
Redfin adalah platform online yang menyediakan informasi real estat, termasuk daftar penjualan dan persewaan, data pasar, dan kemampuan pencarian. Hal ini bertujuan untuk memudahkan pelanggan membeli, menjual atau menyewa rumah dengan memberi mereka akses ke database properti yang luas.
Melalui Pengikisan web Proses pengumpulan data Redfin yang konsisten dapat diotomatisasi. Hal ini memungkinkan analisis tren, penilaian nilai properti, dan perkiraan pasar.
Pada artikel ini, kami akan membahas dan mendemonstrasikan dengan contoh bagaimana Anda dapat mengikis data dari Redfin menggunakan berbagai metode. Ini termasuk membuat scraper Python Anda sendiri, menggunakan scraper tanpa kode, dan memanfaatkan Redfin API tidak resmi. Masing-masing pendekatan ini memiliki kelebihan dan kekurangannya masing-masing dan pilihannya bergantung pada kebutuhan dan kemampuan spesifik pengguna.
Daftar Isi
Memilih metode pengikisan
Seperti disebutkan sebelumnya, ada beberapa cara untuk mengumpulkan data dari Redfin. Sebelum kita mendalami detail masing-masing metode, mari kita lihat sekilas opsi yang tersedia, mulai dari yang paling sederhana dan ramah bagi pemula hingga yang lebih canggih:
- Pengikisan manual. Metode ini gratis namun memakan waktu dan hanya cocok untuk mengumpulkan data dalam jumlah kecil. Halaman yang relevan harus dicari secara manual dan informasi yang diinginkan diekstraksi.
- Pengikis tanpa kode. Layanan ini menawarkan alat pengumpulan data tanpa pengetahuan pemrograman apa pun. Mereka ideal bagi pengguna yang hanya membutuhkan data tanpa mengintegrasikannya ke dalam aplikasi. Cukup tentukan parameter di Redfin No-Code Scraper dan dapatkan kumpulan datanya.
- Alat otomatisasi peramban. Ekstensi dapat digunakan untuk mengumpulkan data dari Redfin. Namun, tidak seperti scraper tanpa kode, jendela browser harus terbuka selama proses scraping dan tidak dapat ditutup hingga proses selesai.
- API sirip merah. Redfin tidak memiliki API resmi, jadi Anda harus menggunakan alternatif tidak resmi. Kami akan memberikan instruksi dan contoh kode nanti.
- Buat pengikis Anda sendiri adalah metode yang paling rumit. Meskipun penggunaan Redfin API melibatkan pengaturan parameter dan penerimaan kumpulan data yang terstruktur dengan baik, membuat scraper Anda sendiri memerlukan penanganan captcha, perlindungan bot, dan proxy untuk mencegah pemblokiran IP saat mengambil data dalam jumlah besar.
Semua opsi yang dipertimbangkan memiliki kelebihan dan kekurangan, sehingga pilihan harus dibuat tergantung kebutuhan Anda. Singkatnya, jika Anda hanya membutuhkan data dari beberapa entri, cukup kumpulkan secara manual. Jika Anda perlu mengumpulkan data dari sejumlah besar entri tetapi tidak memiliki pengalaman pemrograman, Redfin No-Code Scraper adalah pilihan yang bagus. Dan jika Anda ingin mengintegrasikan pengumpulan data ke dalam aplikasi Anda dan tidak ingin repot dengan pengambilan data atau melewati perlindungan bot Redfin, Redfin API cocok untuk Anda.
Namun, jika Anda ingin mengumpulkan data sendiri dan memiliki keterampilan serta waktu untuk menyelesaikan semua masalah yang terkait, buatlah scraper Redfin Anda sendiri dengan Python atau bahasa pemrograman lain.
Metode 1: Kikis data dari Redfin tanpa kode
Alat pengikis web tanpa kode adalah solusi perangkat lunak yang memungkinkan pengguna mengekstrak data dari situs web tanpa harus menulis kode. Mereka menawarkan antarmuka yang sederhana dan intuitif yang memungkinkan pengguna mendapatkan data yang mereka butuhkan hanya dengan beberapa klik.
Karena tidak diperlukan keahlian atau pengetahuan coding, siapa pun dapat menggunakan scraper tanpa kode dari Redfin. Metode ini juga salah satu yang paling aman karena data Redfin dikumpulkan bukan dari PC Anda, tetapi dari layanan yang menyediakan pengikis tanpa kode. Anda hanya mendapatkan kumpulan data yang sudah dibuat sebelumnya dan melindungi diri Anda dari kemungkinan penangguhan oleh Redfin.
Mari kita lihat lebih dekat penggunaan alat tersebut menggunakan Redfin scraper tanpa kode HasData sebagai contoh. Untuk melakukan ini, masuk ke situs web kami dan masuk ke akun Anda.
Navigasikan ke tab “No-Code Scrapers” dan cari “Redfin Property Scraper.” Klik untuk membuka halaman pengikis.
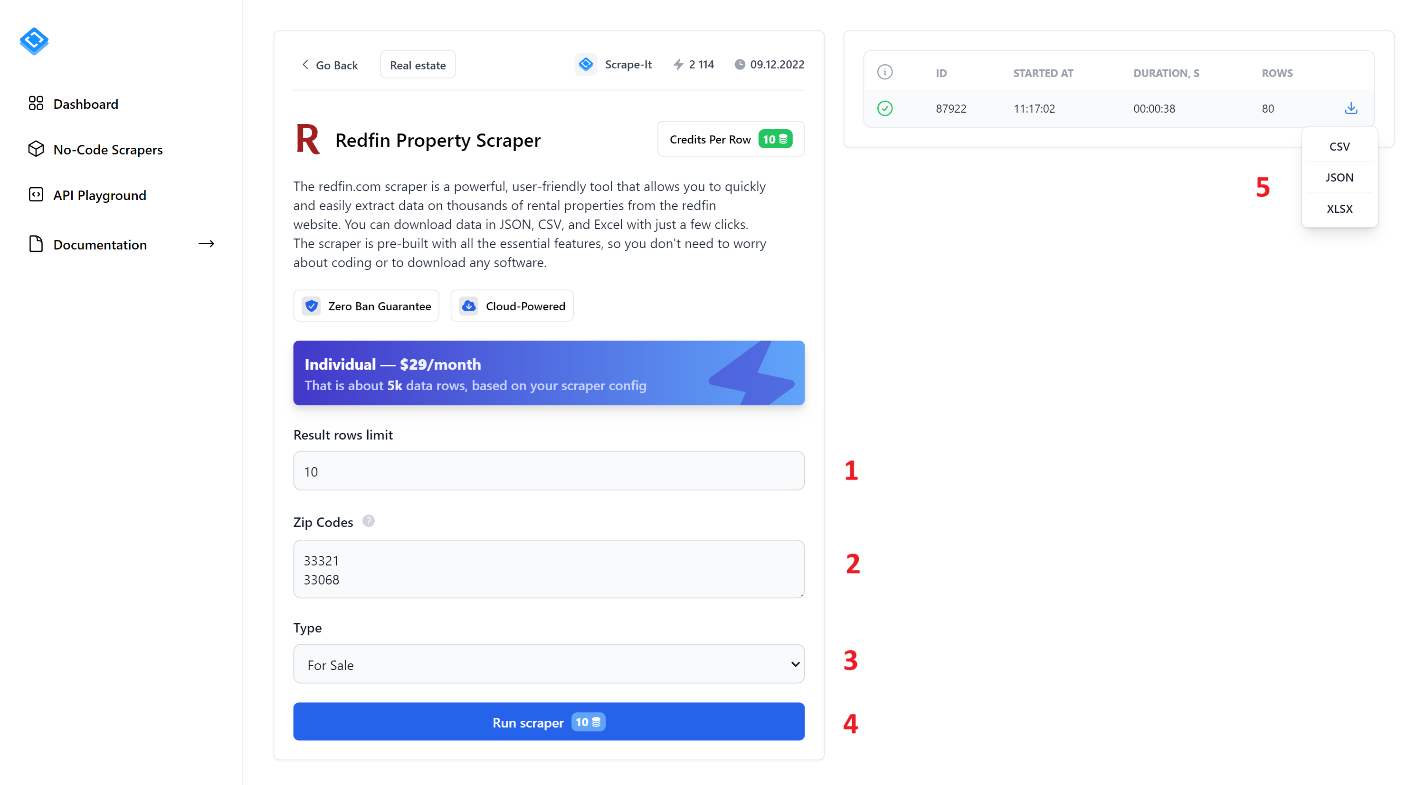
Untuk mengekstrak data, isi semua kolom dan klik tombol Run Scraper. Mari kita lihat lebih dekat elemen scraper tanpa kode:
- Batas baris hasil. Tentukan jumlah entri yang ingin Anda kikis.
- Kode pos. Masukkan kode pos tempat Anda ingin mengekstrak datanya. Anda dapat memasukkan beberapa kode pos, masing-masing pada baris baru.
- Jenis. Pilih jenis daftar: Dijual, Disewakan atau Dijual.
- Jalankan pengikisKlik tombol ini untuk memulai proses pengikisan.
- Setelah Anda memulai scraper, bilah kemajuan dan hasil scraping akan ditampilkan di panel kanan. Setelah selesai, Anda dapat mendownload hasilnya dalam salah satu format yang tersedia: CSV, JSON atau XLSX.
Hasilnya, Anda akan menerima file dengan semua data yang dikumpulkan berdasarkan permintaan Anda. Misalnya, hasilnya mungkin terlihat seperti ini:
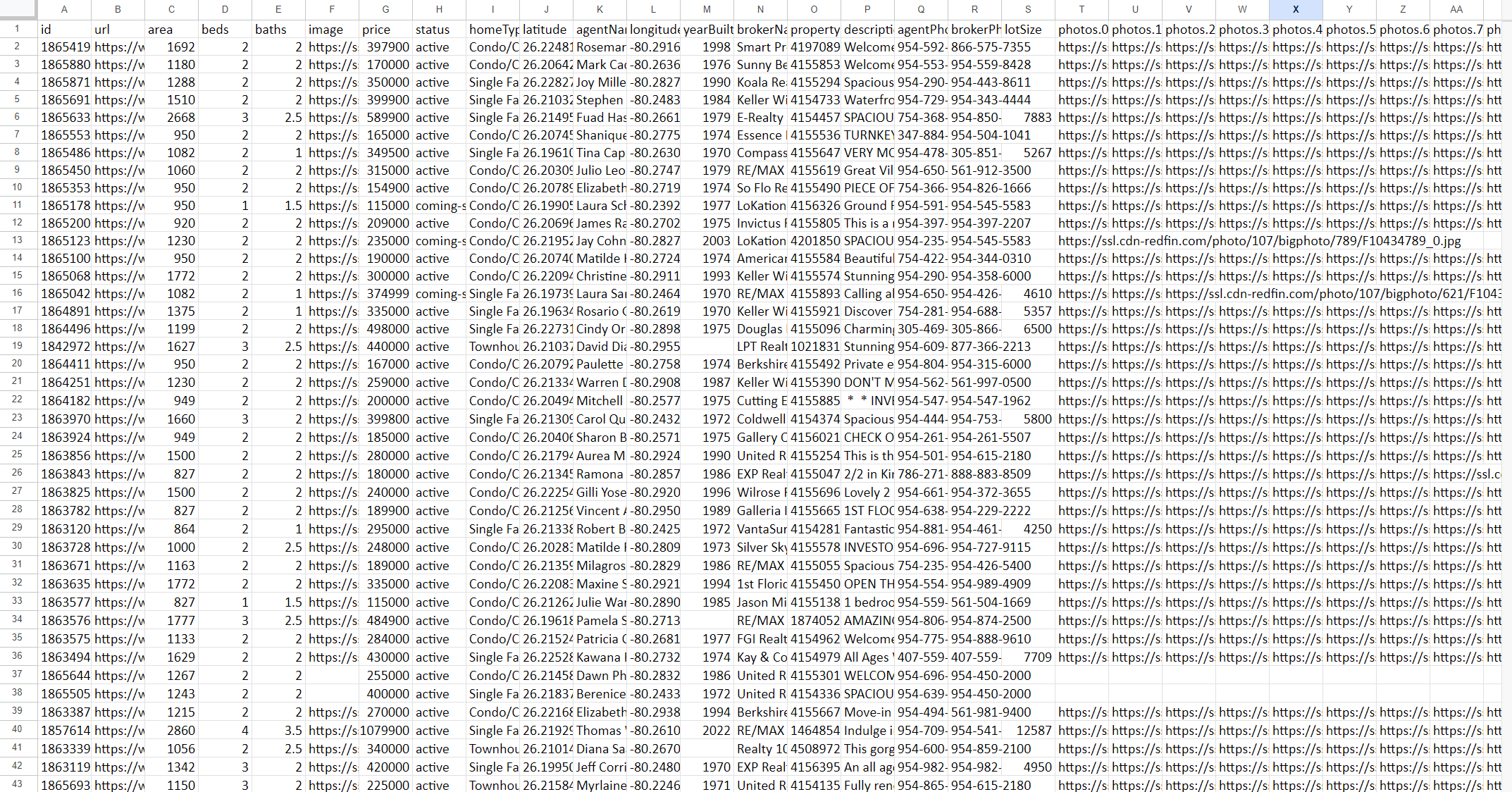
Tangkapan layar hanya menampilkan beberapa kolom karena berisi data dalam jumlah besar. Berikut ini contoh tampilan data dalam format JSON:
{
"properties": (
{
"id": "",
"url": "",
"area": ,
"beds": ,
"baths": ,
"image": "",
"price": ,
"photos": (),
"status": "",
"address": {
"city": "",
"state": "",
"street": "",
"zipcode": ""
},
"homeType": "",
"latitude": ,
"agentName": "",
"longitude": ,
"yearBuilt": ,
"brokerName": "",
"propertyId": ,
"description": "",
"agentPhoneNumber": "",
"brokerPhoneNumber": ""
}
)
}Secara keseluruhan, penggunaan alat pengikis web tanpa kode dapat menyederhanakan proses pengumpulan data dari situs web secara signifikan dan membuatnya dapat diakses oleh banyak pengguna tanpa memerlukan pengetahuan pengkodean apa pun.
Metode 2: Kikis data properti Redfin dengan Python
Sebelum kami mengikis data, kami memeriksa data spesifik yang dapat kami ekstrak dari Redfin. Untuk melakukan ini, kita menavigasi ke situs web dan membuka DevTools (F12 atau klik kanan dan periksa) untuk segera mengidentifikasi pemilih untuk elemen yang kita minati. Kami akan membutuhkan informasi ini nanti. Pertama, mari kita lihat halaman daftar.
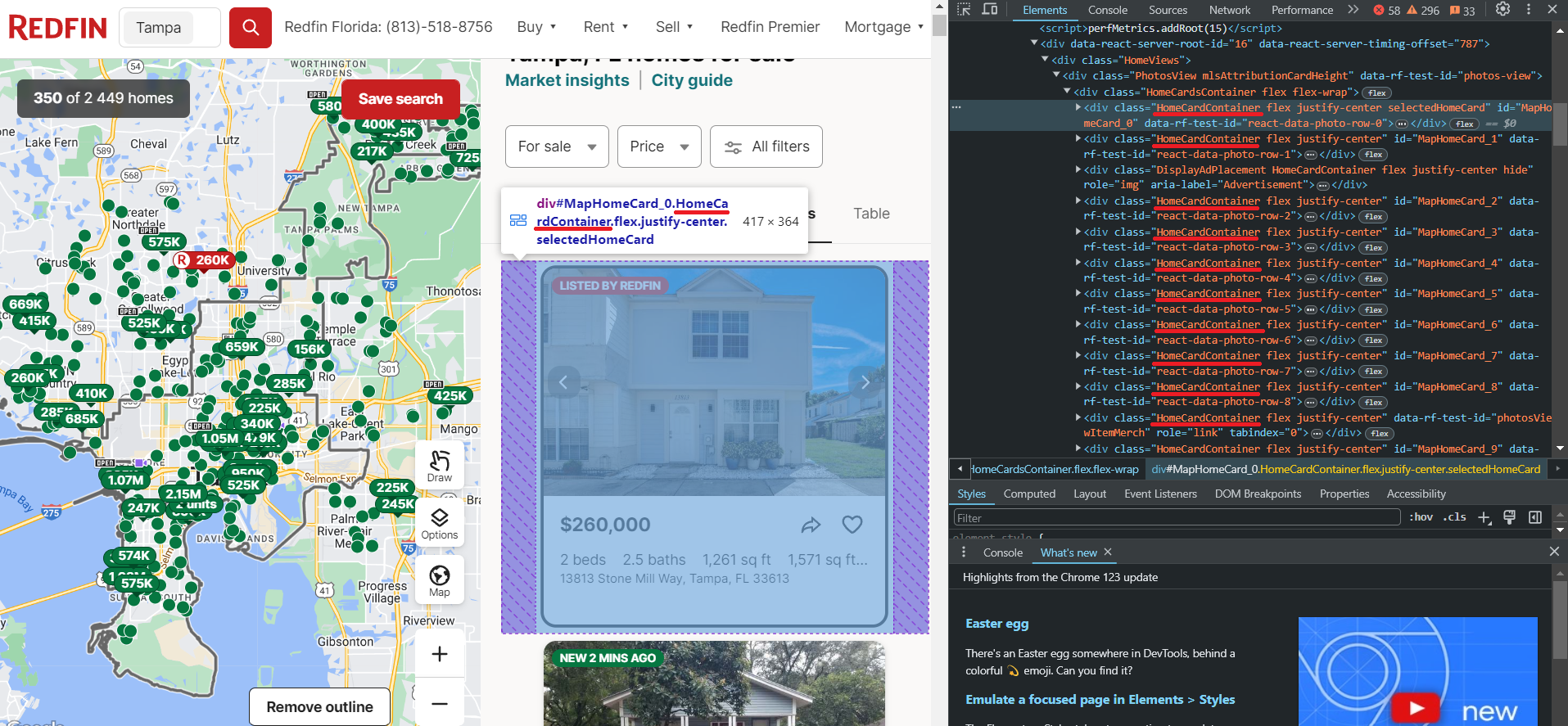
Seperti yang bisa kita lihat, properti berada dalam wadah dengan tag div dan memiliki kelas HomeCardContainer. Artinya cukup mengambil semua elemen dengan tag dan kelas ini untuk menampilkan semua iklan di halaman.
Sekarang mari kita lihat lebih dekat satu properti. Karena semua elemen pada laman memiliki struktur yang sama, apa yang berhasil untuk satu elemen akan berhasil untuk semua elemen lainnya.
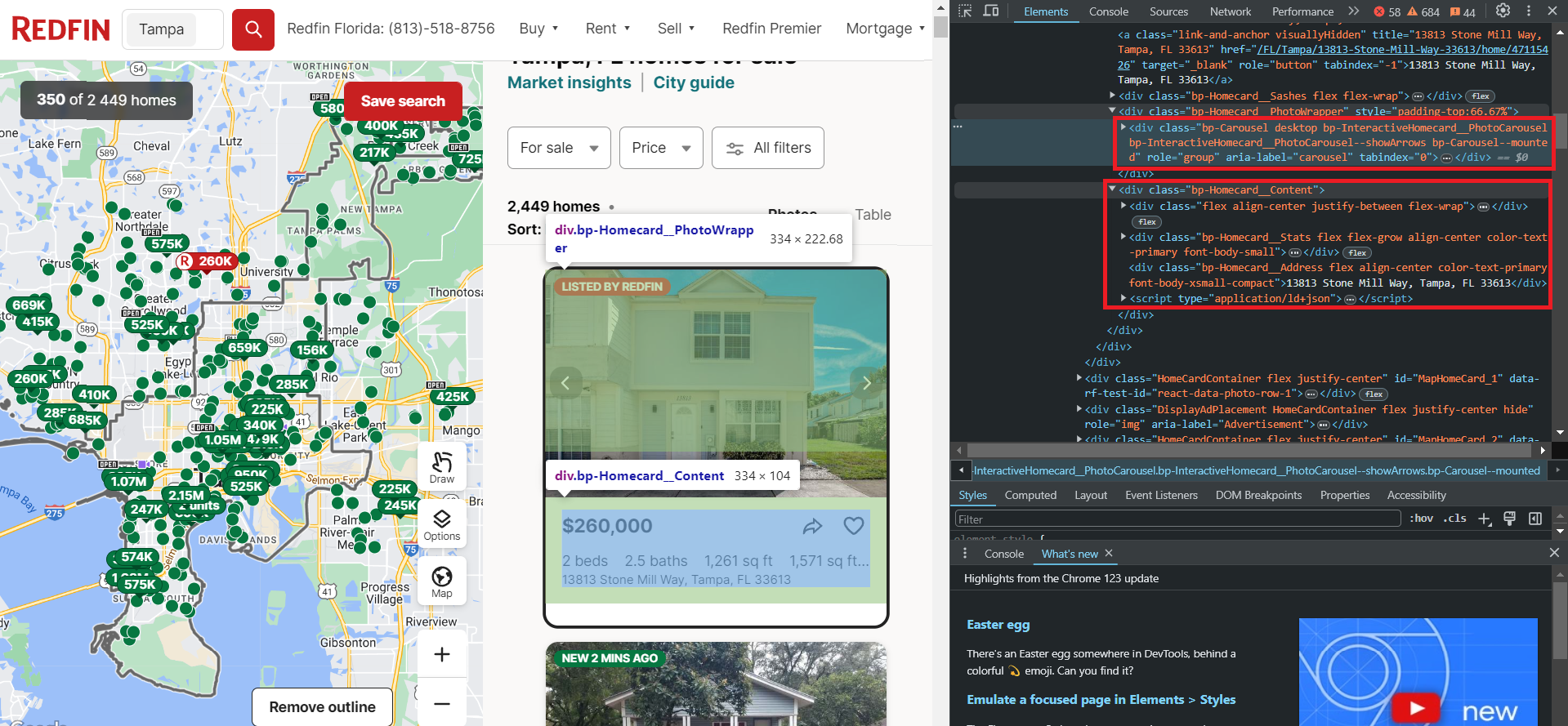
Seperti yang Anda lihat, data disimpan dalam dua blok. Blok pertama berisi gambar listing, sedangkan blok kedua berisi data teks, termasuk informasi harga, jumlah kamar, fasilitas, alamat, dan lainnya.
Perhatikan script Tag yang berisi semua data teks ini terstruktur dengan jelas dalam format JSON. Namun, untuk mengekstrak data ini Anda perlu menggunakan perpustakaan yang mendukung browser tanpa kepala, seperti Selenium, Pyppeteer, atau Playwright.
Sekarang mari beralih ke halaman daftar itu sendiri. Ada lebih banyak informasi yang tersedia di sini, tetapi untuk mengikisnya Anda harus menelusuri semua halaman ini. Ini bisa sangat sulit tanpa layanan proxy dan penyelesaian captcha karena semakin banyak permintaan yang Anda buat, semakin tinggi risiko pemblokiran.
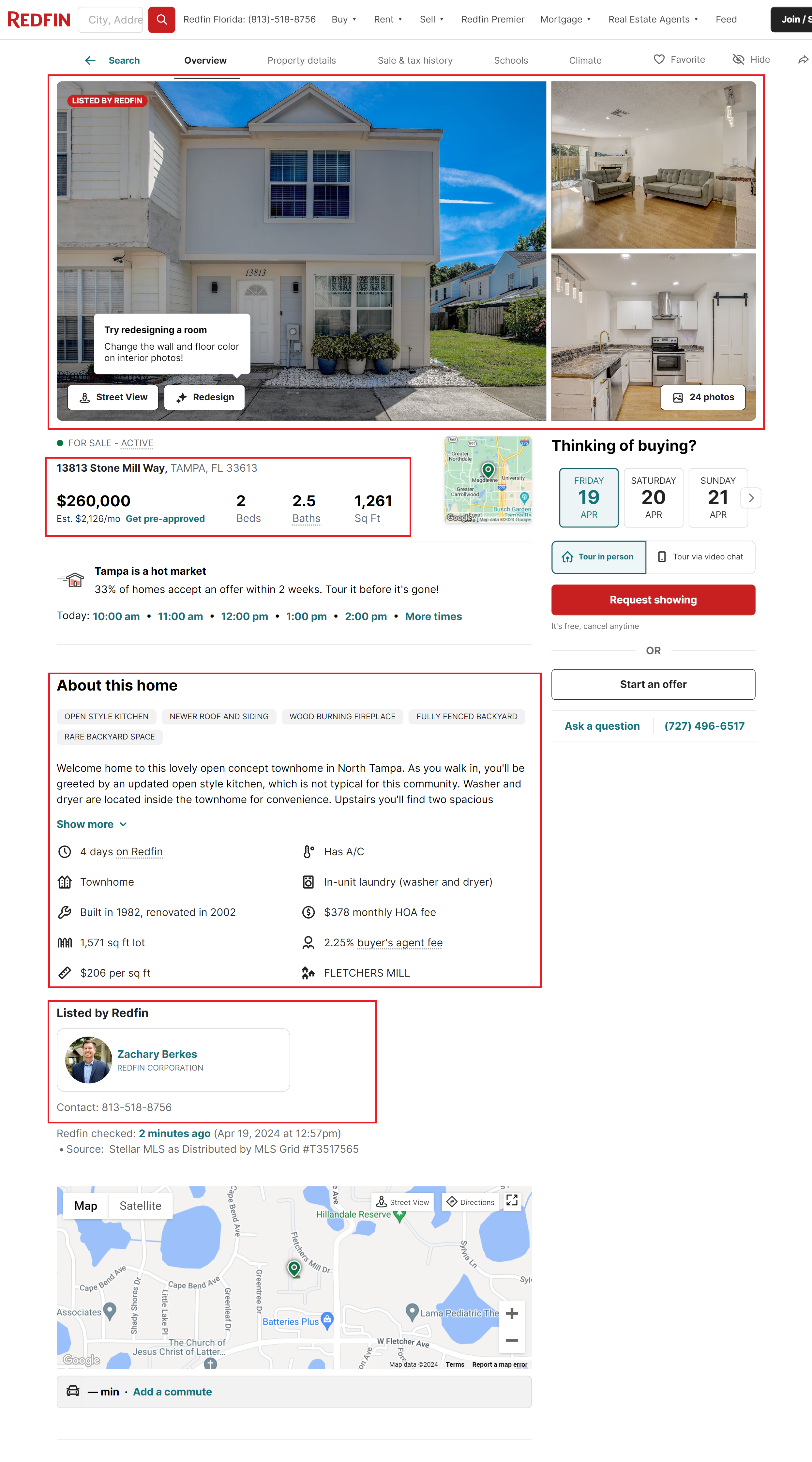
Informasi terpenting yang dapat ditemukan di halaman ini meliputi:
- Foto-foto. Semua gambar terkandung dalam satu wadah. Biasanya setiap entri memiliki banyak gambar.
- Informasi masuk dasar. Informasi ini sama dengan informasi yang dapat ditemukan di halaman daftar itu sendiri.
- Detail properti. Informasi tambahan tentang properti, termasuk tahun pembuatan, deskripsi, dan lainnya.
- Informasi pialang. Bagian ini berisi rincian tentang broker, termasuk informasi kontak mereka dan link ke halaman profil mereka.
Untuk mengambil semua informasi ini, Anda perlu mengidentifikasi penyeleksi atau XPath untuk setiap elemen di semua blok, atau menggunakan Redfin API yang sudah dibuat sebelumnya, yang mengembalikan data yang telah diformat sebelumnya.
Menyiapkan lingkungan pengembangan Anda
Sekarang mari kita siapkan perpustakaan yang diperlukan untuk membuat scraper kita sendiri. Pada artikel ini kami menggunakan Python versi 3.12.2. Untuk mempelajari cara menginstal Python dan menggunakan lingkungan virtual, lihat artikel Pengantar Python Scraping kami. Selanjutnya, instal perpustakaan yang diperlukan:
pip install requests beautifulsoup4 seleniumUntuk menggunakan Selenium, Anda mungkin juga perlu mengunduh driver web. Namun, hal ini tidak lagi diperlukan untuk versi Selenium terbaru. Jika Anda menggunakan perpustakaan versi sebelumnya, Anda dapat menemukan semua tautan penting di artikel tentang scraping dengan Selenium. Untuk bekerja dengan browser tanpa kepala, Anda juga dapat memilih perpustakaan lainnya.
Ambil data dengan kueri dan BS4
Anda dapat melihat dan menjalankan skrip versi final di Google Colaboratory. Buat file dengan ekstensi *.py tempat kita akan menulis skrip kita. Sekarang mari kita impor perpustakaan yang diperlukan.
import requests
from bs4 import BeautifulSoupBuat variabel untuk menyimpan URL halaman daftar:
url = "https://www.redfin.com/city/18142/FL/Tampa"Sebelum kita melanjutkan, mari kita uji kuerinya dan lihat bagaimana respons situs web:
response = requests.get(url)
print(response.content)Hasilnya, kami menerima tanggapan dari situs yang berisi informasi berikut:
There seems to be an issue...
Our usage behavior algorithm thinks you might be a robot.
Ensure you are accessing Redfin.com according to our terms of usage.
Tips:
- If you are using a VPN, pause it while browsing Redfin.com.
- Make sure you have Javascript enabled in your web browser.
- Ensure your browser is up to date.Untuk menghindari masalah ini, kami menambahkan agen pengguna ke permintaan kami. Untuk informasi lebih lanjut mengenai apa itu agen pengguna, mengapa mereka penting, dan daftar agen pengguna terbaru, lihat artikel kami yang lain.
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers)Permintaan sekarang berfungsi dengan benar dan situs web mengembalikan data properti. Mari kita periksa apakah kode status responsnya adalah 200, yang menunjukkan eksekusi berhasil, lalu analisis hasilnya:
if response.status_code == 200:
soup = BeautifulSoup(response.content, "html.parser")Sekarang mari kita gunakan penyeleksi yang kita bahas di bagian sebelumnya untuk mengambil data yang diperlukan:
homecards = soup.find_all("div", class_="bp-Homecard__Content")
for card in homecards:
if (card.find("a", class_="link-and-anchor")):
link = card.find("a", class_="link-and-anchor")("href")
full_link = "https://www.redfin.com" + link
price = card.find("span", class_="bp-Homecard__Price--value").text.strip()
beds = card.find("span", class_="bp-Homecard__Stats--beds").text.strip()
baths = card.find("span", class_="bp-Homecard__Stats--baths").text.strip()
address = card.find("div", class_="bp-Homecard__Address").text.strip()Cetak di layar:
print("Link:", full_link)
print("Price:", price)
print("Beds:", beds)
print("Baths:", baths)
print("Address:", address)
print()Hasilnya, kami mendapatkan 40 objek real estat dengan semua data yang diperlukan dalam format yang mudah digunakan:
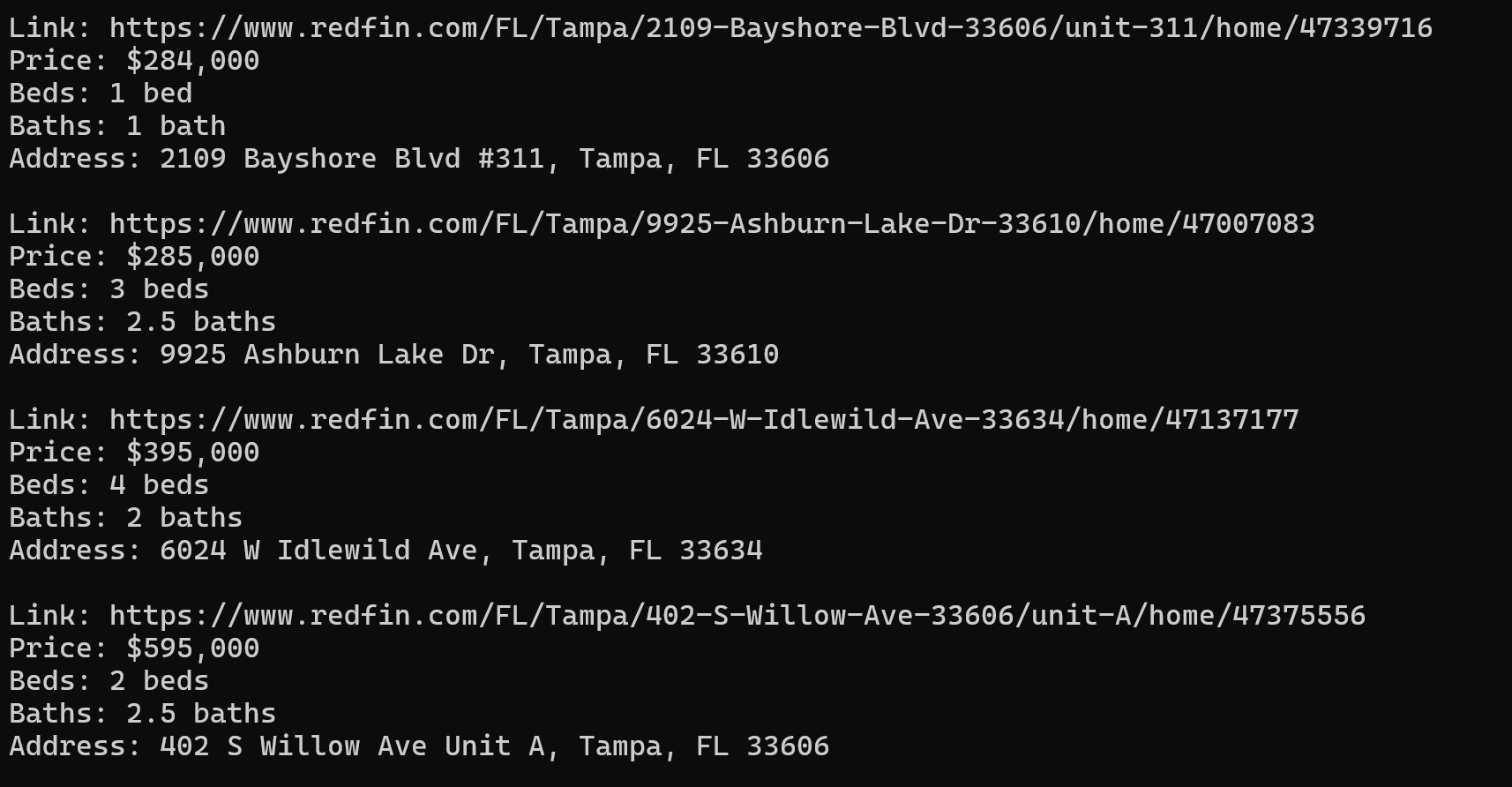
Jika Anda ingin menyimpannya, buatlah variabel di awal skrip untuk menyimpannya:
properties = ()Daripada mencetak data ke layar, simpan data dalam variabel:
properties.append({
"Price": price,
"Beds": beds,
"Baths": baths,
"Address": address,
"Link": full_link
})Langkah selanjutnya bergantung pada format mana Anda ingin menyimpan data. Agar tidak terulang lagi, hal ini akan kami bahas lebih detail pada bagian pengolahan dan penyimpanan data.
Menangani konten dinamis dengan Selenium
Mari kita lakukan hal yang sama dengan Selenium. Kami juga telah mengunggah skrip ini ke situs Colab Research, tetapi Anda hanya dapat menjalankannya di PC Anda sendiri karena Google Colaboratory tidak mengizinkan browser tanpa kepala untuk berjalan.
Kali ini, daripada menggunakan penyeleksi dan memilih semua elemen satu per satu, kita akan menggunakan JSON yang kita lihat sebelumnya dan menggabungkan semuanya ke dalam satu file. Anda juga dapat menghapus atribut yang tidak diperlukan atau membuat JSON Anda sendiri dengan struktur Anda sendiri hanya dengan menggunakan atribut yang diperlukan.
Mari buat file baru dan impor semua modul Selenium dan perpustakaan yang diperlukan untuk pemrosesan JSON.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import jsonSekarang kita mengatur parameter Selenium, menentukan jalur ke driver web dan juga menentukan mode tanpa kepala:
chrome_driver_path = "C:\driver\chromedriver.exe"
chrome_options = Options()
chrome_options.add_argument("--headless")
service = Service(chrome_driver_path)
service.start()
driver = webdriver.Remote(service.service_url, options=chrome_options)Berikan tautan ke halaman daftar:
url = "https://www.redfin.com/city/18142/FL/Tampa"Mari buka halaman properti dan tambahkan blok coba untuk mencegah skrip keluar jika terjadi kesalahan:
try:
driver.get(url)
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CLASS_NAME, "HomeCardContainer")))
homecards = driver.find_elements(By.CLASS_NAME, "bp-Homecard__Content")
properties = ()Ulangi semua kartu produk dan kumpulkan JSON:
for card in homecards:
script_element = card.find_element(By.TAG_NAME, "script")
json_data = json.loads(script_element.get_attribute("innerHTML"))
properties.extend(json_data) Anda kemudian dapat melanjutkan pemrosesan objek JSON atau menyimpannya. Pada akhirnya kita harus menyelesaikan pekerjaan driver web:
finally:
driver.quit()Ini adalah contoh file JSON yang kami dapatkan sebagai hasilnya:
(
{
"@context": "http://schema.org",
"name": "13813 Stone Mill Way, Tampa, FL 33613",
"url": "https://www.redfin.com/FL/Tampa/13813-Stone-Mill-Way-33613/home/47115426",
"address": {
"@type": "PostalAddress",
"streetAddress": "13813 Stone Mill Way",
"addressLocality": "Tampa",
"addressRegion": "FL",
"postalCode": "33613",
"addressCountry": "US"
},
"geo": {
"@type": "GeoCoordinates",
"latitude": 28.0712008,
"longitude": -82.4771742
},
"numberOfRooms": 2,
"floorSize": {
"@type": "QuantitativeValue",
"value": 1261,
"unitCode": "FTK"
},
"@type": "SingleFamilyResidence"
},
…
)Pendekatan ini memungkinkan Anda mendapatkan data yang lebih komprehensif dengan cara yang lebih mudah. Selain itu, menggunakan browser tanpa kepala dapat mengurangi risiko pemblokiran karena memungkinkan Anda mensimulasikan perilaku pengguna sebenarnya dengan lebih baik.
Namun, perlu diingat bahwa jika Anda mengambil data dalam jumlah besar, situs tersebut mungkin masih memblokir Anda. Untuk menghindari hal ini, sambungkan proxy ke skrip Anda. Kami telah menjelaskan cara kerjanya di artikel terpisah tentang proxy.
Metode 3: Kikis Redfin menggunakan API
Sekarang mari kita pertimbangkan cara paling sederhana untuk mendapatkan data yang diperlukan. Opsi ini tidak memerlukan koneksi ke proxy atau layanan penyelesaian captcha dan mengembalikan data terlengkap dalam format respons JSON yang nyaman. Untuk melakukan ini, kami menggunakan Redfin API Hasdata, detail lengkapnya dapat ditemukan di dokumentasi.
Kikis entri menggunakan Redfin API
Karena API ini memiliki dua titik akhir, kami akan mempertimbangkan kedua opsi tersebut dan memulai dengan opsi yang mengembalikan data dengan koleksi karena kami telah mengumpulkan data ini menggunakan pustaka Python. Anda juga dapat menemukan skrip yang sudah jadi di Google Colaboratory.
Impor perpustakaan yang diperlukan:
import requests
import jsonKemudian masukkan kunci API HasData Anda:
api_key = "YOUR-API-KEY"Tetapkan parameter:
params = {
"keyword": "33321",
"type": "forSale"
}Selain kode pos dan tipe properti, Anda juga dapat menentukan jumlah halaman. Kemudian tentukan titik akhir itu sendiri:
url = "https://api.hasdata.com/scrape/redfin/listing"Tetapkan header dan minta API:
headers = {
"x-api-key": api_key
}
response = requests.get(url, params=params, headers=headers)Selanjutnya kita mengambil datanya dan jika kode responnya adalah 200, kita dapat memproses lebih lanjut atau menyimpan data yang diterima:
if response.status_code == 200:
properties = response.json()
if properties:
# Here you can process or save properties
else:
print("No listings found.")
else:
print("Failed to retrieve listings. Status code:", response.status_code)Hasilnya, kami mendapat respons di mana data disimpan dalam format berikut (untuk lebih jelasnya, sebagian besar data telah dihapus):
{
"requestMetadata": {
"id": "da2f6f99-d6cf-442d-b388-7d5a643e8042",
"status": "ok",
"url": "https://redfin.com/zipcode/33321"
},
"searchInformation": {
"totalResults": 350
},
"properties": (
{
"id": 186541913,
"mlsId": "F10430049",
"propertyId": 41970890,
"url": "https://www.redfin.com/FL/Tamarac/7952-Exeter-Blvd-W-33321/unit-101/home/41970890",
"price": 397900,
"address": {
"street": "7952 W Exeter Blvd W #101",
"city": "Tamarac",
"state": "FL",
"zipcode": "33321"
},
"propertyType": "Condo",
"beds": 2,
"baths": 2,
"area": 1692,
"latitude": 26.2248143,
"longitude": -80.2916508,
"description": "Welcome Home to this rarely available & highly sought-after villa in the active 55+ community of Kings Point, Tamarac! This beautiful and spacious villa features volume ceilings…",
"photos": (
"https://ssl.cdn-redfin.com/photo/107/islphoto/049/genIslnoResize.F10430049_0.jpg",
"https://ssl.cdn-redfin.com/photo/107/islphoto/049/genIslnoResize.F10430049_1_1.jpg"
)
},
…
}Seperti yang Anda lihat, menggunakan API untuk mengambil data jauh lebih mudah dan cepat. Selain itu, pendekatan ini memungkinkan Anda mendapatkan semua jenis data dari halaman tanpa harus mengekstraknya secara manual.
Mengikis properti menggunakan Redfin API
Sekarang mari kumpulkan data menggunakan endpoint lain (Hasil di Google Colaboratory) yang memungkinkan Anda mengambil data dari halaman properti tertentu. Ini bisa berguna, misalnya, jika Anda memiliki daftar entri dan perlu mengumpulkan data semuanya dengan cepat.
Keseluruhan skrip akan sangat mirip dengan yang sebelumnya. Hanya parameter permintaan dan titik akhir itu sendiri yang akan berubah:
url = "https://api.hasdata.com/scrape/redfin/property"
params = {
"url": "https://www.redfin.com/IL/Chicago/1322-S-Prairie-Ave-60605/unit-1106/home/12694628"
}Scriptnya tetap sama. API mengembalikan semua data yang tersedia untuk properti tertentu.
Pemrosesan dan penyimpanan data
Untuk menyimpan data, kita memerlukan perpustakaan tambahan tergantung formatnya. Kami menyimpan data kami dalam dua format paling umum: JSON dan CSV. Untuk melakukan ini, kami mengimpor perpustakaan tambahan ke dalam proyek:
import json
import csvSelanjutnya, kita menyimpan data dari variabel yang dibuat sebelumnya ke file yang sesuai:
with open("properties.json", "w") as json_file:
json.dump(properties, json_file, indent=4)
keys = properties(0).keys()
with open("properties.csv", "w", newline="", encoding="utf-8") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=keys)
writer.writeheader()
writer.writerows(properties)Dengan menggunakan metode ini kita dapat menyimpan semua data penting. Jika Anda ingin mengoptimalkan proses penyimpanan data atau menyimpan dalam format berbeda, Anda dapat menggunakan perpustakaan Pandas.
Diploma
Dalam artikel ini, kami memeriksa metode paling populer untuk memperoleh data real estate dari Redfin dan membahas berbagai teknologi dan alat, seperti BeautifulSoup dan Selenium, yang mengekstrak informasi dari situs web. Hal ini memudahkan untuk mendapatkan data harga, alamat, jumlah kamar tidur dan kamar mandi, serta karakteristik properti lainnya. Anda juga dapat melihat tutorial kami tentang cara mengikis Zillow dengan Python untuk mengetahui lebih banyak data real estat.
Semua skrip yang dibahas telah diunggah ke Google Colaboratory sehingga Anda dapat dengan mudah mengakses dan menjalankannya tanpa harus menginstal Python di PC Anda (kecuali untuk contoh browser headless yang tidak dapat dijalankan dari cloud). Pendekatan ini memungkinkan Anda untuk menggunakan semua skrip yang dibahas, meskipun Anda tidak terlalu paham dengan pemrograman.
Selain itu, kami juga memberikan contoh bagaimana Anda dapat menggunakan scraper tanpa kode untuk mengambil data bahkan tanpa pengetahuan pemrograman apa pun. Jika Anda ingin mendapatkan data dari Hasdata menggunakan Redfin API tetapi tidak ingin menulis skrip, Anda dapat menggunakan API Playground kami.