
Redfin ist eine Online-Plattform, die Immobilieninformationen bereitstellt, darunter Verkaufs- und Mietangebote, Marktdaten und Suchfunktionen. Ziel ist es, Kunden den Kauf, Verkauf oder die Miete eines Hauses zu erleichtern, indem sie Zugriff auf eine umfangreiche Datenbank mit Immobilien erhalten.
Durch Web Scraping kann der Prozess der konsistenten Datenerfassung von Redfin automatisiert werden. Dies ermöglicht die Analyse von Trends, die Bewertung von Immobilienwerten und Marktprognosen.
In diesem Artikel besprechen und demonstrieren wir anhand von Beispielen, wie Sie mit verschiedenen Methoden Daten von Redfin scrapen können. Dazu gehört das Erstellen eines eigenen Python-Scrapers, die Verwendung von No-Code-Scrapern und die Nutzung der inoffiziellen Redfin-API. Jeder dieser Ansätze hat seine eigenen Vor- und Nachteile und die Wahl hängt von den spezifischen Bedürfnissen und Fähigkeiten des Benutzers ab.
Auswählen einer Scraping-Methode
Wie bereits erwähnt, gibt es mehrere Möglichkeiten, Daten von Redfin zu sammeln. Bevor wir uns mit den Einzelheiten der einzelnen Methoden befassen, werfen wir einen kurzen Überblick über die verfügbaren Optionen, von der einfachsten und anfängerfreundlichsten bis hin zur fortgeschritteneren:
- Manuelles Scraping. Diese Methode ist kostenlos, aber zeitaufwändig und eignet sich nur zum Sammeln kleiner Datenmengen. Dabei müssen relevante Seiten manuell durchsucht und die gewünschten Informationen extrahiert werden.
- No-Code-Scraper. Diese Dienste bieten Tools zur Datenerfassung ohne Programmierkenntnisse. Sie sind ideal für Benutzer, die die Daten einfach benötigen, ohne sie in eine Anwendung zu integrieren. Geben Sie einfach die Parameter im Redfin No-Code Scraper an und erhalten Sie den Datensatz.
- Tools zur Browserautomatisierung. Erweiterungen können verwendet werden, um Daten von Redfin zu sammeln. Im Gegensatz zu No-Code-Scrapern muss das Browserfenster jedoch während des Scraping-Vorgangs geöffnet sein und kann erst geschlossen werden, wenn der Vorgang abgeschlossen ist.
- Redfin-API. Redfin hat keine offizielle API, daher müssen Sie inoffizielle Alternativen verwenden. Anweisungen und Codebeispiele stellen wir später zur Verfügung.
- Erstellen Sie Ihren eigenen Schaber ist die komplexeste Methode. Während die Verwendung der Redfin-API das Festlegen von Parametern und den Empfang gut strukturierter Datensätze beinhaltet, erfordert die Erstellung eines eigenen Scrapers den Umgang mit Captchas, Bot-Schutz und Proxys, um IP-Blockierungen beim Scraping großer Datenmengen zu verhindern.
Alle in Betracht gezogenen Optionen haben Vor- und Nachteile, daher sollte die Wahl je nach Ihren Anforderungen getroffen werden. Kurz gesagt, wenn Sie nur Daten aus einigen wenigen Einträgen benötigen, erfassen Sie diese einfach manuell. Wenn Sie Daten aus einer großen Anzahl von Einträgen erfassen müssen, aber keine Programmiererfahrung haben, ist der Redfin No-Code Scraper eine großartige Option. Und wenn Sie die Datenerfassung in Ihre Anwendung integrieren möchten und sich nicht mit dem Datenabruf herumschlagen oder den Bot-Schutz von Redfin umgehen möchten, ist die Redfin API genau das Richtige für Sie.
Wenn Sie jedoch selbst Daten erfassen möchten und über die Fähigkeiten und die Zeit verfügen, alle damit verbundenen Probleme zu lösen, erstellen Sie Ihren eigenen Redfin-Scraper in Python oder einer anderen Programmiersprache.
Methode 1: Daten von Redfin ohne Code scrapen
No-Code-Web-Scraping-Tools sind Softwarelösungen, mit denen Benutzer Daten von Websites extrahieren können, ohne Code schreiben zu müssen. Sie bieten eine einfache und intuitive Benutzeroberfläche, mit der Benutzer die benötigten Daten mit wenigen Klicks abrufen können.
Da keine Programmierkenntnisse oder -kenntnisse erforderlich sind, kann jeder einen No-Code Scraper von Redfin verwenden. Diese Methode ist auch eine der sichersten, da die Daten von Redfin nicht von Ihrem PC gesammelt werden, sondern von dem Dienst, der den No-Code Scraper bereitstellt. Sie erhalten nur den vorgefertigten Datensatz und schützen sich vor einer möglichen Sperrung durch Redfin.
Schauen wir uns die Verwendung solcher Tools am Beispiel des No-Code-Scrapers Redfin von HasData genauer an. Melden Sie sich dazu auf unserer Website an und gehen Sie zu Ihrem Konto.
Navigieren Sie zur Registerkarte „No-Code Scrapers“ und suchen Sie den „Redfin Property Scraper“. Klicken Sie darauf, um zur Seite des Scrapers zu gelangen.
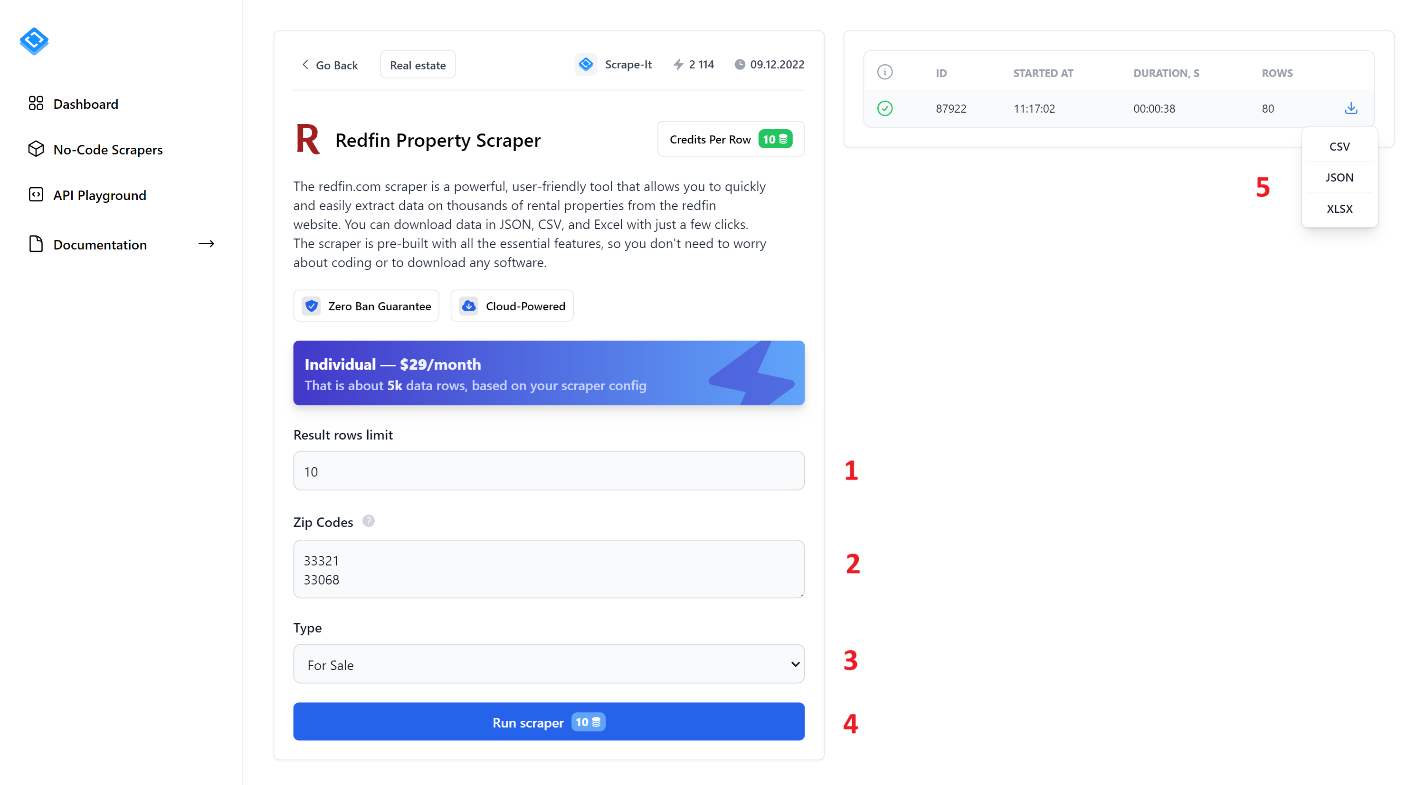
Um Daten zu extrahieren, füllen Sie alle Felder aus und klicken Sie auf die Schaltfläche „Scraper ausführen“. Schauen wir uns die No-Code-Scraper-Elemente genauer an:
- Ergebniszeilenlimit. Geben Sie die Anzahl der Einträge an, die Sie scrapen möchten.
- Postleitzahlen. Geben Sie die Postleitzahlen ein, aus denen Sie Daten extrahieren möchten. Sie können mehrere Postleitzahlen eingeben, jede in einer neuen Zeile.
- Typ. Wählen Sie den Listentyp: Zu verkaufen, Zu vermieten oder Verkauft.
- Scraper ausführenKlicken Sie auf diese Schaltfläche, um den Scraping-Vorgang zu starten.
- Nachdem Sie den Scraper gestartet haben, werden im rechten Bereich der Fortschrittsbalken und die Scraping-Ergebnisse angezeigt. Sobald Sie fertig sind, können Sie die Ergebnisse in einem der verfügbaren Formate herunterladen: CSV, JSON oder XLSX.
Als Ergebnis erhalten Sie eine Datei mit allen Daten, die aufgrund Ihrer Anfrage erhoben wurden. Das Ergebnis kann beispielsweise so aussehen:
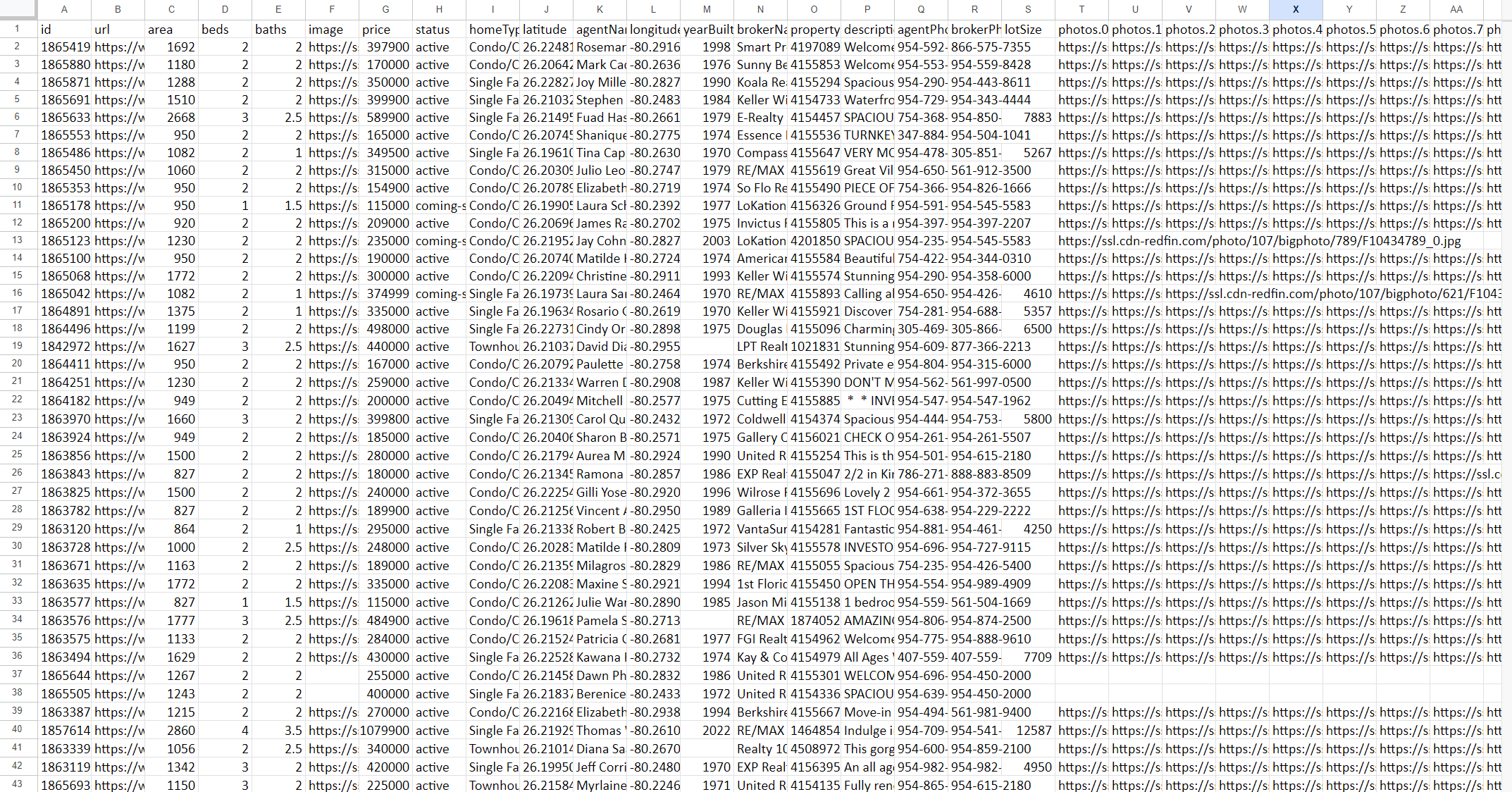
Der Screenshot zeigt nur einige der Spalten, da es sich um eine große Datenmenge handelt. Hier ist ein Beispiel, wie die Daten im JSON-Format aussehen würden:
{
"properties": (
{
"id": "",
"url": "",
"area": ,
"beds": ,
"baths": ,
"image": "",
"price": ,
"photos": (),
"status": "",
"address": {
"city": "",
"state": "",
"street": "",
"zipcode": ""
},
"homeType": "",
"latitude": ,
"agentName": "",
"longitude": ,
"yearBuilt": ,
"brokerName": "",
"propertyId": ,
"description": "",
"agentPhoneNumber": "",
"brokerPhoneNumber": ""
}
)
}Insgesamt kann die Verwendung von Web Scraping Tools ohne Code den Prozess der Datenerfassung von Websites erheblich rationalisieren und sie einem breiten Benutzerkreis zugänglich machen, ohne dass Programmierkenntnisse erforderlich sind.
Methode 2: Scrapen von Redfin-Eigenschaftsdaten mit Python
Bevor wir Daten scrapen, untersuchen wir die spezifischen Daten, die wir aus Redfin extrahieren können. Dazu navigieren wir zur Website und öffnen DevTools (F12 oder Rechtsklick und Untersuchen), um sofort die Selektoren für die Elemente zu identifizieren, an denen wir interessiert sind. Wir werden diese Informationen später benötigen. Sehen wir uns zunächst die Listings-Seite an.
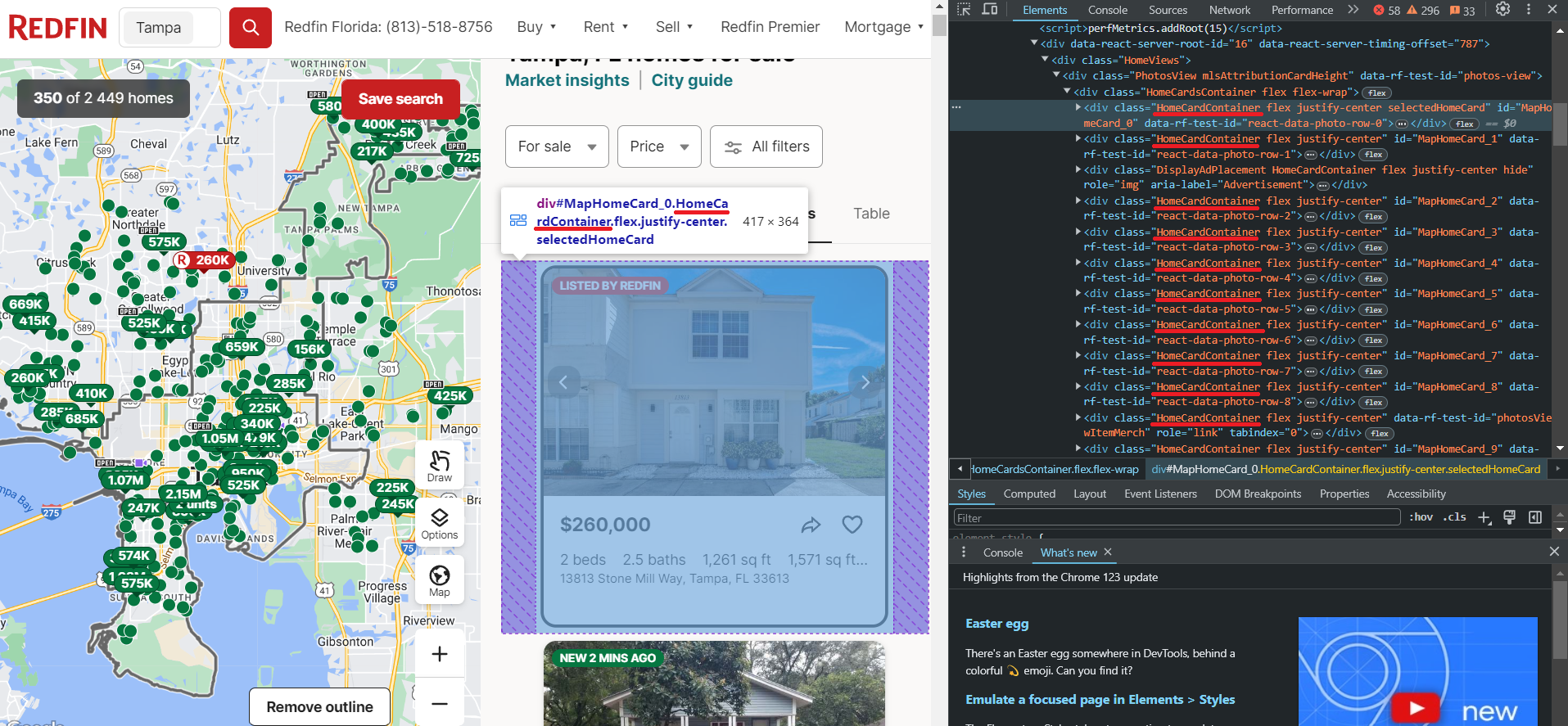
Wie wir sehen, befinden sich die Eigenschaften in Containern mit dem Tag div und haben die Klasse HomeCardContainer. Dies bedeutet, dass es ausreicht, alle Elemente mit diesem Tag und dieser Klasse abzurufen, um alle Anzeigen auf der Seite anzuzeigen.
Schauen wir uns nun eine Eigenschaft genauer an. Da alle Elemente auf der Seite dieselbe Struktur haben, funktioniert das, was für ein Element funktioniert, auch für alle anderen.
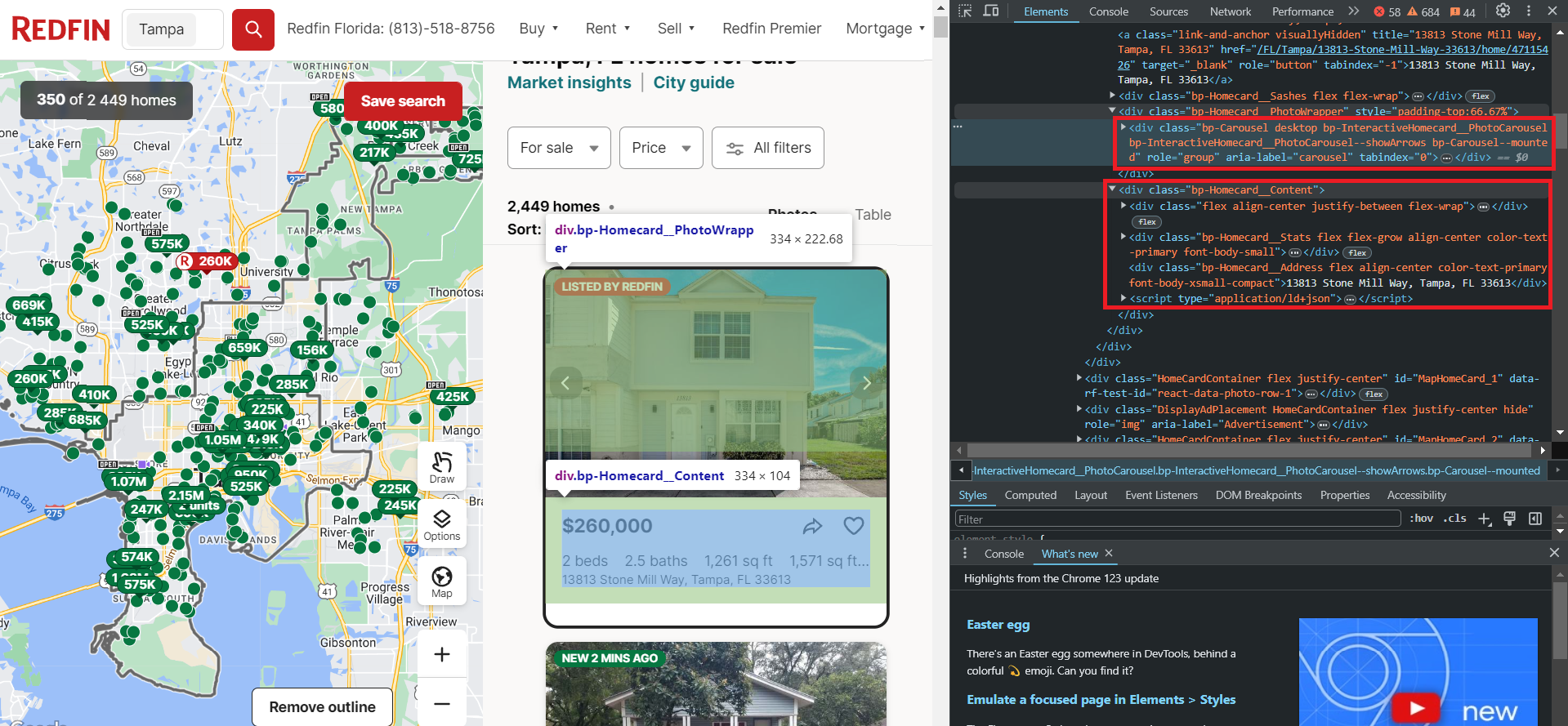
Wie Sie sehen, sind die Daten in zwei Blöcken gespeichert. Der erste Block enthält die Bilder für die Auflistung, während der zweite Block die Textdaten enthält, einschließlich Informationen zu Preis, Anzahl der Zimmer, Ausstattung, Adresse und mehr.
Beachten Sie die script Tag, der alle diese Textdaten übersichtlich strukturiert im JSON-Format enthält. Um diese Daten zu extrahieren, müssen Sie jedoch Bibliotheken verwenden, die Headless-Browser unterstützen, wie Selenium, Pyppeteer oder Playwright.
Kommen wir nun zur Listing-Seite selbst. Hier sind weitere Informationen verfügbar, aber um sie zu scrapen, müssen Sie durch all diese Seiten navigieren. Dies kann ohne Proxys und Captcha-Lösungsdienste recht schwierig sein, denn je mehr Anfragen Sie stellen, desto höher ist das Risiko, blockiert zu werden.
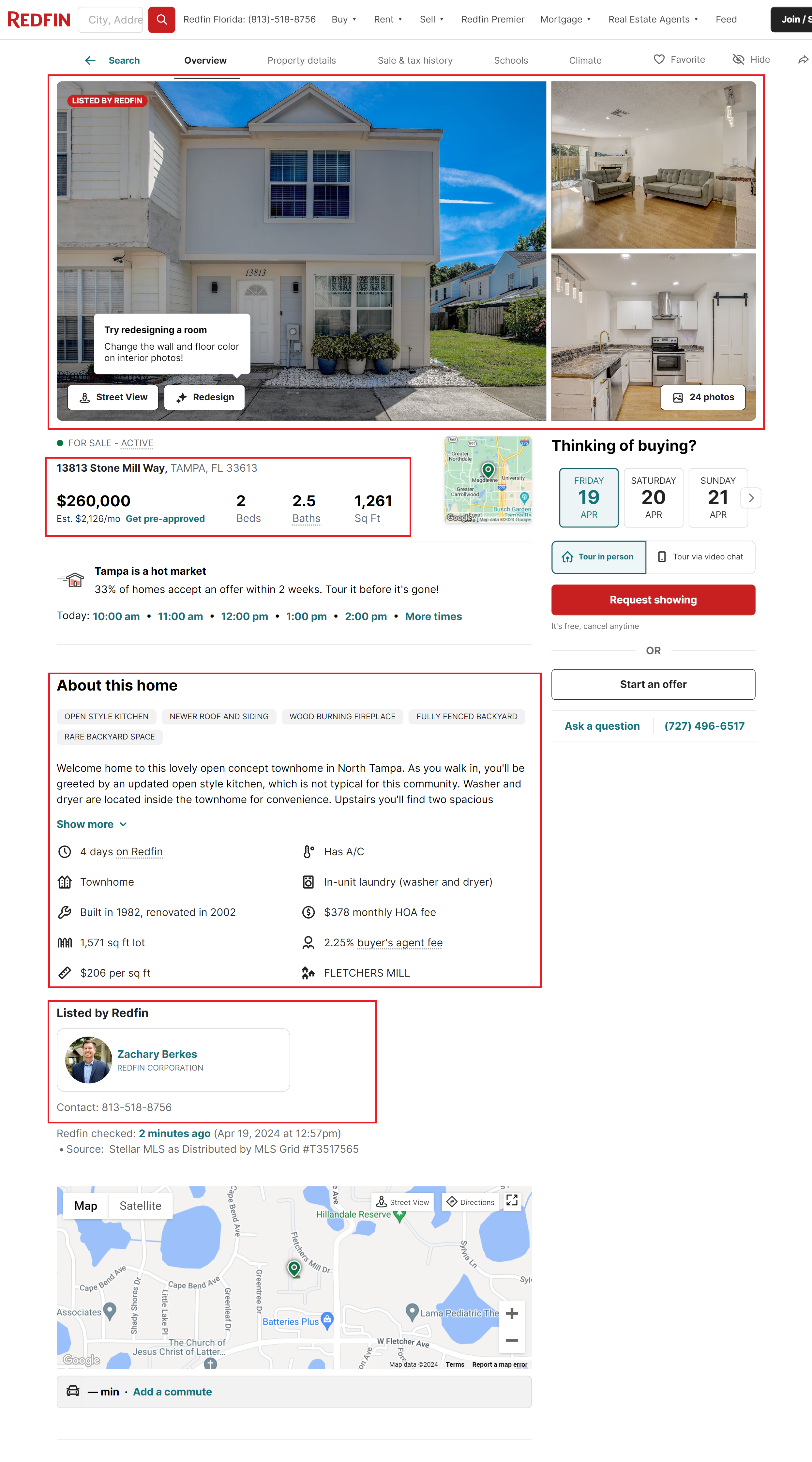
Zu den wichtigsten Informationen, die dieser Seite entnommen werden können, gehören:
- Bilder. Alle Bilder sind in einem einzigen Container enthalten. Normalerweise hat jeder Eintrag mehrere Bilder.
- Grundlegende Eintragsinformationen. Diese Informationen sind identisch mit denen, die auf der Listing-Seite selbst abgerufen werden können.
- Details der Immobilie. Zusätzliche Informationen zur Immobilie, einschließlich Baujahr, Beschreibung und mehr.
- Maklerinformationen. Dieser Abschnitt enthält Einzelheiten zum Makler, einschließlich seiner Kontaktinformationen und eines Links zu seiner Profilseite.
Um alle diese Informationen abzurufen, müssen Sie entweder Selektoren oder XPath für jedes Element in allen Blöcken identifizieren oder die vorgefertigte Redfin-API verwenden, die vorformatierte Daten zurückgibt.
Einrichten Ihrer Entwicklungsumgebung
Richten wir nun die erforderlichen Bibliotheken ein, um unseren eigenen Scraper zu erstellen. In diesem Artikel verwenden wir Python Version 3.12.2. Wie Sie Python installieren und eine virtuelle Umgebung verwenden, erfahren Sie in unserem Artikel zur Einführung in das Scraping mit Python. Installieren Sie als Nächstes die erforderlichen Bibliotheken:
pip install requests beautifulsoup4 seleniumUm Selenium nutzen zu können, muss unter Umständen zusätzlich ein Webdriver heruntergeladen werden. Für die neuesten Selenium-Versionen ist dies jedoch nicht mehr nötig. Falls du eine frühere Version der Bibliothek verwendest, findest du alle wichtigen Links im Artikel zum Scraping mit Selenium. Für die Arbeit mit einem Headless-Browser kannst du auch jede andere Bibliothek auswählen.
Daten abrufen mit Anfragen und BS4
Sie können die endgültige Version des Skripts in Google Colaboratory anzeigen und dort auch ausführen. Erstellen Sie eine Datei mit der Erweiterung *.py, in die wir unser Skript schreiben werden. Jetzt importieren wir die erforderlichen Bibliotheken.
import requests
from bs4 import BeautifulSoupErstellen Sie eine Variable zum Speichern der URL der Listings-Seite:
url = "https://www.redfin.com/city/18142/FL/Tampa"Bevor wir fortfahren, testen wir die Abfrage und sehen, wie die Website reagiert:
response = requests.get(url)
print(response.content)Als Ergebnis erhalten wir von der Website eine Antwort, die folgende Informationen enthält:
There seems to be an issue...
Our usage behavior algorithm thinks you might be a robot.
Ensure you are accessing Redfin.com according to our terms of usage.
Tips:
- If you are using a VPN, pause it while browsing Redfin.com.
- Make sure you have Javascript enabled in your web browser.
- Ensure your browser is up to date.Um dieses Problem zu vermeiden, fügen wir unserer Anfrage User-Agents hinzu. Weitere Informationen dazu, was User-Agents sind, warum sie wichtig sind und eine Liste der neuesten User-Agents finden Sie in unserem anderen Artikel.
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers)Die Anfrage funktioniert nun ordnungsgemäß und die Website gibt Eigenschaftsdaten zurück. Überprüfen wir, ob der Antwortstatuscode 200 lautet, was eine erfolgreiche Ausführung anzeigt, und analysieren wir dann das Ergebnis:
if response.status_code == 200:
soup = BeautifulSoup(response.content, "html.parser")Nutzen wir nun die Selektoren, die wir im vorherigen Abschnitt besprochen haben, um die erforderlichen Daten abzurufen:
homecards = soup.find_all("div", class_="bp-Homecard__Content")
for card in homecards:
if (card.find("a", class_="link-and-anchor")):
link = card.find("a", class_="link-and-anchor")("href")
full_link = "https://www.redfin.com" + link
price = card.find("span", class_="bp-Homecard__Price--value").text.strip()
beds = card.find("span", class_="bp-Homecard__Stats--beds").text.strip()
baths = card.find("span", class_="bp-Homecard__Stats--baths").text.strip()
address = card.find("div", class_="bp-Homecard__Address").text.strip()Drucken Sie sie auf dem Bildschirm aus:
print("Link:", full_link)
print("Price:", price)
print("Beds:", beds)
print("Baths:", baths)
print("Address:", address)
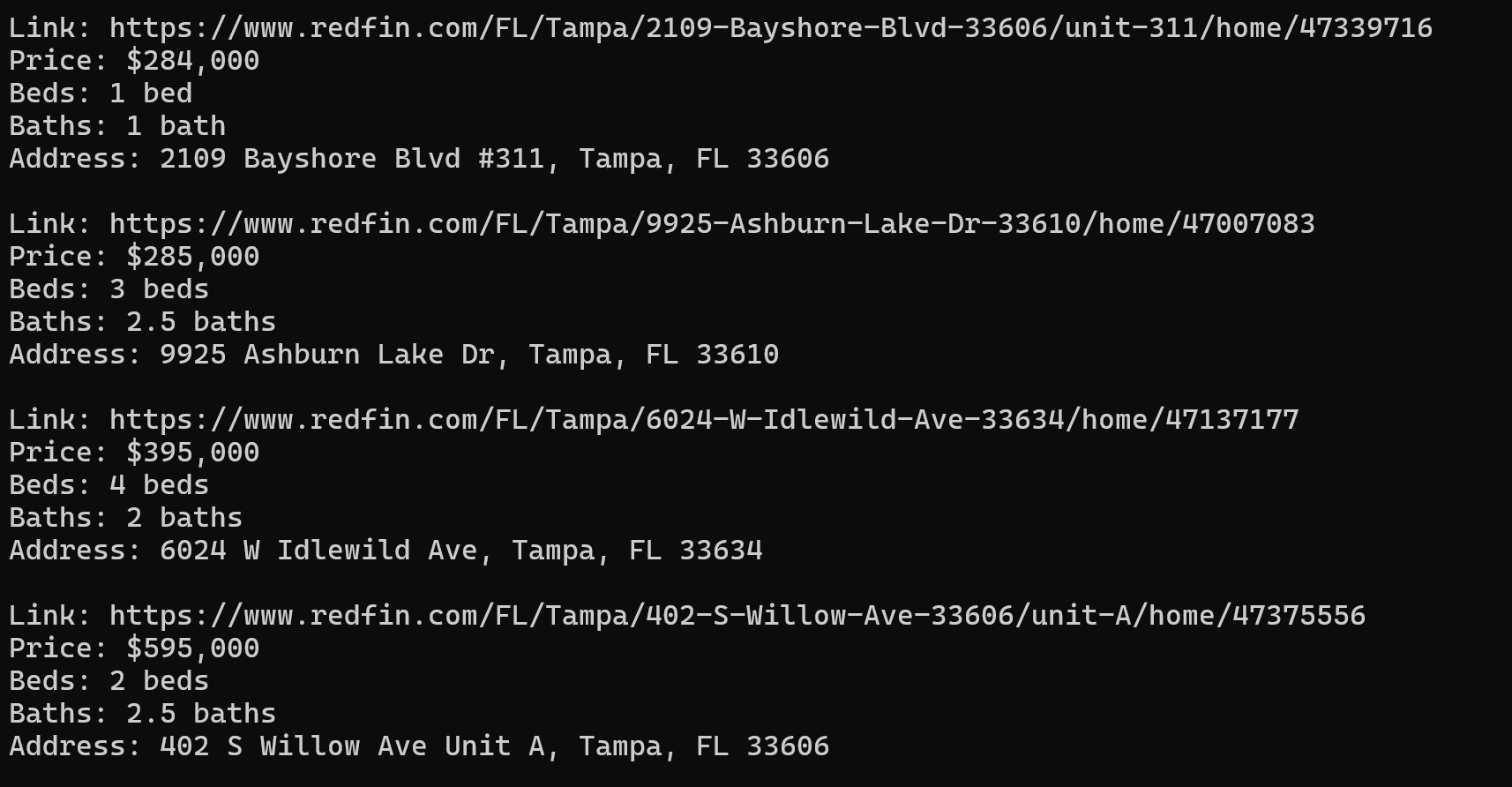
print()Als Ergebnis erhalten wir 40 Immobilienobjekte mit allen benötigten Daten in einem praktischen Format:
Wenn Sie sie speichern möchten, erstellen Sie am Anfang des Skripts eine Variable, um sie zu speichern:
properties = ()Anstatt die Daten auf dem Bildschirm auszudrucken, speichern Sie sie in einer Variablen:
properties.append({
"Price": price,
"Beds": beds,
"Baths": baths,
"Address": address,
"Link": full_link
})Der nächste Schritt hängt davon ab, in welchem Format du die Daten speichern möchtest. Um uns nicht zu wiederholen, gehen wir im Abschnitt zur Datenverarbeitung und -speicherung genauer darauf ein.
Umgang mit dynamischem Inhalt mit Selenium
Machen wir dasselbe mit Selenium. Wir haben dieses Skript auch auf die Colab Research-Seite hochgeladen, aber Sie können es nur auf Ihrem eigenen PC ausführen, da Google Colaboratory die Ausführung von Headless-Browsern nicht zulässt.
Anstatt Selektoren zu verwenden und alle Elemente einzeln auszuwählen, verwenden wir dieses Mal das JSON, das wir zuvor gesehen haben, und kombinieren sie alle in einer Datei. Sie können auch unnötige Attribute entfernen oder Ihr eigenes JSON mit Ihrer eigenen Struktur erstellen und dabei nur die erforderlichen Attribute verwenden.
Erstellen wir eine neue Datei und importieren alle erforderlichen Selenium-Module sowie die Bibliothek zur JSON-Verarbeitung.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import jsonNun legen wir die Selenium-Parameter fest, geben den Pfad zum Webtreiber an und geben auch den Headless-Modus an:
chrome_driver_path = "C:\driver\chromedriver.exe"
chrome_options = Options()
chrome_options.add_argument("--headless")
service = Service(chrome_driver_path)
service.start()
driver = webdriver.Remote(service.service_url, options=chrome_options)Geben Sie einen Link zur Seite mit der Auflistung an:
url = "https://www.redfin.com/city/18142/FL/Tampa"Gehen wir zur Eigenschaftenseite und fügen einen Try-Block hinzu, um zu verhindern, dass das Skript im Fehlerfall beendet wird:
try:
driver.get(url)
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CLASS_NAME, "HomeCardContainer")))
homecards = driver.find_elements(By.CLASS_NAME, "bp-Homecard__Content")
properties = ()Iterieren Sie über alle Produktkarten und sammeln Sie JSON:
for card in homecards:
script_element = card.find_element(By.TAG_NAME, "script")
json_data = json.loads(script_element.get_attribute("innerHTML"))
properties.extend(json_data) Anschließend können Sie entweder mit der Verarbeitung des JSON-Objekts fortfahren oder es speichern. Am Ende sollten wir die Arbeit des Webtreibers beenden:
finally:
driver.quit()Dies ist ein Beispiel für eine JSON-Datei, die wir als Ergebnis erhalten:
(
{
"@context": "http://schema.org",
"name": "13813 Stone Mill Way, Tampa, FL 33613",
"url": "https://www.redfin.com/FL/Tampa/13813-Stone-Mill-Way-33613/home/47115426",
"address": {
"@type": "PostalAddress",
"streetAddress": "13813 Stone Mill Way",
"addressLocality": "Tampa",
"addressRegion": "FL",
"postalCode": "33613",
"addressCountry": "US"
},
"geo": {
"@type": "GeoCoordinates",
"latitude": 28.0712008,
"longitude": -82.4771742
},
"numberOfRooms": 2,
"floorSize": {
"@type": "QuantitativeValue",
"value": 1261,
"unitCode": "FTK"
},
"@type": "SingleFamilyResidence"
},
…
)Mit diesem Ansatz erhalten Sie auf einfachere Weise umfassendere Daten. Darüber hinaus kann die Verwendung eines Headless-Browsers das Risiko einer Blockierung verringern, da Sie damit das Verhalten eines echten Benutzers besser simulieren können.
Beachten Sie jedoch, dass Sie von der Site möglicherweise trotzdem blockiert werden, wenn Sie eine große Datenmenge scrapen. Um dies zu vermeiden, verbinden Sie einen Proxy mit Ihrem Skript. Wie das geht, haben wir bereits in einem separaten Artikel zu Proxys erläutert.
Methode 3: Scrape Redfin mithilfe der API
Betrachten wir nun die einfachste Möglichkeit, die erforderlichen Daten zu erhalten. Diese Option erfordert keine Verbindung zu Proxys oder Captcha-Lösungsdiensten und gibt die vollständigsten Daten in einem praktischen JSON-Antwortformat zurück. Dazu verwenden wir die Redfin-API von Hasdata, deren vollständige Details in der Dokumentation zu finden sind.
Scrape-Einträge mit der Redfin-API
Da diese API zwei Endpunkte hat, betrachten wir beide Optionen und beginnen mit der, die Daten mit einer Auflistung zurückgibt, da wir diese Daten bereits mithilfe von Python-Bibliotheken gesammelt haben. Das vorgefertigte Skript finden Sie auch in Google Colaboratory.
Importieren Sie die erforderlichen Bibliotheken:
import requests
import jsonGeben Sie dann Ihren HasData API-Schlüssel ein:
api_key = "YOUR-API-KEY"Parameter festlegen:
params = {
"keyword": "33321",
"type": "forSale"
}Neben der Postleitzahl und der Objektart können Sie auch die Anzahl der Seiten angeben. Geben Sie dann den Endpunkt selbst an:
url = "https://api.hasdata.com/scrape/redfin/listing"Header festlegen und API anfordern:
headers = {
"x-api-key": api_key
}
response = requests.get(url, params=params, headers=headers)Als nächstes rufen wir die Daten ab und wenn der Antwortcode 200 ist, können wir die empfangenen Daten entweder weiterverarbeiten oder speichern:
if response.status_code == 200:
properties = response.json()
if properties:
# Here you can process or save properties
else:
print("No listings found.")
else:
print("Failed to retrieve listings. Status code:", response.status_code)Als Ergebnis erhalten wir eine Antwort, in der die Daten im folgenden Format gespeichert sind (der Übersichtlichkeit halber wurden die meisten Daten entfernt):
{
"requestMetadata": {
"id": "da2f6f99-d6cf-442d-b388-7d5a643e8042",
"status": "ok",
"url": "https://redfin.com/zipcode/33321"
},
"searchInformation": {
"totalResults": 350
},
"properties": (
{
"id": 186541913,
"mlsId": "F10430049",
"propertyId": 41970890,
"url": "https://www.redfin.com/FL/Tamarac/7952-Exeter-Blvd-W-33321/unit-101/home/41970890",
"price": 397900,
"address": {
"street": "7952 W Exeter Blvd W #101",
"city": "Tamarac",
"state": "FL",
"zipcode": "33321"
},
"propertyType": "Condo",
"beds": 2,
"baths": 2,
"area": 1692,
"latitude": 26.2248143,
"longitude": -80.2916508,
"description": "Welcome Home to this rarely available & highly sought-after villa in the active 55+ community of Kings Point, Tamarac! This beautiful and spacious villa features volume ceilings…",
"photos": (
"https://ssl.cdn-redfin.com/photo/107/islphoto/049/genIslnoResize.F10430049_0.jpg",
"https://ssl.cdn-redfin.com/photo/107/islphoto/049/genIslnoResize.F10430049_1_1.jpg"
)
},
…
}Wie Sie sehen, ist die Verwendung einer API zum Abrufen von Daten viel einfacher und schneller. Darüber hinaus können Sie mit diesem Ansatz alle möglichen Daten von der Seite abrufen, ohne sie manuell extrahieren zu müssen.
Scrapen von Eigenschaften mithilfe der Redfin-API
Lassen Sie uns nun Daten mithilfe eines anderen Endpunkts (Ergebnis in Google Colaboratory) erfassen, mit dem Sie Daten von der Seite einer bestimmten Eigenschaft abrufen können. Dies kann beispielsweise nützlich sein, wenn Sie eine Liste mit Einträgen haben und schnell Daten von allen Einträgen erfassen müssen.
Das gesamte Skript wird dem vorherigen sehr ähnlich sein. Nur die Anforderungsparameter und der Endpunkt selbst werden sich ändern:
url = "https://api.hasdata.com/scrape/redfin/property"
params = {
"url": "https://www.redfin.com/IL/Chicago/1322-S-Prairie-Ave-60605/unit-1106/home/12694628"
}Das Skript bleibt ansonsten gleich. Die API gibt alle verfügbaren Daten für die angegebene Eigenschaft zurück.
Datenverarbeitung und -speicherung
Zum Speichern der Daten benötigen wir je nach Format eine zusätzliche Bibliothek. Wir speichern unsere Daten in zwei der gängigsten Formate: JSON und CSV. Dazu importieren wir zusätzliche Bibliotheken in das Projekt:
import json
import csvAls nächstes speichern wir die Daten aus der zuvor erstellten Variable in den entsprechenden Dateien:
with open("properties.json", "w") as json_file:
json.dump(properties, json_file, indent=4)
keys = properties(0).keys()
with open("properties.csv", "w", newline="", encoding="utf-8") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=keys)
writer.writeheader()
writer.writerows(properties)Mit dieser Methode können wir alle wichtigen Daten bewahren. Wenn Sie den Datenspeicherungsprozess optimieren oder in einem anderen Format speichern möchten, können Sie die Pandas-Bibliothek verwenden.
Abschluss
In diesem Artikel haben wir die beliebtesten Methoden zum Abrufen von Immobiliendaten von Redfin untersucht und verschiedene Technologien und Tools wie BeautifulSoup und Selenium besprochen, die Informationen von Websites extrahieren. So können Sie problemlos Daten zu Preisen, Adressen, der Anzahl der Schlafzimmer und Badezimmer und anderen Immobilienmerkmalen abrufen. Sie können sich auch unser Tutorial zum Scraping von Zillow mit Python ansehen, um weitere Immobiliendaten zu erhalten.
Alle besprochenen Skripte wurden in Google Colaboratory hochgeladen, sodass Sie problemlos darauf zugreifen und sie ausführen können, ohne Python auf Ihrem PC installieren zu müssen (mit Ausnahme des Beispiels mit einem Headless-Browser, das nicht aus der Cloud ausgeführt werden kann). Mit diesem Ansatz können Sie alle besprochenen Skripte nutzen, auch wenn Sie mit der Programmierung nicht sehr vertraut sind.
Darüber hinaus haben wir auch ein Beispiel bereitgestellt, wie Sie mit einem No-Code-Scraper auch ohne Programmierkenntnisse Daten abrufen können. Wenn Sie Daten mit der Redfin-API von Hasdata abrufen möchten, aber kein Skript schreiben möchten, können Sie unseren API-Playground verwenden.
