
In diesem Artikel zeigen wir Ihnen, wie Sie Google Maps in fünf einfachen Schritten durchsuchen, ohne blockiert zu werden, und so von überall auf der Welt lokale Unternehmensdatenbanken erstellen.
Warum Google Maps scrapen?
Das Scraping von Google Maps ist eine hervorragende Möglichkeit für Unternehmen, Analysten und Entwickler:
- Gewinnen Sie geschäftliche Einblicke – Die Analyse von Google Maps-Daten bietet Einblicke in Unternehmen, beispielsweise deren Standorte, Kontaktinformationen, Öffnungszeiten und Kundenbewertungen. Diese Informationen können für die Marktforschung und Wettbewerbsanalyse wertvoll sein.
- Erstellen Sie einen standortbasierten Dienst – Entwickler können gekratzte Standortdaten verwenden, um standortbasierte Dienste zu erstellen, z. B. um nahegelegene Restaurants, Hotels, Buchhandlungen und andere Sehenswürdigkeiten zu finden.
- Führen Sie eine geografische Analyse durch – Forscher und Analysten können gekratzte geografische Daten verwenden, um Bevölkerungsdichte, Verkehrsfluss und Stadtentwicklung zu untersuchen.
- Bauen Sie Reise- und Tourismusdienstleistungen auf – Die gesammelten Daten können Reiseplanungsplattformen unterstützen und Benutzern Informationen über Sehenswürdigkeiten, Unterkünfte, Transportmöglichkeiten und mehr liefern.
- Bereichern Sie Datensätze – Unternehmen können ihre vorhandenen Datensätze mit standortbezogenen Informationen aktualisieren, Kundenprofile verbessern und gezielte Marketingbemühungen verbessern.
So kratzen Sie Google Maps
Um zu demonstrieren, wie man Google Maps durchsucht, schreiben wir ein Skript, das Buchhandlungen in Kalifornien findet.
Für jede Buchhandlung extrahieren wir Folgendes:
- Name
- Typ
- Beschreibung
- Adresse
- Telefonnummer
- Verfügbarkeitszeiten
- Verfügbarkeitsstatus
- Durchschnittliche Bewertung
- Gesamtbewertungen
- Lieferoptionen
- Link zu Google Maps
Außerdem exportieren wir die Daten in JSON, um die Handhabung der Daten zu vereinfachen.
Voraussetzungen
Um diesem Tutorial folgen zu können, müssen diese Tools auf Ihrem Computer installiert sein.
1. Richten Sie das Projekt ein
Erstellen wir einen Ordner, der die Codequelle unseres Google Maps Web Scrapers enthält.
mkdir google-maps-scraper
Initialisieren Sie nun ein Node.js-Projekt, indem Sie den folgenden Befehl ausführen:
cd google-maps-scraper
npm init -y
Der zweite Befehl oben erstellt eine package.json Datei im Ordner. Lassen Sie uns eine Datei index.js erstellen und darin eine einfache JavaScript-Anweisung hinzufügen.
touch index.js
echo "console.log('Hello world!');" > index.js
Führen Sie die Datei aus index.js mit der Node.js-Laufzeitumgebung.
Dieser Befehl wird gedruckt Hallo Welt! im Terminal.
2. Installieren Sie die Abhängigkeiten
Um das Web-Scraping von Google Maps durchzuführen, benötigen wir diese beiden Node.js-Pakete:
- Puppenspieler – um die Google Maps-Website zu laden, nach der Buchhandlung zu suchen, durch die Seite zu scrollen, um weitere Ergebnisse zu laden, und den HTML-Inhalt herunterzuladen.
- Cheerio – um die Informationen aus dem von Puppeteer heruntergeladenen HTML zu extrahieren
Führen Sie den folgenden Befehl aus, um diese Pakete zu installieren:
npm install puppeteer cheerio
3. Identifizieren Sie die DOM-Selektoren, auf die Sie abzielen möchten
Navigieren Sie zu https://www.google.com/maps; Geben Sie in der Texteingabe oben links „Bookshop“ ein und drücken Sie die Eingabetaste.
Nachdem wir nun das Suchergebnis sehen, untersuchen wir die Seite, um den DOM-Selektor zu identifizieren, der mit dem HTML-Tag verknüpft ist, der die Informationen umschließt, die wir extrahieren möchten.
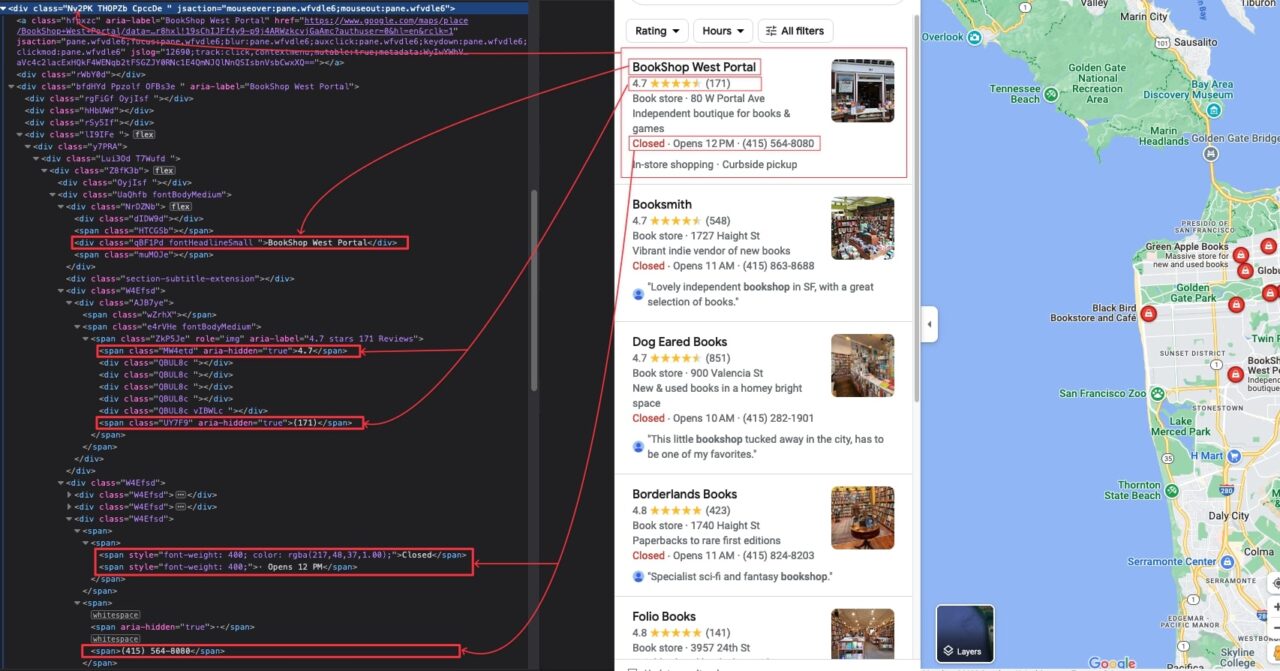
Nach genauer Prüfung sind hier alle DOM-Selektoren aufgeführt, auf die unser Skript abzielt, um die Informationen zu extrahieren:
| Information | DOM-Selektor |
| Name der Buchhandlung | .qBF1Pd |
| Typ | .W4Efsd:last-child .W4Efsd span:first-child > span |
| Beschreibung | .W4Efsd:last-child .W4Efsd span > span |
| Adresse | .W4Efsd:last-child .W4Efsd span:last-child span:last-child |
| Telefonnummer | .W4Efsd:last-child .W4Efsd span span:last-child span:last-child |
| Stundenverfügbarkeit | .W4Efsd:last-child .W4Efsd span > span > span:last-child |
| Verfügbarkeitsstatus | .W4Efsd:last-child .W4Efsd span > span > span:first-child |
| Durchschnittliche Bewertung | .MW4etd |
| Gesamtbewertungen | .UY7F9 |
| Lieferoptionen | .qty3Ue |
| Link zu Google Maps | a.hfpxzc |
Die DOM-Selektoren der Google Maps-Seite sind nicht benutzerfreundlich. Seien Sie daher beim Kopieren vorsichtig, um Probleme zu vermeiden.
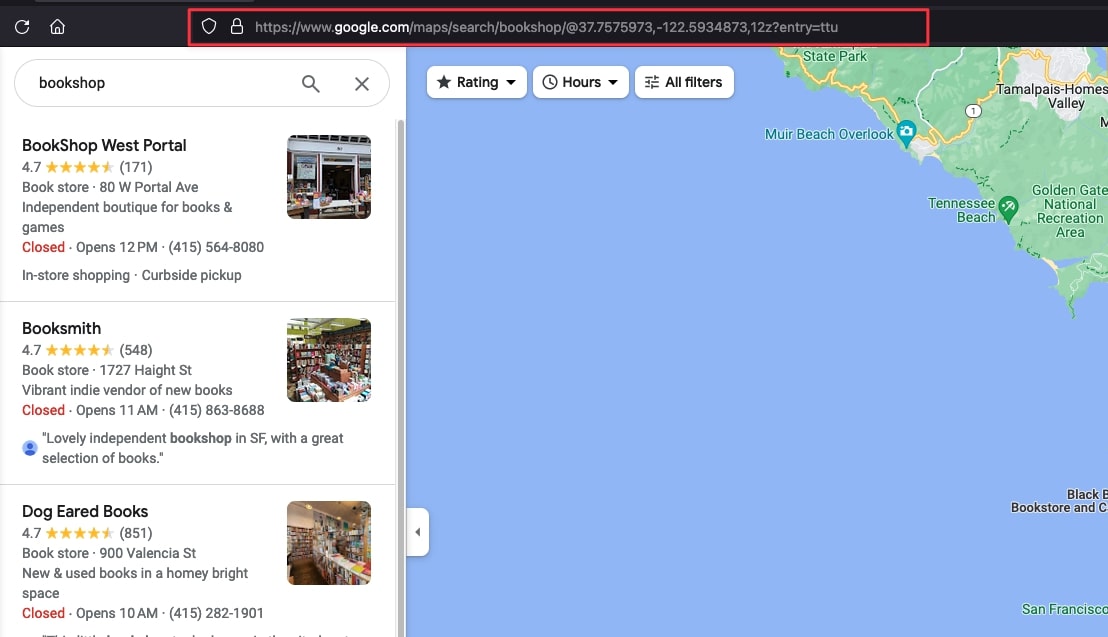
In meinem Fall lautet die URL wie folgt: https://www.google.com/maps/search/bookshop/@37.7575973,-122.5934873,12z?entry=ttu.
Aktualisieren wir den Code von index.js mit dem folgenden Code:
</p>
const puppeteer = require("puppeteer");
const waitFor = (timeInMs) => new Promise(r => setTimeout(r, timeInMs));
const main = async () => {
const browser = await puppeteer.launch({
headless: false,
args: ("--disabled-setuid-sandbox", "--no-sandbox"),
});
const page = await browser.newPage();
await page.setExtraHTTPHeaders({
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 13.5; rv:109.0) Gecko/20100101 Firefox/117.0",
});
await page.goto("https://www.google.com/maps/search/bookshop/@36.6092093,-129.3569836,6z/data=!3m1!4b1" , {
waitUntil: 'domcontentloaded',
timeout: 60000
});
const buttonConsentReject = await page.$('.VfPpkd-LgbsSe(aria-label="Reject all")');
await buttonConsentReject?.click();
await waitFor(5000);
};
void main();
<p>
Der obige Code erstellt eine Browserinstanz mit deaktiviertem Headless-Modus. Im Entwicklungsmodus ist es hilfreich, die Interaktion auf der Seite anzuzeigen und so die Feedbackschleife zu verbessern.
Wir definieren den Browser-User-Agent so, dass Google Maps uns als echten Browser behandelt, und navigieren dann zur Google-Seite.
In einigen Ländern (hauptsächlich in Europa) wird vor der Weiterleitung zur URL eine Seite angezeigt, auf der Sie um Einwilligung gebeten werden. Hier klicken wir auf die Schaltfläche „Alles ablehnen“ und warten fünf Sekunden, bis die Google Maps-Seite vollständig geladen ist.
</p>
const TOTAL_SCROLL = 10;
let scrollCounter = 0;
const scrollContainerSelector = '.m6QErb(aria-label)';
while (scrollCounter < TOTAL_SCROLL) {
await page.evaluate(`document.querySelector("${scrollContainerSelector}").scrollTo(0, document.querySelector("${scrollContainerSelector}").scrollHeight)`);
await waitFor(2000);
scrollCounter++;
}
const html = await page.content();
await browser.close();
console.log(html);
<p>
Der obige Code führt zehn Scrolls im Ergebnislistenabschnitt durch; Jeder Bildlauf wartet zwei Sekunden, bis neue Daten geladen werden. Nach den zehn Scrolls laden wir den HTML-Inhalt der Seite herunter und schließen die Browserinstanz.
Um die Anzahl der abzurufenden Suchergebnisse zu erhöhen, erhöhen Sie die Anzahl der gesamten Scrollvorgänge.
</p>
const extractPlacesInfo = (htmlContent) => {
const result = ();
const $ = cheerio.load(htmlContent);
$(".Nv2PK").each((index, el) => {
const link = $(el).find("a.hfpxzc").attr("href");
const title = $(el).find(".qBF1Pd").text();
const averageRating = $(el).find(".MW4etd").text();
const totalReview = $(el).find(".UY7F9").text();
const infoElement = $(el).find(".W4Efsd:last-child").find('.W4Efsd');
const type = $(infoElement).eq(0).find("span:first-child > span").text();
const address = $(infoElement).eq(0).find("span:last-child span:last-child").text();
let description = null;
let availability = null;
let availabilityStatus = null;
let phoneNumber = null;
if (infoElement.length === 2) {
availabilityStatus = $(infoElement).eq(1).find("span > span > span:first-child").text();
availability = $(infoElement).eq(1).find("span > span > span:last-child").text();
phoneNumber = $(infoElement).eq(1).children("span").last().find("span:last-child").text();
}
if (infoElement.length === 3) {
description = $(infoElement).eq(1).find("span > span").text();
availabilityStatus = $(infoElement).eq(2).find("span > span > span:first-child").text();
availability = $(infoElement).eq(2).find("span > span > span:last-child").text();
phoneNumber = $(infoElement).eq(2).children("span").last().find("span:last-child").text();
}
const deliveryOptions = $(el).find(".qty3Ue").text();
const latitude = link.split("!8m2!3d")(1).split("!4d")(0);
const longitude = link.split("!4d")(1).split("!16s")(0);
const placeInfo = sanitize({
address,
availability,
availabilityStatus,
averageRating,
phoneNumber,
deliveryOptions,
description,
latitude,
link,
longitude,
title,
type,
totalReview
});
result.push(placeInfo);
});
return result;
};
<p>
Die extrahierten Informationen werden an a weitergeleitet sanitize() Funktion, die wir in die Datei utils.js geschrieben haben, um die Daten zu bereinigen und zu formatieren; Durchsuchen Sie das Code-Repository, um seine Implementierung zu sehen.
Hier ist der vollständige Code des index.js Datei:
</p>
const puppeteer = require("puppeteer");
const cheerio = require("cheerio");
const { sanitize } = require("./utils");
const waitFor = (timeInMs) => new Promise(r => setTimeout(r, timeInMs));
const extractPlacesInfo = (htmlContent) => {
const result = ();
const $ = cheerio.load(htmlContent);
$(".Nv2PK").each((index, el) => {
const link = $(el).find("a.hfpxzc").attr("href");
const title = $(el).find(".qBF1Pd").text();
const averageRating = $(el).find(".MW4etd").text();
const totalReview = $(el).find(".UY7F9").text();
const infoElement = $(el).find(".W4Efsd:last-child").find('.W4Efsd');
const type = $(infoElement).eq(0).find("span:first-child > span").text();
const address = $(infoElement).eq(0).find("span:last-child span:last-child").text();
let description = null;
let availability = null;
let availabilityStatus = null;
let phoneNumber = null;
if (infoElement.length === 2) {
availabilityStatus = $(infoElement).eq(1).find("span > span > span:first-child").text();
availability = $(infoElement).eq(1).find("span > span > span:last-child").text();
phoneNumber = $(infoElement).eq(1).children("span").last().find("span:last-child").text();
}
if (infoElement.length === 3) {
description = $(infoElement).eq(1).find("span > span").text();
availabilityStatus = $(infoElement).eq(2).find("span > span > span:first-child").text();
availability = $(infoElement).eq(2).find("span > span > span:last-child").text();
phoneNumber = $(infoElement).eq(2).children("span").last().find("span:last-child").text();
}
const deliveryOptions = $(el).find(".qty3Ue").text();
const latitude = link.split("!8m2!3d")(1).split("!4d")(0);
const longitude = link.split("!4d")(1).split("!16s")(0);
const placeInfo = sanitize({
address,
availability,
availabilityStatus,
averageRating,
phoneNumber,
deliveryOptions,
description,
latitude,
link,
longitude,
title,
type,
totalReview
});
result.push(placeInfo);
});
return result;
}
const main = async () => {
const browser = await puppeteer.launch({
headless: false,
args: ("--disabled-setuid-sandbox", "--no-sandbox"),
});
const page = await browser.newPage();
await page.setExtraHTTPHeaders({
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 13.5; rv:109.0) Gecko/20100101 Firefox/117.0",
});
await page.goto("https://www.google.com/maps/search/bookshop/@37.7575973,-122.5934873,12z?entry=ttu", {
waitUntil: 'domcontentloaded',
timeout: 60000
});
const buttonConsentReject = await page.$('.VfPpkd-LgbsSe(aria-label="Reject all")');
await buttonConsentReject?.click();
await waitFor(5000);
const TOTAL_SCROLL = 5;
let scrollCounter = 0;
const scrollContainerSelector = '.m6QErb(aria-label)';
while (scrollCounter < TOTAL_SCROLL) {
await page.evaluate(`document.querySelector("${scrollContainerSelector}").scrollTo(0, document.querySelector("${scrollContainerSelector}").scrollHeight)`);
await waitFor(2000);
scrollCounter++;
}
const html = await page.content();
await browser.close();
const result = extractPlacesInfo(html);
console.log(result);
};
void main();
<p>
Führen Sie den Code mit dem Befehl aus node index.jsund freuen Sie sich über das Ergebnis:
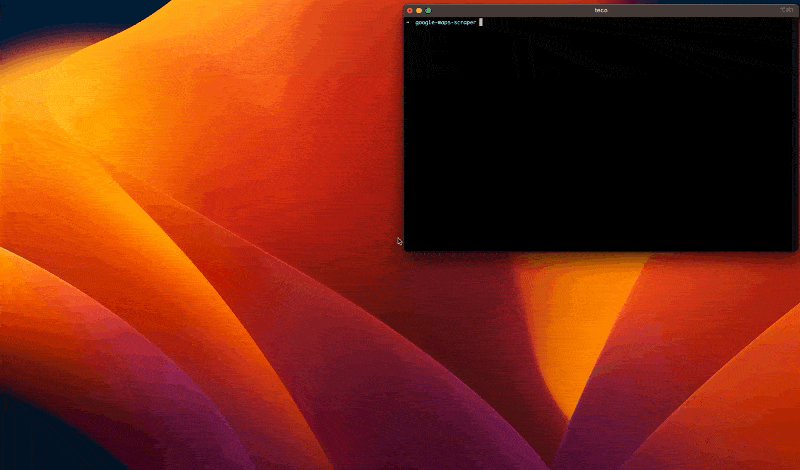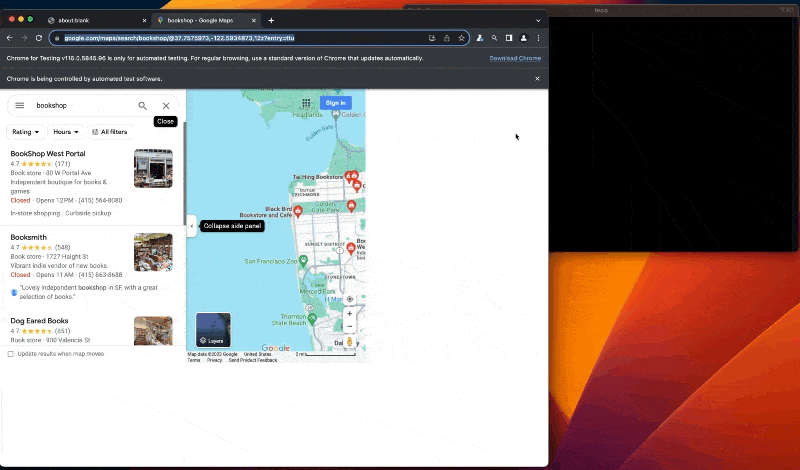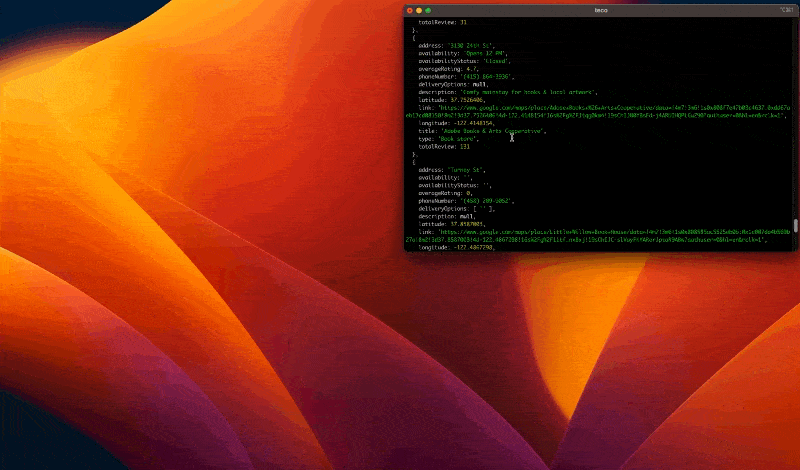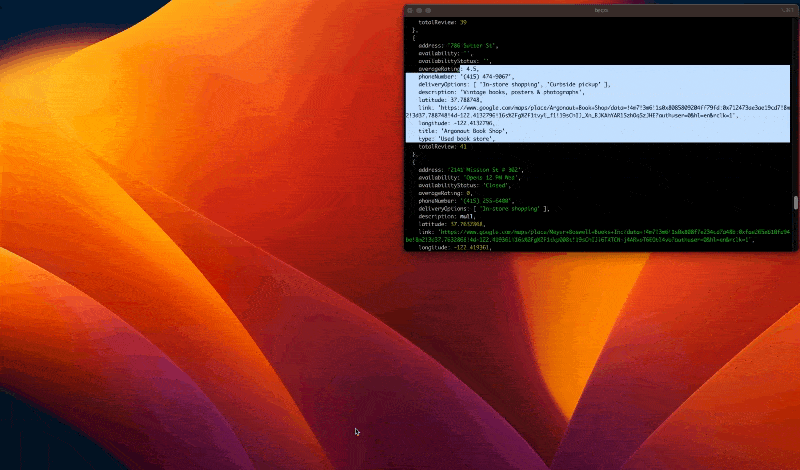
Nachdem wir nun sicher sind, dass unser Code funktioniert, können wir die Browserinstanz im Headless-Modus starten.
Skalieren Sie Ihren Google Maps Scraper
Der große Vorteil des von uns geschriebenen Scrapers besteht darin, dass er für jeden Suchbegriff funktioniert, z. B. für Museen, Kinos, Banken, Restaurants, Krankenhäuser usw. Jede Suche liefert Tausende von Ergebnissen, aus denen Sie Daten sammeln können.
Um Ihre Daten jedoch auf dem neuesten Stand zu halten, müssen Sie das Skript regelmäßig ausführen und jedes Mal Hunderte bis Tausende von Anfragen senden, was ohne die Verwendung der richtigen Tools eine Herausforderung sein kann.
So wie es aussieht, ist unser Scraper durch Anti-Scraping-Mechanismen sehr leicht zu erkennen, wodurch Ihr geistiges Eigentum Gefahr läuft, gesperrt zu werden.
Um diese Herausforderungen zu meistern, müssen Sie Zugriff auf einen Pool hochwertiger Proxys erhalten, verbrannte Proxys regelmäßig bereinigen, ein System zum Rotieren dieser Proxys erstellen, CAPTCHAs verarbeiten, geeignete Header festlegen und viele weitere Systeme aufbauen, um etwaige Hindernisse zu überwinden.
Oder Sie integrieren ScraperAPI in Ihren Scraper und lassen uns Ihre Erfolgsquote auf nahezu 100 % steigern, unabhängig von der Größe Ihres Projekts.
Mit nur einem einfachen API-Aufruf verarbeitet ScraperAPI CAPTCHAs, rotiert Ihre IPs und Header intelligent nach Bedarf, verarbeitet Wiederholungsversuche und macht Ihre Scraper widerstandsfähiger, selbst wenn sie Millionen von Anfragen senden.
