumentasi yang ditulis dengan baik dan komunitas aktif yang mendukungnya.
Kelebihan dan kekurangan perpustakaan
Perpustakaan ini memiliki banyak kelebihan dan sedikit kekurangan. Ini memiliki dukungan komunitas yang sangat baik, dokumentasi yang luas, dan pengembangan serta peningkatan yang konstan.
Selenium memungkinkan Anda menggunakan browser tanpa kepala untuk mensimulasikan perilaku pengguna sebenarnya. Artinya, Anda dapat mengurangi risiko deteksi saat melakukan pengikisan. Selain itu, Anda dapat berinteraksi dengan elemen di halaman web, seperti mengisi formulir atau mengklik tombol.
Adapun kekurangannya, PHP tidak sepopuler NodeJS atau Python dan dapat menjadi tantangan bagi pemula.
Contoh aplikasi
Sekarang mari kita lihat contoh penggunaan Selenium. Agar dapat berfungsi, kita memerlukan driver web. Kami akan menggunakan driver web Chrome. Pastikan cocok dengan versi browser Chrome yang terpasang di komputer Anda. Ekstrak driver web ke drive C Anda.
Anda dapat menggunakan driver web apa pun. Misalnya, Anda dapat memilih Mozilla Firefox atau browser lain yang didukung Selenium.
Pertama, tambahkan dependensi yang diperlukan ke proyek kita.
require 'vendor/autoload.php';
use Facebook\WebDriver\Remote\DesiredCapabilities;
use Facebook\WebDriver\Remote\RemoteWebDriver;
use Facebook\WebDriver\WebDriverBy;Sekarang mari kita tentukan parameter host tempat driver web kita berjalan. Untuk melakukan ini, jalankan file driver web dan periksa port mana yang memulainya.
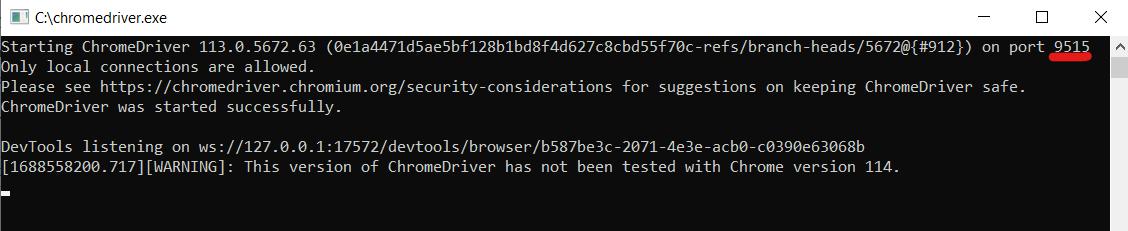
Tentukan parameter berikut dalam skrip:
$host="http://localhost:9515"; Selanjutnya kita perlu meluncurkan browser dan menuju ke sumber daya target.
$capabilities = DesiredCapabilities::chrome();
$driver = RemoteWebDriver::create($host, $capabilities);
$driver->get('https://demo.opencart.com/');Sekarang kita perlu mencari produk di situs web, menelusurinya dan mendapatkan data yang kita inginkan. Setelah itu kita harus menampilkan data di layar. Karena kami telah melakukan ini pada contoh sebelumnya, kami tidak akan membahas langkah ini secara detail.
$elements = $driver->findElements(WebDriverBy::cssSelector('.col'));
foreach ($elements as $element) {
$image = $element->findElement(WebDriverBy::tagName('img'))->getAttribute('src');
$title = $element->findElement(WebDriverBy::tagName('h4'))->getText();
$link = $element->findElement(WebDriverBy::cssSelector('h4 > a'))->getAttribute('href');
$desc = $element->findElement(WebDriverBy::tagName('p'))->getText();
$old_p_element = $element->findElement(WebDriverBy::cssSelector('span.price-old'));
$old_p = $old_p_element ? $old_p_element->getText() : '-';
$new_p = $element->findElement(WebDriverBy::cssSelector('span.price-new'))->getText();
$tax = $element->findElement(WebDriverBy::cssSelector('span.price-tax'))->getText();
echo 'Image: ' . $image . "\n";
echo 'Title: ' . $title . "\n";
echo 'Link: ' . $link . "\n";
echo 'Description: ' . $desc . "\n";
echo 'Old Price: ' . $old_p . "\n";
echo 'New Price: ' . $new_p . "\n";
echo 'Tax: ' . $tax . "\n";
echo "\n";
}Selenium menawarkan banyak cara untuk menemukan elemen berbeda pada halaman. Dalam tutorial ini kami menggunakan pencarian pemilih CSS dan pencarian tag.
Pada akhirnya Anda harus menutup browser.
$driver->quit();Saat kami menjalankan skrip, skrip akan memulai browser, menavigasi ke halaman, dan menutupnya setelah mengumpulkan data.
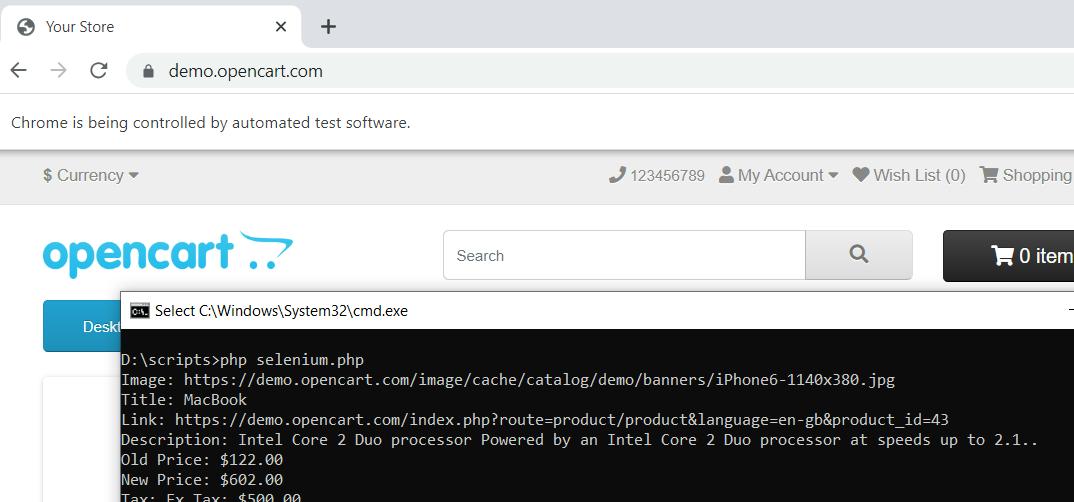
Jika Anda bingung dan ada yang terlewat, berikut kode script lengkapnya:
<?php
require 'vendor/autoload.php';
use Facebook\WebDriver\Remote\DesiredCapabilities;
use Facebook\WebDriver\Remote\RemoteWebDriver;
use Facebook\WebDriver\WebDriverBy;
$host="http://localhost:9515";
$capabilities = DesiredCapabilities::chrome();
$driver = RemoteWebDriver::create($host, $capabilities);
$driver->get('https://demo.opencart.com/');
$elements = $driver->findElements(WebDriverBy::cssSelector('.col'));
foreach ($elements as $element) {
$image = $element->findElement(WebDriverBy::tagName('img'))->getAttribute('src');
$title = $element->findElement(WebDriverBy::tagName('h4'))->getText();
$link = $element->findElement(WebDriverBy::cssSelector('h4 > a'))->getAttribute('href');
$desc = $element->findElement(WebDriverBy::tagName('p'))->getText();
$old_p_element = $element->findElement(WebDriverBy::cssSelector('span.price-old'));
$old_p = $old_p_element ? $old_p_element->getText() : '-';
$new_p = $element->findElement(WebDriverBy::cssSelector('span.price-new'))->getText();
$tax = $element->findElement(WebDriverBy::cssSelector('span.price-tax'))->getText();
echo 'Image: ' . $image . "\n";
echo 'Title: ' . $title . "\n";
echo 'Link: ' . $link . "\n";
echo 'Description: ' . $desc . "\n";
echo 'Old Price: ' . $old_p . "\n";
echo 'New Price: ' . $new_p . "\n";
echo 'Tax: ' . $tax . "\n";
echo "\n";
}
$driver->quit();
?>Seperti yang Anda lihat, Selenium di PHP cukup nyaman, tetapi sedikit lebih rumit dibandingkan perpustakaan lainnya.
Jalur kueri
QueryPath adalah perpustakaan untuk mengekstraksi data dari halaman HTML, memfilter dan memproses elemen.
Kelebihan dan kekurangan perpustakaan
Pustaka QueryPath sangat mudah digunakan, menjadikannya pilihan yang baik untuk pemula. Ini juga mendukung sintaks mirip jQuery untuk penguraian dan pemrosesan HTML/XML. Namun, fungsinya terbatas dibandingkan dengan beberapa perpustakaan lain.
Contoh aplikasi
Ini memiliki perintah pencarian yang mirip dengan perpustakaan yang dibahas sebelumnya. Berkat kesederhanaannya, kita hanya perlu melakukan request ke website dan mengolah data yang diterima. Oleh karena itu, kami tidak akan mengulangi langkah-langkah yang telah dibahas dan memberikan contoh lengkap penggunaan perpustakaan:
<?php
require 'vendor/autoload.php';
use QueryPath\Query;
$html = file_get_contents('https://demo.opencart.com/');
$qp = Query::withHTML($html);
$elements = $qp->find('.col');
foreach ($elements as $element) {
$image = $element->find('img')->attr('src');
$title = $element->find('h4')->text();
$link = $element->find('h4 > a')->attr('href');
$desc = $element->find('p')->text();
$old_p_element = $element->find('span.price-old')->get(0);
$old_p = $old_p_element ? $old_p_element->text() : '-';
$new_p = $element->find('span.price-new')->text();
$tax = $element->find('span.price-tax')->text();
echo 'Image: ' . $image . "\n";
echo 'Title: ' . $title . "\n";
echo 'Link: ' . $link . "\n";
echo 'Description: ' . $desc . "\n";
echo 'Old Price: ' . $old_p . "\n";
echo 'New Price: ' . $new_p . "\n";
echo 'Tax: ' . $tax . "\n";
echo "\n";
}
$qp->unload();
?>Jadi seperti yang Anda lihat, hanya ada sedikit perbedaan dari perpustakaan yang telah dibahas.
Daftar kueri
Berikutnya dalam daftar kami adalah perpustakaan QueryList. Ini memiliki lebih banyak fungsi daripada perpustakaan sebelumnya. Dapat juga dikatakan bahwa prinsip penggunaannya sedikit berbeda dengan perpustakaan yang telah dibahas.
Kelebihan dan kekurangan perpustakaan
QueryList adalah alat yang kuat dan fleksibel untuk mengekstraksi dan memproses data dari HTML/XML. Namun, ini bisa menjadi rumit bagi pemula karena banyaknya fungsi dan fitur.
Contoh aplikasi
Pertama-tama sambungkan dependensi dan tanyakan situs target.
require 'vendor/autoload.php';
use QL\QueryList;
$html = QueryList::get('https://demo.opencart.com/')->getHtml();Kemudian parsing kode HTML halaman tersebut.
$ql = QueryList::html($html);Mari kita proses semua data yang kita miliki untuk mengekstrak informasi yang kita inginkan. Kami kemudian membuat bingkai data dan menyimpan data di dalamnya.
$elements = $ql->find('.col')->map(function ($item) {
$image = $item->find('img')->attr('src');
$title = $item->find('h4')->text();
$link = $item->find('h4 > a')->attr('href');
$desc = $item->find('p')->text();
$old_p = $item->find('span.price-old')->text() ?: '-';
$new_p = $item->find('span.price-new')->text();
$tax = $item->find('span.price-tax')->text();
return (
'Image' => $image,
'Title' => $title,
'Link' => $link,
'Description' => $desc,
'Old Price' => $old_p,
'New Price' => $new_p,
'Tax' => $tax
);
});Sekarang mari kita telusuri setiap elemen dan mencetaknya di layar:
foreach ($elements as $element) {
foreach ($element as $key => $value) {
echo $key . ': ' . $value . "\n";
}
echo "\n";
}Itu saja, kami memiliki data yang kami butuhkan dan jika Anda melewatkan sesuatu, kami memberikan Anda kode lengkapnya:
<?php
require 'vendor/autoload.php';
use QL\QueryList;
$html = QueryList::get('https://demo.opencart.com/')->getHtml();
$ql = QueryList::html($html);
$elements = $ql->find('.col')->map(function ($item) {
$image = $item->find('img')->attr('src');
$title = $item->find('h4')->text();
$link = $item->find('h4 > a')->attr('href');
$desc = $item->find('p')->text();
$old_p = $item->find('span.price-old')->text() ?: '-';
$new_p = $item->find('span.price-new')->text();
$tax = $item->find('span.price-tax')->text();
return (
'Image' => $image,
'Title' => $title,
'Link' => $link,
'Description' => $desc,
'Old Price' => $old_p,
'New Price' => $new_p,
'Tax' => $tax
);
});
foreach ($elements as $element) {
foreach ($element as $key => $value) {
echo $key . ': ' . $value . "\n";
}
echo "\n";
}
?>Perpustakaan ini memiliki banyak fitur dan beragam fungsi. Namun, bagi pemula untuk menavigasinya bisa jadi cukup menantang.
DiDOM
Perpustakaan terakhir di artikel kami adalah DiDom. Ini bagus untuk mengekstraksi data dari kode HTML dan mengubahnya menjadi tampilan yang dapat digunakan.
Kelebihan dan kekurangan perpustakaan
DiDom adalah perpustakaan ringan dengan fungsi sederhana dan jelas. Ini juga memiliki kinerja yang baik. Sayangnya, perpustakaan ini kurang populer dan memiliki komunitas pendukung yang lebih kecil dibandingkan perpustakaan lain.
Contoh aplikasi
Hubungkan dependensi dan buat permintaan ke situs target:
require 'vendor/autoload.php';
use DiDom\Document;
$document = new Document('https://demo.opencart.com/', true);Temukan semua produk dengan kelas “.col”:
$elements = $document->find('.col');Mari kita bahas masing-masing, kumpulkan datanya dan tampilkan di layar:
foreach ($elements as $element) {
$image = $element->find('img', 0)->getAttribute('src');
$title = $element->find('h4', 0)->text();
$link = $element->find('h4 > a', 0)->getAttribute('href');
$desc = $element->find('p', 0)->text();
$old_p_element = $element->find('span.price-old', 0);
$old_p = $old_p_element ? $old_p_element->text() : '-';
$new_p = $element->find('span.price-new', 0)->text();
$tax = $element->find('span.price-tax', 0)->text();
echo 'Image: ' . $image . "\n";
echo 'Title: ' . $title . "\n";
echo 'Link: ' . $link . "\n";
echo 'Description: ' . $desc . "\n";
echo 'Old Price: ' . $old_p . "\n";
echo 'New Price: ' . $new_p . "\n";
echo 'Tax: ' . $tax . "\n";
echo "\n";
}Sampai di sini skrip sudah siap dan Anda dapat mengolah data sesuai keinginan. Kami juga menyertakan contoh kode lengkap:
<?php
require 'vendor/autoload.php';
use DiDom\Document;
$document = new Document('https://demo.opencart.com/', true);
$elements = $document->find('.col');
foreach ($elements as $element) {
$image = $element->find('img', 0)->getAttribute('src');
$title = $element->find('h4', 0)->text();
$link = $element->find('h4 > a', 0)->getAttribute('href');
$desc = $element->find('p', 0)->text();
$old_p_element = $element->find('span.price-old', 0);
$old_p = $old_p_element ? $old_p_element->text() : '-';
$new_p = $element->find('span.price-new', 0)->text();
$tax = $element->find('span.price-tax', 0)->text();
echo 'Image: ' . $image . "\n";
echo 'Title: ' . $title . "\n";
echo 'Link: ' . $link . "\n";
echo 'Description: ' . $desc . "\n";
echo 'Old Price: ' . $old_p . "\n";
echo 'New Price: ' . $new_p . "\n";
echo 'Tax: ' . $tax . "\n";
echo "\n";
}
?>Ini menyimpulkan koleksi perpustakaan scraping PHP terbaik kami. Saatnya memilih yang terbaik dari semua perpustakaan yang diulas.
Pustaka PHP terbaik untuk scraping
Memilih pustaka PHP web scraping terbaik bergantung pada beberapa faktor: tujuan proyek, persyaratan, dan keterampilan pemrograman Anda. Untuk membantu Anda memutuskan, kami telah mengumpulkan informasi terpenting yang dibahas dalam artikel dan membuat tabel perbandingan 10 perpustakaan scraping terbaik.
|
perpustakaan |
Keuntungan |
Kekurangan |
Mengikis data dinamis |
keramahan pengguna |
|---|---|---|---|---|
|
Makan |
|
|
TIDAK |
Diantara |
|
HTTP penuh |
|
|
TIDAK |
Pemula |
|
simfoni |
|
|
Ya |
Progresif |
|
Asam urat |
|
|
TIDAK |
Pemula |
|
Kikis-It.Cloud |
|
Ya |
Pemula |
|
|
DOM HTML sederhana |
|
|
TIDAK |
Pemula |
|
selenium |
|
|
Ya |
Diantara |
|
Jalur kueri |
|
|
TIDAK |
Diantara |
|
Daftar kueri |
|
|
Ya |
Diantara |
|
DiDom |
|
|
TIDAK |
Pemula |
Ini akan membantu Anda menemukan perpustakaan scraping PHP terbaik untuk mencapai tujuan Anda.
Kesimpulan dan temuan
Dalam artikel ini, kita melihat pengaturan lingkungan pemrograman PHP dan memeriksa cara untuk mengotomatiskan integrasi dan pembaruan perpustakaan. Kami juga telah memperkenalkan 10 perpustakaan web scraping terbaik untuk memberi Anda opsi berbeda untuk proyek scraping Anda.
Namun, jika Anda kesulitan memilih perpustakaan terbaik, kami telah membandingkan semua perpustakaan yang kami pertimbangkan. Namun, jika Anda masih belum tahu harus memilih yang mana, Anda dapat mencoba API web scraping kami. Hal ini tidak hanya menyederhanakan proses pengumpulan data, namun juga membantu mengatasi potensi tantangan. Fitur-fiturnya memungkinkan Anda mengotomatiskan tugas pengumpulan data dan mengatasi semua kesulitan.