
Unter Web Scraping versteht man die Übertragung von im Internet veröffentlichten Daten in Form von HTML-Seiten (auf einer Website) in einen Speicherort (sei es eine Textdatei oder eine Datenbank).
Der Vorteil der Programmiersprache C# beim Web Scraping besteht darin, dass sie die direkte Integration des Browsers in Formulare mithilfe des C#-WebBrowsers ermöglicht. Die geschabten Daten können in einer beliebigen Ausgabedatei gespeichert oder auf dem Bildschirm angezeigt werden.
Web Scraping-Grundlagen in ASP Net mit C#
Für die C#-Entwicklungsumgebung können Sie Visual Studio oder Visual Studio Code verwenden. Die Wahl hängt von den Entwicklungszielen und PC-Fähigkeiten ab.
Visual Studio ist eine Umgebung für die umfassende Entwicklung von Desktop-, Mobil- und Serveranwendungen mit vorgefertigten Vorlagen und der Möglichkeit, das zu entwickelnde Programm grafisch zu bearbeiten.
Visual Studio Code hingegen ist eine grundlegende Shell, auf der man die erforderlichen Pakete installieren kann. Es nimmt viel weniger Platz und CPU-Zeit in Anspruch.
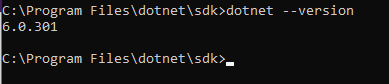
Wählt man Visual Studio Code, muss man zusätzlich .NET Framework und .NET Core 3.1 installieren. Um sicherzustellen, dass alle Komponenten korrekt installiert sind, geben Sie in der Befehlszeile den folgenden Befehl ein:
dotnet --versionWenn alles korrekt funktioniert, sollte der Befehl die installierte Version von .NET zurückgeben.
Instrumental für Web Scraping
Um Web Scraping in C# optimal zu nutzen, lohnt sich der Einsatz zusätzlicher Bibliotheken. Und bevor Sie Bibliotheken verwenden, sollten Sie alle C#-Bibliotheken für Web Scraping kennen. Am häufigsten werden PhantomJS mit Selenium, HtmlAgilityPack mit ScrapySharp und Puppeteer Sharp verwendet.
Erhalten Sie Daten mit Selenium und PhantomJS Web Scraping C#
Um PhantomJS, die beste C#-Web-Scraping-Bibliothek, verwenden zu können, müssen Sie sie installieren. Am einfachsten geht das über den NuGet Package Manager. Um ein Paket in Visual Studio einzubinden, klicken Sie mit der rechten Maustaste auf die Registerkarte „Referenzen“ im Projekt und geben Sie „PhantomJS“ in die Suchleiste ein.
Was ist die Selenium-Bibliothek?
Wenn jedoch jemand von PhantomJS spricht, meint er PhantomJS mit Selenium. Um PhantomJS mit Selenium nutzen zu können, müssen Sie zusätzlich folgende Pakete installieren:
-
Selenium.WebDriver.
-
Selen-Unterstützung.
Dies kann mithilfe von NuGet erfolgen. Um NuGet in Visual Studio Code zu verwenden, installieren Sie einfach den NuGet-Paketmanager mit GUI:
Oder nicht:
Um alle Titel auf die Seite zu bekommen, verwenden Sie einfach:
using (var driver = new PhantomJSDriver())
{
driver.Navigate().GoToUrl("http://example.com/");
var titles = driver.FindElements(By.ClassName("title"));
foreach (var title in titles)
{
Console.WriteLine(title.Text);
}
}Dieser einfache Code findet alle Elemente mit Klassentitel und gibt den gesamten darin enthaltenen Text zurück.
Selenium enthält viele Funktionen, um das benötigte Element zu finden. Ein Element kann nach XPath, CSS-Selektor oder HTML-Tag durchsucht werden. Um beispielsweise ein Element anhand seines XPath zu finden, beispielsweise ein Eingabefeld, und einen Wert zu übergeben, verwenden Sie einfach Folgendes:
driver.FindElement(By.XPath(@".//div")).SendKeys("c#");Um auf ein beliebiges Element zu klicken, zum Beispiel auf die Schaltfläche „Bestätigen“, kann man den folgenden Code verwenden:
driver.FindElement(By.XPath(@".//input(@id='searchsubmit')")).Click();Wozu dient die Selenium-Bibliothek?
Selenium ist eine plattformübergreifende Bibliothek und funktioniert mit den meisten Programmiersprachen, verfügt über eine vollständige und gut geschriebene Dokumentation und eine aktive Community.
Die Verwendung von Selenium mit PhantomJS ist eine gute Lösung, die es ermöglicht, eine Vielzahl von Scraping-Aufgaben zu lösen, einschließlich dynamischem Page Scraping. Allerdings ist es ziemlich ressourcenintensiv.
HtmlAgilityPack für den Schnellstart
Wenn die Website nicht gegen Bots geschützt ist und alle erforderlichen Inhalte sofort bereitgestellt werden, kann eine einfache Lösung verwendet werden – die Html Agility Pack-Bibliothek, eine weitere C#-Web-Scraping-Bibliothek. Dies ist eine der beliebtesten Bibliotheken zum Scrapen in C#. Die Verbindung erfolgt auch über das NuGet-Paket.
Was ist das HtmlAgilityPac?
Diese Bibliothek erstellt einen DOM-Baum aus HTML. Das Problem ist, dass man den Seitencode selbst laden muss. Um die Seite zu laden, verwenden Sie einfach den nächsten Code:
using (WebClient client = new WebClient())
{ string html = client.DownloadString("http://example.com");
//Do something with html then
}Um anschließend einige Elemente auf der Seite zu finden, kann man beispielsweise XPath verwenden:
HtmlNodeCollection links = document.DocumentNode.SelectNodes(".//h2/a");
foreach (HtmlNode link in links)
Console.WriteLine("{0} - {1}", link.InnerText, link.GetAttributeValue("href", "")); Wozu dient das HtmlAgilityPac?
Das HtmlAgilityPac ist eine einfachere Einstiegsoption und eignet sich gut für Anfänger. Es gibt auch eine eigene Website mit Anwendungsbeispielen. Es ist einfacher als Selenium und unterstützt einige Funktionen nicht, eignet sich aber gut für nicht allzu komplexe Projekte.
Mit dem Html Agility Pack können Sie den Browser in Windows-Form einbetten und so eine vollständige Desktop-Anwendung erstellen.
C# Web Scraping mit ScrapySharp
Um ein Paket in Visual Studio einzubinden, klicken Sie mit der rechten Maustaste auf die Registerkarte „Referenzen“ im Projekt und geben Sie „ScrapySharp“ in die Suchleiste ein.
Um dieses Paket in Visual Studio Code hinzuzufügen, schreiben Sie in die Befehlszeile:
dotnet add package ScrapySharpWas ist die ScrapySharp-Bibliothek?
ScrapySharp ist eine Open-Source-Web-Scraping-Bibliothek für die Programmiersprache C#, die über ein NuGet-Paket verfügt. Darüber hinaus ist ScrapySharp eine Html Agility Pack-Erweiterung zum Scrapen von Datenstrukturen mithilfe von CSS-Selektoren und zur Unterstützung dynamischer Webseiten.
Um ein HTML-Dokument mit ScrapySharp abzurufen, kann man den folgenden Code verwenden:
static ScrapingBrowser browser = new ScrapingBrowser();
static HtmlNode GetHtml(string url){
WebPage webPage = browser.NavigateToPage(new Uri(url));
return webPage.Html;
}Wozu dient die ScrapySharp-Bibliothek?
Es ist also nicht so ressourcenintensiv wie Selenium, unterstützt aber auch die Fähigkeit, dynamische Webseiten zu crawlen. Wenn ScrapySharp jedoch ausreicht, um alltägliche Aufgaben zu lösen, ist es für komplexere Aufgaben besser, Selenium zu verwenden.
Puppenspieler für Headless Scraping
Puppeteer ist eine Node.js-Bibliothek, die eine High-Level-API zur Steuerung von Headless Chrome oder Chromium oder zur Interaktion mit dem DevTools-Protokoll bereitstellt. Es gibt aber auch einen Wrapper für die Verwendung in C# – Puppeteer Sharp, der über ein NuGet-Paket verfügt.
Was ist die Puppenspielerbibliothek?
Puppeteer bietet die Möglichkeit, mit Headless-Browsern zu arbeiten und lässt sich in die meisten Anwendungen integrieren.
Puppeteer bietet gut geschriebene Dokumentationen und Anwendungsbeispiele auf der offiziellen Website. Die einfachste Anwendung ist beispielsweise:
using var browserFetcher = new BrowserFetcher();
await browserFetcher.DownloadAsync(BrowserFetcher.DefaultChromiumRevision);
var browser = await Puppeteer.LaunchAsync(new LaunchOptions
{
Headless = true
});
var page = await browser.NewPageAsync();
await page.GoToAsync("http://www.google.com");
await page.ScreenshotAsync(outputFile);Wozu dient die Puppenspielerbibliothek?
Puppeteer unterstützt auch den Headless-Modus, wodurch Sie die CPU-Zeit und den RAM-Verbrauch reduzieren können.
Die beste C#-Web-Scraping-Bibliothek
Abhängig vom Projekt, seinen Zielen und Ihren Fähigkeiten variiert die beste Bibliothek für verschiedene Fälle. Um den Auswahlprozess zu vereinfachen und Sie bei der Suche nach der am besten geeigneten C#-Web-Scraping-Bibliothek zu unterstützen, haben wir daher eine Vergleichstabelle aller heute besprochenen Bibliotheken zusammengestellt.
|
Bibliothek |
Beschreibung |
Vorteile |
Nachteile |
|---|---|---|---|
|
PhantomJS |
Integration von PhantomJS mit Selenium für Web Scraping |
Ermöglicht das Scrapen dynamischer Webseiten |
Ressourcenintensiv, erfordert eine zusätzliche Installation von PhantomJS |
|
Selen |
Plattformübergreifende Bibliothek mit umfangreicher Dokumentation und aktiver Community |
Unterstützt verschiedene Elementsuchmethoden (XPath, CSS Selector, HTML-Tag) |
Kann im Vergleich zu anderen Bibliotheken langsamer sein und erfordert möglicherweise mehr Code, um bestimmte Aktionen auszuführen |
|
HtmlAgilityPack |
Erstellt einen DOM-Baum aus HTML und bietet eine benutzerfreundliche Oberfläche |
Geeignet für einfachere Projekte und Einsteiger, keine Browser-Integration erforderlich |
Unterstützt bestimmte erweiterte Funktionen von Selenium nicht |
|
ScrapySharp |
Erweiterung von HtmlAgilityPack mit Unterstützung für CSS-Selektoren und dynamische Webseiten |
Bietet die Möglichkeit, dynamische Webseiten zu scannen, was weniger ressourcenintensiv als Selenium ist |
Begrenzte Dokumentation und Community-Unterstützung, kann komplexe Szenarien möglicherweise nicht so effektiv bewältigen wie Selenium |
|
Puppenspieler Sharp |
C#-Wrapper für Puppeteer, der Headless Chrome oder Chromium steuert und mit DevTools interagiert |
Unterstützt den Headless-Modus, gut dokumentiert, reduziert CPU-Zeit und RAM-Verbrauch |
Erfordert die Installation eines Headless-Chrome- oder Chromium-Browsers, möglicherweise mit einer Lernkurve für Neulinge verbunden |
Da Sie nun die Unterschiede in den Zielen, Vor- und Nachteilen der einzelnen Optionen erkennen können, hoffen wir, dass es Ihnen leichter fällt, die richtige Wahl zu treffen.
C#-Proxy für Web Scraping
Einige Websites verfügen über Überprüfungen und Fallen zur Erkennung von Bots, die verhindern, dass der Scraper viele Daten sammelt. Es gibt jedoch auch Workarounds.
Sie können beispielsweise Headless-Browser verwenden, um die Aktionen eines echten Benutzers nachzuahmen, die Verzögerung zwischen Iterationen zu erhöhen oder einen Proxy zu verwenden.
Beispiel für die Verwendung eines Proxys:
public static void proxyConnect();
WebProxy proxy = new WebProxy();
proxy.address = “http://IP:Port”;
HTTPWebRequest req = (HTTPWebRequest);
WebRequest.Create(“https://example.com/”);
req.proxy = proxy;Ein Proxyserver ist ein Muss für jeden C#-Web-Scraper. Es gibt viele Optionen, wie zum Beispiel SmartProxy-Dienste, Luminati Network, Blazing SEO. Kostenlose Proxys sind für solche Zwecke nicht immer geeignet: Sie sind oft langsam und unzuverlässig. Man kann auch sein eigenes Proxy-Netzwerk auf dem Server erstellen, beispielsweise mit Scrapoxy, einer Open-Source-API.
Wer einen Proxy zu lange nutzt, riskiert einen IP-Verbot oder eine Blacklist. Um eine Blockierung zu vermeiden, kann man rotierende Residential-Proxys verwenden. Durch die Auswahl eines bestimmten Ortes zum Scrapen und das ständige Ändern der IP-Adresse kann der Scraper praktisch immun gegen das Blockieren von IP-Adressen werden.
Eine alternative Lösung besteht darin, unsere API in Ihrem Scraper zu verwenden, die es ermöglicht, die angeforderten Daten zu sammeln und Blockierungen effektiv zu vermeiden, ohne ein Captcha einzugeben.
Lesen Sie auch über Proxys für Scraping
Fazit und Erkenntnisse
C# ist eine gute Option, wenn es darum geht, einen Desktop-Scraper zu erstellen. Es gibt dafür weniger Bibliotheken als für NodeJS oder Python, sie sind jedoch hinsichtlich der Funktionalität nicht schlechter. Wenn außerdem ein hochsicherer Parser erforderlich ist, bietet C# mehr Optionen für die Implementierung.
Die betrachteten Bibliotheken ermöglichen die Erstellung komplexerer Projekte, die Daten erfordern, mehrere Seiten analysieren und Daten extrahieren können. Natürlich wurden im Artikel nicht alle Bibliotheken aufgeführt, sondern nur die funktionsfähigsten und mit einer guten Dokumentation. Zusätzlich zu den aufgeführten gibt es jedoch noch andere Bibliotheken von Drittanbietern, von denen nicht alle über das NuGet-Paket verfügen.
