Tersesat di perpustakaan dengan proporsi epik, Anda mati-matian mencari kunci yang akan membuka bab berikutnya.
Segunung informasi mengelilingi Anda, dan menemukan bagian yang penting terasa seperti mencari jarum di tumpukan jerami.
Dengan latar belakang ini, memang demikian Pengikisan web penting untuk mengumpulkan data dari sejumlah besar informasi di World Wide Web. Namun bukan itu saja – ekstraksi data hanyalah puncak gunung es. Tujuannya adalah untuk mendapatkan data yang bersih, relevan, dan bermakna yang dapat memberi Anda nilai.
Anda dapat melihat pentingnya kualitas data ketika melihat temuan seperti Gartner, yang menyatakan bahwa kualitas data yang buruk merugikan perusahaan rata-rata sebesar $12,9 juta. Dalam hal memastikan kualitas data, proses Ekstrak, Transformasi, Muat (ETL) ikut berperan.
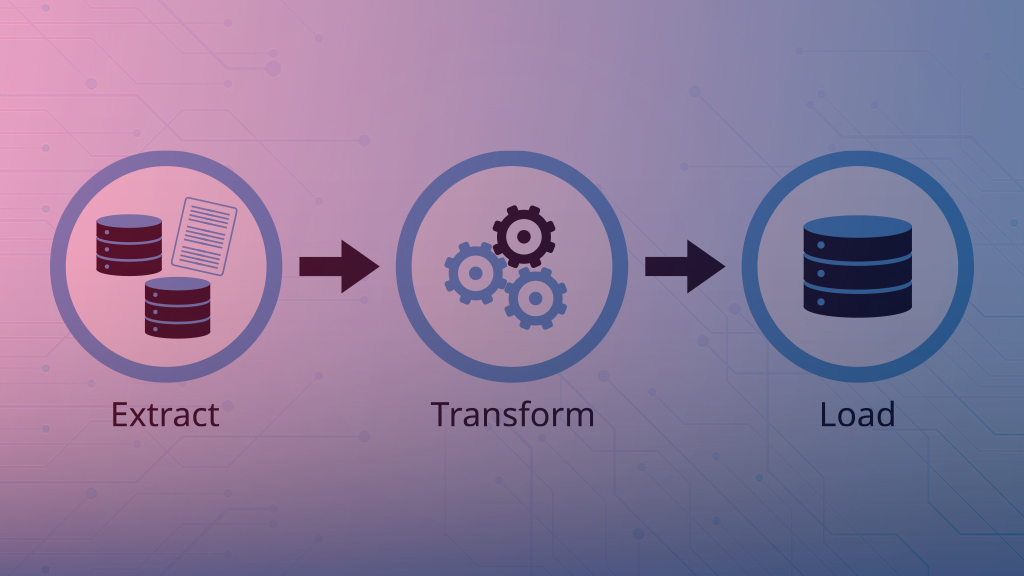
Extract, Transform, Load (ETL) adalah proses tiga langkah yang dimulai dengan ekstraksi data dari berbagai sumber. Setelah ekstraksi data, ubah sesuai kebutuhan bisnis.
Pada langkah ketiga, Anda memuat data yang diubah ke dalam database keluaran atau gudang data. Hasilnya, database keluaran atau gudang data menampung data yang konsisten dan dapat diandalkan untuk dianalisis.
Ekstrak: Ini adalah fase pertama di mana Anda mengekstrak data dari berbagai sumber. Contoh yang mencolok adalah web scraping yang dilakukan oleh bot yang beroperasi pada konten digital online yang luas.
Mengubah: Ini adalah fase kedua di mana Anda merangkum data yang dikumpulkan dalam pementasan untuk diproses. Pemrosesan mencakup pembersihan, menangani nilai yang hilang, menghapus duplikat, menentukan integritas data, mengubah tipe data, dll.
Bergantung pada kebutuhan bisnis Anda, Anda dapat memperoleh metrik tertentu dari data yang ada. Metrik ini memungkinkan pelaporan dan analisis menjadi lebih mudah, cepat, dan bermakna. Fase transformasi sangat penting karena memproses data untuk menjadikannya bentuk yang relevan untuk dianalisis. Dalam kasus data web scraping, ini mempunyai nilai yang sangat besar – topik ini akan dibahas lebih lanjut nanti.
Beban: Ini adalah fase ketiga di mana Anda memuat data yang diubah ke dalam database, data mart, gudang data, atau sistem penyimpanan lainnya. Penting untuk memiliki desain database yang tepat untuk menyimpan data agar mudah diambil dan dianalisis secara bermakna.
Bisa dibayangkan betapa tidak efisien dan tidak dapat diandalkannya analisis data jika Anda tidak melakukan 3 fase di atas dengan benar. Kurangnya ETL yang tepat bisa menjadi masalah nyata. Namun, bila ditangani dengan benar dan tepat waktu, ETL menyediakan satu sumber informasi bagi organisasi.
Daftar Isi
Mengapa ETL penting untuk memproses data dari web scraping?
Pengikisan web sangat penting, namun sering kali dapat mengakibatkan tumpukan informasi mentah tidak terstruktur yang mungkin tidak banyak berguna. Proses ETL yang dirancang dengan baik memastikan bahwa data diproses dan diubah menjadi sumber wawasan yang bermakna:
- Integrasi data: ETL mengintegrasikan data dari berbagai sumber dan proses serta mengubah data menjadi bentuk yang konsisten. Pengikisan web memungkinkan Anda mengambil data dari beberapa situs web. Integrasi data yang tepat memastikan bahwa data disatukan dan menghilangkan definisi yang tidak konsisten.
- Kualitas data: Internet dapat memberikan data yang tidak akurat dan menyesatkan. Desain ETL yang dibuat dengan cermat membersihkan ketidakkonsistenan, menghilangkan duplikat, dan memproses data yang hilang untuk memastikan kualitas tinggi.
- Otomatisasi dalam Skala Besar: Anda dapat mengotomatiskan seluruh proses ekstraksi, transformasi, dan pemuatan. Otomatisasi memungkinkan data yang bersih dan andal dalam skala besar, terus menerus dan efisien. Pemangku kepentingan bisnis tidak perlu menunggu berjam-jam dan berhari-hari hingga pipeline ETL diotomatisasi untuk menangani aliran data yang terus-menerus.
- Analisis Tingkat Lanjut: ETL mengubah data masukan menjadi format terstruktur yang memudahkan penggunaannya melalui kueri, laporan, analitik tingkat lanjut, atau model pembelajaran mesin.
Bagaimana ETL memperbaiki kekacauan tersebut
Lebih dalam lagi, data dari web scraping rentan terhadap kesalahan karena sifatnya. Data yang diperoleh melalui web scraping tidak terstruktur, dan peran ETL dalam memproses data tersebut sangat penting:
- Kode situs web kurang optimal: Sebagian besar pengembang tidak membuat kode situs web dengan baik, sehingga menyebabkan masalah web scraping. Misalnya, membaca data dari kode HTML yang buruk dapat menyebabkan skenario yang tidak akurat dan menyesatkan. Fase transformasi ETL menangani hal ini dengan membawa data ke keadaan yang akurat dan konsisten.
- Pemuatan konten secara dinamis: Situs web sering kali menggunakan pemuatan konten dinamis, yang dapat mempersulit pengikis web untuk mengumpulkan semua data yang relevan. Proses ETL dapat menangani hal ini dengan mengubah konten dinamis yang sesuai
- Pengolahan kata: Mengekstraksi informasi dari teks tidak terstruktur seperti blog dan artikel dapat menjadi tantangan. Skrip ETL modern yang dilengkapi dengan kemampuan Natural Language Processing (NLP) dapat menganalisis dan memproses data teks, sehingga cocok untuk analisis yang andal.
Bagaimana cara mengatur ETL untuk web scraping?
Kami telah membahas secara rinci tentang perlunya ETL untuk mencapai hasil yang bermanfaat dalam pengikisan data. Bagaimana Anda mengatur proses ETL yang tepat untuk web scraping? Mari kita bicarakan secara singkat. Berikut adalah langkah-langkah penting yang mungkin ingin Anda ambil agar proses ETL berjalan dengan benar:
1) Tentukan persyaratan: Tentukan situs web atau halaman web tempat Anda ingin mengekstrak data. Tentukan strategi untuk format data yang ingin Anda ekstrak, metode transformasi dengan mempertimbangkan aturan bisnis, format data keluaran, dan desain database target.
2) Identifikasi kumpulan alat/teknologi: Identifikasi teknologi dan alat yang diperlukan untuk masing-masing dari tiga fase dalam ETL. Misalnya, Anda dapat memilih Selenium untuk ekstraksi data, Python untuk transformasi data, dan MySQL untuk gudang data target.
3) Pastikan kelancaran eksekusi:
- Gunakan pustaka web scraping untuk ekstraksi data dengan mengirimkan permintaan HTTP, menguraikan HTML, dan mengekstrak informasi yang relevan. Patuhi syarat dan ketentuan situs web untuk memastikan kepatuhan hukum dan etika dalam ekstraksi data.
- Transformasi data, termasuk mengonversi tipe data, mengganti nama kolom, menangani nilai yang hilang, membuat data turunan berdasarkan kebutuhan bisnis, dll.
- Muat data ke dalam database target atau gudang data menggunakan kueri optimal. Kueri optimal memberikan jawaban cepat bagi pengguna yang mencari laporan dan analisis.
4) Otomatisasi proses ETL: Otomatiskan proses ETL pada interval terjadwal menggunakan alat seperti Apache Airflow.
5) Pemantauan dan Penyempurnaan: Pantau proses ETL untuk menemukan kesalahan dan masalah dan catat insiden tersebut. Perbaiki kesalahan dan masalah untuk membuat proses ETL lebih tangguh
Singkatnya, untuk mencapai hasil yang baik dalam web scraping, Anda memerlukan proses ETL yang dipikirkan dengan matang dan eksekusi yang lancar. Dibandingkan dengan kegunaan data yang andal untuk mendukung keputusan, biaya data berkualitas rendah mewakili kesenjangan yang sangat besar, sehingga memerlukan ETL untuk menjembatani kesenjangan ini dan mencapai hasil terbaik.