
Pengikisan data adalah bagian penting dari setiap bisnis. Untuk menawarkan informasi terkini, penting untuk melacak minat dan tren pelanggan dan pengguna reguler.
Salah satu kegunaan paling berharga dari scraper adalah menggores hasil pencarian Google. Mengikis hasil mesin pencari memungkinkan Anda melacak data apa yang diterima pengguna dan mengumpulkan prospek.
Berdasarkan pengalaman kami, Python adalah salah satu bahasa pemrograman yang paling cocok untuk scraping. Ini memungkinkan Anda menulis skrip dengan mudah dan cepat untuk mengumpulkan data. Jadi dalam tutorial ini, kita akan melihat cara mencari halaman hasil pencarian Google dengan Python, tantangan apa yang akan Anda hadapi, dan cara mengatasinya.
Daftar Isi
Analisis halaman SERP Google
Sebelum Anda membuat pengikis Google, Anda perlu menganalisis halaman yang ingin Anda kikis untuk mengetahui di mana letak elemen yang diperlukan. Anda harus terlebih dahulu mempertimbangkan tautan yang dihasilkan Google selama permintaan pencarian.
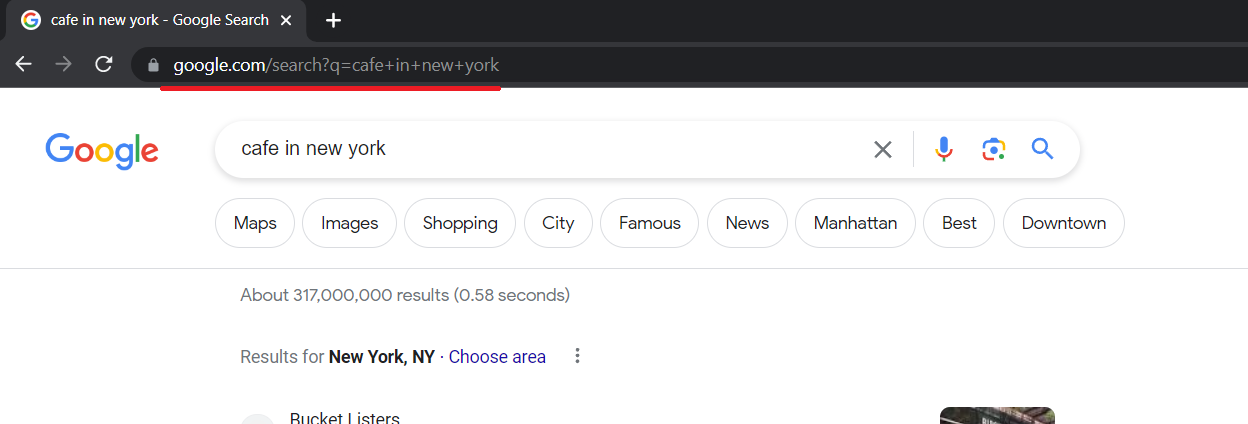
Tautannya sangat sederhana dan kita bisa membuatnya sendiri. Bagian “https://www.google.com/search?q=” tetap tidak berubah, diikuti dengan teks kueri dengan “+” dan bukan spasi.
Sekarang kita perlu memahami di mana letak data yang kita butuhkan. Untuk melakukan ini, buka DevTools (klik kanan pada layar dan tekan “Inspect” atau cukup tekan F12).
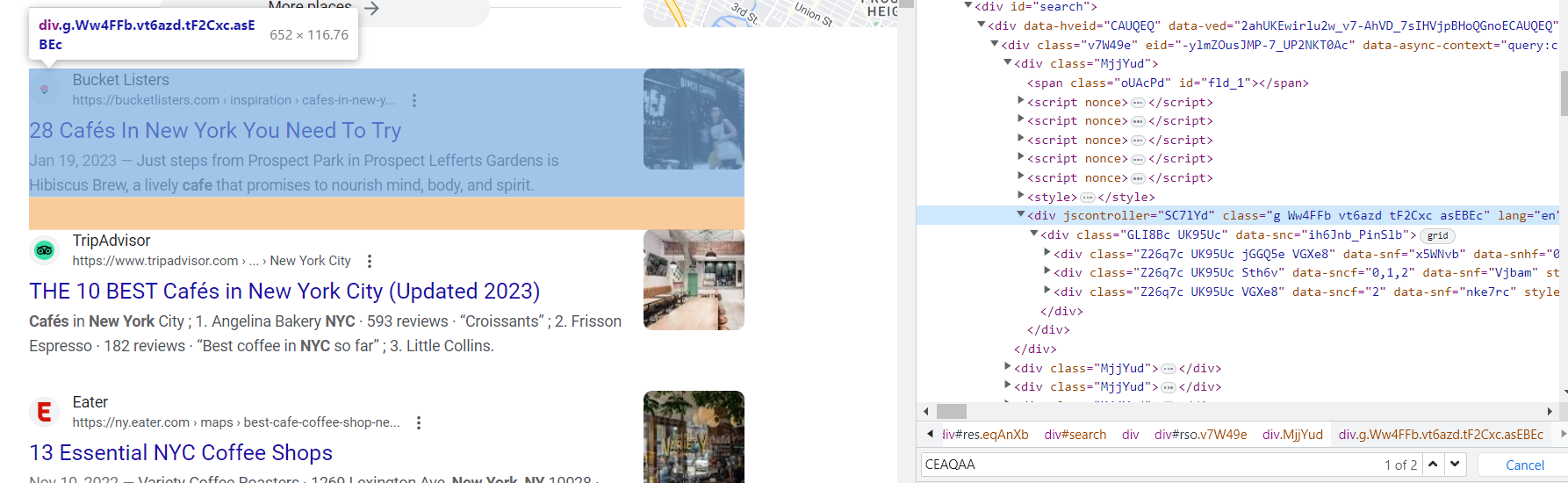
Sayangnya, hampir semua kelas di halaman hasil mesin pencari dibuat secara otomatis. Oleh karena itu, sulit untuk mengambil data berdasarkan nama kelas. Namun, struktur halamannya tetap tidak berubah. Kelas “g” pada hasil pencarian juga tetap tidak berubah.
Jika kita mencermati elemen-elemen di kelas ini, kita dapat mengidentifikasi tag yang berisi link, judul, dan deskripsi elemen:
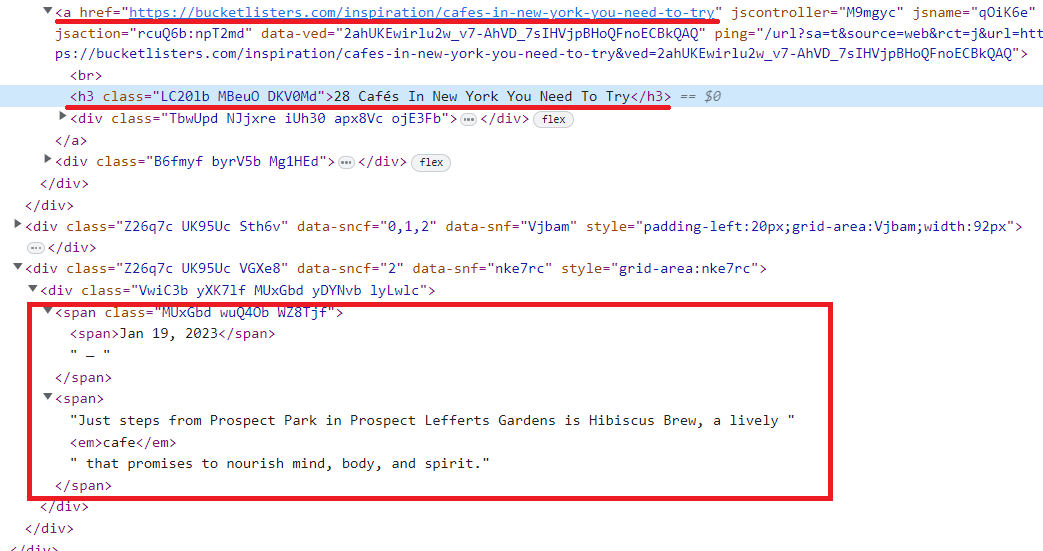
Sekarang kita telah melihat halaman dan menemukan elemen yang akan kita gores, kita bisa mulai membuat scraper.
Menyiapkan lingkungan pengembangan
Sebelum kita mempelajari hasil pencarian Google web scraping, penting untuk menyiapkan lingkungan pengembangan yang sesuai dengan Python. Ini termasuk memasang pustaka dan alat yang diperlukan yang memungkinkan kami mengirimkan kueri ke Google, menganalisis respons HTML, dan memproses data secara efektif.
Pertama, pastikan Python terinstal di komputer Anda. Untuk memeriksanya, Anda dapat menggunakan:
python -vJika Anda memiliki versi Python, maka Anda memilikinya. Kami akan menggunakan Python versi 3.10.7. Jika Anda belum menginstal Python, kunjungi situs web resmi Python dan unduh versi terbaru yang kompatibel dengan sistem operasi Anda. Ikuti petunjuk instalasi dan tambahkan Python ke variabel PATH sistem Anda.
Untuk menunjukkan berbagai cara mengikis SERP Google, mari instal perpustakaan berikut:
pip install beautifulsoup4
pip install selenium
pip install google-serp-apiKami juga akan menggunakan perpustakaan Permintaan dalam skrip Python kami, perpustakaan Python yang sudah diinstal sebelumnya. Namun, jika Anda tidak memilikinya karena alasan tertentu, Anda dapat menggunakan perintah berikut:
pip install requestsAnda juga dapat menggunakan pustaka URL, bukan pustaka Permintaan.
Untuk menggunakan browser tanpa kepala Selenium, Anda juga perlu mengunduh WebDriver yang sesuai yang dapat dijalankan untuk browser Anda. Selenium memerlukan WebDriver terpisah untuk terhubung ke setiap browser. Misalnya, jika Anda menggunakan Google Chrome, Anda memerlukan ChromeDriver. Anda dapat mengunduhnya dari situs resminya.
Mengikis Pencarian Google dengan Python menggunakan BeautifulSoup
Sekarang kita sudah menyiapkan lingkungan pengembangan, mari selami proses penguraian dan ekstraksi data dari hasil penelusuran Google. Kami menggunakan perpustakaan Permintaan untuk mengirim permintaan HTTP dan mendapatkan respons HTML, dan perpustakaan BeautifulSoup untuk menguraikan dan menavigasi struktur HTML. Mari buat file baru dan sambungkan perpustakaan:
import requests
from bs4 import BeautifulSoupUntuk mengaburkan scraper kami dan mengurangi kemungkinan pemblokiran, kami menetapkan header kueri:
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'}Dianjurkan untuk menunjukkan kategori yang ada dalam permintaan. Misalnya, Anda dapat menggunakan milik Anda sendiri, yang dapat Anda temukan di DevTools pada tab Jaringan. Kemudian kita menjalankan query dan menulis jawaban ke variabel:
data = requests.get('https://www.google.com/search?q=cafe+in+new+york', headers=header)Pada titik ini kita sudah menerima kode halaman tersebut dan kemudian kita perlu memprosesnya. Buat objek BeautifulSoup dan parsing HTML halaman yang dihasilkan:
soup = BeautifulSoup(data.content, "html.parser")Mari kita juga membuat variabel hasil di mana kita akan menulis data tentang elemen:
results = ()Agar kita dapat mengolah data elemen demi elemen, kita ingat bahwa setiap elemen memiliki kelas “g”. Artinya, telusuri semua elemen dan dapatkan data darinya, dapatkan semua elemen dengan kelas "g" dan telusuri satu per satu untuk mendapatkan data yang diperlukan. Untuk melakukan ini, kita membuat perulangan for:
for g in soup.find_all('div', {'class':'g'}):Jika kita melihat lebih dekat pada kode halaman tersebut, kita juga dapat melihat bahwa semua elemen adalah turunan dari -Tag adalah tempat penyimpanan tautan halaman. Mari gunakan ini dan dapatkan data judul, tautan, dan deskripsi. Kami memperhitungkan bahwa deskripsi boleh kosong dan meletakkannya di blok coba…kecuali:
if anchors:
link = anchors(0)('href')
title = g.find('h3').text
try:
description = g.find('div', {'data-sncf':'2'}).text
except Exception as e:
description = "-"Masukkan data tentang elemen ke dalam variabel hasil:
results.append(str(title)+";"+str(link)+';'+str(description))Sekarang kita bisa menampilkan variabel di layar, tapi mari kita memperumitnya dan menyimpan data ke file. Untuk melakukan ini, buat atau timpa file dengan kolom “Judul”, “Tautan”, “Deskripsi”:
with open("serp.csv", "w") as f:
f.write("Title; Link; Description\n")Dan mari masukkan data dari variabel hasil baris demi baris:
for result in results:
with open("serp.csv", "a", encoding="utf-8") as f:
f.write(str(result)+"\n")Saat ini kami memiliki scraper mesin pencari sederhana yang mengumpulkan hasil dalam file CSV.
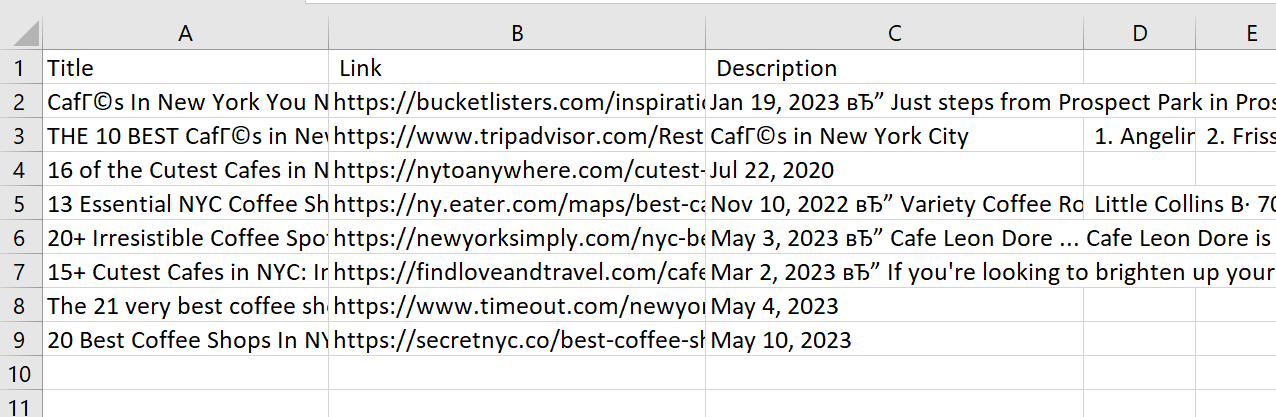
Kode lengkap:
import requests
from bs4 import BeautifulSoup
url="https://www.google.com/search?q=cafe+in+new+york"
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'}
data = requests.get(url, headers=header)
if data.status_code == 200:
soup = BeautifulSoup(data.content, "html.parser")
results = ()
for g in soup.find_all('div', {'class':'g'}):
anchors = g.find_all('a')
if anchors:
link = anchors(0)('href')
title = g.find('h3').text
try:
description = g.find('div', {'data-sncf':'2'}).text
except Exception as e:
description = "-"
results.append(str(title)+";"+str(link)+';'+str(description))
with open("serp.csv", "w") as f:
f.write("Title; Link; Description\n")
for result in results:
with open("serp.csv", "a", encoding="utf-8") as f:
f.write(str(result)+"\n")Sayangnya skrip ini memiliki beberapa kelemahan:
- Hanya sejumlah kecil data yang dikumpulkan.
- Tidak ada data dinamis yang dikumpulkan.
- Tidak ada proxy yang digunakan.
- Tidak ada tindakan yang diambil pada halaman tersebut.
- Itu tidak menyelesaikan captcha.
Mari kita menulis skrip baru berdasarkan perpustakaan Selenium untuk menyelesaikan beberapa masalah ini.
Gunakan Headless Browser untuk mengambil data dari hasil pencarian
Peramban tanpa kepala dapat bermanfaat saat bekerja dengan situs web yang menggunakan konten dinamis, memerlukan tantangan CAPTCHA, atau memerlukan rendering JavaScript. Selenium, alat otomatisasi web yang kuat, memungkinkan kita berinteraksi dan mengekstrak data dari halaman web melalui browser tanpa kepala.
Buat file baru dan sambungkan perpustakaan:
from selenium import webdriver
from selenium.webdriver.common.by import BySekarang mari kita tunjukkan di mana letak driver web yang diunduh sebelumnya:
DRIVER_PATH = 'C:\chromedriver.exe'
driver = webdriver.Chrome(executable_path=DRIVER_PATH)Pada skrip sebelumnya, kami menentukan kueri dengan tautan. Namun kami melihat bahwa semua kueri tampak sama. Jadi mari kita tingkatkan ini dan memungkinkan pembuatan tautan berdasarkan kueri teks:
search_query = "cafe in new york"
base_url = "https://www.google.com/search?q="
search_url = base_url + search_query.replace(" ", "+")Sekarang kita bisa pergi ke halaman yang kita butuhkan:
driver.get(search_url)Mari kita ekstrak datanya menggunakan pemilih CSS dari skrip sebelumnya:
results = ()
result_divs = driver.find_elements(By.CSS_SELECTOR, "div.g")
for result_div in result_divs:
result = {}
anchor = result_div.find_elements(By.CSS_SELECTOR, "a")
link = anchor(0).get_attribute("href")
title = result_div.find_element(By.CSS_SELECTOR, "h3").text
description_element = result_div.find_element(By.XPATH, "//div(@data-sncf="2")")
description = description_element.text if description_element else "-"
results.append(str(title)+";"+str(link)+';'+str(description))Tutup peramban:
driver.quit()Dan kemudian simpan data ke file:
with open("serp.csv", "w") as f:
f.write("Title; Link; Description\n")
for result in results:
with open("serp.csv", "a", encoding="utf-8") as f:
f.write(str(result)+"\n")Dengan Selenium kami telah memecahkan beberapa masalah yang terkait dengan pengikisan. Misalnya, kami telah mengurangi risiko pemblokiran secara signifikan karena browser tanpa kepala sepenuhnya mensimulasikan pekerjaan pengguna sebenarnya, sehingga skrip tidak dapat dibedakan dari seseorang.
Pendekatan ini juga memungkinkan kita bekerja dengan berbagai elemen pada halaman dan menghapus halaman dinamis.
Namun kami masih belum bisa mengontrol lokasi kami, kami tidak bisa menyelesaikan captcha jika itu terjadi, dan kami tidak menggunakan proxy. Mari beralih ke perpustakaan berikut untuk menyelesaikan masalah ini.
Pengikisan web dengan Google Search API
Untuk bekerja dengan perpustakaan kami, Anda memerlukan kunci API, yang dapat Anda temukan di akun Anda. Jadi, untuk membuat scraper SERP Google yang kaya fitur, kami menggunakan perpustakaan kami:
from google_serp_api import ScrapeitCloudClientMari kita sambungkan juga pustaka JSON bawaan untuk memproses respons, yang dalam format JSON:
import jsonMari tentukan kunci API dan atur parameternya:
client = ScrapeitCloudClient(api_key='YOUR-API-KEY')
response = client.scrape(
params={
"q": search_key,
"location": "Austin, Texas, United States",
"domain": "google.com",
"deviceType": "desktop",
"num": 100
}
)Anda dapat mengatur kata pencarian, negara tempat Anda ingin mengambil data, jumlah hasil yang akan dipindai, dan domain Google. Menjalankan kode ini akan mengembalikan respons berformat JSON dengan data dalam tampilan berikut:
- requestMetadata (request metadata)
- id (request ID)
- googleUrl (Google search URL)
- googleHtmlFile (URL of the Google HTML file)
- status (request status)
- organicResults (organic results)
- position (result position)
- title (result title)
- link (result link)
- displayedLink (displayed result link)
- source (result source)
- snippet (result snippet)
- snippetHighlitedWords (highlighted words in the result snippet)
- sitelinks (site links embedded in the result)
- localResults (local results)
- places (places)
- position (place position)
- title (place title)
- rating (place rating)
- reviews (number of reviews for the place)
- reviewsOriginal (original format of the number of reviews for the place)
- price (place price)
- address (place address)
- hours (place hours of operation)
- serviceOptions (service options)
- placeId (place ID)
- description (place description)
- moreLocationsLink (link to more locations)
- relatedSearches (related searches)
- query (related query)
- link (link to related search results)
- relatedQuestions (related questions)
- question (related question)
- snippet (snippet of the answer to the related question)
- link (link to related question results)
- title (title of the related question result)
- displayedLink (displayed link of the related question result)
- pagination (pagination)
- next (link to the next page of results)
- knowledgeGraph (knowledge graph)
- title (title)
- type (type)
- description (description)
- source (source)
- link (source link)
- name (source name)
- peopleAlsoSearchFor (people also search for)
- name (name)
- link (link to related search results)
- searchInformation (search information)
- totalResults (total number of results)
- timeTaken (time taken for the request)Mari simpan data hasil organik dan penelusuran terkait dalam file terpisah. Pertama, format respon yang diterima dari string ke dalam JSON dan masukkan data dari atribut yang diinginkan ke dalam variabel.
data = json.loads(response.text)
organic_results = data('organicResults')
keywords = data('relatedSearches')Buat variabel dengan hasil yang diinginkan.
rows_organic = ()
rows_keys =()Telusuri semua trek elemen demi elemen dan masukkan ke dalam variabel dalam bentuk yang benar:
for result in organic_results:
rows_organic.append(str(result('position'))+";"+str(result('title'))+";"+str(result('link'))+";"+str(result('source'))+";"+str(result('snippet')))
for result in keywords:
rows_keys.append(str(result('query'))+";"+str(result('link')))Mari simpan data dalam file:
with open("data_organic.csv", "w") as f:
f.write("position; title; url; domain; snippet'\n")
for row in rows_organic:
with open("data_organic.csv", "a", encoding="utf-8") as f:
f.write(str(row)+"\n")
with open("data_keys.csv", "w") as f:
f.write("keyword; path'\n")
for row in rows_keys:
with open("data_keys.csv", "a", encoding="utf-8") as f:
f.write(str(row)+"\n")Sebagai hasil dari menjalankan skrip, kami menerima dua file:
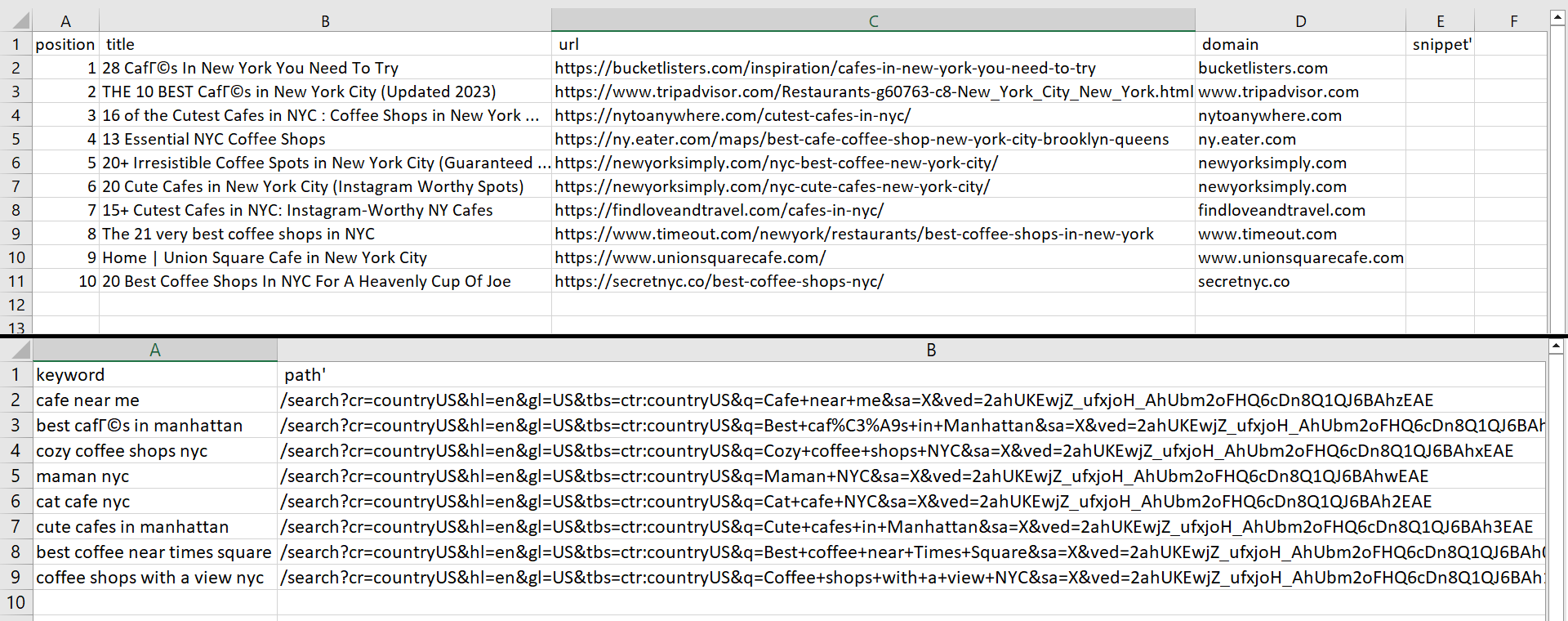
Kita dapat mengubah jumlah hasil dengan mengubah parameter num_results menjadi “params”. Namun, katakanlah kita memiliki file yang menyimpan semua kata kunci yang kita perlukan untuk mengikis data. Kita perlu membuka file tersebut terlebih dahulu dan kemudian menelusurinya baris demi baris dengan kata kunci baru:
with open("keywords.csv") as f:
lines = f.readlines()
with open("data_keys.csv", "w") as f:
f.write("search_key; keyword; path'\n")
with open("data_organic.csv", "w") as f:
f.write("search_key; position; title; url; domain; snippet'\n")
for line in lines:Kami menentukan judul kolom untuk file baru sebelum memasukkan kata kunci. Artinya file tersebut tidak akan tertimpa saat Anda mencari kata kunci baru. Sebaliknya, file tersebut dilengkapi dengan data tambahan. Kami juga menambahkan kolom lain yang berisi permintaan pencarian teks yang hasilnya cocok.
Sekarang kita ubah jawabannya dan tentukan kata kunci yang harus sama dengan variabel baris:
response = client.scrape(
params={
"q": search_key,
"location": "Austin, Texas, United States",
"domain": "google.com",
"deviceType": "desktop",
"num": 100
}
)Kode lainnya akan serupa. Yang ditambahkan hanyalah kolom baru dengan variabel baris. Hasilnya kami mendapatkan dua file berikut:
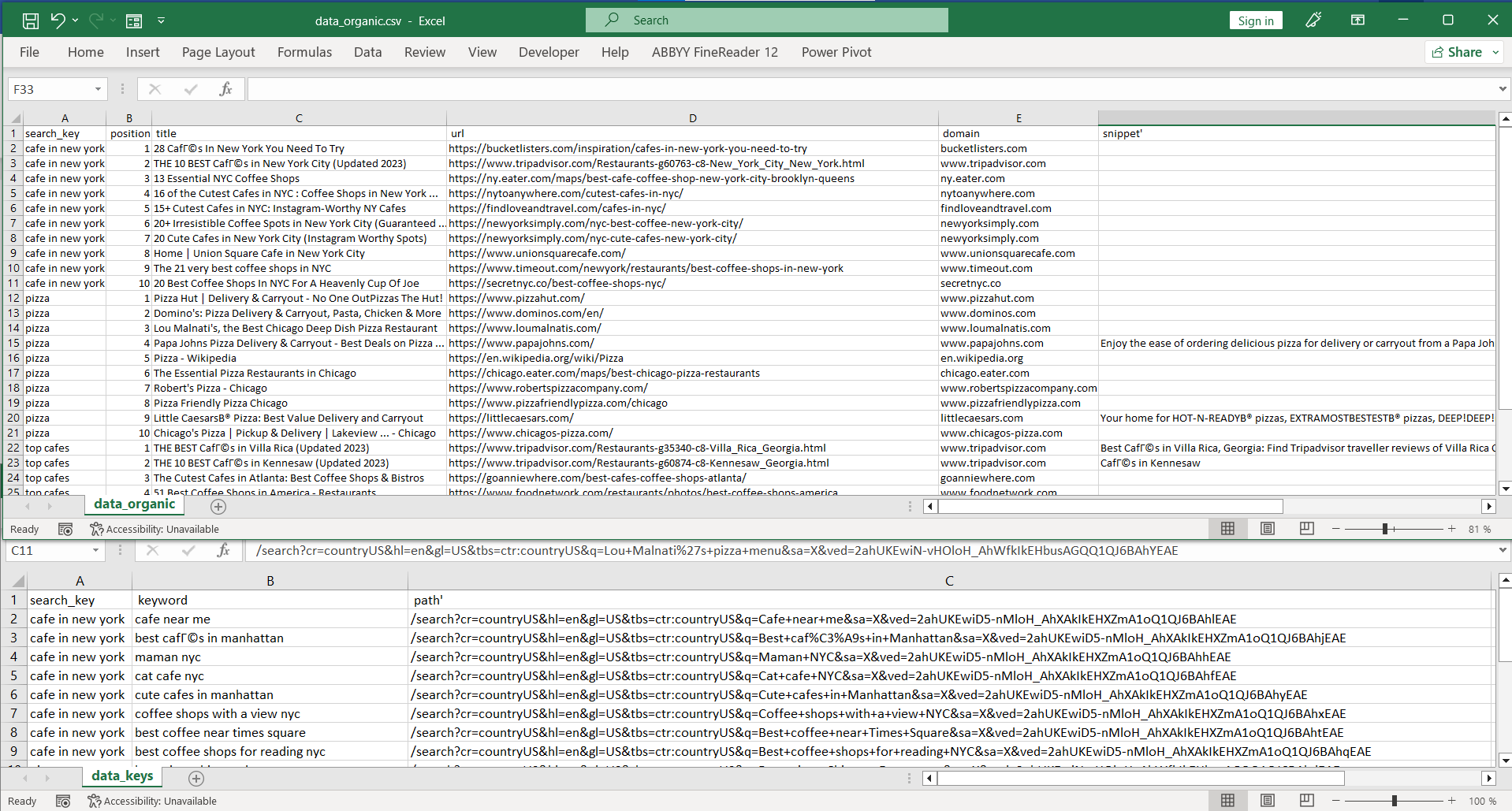
Kode Python lengkap:
from google_serp_api import ScrapeitCloudClient
import json
with open("keywords.csv") as f:
lines = f.readlines()
with open("data_keys.csv", "w") as f:
f.write("search_key; keyword; path'\n")
with open("data_organic.csv", "w") as f:
f.write("search_key; position; title; url; domain; snippet'\n")
for line in lines:
search_key = str(line.replace("\n", ""))
client = ScrapeitCloudClient(api_key='YOUR-API-KEY')
response = client.scrape(
params={
"q": search_key,
"location": "Austin, Texas, United States",
"domain": "google.com",
"deviceType": "desktop",
"num": 100
}
)
data = json.loads(response.text)
organic_results = data.get('organicResults', ())
keywords = data.get('relatedSearches', ())
rows_organic = ()
rows_keys = ()
for result in organic_results:
rows_organic.append(f"{search_key};{result.get('position', '')};{result.get('title', '')};{result.get('link', '')};{result.get('source', '')};{result.get('snippet', '')}")
for result in keywords:
rows_keys.append(f"{search_key};{result.get('query', '')};{result.get('link', '')}")
for row in rows_organic:
with open("data_organic.csv", "a", encoding="utf-8") as f:
f.write(row + "\n")
for row in rows_keys:
with open("data_keys.csv", "a", encoding="utf-8") as f:
f.write(row + "\n")Keuntungan utama menggunakan perpustakaan Scrape-It.Cloud adalah Anda tidak perlu khawatir tentang rotasi proxy, rendering JavaScript, atau penyelesaian captcha - API menyediakan data yang telah disiapkan.
Mengikis Pencarian Google dengan Python: Tantangan dan Keterbatasan
Mengikis hasil pencarian Google dengan Python bisa jadi sulit. Ada beberapa tantangan yang harus diatasi saat melakukan scraping pada hasil penelusuran Google, mulai dari kerumitan teknis yang terkait dengan algoritma mesin pencari yang selalu berubah hingga perlindungan anti-scraping yang ada di dalamnya. Ada juga kemungkinan pemblokiran alamat IP dan entri captcha, serta banyak tantangan lainnya yang akan kita bahas di bawah.
Batasan geolokasi
Hasil pencarian Google mungkin berbeda tergantung lokasi Anda. Misalnya, jika Anda melakukan penelusuran di AS, hasilnya mungkin berbeda dengan hasil penelusuran di Kanada. Jika Anda memiliki izin untuk mengakses data lokasi atau telah melakukan cukup banyak pencarian dari suatu lokasi, Google akan memberikan hasil pencarian yang dilokalkan hanya untuk area tersebut. Untuk mengetahui seperti apa hasil pencarian di negara atau kota lain, Anda perlu menggunakan server proxy dari lokasi tersebut atau Anda dapat menggunakan API web scraping siap pakai yang melakukan semua ini.
Domain khusus negara
Google mendukung domain pencarian berbeda untuk berbagai negara. Misalnya google.co.uk untuk Inggris Raya atau google.de untuk Jerman. Masing-masing memiliki fiturnya sendiri, Google SERP-nya sendiri, dan Google Mapsnya sendiri yang perlu diperhitungkan saat melakukan scraping.
Pembatasan pada halaman hasil
Situs ini menampilkan sejumlah hasil yang terbatas. Untuk melihat kalimat berikutnya, Anda harus menelusuri hasil pencarian yang ada atau membuka halaman berikutnya. Ingatlah bahwa setiap kali Anda berpindah halaman, permintaan baru akan dipertimbangkan oleh Google dan jika ada terlalu banyak permintaan, alamat IP Anda mungkin diblokir atau Anda mungkin harus melakukan tantangan captcha untuk tujuan verifikasi.
Captcha dan tindakan anti-scraping
Seperti yang telah disebutkan sebelumnya, Google memiliki berbagai metode untuk menangani web scraping. Pemblokiran captcha dan alamat IP adalah dua strategi yang paling umum.
Untuk mengatasi tantangan captcha, Anda dapat menggunakan layanan pihak ketiga di mana orang sungguhan menyelesaikannya dengan sedikit biaya. Namun, Anda perlu mengintegrasikannya ke dalam aplikasi Anda sendiri dan mengaturnya dengan benar.
Hal yang sama berlaku untuk pemblokiran IP. Anda dapat menghindari tantangan ini dengan menyewa proxy untuk menyembunyikan alamat IP Anda dan juga melewati pemblokiran ini - tetapi hanya jika Anda menemukan penyedia proxy terkait yang cukup andal untuk mempercayakan tugas ini kepada Anda. Anda juga dapat melihat daftar proxy gratis kami.
Struktur HTML dinamis
Rendering JavaScript adalah cara lain untuk melindungi diri Anda dari pencakar dan bot. Artinya konten halaman dibuat secara dinamis dan berubah setiap kali halaman dimuat. Misalnya, kelas di halaman web mungkin memiliki nama yang berbeda setiap kali Anda membukanya - namun keseluruhan struktur halaman web tetap konsisten. Hal ini membuat pengikisan halaman menjadi sulit, namun masih memungkinkan.
Perubahan yang tidak dapat diprediksi
Google terus mengembangkan dan meningkatkan algoritme dan prosesnya. Artinya, tidak semua alat pengikis web dapat digunakan secara permanen tanpa pemeliharaan - alat tersebut harus selalu diperbarui dengan perubahan terbaru dari Google.
Kesimpulan dan temuan
Berbagai opsi dan pustaka dapat membantu ekstraksi data dari SERP Google dengan Python. Setiap orang memilih opsi yang paling sesuai dengan proyek dan keterampilan mereka.
Jika Anda baru dalam scraping dan ingin mendapatkan sejumlah kecil data, Anda mungkin puas dengan pustaka Permintaan untuk menjalankan kueri dan pustaka BeautifulSoup untuk menguraikan data yang Anda dapatkan. Jika Anda terbiasa dengan browser tanpa kepala dan alat otomatisasi, Selenium cocok untuk Anda.
Dan jika Anda ingin menghindari menghubungkan layanan pihak ketiga untuk menyelesaikan captcha, menyewa proxy dan tidak ingin memikirkan cara menghindari pemblokiran atau mendapatkan data yang diinginkan, Anda dapat menggunakan perpustakaan google_serp_api.