
TL;DR: Menggunakan Permintaan dan BeautifulSoup untuk pengikisan web
Pertama, instal kedua dependensi dari terminal Anda menggunakan perintah berikut:
pip install requests beautifulsoup4Setelah instalasi selesai, impor
requestsDanBeautifulSoupke file Anda:import requests from bs4 import BeautifulSoupKirim
get()Permintaan dengan permintaan untuk mengunduh konten HTML laman landas Anda dan menyimpannya ke variabel - untuk contoh ini kami akan mengirimkannyaget()Minta ke BooksToScrape dan simpan HTML dalam saturesponseVariabel:response = requests.get(“https://books.toscrape.com/catalogue/page-1.html”)Untuk mengekstrak titik data tertentu dari HTML, kita perlu mengurai responsnya menggunakan BS4:
soup = BeautifulSoup(response.content, "lxml")Terakhir, kita dapat memilih elemen menggunakan pemilih CSS atau tag HTML seperti ini:
title = soup.find(“h1”) print(title)
Internet menawarkan sejumlah besar data dan merupakan sumber daya berharga untuk bidang penelitian atau kepentingan pribadi apa pun. Namun, tidak semua informasi ini dapat diakses dengan mudah melalui cara tradisional.
Beberapa situs web tidak menyediakan API untuk mengambil kontennya; yang lain mungkin menggunakan teknologi kompleks yang menyulitkan ekstraksi data menggunakan metode tradisional.
Untuk memulainya, dalam tutorial ini kami akan menunjukkan cara mengekstrak data dari situs web mana pun menggunakan paket Python Requests dan BeautifulSoup. Ini mencakup dasar-dasar web scraping, termasuk mengirim permintaan HTTP, mengurai HTML, dan mengekstrak informasi spesifik.
Agar lebih praktis, mari pelajari cara membuat scraper untuk mengumpulkan daftar artikel teknis dari Techcrunch. Pada akhirnya, Anda akan mempelajari cara:
- Unduh situs web
- Parsing konten HTML
- Ekstrak data menggunakan metode BeautifulSoup dan pemilih CSS
Daftar Isi
persyaratan
Untuk mengikuti tutorial ini Anda perlu menginstal ular piton 3.7 atau lebih tinggi di komputer Anda. Anda dapat mendownloadnya dari situs resminya jika Anda belum menginstalnya.
Anda juga memerlukan persyaratan berikut:
Menginstal lingkungan virtual
Sebelum menginstal perpustakaan yang diperlukan, disarankan untuk membuat lingkungan virtual untuk mengisolasi dependensi proyek.
Membuat lingkungan virtual di Windows
Buka prompt perintah dengan hak administratif dan jalankan perintah berikut untuk membuat lingkungan virtual baru bernama Venv:
Aktifkan lingkungan virtual dengan perintah berikut:
Membuat lingkungan virtual di macOS/Linux
Buka terminal dan jalankan perintah berikut untuk membuat lingkungan virtual baru bernama Venv:
sudo python3 -m venv venv
Aktifkan lingkungan virtual:
Menginstal Permintaan, BeautifulSoup dan Lxml
Setelah Anda membuat dan mengaktifkan lingkungan virtual, Anda dapat menginstal perpustakaan yang diperlukan dengan menjalankan perintah berikut di terminal Anda:
pip install requests beautifulsoup4 lxml
- Permintaan adalah pustaka HTTP untuk Python yang menyederhanakan pengiriman permintaan HTTP dan pemrosesan respons.
- BeautifulSoup adalah perpustakaan untuk mengurai dokumen HTML dan XML.
- Lxml adalah parser XML dan HTML yang kuat dan cepat yang ditulis dalam C. Lxml digunakan oleh BeautifulSoup untuk menyediakan dukungan XPath.
Unduh halaman web pertanyaan
Langkah pertama dalam melakukan scraping data web adalah mendownload halaman web yang ingin Anda scrap. Anda dapat melakukan ini menggunakan get() Meminta metode perpustakaan.
import requests
url = 'https://techcrunch.com/category/startups/'
response = requests.get(url)
print(response.text)
Di atas kami menggunakan Permintaan untuk mendapatkan respons HTML dari TechCrunch. get() Ada satu metode response Objek yang berisi HTML halaman web. Kami menggunakan BeautifulSoup untuk mengekstrak data yang kami perlukan dari respons HTML ini.
Parsing respons HTML menggunakan BeautifulSoup
Setelah Anda mengunduh halaman web, Anda perlu mengurai HTML. Anda dapat melakukan ini menggunakan perpustakaan BeautifulSoup:
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, 'lxml)
Konstruktor BeautifulSoup mengambil dua argumen:
- HTML yang akan diurai
- Pengurai yang akan digunakan
Dalam hal ini kami menggunakan lxml Parser, lalu kita meneruskan respons HTML ke BeautifulSoup dan membuat sebuah instance bernama soup.
Saat halaman HTML diinisialisasi dalam instance BeautifulSoup, BS4 mengubah dokumen HTML menjadi pohon objek Python yang kompleks dan kemudian menyediakan beberapa cara untuk menanyakan pohon DOM ini:
- Atribut objek Python: Setiap objek BeautifulSoup memiliki sekumpulan atribut yang dapat digunakan untuk mengakses objek anak, induk, dan saudaranya. Misalnya saja ini Anak-anak Atribut mengembalikan daftar anak objek, dan induk Atribut mengembalikan induk objek.
- Metode Sup yang Indah (misalnya
.find()Dan.find_all()): Ini dapat digunakan untuk mencari elemen di pohon DOM yang cocok dengan kriteria tertentu..find()Metode mengembalikan elemen pertama yang cocok sementara.find_all()Metode mengembalikan daftar semua elemen yang cocok. - Pemilih CSS (misalnya
.select()Dan.select_one()): Pemilih CSS memungkinkan Anda memilih elemen berdasarkan kelas, ID, dan atribut lainnya.
Tapi tag mana yang harus Anda cari?
Anda dapat mengetahuinya dengan menggunakan opsi centang di browser Anda. Buka website Techcrunch, cari item yang ingin dikikis, klik kanan dan pilih “Memeriksa„.
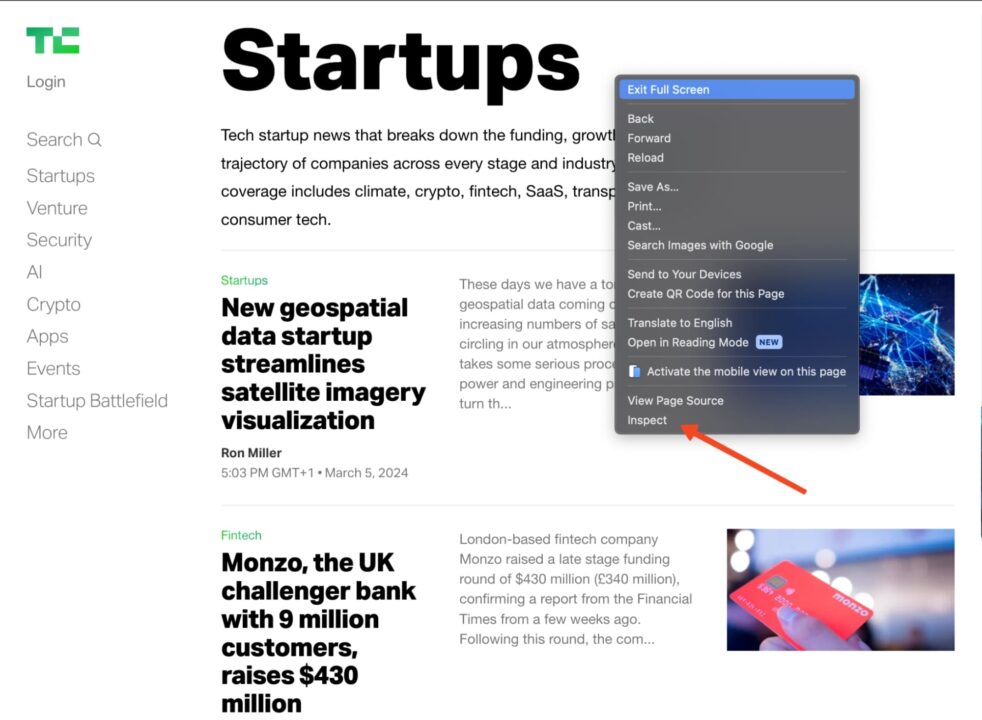
Ini akan membuka dokumen HTML pada item yang Anda pilih.
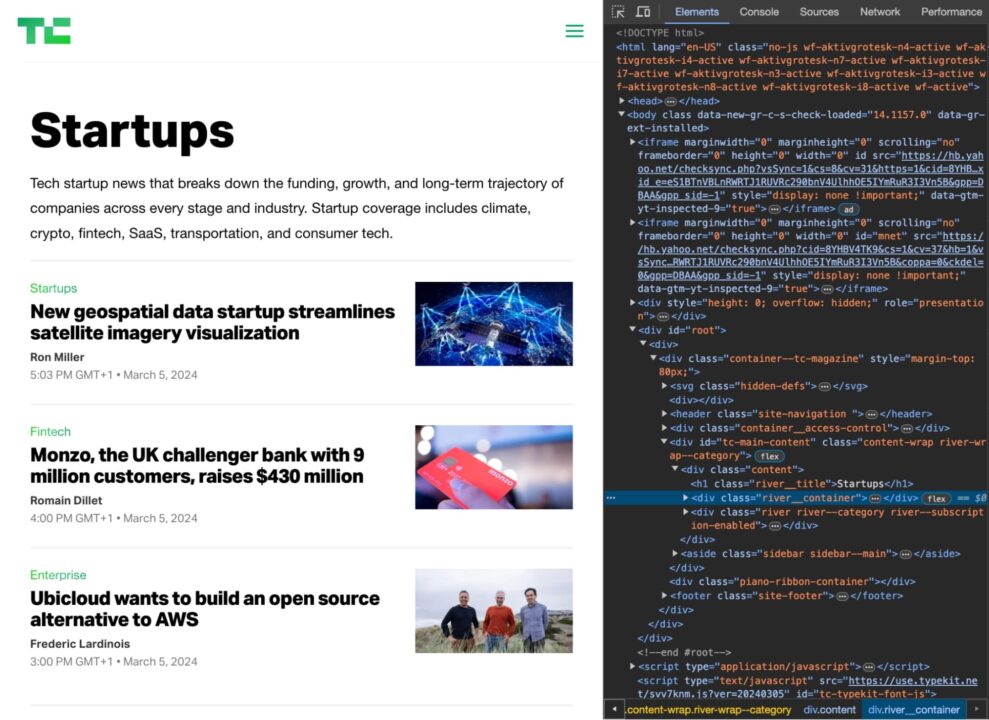
Sekarang Anda perlu menemukan kombinasi tag dan kelas elemen HTML yang secara unik mengidentifikasi elemen yang Anda perlukan.
Misalnya, jika Anda ingin mengikis judul artikel di beranda TechCrunch, Anda akan memeriksa HTML dan melihat bahwa semua judul disertakan. h2 Tag dengan kelas post-block__title.

Jadi Anda bisa menggunakan pemilih CSS berikut untuk memilih judul:
soup.select('h2.post-block__title')
Ini memberikan daftar semuanya h2 Tag dengan kelas post-block__title pada halaman judul artikel.
Dapatkan elemen dengan tag HTML
sintaksis: element_name
Anda dapat menggunakan... find() Dan find_all() Metode untuk menemukan elemen berdasarkan tag HTML-nya.
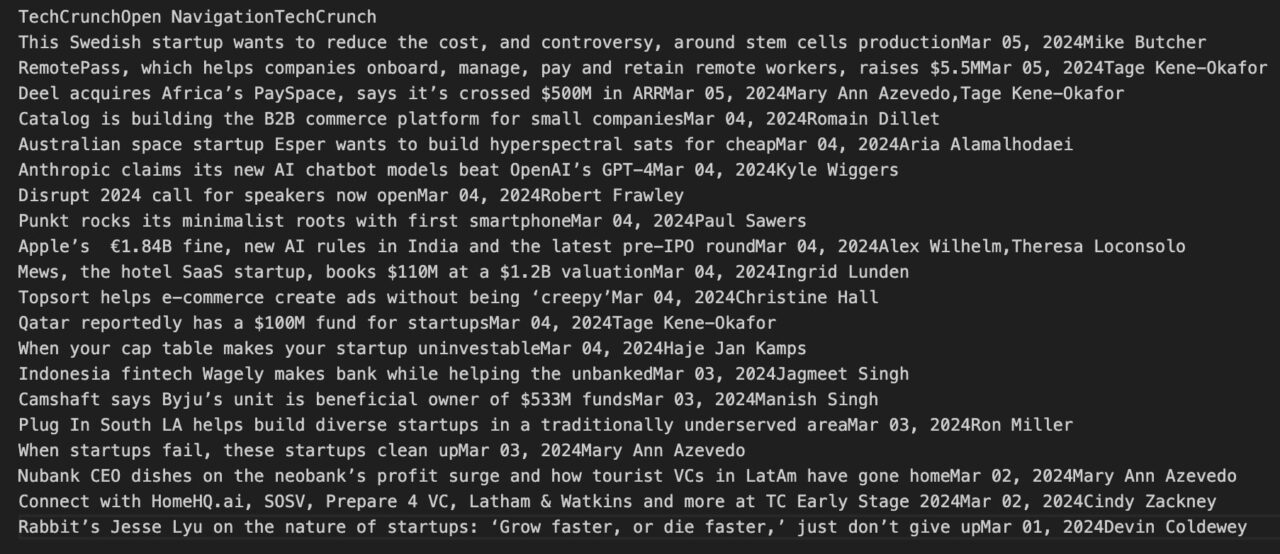
Misalnya, kode berikut menemukan semuanya header Tag di halaman:
header_tags = soup.find_all('header')
for header_tag in header_tags:
print(header_tag.get_text(strip=True))
Output di konsol akan terlihat seperti ini:
Dapatkan elemen berdasarkan kelas CSS
sintaksis: .class_name
Pemilih kelas mengurutkan elemen berdasarkan isinya class Atribut.
title = soup.select('.post-block__title__link')(0).text
print(title)
Titik (.) sebelum nama kelas memberitahu BS4 bahwa itu adalah kelas CSS.
Ambil elemen berdasarkan ID
sintaksis: #id_value
Pemilih ID mencocokkan elemen berdasarkan nilai elemen. id Atribut. Agar elemen dapat dipilih, elemen tersebut harus dipilih id Atribut harus sama persis dengan nilai yang ditentukan dalam pemilih.
element_by_id = soup.select('#element_id') # returns the element at "element_id"
print(element_by_id)
Simbol hash di depan nama ID memberitahu BS4 bahwa kita sedang mencari a id.
Mengambil elemen melalui penyeleksi atribut
sintaksis: (attribute=attribute_value) atau (attribute)
Pemilih atribut mencocokkan elemen berdasarkan keberadaan atau nilai atribut tertentu. Satu-satunya perbedaan adalah pemilih ini menggunakan tanda kurung siku () dan bukan titik (.). class atau simbol hash (#) sebagai id.
# Get the URL of the article
url = soup.select('.post-block__title__link')(0)('href')
print(url)
keluaran:
Mengambil item menggunakan XPath
XPath menggunakan sintaks seperti jalur untuk menemukan elemen dalam dokumen XML atau HTML. Ia bekerja seperti sistem file tradisional.
Untuk menemukan XPath untuk elemen tertentu pada halaman:
- Klik kanan elemen pada halaman dan klik “Memeriksa" untuk membuka tab Alat Pengembang.
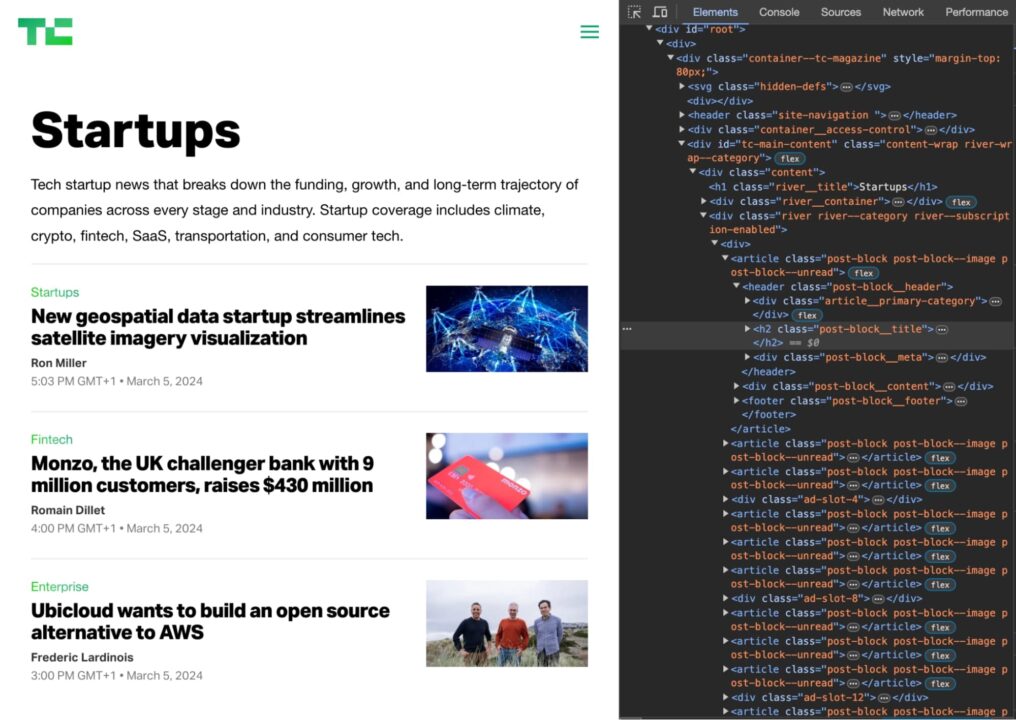
- Pilih item pada tab Item.

- Klik "Menyalin“ -> „Salin XPath„.
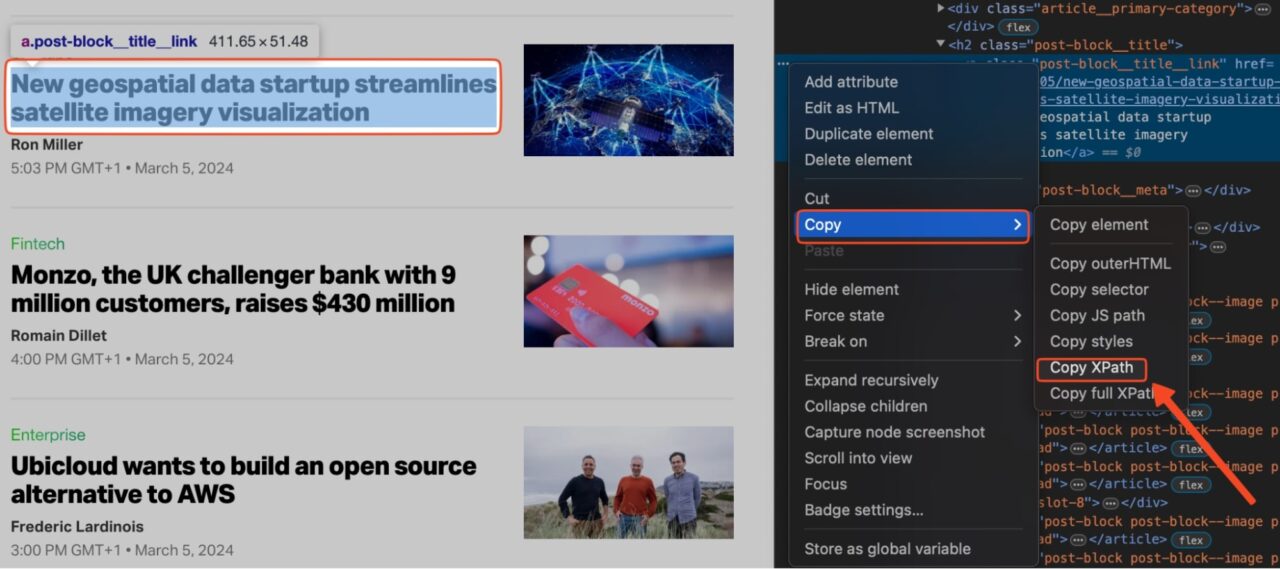
catatan: Jika XPath tidak memberikan hasil yang diinginkan, salin XPath lengkap, bukan hanya jalurnya. Langkah-langkah selanjutnya sama.
Sekarang kita dapat menjalankan kode berikut untuk mengekstrak artikel pertama di halaman tersebut XPath:
from bs4 import BeautifulSoup
import requests
from lxml import etree
url = 'https://techcrunch.com/category/startups/'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Accept-Language": "en-US, en;q=0.5",
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.content, "lxml")
dom = etree.HTML(str(soup))
print(dom.xpath('//*(@id="tc-main-content")/div/div(2)/div/article(1)/header/h2/a')(0).text)
Inilah hasilnya:
New geospatial data startup streamlines satellite imagery visualization
Permintaan dan contoh pengikisan BeautifulSoup
Mari gabungkan semua ini untuk mencari TechCrunch untuk daftar artikel startup:
import requests
from bs4 import BeautifulSoup
url = 'https://techcrunch.com/category/startups/'
article_list = ()
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.content, "lxml")
articles = soup.find_all('header')
for article in articles:
title = article.get_text(strip=True)
url = article.find('a')('href')
print(title)
print(url)
Kode ini mencetak judul dan URL setiap artikel startup.
Simpan data dalam file CSV
Setelah Anda mengekstrak data yang diinginkan dari halaman web, Anda dapat menyimpannya ke file CSV untuk analisis lebih lanjut. Untuk melakukan ini, gunakan csv Modul, tambahkan kode ini ke scraper Anda:
import requests
from bs4 import BeautifulSoup
import csv
url = 'https://techcrunch.com/category/startups/'
article_list = ()
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.content, "lxml")
articles = soup.find_all('header')
for article in articles:
title = article.get_text(strip=True)
url = article.find('a')('href')
article_list.append((title, url))
with open('startup_articles.csv', 'w', newline='') as f:
csvwriter = csv.writer(f)
csvwriter.writerow(('Title', 'URL'))
for article in article_list:
csvwriter.writerow(article)
Ini akan membuat file CSV bernama startup_artikel.csv dan tulis judul dan URL artikel ke file tersebut. Anda kemudian dapat melihat file CSV dalam program spreadsheet seperti Microsoft Excel atau Google Spreadsheet untuk analisis lebih lanjut.
Terus belajar
Selamat, Anda baru saja membuat situs web pertama Anda dengan Permintaan dan BeautifulSoup!
Ingin mempelajari lebih lanjut tentang web scraping? Kunjungi pusat pengikisan kami. Di sana Anda akan menemukan semua yang Anda butuhkan untuk menjadi seorang ahli.
Jika Anda siap menangani proyek nyata, ikuti tutorial lanjutan kami:
Teruslah menjelajah dan selamat menggores!