
Java ist eine der beliebtesten Programmiersprachen, daher fragt man sich natürlich, ob sie eine gute Wahl für Web Scraping ist. Obwohl Java zum Scrapen von Daten verwendet werden kann, ist es möglicherweise nicht die optimale Wahl für kleine Projekte, bei denen es auf Geschwindigkeit ankommt. Andererseits kann Java eine ausgezeichnete Wahl für große oder skalierbare Projekte sein, die Multithreading für die Datenerfassung und -verarbeitung erfordern.
In diesem Artikel bieten wir ein umfassendes Tutorial zu den Vor- und Nachteilen der Verwendung von Java für Web-Scraping, wann Sie Java für das Scraping wählen sollten, wie Sie die erforderlichen Komponenten installieren und konfigurieren und wie Sie Ihren ersten Scraper erstellen. Wir behandeln auch fortgeschrittenere Techniken, wie die Erstellung eines vollwertigen Crawlers zum Crawlen aller Website-Seiten, Parallelitäts- und Parallelitätsprinzipien und die Verwendung von Headless-Browsern in Java.
Verwendung von Java für Web Scraping
Java ist eine der beliebtesten und ältesten Programmiersprachen. Es handelt sich um eine vielseitige Sprache, die zur Entwicklung verschiedener Anwendungen, einschließlich Web Scraping, verwendet werden kann.
| Vorteile von Java für Web Scraping | Nachteile von Java für Web Scraping |
|---|---|
| Große und aktive Community | Relativ komplexe Sprache |
| Umfangreiches Ökosystem und Bibliotheken (z. B. Jsoup, HtmlUnit) | Erfordert eine explizite Deklaration von Datentypen (statische Typisierung) |
| Umfangreiche Dokumentation, Tutorials und Foren | Beinhaltet Boilerplate-Code, was ihn ausführlicher macht |
| „Einmal schreiben, überall ausführen“-Ansatz | Anwendungen können langsamer sein als Anwendungen in anderen Sprachen |
| Zuverlässige Unterstützung für parallele Programmierung | Die Kompilierung in Bytecode fügt der Entwicklung einen zusätzlichen Schritt hinzu |
Diese Tabelle gibt einen allgemeinen Überblick über die Vor- und Nachteile von Web Scraping in Java. Jetzt werden wir sie ausführlicher besprechen.
Vorteile von Java für Web Scraping
Java verfügt über eine große und aktive Community, ein reichhaltiges Ökosystem und viele Bibliotheken, die das Web-Scraping einfacher machen, wie z. B. Jsoup und HtmlUnit. Bei Fragen oder Schwierigkeiten besteht jederzeit die Möglichkeit, sich an eine große und aktive Community zu wenden, die zu umfangreichen Dokumentationen, Tutorials und Foren führt. Eine solche Unterstützung erleichtert es Entwicklern, Problemlösungen zu finden und Erfahrungen auszutauschen.
Der Java-Ansatz „Einmal schreiben, überall ausführen“ ermöglicht es Entwicklern, Web-Scraping-Anwendungen ohne Änderungen auf verschiedenen Plattformen zu entwickeln und bereitzustellen. Darüber hinaus eignet sich Java dank seiner zuverlässigen Unterstützung für parallele Programmierung für die Lösung umfangreicher Web-Scraping-Aufgaben und steigert die Effizienz und Leistung.
Nachteile von Java für Web Scraping
Java ist eine leistungsstarke und vielseitige Programmiersprache mit einem breiten Anwendungsspektrum. Allerdings weist sie auch einige Nachteile auf, die berücksichtigt werden sollten, bevor man sie als Lernsprache auswählt.
Eine der größten Herausforderungen beim Erlernen von Java besteht darin, dass es sich um eine relativ komplexe Sprache handelt. Dies liegt daran, dass es sich um eine statisch typisierte Sprache handelt, was bedeutet, dass die Datentypen von Variablen und Ausdrücken explizit deklariert werden müssen. Dies kann das Erlernen schwieriger machen als das Erlernen dynamisch typisierter Sprachen wie Python.
Eine weitere Herausforderung von Java besteht darin, dass viel Boilerplate-Code verwendet wird. Boilerplate-Code wird wiederholt verwendet, z. B. Code, um Objekte zu erstellen oder auf Ressourcen zuzugreifen. Dadurch kann Java-Code ausführlicher sein als in anderen Sprachen geschriebener Code.
Schließlich können Java-Anwendungen langsamer sein als in anderen Sprachen geschriebene Anwendungen. Java-Code muss in Bytecode kompiliert werden, bevor er ausgeführt werden kann. Dies kann einen zusätzlichen Schritt zum Entwicklungsprozess hinzufügen und zu Leistungsproblemen führen.
Voraussetzungen für Web Scraping mit Java
Bevor Sie mit der Entwicklung eines Web Scrapers in Java beginnen, müssen Sie eine Java-Entwicklungsumgebung einrichten. Dazu gehört Folgendes:
- Java LTS. Es wird empfohlen, die neueste stabile Version von der offiziellen Website zu verwenden. Ohne dies können Sie keine Java-Projekte erstellen.
- System aufbauen. Mit Build-Systemen wie Maven und Gradle können Sie Ihr Projekt auf einer Maschine kompilieren und ausführen. Wir werden die Installation später besprechen.
- Java-IDE. Dies ist nicht erforderlich, wird aber dringend empfohlen. IDEs erleichtern die Entwicklung und Ausführung von Projekten. Die beliebteste IDE ist IntelliJ IDEA, mit der Sie Projekte mit Gradle oder Maven und einem eigenen Build-System kompilieren können. Dies ist die empfohlene Methode für Anfänger.
Sobald Sie über diese Komponenten verfügen, können Sie Ihren Java Web Scraper erstellen.
So installieren und verwenden Sie Java Build Systems
Die Wahl des Build-Systems liegt bei Ihnen, aber wenn Sie ein Anfänger sind, empfehlen wir die Verwendung von IntelliJ IDEA und seinem integrierten Build-System. Maven und Gradle können ohne IDE über die Kommandozeile genutzt werden.
Maven
Um Maven zu installieren, laden Sie die neueste Version von der offiziellen Website herunter und extrahieren Sie das Archiv auf das Laufwerk C:. Fügen Sie dann das bin-Verzeichnis des extrahierten Maven-Ordners zur PATH-Umgebungsvariablen Ihres Systems hinzu.
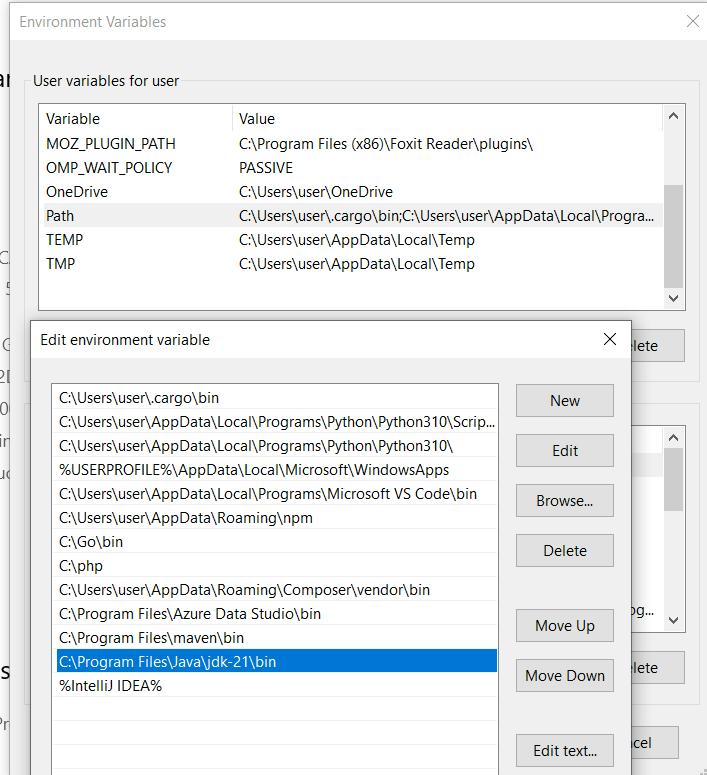
Um zu überprüfen, ob das Paket richtig konfiguriert ist, führen Sie Folgendes in der Eingabeaufforderung aus:
mvn -versionWenn Maven korrekt installiert ist, sollten Informationen zur Maven-Version und zugehörige Details angezeigt werden.

Um ein Projekt mit Maven zu erstellen, benötigen Sie eine Befehlszeile. Navigieren Sie zum Verzeichnis Ihres Projekts und führen Sie den folgenden Befehl aus, um das Projekt zu erstellen:
mvn clean installDieser Befehl erstellt und installiert das Projekt in Ihrem lokalen Maven-Repository. Führen Sie nach einem erfolgreichen Build den folgenden Befehl aus, um die Anwendung auszuführen:
java -cp target/project_name.jar MainClassNameBeachten Sie, dass Sie den Namen der Hauptklasse angeben müssen, die den Einstiegspunkt für Ihre Anwendung darstellt.
Gradle
Um Gradle verwenden zu können, müssen Sie außerdem das Archiv von der offiziellen Website herunterladen und den Pfad zum bin-Verzeichnis des extrahierten Archivs zu Ihren Umgebungsvariablen hinzufügen.
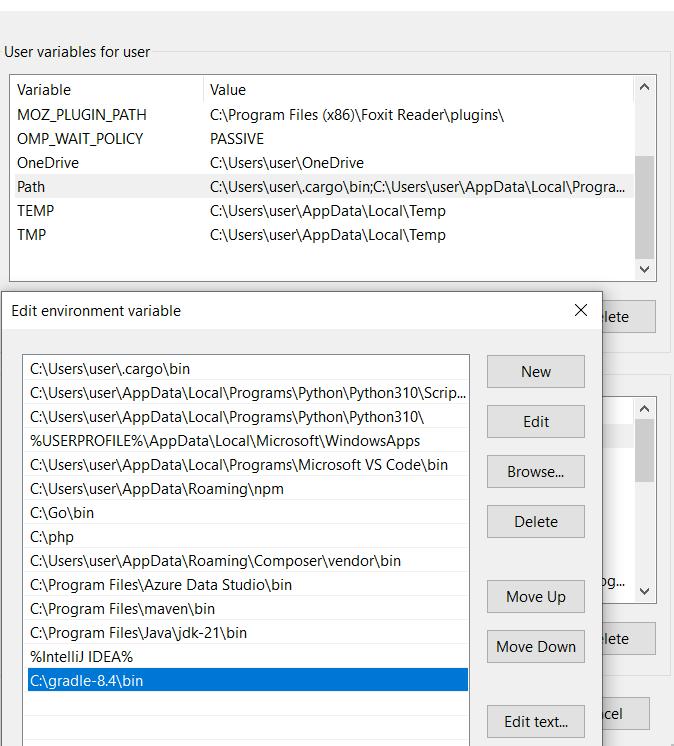
Sobald Sie dies getan haben, können Sie die Installation überprüfen, indem Sie den folgenden Befehl in einem Terminal ausführen:
gradle -vWenn Gradle korrekt installiert ist, sollten Sie eine Ausgabe ähnlich der folgenden sehen:
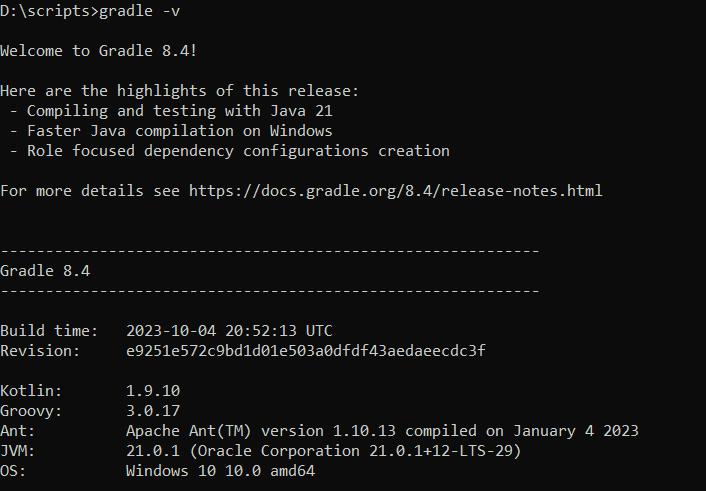
Um Gradle mit SDKMAN zu installieren, führen Sie den folgenden Befehl aus:
sdk install gradle 8.4Um ein Projekt zu erstellen, öffnen Sie eine Eingabeaufforderung und navigieren Sie zum Projektverzeichnis. Führen Sie dann den Build-Befehl in der Eingabeaufforderung aus:
gradlew buildFühren Sie nach einem erfolgreichen Build den Befehl aus, um die Anwendung zu starten:
java -jar build/libs/your-project.jarWie Sie sehen, ist die Verwendung von Maven und Gradle sehr ähnlich. Sie können sie auch zum Erstellen über die Befehlszeile und über IntelliJ verwenden, worauf wir weiter unten eingehen.
IntelliJ-IDEE
Um das IntelliJ-Build-System verwenden zu können, müssen Sie IntelliJ IDEA von der offiziellen Website herunterladen und installieren. Nach der Installation können Sie beim Erstellen eines neuen Projekts die gewünschte Programmiersprache auswählen und ein System erstellen.
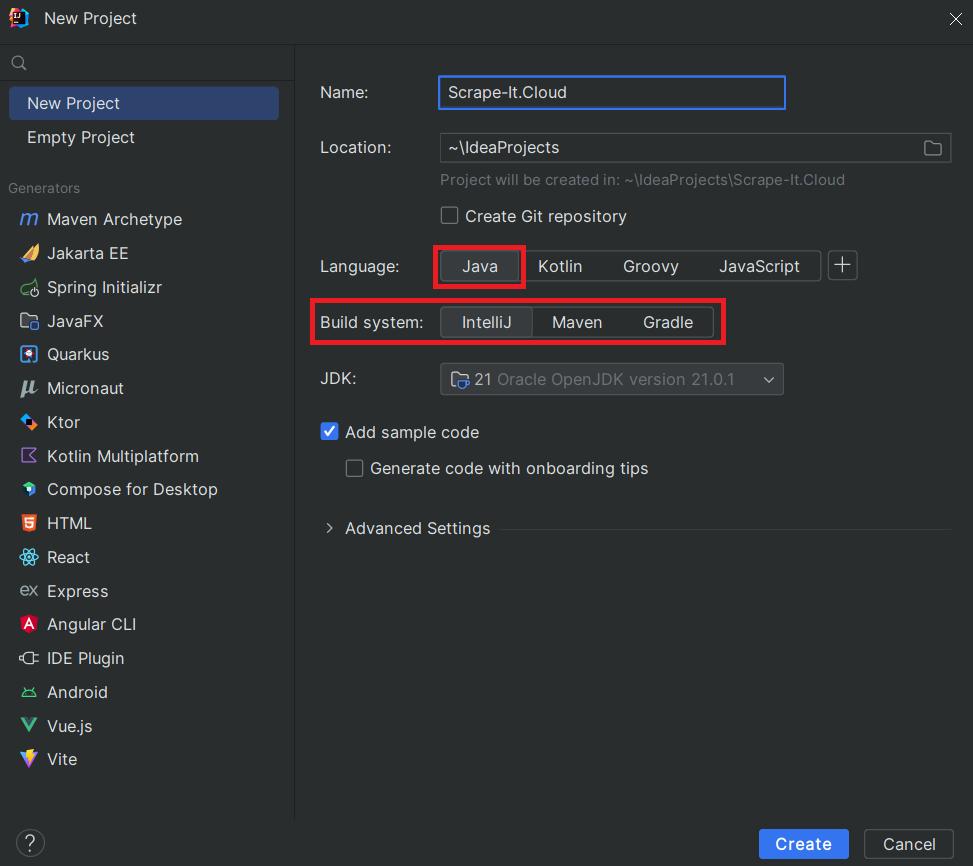
Danach können Sie das Projekt jederzeit über die entsprechenden Schaltflächen oben starten.
Bibliotheken für Web Scraping in Java
Java verfügt über zwei Bibliotheken, die am häufigsten für Web Scraping verwendet werden: Jsoup und HtmlUnit. Beide eignen sich für Web-Scraping und HTML-Parsing, haben jedoch unterschiedliche Zwecke, Stärken und Schwächen. Schauen wir uns beide Java-Bibliotheken an und wählen die passendere für unsere nachfolgenden Beispiele aus.
Jsuppe
Jsoup ist eine einfache und leichte Java-Bibliothek für die Arbeit mit HTML und DOM. Es ist eine gute Wahl für Anfänger und bietet eine praktische API zum Extrahieren und Bearbeiten von Daten aus HTML-Dokumenten.
Jsoup verwendet CSS-Selektoren zum Abfragen und Auswählen von HTML-Elementen, was das Verständnis erleichtert. Obwohl die Verwendung von CSS-Selektoren einen kleineren Funktionsumfang als XPath bietet, ist sie aufgrund ihrer Einfachheit beliebter.
Leider kann diese Bibliothek keine Daten von dynamischen Webseiten sammeln und verarbeiten, die Inhalte mithilfe von JavaScript laden. Es kann auch nicht das Verhalten eines echten Benutzers simulieren, der Headless-Browser verwendet.
HtmlUnit
Die HtmlUnit-Bibliothek hingegen behebt die Mängel von Jsoup, es mangelt ihr jedoch an ihrer leichten und benutzerfreundlichen Natur. Es stellt einen Headless-Browser bereit, der es Ihnen ermöglicht, mit Webseiten wie mit einem echten Browser zu interagieren und so das Verhalten eines echten Benutzers zu simulieren.
Darüber hinaus verfügt HtmlUnit über eine JavaScript-Engine, mit der Sie JavaScript auf Webseiten ausführen können. Sie können mit Webseiten interagieren, indem Sie Formulare senden, Links folgen und auf Seiten navigieren.
Jsoup vs. HtmlUnit
Aufgrund unserer Erfahrung empfehlen wir die Verwendung der Jsoup-Bibliothek zum Scrapen einfacher Seiten und HtmlUnit, wenn Sie einen Headless-Browser verwenden müssen. Welche Bibliothek für Ihre Bedürfnisse am besten geeignet ist, hängt jedoch von Ihren Fähigkeiten, spezifischen Zielen und Anforderungen ab. Um den Auswahlprozess zu vereinfachen, haben wir eine Tabelle erstellt, die die Bedingungen auflistet, unter denen Sie sich für die eine oder andere Bibliothek entscheiden sollten.
| Jsuppe | HtmlUnit |
|---|---|
| Geeignet zum Parsen statischer HTML-Dokumente. | Begrenzt im Vergleich zu HtmlUnit, nicht sein Hauptaugenmerk. |
| Eingeschränkte Unterstützung für dynamische Inhalte, die von JavaScript gerendert werden. | Kann dynamische Inhalte extrahieren. |
| Nicht für die Simulation von Benutzerinteraktionen auf Webseiten konzipiert. | Geeignet zum Simulieren von Browseraktionen, zum Absenden von Formularen und zum Klicken auf Links. |
| Führt kein JavaScript aus. | Verfügt über eine integrierte JavaScript-Engine zum Ausführen von JavaScript auf Webseiten. |
| Keine Unterstützung für die Navigation durch Seiten wie in einem Browser. | Bietet Headless-Browserfunktionen für Navigation und Interaktion. |
| Eher für einfache Parsing-Aufgaben geeignet. | Gut geeignet für Testszenarien, die eine Browserinteraktion erfordern. |
| Leichte Bibliothek mit geringerem Platzbedarf. | Größerer Platzbedarf aufgrund der Headless-Browser-Funktionen. |
| Einfache und benutzerfreundliche API. | Aufgrund zusätzlicher Browsersimulationsfunktionen ist es komplexer. |
Web Scraping mit Java mit Jsoup
Wie bereits erwähnt, ist Jsoup eine gute Wahl zum Scrapen einfacher Seiten und für Anfänger. Daher werden wir es als unser Hauptbeispiel verwenden. Wir werden HtmlUnit später behandeln, wenn wir fortgeschrittene Techniken und Headless-Browser besprechen.
Bibliothek in Java-Projekt importieren
Die Art und Weise, eine Bibliothek zu verbinden, kann je nach verwendetem Build-System unterschiedlich sein. Gradle und Maven erfordern die Beschreibung des Projekts und seiner Abhängigkeiten in einer XML-Datei, während IntelliJ den direkten Import der JAR-Datei der Bibliothek über die IntelliJ IDEA-Schnittstelle erfordert.
Um Maven verwenden zu können, müssen Sie eine pom.xml-Datei erstellen, die die neueste Jsoup-Bibliothek als Abhängigkeit angibt:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>web-scraper</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.16.2</version>
</dependency>
</dependencies>
</project>Um Ihrem Projekt in IntelliJ IDEA eine Bibliothek hinzuzufügen, laden Sie die JAR-Datei der Bibliothek herunter und fügen Sie sie dem Projekt hinzu, indem Sie zu Datei > Projektstruktur > Bibliotheken > Hinzufügen navigieren.
Anschließend können Sie die benötigten Bibliotheksmodule in Ihr Projekt importieren:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;Darüber hinaus müssen wir ein Ein-/Ausgabemodul importieren, um die Ausgabedaten in Zukunft auf dem Bildschirm anzuzeigen.
import java.io.IOException;Diese Module ermöglichen es uns nun, beliebige Daten zu extrahieren.
Stellen Sie eine Anfrage, um HTML zu erhalten
Um eine Website zu scrapen, müssen wir zunächst die Struktur unseres Projekts definieren. Dazu gehören die Hauptklasse, die die Projektinitialisierung startet, und die Funktion, die das Scraping durchführt.
public class Main {
public static void main(String() args) {
// Here will be code
}
}Um den Scraping-Prozess in Java zu demonstrieren, verwenden wir die OpenCart-Demoseite, auf der wir Produkte sammeln können. Um die CSS-Selektoren zu finden, die die Titel und Links beschreiben, öffnen Sie DevTools (F12 oder klicken Sie mit der rechten Maustaste und gehen Sie zu „Inspizieren“) und wählen Sie das gewünschte Element aus.
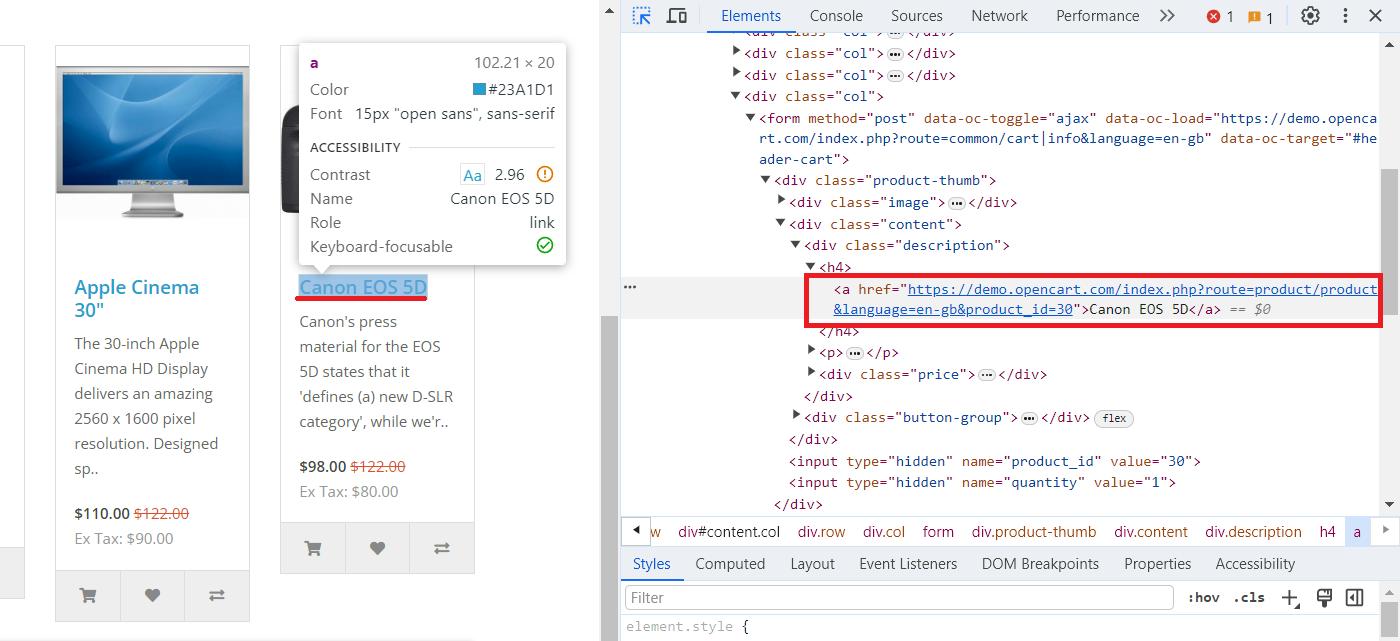
Kehren wir nun zu unserem Projekt zurück und besorgen uns den HTML-Code für diese Seite:
Document document = null;
try {
document = Jsoup.connect("https://demo.opencart.com/").get();
} catch (IOException e) {
throw new RuntimeException(e);
}Wir haben einen Try-Catch-Block verwendet, um zu verhindern, dass unser Skript abstürzt und im Falle einer fehlgeschlagenen Anfrage Fehlerinformationen erhält. Fahren wir mit dem nächsten Teil fort und extrahieren alle Titel und Links.
Lassen Sie uns nun die Website-Struktur untersuchen, die wir zuvor überprüft haben, und die erhaltene HTML-Struktur analysieren. Dazu wählen wir die notwendigen Elemente aus:
Elements links = document.select("a(href)");Dann durchlaufen Sie alle gefundenen Elemente, geben den Titel aus und verknüpfen die Daten mit dem Bildschirm:
for (Element link : links) {
System.out.println("Title: " + link.text());
System.out.println("Link: " + link.attr("href"));
}Starten Sie das Projekt und sehen Sie sich die Ergebnisse an:
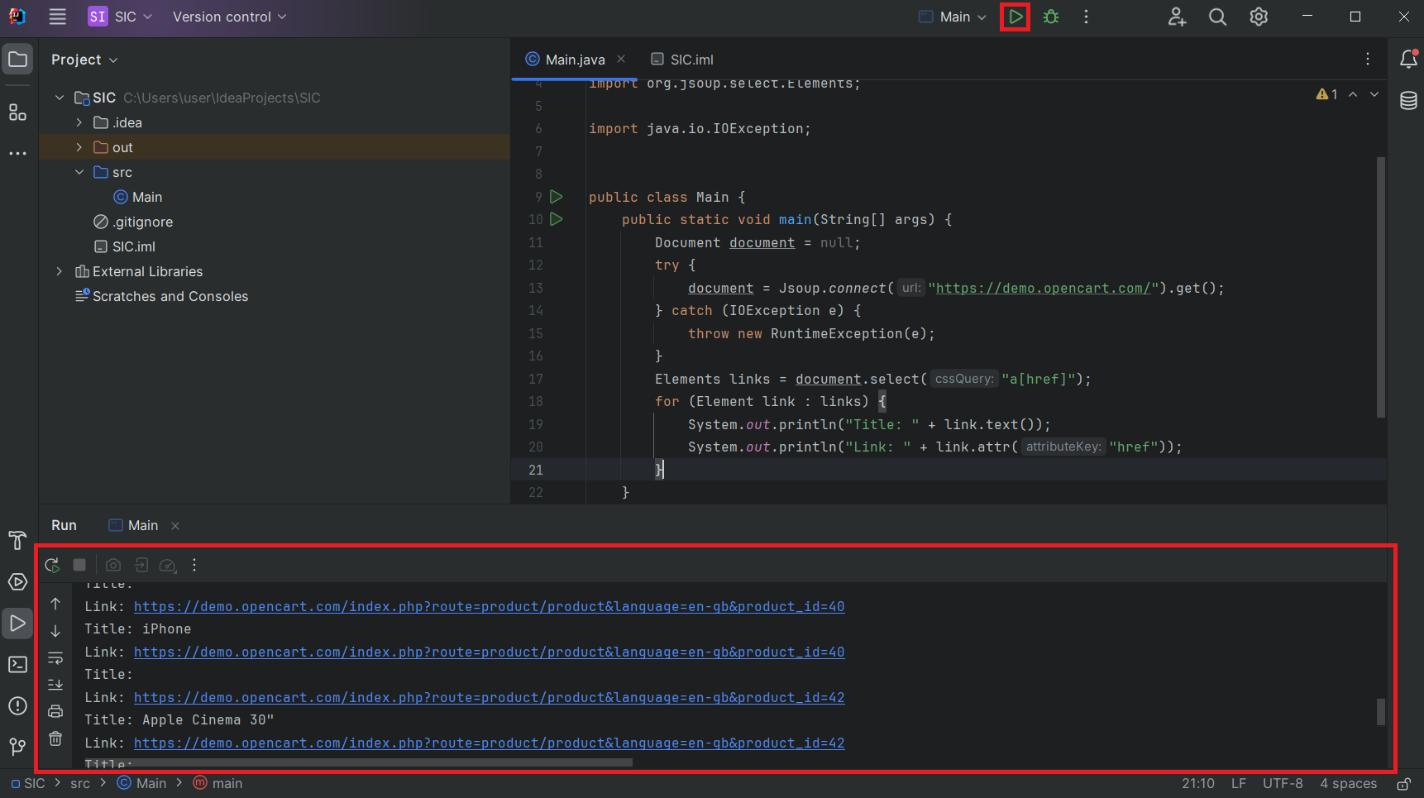
Obwohl die Anzeige von Daten auf dem Bildschirm während der Entwicklung und beim Testen eine praktische Option ist, ist sie für die Datenspeicherung nicht sehr praktisch. Betrachten wir daher Möglichkeiten zum Speichern von Daten in CSV und JSON.
Als CSV exportieren
Um CSV zu verwenden, sollten Sie die opencsv-Bibliothek herunterladen und in Ihr Projekt importieren. Sie können dies auf die gleiche Weise tun, wie Sie Jsoup zuvor importiert haben. In Ihren Code müssen Sie das folgende Modul importieren:
import com.opencsv.CSVWriter;Außerdem müssen wir für die Arbeit mit Listen eine Bibliothek verwenden, um Informationen über alle Elemente auf der Seite zu speichern:
import java.util.ArrayList;
import java.util.List;Als nächstes fügen wir in der Hauptfunktion eine Variable hinzu, um das Array von Elementen zu speichern. Um die Spaltenüberschriften in einer Datei zu definieren, geben Sie zuerst die Namen ein:
List<String()> dataList = new ArrayList<>();
dataList.add(new String(){"Title", "Link"});In der for-Schleife fügen wir Code hinzu, um die Elemente in der Variablen zu speichern, anstatt sie auf dem Bildschirm auszugeben:
for (Element link : links) {
String title = link.text();
String linkUrl = link.attr("href");
dataList.add(new String(){title, linkUrl});
}Speichern Sie die gesammelten Daten in einer CSV-Datei:
try (CSVWriter writer = new CSVWriter(new FileWriter("data.csv"))) {
writer.writeAll(dataList);
} catch (IOException e) {
e.printStackTrace();
}Beim Ausführen des resultierenden Projekts wird eine data.csv-Datei im Projektordner mit den restlichen Projektdateien generiert:
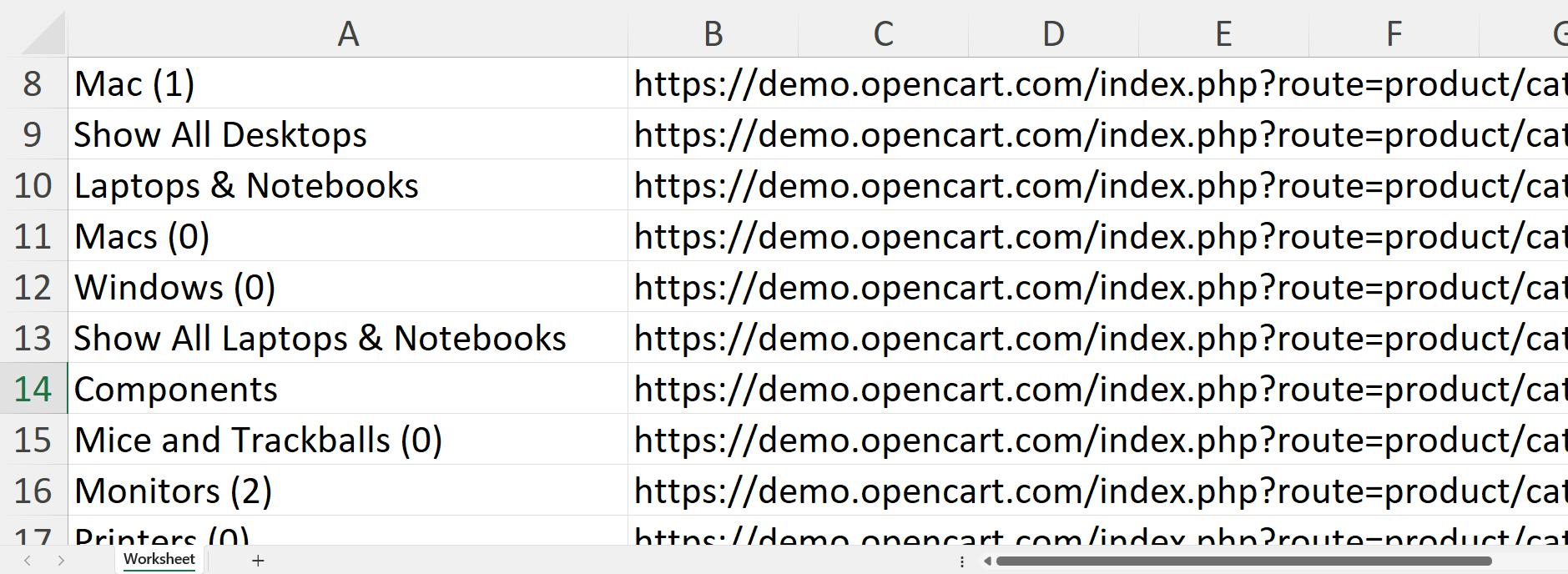
Sie können jetzt Daten in einer Datei schnell verarbeiten. Allerdings ist CSV kein gutes Format für die Datenübertragung. JSON ist ein besseres Format, also schauen wir uns eine andere Exportoption an.
Export nach JSON
Um mit JSON arbeiten zu können, benötigen Sie die GSON-Bibliothek. Importieren Sie das erforderliche Modul in das Projekt:
import com.google.gson.Gson;Als Datenquelle verwenden wir die Liste, die wir im Beispiel zum Speichern von CSV-Dateien erstellt haben. Zuerst müssen wir ein neues GSON-Objekt erstellen und die Daten aus der Liste in einen JSON-String konvertieren:
Gson gson = new Gson();
String json = gson.toJson(dataList);Anschließend speichern Sie die Daten im JSON-Format:
try (FileWriter writer = new FileWriter("data.json")) {
writer.write(json);
} catch (IOException e) {
e.printStackTrace();
}Sie können die erhaltenen Daten nutzen, um sie in andere Programme zu exportieren oder an andere weiterzuleiten.
Fortgeschrittene Themen im Java Web Scraping
Das von uns betrachtete Beispiel ist recht einfach und verwendet nur relativ einfache Funktionen, die auch Anfänger nutzen können. Die Programmiersprache Java ermöglicht jedoch noch viel mehr. Beispielsweise können Sie die erlernten Fähigkeiten nutzen, um einen vollwertigen Crawler zu schreiben, der Sitemaps erstellt und alle Seiten crawlt.
Angenommen, Sie möchten fortgeschrittenere Techniken erlernen. In diesem Fall verraten wir Ihnen, welche am nützlichsten sind: die Verwendung von Parallelität und Parallelität zur Verbesserung der Leistung und die Verwendung von Headless-Browsern zur Simulation des Benutzerverhaltens, um Elemente auf der Seite zu steuern und Blockierungen zu vermeiden.
Web-Crawling-Strategien
In früheren Artikeln haben wir den Unterschied zwischen Web-Crawling und Web-Scraping besprochen. Wir haben auch behandelt, wie man einen Webcrawler in Python erstellt. In diesem Artikel erstellen wir mithilfe der von Ihnen erlernten Fähigkeiten und Kenntnisse den genauen Webcrawler in Java. Zuerst müssen wir die notwendigen Module und Java-Web-Scraping-Bibliotheken importieren.
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
import java.util.HashSet;
import java.util.LinkedList;
import java.util.Queue;
import java.util.Set;Als Nächstes erstellen wir eine Basisklasse und -funktion und geben die anfängliche URL an, von der aus wir mit dem Crawlen der Website beginnen.
public class WebCrawler {
public static void main(String() args) {
String startUrl = "https://demo.opencart.com/";
//Here will be code
}
}Anschließend definieren wir Variablen, um besuchte URLs zu verfolgen, neue URLs zu einer Warteschlange hinzuzufügen und die eindeutigen Adressen besuchter Seiten zu speichern.
Set<String> visitedUrls = new HashSet<>();
Queue<String> queue = new LinkedList<>();
queue.add(startUrl);
Set<String> allVisitedPages = new HashSet<>();Danach erstellen wir eine Schleife, um die Adresswarteschlange zu durchlaufen.
while (!queue.isEmpty()) {
//Here will be code
}Wenn wir eine Seite besuchen, entfernen wir sie aus der Warteschlange.
String currentUrl = queue.poll();Wenn die URL bereits besucht wurde, überspringen wir sie.
if (visitedUrls.contains(currentUrl)) {
continue;
}Wir werden die Anfrage und die Datenerfassung in einen Try/Catch-Block stellen.
try {
Document document = Jsoup.connect(currentUrl).get();
//Here will be code
} catch (IOException e) {
visitedUrls.add(currentUrl);
System.err.println("Error fetching URL: " + currentUrl);
e.printStackTrace();
}Wir fügen die aktuelle Seite zur Liste der besuchten Seiten hinzu, suchen alle Links auf der Seite und fügen die eindeutigen Links zur Warteschlange für spätere Besuche hinzu.
allVisitedPages.add(currentUrl);
Elements links = document.select("a(href)");
for (Element link : links) {
String linkText = link.text();
String linkUrl = link.absUrl("href");
if (!visitedUrls.contains(linkUrl)) {
queue.add(linkUrl);
}
}
visitedUrls.add(currentUrl);Zum Schluss drucken wir die Liste aller besuchten Seiten aus.
System.out.println("\nAll Visited Pages:");
for (String page : allVisitedPages) {
System.out.println(page);
}Mit diesem Crawler können die meisten Aufgaben gelöst werden, und Sie können ihn bei Bedarf problemlos um die erforderliche Funktionalität erweitern.
Parallelität und Parallelität
Parallelität und Parallelität sind Konzepte, die sich auf die Ausführung mehrerer Aufgaben oder Prozesse in einer Computerumgebung beziehen. Obwohl diese Konzepte oft synonym verwendet werden, beschreiben sie unterschiedliche Aspekte des Multitasking.
Parallelität beschreibt die Fähigkeit, mehrere Aufgaben gleichzeitig auszuführen. Da die Aufgaben jedoch nicht gleichzeitig ausgeführt werden müssen, kann dies durch einen schnellen Wechsel zwischen den Aufgaben erreicht werden.
Parallelität hingegen impliziert die physische Ausführung mehrerer Aufgaben gleichzeitig. Jede Aufgabe wird in kleinere Teilaufgaben zerlegt und gleichzeitig ausgeführt. Dies wird typischerweise durch die Verteilung von Daten auf mehrere Prozessoren oder Kerne implementiert.
Um Parallelität zu nutzen, müssen Sie solche Aufgaben in separaten Thread-Klassen definieren, zum Beispiel:
public class MyThread extends Thread {
public void run() {
// Do something
}
}Danach können Sie die angegebenen Threads in der Hauptfunktion aufrufen:
MyThread thread1 = new MyThread();
MyThread thread2 = new MyThread();
thread1.start();
thread2.start();Um die Prinzipien der Parallelität nutzen zu können, benötigen Sie das Fork/Join Framework, um separate Objekte für die parallele Ausführung von Aufgaben zu erstellen:
ForkJoinPool forkJoinPool = new ForkJoinPool();
ForkJoinTask<Integer> task = new MyForkJoinTask();
forkJoinPool.submit(task);Das Erlernen dieser Ansätze wird die Leistung Ihres Java Web Scrapers verbessern und die Datenverarbeitungsgeschwindigkeit erhöhen.
Headless-Browser in Java
Headless-Browser sind für das Scraping von Websites mit komplexerer Sicherheit oder die bestimmte Aktionen erfordern, um Daten zu erhalten, unerlässlich. Wenn Sie sich beispielsweise anmelden müssen, bevor Sie Daten extrahieren können, oder wenn die Daten auf der Website mithilfe von JavaScript geladen werden. Darüber hinaus kann die Verwendung von Headless-Browsern dazu beitragen, das Risiko einer Blockierung zu verringern, indem beispielsweise das Verhalten eines echten Benutzers simuliert wird.
HtmlUnit
Wie bereits erwähnt, ist HtmlUnit eine Headless-Webbrowser-Bibliothek, die eine breite Palette an Funktionen für Web Scraping bietet. Um es zu verwenden, müssen Sie die JAR-Datei der Bibliothek herunterladen und die erforderlichen Module in Ihr Projekt importieren.
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import com.gargoylesoftware.htmlunit.html.HtmlAnchor;Sobald Sie die Bibliothek importiert haben, können Sie eine Klasse und Funktion erstellen, um Ihre Scraping-Aufgaben zu erledigen.
public class HtmlUnitHeadlessExample {
public static void main(String() args) {
// Here will be code
}
}Um eine Webseite in einem Headless-Browser zu öffnen, müssen Sie eine neue Instanz der WebDriver-Klasse erstellen und zusätzliche Einstellungen konfigurieren, wie z. B. den Betriebsmodus und Anzeigeparameter.
WebClient webClient = new WebClient(BrowserVersion.CHROME);
webClient.getOptions().setCssEnabled(false); Sobald Sie die Webseite geöffnet haben, können Sie das WebDriver-Objekt verwenden, um mit der Seite zu interagieren, z. B. auf Links zu klicken, Formulare auszufüllen und den HTML-Code zu analysieren.
try {
HtmlPage page = webClient.getPage("https://demo.opencart.com/");
java.util.List<HtmlAnchor> anchors = page.getByXPath("//a");
for (HtmlAnchor anchor : anchors) {
System.out.println("Title: " + anchor.asText());
System.out.println("Link: " + anchor.getHrefAttribute());
}
} catch (Exception e) {
e.printStackTrace();
}Wenn Sie mit dem Scrapen der Seite fertig sind, sollten Sie das WebDriver-Objekt schließen, um Ressourcen freizugeben.
finally {
webClient.close();
}Die Verwendung eines Headless-Browsers ist eine gute Option zum Scrapen von Webseiten, die keine grafische Benutzeroberfläche erfordern. Er kann schneller und effizienter als ein herkömmlicher Webbrowser sein und es kann auch einfacher sein, Aufgaben zu automatisieren.
Selenium WebDriver
Selenium ist ein plattformübergreifendes Framework, das die meisten Programmiersprachen, einschließlich Java, unterstützt. Wir haben die Verwendung und Einrichtung in Python bereits behandelt, schauen wir uns also an, wie man es in Java verwendet.
Um Selenium verwenden zu können, benötigen Sie zwei Dinge:
- Die Selenium-Bibliothek. Importieren Sie es wie jede andere Bibliothek in Ihr Projekt.
- Ein WebDriver. Es muss die gleiche Version wie Ihr installierter Browser sein. Sie können den erforderlichen WebDriver von den offiziellen Websites von Chrome, Firefox und Edge herunterladen.
Sie sollten die notwendigen Module in Ihr Projekt importieren, um Selenium mit Java zu verwenden.
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;Als nächstes erstellen Sie eine Hauptklasse und eine Funktion. Geben Sie dann den Pfad zur WebDriver-Datei an und legen Sie die gewünschten Einstellungen und Parameter fest.
public class SeleniumExample {
public static void main(String() args) {
System.setProperty("webdriver.chrome.driver", "path/chromedriver");
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless");
WebDriver driver = new ChromeDriver(options);
// Extract data
}
}Vergessen Sie nicht, die WebDriver-Instanz zu schließen, wenn Sie fertig sind.
driver.quit();Selenium ist eine überzeugende Bibliothek sowohl für Scraping- als auch für Automatisierungsaufgaben. Es unterstützt verschiedene Funktionen zum Suchen und Interagieren mit Elementen und ist damit ein vielseitiges Werkzeug für viele Anwendungen.
Herausforderungen beim Web Scraping mit Java
Web Scraping ist eine der häufigsten Aufgaben zur automatischen Datenerfassung. Allerdings ist der Prozess auch mit einigen Herausforderungen verbunden. Die Herausforderungen beim Web Scraping in Java lassen sich in zwei Arten einteilen:
- Herausforderungen im Zusammenhang mit der Umgehung des Website-Schutzes. Hierbei handelt es sich um allgemeine Web-Scraping-Herausforderungen, die nicht spezifisch für Java sind. Um sie zu bewältigen, können Sie die folgenden Methoden verwenden: Proxys, Headless-Browser oder vorgefertigte Web-Scraping-APIs, die diese Herausforderungen für Sie erledigen.
- Herausforderungen im Zusammenhang mit Java. Zu diesen Herausforderungen gehören die Mängel der Sprache selbst, die wir zu Beginn des Artikels besprochen haben. Dazu gehören die Schwierigkeit, Java zu erlernen, und die Schwere der daraus resultierenden Web-Scraping-Programme. Wie bereits erwähnt, ist Java keine gute Wahl für kleine Projekte, kann aber eine gute Option für große oder skalierbare Web-Scraper sein.
Bevor Sie einen Web Scraper in Java erstellen, müssen Sie daher sicherstellen, dass es sich um die beste Lösung für Ihr Projekt handelt und Sie alle damit verbundenen Herausforderungen meistern können. Wenn Sie die Aufgabe vereinfachen und die Leistung Ihres Programms beschleunigen möchten, sollten Sie die Verwendung einer vorgefertigten Web-Scraping-API in Betracht ziehen, die die Datenerfassung für Sie übernimmt.
Fazit und weitere Erkundung
In diesem umfassenden Leitfaden haben wir alle Fragen beantwortet, die wir zu Beginn des Artikels gestellt haben. Wir haben auch gezeigt, wie man Java-Komponenten installiert und einen Scraper und Crawler erstellt. Darüber hinaus zeigten wir, wie man die benötigten Daten abruft und in einem geeigneten Format speichert.
Wir hoffen, dass dieses Java-Web-Scraping-Tutorial sowohl für Anfänger als auch für erfahrene Java-Programmierer nützlich ist. Auch erfahrene Programmierer finden im Abschnitt über fortgeschrittene Techniken möglicherweise etwas Interessantes.
Mit den Fähigkeiten, die Sie in diesem Artikel gelernt haben, können Sie ganz einfach einen Scraper erstellen, um automatisch Daten von einer Website zu sammeln, sie zu optimieren und sogar das Verhalten echter Benutzer mit einem Headless-Browser zu simulieren.
