
Web scraping adalah pemindahan data yang dipublikasikan di Internet dalam bentuk halaman HTML (di situs web) ke lokasi penyimpanan (baik itu file teks atau database).
Kelebihan bahasa pemrograman C# pada web scraping adalah memungkinkan browser untuk diintegrasikan langsung ke dalam form menggunakan C# WebBrowser. Data yang tergores dapat disimpan ke file keluaran apa pun atau ditampilkan di layar.
Daftar Isi
Dasar-dasar Scraping Web di ASP Net dengan C#
Untuk lingkungan pengembangan C#, Anda dapat menggunakan Visual Studio atau Visual Studio Code. Pilihannya tergantung pada tujuan pengembangan dan kemampuan PC.
Visual Studio adalah lingkungan untuk pengembangan komprehensif aplikasi desktop, seluler, dan server dengan templat siap pakai dan kemampuan untuk mengedit program yang sedang dikembangkan secara grafis.
Visual Studio Code, di sisi lain, adalah shell dasar tempat Anda dapat menginstal paket yang diperlukan. Dibutuhkan lebih sedikit ruang dan waktu CPU.
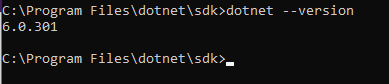
Jika Anda memilih Visual Studio Code, Anda juga harus menginstal .NET Framework dan .NET Core 3.1. Untuk memastikan semua komponen terpasang dengan benar, masukkan perintah berikut pada baris perintah:
dotnet --versionJika semuanya berfungsi dengan benar, perintah tersebut akan mengembalikan versi .NET yang diinstal.
Berperan untuk pengikisan web
Untuk memanfaatkan web scraping secara optimal di C#, ada baiknya menggunakan perpustakaan tambahan. Dan sebelum menggunakan perpustakaan, Anda harus mengetahui semua perpustakaan C# untuk web scraping. Yang paling umum digunakan adalah PhantomJS dengan Selenium, HtmlAgilityPack dengan ScrapySharp dan Puppeteer Sharp.
Dapatkan Data dengan Selenium dan PhantomJS Web Scraping C#
Untuk menggunakan PhantomJS, pustaka web scraping C# terbaik, Anda perlu menginstalnya. Cara termudah untuk melakukannya adalah dengan menggunakan Manajer Paket NuGet. Untuk menyertakan paket di Visual Studio, klik kanan tab Referensi di proyek dan ketik “PhantomJS” di bilah pencarian.
Apa itu perpustakaan Selenium?
Namun, ketika seseorang berbicara tentang PhantomJS, yang mereka maksud adalah PhantomJS dengan Selenium. Untuk menggunakan PhantomJS dengan Selenium, Anda juga harus menginstal paket berikut:
-
Selenium.WebDriver.
-
Dukungan selenium.
Ini dapat dilakukan dengan menggunakan NuGet. Untuk menggunakan NuGet dalam Visual Studio Code, cukup instal manajer paket NuGet dengan GUI:
Atau tidak:
Untuk mendapatkan semua judul di halaman, cukup gunakan:
using (var driver = new PhantomJSDriver())
{
driver.Navigate().GoToUrl("http://example.com/");
var titles = driver.FindElements(By.ClassName("title"));
foreach (var title in titles)
{
Console.WriteLine(title.Text);
}
}Kode sederhana ini menemukan semua elemen dengan judul kelas dan mengembalikan semua teks di dalamnya.
Selenium mengandung banyak fungsi untuk menemukan elemen yang Anda butuhkan. Sebuah elemen dapat dicari dengan XPath, pemilih CSS atau tag HTML. Misalnya, untuk menemukan elemen berdasarkan XPathnya, seperti kolom input, dan meneruskan nilai, cukup gunakan:
driver.FindElement(By.XPath(@".//div")).SendKeys("c#");Untuk mengklik elemen apa pun, misalnya tombol konfirmasi, Anda dapat menggunakan kode berikut:
driver.FindElement(By.XPath(@".//input(@id='searchsubmit')")).Click();Untuk apa perpustakaan Selenium?
Selenium adalah perpustakaan lintas platform dan bekerja dengan sebagian besar bahasa pemrograman, memiliki dokumentasi yang lengkap dan ditulis dengan baik serta komunitas yang aktif.
Menggunakan Selenium dengan PhantomJS adalah solusi bagus yang memungkinkan penyelesaian berbagai tugas pengikisan, termasuk pengikisan halaman dinamis. Namun, ini memerlukan sumber daya yang cukup intensif.
HtmlAgilityPack untuk memulai dengan cepat
Jika situs web tidak terlindungi dari bot dan semua konten yang diperlukan segera disediakan, solusi sederhana dapat digunakan – pustaka Html Agility Pack, pustaka web scraping C# lainnya. Ini adalah salah satu perpustakaan paling populer untuk scraping di C#. Koneksi juga dilakukan melalui paket NuGet.
Apa itu HtmlAgilityPac?
Perpustakaan ini membuat pohon DOM dari HTML. Masalahnya adalah Anda harus memuat sendiri kode halamannya. Untuk memuat halaman cukup gunakan kode berikutnya:
using (WebClient client = new WebClient())
{ string html = client.DownloadString("http://example.com");
//Do something with html then
}Untuk kemudian menemukan beberapa elemen pada halaman, Anda dapat menggunakan XPath, misalnya:
HtmlNodeCollection links = document.DocumentNode.SelectNodes(".//h2/a");
foreach (HtmlNode link in links)
Console.WriteLine("{0} - {1}", link.InnerText, link.GetAttributeValue("href", "")); Untuk apa HtmlAgilityPac digunakan?
HtmlAgilityPac adalah opsi tingkat pemula yang lebih mudah dan bagus untuk pemula. Ada juga situs web khusus dengan contoh aplikasi. Ini lebih sederhana dari Selenium dan tidak mendukung beberapa fitur, tetapi bagus untuk proyek yang tidak terlalu rumit.
Html Agility Pack memungkinkan Anda menyematkan browser dalam bentuk Windows, membuat aplikasi desktop lengkap.
Pengikisan Web C# dengan ScrapySharp
Untuk menyertakan paket dalam Visual Studio, klik kanan tab Referensi di proyek dan ketik "ScrapySharp" di bilah pencarian.
Untuk menambahkan paket ini dalam Visual Studio Code, tulis di baris perintah:
dotnet add package ScrapySharpApa itu perpustakaan ScrapySharp?
ScrapySharp adalah pustaka web scraping open source untuk bahasa pemrograman C# yang memiliki paket NuGet. Selain itu, ScrapySharp adalah ekstensi Html Agility Pack untuk menggores struktur data menggunakan pemilih CSS dan mendukung halaman web dinamis.
Untuk mengambil dokumen HTML menggunakan ScrapySharp, seseorang dapat menggunakan kode berikut:
static ScrapingBrowser browser = new ScrapingBrowser();
static HtmlNode GetHtml(string url){
WebPage webPage = browser.NavigateToPage(new Uri(url));
return webPage.Html;
}Untuk apa perpustakaan ScrapySharp?
Jadi tidak intensif sumber daya seperti Selenium, tetapi juga mendukung kemampuan merayapi halaman web dinamis. Namun jika ScrapySharp sudah cukup untuk menyelesaikan tugas sehari-hari, untuk tugas yang lebih kompleks lebih baik menggunakan Selenium.
Dalang untuk mengikis tanpa kepala
Puppeteer adalah pustaka Node.js yang menyediakan API tingkat tinggi untuk mengontrol Chrome atau Chromium tanpa kepala atau berinteraksi dengan protokol DevTools. Namun ada juga pembungkus untuk digunakan di C# – Puppeteer Sharp, yang memiliki paket NuGet.
Apa itu Perpustakaan Dalang?
Dalang menawarkan kemampuan untuk bekerja dengan browser tanpa kepala dan terintegrasi dengan sebagian besar aplikasi.
Dalang menyediakan dokumentasi yang ditulis dengan baik dan contoh penggunaan di situs resmi. Aplikasi yang paling sederhana misalnya:
using var browserFetcher = new BrowserFetcher();
await browserFetcher.DownloadAsync(BrowserFetcher.DefaultChromiumRevision);
var browser = await Puppeteer.LaunchAsync(new LaunchOptions
{
Headless = true
});
var page = await browser.NewPageAsync();
await page.GoToAsync("http://www.google.com");
await page.ScreenshotAsync(outputFile);Untuk apa Perpustakaan Dalang?
Dalang juga mendukung mode tanpa kepala, yang memungkinkan Anda mengurangi waktu CPU dan konsumsi RAM.
Pustaka pengikisan web C# terbaik
Bergantung pada proyek, tujuannya, dan kemampuan Anda, perpustakaan terbaik untuk berbagai kasus berbeda-beda. Oleh karena itu, untuk menyederhanakan proses pemilihan dan membantu Anda menemukan pustaka web scraping C# yang paling sesuai, kami telah menyusun tabel perbandingan semua pustaka yang dibahas hari ini.
|
perpustakaan |
Keterangan |
Keuntungan |
Kekurangan |
|---|---|---|---|
|
PhantomJS |
Mengintegrasikan PhantomJS dengan Selenium untuk web scraping |
Memungkinkan Anda mengikis situs web dinamis |
Sumber daya intensif, memerlukan instalasi tambahan PhantomJS |
|
selenium |
Perpustakaan lintas platform dengan dokumentasi ekstensif dan komunitas aktif |
Mendukung berbagai metode pencarian elemen (XPath, CSS Selector, HTML Tag) |
Mungkin lebih lambat dibandingkan perpustakaan lain dan mungkin memerlukan lebih banyak kode untuk melakukan tindakan tertentu |
|
HtmlAgilityPack |
Membuat pohon DOM dari HTML dan menyediakan antarmuka yang ramah pengguna |
Cocok untuk proyek yang lebih sederhana dan pemula, tidak diperlukan integrasi browser |
Tidak mendukung fitur-fitur canggih tertentu dari Selenium |
|
ScrapySharp |
Perpanjangan HtmlAgilityPack dengan dukungan untuk pemilih CSS dan halaman web dinamis |
Memberikan kemampuan untuk memindai halaman web dinamis, yang lebih hemat sumber daya dibandingkan Selenium |
Dokumentasi dan dukungan komunitas yang terbatas, mungkin tidak menangani skenario kompleks seefektif Selenium |
|
Dalang Tajam |
Pembungkus C# untuk Puppeteer yang mengontrol Chrome atau Chromium tanpa kepala dan berinteraksi dengan DevTools |
Mendukung mode tanpa kepala, terdokumentasi dengan baik, mengurangi waktu CPU dan konsumsi RAM |
Memerlukan pemasangan browser Chrome atau Chromium tanpa kepala, mungkin dengan kurva pembelajaran untuk pemula |
Sekarang Anda sudah bisa melihat perbedaan tujuan, kelebihan dan kekurangan masing-masing pilihan, kami berharap akan lebih mudah bagi Anda untuk menentukan pilihan yang tepat.
Proksi C# untuk pengikisan web
Beberapa situs web memiliki pemeriksaan dan jebakan deteksi bot yang mencegah pengikis mengumpulkan banyak data. Namun, ada juga solusinya.
Misalnya, Anda dapat menggunakan browser tanpa kepala untuk meniru tindakan pengguna sebenarnya, meningkatkan penundaan antar iterasi, atau menggunakan proxy.
Contoh penggunaan proxy:
public static void proxyConnect();
WebProxy proxy = new WebProxy();
proxy.address = “http://IP:Port”;
HTTPWebRequest req = (HTTPWebRequest);
WebRequest.Create(“https://example.com/”);
req.proxy = proxy;Server proxy adalah suatu keharusan bagi setiap web scraper C#. Ada banyak pilihan seperti layanan SmartProxy, Luminati Network, Blazing SEO. Proxy gratis tidak selalu cocok untuk tujuan tersebut: sering kali lambat dan tidak dapat diandalkan. Anda juga dapat membuat jaringan proxy Anda sendiri di server, misalnya menggunakan Scrapoxy, API sumber terbuka.
Siapa pun yang menggunakan proxy terlalu lama berisiko terkena larangan IP atau daftar hitam. Untuk menghindari pemblokiran, Anda dapat menggunakan proxy perumahan yang berputar. Dengan memilih lokasi tertentu untuk dikikis dan terus-menerus mengubah alamat IP, pengikis bisa menjadi kebal terhadap pemblokiran alamat IP.
Solusi alternatifnya adalah dengan menggunakan API kami di scraper Anda, yang memungkinkan pengumpulan data yang diminta dan secara efektif menghindari pemblokiran tanpa memasukkan captcha.
Baca juga tentang proxy untuk scraping
Kesimpulan dan temuan
C# adalah pilihan yang baik untuk membuat scraper desktop. Jumlah perpustakaan untuk ini lebih sedikit dibandingkan NodeJS atau Python, tetapi fungsinya tidak lebih buruk. Selain itu, jika parser yang sangat aman diperlukan, C# menawarkan lebih banyak opsi untuk implementasi.
Pustaka yang dipertimbangkan memungkinkan pembuatan proyek yang lebih kompleks yang memerlukan data, dapat menganalisis banyak halaman, dan mengekstrak data. Tentu saja, tidak semua perpustakaan tercantum dalam artikel, tetapi hanya perpustakaan yang paling fungsional dan memiliki dokumentasi yang baik. Namun, selain yang terdaftar, ada perpustakaan pihak ketiga lainnya, yang tidak semuanya memiliki paket NuGet.