
Der SERP-Verlauf bietet wertvolle Erkenntnisse darüber, wie sich Website-Rankings, Mitbewerberaktivitäten und andere SEO-bezogene Faktoren verändert haben. Durch die Analyse der SERP-Verlaufsdaten können Sie die Faktoren besser verstehen, die sich auf die Sichtbarkeit Ihrer Website in den Suchergebnissen auswirken.
In diesem Artikel besprechen wir Tools, mit denen sich der Google SERP-Verlauf verfolgen lässt. Wir besprechen auch die Erstellung Ihres Tools zur Erfassung der erforderlichen Daten. Wir stellen außerdem ein Skript zur Verfügung, mit dem jeder den SERP-Verlauf erfassen kann.
Tools für die SERP-Verlaufssammlung
Tools zur Erfassung des SERP-Verlaufs dienen dazu, Änderungen auf Suchmaschinen-Ergebnisseiten (SERPs) zu verfolgen und zu speichern. Mit diesen Tools können Sie die Dynamik von Änderungen bei Website-Rankings, Schlüsselwörtern und anderen Parametern im SERP analysieren.
Es gibt zwei Hauptansätze zum Sammeln des SERP-Verlaufs: das Speichern von Daten über das SERP oder das Speichern eines Snapshots des SERP. Der letztere Ansatz ist bequemer und liefert vollständigere Daten, sodass Sie die SERP so anzeigen können, wie sie zu einem bestimmten Zeitpunkt angezeigt wurde.
Für die Erfassung des SERP-Verlaufs stehen verschiedene Tools zur Verfügung:
- SEO-Tools und -Plattformen. Viele SEO-Plattformen wie Serpstat, Ahrefs und SEMrush bieten SERP-Tracking-Tools an. Diese Tools liefern in der Regel Daten zu Website-Rankings, Konkurrenzaktivitäten und anderen Kennzahlen. Allerdings können sie teuer sein und über 200 US-Dollar pro Monat kosten. Darüber hinaus stellen einige Tools nur begrenzte Informationen bereit, beispielsweise Website-Rankings und Links.
- SERP-APIs. Einige Dienste bieten APIs an, mit denen SERP-Daten erfasst werden können. Dieser Ansatz ist flexibler und kostengünstiger als die Verwendung einer SEO-Plattform. APIs stellen normalerweise alle verfügbaren Informationen aus dem SERP bereit, einschließlich Snapshots, und Sie können auswählen, welche Daten Sie benötigen. Darüber hinaus können API-basierte Datenerfassungstools in Ihre Anwendungen integriert werden.
- Web-Scraping-Dienste. Sie können Web Scraper auch verwenden, um SERP-Daten zu sammeln. Web Scraper sind Tools, die automatisch Daten von Websites extrahieren können. Dieser Ansatz ist der einfachste Weg, an die erforderlichen Daten zu gelangen.
Die beste Option zum Sammeln des SERP-Verlaufs ist die Verwendung einer API, die Daten zu Suchergebnissen und einen Seiten-Snapshot bereitstellen kann. Dadurch können Sie jederzeit genau sehen, wie die Suchergebnisse aussahen. Als Beispiel verwenden wir die Scrape-It.Cloud SERP API, die diese Daten zurückgibt.
So verfolgen Sie historische SERPs
Dieses Tutorial zeigt Ihnen, wie Sie den SERP-Verlauf mithilfe einer SERP-API verfolgen, die für Nicht-Programmierer und diejenigen geeignet ist, die ihr Skript erstellen möchten. Der einfachste Weg, an die Daten zu gelangen, ist die Verwendung eines vorkonfigurierten Google Sheets mit App Script.
Wenn Sie Ihr flexibles Tool erstellen möchten, ohne sich mit der Programmierung zu befassen, verwenden Sie Make.com oder Zapier, um einfache Integrationen zu erstellen. Oder Sie können ein Skript erstellen, das Ihre benötigten Funktionen ausführt.
Verwenden Sie die Google Sheets-Vorlage
Der einfachste Weg, Snapshots der Google-Suchergebnisse zu sammeln, ist die Verwendung einer vorgefertigten Vorlage. Kopieren Sie dazu unsere Google-Tabelle und starten Sie das Add-on Scrape-It.Cloud. Wählen Sie „Rank Checker“ und geben Sie Ihren API-Schlüssel, Ihre Schlüsselwörter und einen Link zu der Domain ein, deren Position Sie überprüfen möchten. Auch die anderen Parameter können Sie nach Wunsch anpassen.
Sobald Sie den Rank Checker konfiguriert haben, können Sie ihn starten, um für jedes Schlüsselwort Schnappschüsse und Links zur gefundenen Seite sowie deren aktuelle Position zu erhalten. Um ein Archiv mit Screenshots von Suchergebnissen zu erstellen, führen Sie einfach den Rank Checker in der gewünschten Häufigkeit aus.
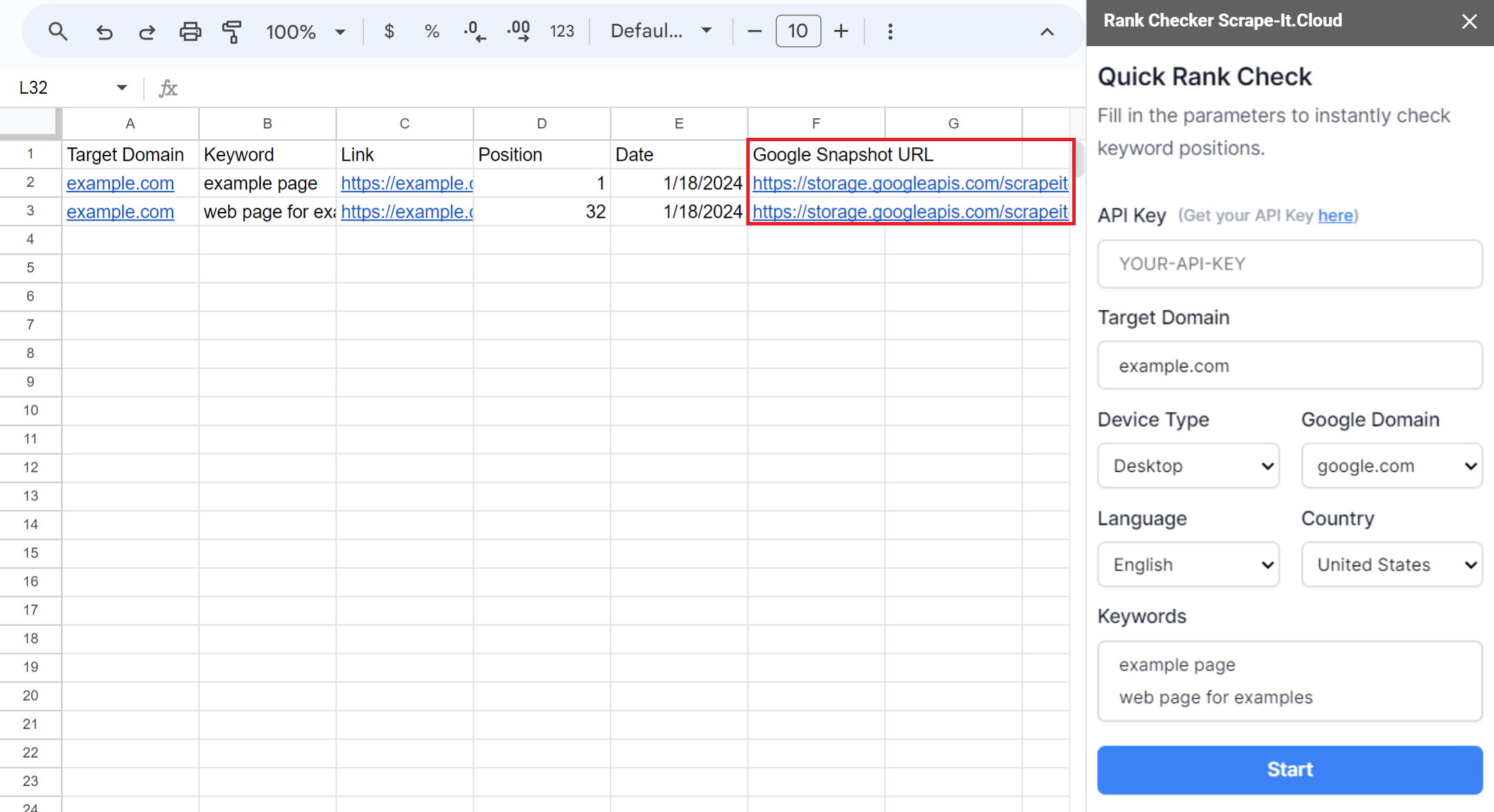
Neben dem Sammeln von Schnappschüssen und dem Verfolgen von Positionen können Sie weitere Funktionen dieser Vorlage nutzen, wie zum Beispiel die automatische Positionsverfolgung mit Google Sheets. Weitere Informationen finden Sie in unserem Artikel zum Rank Tracker in Google Sheets.
Verwenden Sie Zapier oder den Make.com Integration Service
Eine andere Lösung besteht darin, Integrationsdienste zu nutzen, um personalisierte Apps ohne Programmierkenntnisse zu erstellen. Zapier und Make.com sind die beliebtesten Dienste dieser Art. Wir haben bereits erläutert, wie man Zaps mit Zapier entwickelt, Daten von Google SERP und verschiedenen Websites mit Make.com erhält.
Um einen SERP-Verlaufs-Tracker in Zapier zu erstellen, erstellen Sie einen Trigger für die Snapshot-Sammlung, die Keyword-Quelle und die Scrape-It.Cloud SERP-API. Dabei ergeben sich folgende Daten:
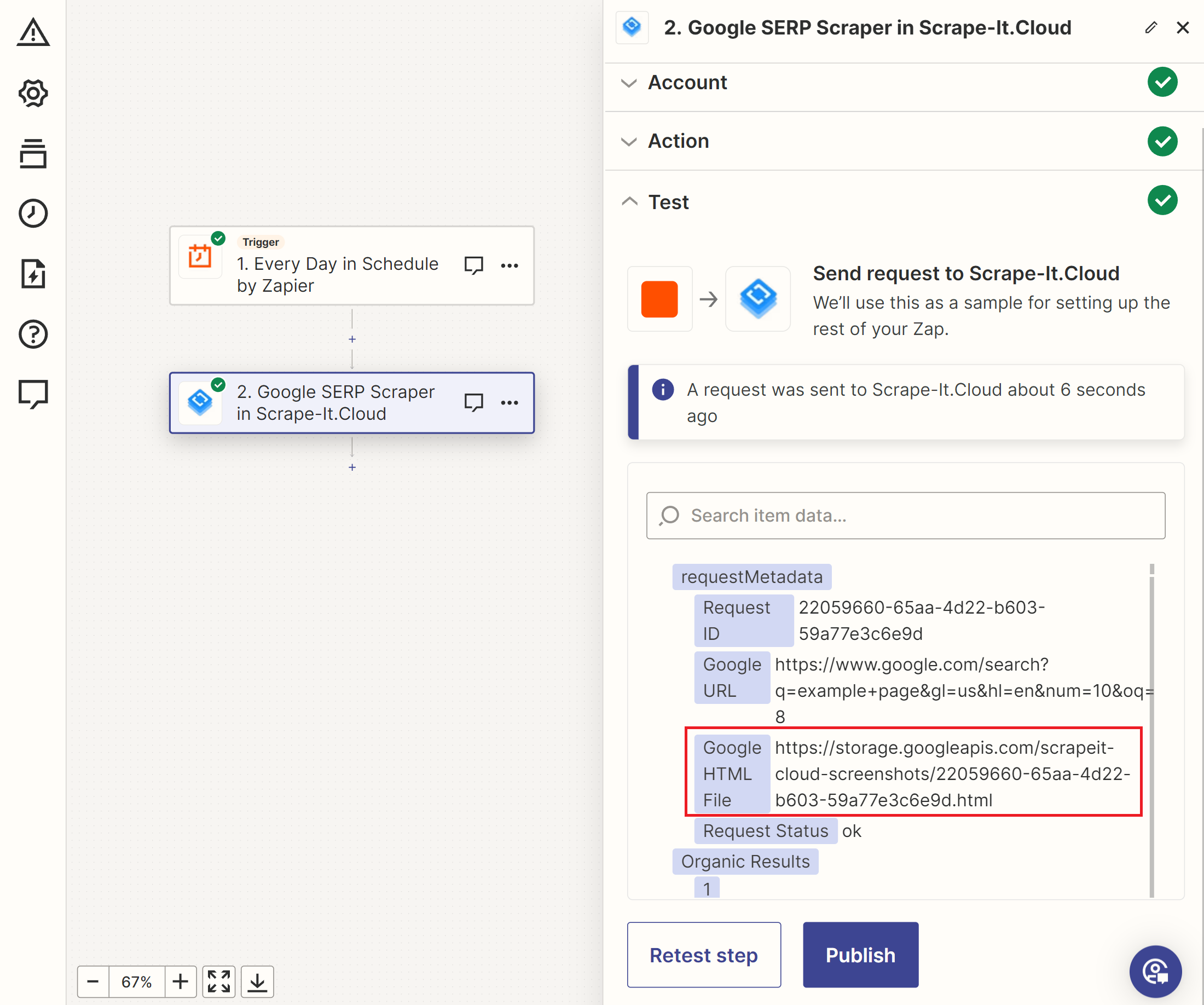
Anschließend können Sie diese Daten in Google Sheets, E-Mail oder einen anderen Dienst integrieren, um sie zu speichern oder zu verarbeiten.
Make.com bietet mehr Flexibilität bei der Verarbeitung von Arrays. Für das regelmäßige Scraping von Snapshots des SERP-Verlaufs für alle Schlüsselwörter können Sie die Funktionen von Make.com nutzen, ohne zusätzliche Quellen hinzuzufügen. Der übrige Ansatz ist derselbe wie bei Zapier.
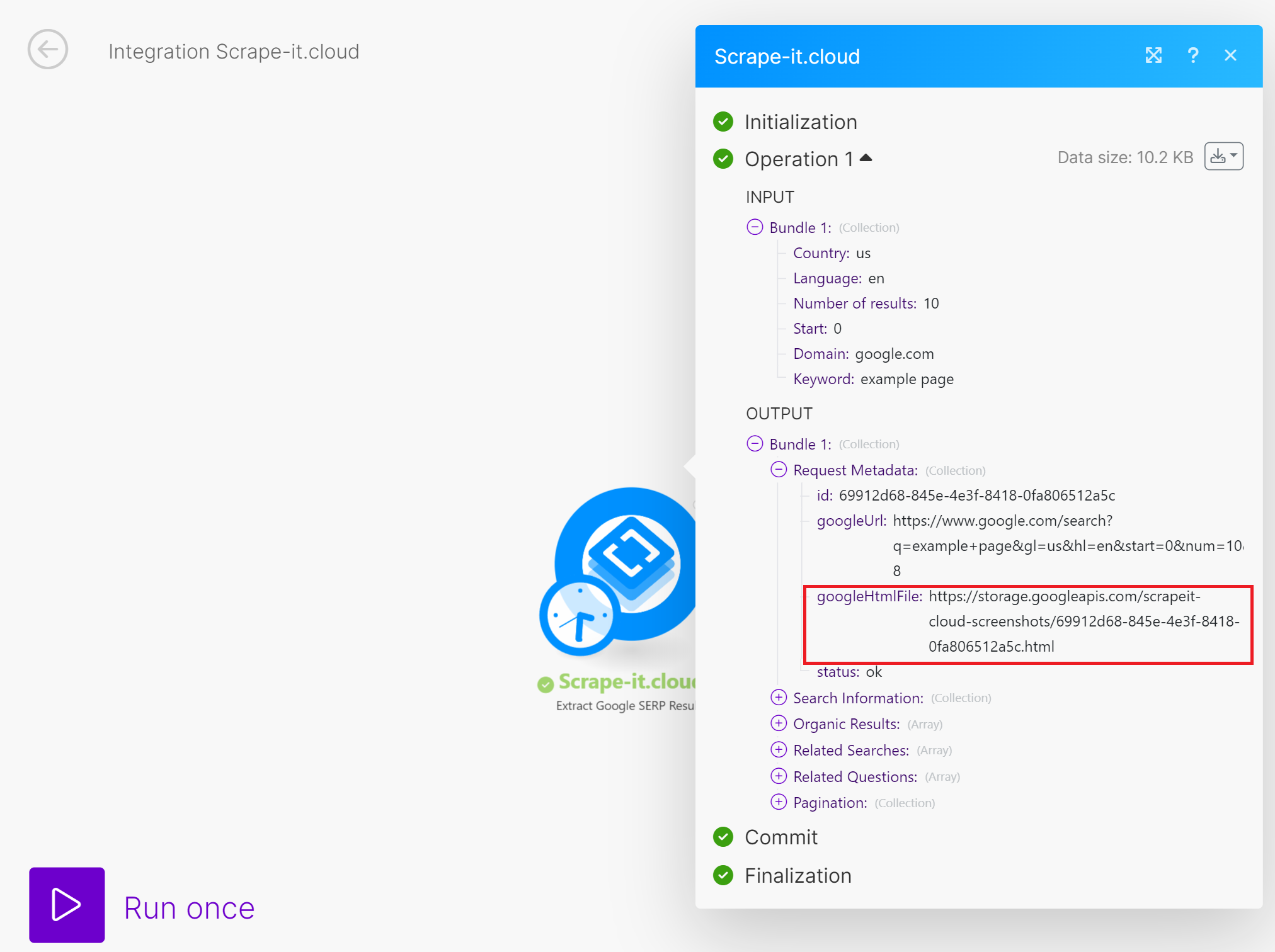
Sie können auch entscheiden, wie Sie die gesammelten Daten verarbeiten oder speichern und in Ihre App integrieren möchten.
Verwenden Sie Python-Skript
Um zu beginnen, haben wir auf Google Colaboratory ein lauffähiges Skript bereitgestellt, damit Sie es sofort verwenden können. Dazu müssen Sie Ihren API-Schlüssel und Ihre Schlüsselwörter eingeben. Sobald Sie dies getan haben, können Sie das Skript ausführen, um die Daten abzurufen.
Wenn Sie Ihre eigene erstellen möchten, erstellen Sie eine neue Datei mit der Erweiterung *.py und importieren Sie die erforderlichen Bibliotheken. In diesem Skript verwenden wir:
- Der Anfragen Bibliothek, um HTTP-Anfragen an die API zu stellen.
- Der Betriebssystem Die Bibliothek kann die Datei überprüfen, in der wir die SERP-Verlaufsdaten speichern.
- Der Terminzeit Die Bibliothek fügt das aktuelle Datum und die aktuelle Uhrzeit hinzu.
- Der Pandas Die Bibliothek erstellt einen Datenrahmen und speichert die Daten in einer Datei. In dieser Anleitung speichern wir die Daten in einer CSV-Datei, Pandas unterstützt jedoch auch andere Dateiformate.
Alle Bibliotheken außer Pandas sind vorinstalliert und können sofort verwendet werden. Um Pandas zu installieren, können Sie den folgenden Befehl verwenden:
pip install pandasUm die Bibliotheken in Ihr Python-Skript zu importieren, verwenden Sie den folgenden Code:
import requests
import pandas as pd
from datetime import datetime
import osDefinieren wir nun die Variablen, in denen die Daten gespeichert werden. Wir benötigen zwei – einen zum Speichern der verarbeiteten Schlüsselwörter und einen zum Sammeln der Ergebnisse. Wir werden sie später verwenden:
keywords = ()
results = ()Legen Sie die Variable fest, in der Sie die Schlüsselwörter platzieren können, die in Zukunft verarbeitet und zur Schlüsselwortvariable hinzugefügt werden:
serp_keywords = ("""
web scraping, top scraping tools
scraper
""")Dieser Ansatz ist aus Bequemlichkeitsgründen erforderlich, da es manchmal einfacher ist, Schlüsselwörter mit einer neuen Zeile und manchmal mit einem Komma anzugeben. Um Fehler in Zukunft zu vermeiden, platzieren wir daher zunächst die Originaldaten in einer separaten Variablen, verarbeiten sie dann und erstellen ein Array.
Als nächstes legen wir die Parameter für die Arbeit mit der API fest – den Link, den API-Schlüssel und die grundlegenden Parameter, wie die Google-Domain, das Land und die Suchsprache. Dies ist notwendig, um die Anfrage individueller und nützlicher zu gestalten:
api_url="https://api.scrape-it.cloud/scrape/google"
headers = {'x-api-key': 'API-KEY'}
base_params = {
'domain': 'google.com',
'gl': 'us',
'hl': 'en'
}Um fortzufahren, müssen wir alle Schlüsselwörter aus der in der Variablen serp_keywords gespeicherten Zeichenfolge extrahieren. Dazu teilen wir es Zeile für Zeile auf und prüfen, ob Kommas als Trennzeichen dienen. Danach fügen wir jedes Schlüsselwort zur Schlüsselwortvariable hinzu:
serp_keywords = (line.strip() for line in serp_keywords(0).split('\n') if line.strip())
for input_line in serp_keywords:
words = input_line.split(',')
if words:
keywords.extend(words)Jetzt können wir das resultierende Array Element für Element durchlaufen und Snapshots für jede Abfrage sammeln. Fügen wir eine Schleife zum Durchlaufen aller Schlüsselwörter hinzu und fügen sie zusammen mit den zuvor hinzugefügten Grundparametern als Parameter zum Aufrufen der API hinzu.
for keyword in keywords:
if keyword.strip():
params = {**base_params, 'q': keyword.strip()}
try:
# Here will be code
except Exception as e:
print('Error:', e)Wir haben einen Try/Except-Block verwendet, um Code von Fehlern zu isolieren, die während der Ausführung von Anforderungen auftreten könnten. Selbst wenn bei der Verarbeitung eines Schlüsselworts ein Fehler auftritt, gibt das Skript bei diesem Ansatz Fehlerinformationen an die Konsole aus und fährt mit dem nächsten Schlüsselwort fort, anstatt die Ausführung vollständig anzuhalten.
Stellen Sie eine API-Anfrage und speichern Sie bei positiver Antwort (Statuscode 200) das Schlüsselwort, die Google SERP-Snapshot-URL sowie das aktuelle Datum und die aktuelle Uhrzeit in der Ergebnisvariablen:
response = requests.get(api_url, params=params, headers=headers)
if response.status_code == 200:
data = response.json()
print(f"{keyword.strip()},{data('requestMetadata')('googleHtmlFile')},{datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
result = {
'Keyword': keyword.strip(),
'Screenshot': data('requestMetadata')('googleHtmlFile'),
'Date': datetime.now().strftime("%Y-%m-%d %H:%M:%S")
}
results.append(result)Nachdem wir alle Schlüsselwörter durchlaufen haben, speichern wir abschließend die historischen Daten in einer CSV-Datei. Wir prüfen, ob die Datei existiert, und wenn nicht, erstellen wir sie. Wenn die Datei vorhanden ist, hängen wir die Daten einfach an die vorhandene Datei an.
df = pd.DataFrame(results)
csv_file_path="serp_history.csv"
file_exists = os.path.isfile(csv_file_path)
mode="a" if file_exists else 'w'
df.to_csv(csv_file_path, mode=mode, index=False, encoding='utf-8', header=not file_exists)Lassen Sie uns das Skript Schritt für Schritt ausführen und die Ergebnisse überprüfen.
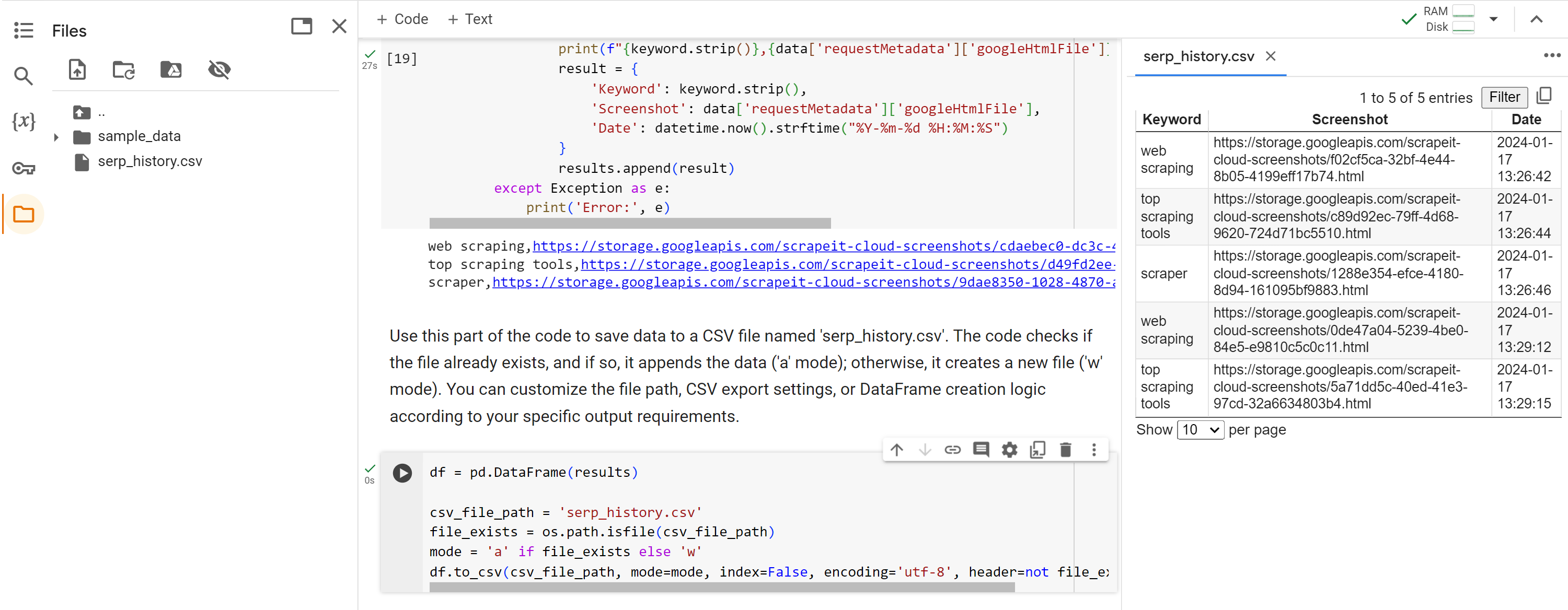
Wie bereits erwähnt, ist das gesamte Skript in Google Collaboratory verfügbar.
Abschluss
In diesem Artikel haben wir die verschiedenen Möglichkeiten zur Erfassung des SERP-Verlaufs untersucht, einschließlich SEO-Plattformen und APIs. SEO-Plattformen bieten eine Fülle von Daten, APIs bieten jedoch Flexibilität und Kosteneffizienz, insbesondere für spezifische Anforderungen.
Das bereitgestellte Python-Skript bietet ein praktisches Beispiel für die Verwendung der Scrape-It.Cloud SERP-API zum Sammeln und Analysieren von SERP-Ranking-Verlaufsdaten. Dieses Skript erfasst Schlüsselwort-Snapshots und Zeitstempel und exportiert die Informationen zur detaillierten Analyse in eine CSV-Datei.
Durch den Einsatz von SERP-History-Tools können Sie wertvolle Einblicke in Suchmaschinen-Rankings, Mitbewerberaktivitäten und andere SEO-bezogene Faktoren gewinnen. Diese Daten können Ihre SEO-Strategien beeinflussen und die Sichtbarkeit Ihrer Website in den Suchergebnissen erhöhen.
