
Scrapy adalah kerangka web scraping paling populer dengan Python. Sebelumnya sudah ada review alat serupa. Berbeda dengan BeautifulSoup atau Selenium, Scrapy bukanlah perpustakaan. Keuntungan besarnya adalah alat ini sepenuhnya gratis.
Namun demikian, ini multifungsi dan dapat menyelesaikan sebagian besar tugas yang diperlukan saat menggores data, misalnya:
- Mendukung multi-threading.
- Dapat digunakan untuk berpindah dari satu tautan ke tautan lainnya.
- Cocok untuk ekstraksi data.
- Memungkinkan Anda melakukan validasi data.
- Menyimpan dalam format/database paling populer.
Scrapy menggunakan laba-laba, perayap mandiri dengan serangkaian instruksi khusus. Artinya, kode ini dapat dengan mudah diskalakan untuk proyek dengan ukuran berapa pun sambil menjaga kode tetap terstruktur dengan baik. Hal ini juga memungkinkan pengembang baru untuk memahami proses yang sedang berlangsung. Data yang tergores dapat disimpan dalam format CSV untuk diproses lebih lanjut oleh data scientist.
Daftar Isi
Cara menginstal Scrapy dengan Python
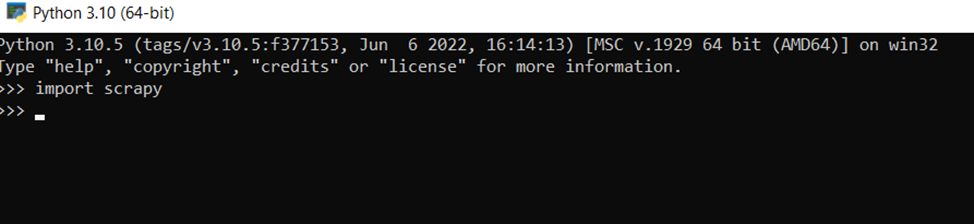
Sebelum mempelajari penggunaan praktis Scrapy, Anda harus menginstalnya. Ini dilakukan melalui baris perintah:
pip install scrapyUntuk memastikan semuanya berjalan dengan baik, Anda dapat mengimpor Scrapy ke penerjemah menggunakan perintah:
>>> import scrapyDan jika tidak ada pesan error, maka semuanya berjalan dengan baik.
Cara menggunakan XPath dengan Scrapy
Scrapy bekerja sama baiknya dengan penyeleksi XPath dan CSS. Namun, XPath memiliki sejumlah keunggulan, itulah sebabnya XPath lebih sering digunakan. Untuk menyederhanakan contoh, semua kode XPath dijalankan pada baris perintah. Untuk melakukan ini, buka shell Python khusus:
scrapy shellKemudian pilih situs yang akan dirayapi web dan gunakan perintah berikut:
fetch("http://example.com/")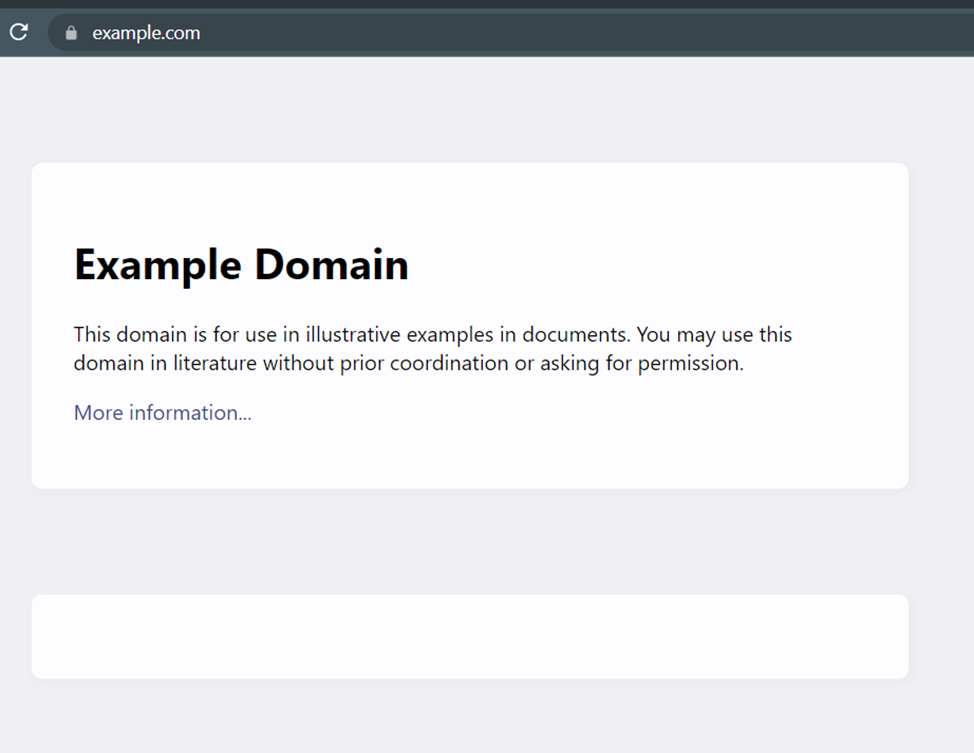
Hasil eksekusinya adalah sebagai berikut:
2022-07-20 14:50:33 (scrapy.core.engine) DEBUG: Crawled (200) <GET http://example.com/> (referer: None)Hal ini wajar karena tidak ditentukan data mana yang perlu dirayapi. Di sekitar semua orang pada hari itu <html>…