
Saat membuat web scraper, ada baiknya mempertimbangkan kemungkinan pemblokiran - tidak semua layanan siap membagikan data Anda
Untuk mengurangi jumlah bot yang menggunakan situs web, pengembang menggunakan deteksi alamat IP, inspeksi header permintaan HTTP, CAPTCHA, dan metode lain untuk mendeteksi lalu lintas bot. Namun, hal ini masih bisa dielakkan. Untuk melakukan ini, Anda harus mengikuti beberapa aturan saat mengikis.
Namun meskipun situs web tersebut tidak memberikan larangan apa pun, tetap ada baiknya menunjukkan rasa hormat dan tidak menyebabkan kerugian apa pun pada situs web tersebut. Ikuti aturan yang tercantum di robots.txtHindari mengambil data selama jam sibuk, batasi permintaan yang berasal dari alamat IP yang sama, dan tetapkan penundaan di antara permintaan tersebut.
Daftar Isi
Set untuk non-blok
Pertama, posisikan scraper dengan benar.
Tetapkan interval permintaan
Kesalahan paling umum saat membuat web scraper adalah menggunakan interval yang tetap. Orang tidak dapat mengakses situs web 24 jam sehari setelah jangka waktu yang ditentukan secara ketat.
Oleh karena itu, perlu untuk menetapkan interval di mana waktu antar iterasi berubah. Biasanya lebih baik menyelesaikan instalasi selama dua detik atau lebih.
Selain itu, jangan membolak-balik halaman terlalu cepat. Tetap di situs web untuk sementara waktu. Peniruan perilaku pengguna seperti itu mengurangi risiko pemblokiran.
Tetapkan agen pengguna
Agen pengguna berisi informasi tentang pengguna dan perangkat yang digunakan. Dengan kata lain, ini adalah data yang diterima server pada saat pengguna berkunjung. Ini membantu server untuk mengidentifikasi setiap pengunjung. Dan jika pengguna dengan agen pengguna yang sama membuat terlalu banyak permintaan, server mungkin melarangnya.
Oleh karena itu, ada baiknya memikirkan untuk memperkenalkan ke dalam web scraper kemampuan untuk mengubah header Agen-Pengguna secara berkala dan acak ke header lain dari keseluruhan daftar. Hal ini memungkinkan untuk menghindari pemblokiran dan terus mengumpulkan informasi.
Untuk melihat agen pengguna Anda sendiri, buka DevTools (F12) lalu tab Jaringan.
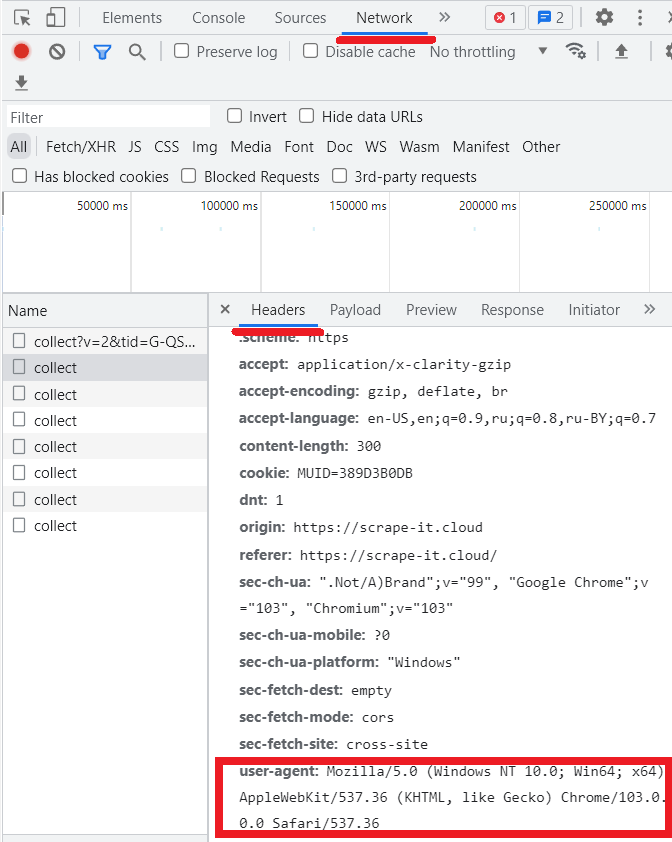
Namun, ada header lain selain agen pengguna yang dapat menyabotase pekerjaan scraper. Sayangnya, web scraper dan crawler sering kali mengirimkan header yang berbeda dari yang dikirim oleh browser web sebenarnya. Oleh karena itu, ada baiknya meluangkan waktu untuk mengubah semua header agar tidak terlihat seperti permintaan otomatis yang dikirimkan bot.
Biasanya, ketika pengguna sebenarnya menggunakan browser, header “Terima”, “Terima-Encoding”, “Bahasa Terima”, dan “Permintaan Tidak Aman” juga diisi. Jadi jangan lupakan mereka juga. Contoh pengisian kolom tersebut:
accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
accept-encoding: gzip, deflate, br
accept-language: en-US,en;q=0.9
upgrade-insecure-requests: 1Tetapkan perujuk
Header pengarah menunjukkan situs asal pengguna. Jika Anda tidak tahu apa yang harus dimasukkan di kolom ini, Anda dapat menggunakan "google.com". Ini bisa berupa mesin pencari lainnya (Yahoo.com, Bing.com, dll.) atau situs media sosial apa pun. Misalnya, tampilannya akan seperti ini:
Referer: https://www.google.com/Atur sidik jari Anda dengan benar
Setiap kali seseorang terhubung ke situs web target, perangkatnya mengirimkan permintaan yang berisi header HTTP. Header ini berisi informasi seperti zona waktu perangkat, bahasa, pengaturan privasi, cookie, dan lainnya. Header web dikirimkan oleh browser setiap kali situs web dikunjungi dan secara keseluruhan cukup unik.
Misalnya, kombinasi tertentu dari parameter tersebut mungkin unik untuk sekitar 200.000 pengguna. Oleh karena itu, ada baiknya untuk selalu mengikuti perkembangan informasi tersebut. Alternatifnya adalah dengan menggunakan layanan scraping pihak ketiga atau IP penduduk. Untuk pengecekan sidik jari sendiri bisa digunakan pada layanan selanjutnya.
Namun, tidak hanya sidik jari browser yang harus benar, tetapi juga sidik jari TLS. Sangat penting untuk melacak sidik jari TLS/HTTP yang dikumpulkan oleh berbagai situs web. Misalnya, sebagian besar parser menggunakan HTTP/1.1 dan sebagian besar browser menggunakan HTTP/2 jika tersedia. Oleh karena itu, permintaan melalui HTTP/1.1 mencurigakan bagi sebagian besar situs web.
Cara lain untuk menghindari penyumbatan
Jadi, setelah semua pengaturan selesai, saatnya beralih ke jebakan utama dan aturan yang harus diikuti.
Gunakan browser tanpa kepala
Hal pertama yang perlu diperhatikan adalah sebaiknya gunakan browser tanpa kepala jika memungkinkan. Mereka mengizinkan perilaku pengguna untuk ditiru, sehingga mengurangi risiko pemblokiran. Jika browser seperti itu mengganggu, Anda selalu dapat menyembunyikannya dan melakukan semuanya di latar belakang.
Ini juga membantu untuk menerima bahkan data yang dimuat melalui JavaScript atau halaman web AJAX dinamis. Peramban tanpa kepala yang paling umum adalah Chrome Tanpa Kepala, yang dapat digunakan oleh sebagian besar perpustakaan pengikis (misalnya Selenium).
Browser tanpa kepala memperkenalkan berbagai elemen gaya seperti font, tata letak, dan warna, sehingga lebih sulit dikenali dan dibedakan oleh pengguna sebenarnya.
Gunakan server proksi
Jika permintaan datang dari tempat yang sama dalam jarak dekat dalam jangka waktu yang lama, perilaku ini tidak sama dengan perilaku pengguna normal. Mirip seperti bot, namun agar website target tidak curiga, Anda bisa menggunakan server proxy.
Secara sederhana, proxy adalah komputer perantara yang membuat permintaan ke server, bukan ke klien, dan mengembalikan hasilnya ke klien. Oleh karena itu, server target berasumsi bahwa permintaan tersebut berasal dari lokasi yang sama sekali berbeda dan oleh karena itu dari pengguna yang sama sekali berbeda.
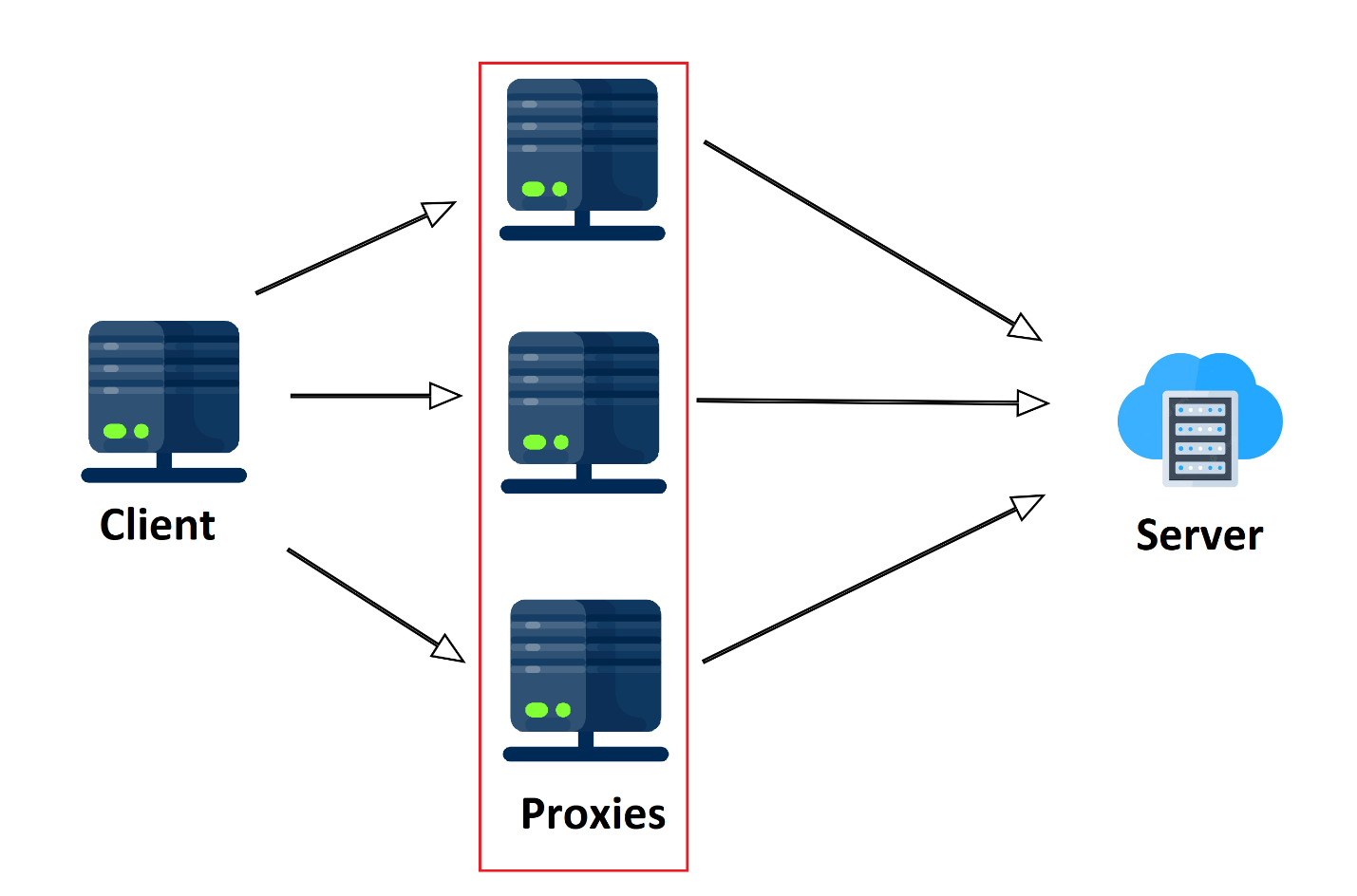
Proksi gratis dan berbayar. Namun, lebih baik tidak menggunakan proxy gratis untuk pengumpulan data – karena sangat lambat dan tidak dapat diandalkan. Idealnya, Anda harus menggunakan proxy pribadi atau seluler. Selain itu, menggunakan proxy saja tidak cukup. Untuk scraping, lebih baik membuat seluruh kumpulan proxy.
Selain itu, sangat penting untuk memperhatikan alamat IP asal permintaan tersebut. Jika lokasinya tidak memenuhi ekspektasi situs web, lokasi tersebut dapat diblokir begitu saja. Misalnya saja, kecil kemungkinan infrastruktur lokal akan berguna bagi pengguna asing. Oleh karena itu, lebih baik gunakan proxy lokal untuk mengurai website agar tidak menimbulkan kecurigaan.
Gunakan layanan penyelesaian CAPTCHA
Jika ada terlalu banyak permintaan, situs mungkin menawarkan untuk menyelesaikan captcha untuk memastikan permintaan tersebut berasal dari pengguna sebenarnya dan bukan bot. Dalam hal ini, layanan dapat membantu yang secara otomatis mengenali captcha yang diusulkan dengan sedikit biaya.
Hindari perangkap honeypot
Untuk menangkap bot, banyak situs menggunakan perangkap honeypot. Secara umum, honeypot adalah link kosong yang tidak ada pada halaman tetapi ada dalam kode HTML sumber. Ketika terdeteksi secara otomatis, kait ini dapat mengarahkan web scraper ke halaman yang menipu atau halaman kosong.
Faktanya, mereka sangat mudah dikenali. Berbagai properti CSS “masking” ditentukan untuk tautan tersebut. Misalnya “Tampilan: tidak ada”, “Visibilitas: tersembunyi” atau warna link identik dengan background website.
Hindari JavaScript
Seperti halnya gambar, menghapus JavaScript sebenarnya tidak mengakibatkan pemblokiran. Namun, perlu dicatat bahwa tidak semua perpustakaan mengizinkan pengikisan data tersebut, artinya web scraper yang dapat mengumpulkan data dinamis akan memiliki kode yang lebih kompleks dan memerlukan kekuatan pemrosesan yang lebih besar.
Menggunakan Ready API di web scraper
Jika Anda merasa bahwa pengaturan dan aturan yang tercantum terlalu banyak, dan biaya layanan proxy dan penyelesaian captcha terlalu tinggi, Anda dapat mempermudah dan “mengalihkan” interaksi dengan situs ke sumber daya pihak ketiga.
Scrape-it.Cloud menawarkan REST API untuk menggores situs web dengan ukuran berapa pun. Layanan ini menangani pemblokiran IP, rotasi IP, captcha, rendering JavaScript, menemukan dan menggunakan proxy perumahan atau pusat data, dan mengatur header HTTP dan cookie khusus. Pengguna menetapkan kueri dan API mengembalikan data.
Tips & trik menggores
Hal terakhir yang juga patut disebutkan adalah kapan waktu terbaik untuk melakukan scraping situs web dan metode rekayasa balik dalam melakukan scraping. Hal ini diperlukan tidak hanya untuk menghindari pemblokiran, tetapi juga agar tidak menyebabkan kerusakan pada situs.
Menggaruk di luar jam sibuk
Karena crawler menelusuri halaman lebih cepat dibandingkan pengguna sebenarnya, crawler meningkatkan beban di server secara signifikan. Pada saat yang sama, jika penguraian dilakukan saat server sedang mengalami beban berat, kinerja layanan akan menurun dan situs akan memuat lebih lambat.
Hal ini tidak hanya berdampak negatif pada lalu lintas situs dari pengguna sebenarnya, namun juga meningkatkan waktu yang dihabiskan untuk mengumpulkan data.
Oleh karena itu, ada baiknya mengumpulkan dan mengekstrak data pada saat situs memuat minimal. Secara umum, disarankan untuk menjalankan parser setelah tengah malam waktu setempat.

Kikis pada waktu yang berbeda dalam sehari
Jika situs tersebut sibuk antara pukul 08.00 hingga 08.20 setiap hari, maka timbul kecurigaan. Oleh karena itu, ada baiknya menentukan nilai acak di mana waktu pengikisan berubah.
Rekayasa balik untuk pengikisan yang lebih baik
Rekayasa terbalik adalah metode pengembangan yang umum digunakan. Singkatnya, rekayasa balik melibatkan penelitian aplikasi perangkat lunak untuk memahami cara kerjanya.
Dalam kasus pengembangan scraper, pendekatan ini berarti memiliki analisis utama untuk menyusun permintaan di masa depan. Alat Pengembang atau DevTools di browser (tekan F12) dapat membantu menganalisis halaman web.
Mari kita coba melihat lebih dekat pada SERP Google. Buka DevTools di bawah tab Jaringan, lalu coba temukan sesuatu di google.com dan lihat permintaan yang sudah selesai. Untuk melihat responsnya, cukup klik permintaan yang diterima dan buka tab “Pratinjau”:
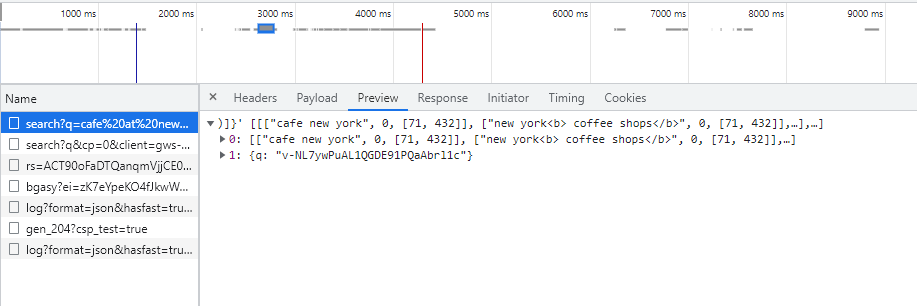
Data ini membantu untuk memahami permintaan apa yang harus dikembalikan dan dalam bentuk apa. Data di tab Header membantu memahami data apa yang harus dikirim untuk mengkompilasi permintaan. Hal utama adalah mengeksekusi permintaan dengan benar dan menafsirkan jawabannya dengan benar.
Membalikkan aplikasi seluler
Situasinya mirip dengan rekayasa balik aplikasi seluler. Hanya dalam hal ini perlu untuk mencegat permintaan yang dikirim oleh aplikasi seluler ke server. Tidak seperti mencegat permintaan normal, untuk aplikasi seluler Anda harus menggunakan proksi man-in-the-middle seperti proksi Charles.
Selain itu, jangan lupa bahwa permintaan yang dikirim melalui aplikasi seluler lebih kompleks dan membingungkan.
Kesimpulan dan temuan
Terakhir, mari kita lihat langkah-langkah keamanan apa yang dapat diambil oleh situs web dan tindakan pencegahan apa yang dapat diambil untuk melewatinya.
|
Tindakan keamanan |
Tindakan balasan |
|
Sidik jari peramban |
Peramban tanpa kepala |
|
Menyimpan data dalam JavaScript |
Peramban tanpa kepala |
|
Batasan kecepatan IP |
Rotasi proxy |
|
Sidik jari TLS |
Memalsukan sidik jari TLS |
|
CAPTCHA |
Layanan penyelesaian CAPTCHA |
Dengan mengikuti sejumlah aturan sederhana yang tercantum di atas, Anda tidak hanya dapat menghindari penyumbatan, tetapi juga meningkatkan efisiensi scraper secara signifikan.
Selain itu, saat membuat scraper, penting untuk diingat bahwa banyak situs web menyediakan API untuk mengambil data. Dan jika memungkinkan, lebih baik menggunakannya daripada mengumpulkan data secara manual dari situs.