
Die meisten Unternehmen (und Menschen) sind sich heute mehr oder weniger der Auswirkungen von Daten auf ihr Geschäft bewusst.
ERP-Systeme ermöglichen es Unternehmen, ihre internen Daten zu verarbeiten und entsprechende Entscheidungen zu treffen.
Was an sich schon ausgereicht hätte, wenn die Erzeugung von Webdaten nicht in diesem Moment exponentiell angestiegen wäre. Einige Quellen schätzen, dass es täglich 328,77 Millionen Terabyte Daten sind!
Und natürlich operierte Ihr Unternehmen im luftleeren Raum.
Beim Web Scraping werden Daten aus dem Web extrahiert, um verschiedene Ereignisse zu überwachen, die sich auf Ihr Unternehmen auswirken können.
Wenn Sie ein Logistikunternehmen betreiben, kann Ihnen die Auswertung von Klimadaten dabei helfen, fundierte Entscheidungen zu treffen. Denken Sie an Informationen über bevorstehende Hurrikane und Stürme aus den Nachrichten.
Manche Unternehmen generieren den Großteil ihrer Umsätze online. Wenn Sie in dieses Segment fallen, können Sie durch das Sammeln und Überwachen von Social-Media-Daten die Kundenstimmung einschätzen.
Grepsr ist seinerseits auf die verwaltete Datenerfassung aus dem Internet spezialisiert.
Mit über einem Jahrzehnt Erfahrung auf diesem Gebiet verfügen wir über bewährtes Fachwissen, um die lästigsten Anwendungsfälle der Datenextraktion zu lösen und Unternehmen die Aufnahme großer Datenmengen in Byte-großen Teilen zu ermöglichen.
Lesen Sie hier mehr über die Datenextraktion mit PHP:
In einem unserer älteren Artikel haben wir erklärt, wie Sie Ihren eigenen Crawler erstellen und das Web mit PHP durchsuchen können.
Dieses Mal konzentrieren wir uns auf die Datenextraktion mit Python.
Python ist, ähnlich wie PHP, eine Programmiersprache, die weltweit für eine Vielzahl von Anwendungen verwendet wird.
Von einfachen Skripting-Zwecken bis hin zur Generierung komplexer Sprachmodelle für künstliche Intelligenz und maschinelles Lernen (wie ChatGPT und verschiedene andere LLMs) greifen Entwickler wegen seiner Einfachheit häufig auf Python zurück.
Seine Syntax ist leicht zu erlernen, anfängerfreundlich und eine robuste Community von Plugins und Bibliotheken hat ihm dabei geholfen, jede Aufgabe im Zusammenhang mit Computern zu meistern.
Web Scraping ist nicht anders. Wir können die Datenextraktion mit Sicherheit mit Python durchführen.
In dieser Lektion werden wir mit Python einen Crawler schreiben, der die 250 besten IMDB-Filme durchsucht und die Daten in einer CSV-Datei speichert.
Für eine effektive Navigation haben wir diesen Artikel in die folgenden Abschnitte unterteilt:
- Voraussetzungen
- Definitionen
- Aufstellen
- Den Schaber schreiben
- Letzte Worte
Voraussetzungen, um mit dem Web Scraping mit Python zu beginnen
Ähnlich wie beim PHP-Artikel benötigen wir vor dem Start bestimmte Tools und Grundkenntnisse über einige Begriffe. Anschließend richten wir ein Projektverzeichnis ein und installieren verschiedene Pakete und Bibliotheken, die in diesem Projekt von Nutzen sind.
Da Python eine „Alleskönner“-Sprache ist, ist der gesamte Funktionsumfang auf fast jeder Plattform verfügbar.
Danach werden wir jede Zeile des Python-Codes durchgehen und darüber nachdenken, was er tut und warum er das tut. Am Ende dieses Tutorials haben Sie die Grundlagen der Python-Programmierung erlernt, zumindest was das Web-Scraping betrifft. Sie generieren eine CSV-Datei, die Sie zur Datenanalyse und Datenverarbeitung verwenden können.
Grundlagen zu Python
Bibliotheken
Hierbei handelt es sich um vorgefertigte Python-Programme, die für die Ausführung einer kleinen Operation oder Funktion konzipiert sind. Sie können sie unter einer Lizenz, kostenlos oder mit einem Eigentumsrecht über das Internet verbreiten.
Paket-Manager
Die Paketmanager helfen bei der Verwaltung der Bibliotheken, die wir in unserem Python-Programm verwenden.
Bedenken Sie, dass die rücksichtslose Installation von Python-Paketen durch Ersetzen oder vollständiges Überschreiben der aktuellen Installation möglicherweise Ihr System beschädigen kann. Aus diesem Grund verwenden wir ein Konzept namens „Umgebung“.
Hier sind einige Paketmanager, die Sie verwenden können: pip, conda, pipenvusw. Sie können auch Betriebssystempaketmanager verwenden, um Python-Pakete zu installieren.
Umfeld
Die meisten modernen Betriebssysteme verwenden Python in ihren Kernprozessen und Anwendungen. Die unkontrollierte Installation verschiedener Pakete kann das System beschädigen und es daran hindern, zu booten oder Routineaufgaben auszuführen.
Um dies zu verhindern, verwenden wir eine Containerisierungslogik namens Umgebung. Eine Umgebung ist ein Sandbox-Container in einem Computersystem, in dem neue Versionen einer bestimmten Datei (oder Dateien) installiert werden können. Die Umgebung kommuniziert nicht mit der Installation, sondern erfüllt die Anforderungen eines bestimmten Programms.
Vereinfacht gesagt ähnelt die Umgebung einer virtuellen Maschine. Um zu verhindern, dass unser System auseinanderfällt, erstellen wir eine virtuelle Maschine und führen unser Programm aus, indem wir stattdessen Pakete auf dieser virtuellen Maschine installieren.
Auf diese Weise können die neuen Pakete das System nicht überschreiben und die Anwendung erhält alle Pakete, die sie benötigt. Conda, venvUnd pipenv sind einige Beispiele für Umgebungsmanager für Python.
Sandkasten
Wir verwenden das Konzept des Sandboxings, wenn wir eine Anwendung ohne Beeinträchtigung durch andere Systeme ausführen möchten. Es handelt sich um eine Sicherheitsmaßnahme, die wir bei der Python-Programmierung verwenden, um die Sicherheit unserer Anwendung zu erhöhen. Dies trägt auch dazu bei, die Gesamtsicherheit unseres Systems zu festigen.
Lxml
Wir verwenden Lxml, um HTML-Dokumente zu analysieren und ein DOM des HTML-Dokuments zu generieren. Das Erstellen eines DOM ist eine Frage der Bequemlichkeit. Es hilft uns bei der Suche nach den gewünschten Daten.
Pandas
Pandas ist eine weitere Python-Bibliothek, die häufig in der Datenwissenschaft und Datenverarbeitung verwendet wird. Dies ist praktisch, wenn Sie große Datenmengen verarbeiten und umsetzbare Erkenntnisse gewinnen möchten. Wir werden diese Bibliothek verwenden, um eine CSV-Datei der Daten zu generieren, die wir aus der IMDB extrahieren.
JSON
Es ermöglicht unserem Programm, das HTML-DOM mithilfe von CSS-Selektoren zu durchsuchen. Sie sind eine Erweiterung der LXML-Bibliothek. Sie können diese zusammen verwenden, um mit CSS Selector schnell ein durchsuchbares HTML-DOM zu generieren.
Wir erstellen ein Verzeichnis, in dem wir unser Hauptprogramm und auch die endgültige CSV-Ausgabedatei speichern. Um ein Projektverzeichnis zu erstellen, erstellen wir einfach mit unserem Betriebssystem einen neuen Ordner und öffnen darin einen Texteditor. Für dieses Tutorial verwenden wir Visual Studio Code von Microsoft.
Sobald dies erledigt ist, installieren wir einen Umgebungsmanager, um zu verhindern, dass neue Pakete unser System stören.
Öffnen Sie das Terminal in unserem Texteditor und geben Sie Folgendes ein:
pip install pipenv
Dadurch wird der Umgebungsmanager namens installiert pipenv. Wir hätten es gebrauchen können conda und andere, aber ihre Einrichtung ist im Vergleich zu etwas umständlicher pipenv.
Erstellen Sie nun eine neue Datei mit dem Namen requirements.txt.
In dieser Datei notieren wir die Namen der Pakete, die wir installieren sollen. Die Inhalte von Anforderungen.txt Die Datei wird sein:
pandasrequestsLxmlCssselect
Sobald dieser Schritt abgeschlossen ist, notieren Sie sich den folgenden Befehl, um alle diese auf einmal zu installieren.
pipenv install -r requirements.txt
Dieser Befehl liest die requirements.txt Datei und installiert jede der Bibliotheken, nachdem eine Python-Umgebung mit demselben Namen wie der Ordner erstellt wurde. Wir generieren zwei neue Dateien: Pipfile Und Pipfile.lock.
Dies signalisiert, dass unsere Pakete installiert sind und wir für den nächsten Schritt bereit sind.
Jetzt muss unser Programm wissen, dass wir die in der neuen Umgebung und nicht vom System installierten Pakete verwenden möchten. Daher führen wir den folgenden Befehl aus, um den Speicherort der ausführbaren Datei festzulegen.
pipenv shell
Erstellen Sie nun eine neue Datei mit dem Namen imdb.py um endlich mit dem Schreiben des Programms zu beginnen.
Den Crawler in Python schreiben
Im Gegensatz zum PHP-Crawler wird unsere Scraping-Technik dieses Mal etwas anders sein. Anstatt bei den ersten 250 Seiten stehen zu bleiben, gehen wir noch einen Schritt weiter und extrahieren die Filmzusammenfassung für jeden der aufgelisteten 250 Filme.
Unsere Spaltennamen für diese Scraping-Sitzung lauten also: Titel, Bewertung und Zusammenfassung.
Auf dieser Seite möchten wir die 250 besten IMDB-Filme aller Zeiten extrahieren. Bitte lesen Sie unseren vorherigen Blog „So führen Sie Web Scraping mit PHP durch“, um mehr über die detaillierte Struktur dieser Seite zu erfahren.
Hier konzentrieren wir uns nur auf die nächste Seite, von der aus wir den zusammenfassenden Text für jeden der 250 Filme extrahieren.
Sobald wir auf einen der Filme klicken, können wir sehen, dass wir zu einer Webseite gelangen, die dieser ähnelt:
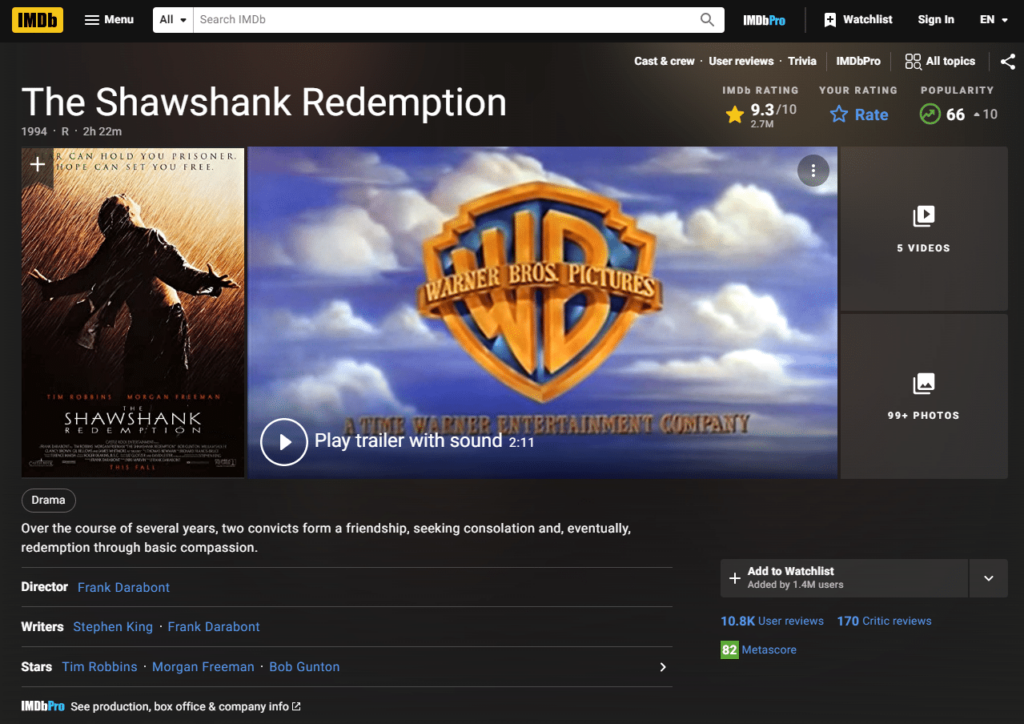
Hier sehen wir unsere erforderliche Zusammenfassung im unteren Teil unserer Webseite. Wenn wir es über unser Entwicklerkonsolentool überprüfen, können wir das genaue CSS-Tag sehen, in dem die Zusammenfassung vorhanden ist.
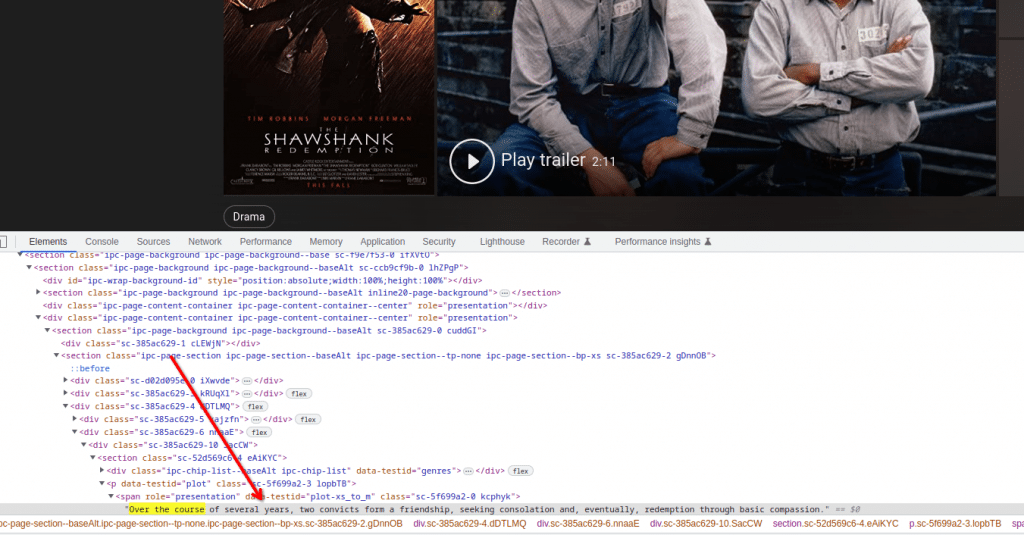
Wir können diese Informationen während unseres Scrapings direkt verwenden, aber lassen Sie uns herausfinden, ob es eine einfachere Methode gibt, mit diesen Informationen umzugehen. Suchen wir in der Seitenquelle nach dem Zusammenfassungstext für diesen Film.

Darüber hinaus stellen wir fest, dass der Zusammenfassungstext aus einem Skript-Tag abgerufen wird, das Daten im JSON-Format enthält. Es ist ein wünschenswerteres Format, da der Inhalt von JSON immer in einem erwarteteren Format vorliegt, im Gegensatz zum HTML-Text, der sich ändern kann, wenn die Webseite aktualisiert wird.
Daher ist es am besten, die Daten aus dem JSON-Objekt zu extrahieren. Sobald Sie sich ein Bild vom Arbeitsablauf des Scrapers gemacht haben, können Sie mit dem Schreiben beginnen.
Beginnen Sie das Python-Skript, indem Sie alle installierten Pakete mit dem Schlüsselwort importieren importieren ähnlich zu:
import pandas as pd
import requests as re
import lxml.html as ext
import jsonUm mit dem Scraping zu beginnen, definieren wir eine Header-Variable, die alle erforderlichen Header für die Website enthält.
Die Header sind wichtig, da sie das Format der Handshakes zwischen der Quellwebsite und unserem Code bestimmen, sodass eine reibungslose Datenübertragung zwischen den beiden Agenten erfolgen kann.
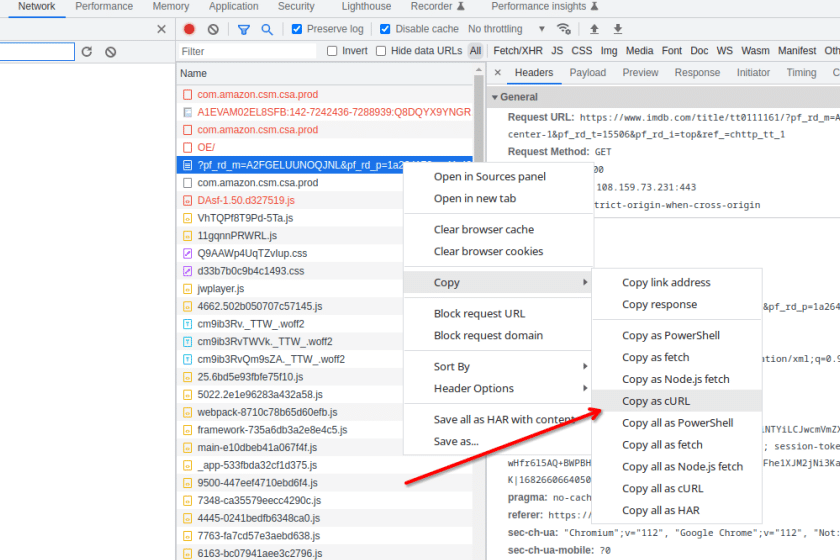
Infolgedessen können wir die entsprechenden Header aus der Registerkarte „Netzwerk“ der Entwicklerkonsole abrufen. Suchen Sie einfach nach der gewünschten Seite, klicken Sie mit der rechten Maustaste auf die Webseite, klicken Sie dann und kopieren Sie sie als cURL.
Fügen Sie den Inhalt vorübergehend in eine andere Datei ein, um alle Header zu überprüfen.
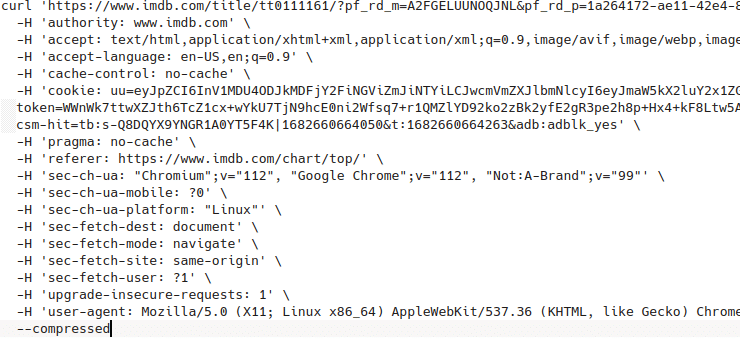
cURL headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36 Edg/111.0.1661.51',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'en-US,en;q=0.9'
}
Wenn dies definiert ist, verwenden wir die Anforderungsbibliothek, um eine Get-Anfrage an die Website von IMDB zu senden, die die 250 besten Filme enthält.
response = re.get(‘https://www.imdb.com/chart/top/?ref_=nv_mp_mv250’, headers=headers)Der Hauptteil des Antwortinhalts wird in die Antwortvariable eingefügt. Jetzt müssen wir ein HTML-DOM-Dokument der jeweiligen Antwort generieren, damit wir es problemlos verwenden können lxml Und cssselect um nach unseren benötigten Daten zu suchen. Darüber hinaus können wir dies mit der folgenden Codezeile tun:
tree = ext.fromstring(response.text)
movies = (ext.tostring(x) for x in tree.cssselect('table(data-caller-name="chart-top250movie") > tbody > tr'))Sobald dies erledigt ist, werden alle benötigten Informationen zu den 250 Filmen in der Variable movies als Liste gespeichert. Jetzt müssen Sie nur noch diese Variable durchlaufen, um weiter in die Webseite jedes Films zu gelangen und die Zusammenfassung zu erhalten. Sie können dies mit dem folgenden Codeblock tun:
url="https://www.imdb.com{}".format(tree.cssselect('a')(1).get('href'))
response = req.get(url, headers=headers)Daraufhin wird eine Webseite angezeigt, die die Filmzusammenfassung für unsere Filme enthält. Nun müssen wir, wie bereits erwähnt, das JSON-Objekt aus dem Skript-Tag dieser neuen Webseite extrahieren. Wir können dies tun, indem wir die JSON-Bibliothek wie unten gezeigt verwenden:
script = json.loads(tree.cssselect('script(type="application/ld+json")')(0).text_content())Darüber hinaus enthält diese neue Skriptvariable das JSON-Objekt von der Website. Platzieren Sie die Informationen in einem übersichtlichen Array und Sie erhalten die entsprechenden Zeilendaten für einen Film. Machen Sie es so:
row = {
'Title': script('name'),
'Rating': rating,
'Summary': script('description')
}Wenn wir diesen Prozess mehr als 250 Mal wiederholen, erhalten wir die erforderlichen Daten. Ohne die Speicherung dieser Daten an einem zwischengeschalteten Ort können wir die Daten jedoch nicht für die weitere Verarbeitung und Analyse verwenden, wofür unsere Zwecke zuständig sind pandas Die Bibliothek kommt herein.
Während jeder Iteration speichern wir die Zeileninformationen in a Datenrahmen Reihe unserer Pandas Objekt mit dem folgenden Code:
all_data = pd.concat((all_data, pd.DataFrame((row))), ignore_index=True)Nachdem die Iterationen abgeschlossen sind, können wir das Pandas-Objekt in eine CSV-Datei exportieren, um die Daten zur nachgelagerten Analyse zu senden.
Im Folgenden finden Sie den gesamten Python-Code:
import pandas as pd
import requests as req
import lxml.html as ext
import json
url="https://www.imdb.com/chart/top/?ref_=nv_mp_mv250"
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36 Edg/111.0.1661.51',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'en-US,en;q=0.9'
}
response = req.get(url, headers=headers)
tree = ext.fromstring(response.text)
movies = (ext.tostring(x) for x in tree.cssselect('table(data-caller-name="chart-top250movie") > tbody > tr'))
all_data = pd.DataFrame()
for idx, movie in enumerate(movies):
print('Processing {}'.format(idx))
tree = ext.fromstring(movie)
url="https://www.imdb.com{}".format(tree.cssselect('a')(1).get('href'))
rating = tree.cssselect('td.ratingColumn.imdbRating strong')(0).text_content()
response = req.get(url, headers=headers)
tree = ext.fromstring(response.text)
script = json.loads(tree.cssselect('script(type="application/ld+json")')(0).text_content())
row = {
'Title': script('name'),
'Rating': rating,
'Summary': script('description')
}
all_data = pd.concat((all_data, pd.DataFrame((row))), ignore_index=True)
all_data.to_csv('final_data.csv', index = False)
Verwenden Sie den folgenden Datensatz nach Belieben. Binge-Watching am Wochenende vielleicht?
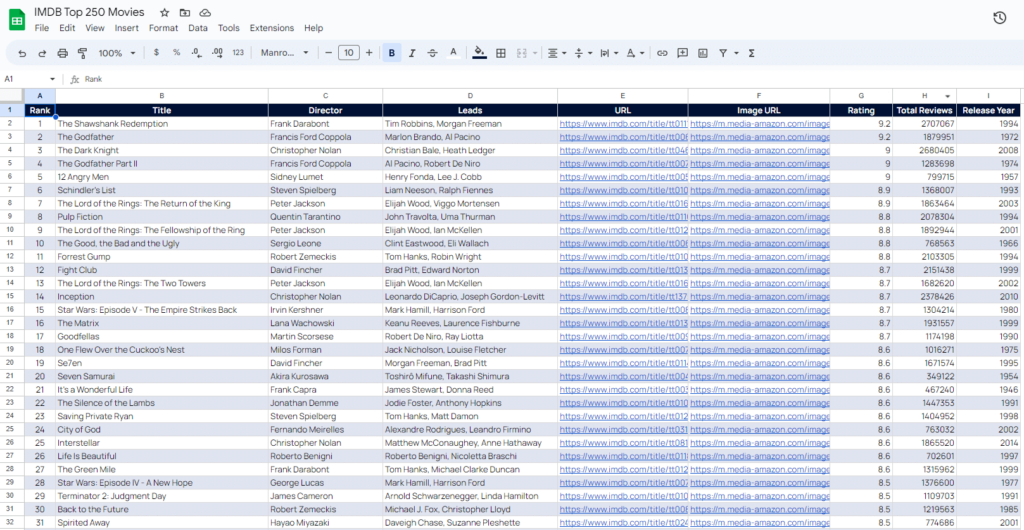
Letzte Worte
In Python geben wir jede Filmseite ein und extrahieren die Zusammenfassungen der Filme.
Die Verknüpfung in PHP aufheben, wir mussten in unserem Code keine Header definieren. Hauptsächlich, weil die interne Seite dieses Mal viel schwieriger war und vom Webserver weiter geshellt wurde.
In diesem Artikel haben wir die grundlegenden Methoden verwendet, um auf die Daten zuzugreifen, ohne unnötige Fehler zu verursachen.
Heutzutage verfügen die meisten Websites im Internet über strenge Anti-Bot-Maßnahmen. Bei ernsthaften und langfristigen Datenextraktionsprojekten funktionieren einfache Umgehungen wie diese nicht.
Daher entscheiden sich Unternehmen, die regelmäßig auf groß angelegte Datenextraktionsprojekte angewiesen sind, für Grepsr.
Verwandte Lektüre:
