
Yelp adalah direktori bisnis lokal yang besar dan populer seperti restoran, hotel, spa, tukang ledeng, dan hampir semua jenis bisnis yang dapat Anda temukan. Platform ini ideal untuk menemukan pelanggan potensial B2B.
Namun, mencari pihak yang berkepentingan secara manual di platform ini memakan waktu. Oleh karena itu, Anda dapat menggunakan alat web scraping untuk mengumpulkan data dari Yelp. Strategi seperti ini akan membuahkan hasil dalam jangka panjang.
Daftar Isi
Mengapa menggaruk Yelp?
Data Yelp dapat menjadi berharga dan membantu kesuksesan bisnis Anda bila digunakan dengan benar. Ada banyak manfaat mengumpulkan informasi melalui platform ini. Misalnya:
- penelitian kompetitif;
- meningkatkan pengalaman pengguna;
- validasi kampanye pemasaran;
- memantau sentimen pelanggan;
- Generasi pemimpin.
Setiap bisnis yang terdaftar di Yelp memiliki halamannya sendiri. Di halaman ini Anda akan menemukan informasi tentang nama perusahaan, nomor telepon, alamat, link website dan jam buka. Hasil pencarian bisnis disaring berdasarkan lokasi geografis, kisaran harga, dan karakteristik unik lainnya. Untuk mendapatkan data yang diperlukan, Anda dapat menggunakan Yelp API resmi atau membuat web scraper Anda sendiri.
Kami telah menyiapkan tutorial di mana kami akan membuat scraper Yelp yang dapat mengambil link ke direktori bisnis, membuka halaman bisnis mana pun, dan mengumpulkan informasi tersebut:
- nama perusahaan;
- nomor telepon;
- Alamat;
- tautan situs web;
- Evaluasi;
- jumlah ulasan.
Analisis situs web
Misalnya, kita memerlukan informasi tentang semua restoran di pusat kota Calgary. Untuk melakukan ini, kami memasukkan permintaan pencarian “restoran” dan memilih kota Calgary.
Yelp mengarahkan kami ke halaman hasil mesin pencari:
https://www.yelp.ca/search?find_desc=restaurants&find_loc=Calgary%2C+AB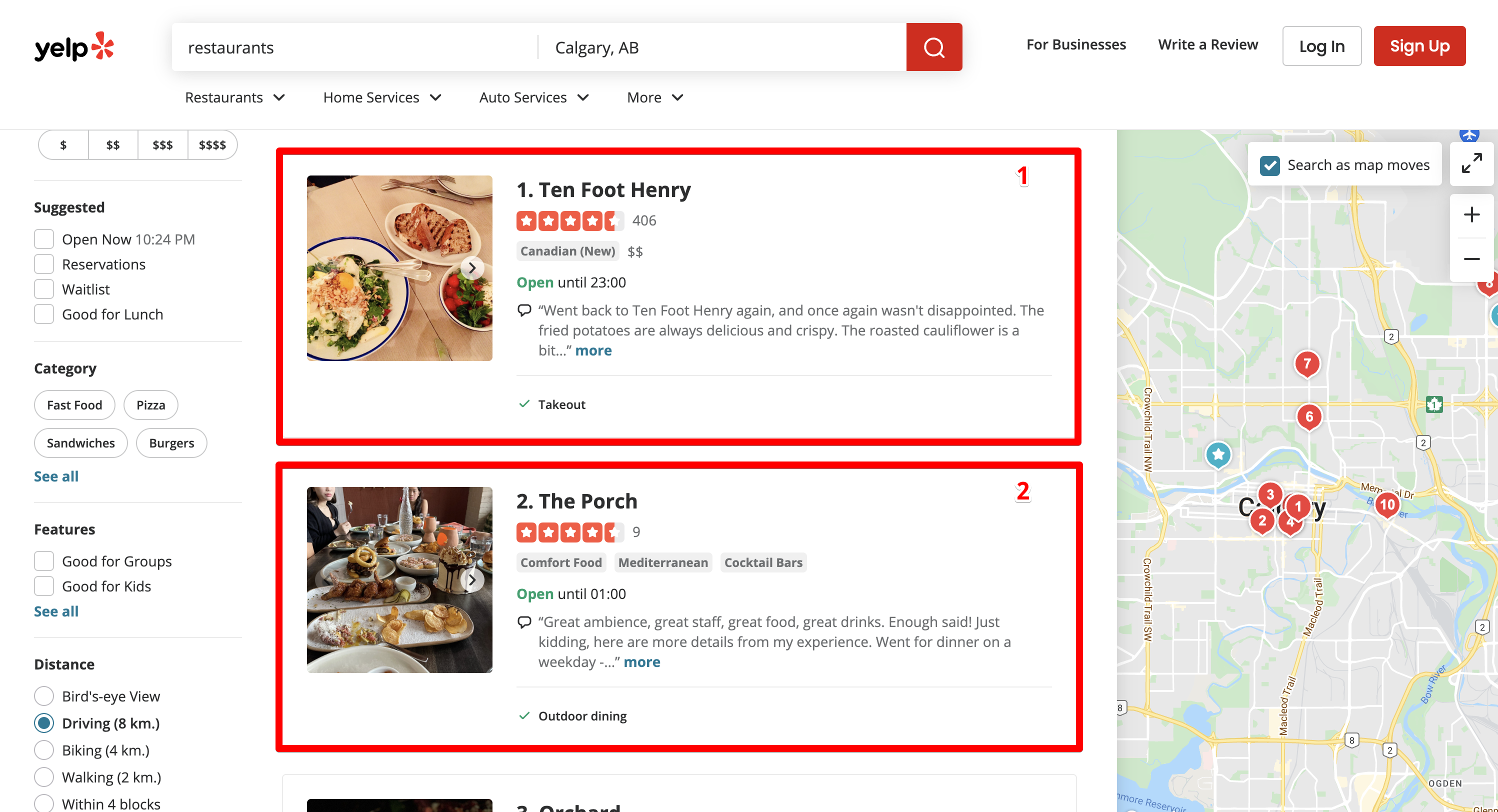
Ada 10 restoran yang terdaftar di setiap halaman. totalnya 24 halaman.
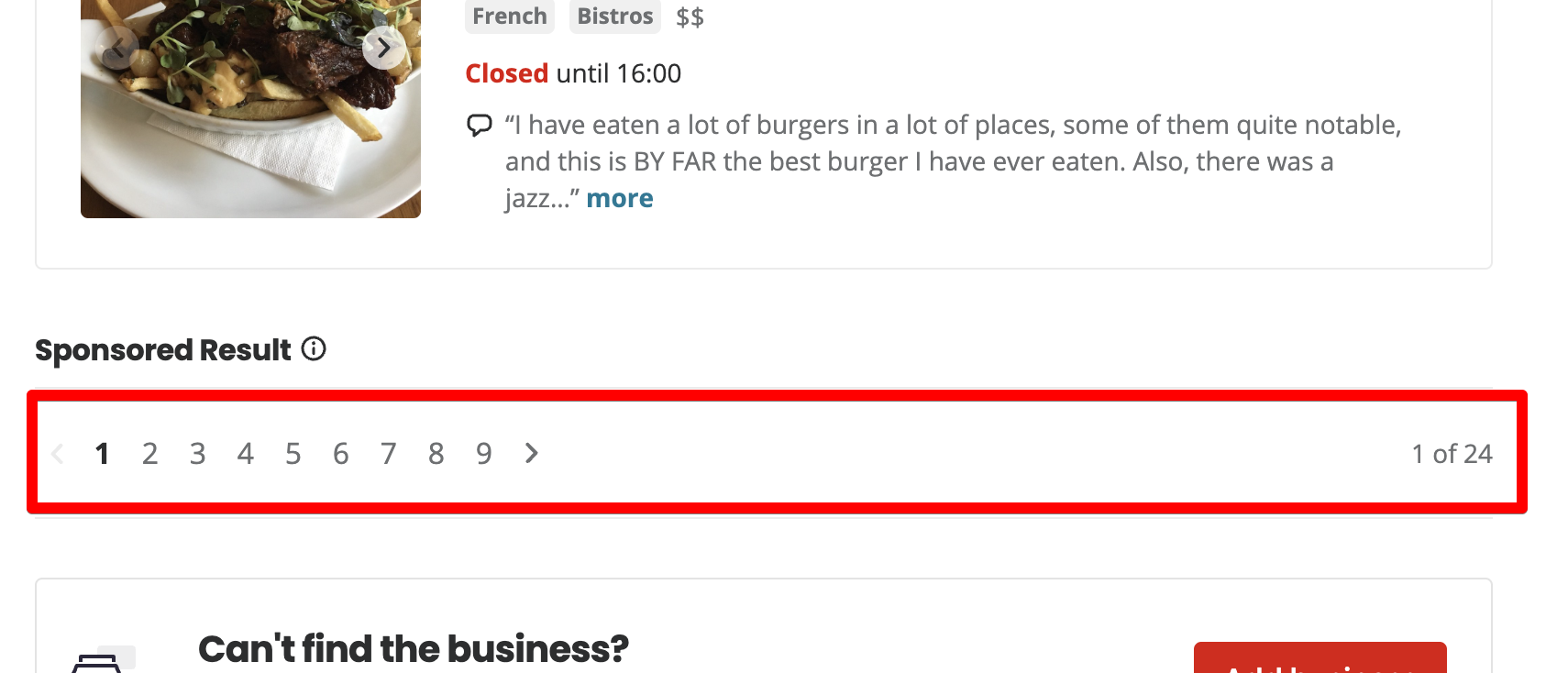
Saat Anda mengklik halaman 2, Yelp menambahkan parameter startup ke URL.
https://www.yelp.ca/search?find_desc=restaurants&find_loc=Calgary%2C+AB&start=10Saat Anda masuk ke halaman 3, nilai parameter startup berubah menjadi 20.
https://www.yelp.ca/search?find_desc=restaurants&find_loc=Calgary%2C+AB&start=20Oke, sekarang kita memahami logika cara kerja penomoran halaman di Yelp – Mulai adalah offset dari catatan nol. Jika Anda ingin menampilkan 10 entri pertama, Anda harus mengatur parameter awal ke 0. Jika Anda ingin menampilkan entri dari 11 hingga 20, maka kami mengatur parameter awal ke 10.
Halaman perusahaan
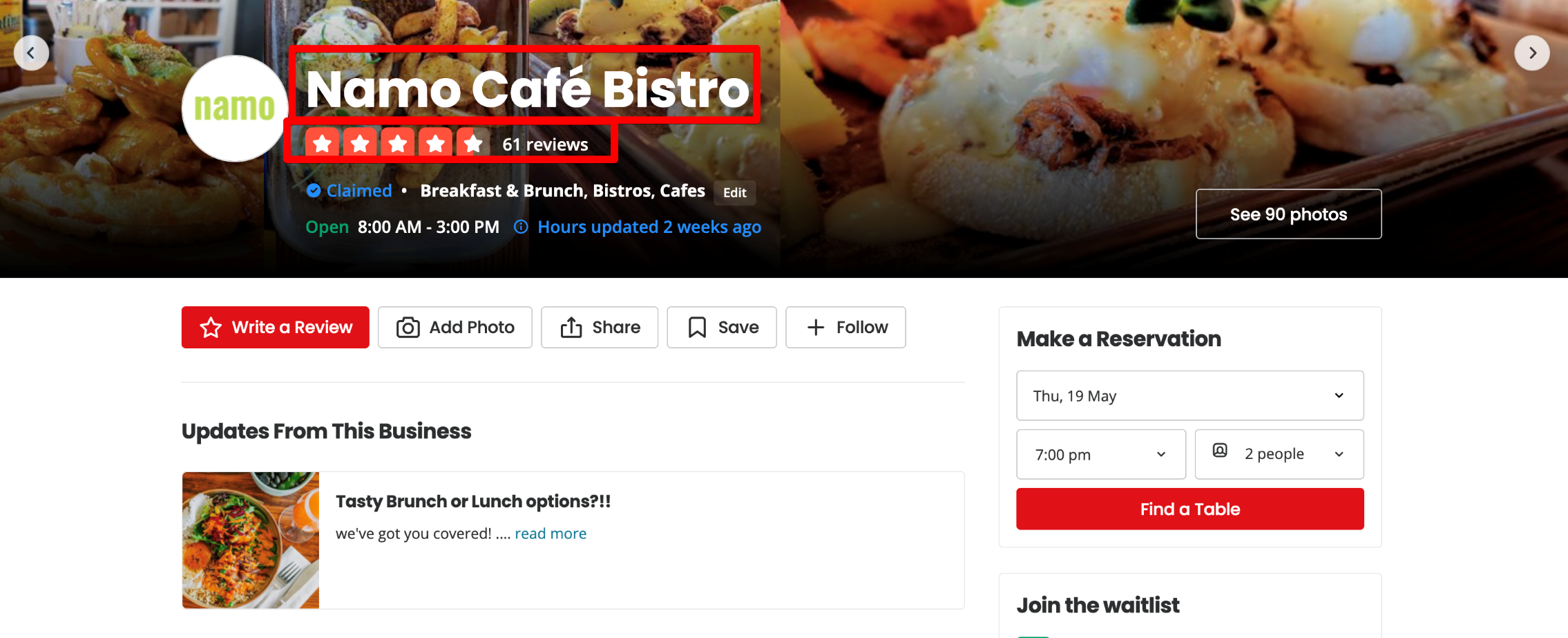
Di bagian atas halaman perusahaan, nama, peringkat, dan jumlah ulasan ditampilkan.
Gulir ke bawah halaman.
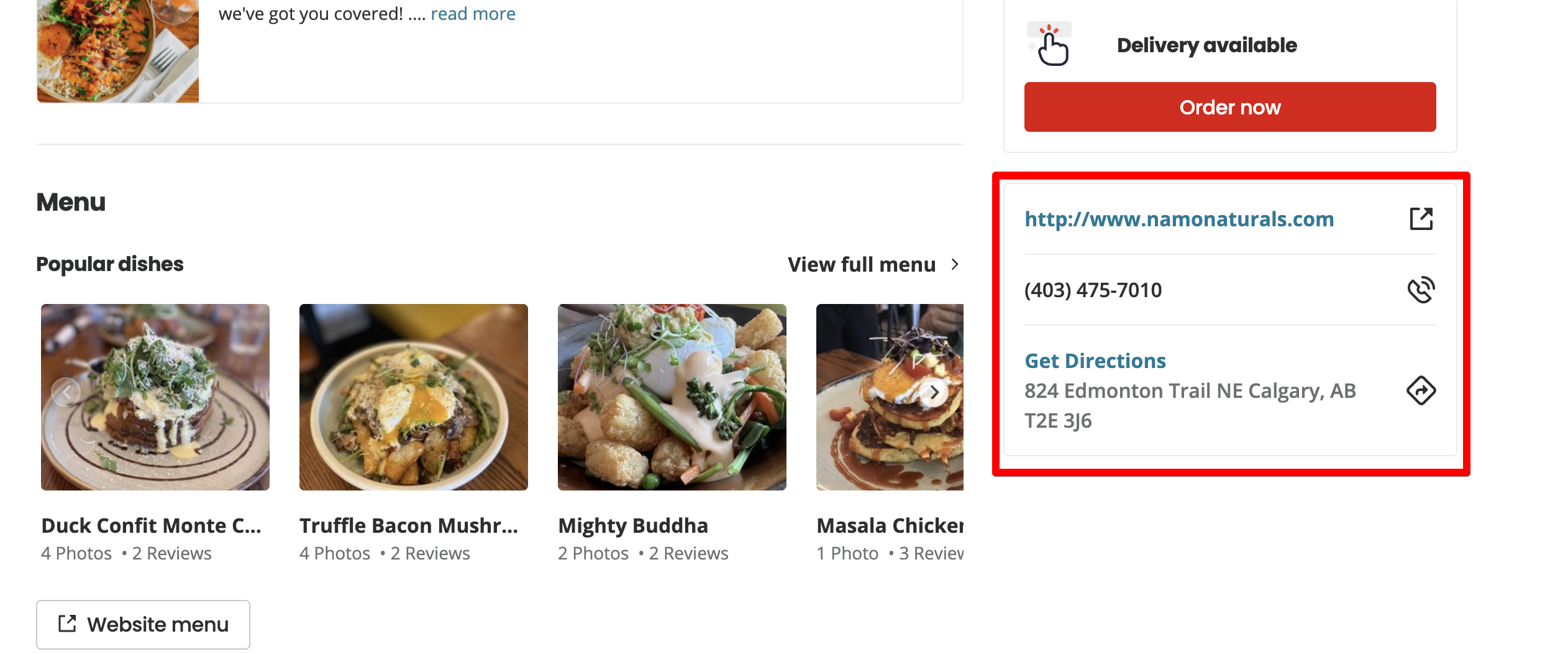
Di bagian kedua halaman kita melihat data lainnya yang kita minati: tautan situs, nomor telepon, dan alamat.
Menulis scraper NodeJS menggunakan Puppeteer
Anda dapat membuat scraper menggunakan contoh JavaScript Yelp API dari situs web resmi Yelp, tetapi ini cukup sederhana. Mari buat tugas ini lebih menantang dan buat scraper kita sendiri dengan Puppeteer.
Buat direktori untuk scraper
scrapeit@MBP-scrapeit scrapeit-cloud-samples % mkdir yelp-scraper
scrapeit@MBP-scrapeit scrapeit-cloud-samples % cd yelp-scraper
scrapeit@MBP-scrapeit yelp-scraper %Menginisialisasi proyek melalui npm
Misalnya, Anda dapat menginisialisasi proyek melalui npm:
scrapeit@MBP-scrapeit yelp-scraper % npm init
This utility will walk you through creating a package.json file.
It only covers the most common items, and tries to guess sensible defaults.
See `npm help init` for definitive documentation on these fields
and exactly what they do.
Use `npm install ` afterwards to install a package and
save it as a dependency in the package.json file.
Press ^C at any time to quit.
package name: (yelp-scraper)
version: (1.0.0)
description: Yelp business scraper
entry point: (index.js)
test command:
git repository:
keywords:
author: Roman M
license: (ISC)
About to write to /Users/scrapeit/workspace/scrapeit-cloud-samples/yelp-scraper/package.json:
{
"name": "yelp-scraper",
"version": "1.0.0",
"description": "Yelp business scraper",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "Roman M",
"license": "ISC"
}
Is this OK? (yes) yesMengatur dependensi yang kita perlukan
Kami akan menggunakan beberapa dependensi:
- Dalang – Pustaka NodeJS yang menyediakan API untuk berinteraksi dan mengontrol browser Chrome.
- Cheerio – kernel jQuery yang dirancang khusus untuk penggunaan server.
Kami akan menggunakan Dalang untuk membuka halaman Yelp dan mengambil HTML.
npm i puppeteerCheerio digunakan untuk penguraian HTML.
npm i cheerioArsitektur pengikis
Kami membuat beberapa kelas dan membagi tanggung jawab di antara mereka:
- YelpScraper – kelas yang bertanggung jawab untuk mengambil HTML dari Yelp.
- YelpParser – kelas yang bertanggung jawab untuk parsing HTML, yang kami dapatkan dari kelas YelpScraper.
- dapatkanPagesAmount(listingPageHtml)
- getBusinessesLinks(listingPageHtml)
- ekstrakInformasiBisnis(businessPageHtml)
Kami membuat aplikasi yang menggunakan dua kelas dan index.js untuk menyatukan semua hal ini.
pemrograman
Pertama, mari kita ubah arsitektur menjadi kode. Sebagai contoh, mari kita menguraikan kelas-kelas dan mendeklarasikan metode-metodenya secara sederhana.
Buat dua file: yelp-scraper.js dan yelp-parser.js di folder root proyek.
// yelp-scraper.js
class YelpScraper {
async scrape(url) {
}
}
export default YelpScraper;// yelp-parser.js
class YelpParser {
getPagesAmount(listingPageHtml) {
}
getBusinessLinks(listingPageHtml) {
}
extractBusinessInformation(businessPageHtml) {
}
}
export default YelpParser;Implementasi scrape metode dari YelpScrape Kelas
// yelp-scraper.js
import puppeteer from "puppeteer";
class YelpScraper {
async scrape(url) {
let browser = null;
let page = null;
let content = null;
try {
browser = await puppeteer.launch({ headless: false });
page = await browser.newPage();
await page.goto(url, { waitUntil: 'load' });
content = await page.content();
} catch(e) {
console.log(e.message);
} finally {
if (page) {
await page.close();
}
if (browser) {
await browser.close();
}
}
return content;
}
}
export default YelpScraper;
Tanggung jawab utama dan satu-satunya terletak pada scrape Caranya adalah dengan mengembalikan kode HTML halaman yang dilewati.
Untuk melakukan ini, Anda harus:
Buka peramban:
browser = await puppeteer.launch();
page = await browser.newPage();Buka halaman tersebut dan tunggu hingga dimuat:
await page.goto(url, { waitUntil: 'load' });Tulis kode HTML halaman tersebut di content Variabel:
content = await page.content();Jika terjadi kesalahan, catatlah:
console.log(e.message);Tutup halaman dan browser:
if (page) {
await page.close();
}
if (browser) {
await browser.close();
}
Kembalikan konten:
return content;penerapan YelpParser Metode kelas
// yelp-parser.js
import * as cheerio from 'cheerio';
class YelpParser {
getPagesAmount(listingPageHtml) {
const $ = cheerio.load(listingPageHtml);
const paginationTotalText = $('.pagination__09f24__VRjN4 .css-chan6m').text();
const totalPages = paginationTotalText.match(/of.((0-9)+)/)(1);
return Number(totalPages);
}
getBusinessLinks(listingPageHtml) {
const $ = cheerio.load(listingPageHtml);
const links = $('a.css-1m051bw')
.filter((i, el) => /^\/biz\//.test($(el).attr('href')))
.map((i, el) => $(el).attr('href'))
.toArray();
return links;
}
extractBusinessInformation(businessPageHtml) {
const $ = cheerio.load(businessPageHtml);
const title = $('div(data-testid="photoHeader")').find('h1').text().trim();
const address = $('address')
.children('p')
.map((i, el) => $(el).text().trim())
.toArray();
const fullAddress = address.join(', ');
const phone = $('p(class=" css-1p9ibgf")')
.filter((i, el) => /\(\d{3}\)\s\d{3}-\d{4}/g.test($(el).text()))
.map((i, el) => $(el).text().trim())
.toArray()(0);
const reviewsCount = $('span(class=" css-1fdy0l5")')
.filter((i, el) => /review/.test($(el).text()))
.text()
.trim()
.match(/\d{1,}/g)(0) || '';
let rating = '';
const headerHtml = $('div(data-testid="photoHeader")').html();
if (!headerHtml || headerHtml.indexOf('aria-label="') === -1) {
rating = '';
}
const startIndx = headerHtml.indexOf('aria-label="') + 'aria-label="'.length;
rating = Number(headerHtml.slice(startIndx, startIndx + 1)) || '';
return {
title,
fullAddress,
phone,
reviewsCount,
rating
}
}
}
export default YelpParser;
Itu getPagesAmount Metode ini mengambil kode HTML dari halaman daftar pertama dan menganalisis jumlah halaman keluaran Yelp.

Inisialisasi cheerio dan hapus teks yang ada di elemen dengan .pagination__09f24__VRjN4 .css-chan6m pemilih.
const $ = cheerio.load(listingPageHtml);
const paginationTotalText = $('.pagination__09f24__VRjN4 .css-chan6m').text();Untuk menemukan pemilih elemen, klik kanan pada halaman dan klik Inspect di menu konteks Chrome. Temukan elemen yang diinginkan di kode sumber halaman dan salin pemilihnya.
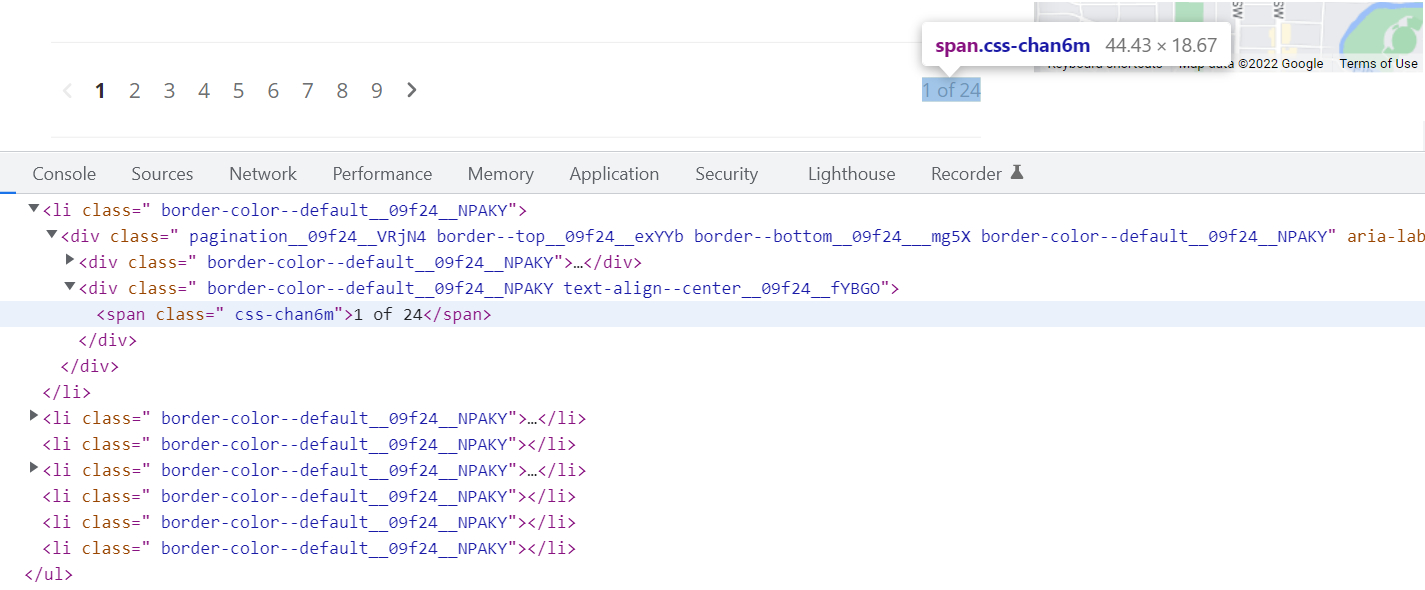
Dalam hal ini, elemen yang menampilkan jumlah halaman memiliki satu .css-chan6m Kelas, tetapi dengan kelas ini pada halaman tersebut terdapat elemen lain, jadi kita juga mengambil pemilih elemen, yang merupakan elemen induk. Kami mengambil .pagination__09f24__VRjN4. Hasilnya adalah .pagination__09f24__VRjN4 .css-chan6m.
Untuk menentukan jumlah halaman total teks 1 of 24, kami menggunakan ekspresi reguler. Misalnya, Anda dapat menggunakan:
const totalPages = paginationTotalText.match(/of.((0-9)+)/)(1);
return Number(totalPages);Hasilnya, fungsi ini mengembalikan nomor tersebut 24yaitu jumlah halaman.
Algoritme yang sama untuk mengurai tautan ke halaman perusahaan digunakan di getBusinessLinks Fungsi yang seharusnya mengembalikan sekumpulan link ke halaman bisnis.
Itu extractBusinessInformation Fungsi ini mengambil kode HTML halaman bisnis dan mem-parsing informasi yang diperlukan melalui penyeleksi dengan cara yang sama.
Titik masuk aplikasi
Untuk menghubungkan kelas parser dan scraper, kami membuat file index.js. Ini adalah titik masuk aplikasi yang memulai dan mengontrol proses pengambilan data.
import YelpScraper from "./yelp-scraper.js";
import YelpParser from "./yelp-parser.js";
const url="https://www.yelp.ca/search?find_desc=restaurants&find_loc=Calgary%2C+AB&start=0";
const main = async() => {
const yelpScraper = new YelpScraper();
const yelpParser = new YelpParser();
const firstPageListingHTML = await yelpScraper.scrape(url);
const numberOfPages = yelpParser.getPagesAmount(firstPageListingHTML);
const scrapedData = ();
for (let i = 0; i < numberOfPages; i++) {
const link = `https://www.yelp.ca/search?find_desc=restaurants&find_loc=Calgary%2C+AB&start=${i * 10}`;
const listingPage = await yelpScraper.scrape(link);
const businessesLinks = yelpParser.getBusinessLinks(listingPage);
for (let k = 0; k < businessesLinks.length; k++) {
const businessesLink = businessesLinks(k);
const businessPageHtml = await yelpScraper.scrape(`https://www.yelp.ca${businessesLink}`);
const extractedInformation = yelpParser.extractBusinessInformation(businessPageHtml);
scrapedData.push(extractedInformation);
}
}
console.log(scrapedData);
};
main();
Pertama kita menginisialisasi kelas scraper dan parser kita.
const yelpScraper = new YelpScraper();
const yelpParser = new YelpParser();Selanjutnya, kita mendapatkan konten halaman hasil pencarian Yelp dan mengekstrak jumlah halamannya.
const firstPageListingHTML = await yelpScraper.scrape(url);
const numberOfPages = yelpParser.getPagesAmount(firstPageListingHTML);Jalankan loop dari 0 hingga 23. Dalam setiap iterasi, kami membuat link ke halaman hasil pencarian tertentu dan menganalisis link ke halaman perusahaan.
const link = `https://www.yelp.ca/search?find_desc=restaurants&find_loc=Calgary%2C+AB&start=${i * 10}`;
const listingPage = await yelpScraper.scrape(link);
const businessesLinks = yelpParser.getBusinessLinks(listingPage);Jalankan loop di halaman perusahaan. Di setiap iterasi, kami mengambil konten halaman perusahaan dan mendapatkan informasi yang kami inginkan.
for (let k = 0; k < businessesLinks.length; k++) {
const businessesLink = businessesLinks(k);
const businessPageHtml = await yelpScraper.scrape(`https://www.yelp.ca${businessesLink}`);
const extractedInformation = yelpParser.extractBusinessInformation(businessPageHtml);
scrapedData.push(extractedInformation);
}
Jalankan pengikis.
node index.jsTunggu hingga pengikisan selesai dan dengan demikian berakhir scrapedData Variabel kita mendapatkan data akhir yang bisa kita tulis ke database atau menghasilkan CSV.
(
{
title: 'Ten Foot Henry',
fullAddress: '1209 1st Street SW, Calgary, AB T2R 0V3',
phone: '(403) 475-5537',
reviewsCount: '406',
rating: 4
}
{
title: 'The Porch',
fullAddress: '730 17th Avenue SW, Calgary, AB T2S 0B7',
phone: '(587) 391-8500',
reviewsCount: '9',
rating: 4
}
{
title: 'Orchard',
fullAddress: '134 - 620 10 Avenue SW, Calgary, AB T2R 1C3',
phone: '(403) 243-2392',
reviewsCount: '12',
rating: 4
},
...
)
Penyempurnaan pengikis
Yelp melindungi situs web dari scraping dengan memblokir permintaan umum dari alamat IP yang sama. Anda dapat menghubungkan proxy, tetapi kami menggunakan API Scrape-it.Cloud, yang merotasi proxy dan menjalankan Puppeteer di cloud.
Dengan menggunakan Scrape-it.Cloud kami tidak dapat membebani sistem dengan menjalankan browser headless secara lokal atau di server kami. Ini bisa menjadi masalah jika Anda ingin mengikis banyak utas dengan cepat.

https://github.com/puppeteer/puppeteer/issues?q=CPU+usage+
Kikis Yelp dengan Scrape-it.Cloud
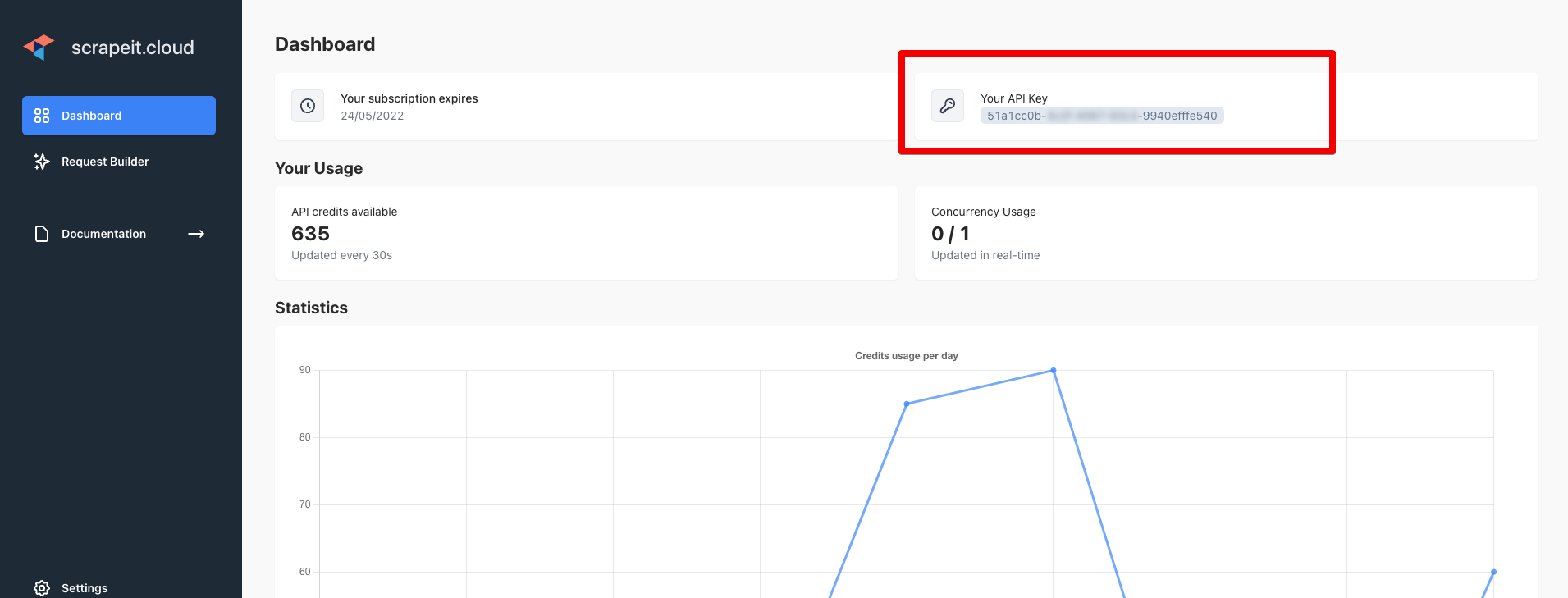
Masuk ke https://scrape-it.cloud/ dan salin kunci API dari halaman dasbor:
Instal axios untuk membuat permintaan ke Scrape-it.Cloud.
npm i axiosMenulis ulang YelpScraper
// yelp-scraper.js
import axios from "axios";
class YelpScraper {
async scrape(url) {
const data = JSON.stringify({
"url": url,
"window_width": 1920,
"window_height": 1080,
"block_resources": false,
"wait": 0,
"proxy_country": "US",
"proxy_type": "datacenter"
});
const config = {
method: 'post',
url: 'https://api.scrape-it.cloud/scrape',
headers: {
'x-api-key': 'YOUR_API_KEY',
'Content-Type': 'application/json'
},
data : data
};
try {
let response = await axios(config);
if (response.data.status === 'error') {
console.log('1 attempt error');
response = await axios(config);
}
return response.data.scrapingResult.content;
} catch(e) {
console.log(e.message);
return '';
}
}
}
export default YelpScraper;
Tentukan parameter untuk Scrape-it.Cloud API. Dengan menggunakan parameter ini, Scrape-it.Cloud membuat permintaan menggunakan alamat IP AS. Setiap permintaan dibuat dengan alamat IP baru. Dengan cara ini kami melewati perlindungan jumlah permintaan dari sebuah IP.
const data = JSON.stringify({
"url": url,
"window_width": 1920,
"window_height": 1080,
"block_resources": false,
"wait": 0,
"proxy_country": "US",
"proxy_type": "datacenter"
});
Pengaturan Aksio. Di header kami meneruskan kunci API yang Anda terima di halaman dasbor.
const config = {
method: 'post',
url: 'https://api.scrape-it.cloud/scrape',
headers: {
'x-api-key': 'YOUR_API_KEY',
'Content-Type': 'application/json'
},
data : data
};
Buat permintaan ke Scrape-it.Cloud API untuk mengambil konten dan coba lagi jika permintaan gagal. Hal ini bisa terjadi jika alamat IP yang digunakan oleh Scrape-it.Cloud telah diblokir.
try {
let response = await axios(config);
if (response.data.status === 'error') {
console.log('1 attempt error');
response = await axios(config);
}
return response.data.scrapingResult.content;
} catch(e) {
console.log(e.message);
return '';
}
Jika Anda tidak dapat menggunakan konten datacenter Proxy, coba ubah itu proxy_type Parameter juga residentialini adalah IP perangkat sebenarnya
const data = JSON.stringify({
"url": url,
"window_width": 1920,
"window_height": 1080,
"block_resources": false,
"wait": 0,
"proxy_country": "US",
"proxy_type": "residential"
});
Setelah semuanya selesai, mari kita mulai pengikisnya:
node index.jsDan kami mendapatkan hasil yang sama:
(
{
title: 'Ten Foot Henry',
fullAddress: '1209 1st Street SW, Calgary, AB T2R 0V3',
phone: '(403) 475-5537',
reviewsCount: '406',
rating: 4
}
{
title: 'The Porch',
fullAddress: '730 17th Avenue SW, Calgary, AB T2S 0B7',
phone: '(587) 391-8500',
reviewsCount: '9',
rating: 4
}
{
title: 'Orchard',
fullAddress: '134 - 620 10 Avenue SW, Calgary, AB T2R 1C3',
phone: '(403) 243-2392',
reviewsCount: '12',
rating: 4
},
...
)
Akhirnya
Kini menjauhi Internet bukanlah suatu pilihan karena Anda akan mengabaikan sekelompok besar pelanggan potensial.
Pengikisan web adalah langkah lain dalam pengembangan bisnis – mengotomatiskan proses pengumpulan data. Keuntungannya adalah serbaguna dan banyak aktivitas menjadi lebih mudah dengan alat yang tepat.
Terima kasih telah membaca sampai akhir. Kami harap tutorial ini benar-benar membantu Anda.
Baca selengkapnya tentang perangkat lunak Amazon Product Scraper