
Yelp ist ein großes und beliebtes Verzeichnis mit lokalen Unternehmen wie Restaurants, Hotels, Spas, Klempnern und so ziemlich jeder Art von Unternehmen, die Sie finden können. Die Plattform ist ideal, um B2B-Potenzialkunden zu finden.
Allerdings ist die manuelle Suche nach Interessenten auf der Plattform zeitaufwändig. Daher können Sie ein Web-Scraping-Tool verwenden, um Daten von Yelp zu sammeln. Eine solche Strategie wird sich auf lange Sicht auszahlen.
Warum Yelp kratzen?
Yelp-Daten können wertvoll sein und Ihrem Unternehmen zum Erfolg verhelfen, wenn sie richtig eingesetzt werden. Das Sammeln von Informationen über diese Plattform bietet viele Vorteile. Zum Beispiel:
- Wettbewerbsforschung;
- Verbesserung der Benutzererfahrung;
- Validierung von Marketingkampagnen;
- Überwachung der Kundenstimmung;
- Generierung von Leads.
Jedes auf Yelp gelistete Unternehmen hat seine eigene Seite. Auf dieser Seite finden Sie Informationen zum Firmennamen, zur Telefonnummer, zur Adresse, zum Link zur Website und zu den Öffnungszeiten. Unternehmenssuchergebnisse werden nach geografischem Standort, Preisspanne und anderen einzigartigen Merkmalen gefiltert. Um die erforderlichen Daten zu erhalten, können Sie entweder die offizielle Yelp-API verwenden oder Ihren eigenen Web-Scraper erstellen.
Wir haben ein Tutorial vorbereitet, in dem wir einen Yelp-Scraper erstellen, der einen Link zu einem Unternehmensverzeichnis aufnehmen, zu jeder Unternehmensseite gehen und diese Informationen sammeln kann:
- Firmenname;
- Telefonnummer;
- Adresse;
- Website-Link;
- Bewertung;
- die Anzahl der Bewertungen.
Analyse der Website
Beispielsweise benötigen wir Informationen über alle Restaurants in der Innenstadt von Calgary. Dazu haben wir die Suchanfrage „Restaurants“ eingegeben und die Stadt Calgary ausgewählt.
Yelp hat uns zur Suchergebnisseite der Suchmaschine weitergeleitet:
https://www.yelp.ca/search?find_desc=restaurants&find_loc=Calgary%2C+AB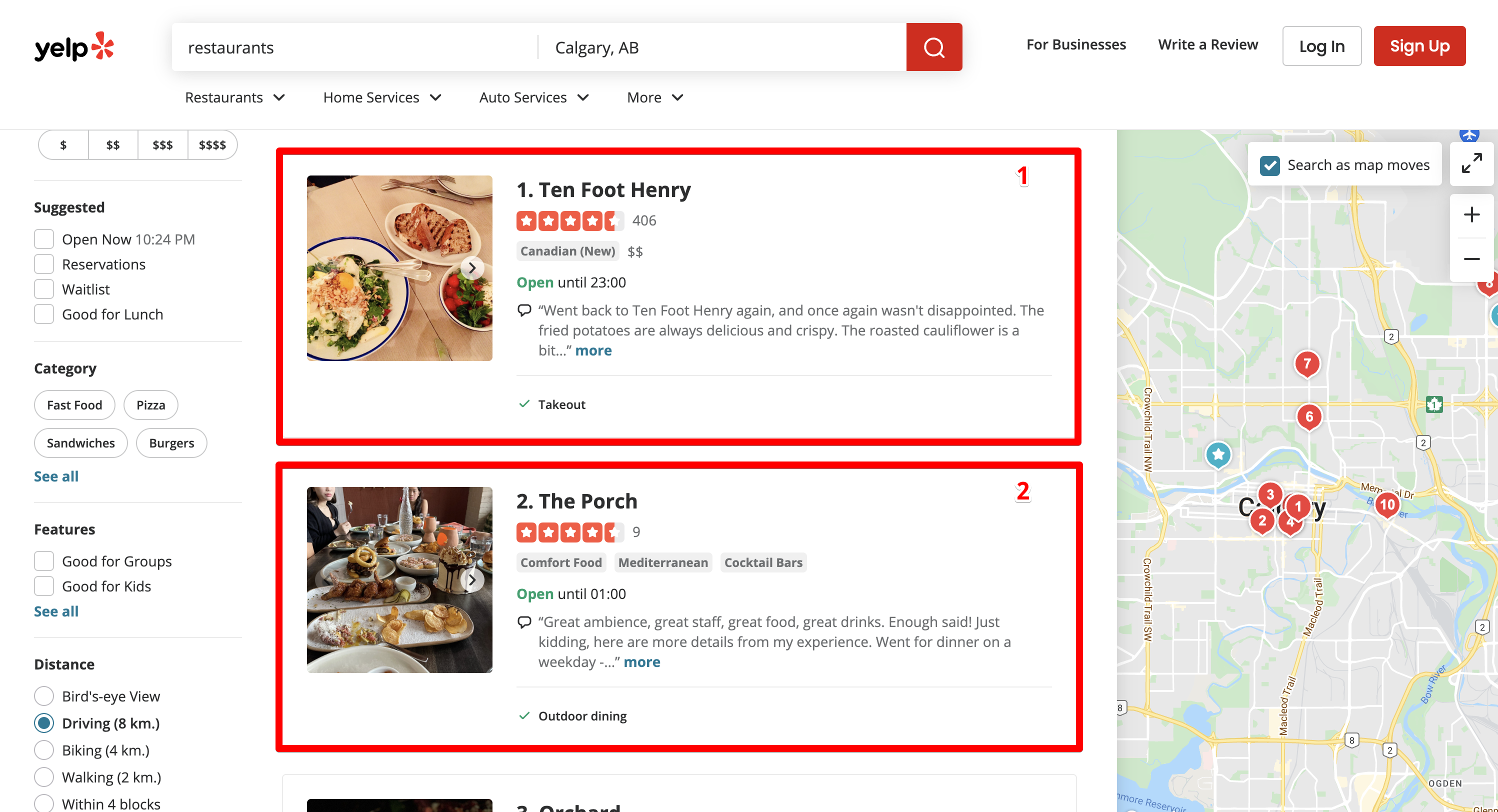
Auf jeder Seite sind 10 Restaurants aufgeführt. Insgesamt 24 Seiten.
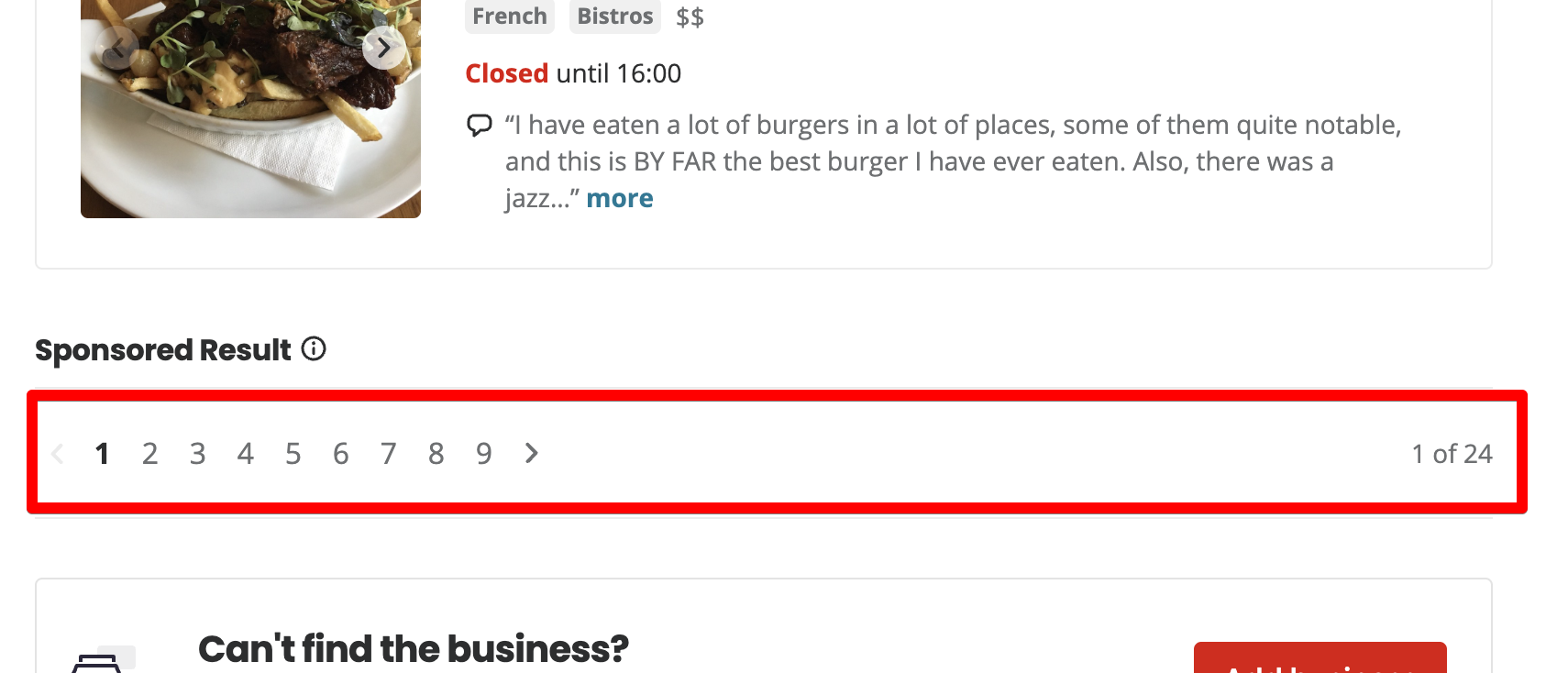
Wenn Sie auf Seite 2 klicken, fügt Yelp den Startparameter zur URL hinzu.
https://www.yelp.ca/search?find_desc=restaurants&find_loc=Calgary%2C+AB&start=10Wenn Sie zu Seite 3 wechseln, ändert sich der Wert des Startparameters auf 20.
https://www.yelp.ca/search?find_desc=restaurants&find_loc=Calgary%2C+AB&start=20Okay, jetzt verstehen wir die Logik, wie die Paginierung in Yelp funktioniert – Start ist ein Offset von den Nulldatensätzen. Wenn Sie die ersten 10 Einträge anzeigen möchten, dann sollten Sie den Startparameter auf 0 setzen. Wenn Sie Einträge von 11 bis 20 anzeigen möchten, dann setzen wir den Startparameter auf 10.
Unternehmensseite
Oben auf der Unternehmensseite werden der Name, die Bewertung und die Anzahl der Bewertungen angezeigt.
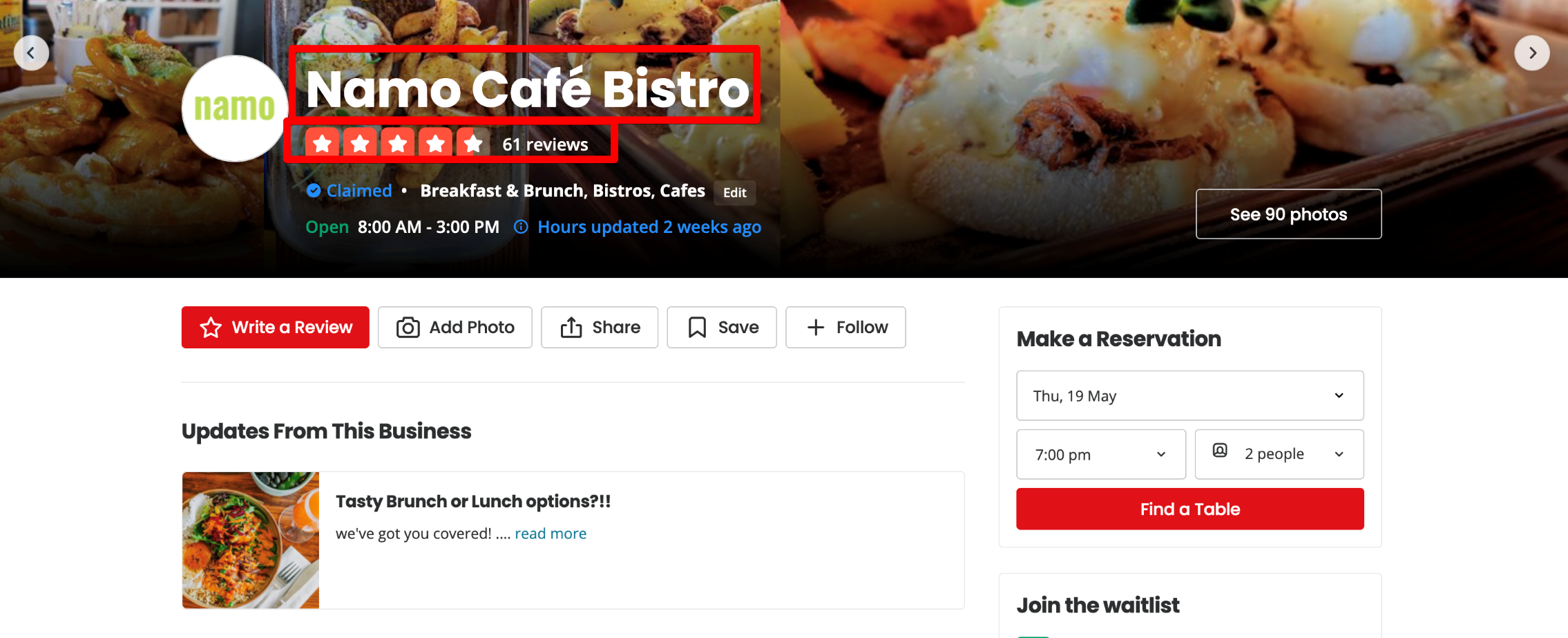
Scrollen Sie auf der Seite nach unten.
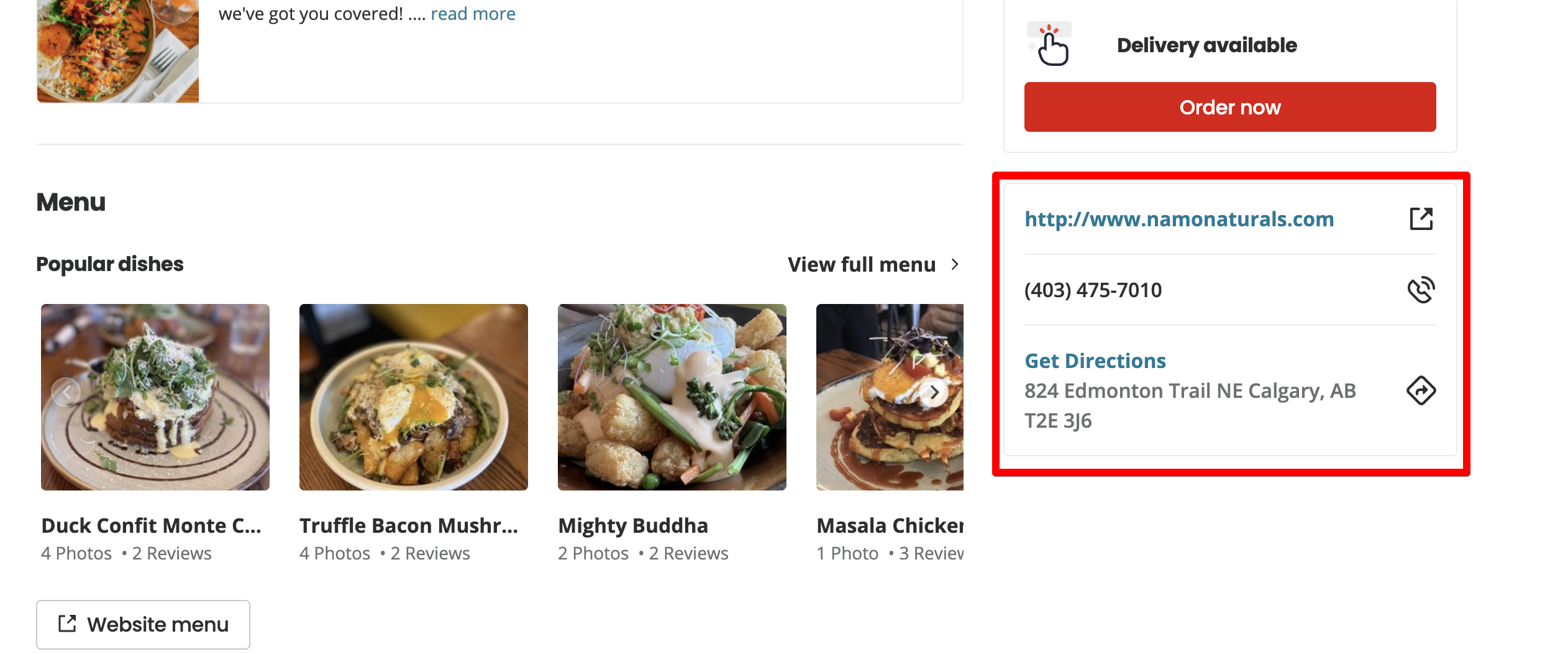
Im zweiten Teil der Seite sehen wir die restlichen Daten, die uns interessieren: einen Site-Link, eine Telefonnummer und eine Adresse.
Schreiben eines NodeJS-Scraper mit Puppeteer
Sie können Ihren Scraper mithilfe des Yelp-API-JavaScript-Beispiels von der offiziellen Yelp-Website erstellen, aber das ist ganz einfach. Machen wir die Aufgabe anspruchsvoller und bauen wir mit Puppeteer unseren eigenen Scraper.
Erstellen Sie ein Verzeichnis für den Scraper
scrapeit@MBP-scrapeit scrapeit-cloud-samples % mkdir yelp-scraper
scrapeit@MBP-scrapeit scrapeit-cloud-samples % cd yelp-scraper
scrapeit@MBP-scrapeit yelp-scraper %Initialisierung des Projekts über npm
Sie können das Projekt beispielsweise über npm initialisieren:
scrapeit@MBP-scrapeit yelp-scraper % npm init
This utility will walk you through creating a package.json file.
It only covers the most common items, and tries to guess sensible defaults.
See `npm help init` for definitive documentation on these fields
and exactly what they do.
Use `npm install ` afterwards to install a package and
save it as a dependency in the package.json file.
Press ^C at any time to quit.
package name: (yelp-scraper)
version: (1.0.0)
description: Yelp business scraper
entry point: (index.js)
test command:
git repository:
keywords:
author: Roman M
license: (ISC)
About to write to /Users/scrapeit/workspace/scrapeit-cloud-samples/yelp-scraper/package.json:
{
"name": "yelp-scraper",
"version": "1.0.0",
"description": "Yelp business scraper",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "Roman M",
"license": "ISC"
}
Is this OK? (yes) yesFestlegen der Abhängigkeiten, die wir brauchen
Wir werden mehrere Abhängigkeiten verwenden:
- Puppeteer – NodeJS-Bibliothek, die eine API für die Interaktion und Steuerung des Chrome-Browsers bereitstellt.
- Cheerio – jQuery-Kernel, der speziell für den Servergebrauch entwickelt wurde.
Wir werden Puppeteer verwenden, um Yelp-Seiten zu öffnen und HTML abzurufen.
npm i puppeteerCheerio wird für die HTML-Analyse verwendet.
npm i cheerioScraper-Architektur
Wir erstellen mehrere Klassen und teilen die Verantwortung zwischen ihnen auf:
- YelpScraper – die Klasse, die für das Abrufen von HTML von Yelp verantwortlich ist.
- YelpParser – die für das HTML-Parsing verantwortliche Klasse, die wir von der YelpScraper-Klasse erhalten haben.
- getPagesAmount(listingPageHtml)
- getBusinessesLinks(listingPageHtml)
- extractBusinessInformation(businessPageHtml)
Wir erstellen die App, die zwei Klassen und index.js verwendet, um all diese Dinge miteinander zu verknüpfen.
Programmierung
Lassen Sie uns zunächst die Architektur in Code umwandeln. Lassen Sie uns in einfachen Worten beispielsweise die Klassen skizzieren und die Methoden deklarieren.
Erstellen Sie zwei Dateien: yelp-scraper.js und yelp-parser.js im Stammordner des Projekts.
// yelp-scraper.js
class YelpScraper {
async scrape(url) {
}
}
export default YelpScraper;// yelp-parser.js
class YelpParser {
getPagesAmount(listingPageHtml) {
}
getBusinessLinks(listingPageHtml) {
}
extractBusinessInformation(businessPageHtml) {
}
}
export default YelpParser;Umsetzung der scrape Methode der YelpScrape Klasse
// yelp-scraper.js
import puppeteer from "puppeteer";
class YelpScraper {
async scrape(url) {
let browser = null;
let page = null;
let content = null;
try {
browser = await puppeteer.launch({ headless: false });
page = await browser.newPage();
await page.goto(url, { waitUntil: 'load' });
content = await page.content();
} catch(e) {
console.log(e.message);
} finally {
if (page) {
await page.close();
}
if (browser) {
await browser.close();
}
}
return content;
}
}
export default YelpScraper;
Die Haupt- und einzige Verantwortung liegt bei der scrape Die Methode besteht darin, den HTML-Code der übergebenen Seite zurückzugeben.
Dazu müssen Sie:
Öffnen Sie den Browser:
browser = await puppeteer.launch();
page = await browser.newPage();Wechseln Sie zur Seite und warten Sie, bis sie geladen ist:
await page.goto(url, { waitUntil: 'load' });Schreiben Sie den HTML-Code der Seite in die content Variable:
content = await page.content();Wenn ein Fehler auftritt, protokollieren Sie ihn:
console.log(e.message);Schließen Sie die Seite und den Browser:
if (page) {
await page.close();
}
if (browser) {
await browser.close();
}
Geben Sie den Inhalt zurück:
return content;Umsetzung YelpParser Klassenmethoden
// yelp-parser.js
import * as cheerio from 'cheerio';
class YelpParser {
getPagesAmount(listingPageHtml) {
const $ = cheerio.load(listingPageHtml);
const paginationTotalText = $('.pagination__09f24__VRjN4 .css-chan6m').text();
const totalPages = paginationTotalText.match(/of.((0-9)+)/)(1);
return Number(totalPages);
}
getBusinessLinks(listingPageHtml) {
const $ = cheerio.load(listingPageHtml);
const links = $('a.css-1m051bw')
.filter((i, el) => /^\/biz\//.test($(el).attr('href')))
.map((i, el) => $(el).attr('href'))
.toArray();
return links;
}
extractBusinessInformation(businessPageHtml) {
const $ = cheerio.load(businessPageHtml);
const title = $('div(data-testid="photoHeader")').find('h1').text().trim();
const address = $('address')
.children('p')
.map((i, el) => $(el).text().trim())
.toArray();
const fullAddress = address.join(', ');
const phone = $('p(class=" css-1p9ibgf")')
.filter((i, el) => /\(\d{3}\)\s\d{3}-\d{4}/g.test($(el).text()))
.map((i, el) => $(el).text().trim())
.toArray()(0);
const reviewsCount = $('span(class=" css-1fdy0l5")')
.filter((i, el) => /review/.test($(el).text()))
.text()
.trim()
.match(/\d{1,}/g)(0) || '';
let rating = '';
const headerHtml = $('div(data-testid="photoHeader")').html();
if (!headerHtml || headerHtml.indexOf('aria-label="') === -1) {
rating = '';
}
const startIndx = headerHtml.indexOf('aria-label="') + 'aria-label="'.length;
rating = Number(headerHtml.slice(startIndx, startIndx + 1)) || '';
return {
title,
fullAddress,
phone,
reviewsCount,
rating
}
}
}
export default YelpParser;
Der getPagesAmount Die Methode verwendet den HTML-Code der ersten Auflistungsseite und analysiert die Anzahl der Yelp-Ausgabeseiten.

Initialisieren Sie cheerio und entfernen Sie den Text, der sich im Element befindet, mit dem .pagination__09f24__VRjN4 .css-chan6m Wähler.
const $ = cheerio.load(listingPageHtml);
const paginationTotalText = $('.pagination__09f24__VRjN4 .css-chan6m').text();Um den Selektor des Elements zu finden, klicken Sie mit der rechten Maustaste auf die Seite und klicken Sie auf Inspect im Chrome-Kontextmenü. Suchen Sie im Quellcode der Seite das gewünschte Element und kopieren Sie den Selektor.
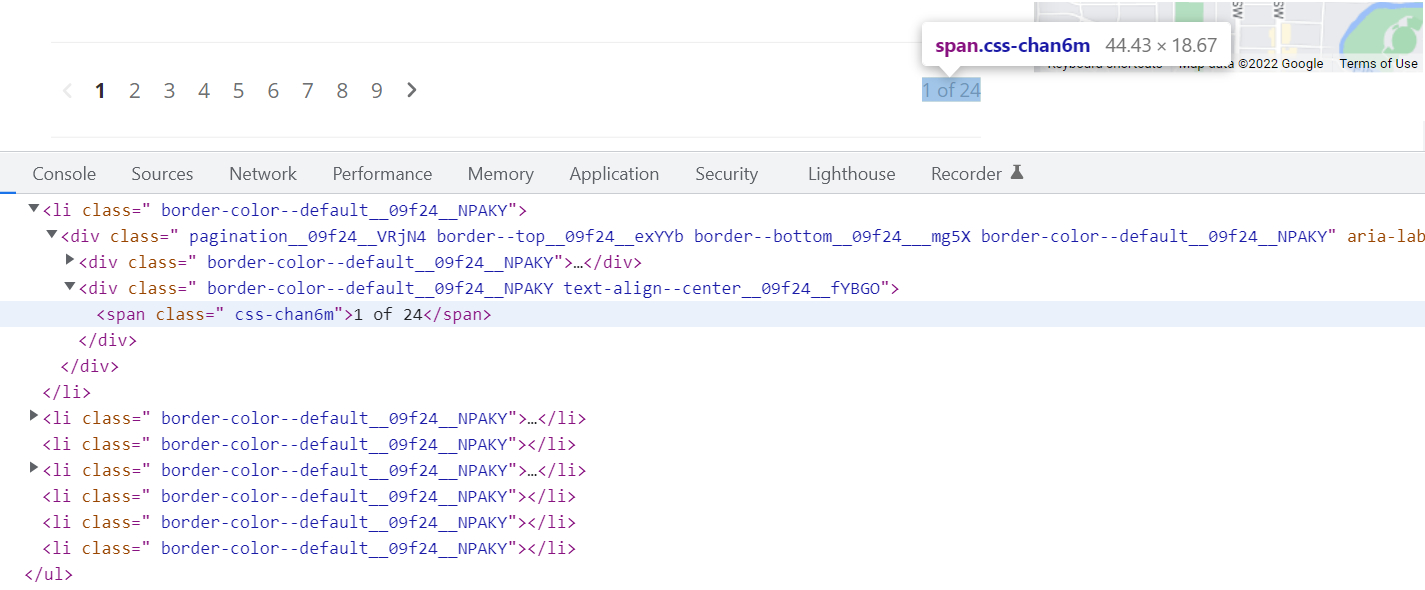
In diesem Fall hat das Element, das die Anzahl der Seiten anzeigt, einen .css-chan6m Klasse, aber mit dieser Klasse auf der Seite gibt es andere Elemente, also nehmen wir auch den Elementselektor, der das übergeordnete Element ist. Wir nahmen .pagination__09f24__VRjN4. Das Ergebnis ist .pagination__09f24__VRjN4 .css-chan6m.
Um die Gesamtseitenzahl des Textes zu ermitteln 1 of 24, wir verwenden einen regulären Ausdruck. Sie können beispielsweise Folgendes verwenden:
const totalPages = paginationTotalText.match(/of.((0-9)+)/)(1);
return Number(totalPages);Als Ergebnis gibt diese Funktion die Nummer zurück 24also die Anzahl der Seiten.
Derselbe Algorithmus zum Parsen von Links zu Unternehmensseiten wird im verwendet getBusinessLinks Funktion, die eine Reihe von Links zu Geschäftsseiten zurückgeben sollte.
Der extractBusinessInformation Die Funktion übernimmt den HTML-Code der Geschäftsseite und analysiert die benötigten Informationen durch Selektoren auf die gleiche Weise.
Anwendungseinstiegspunkt
Um die Parser- und Scraper-Klassen zu verbinden, erstellen wir eine index.js-Datei. Dies ist der Einstiegspunkt der Anwendung, der den Datenabrufprozess startet und steuert.
import YelpScraper from "./yelp-scraper.js";
import YelpParser from "./yelp-parser.js";
const url="https://www.yelp.ca/search?find_desc=restaurants&find_loc=Calgary%2C+AB&start=0";
const main = async() => {
const yelpScraper = new YelpScraper();
const yelpParser = new YelpParser();
const firstPageListingHTML = await yelpScraper.scrape(url);
const numberOfPages = yelpParser.getPagesAmount(firstPageListingHTML);
const scrapedData = ();
for (let i = 0; i < numberOfPages; i++) {
const link = `https://www.yelp.ca/search?find_desc=restaurants&find_loc=Calgary%2C+AB&start=${i * 10}`;
const listingPage = await yelpScraper.scrape(link);
const businessesLinks = yelpParser.getBusinessLinks(listingPage);
for (let k = 0; k < businessesLinks.length; k++) {
const businessesLink = businessesLinks(k);
const businessPageHtml = await yelpScraper.scrape(`https://www.yelp.ca${businessesLink}`);
const extractedInformation = yelpParser.extractBusinessInformation(businessPageHtml);
scrapedData.push(extractedInformation);
}
}
console.log(scrapedData);
};
main();
Zuerst initialisieren wir unsere Scraper- und Parser-Klassen.
const yelpScraper = new YelpScraper();
const yelpParser = new YelpParser();Als Nächstes erhalten wir den Inhalt der Yelp-Suchergebnisseite und extrahieren die Anzahl der Seiten.
const firstPageListingHTML = await yelpScraper.scrape(url);
const numberOfPages = yelpParser.getPagesAmount(firstPageListingHTML);Führen Sie die Schleife von 0 bis 23 aus. In jeder Iteration generieren wir einen Link zu einer bestimmten Suchergebnisseite und analysieren die Links zu den Unternehmensseiten.
const link = `https://www.yelp.ca/search?find_desc=restaurants&find_loc=Calgary%2C+AB&start=${i * 10}`;
const listingPage = await yelpScraper.scrape(link);
const businessesLinks = yelpParser.getBusinessLinks(listingPage);Führen Sie die Schleife auf Unternehmensseiten aus. In jeder Iteration rufen wir den Inhalt der Unternehmensseite ab und erhalten die gewünschten Informationen.
for (let k = 0; k < businessesLinks.length; k++) {
const businessesLink = businessesLinks(k);
const businessPageHtml = await yelpScraper.scrape(`https://www.yelp.ca${businessesLink}`);
const extractedInformation = yelpParser.extractBusinessInformation(businessPageHtml);
scrapedData.push(extractedInformation);
}
Den Schaber laufen lassen.
node index.jsWarten Sie auf das Ende des Schabens und damit auf das Ende scrapedData Variable erhalten wir die endgültigen Daten, die wir in die Datenbank schreiben oder eine CSV generieren können.
(
{
title: 'Ten Foot Henry',
fullAddress: '1209 1st Street SW, Calgary, AB T2R 0V3',
phone: '(403) 475-5537',
reviewsCount: '406',
rating: 4
}
{
title: 'The Porch',
fullAddress: '730 17th Avenue SW, Calgary, AB T2S 0B7',
phone: '(587) 391-8500',
reviewsCount: '9',
rating: 4
}
{
title: 'Orchard',
fullAddress: '134 - 620 10 Avenue SW, Calgary, AB T2R 1C3',
phone: '(403) 243-2392',
reviewsCount: '12',
rating: 4
},
...
)
Verfeinerung des Schabers
Yelp schützt die Website vor Scraping, indem es häufige Anfragen von derselben IP-Adresse blockiert. Sie können einen Proxy verbinden, aber wir verwenden die Scrape-it.Cloud-API, die Proxys rotiert und Puppeteer in der Cloud ausführt.
Durch die Verwendung von Scrape-it.Cloud können wir das System nicht durch die Ausführung kopfloser Browser lokal oder auf unserem Server belasten. Dies kann ein Problem sein, wenn Sie schnell mit mehreren Threads scrapen möchten.

https://github.com/puppeteer/puppeteer/issues?q=CPU+usage+
Scrape Yelp mit Scrape-it.Cloud
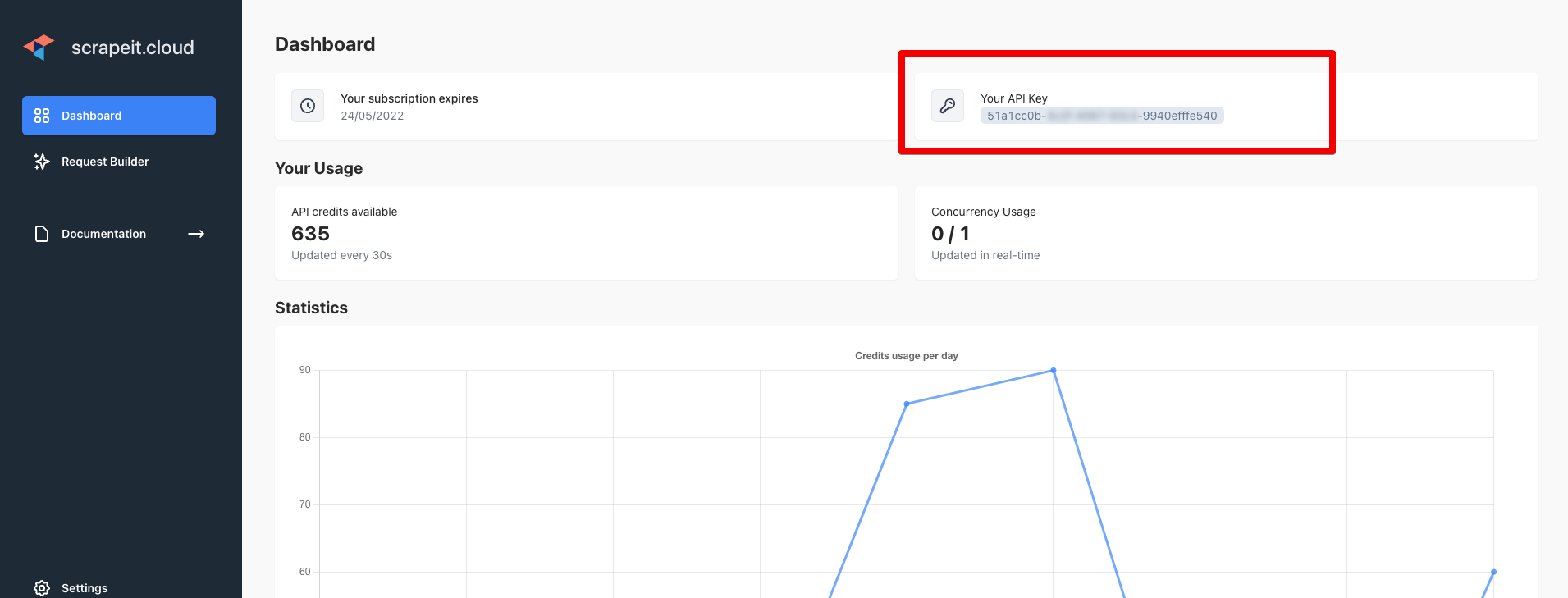
Melden Sie sich unter https://scrape-it.cloud/ an und kopieren Sie den API-Schlüssel von der Dashboard-Seite:
Installieren Sie axios, um Anfragen an Scrape-it.Cloud zu stellen.
npm i axiosUmschreiben der YelpScraper
// yelp-scraper.js
import axios from "axios";
class YelpScraper {
async scrape(url) {
const data = JSON.stringify({
"url": url,
"window_width": 1920,
"window_height": 1080,
"block_resources": false,
"wait": 0,
"proxy_country": "US",
"proxy_type": "datacenter"
});
const config = {
method: 'post',
url: 'https://api.scrape-it.cloud/scrape',
headers: {
'x-api-key': 'YOUR_API_KEY',
'Content-Type': 'application/json'
},
data : data
};
try {
let response = await axios(config);
if (response.data.status === 'error') {
console.log('1 attempt error');
response = await axios(config);
}
return response.data.scrapingResult.content;
} catch(e) {
console.log(e.message);
return '';
}
}
}
export default YelpScraper;
Geben Sie Parameter für die Scrape-it.Cloud-API an. Mithilfe dieser Parameter stellt Scrape-it.Cloud Anfragen unter Verwendung von US-IP-Adressen. Jede Anfrage wird mit einer neuen IP-Adresse gestellt. Auf diese Weise umgehen wir den Schutz der Anzahl der Anfragen von einer IP.
const data = JSON.stringify({
"url": url,
"window_width": 1920,
"window_height": 1080,
"block_resources": false,
"wait": 0,
"proxy_country": "US",
"proxy_type": "datacenter"
});
Die Axios-Einstellungen. In den Headern übergeben wir den API-Schlüssel, den Sie auf der Dashboard-Seite erhalten haben.
const config = {
method: 'post',
url: 'https://api.scrape-it.cloud/scrape',
headers: {
'x-api-key': 'YOUR_API_KEY',
'Content-Type': 'application/json'
},
data : data
};
Stellen Sie eine Anfrage an die Scrape-it.Cloud-API, um den Inhalt abzurufen, und versuchen Sie es erneut, wenn die Anfrage fehlschlägt. Dies kann passieren, wenn die von Scrape-it.Cloud verwendete IP-Adresse bereits gesperrt wurde.
try {
let response = await axios(config);
if (response.data.status === 'error') {
console.log('1 attempt error');
response = await axios(config);
}
return response.data.scrapingResult.content;
} catch(e) {
console.log(e.message);
return '';
}
Wenn Sie Inhalte nicht verwenden können datacenter Proxy, versuchen Sie, den zu ändern proxy_type Parameter zu residentialdas ist die tatsächliche Geräte-IP
const data = JSON.stringify({
"url": url,
"window_width": 1920,
"window_height": 1080,
"block_resources": false,
"wait": 0,
"proxy_country": "US",
"proxy_type": "residential"
});
Sobald alles erledigt ist, starten wir den Scraper:
node index.jsUnd wir erhalten das gleiche Ergebnis:
(
{
title: 'Ten Foot Henry',
fullAddress: '1209 1st Street SW, Calgary, AB T2R 0V3',
phone: '(403) 475-5537',
reviewsCount: '406',
rating: 4
}
{
title: 'The Porch',
fullAddress: '730 17th Avenue SW, Calgary, AB T2S 0B7',
phone: '(587) 391-8500',
reviewsCount: '9',
rating: 4
}
{
title: 'Orchard',
fullAddress: '134 - 620 10 Avenue SW, Calgary, AB T2R 1C3',
phone: '(403) 243-2392',
reviewsCount: '12',
rating: 4
},
...
)
Endlich
Jetzt ist es keine Option, sich vom Internet fernzuhalten, denn dann kehren Sie einer riesigen Gruppe möglicher Kunden den Rücken.
Web Scraping ist ein weiterer Schritt in der Geschäftsentwicklung – die Automatisierung des Datenerfassungsprozesses. Sein Vorteil ist, dass es vielseitig einsetzbar ist und viele Tätigkeiten mit dem richtigen Werkzeug einfacher werden.
Vielen Dank, dass Sie bis zum Ende gelesen haben. Wir hoffen, dass Ihnen dieses Tutorial wirklich weiterhilft.
Lesen Sie noch mehr über die Amazon Product Scraper-Software
