
Riwayat SERP memberikan wawasan berharga tentang bagaimana peringkat situs web, aktivitas pesaing, dan faktor terkait SEO lainnya telah berubah. Dengan menganalisis data historis SERP, Anda dapat lebih memahami faktor-faktor yang memengaruhi visibilitas situs web Anda di hasil pencarian.
Pada artikel kali ini kita akan membahas tools yang dapat digunakan untuk melacak riwayat SERP Google. Kami juga mendiskusikan pembuatan alat Anda untuk mengumpulkan data yang diperlukan. Kami juga menyediakan skrip yang dapat digunakan siapa saja untuk menangkap riwayat SERP.
Daftar Isi
Alat pengumpulan sejarah SERP
Alat penangkapan riwayat SERP dirancang untuk melacak dan menyimpan perubahan pada halaman hasil mesin pencari (SERP). Alat-alat ini memungkinkan Anda menganalisis dinamika perubahan peringkat situs web, kata kunci, dan parameter lainnya di SERP.
Ada dua pendekatan utama untuk mengumpulkan riwayat SERP: menyimpan data tentang SERP atau menyimpan cuplikan SERP. Pendekatan terakhir lebih nyaman dan memberikan data yang lebih lengkap, memungkinkan Anda melihat SERP seperti yang muncul pada titik waktu tertentu.
Ada berbagai alat yang tersedia untuk menangkap riwayat SERP:
- Alat dan platform SEO. Banyak platform SEO seperti Serpstat, Ahrefs, dan SEMrush menawarkan alat pelacakan SERP. Alat-alat ini biasanya menyediakan data tentang peringkat situs web, aktivitas pesaing, dan metrik lainnya. Namun, biayanya bisa mahal, dengan biaya lebih dari $200 per bulan. Selain itu, beberapa alat hanya memberikan informasi terbatas, seperti peringkat situs web dan tautan.
- API SERP. Beberapa layanan menawarkan API yang dapat digunakan untuk mengumpulkan data SERP. Pendekatan ini lebih fleksibel dan hemat biaya dibandingkan menggunakan platform SEO. API biasanya menyediakan semua informasi yang tersedia dari SERP, termasuk snapshot, dan Anda dapat memilih data mana yang Anda perlukan. Selain itu, alat pengumpulan data berbasis API dapat diintegrasikan ke dalam aplikasi Anda.
- Layanan pengikisan web. Anda juga dapat menggunakan web scraper untuk mengumpulkan data SERP. Pencakar web adalah alat yang secara otomatis dapat mengekstrak data dari situs web. Pendekatan ini adalah cara termudah untuk mendapatkan data yang diperlukan.
Pilihan terbaik untuk mengumpulkan riwayat SERP adalah dengan menggunakan API yang dapat menyediakan data hasil pencarian dan cuplikan halaman. Artinya, Anda dapat melihat dengan tepat tampilan hasil penelusuran kapan saja. Sebagai contoh, kami akan menggunakan API Scrape-It.Cloud SERP, yang mengembalikan data ini.
Cara Melacak SERP Historis
Tutorial ini akan menunjukkan kepada Anda cara melacak riwayat SERP menggunakan SERP API yang cocok untuk non-programmer dan mereka yang ingin membuat skrip sendiri. Cara termudah untuk mendapatkan data adalah dengan menggunakan Google Sheets yang telah dikonfigurasi sebelumnya dengan App Script.
Jika Anda ingin membuat alat fleksibel tanpa harus berurusan dengan pengkodean, gunakan Make.com atau Zapier untuk membuat integrasi sederhana. Atau Anda dapat membuat skrip yang menjalankan fungsi yang Anda perlukan.
Gunakan templat Google Spreadsheet
Cara termudah untuk mengumpulkan cuplikan hasil pencarian Google adalah dengan menggunakan template yang sudah jadi. Untuk melakukan ini, salin spreadsheet Google kami dan mulai add-on Scrape-It.Cloud. Pilih “Pemeriksa Peringkat” dan masukkan kunci API Anda, kata kunci, dan tautan ke domain yang posisinya ingin Anda periksa. Anda juga dapat mengatur parameter lainnya sesuai keinginan.
Setelah Anda mengonfigurasi Pemeriksa Peringkat, Anda dapat meluncurkannya untuk mendapatkan cuplikan dan tautan ke halaman yang ditemukan untuk setiap kata kunci, serta posisinya saat ini. Untuk membuat arsip tangkapan layar hasil pencarian, cukup jalankan Pemeriksa Peringkat pada frekuensi yang diinginkan.
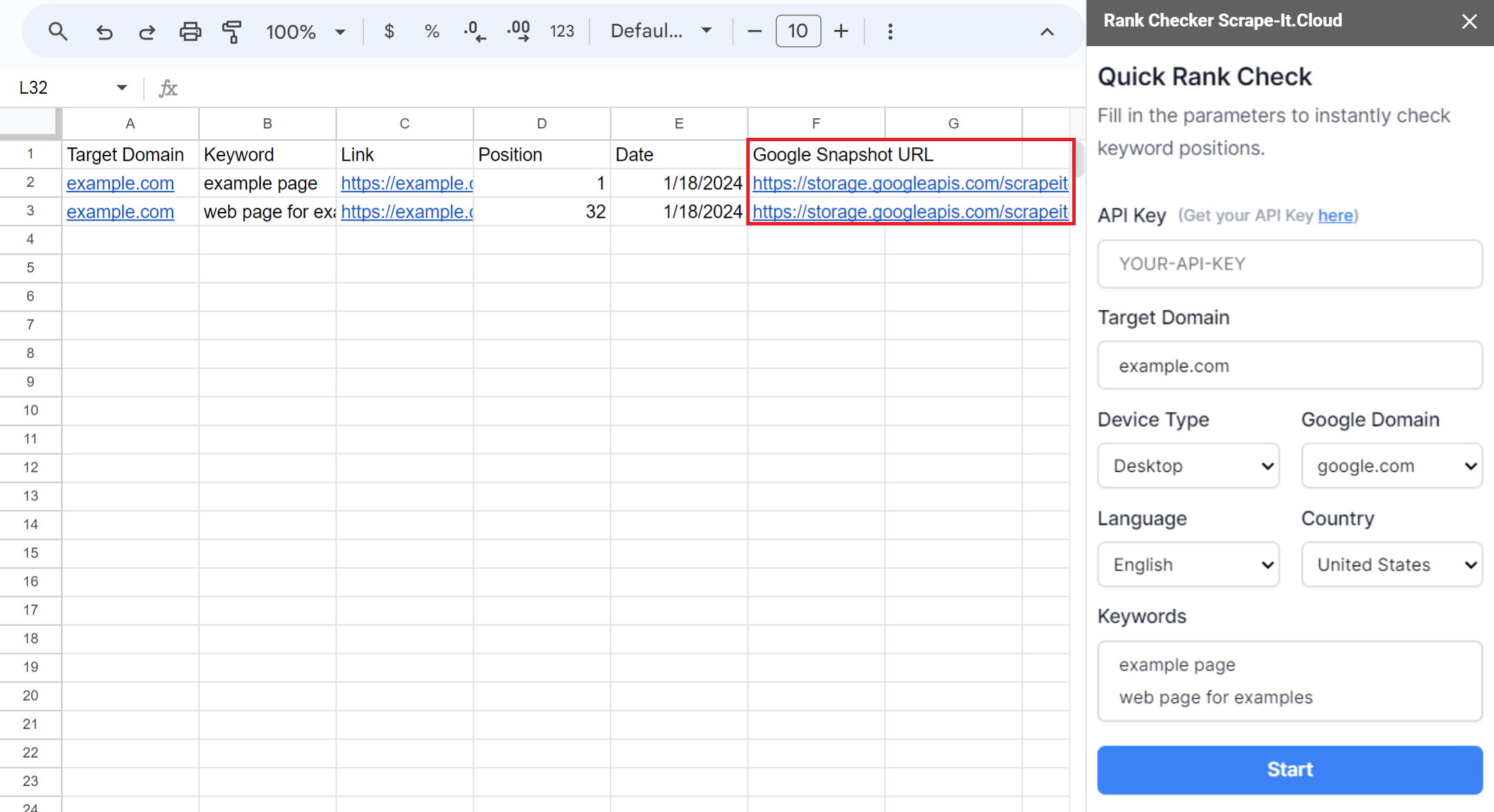
Selain mengumpulkan snapshot dan melacak posisi, Anda dapat menggunakan fitur lain dari template ini seperti pelacakan posisi otomatis dengan Google Sheets. Untuk informasi lebih lanjut, lihat artikel kami tentang Pelacak Peringkat di Google Spreadsheet.
Gunakan Zapier atau Layanan Integrasi Make.com
Solusi lainnya adalah dengan menggunakan layanan integrasi untuk membuat aplikasi yang dipersonalisasi tanpa pengetahuan pengkodean apa pun. Zapier dan Make.com adalah layanan paling populer dari jenis ini. Kami telah menjelaskan cara mengembangkan Zaps dengan Zapier, mendapatkan data dari Google SERP dan berbagai website dengan Make.com.
Untuk membuat pelacak riwayat SERP di Zapier, buat pemicu untuk kumpulan snapshot, sumber kata kunci, dan API SERP Scrape-It.Cloud. Ini menghasilkan data berikut:
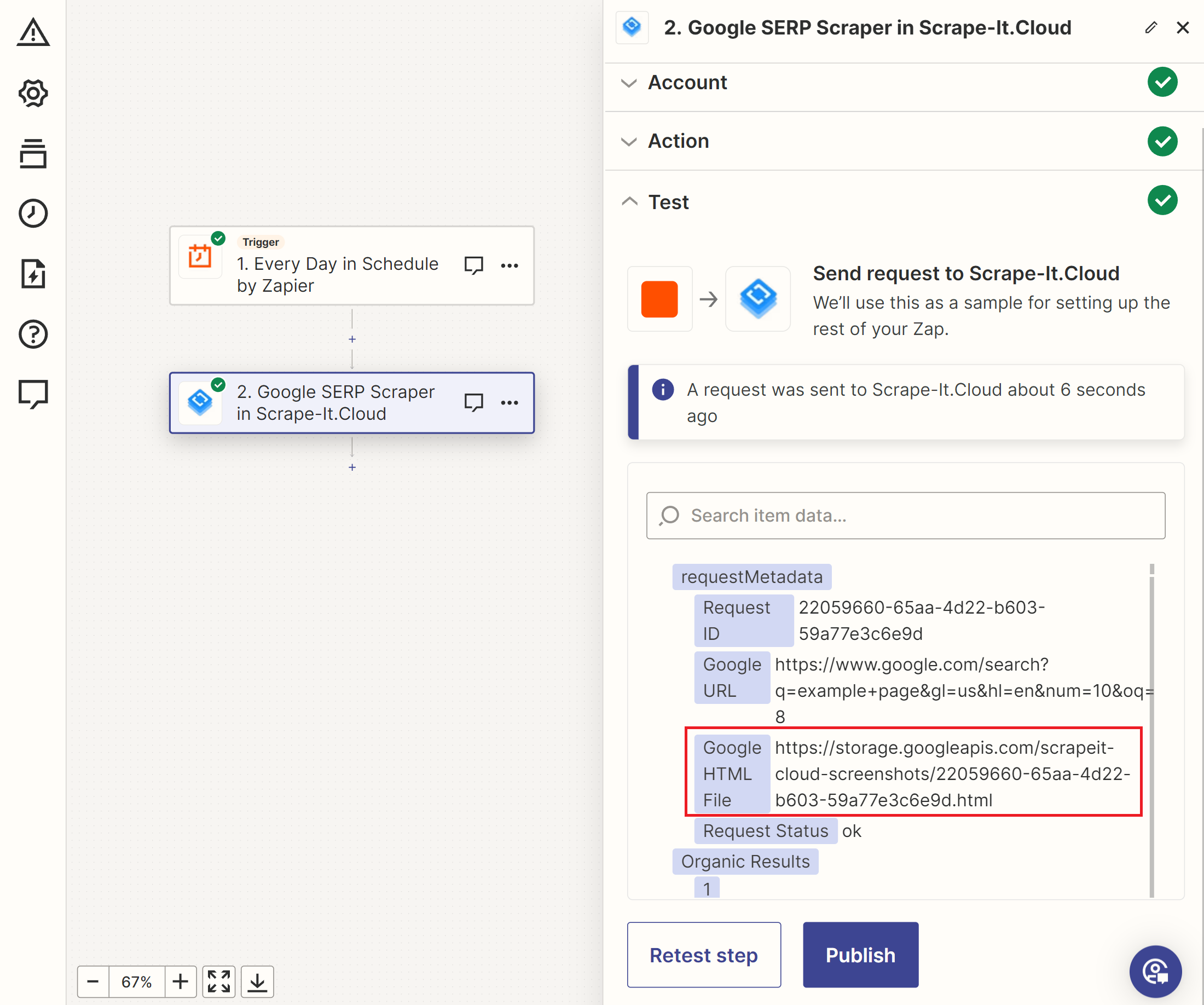
Anda kemudian dapat mengintegrasikan data ini dengan Google Spreadsheet, email, atau layanan lain untuk penyimpanan atau pemrosesan.
Make.com menawarkan lebih banyak fleksibilitas saat memproses array. Untuk pengambilan cuplikan riwayat SERP secara teratur untuk semua kata kunci, Anda dapat menggunakan fitur Make.com tanpa menambahkan sumber tambahan. Pendekatan lainnya sama seperti Zapier.
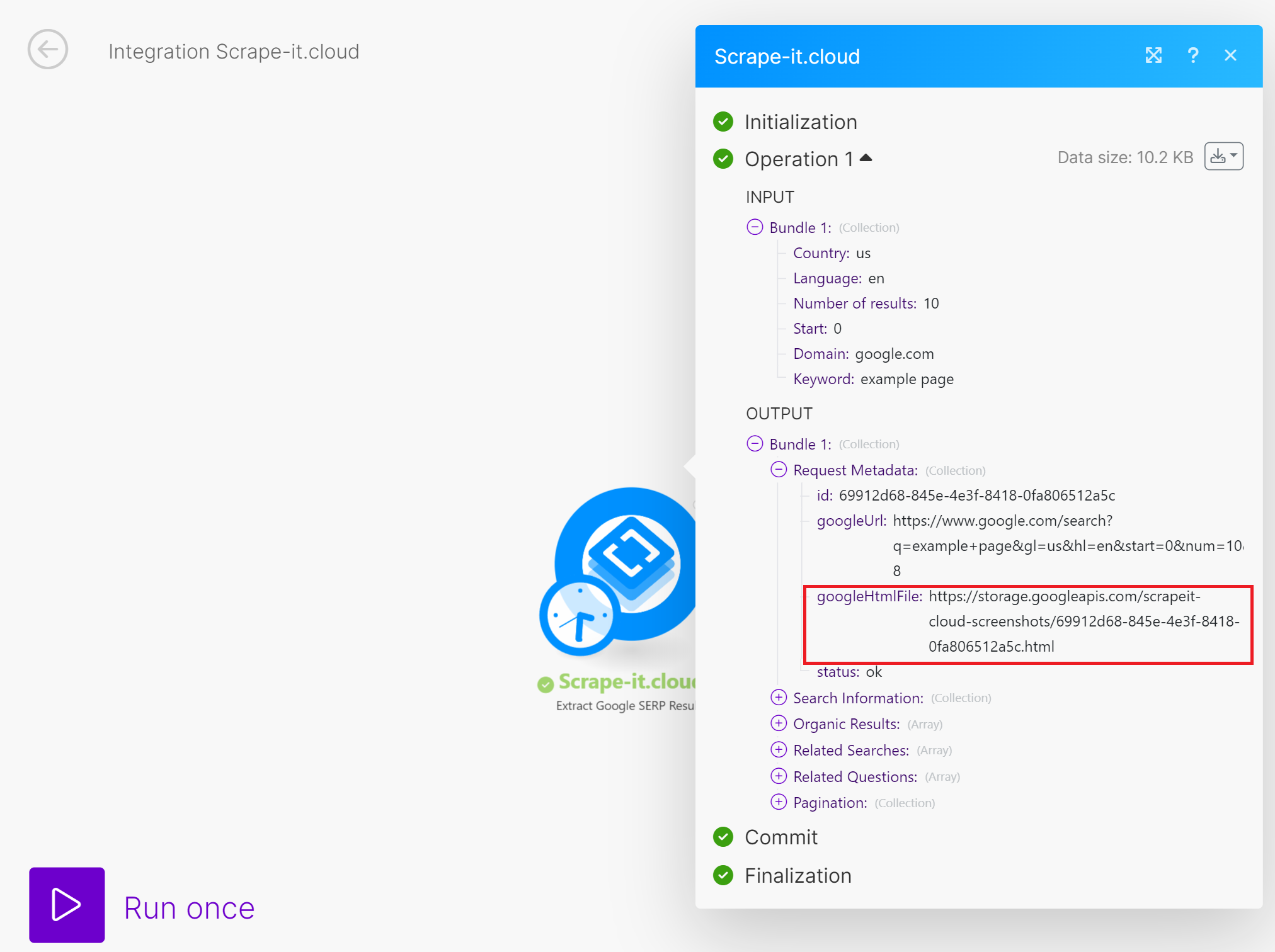
Anda juga dapat memutuskan bagaimana Anda ingin memproses atau menyimpan data yang dikumpulkan dan mengintegrasikannya ke dalam aplikasi Anda.
Gunakan skrip Python
Untuk memulai, kami telah menyediakan skrip berjalan di Google Colaboratory sehingga Anda dapat langsung menggunakannya. Untuk melakukan ini, Anda perlu memasukkan kunci API dan kata kunci Anda. Setelah Anda selesai melakukannya, Anda dapat menjalankan skrip untuk mengambil data.
Jika Anda ingin membuatnya sendiri, buat file baru dengan ekstensi *.py dan impor perpustakaan yang diperlukan. Dalam skrip ini kami menggunakan:
- Itu Permintaan Library untuk membuat permintaan HTTP ke API.
- Itu sistem operasi Library dapat memeriksa file tempat kita menyimpan data history SERP.
- Itu Waktu perjanjian Perpustakaan menambahkan tanggal dan waktu saat ini.
- Itu Panda Perpustakaan membuat bingkai data dan menyimpan data ke file. Dalam panduan ini, kami akan menyimpan data dalam file CSV, tetapi Pandas juga mendukung format file lainnya.
Semua perpustakaan kecuali Pandas sudah diinstal sebelumnya dan siap digunakan. Untuk menginstal pandas Anda dapat menggunakan perintah berikut:
pip install pandasUntuk mengimpor perpustakaan ke dalam skrip Python Anda, gunakan kode berikut:
import requests
import pandas as pd
from datetime import datetime
import osSekarang mari kita tentukan variabel di mana data akan disimpan. Kami membutuhkan dua – satu untuk menyimpan kata kunci yang diproses dan satu lagi untuk mengumpulkan hasilnya. Kami akan menggunakannya nanti:
keywords = ()
results = ()Tetapkan variabel di mana Anda dapat menempatkan kata kunci yang akan diproses di masa depan dan ditambahkan ke variabel kata kunci:
serp_keywords = ("""
web scraping, top scraping tools
scraper
""")Pendekatan ini diperlukan untuk kenyamanan, karena terkadang lebih mudah untuk menentukan kata kunci dengan baris baru, dan terkadang dengan koma. Oleh karena itu, untuk menghindari kesalahan di kemudian hari, pertama-tama kita tempatkan data asli pada variabel tersendiri, kemudian mengolahnya dan membuat array.
Selanjutnya, kami menetapkan parameter untuk bekerja dengan API - tautan, kunci API, dan parameter dasar seperti domain Google, negara, dan bahasa pencarian. Hal ini diperlukan untuk membuat permintaan lebih personal dan berguna:
api_url="https://api.scrape-it.cloud/scrape/google"
headers = {'x-api-key': 'API-KEY'}
base_params = {
'domain': 'google.com',
'gl': 'us',
'hl': 'en'
}Untuk melanjutkan, kita perlu mengekstrak semua kata kunci dari string yang disimpan dalam variabel serp_keywords. Untuk melakukan ini, kami membaginya baris demi baris dan memeriksa apakah koma berfungsi sebagai pemisah. Setelah itu, kita menambahkan setiap kata kunci ke variabel kata kunci:
serp_keywords = (line.strip() for line in serp_keywords(0).split('\n') if line.strip())
for input_line in serp_keywords:
words = input_line.split(',')
if words:
keywords.extend(words)Sekarang kita dapat mengulangi elemen array yang dihasilkan demi elemen dan mengumpulkan snapshot untuk setiap kueri. Mari tambahkan loop untuk mengulangi semua kata kunci dan menambahkannya sebagai parameter untuk memanggil API bersama dengan parameter dasar yang ditambahkan sebelumnya.
for keyword in keywords:
if keyword.strip():
params = {**base_params, 'q': keyword.strip()}
try:
# Here will be code
except Exception as e:
print('Error:', e)Kami menggunakan blok coba/kecuali untuk mengisolasi kode dari kesalahan yang mungkin terjadi selama eksekusi permintaan. Dengan pendekatan ini, meskipun terjadi kesalahan saat memproses kata kunci, skrip mencetak informasi kesalahan ke konsol dan berpindah ke kata kunci berikutnya alih-alih menghentikan eksekusi sepenuhnya.
Buat permintaan API dan jika responsnya positif (kode status 200), simpan kata kunci, URL cuplikan SERP Google, serta tanggal dan waktu saat ini dalam variabel hasil:
response = requests.get(api_url, params=params, headers=headers)
if response.status_code == 200:
data = response.json()
print(f"{keyword.strip()},{data('requestMetadata')('googleHtmlFile')},{datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
result = {
'Keyword': keyword.strip(),
'Screenshot': data('requestMetadata')('googleHtmlFile'),
'Date': datetime.now().strftime("%Y-%m-%d %H:%M:%S")
}
results.append(result)Terakhir, setelah menelusuri semua kata kunci, kami menyimpan data historis ke file CSV. Kami memeriksa apakah file tersebut ada, dan jika tidak, kami membuatnya. Jika file tersebut ada, kita cukup menambahkan datanya ke file yang sudah ada.
df = pd.DataFrame(results)
csv_file_path="serp_history.csv"
file_exists = os.path.isfile(csv_file_path)
mode="a" if file_exists else 'w'
df.to_csv(csv_file_path, mode=mode, index=False, encoding='utf-8', header=not file_exists)Mari jalankan skrip langkah demi langkah dan periksa hasilnya.
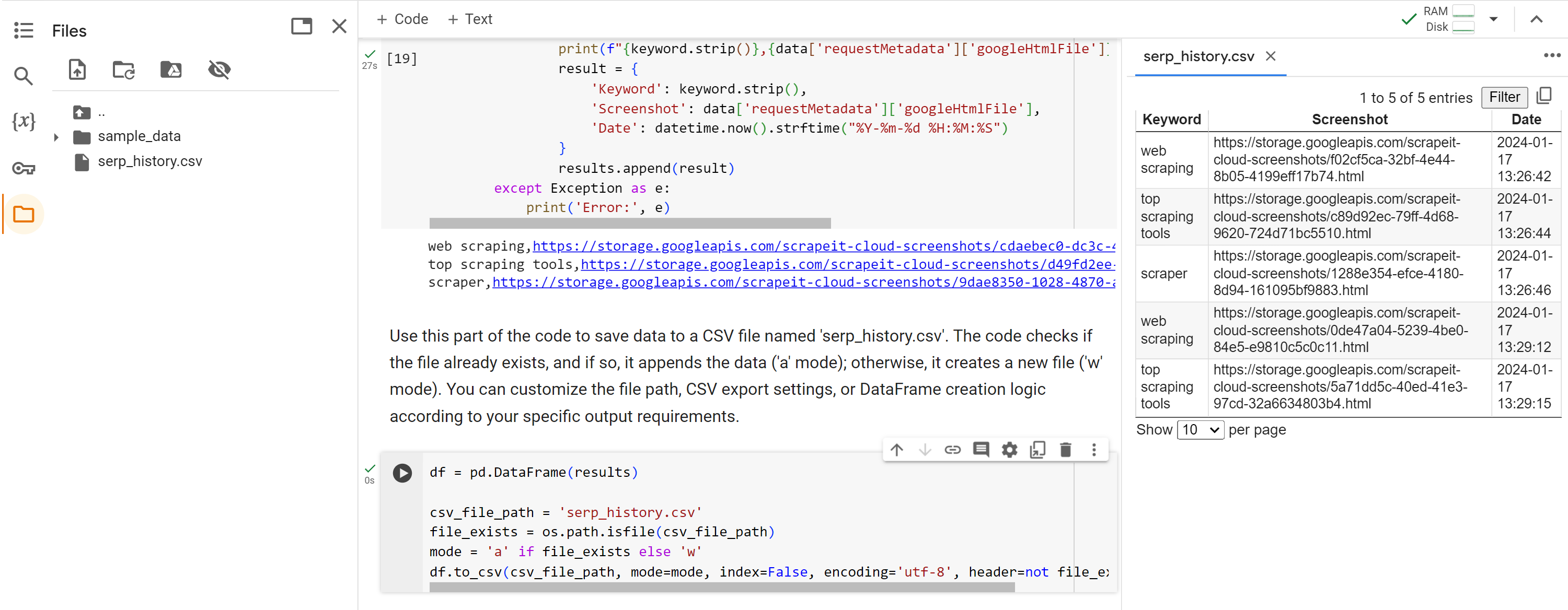
Seperti disebutkan, seluruh skrip tersedia di Google Collaboratory.
Diploma
Pada artikel ini, kami menjelajahi berbagai cara untuk mengumpulkan riwayat SERP, termasuk platform SEO dan API. Platform SEO menawarkan banyak data, namun API menawarkan fleksibilitas dan efektivitas biaya, terutama untuk kebutuhan spesifik.
Skrip Python yang disediakan memberikan contoh praktis penggunaan API SERP Scrape-It.Cloud untuk mengumpulkan dan menganalisis data riwayat peringkat SERP. Skrip ini menangkap cuplikan kata kunci dan stempel waktu serta mengekspor informasi ke file CSV untuk analisis mendetail.
Dengan menggunakan alat riwayat SERP, Anda bisa mendapatkan wawasan berharga tentang peringkat mesin pencari, aktivitas pesaing, dan faktor terkait SEO lainnya. Data ini dapat memengaruhi strategi SEO Anda dan meningkatkan visibilitas situs web Anda di hasil pencarian.