
Selenium ist eine beliebte Open-Source-Bibliothek zur Automatisierung von Webbrowsern, Tests und Scraping. Es ist in den meisten gängigen Programmiersprachen verfügbar, einschließlich Python. Aufgrund seiner Benutzerfreundlichkeit und aktiven Community ist Selenium die erste Wahl für Web-Automatisierungsaufgaben.
In diesem Artikel tauchen wir in die Welt der Verwendung von Proxys mit Selenium ein, um die Sicherheit und Effizienz Ihrer Web-Scraping-Bemühungen zu verbessern. Wir werden Themen von den Grundlagen der Proxy-Nutzung mit Selenium bis hin zu fortgeschrittenen Themen behandeln.
Warum Proxys mit Selen verwenden?
Ein Proxyserver fungiert als Vermittler zwischen Ihnen und den Internetressourcen, auf die Sie zugreifen. Wenn Sie eine Website anfordern, sendet Ihr Computer die Anfrage an den Proxyserver und nicht direkt an die Website. Der Proxyserver leitet die Anfrage dann an die Website weiter und empfängt die Antwort. Schließlich sendet der Proxyserver die Antwort zurück an Ihren Computer.
Es gibt viele verschiedene Arten von Proxyservern, jeder mit seinen Vor- und Nachteilen. Einige Proxyserver dienen der Verbesserung der Sicherheit, während andere die Anonymität verbessern sollen. Einige Proxyserver sind auch darauf ausgelegt, Inhalte zwischenzuspeichern, was die Leistung verbessern kann. Da wir die verschiedenen Arten von Proxys jedoch bereits ausführlich besprochen haben, gehen wir hier nicht näher darauf ein.
Es gibt mehrere entscheidende Gründe, warum die Verwendung von Proxys für Web Scraping unerlässlich ist:
- Verhindern Sie IP-Adressblöcke und CAPTCHAs.
- Umgehen Sie geografische Beschränkungen und lokalisieren Sie Anfragen.
- Verbergen Sie Ihre echte IP-Adresse und erhöhen Sie die Anonymität.
Lassen Sie uns jeden dieser Punkte genauer untersuchen.
Verhindern von IP-Verboten und Captchas
Beim Scraping ist der Einsatz von Proxys vor allem wichtig, um IP-Adresssperren und CAPTCHA-Unterbrechungen zu umgehen. Wie bereits erwähnt, fungiert ein Proxyserver als Vermittler zwischen Ihnen und der Zielwebsite. Wenn Ihre IP-Adresse blockiert wird, gilt die Zugriffsbeschränkung auf diese Weise für den Proxyserver und nicht für Ihre tatsächliche IP. Um das Scraping fortzusetzen, können Sie einfach zu einem anderen Proxy wechseln.
Noch einfacher ist der Umgang mit CAPTCHAs. Anstatt CAPTCHAs während des Scrapings zu lösen, können Sie versuchen, sie ganz zu vermeiden, indem Sie einfach die Proxys ändern, wenn sie erscheinen. Es ist jedoch wichtig zu beachten, dass diese Methode nur dann funktioniert, wenn Sie hochwertige Proxys verwenden, vorzugsweise solche für Privathaushalte.
Umgehung von geografischen Beschränkungen
Mithilfe von Proxys können Sie geografische Beschränkungen umgehen und auf Inhalte zugreifen, die je nach Standort möglicherweise blockiert oder eingeschränkt sind. Indem Sie Ihren Datenverkehr über einen Proxyserver in einer anderen Region oder einem anderen Land leiten, können Sie den Eindruck erwecken, als würden Sie von diesem Standort aus eine Verbindung zum Internet herstellen, und so geografische Sperren umgehen.
Verbesserung der Anonymität und Sicherheit
Ein weiterer Grund für die Verwendung von Proxys besteht darin, die Sicherheit und Anonymität beim Scraping zu erhöhen. Beachten Sie jedoch, dass nicht alle Proxys Ihre Sicherheit verbessern können. Beispielsweise richten kostenlose Proxys in diesem Fall typischerweise mehr Schaden als Nutzen an. Sie sind oft ungeschützt, instabil, haben niedrige Datenübertragungsgeschwindigkeiten und überwachen möglicherweise sogar Ihren Datenverkehr und verkaufen ihn an Dritte.
Andererseits können hochwertige Proxys Ihre Online-Präsenz anonym und sicher machen. Einige Proxyserver bieten eine Verschlüsselung, die Ihre Daten in ein unlesbares Format verschlüsselt und sie so vor dem Abfangen durch Dritte schützt. Dies ist besonders wichtig, wenn Sie öffentliche WLAN-Netzwerke nutzen, wo Ihre Daten möglicherweise gefährdet sind.
Voraussetzungen
Bevor wir zu Beispielen für die Verwendung von Proxys mit Selenium übergehen, müssen wir sicherstellen, dass alle erforderlichen Komponenten auf Ihrem Computer installiert sind. Für diesen Artikel benötigen Sie Python 3, ein vollständiges Installations-Tutorial finden Sie unter Python-Scraping-Grundlagen. Wenn Sie außerdem daran interessiert sind, Proxys mit der Requests-Bibliothek zu verwenden, können Sie sehen, wie Sie Proxys in Python-Anfragen verwenden.
Um Selenium zu installieren, können Sie den Paketmanager verwenden und den folgenden Befehl im Terminal ausführen:
pip install seleniumSie benötigen dann einen Chromedriver oder einen anderen Webtreiber der gleichen Version wie der auf Ihrem Computer installierte Browser. Im Artikel zum Selenium-Scraping finden Sie eine ausführliche Anleitung und alle notwendigen Links zu Web-Treibern für verschiedene Browser.
Einrichten eines Proxys in Selenium
Lassen Sie uns die verschiedenen Möglichkeiten zur Verwendung von Proxys mit Selenium sowie die Unterschiede bei der Verwendung basierend auf der Art der ausgewählten Proxys untersuchen. Es gibt zwei Hauptansätze zum Verbinden von Proxys in Selenium:
- Nutzen Sie die integrierten Funktionen von Selenium und fügen Sie Proxys mithilfe von Optionen hinzu.
- Einsatz von Bibliotheken von Drittanbietern für die Proxy-Verwaltung, wie z. B. Selenium Wire.
In diesem Artikel werden wir uns mit beiden Methoden befassen, aber die Wahl hängt letztendlich von Ihren Kenntnissen und Projektanforderungen ab.
Integrierte Selenium-Proxy-Konfiguration
Lassen Sie uns zunächst untersuchen, wie Sie die integrierte Funktionalität von Selenium nutzen können, um eine Proxy-Verbindung herzustellen. Zuerst importieren wir die notwendigen Bibliotheken:
from selenium import webdriver
from selenium.webdriver.chrome.options import OptionsAls Nächstes erstellen wir eine Variable zum Speichern der Proxy-Daten:
proxy_server = "proxy_address:port"Erstellen wir ein Optionsobjekt und füllen es mit Proxy-Informationen:
options = webdriver.ChromeOptions()
options.add_argument('--proxy-server=%s' % proxy_server)Erstellen Sie als Nächstes eine Instanz des Webtreibers mit den angegebenen Optionen:
driver = webdriver.Chrome(options=options)Der weitere Prozess für die Arbeit mit einem Web-Treiber bleibt derselbe, wie in unserem Artikel über Selenium-Scraping beschrieben.
Nutzung von Bibliotheken Dritter
Für eine erweiterte Proxy-Verwaltung, einschließlich des Abfangens und Änderns von Netzwerkanforderungen, können Sie Bibliotheken von Drittanbietern wie Selenium Wire verwenden. Um es nutzen zu können, müssen Sie ein zusätzliches Modul installieren:
Pip Selendraht installieren
Um dieses Paket verwenden zu können, müssen Python 3.7 oder höher und Selenium 4.0.0 oder höher auf Ihrem Computer installiert sein. Wir werden den Import des Webtreibers ersetzen und den Rest des Skripts unverändert lassen:
from seleniumwire import webdriver
proxy_server = "proxy_address:port"
driver = webdriver.Chrome()Geben Sie den Proxy an:
driver.scopes = ((webdriver.request.Proxy(), 'http://' + proxy_server))Sobald dies erledigt ist, sind Seitennavigation und Datenverarbeitung möglich.
Konfigurieren von HTTP-, HTTPS- und SOCKS5-Proxys
Mit der Proxy-Konfiguration in Selenium WebDriver können Sie Ihren Webverkehr mithilfe verschiedener Protokolle über einen Proxyserver leiten. In diesem Abschnitt wird nicht auf die Details dieser Protokolle eingegangen, sondern der Schwerpunkt liegt auf der Verwendung von Proxys unabhängig vom Protokoll.
HTTP- und HTTPS-Proxys sind im Wesentlichen gleich, mit der Ausnahme, dass HTTPS-Proxys sicher sind, HTTP-Proxys hingegen nicht. Sie werden auch auf ganz ähnliche Weise verwendet:
proxy_server = "116.203.28.43:80"
options = webdriver.ChromeOptions()
options.add_argument('--proxy-server=http://%s' % proxy_server)
options.add_argument('--proxy-server=https://%s' % proxy_server)Im Gegensatz zu HTTP- und HTTPS-Proxys können SOCKS- und SOCKS5-Proxys UDP-Anfragen verarbeiten, was sie vielseitiger macht. Geben Sie zur Verwendung den Proxy-Typ an, wenn Sie die Optionen konfigurieren:
options.add_argument('--proxy-server=socks5://%s' % socks5_proxy)Wie Sie sehen, unterstützt Selenium alle Arten von Proxys und ihr Import erfolgt auf die gleiche Weise. Der einzige Unterschied besteht darin, dass Sie beim Import die Art der Proxys angeben müssen, die Sie verwenden.
Verwendung von Selenium mit einem Proxy
Sehen wir uns Beispiele für die Verwendung von Proxys mit und ohne Authentifizierung an. Um das Beispiel anschaulicher zu machen, stellen wir Anfragen an die httpbin-Website, die eine JSON-Antwort mit unserer aktuellen IP-Adresse zurückgeben sollte. Dies wird uns helfen, die Funktionalität des Proxys zu überprüfen und die Beispiele klarer zu machen.
Nicht authentifizierte Proxys
Kostenlose Proxys sind solche, für deren Zugriff kein Benutzername und kein Passwort erforderlich sind. Dies ist die Art von Proxys, die in den vorherigen Beispielen verwendet wurde. Obwohl sie praktisch sind, sind sie oft unzuverlässig und können leicht blockiert werden.
Ändern wir eines der zuvor besprochenen Skripte, um auf die Website httpbin zuzugreifen. Hier wird gezeigt, wie Sie einen kostenlosen Proxy verwenden, um eine Anfrage zu stellen:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
proxy_server = "116.203.28.43:80"
options = webdriver.ChromeOptions()
options.add_argument('--proxy-server=http://%s' % proxy_server)
driver = webdriver.Chrome(options=options)
driver.get('https://httpbin.org/ip')Als nächstes rufen wir den gesamten Webseiteninhalt ab und zeigen ihn auf dem Bildschirm an:
page_source = driver.page_source
print("Page title:", page_source)Stellen Sie sicher, dass der Webtreiber am Ende des Skripts ordnungsgemäß geschlossen ist:
driver.quit()Beim Ausführen des Skripts öffnet sich ein vom Webtreiber gesteuertes Browserfenster und das Ergebnis wird in der Befehlszeile oder im Terminal angezeigt:
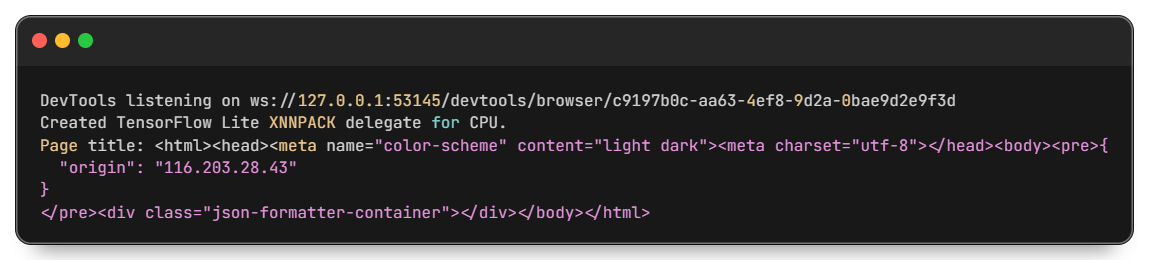
Um dieses Skript zu testen, können Sie unsere Liste kostenloser und aktueller Proxys nutzen.
Authentifizierte Proxys
Die Proxy-Authentifizierung in Selenium umfasst die Bereitstellung von Anmeldeinformationen (Benutzername und Passwort) für den Zugriff auf den Proxy, bevor dieser zum Weiterleiten des Webdatenverkehrs verwendet werden kann. Diese werden normalerweise in einem URL-Format wie dem folgenden angegeben:
http://username:password@proxy_address:portAnstelle von HTTP können Sie einen anderen Protokolltyp angeben, beispielsweise HTTPS oder SOCKS5. Nehmen wir das vorherige Beispiel und verwenden einen authentifizierten Proxy:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
proxy_server = "hasdata:^G*(email protected):3132"
options = webdriver.ChromeOptions()
options.add_argument('--proxy-server=https://%s' % proxy_server)
driver = webdriver.Chrome(options=options)
driver.get('https://httpbin.org/ip')
page_source = driver.page_source
print("Page title:", page_source)
driver.quit()Als Ergebnis erhalten wir:
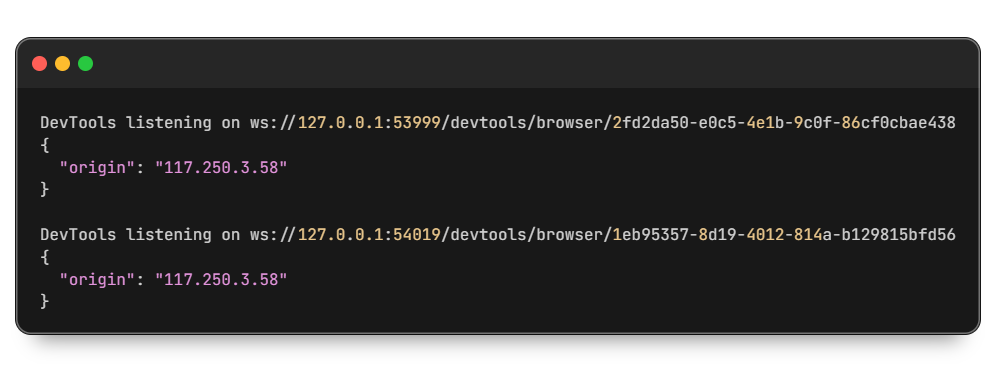
Die Verwendung eines authentifizierten Proxys ist wesentlich sicherer, da ein unbefugter Zugriff Dritter ausgeschlossen ist. Diese verbesserte Sicherheit ergibt sich aus der Implementierung eines Authentifizierungsmechanismus, der die Anmeldeinformationen des Benutzers überprüft, bevor er Zugriff auf den Proxyserver gewährt.
Fortgeschrittene Themen
Lassen Sie uns zusätzlich zu den grundlegenden Beispielen für die Arbeit mit Proxys fortgeschrittene Themen untersuchen, die möglicherweise zusätzliche Fähigkeiten und Kenntnisse erfordern, aber die Fähigkeiten Ihres Skripts bei der Verwendung von Proxys in Selenium erheblich verbessern können.
Debuggen
Das Debuggen ist ein wesentlicher Bestandteil der Skriptentwicklung, da es dabei hilft, Fehler zu identifizieren und zu beheben sowie das Verhalten des Skripts in verschiedenen Szenarien zu analysieren. Um beispielsweise zu verhindern, dass das Skript während der Ausführung anhält, wenn Fehler auftreten (nicht funktionierende Proxys, Zeitüberschreitung oder aus einem anderen Grund), können Sie den Block try..exclusive verwenden:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
proxy_server = "193.242.145.106:3132"
options = webdriver.ChromeOptions()
options.add_argument('--proxy-server=http://%s' % proxy_server)
try:
driver = webdriver.Chrome()
driver.get('https://httpbin.org/ip')
ip_json = driver.find_element(By.TAG_NAME, 'pre').text
print(ip_json)
except Exception as e:
print(e)
finally:
driver.quit()Der bereitgestellte Code erfasst alle aufgetretenen Fehler und zeigt sie an. Sie können die Fehlerbehandlung jedoch an Ihre Bedürfnisse anpassen. Sie können beispielsweise Fehler filtern, um nur Netzwerkfehler oder bestimmte Fehlercodes anzuzeigen. Darüber hinaus können Sie die Ausgabe so anpassen, dass nur der Fehlercode oder andere relevante Informationen angezeigt werden.
Der finally Block stellt sicher, dass der Browser unabhängig von Fehlern oder Ausnahmen geschlossen wird. Darüber hinaus werden durch das Extrahieren nur des Textinhalts aus der Seite unnötige Informationen eliminiert und der Prozess optimiert.
Durch die Integration der Protokollierung in das Skript werden die Fehlerverfolgung und das Debugging weiter verbessert. Nutzen Sie eine Protokollierungsbibliothek, um Fehler, deren Beschreibungen und relevante Zeitstempel aufzuzeichnen. Dieses strukturierte Protokoll kann analysiert werden, um Muster, wiederkehrende Probleme und Verbesserungsbereiche zu identifizieren:
import logging
logging.basicConfig(level=logging.DEBUG)Durch die Implementierung dieser Verbesserungen können Sie robuste Selenium-Skripte erstellen, die Fehler effektiv behandeln, wertvolle Erkenntnisse liefern und den Debugging-Prozess optimieren.
Proxy-Rotation
Bei der Proxy-Rotation handelt es sich um eine Technik, bei der der Proxy-Server, der für Anfragen verwendet wird, regelmäßig gewechselt wird. Dies kann nützlich sein, um Website-Blockierungen zu umgehen, die Zuverlässigkeit von Anfragen zu erhöhen und Ihre Anonymität zu schützen. Sie können entweder rotierende Proxys erwerben oder ein Proxy-Rotationssystem aus einem IP-Pool implementieren.
Mit der Proxy-Rotation verfügen Sie über einen Pool verfügbarer Proxys, die Sie bei jeder Anfrage durchlaufen. Dadurch wird die Anzahl der Anfragen reduziert, die von derselben IP-Adresse kommen, sodass es für die Zielwebsite so aussieht, als kämen die Anfragen von verschiedenen Geräten.
Um die Proxy-Rotation zu implementieren, können Sie verschiedene Strategien anwenden, darunter:
- Wechsel der Proxys nach jeder Anfrage. Diese Methode bietet das höchste Maß an Anonymität, eignet sich jedoch möglicherweise nicht für Anfragen mit großem Volumen.
- Proxy-Änderung nach einer bestimmten Anzahl von Anfragen. Dieser Ansatz bringt Anonymität mit Leistung in Einklang und eignet sich daher für Szenarien mit mittlerem Datenverkehr.
- Auswahl zufälliger Proxys für jede Anfrage. Diese Strategie bietet ein Gleichgewicht zwischen Anonymität und Effizienz und ist daher ideal für allgemeine Anwendungen.
Lassen Sie uns die letzte Option implementieren. Zuerst importieren wir die notwendigen Bibliotheken und Module und deklarieren außerdem eine Variable, um eine Liste von Proxys zu platzieren:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import random
proxy_servers = (
"116.203.28.43:80",
"117.250.3.58:8080",
"111.206.0.99:8181"
)Um das Beispiel anschaulicher zu machen, definieren wir eine Schleife, die fünfmal iteriert:
for i in range(5):Stellen Sie Anfragen an die httpbin-Website und wählen Sie zufällig Proxys aus einem Pool verfügbarer Proxys aus:
try:
options = Options()
options.add_argument("--proxy-server=http://{}".format(random.choice(proxy_servers)))
driver = webdriver.Chrome(options=options)
driver.get('https://httpbin.org/ip')
ip_json = driver.find_element(By.TAG_NAME, 'pre').text
print(ip_json)
except Exception as e:
print(e)
finally:
driver.quit()Führen Sie das Skript aus und erhalten Sie das Ergebnis:
Auf diese Weise wählt das Skript jedes Mal zufällig Proxys aus einer Liste aus und stellt eine Anfrage. Dieser Ansatz verbessert die Scraping-Qualität und erhöht die Zuverlässigkeit Ihrer Skripte.
Abschluss
In diesem Artikel haben wir die Grundprinzipien der Verwendung von Proxys mit Selenium untersucht, die es Ihnen ermöglichen, Ihre tatsächliche IP-Adresse zu maskieren, während Sie Daten extrahieren und Browseraktionen automatisieren. Dieser Ansatz bietet mehr Sicherheit und Anonymität im Internet und verringert das Risiko, dass Ihre echte IP-Adresse blockiert wird.
Proxys können auch bei der Umgehung von geografischen Beschränkungen, Anforderungsbeschränkungen und anderen von Websites auferlegten Beschränkungen hilfreich sein. Die Proxy-Rotation hingegen kann die Zuverlässigkeit und Anonymität Ihres Skripts verbessern und gleichzeitig eine gleichmäßige Lastverteilung auf die Proxy-Server gewährleisten. Obwohl Proxys diese Vorteile bieten, kann ihre effektive Nutzung eine Herausforderung sein, insbesondere bei der Bewältigung komplexer Scraping-Aufgaben. Für ein problemloses und zuverlässiges Scraping-Erlebnis sollten Sie die Verwendung der Web-Scraping-API von HasData in Betracht ziehen.
