
Dalam tutorial ini, kita akan menggunakan Python untuk mengekstrak data produk dari situs Walmart. Kami akan menjelajahi berbagai cara untuk mengurai dan mengekstrak data yang Anda perlukan, dan mendiskusikan beberapa potensi tantangan yang terkait dengan web scraping.
Daftar Isi
Mengapa menghapus data produk Walmart?
Walmart menawarkan berbagai macam produk di toko online-nya, menjadikannya kandidat ideal untuk proyek web scraping. Dengan menggunakan teknik web scraping, Anda dapat mengotomatiskan pengumpulan data produk seperti harga, ketersediaan, gambar, deskripsi, peringkat, ulasan, dan lainnya. Anda kemudian dapat menggunakan data ini dalam aplikasi atau proyek analisis Anda.
Pengantar Pengikisan Walmart
Untuk mengekstrak data produk, Anda harus menganalisisnya terlebih dahulu. Mari kita lihat halaman produk - semuanya memiliki tipe yang sama, dan setelah menganalisisnya, Anda dapat mengekstrak data web yang Anda perlukan menggunakan skrip tertulis.
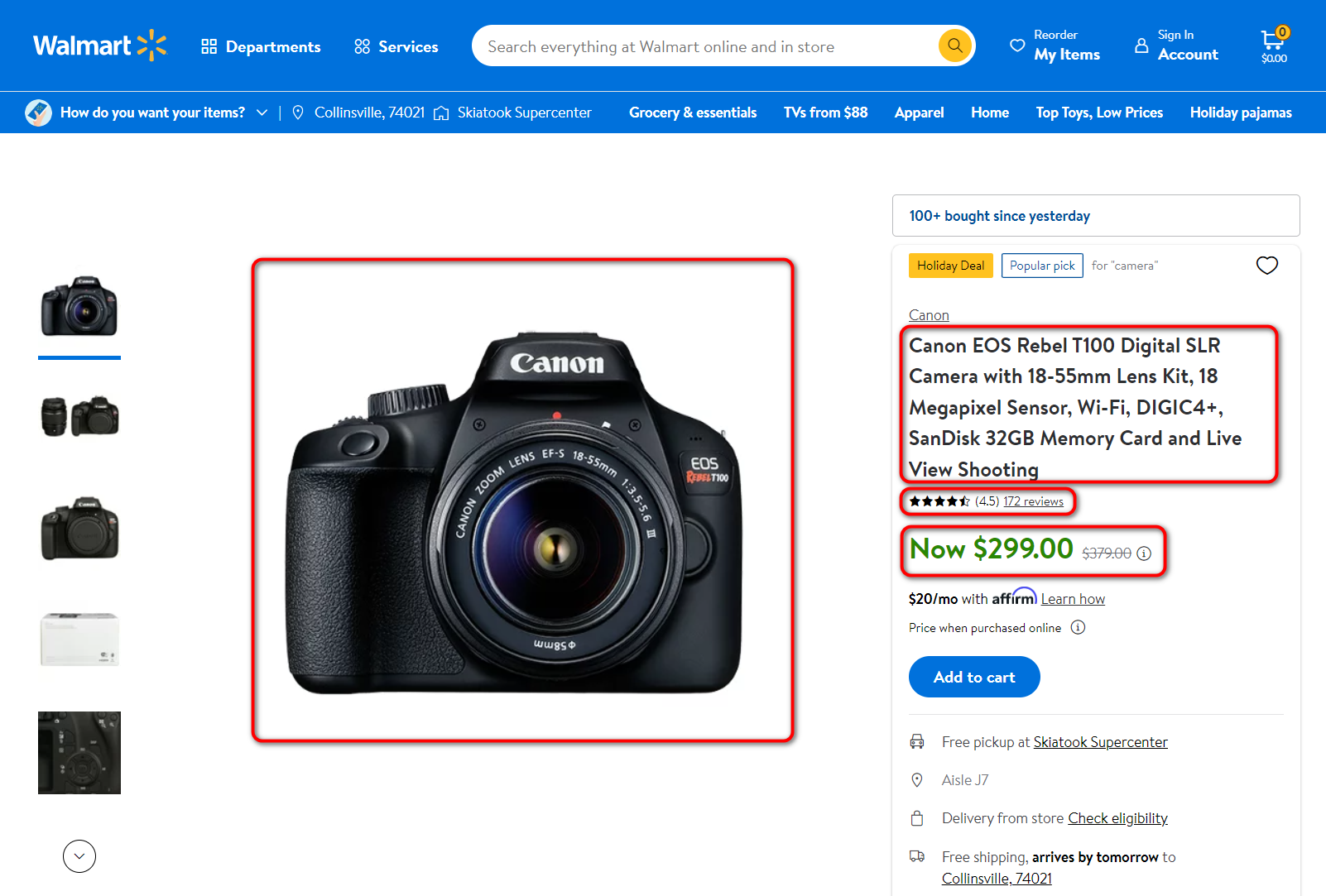
Kami tertarik pada area pengikisan berikut:
- Nama Produk
- Harga produk
- Jumlah ulasan
- Evaluasi
- Gambar utama
Tentu saja, Anda mungkin memerlukan bidang lain dengan data lain untuk tujuan tertentu seperti deskripsi atau merek, namun kami hanya akan mempertimbangkan data produk utama dalam contoh ini. Detail lainnya dapat diekstraksi dengan cara yang sama. Sebagai contoh, mari kita buat scraper yang mengumpulkan link dari file CSV, mengikuti setiap link, dan menyimpan data yang dihasilkan ke file lain. Baca juga tentang itu cURL ke Python.
Anda juga dapat mengumpulkan URL produk dari halaman dan kategori menggunakan skrip untuk mengumpulkan semua produk. Namun, kami tidak akan membahasnya dalam panduan ini. Kami sebelumnya menerbitkan artikel tentang mengambil data dari Amazon dan memeriksa cara mengatur transisi ke halaman hasil pencarian dan mengumpulkan semua tautan produk. Hal serupa dapat dilakukan untuk Walmart.
Mengekstraksi data cukup bermasalah di Walmart, karena perusahaan tidak mendukung pengikisan produk dan memiliki sistem anti-spam. Melacak dan memblokir alamat IP kemungkinan akan memblokir sebagian besar pengikis yang mencoba mengakses situs web Anda. Oleh karena itu, sebelum kita membuat scraper Walmart dengan Python, perhatikan bahwa saat menulis scraper Anda sendiri, Anda juga harus berhati-hati dalam melewati blok.
Jika tidak ada kesempatan atau waktu untuk mengatur sistem bypass kunci, Anda dapat mengikis data menggunakan API web scraping, yang memecahkan masalah ini. Anda dapat mengetahui lebih lanjut tentang cara mencari Walmart menggunakan API kami di akhir artikel.
Menginstal perpustakaan Python untuk scraping
Sebelum kita mencari item untuk dikikis, mari buat file Python dan tambahkan perpustakaan yang diperlukan. Kami akan menggunakan:
- Pustaka Permintaan untuk menjalankan permintaan.
- Pustaka BeautifulSoup untuk menyederhanakan penguraian halaman web.
Jika Anda tidak memiliki perpustakaan BeautifulSoup (perpustakaan permintaan sudah ada di dalamnya), gunakan perintah berikut pada baris perintah:
pip install beautifulsoup4Masukkan perpustakaan ini ke dalam file Python:
from bs4 import BeautifulSoup
import requestsMari kita membuat atau menghapus (menimpa) file tempat kita menyimpan data Walmart. Beri nama file ini result.csv dan tentukan kolom di dalamnya:
with open("result.csv", "w") as f:
f.write("title; price; rating; reviews; image\n")Selanjutnya buka file links.csv yang menyimpan link ke halaman produk yang kita telusuri. Kami akan membahas semuanya secara berurutan dan melakukan pemrosesan data untuk masing-masingnya. Kode berikut akan melakukannya:
with open("links.csv", "r+") as links:
for link in links:Sekarang kita mendapatkan semua kode halaman yang akan terus kita kerjakan dan menganalisisnya menggunakan BeautifulSoup:
html_text = requests.get(link).text
soup = BeautifulSoup(html_text, 'lxml')Pada titik ini kita sudah memiliki kode halaman produk dan dapat menampilkannya menggunakan, misalnya, print(soup).
Cara 1. Analisis teks halaman
Untuk memilih hanya informasi yang diperlukan, kami menganalisis halaman untuk menemukan penyeleksi dan atribut yang menggambarkan data penting dengan jelas.
Mari buka situs web Walmart dan lihat halaman produk lagi. Yuk cari judul produknya dulu. Untuk melakukan ini, buka DevTools (F12) dan temukan kode item (Ctrl + Shift + C dan pilih item):
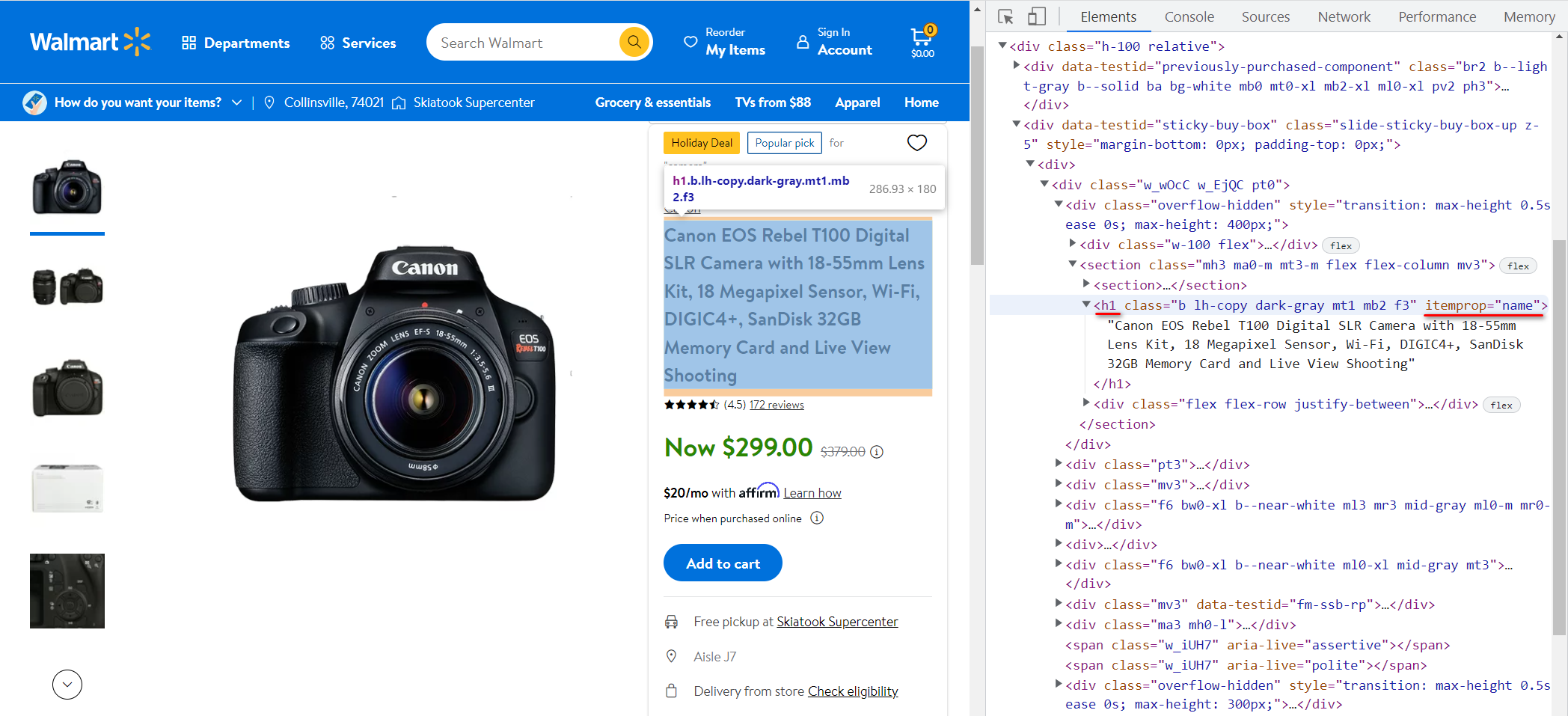
Dalam hal ini berada di <h1> Tag dan atribut itempropnya memiliki nilai “name“. Mari masukkan nilai teks yang disimpan dalam tag ini ke dalam variabel judul:
title = soup.find('h1', attrs={'itemprop': 'name'}).textMari kita lakukan hal yang sama, tapi sekarang untuk harganya:
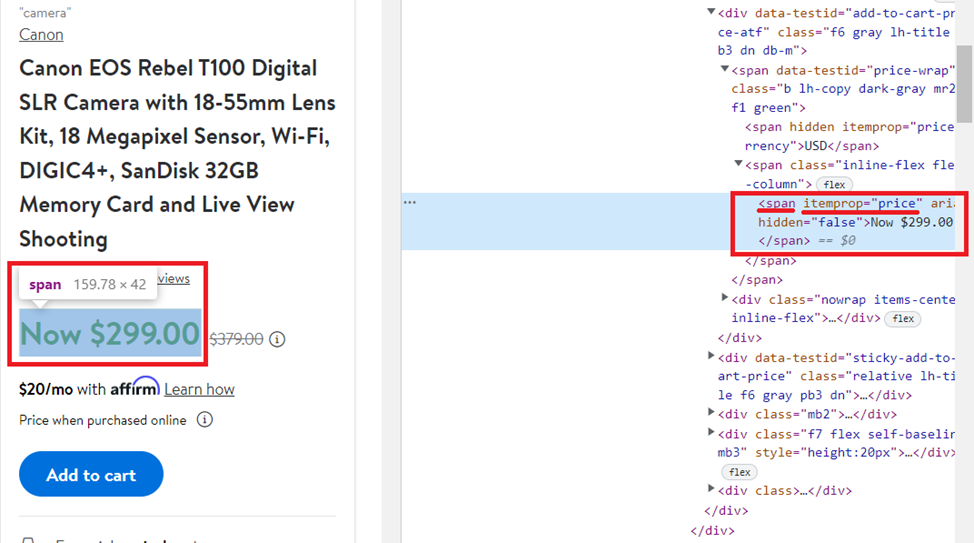
Dapatkan kontennya <span> Tag dengan nilai atribut itemprop sama dengan “price„:
price = soup.find('span', attrs={'itemprop': 'price'}).textUntuk verifikasi dan evaluasi, analisis dilakukan dengan cara yang sama, maka kita tuliskan hasil akhirnya:
reviews = soup.find('a', attrs={'itemprop': 'ratingCount'}).text
rating = soup.find('span', attrs={'class': 'rating-number'}).textSemuanya sedikit berbeda dalam gambar. Mari kita lihat halaman produk dan kode item:
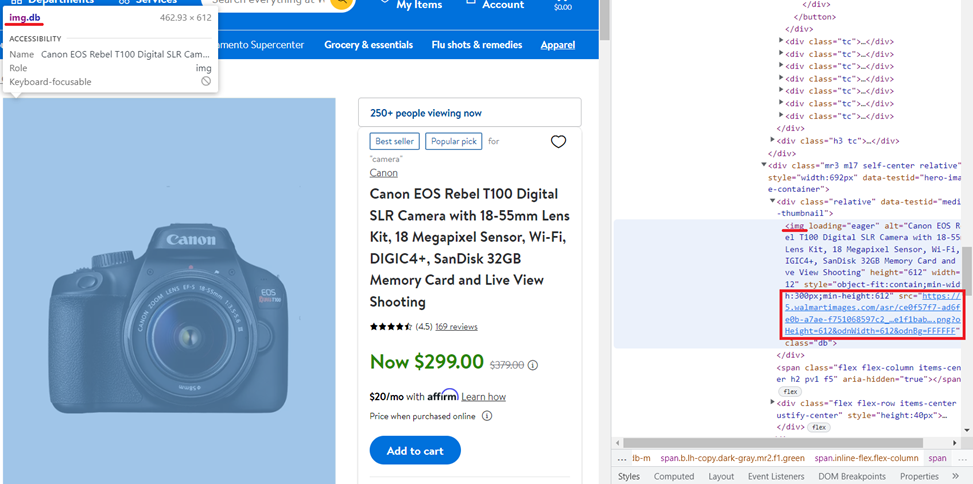
Kali ini Anda perlu mendapatkan nilai atribut src yang disimpan di file <img> hari dengan “db“Atribut kelas dan muatan sama”eager“. Berkat perpustakaan BeautifulSoup, ini menjadi mudah:
image = soup.find('img', attrs={'class': 'db','loading': 'eager'})("src")Kita harus ingat bahwa dalam kasus ini tidak setiap halaman akan mengembalikan gambar tersebut. Oleh karena itu, lebih baik menggunakan informasi dari meta tag:
image = soup.find('meta', property="og:image")("content")Jika kita mulai dengan variabel di atas, kita mendapatkan detail produk berikut:
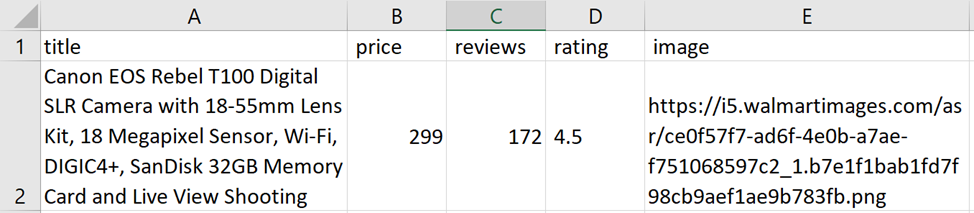
Canon EOS Rebel T100 Digital SLR Camera with 18-55mm Lens Kit, 18 Megapixel Sensor, Wi-Fi, DIGIC4+, SanDisk 32GB Memory Card and Live View Shooting
Now $299.00
172 reviews
(4.5)
https://i5.walmartimages.com/asr/ce0f57f7-ad6f-4e0b-a7ae-f751068597c2_1.b7e1f1bab1fd7f98cb9aef1ae9b783fb.pngMari simpan data yang diterima ke file yang dibuat/dihapus sebelumnya:
try:
with open("result.csv", "a") as f:
f.write(str(title)+"; "+str(price)+"; "+str(reviews)+"; "+str(rating)+"; "+str(image)+"\n")
except Exception as e:
print("There is no data")Disarankan untuk melakukan ini di blok try…exclusive, karena jika tidak ada data atau tautan tidak ditentukan dengan benar, eksekusi program akan terganggu. Anda dapat menggunakan blok try…exclusive untuk “menangkap” kesalahan tersebut, melaporkannya, dan melanjutkan program.
Saat Anda menjalankan program ini, data yang tergores akan disimpan dalam file result.csv:

Di sini kita melihat beberapa masalah. Pertama, ada teks tambahan pada kolom Harga, Review, dan Rating. Kedua, jika ada diskon, kolom harga bisa saja menampilkan informasi yang salah atau dua harga.
Tentu saja, membiarkan ekspresi reguler hanya pada nilai numerik tidak menjadi masalah, tetapi mengapa mempersulit tugas jika ada cara yang lebih mudah?
Cara 2. Parsing data terstruktur JSON-LD
Jika Anda melihat lebih dekat pada kode halaman, Anda akan melihat bahwa semua informasi yang diperlukan disimpan tidak hanya di badan halaman. Mari kita perhatikan <head>…</head> hari, lebih tepatnya miliknya <script nonce type="application/ld+json">…</script> Label.
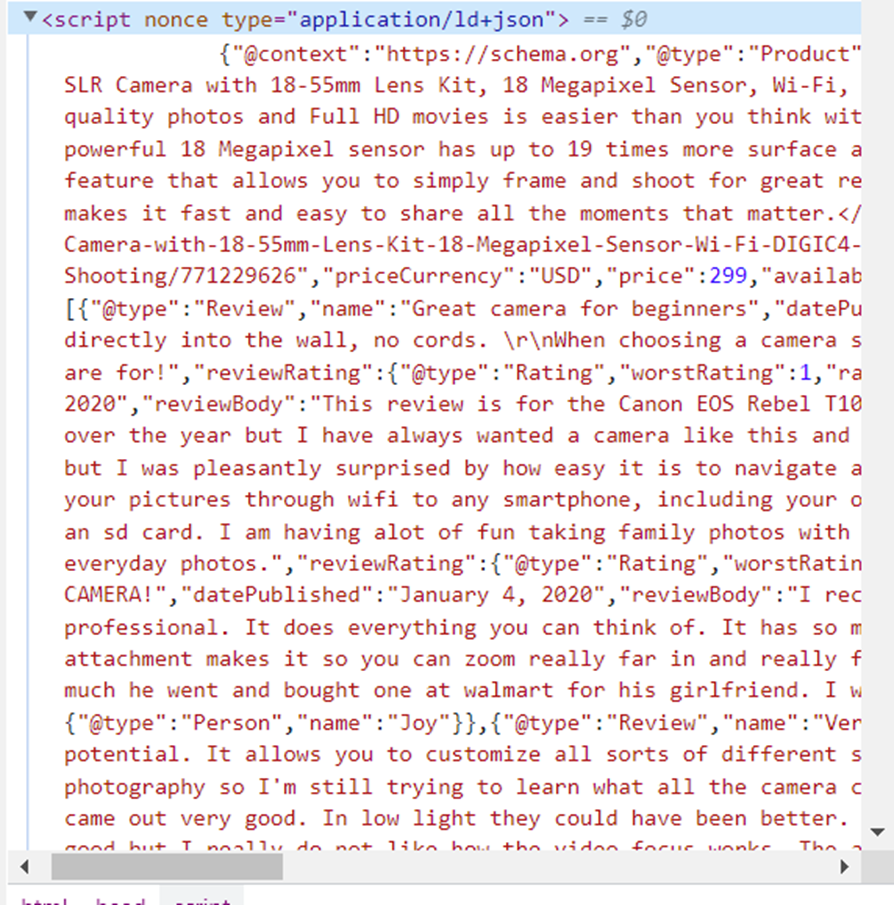
Ini adalah markup skema Produk dalam format JSON. Skema produk memungkinkan atribut produk tertentu ditambahkan ke daftar produk yang dapat ditampilkan sebagai hasil kaya di halaman hasil mesin pencari (SERP). Mari kita salin dan format ke dalam bentuk yang nyaman untuk penelitian:
{ "@context": "https://schema.org", "@type": "Produk", "image": "https://i5.walmartimages.com/asr/ce0f57f7-ad6f-4e0b-a7ae- f751068597c2_1.b7e1f1bab1fd7f98cb9aef1ae9b783fb.png", "name": "Kamera SLR Digital Canon EOS Rebel T100 dengan Kit Lensa 18-55mm, Sensor 18 Megapiksel, Wi-Fi, DIGIC4+, Kartu Memori SanDisk 32GB dan Pemotretan Live View", "sku": "771229626", "gtin13": "013803300550", "deskripsi": "<p>Membuat cerita khas dengan foto berkualitas DSLR dan film Full HD lebih mudah dari yang Anda kira dengan Canon EOS Rebel T100 18 Megapiksel. Bagikan secara instan dan potret dari jarak jauh melalui ponsel cerdas Anda yang kompatibel dengan Wi-Fi dan aplikasi Canon Camera Connect. Sensor 18 Megapiksel yang kuat memiliki luas permukaan hingga 19 kali lebih luas dibandingkan kebanyakan ponsel cerdas, dan Anda dapat langsung mentransfer foto dan film ke perangkat pintar Anda. Canon EOS Rebel T100 memiliki fitur Scene Intelligent Auto yang memungkinkan Anda membingkai dan memotret dengan mudah untuk hasil yang luar biasa. Ia juga dilengkapi pemotretan Guided Live View dengan mode Creative Auto, dan Anda dapat menambahkan hasil akhir yang unik dengan Creative Filters. Canon EOS Rebel T100 menjadikannya cepat dan mudah untuk berbagi semua momen penting.</p>", "model": "T100", "merek": { "@type": "Merek", "nama": "Canon" }, "penawaran": { "@type": "Penawaran", "url" : "https://www.walmart.com/ip/Canon-EOS-Rebel-T100-Digital-SLR-Camera-with-18-55mm-Lens-Kit-18-Megapixel-Sensor-Wi-Fi-DIGIC4- SanDisk-32GB-Memory-Card-and-Live-View-Shooting/771229626", "priceCurrency": "USD", "price": 299, "availability": "https://schema.org/InStock", " itemCondition": "https://schema.org/NewCondition", "availableDeliveryMethod": "https://schema.org/OnSitePickup" }, "review": ( { "@type": "Review", "name" : "Kamera bagus untuk pemula", "datePublished": "4 Januari 2020", "reviewBody": "Suka kamera ini....", "reviewRating": { "@type": "Rating", "worstRating" : 1, "ratingValue": 5, "bestRating": 5 }, "penulis": { "@type": "Orang", "nama": "Sparkles" } }, { "@type": "Ulasan", "name": "Sempurna untuk pemula", "datePublished": "7 Januari 2020", "reviewBody": "Saya sangat jatuh cinta dengan kamera ini!...", "reviewRating": { "@type": "Rating", "worstRating": 1, "ratingValue": 5, "bestRating": 5 }, "author": { "@type": "Orang", "name": "Brazilchick32" } }, { "@ type": "Review", "name": "Kamera hebat", "datePublished": "17 Januari 2020", "reviewBody": "Saya sangat menyukai semua fitur yang dimiliki kamera ini. Setiap kali saya menggunakannya, saya menemukan yang baru. Saya cukup tertantang secara teknologi, namun hal ini tidak menghalangi saya. Zoom dan fokus memberikan gambar yang sangat detail dan tajam. Saya tidak sabar untuk membawanya pada perjalanan saya berikutnya karena saat ini saya baru memotret anjing itu jutaan kali", "reviewRating": { "@type": "Rating", "worstRating": 1, "ratingValue": 5 , "bestRating": 5 }, "penulis": { "@type": "Orang", "nama": "ramah pengguna" } } ), "aggregateRating": { "@type": "AggregateRating", "ratingValue" : 4.5, "peringkat terbaik": 5, "jumlah ulasan": 172 } }Sekarang jelas bahwa informasi ini sudah cukup dan disimpan dalam bentuk yang lebih nyaman. Artinya, perlu untuk membaca isi dari <head>…</head> Tandai dan pilih tag yang menyimpan data di JSON. Kemudian atur variabel ke nilai berikut:
-
nilai judul dari
(name)Atribut. -
Nilai murah dari
(offers)(price)Atribut. -
Ulasan nilai
(aggregateRating)(reviewCount)Atribut. -
Nilai peringkat dari
(aggregateRating)(ratingValue)Atribut. -
Nilai gambar dari
(image)Atribut.
Untuk dapat bekerja dengan JSON, cukup menyertakan perpustakaan terintegrasi:
import jsonMari buat variabel data yang akan kita masukkan data JSON:
data = (json.loads(soup.find('script', attrs={'type': 'application/ld+json'}).text))Setelah itu, kita memasukkan data ke dalam variabel yang sesuai:
title = data('name')
price = data('offers')('price')
reviews = data('aggregateRating')('reviewCount')
rating = data('aggregateRating')('ratingValue')
image = data('image')Sisanya tetap sama. Periksa eksekusi skrip:
Skrip lengkap:
from bs4 import BeautifulSoup
import requests
import json
with open("result.csv", "w") as f:
f.write("title; price; rating; reviews; image\n")
with open("links.csv", "r+") as links:
for link in links:
html_text = requests.get(link).text
soup = BeautifulSoup(html_text, 'lxml')
data = (json.loads(soup.find('script', attrs={'type': 'application/ld+json'}).text))
title = data('name')
price = data('offers')('price')
reviews = data('aggregateRating')('reviewCount')
rating = data('aggregateRating')('ratingValue')
image = data('image')
try:
with open("result.csv", "a") as f:
f.write(str(title)+"; "+str(price)+"; "+str(reviews)+"; "+str(rating)+"; "+str(image)+"\n")
except Exception as e:
print("There is no data")Perlindungan Anti-Bot Walmart
Namun, seperti yang disebutkan di awal artikel, layanan memantau aktivitas yang terlihat seperti bot, memblokirnya, dan menawarkan untuk memecahkan captcha. Jadi, alih-alih mendapatkan halaman berisi data, halaman lain akan ditampilkan:

Ini adalah saran untuk mengatasi captcha. Untuk menghindari hal ini, Anda harus mematuhi ketentuan yang dijelaskan sebelumnya.
Anda juga dapat menambahkan header ke kode, yang akan sedikit mengurangi kemungkinan pemblokiran:
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36"}Kemudian permintaannya terlihat sedikit berbeda:
html_text = requests.get(link, headers=headers).textHasil pengeriknya:
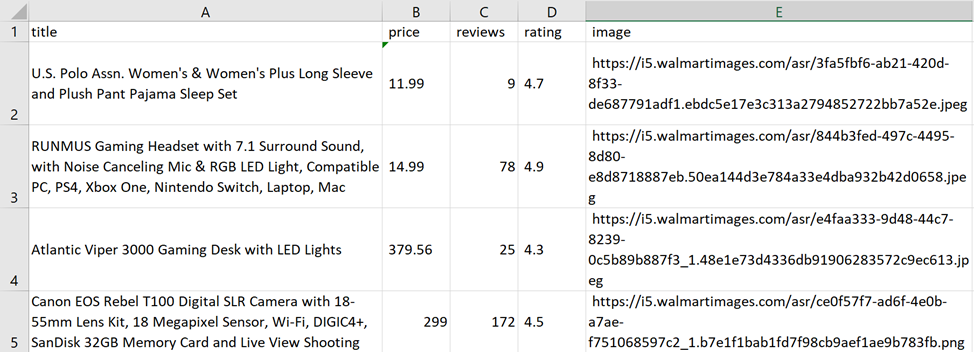
Sayangnya, hal ini tidak selalu membantu menghindari penyumbatan. Di sinilah API web scraping berperan.
Kikis data produk Walmart menggunakan Web Scraping API
Mari kita lihat kasus penggunaan API web scraping yang menangani penghindaran pemblokiran. Bagian dari skrip yang dijelaskan sebelumnya tidak akan berubah. Kami hanya akan mengubahnya.
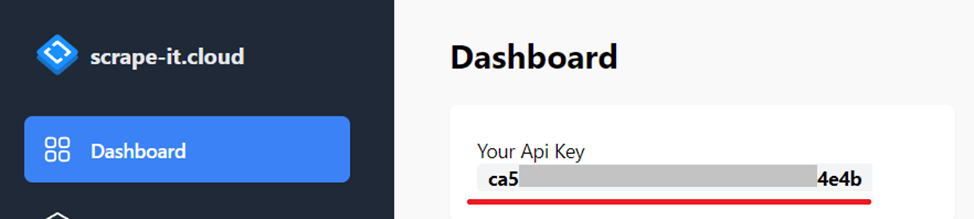
Buat akun scrape-it.cloud. Setelah itu Anda akan menerima 1.000 kredit. Anda memerlukan kunci API, yang dapat Anda temukan di akun Anda di bagian dasbor:
Kita juga memerlukan perpustakaan JSON, jadi mari tambahkan ke proyek:
import jsonSekarang kita menetapkan nilai API ke variabel URL dan menambahkan kunci API dan tipe konten di header:
url = "https://api.scrape-it.cloud/scrape"
headers = {
'x-api-key': 'YOUR-API-KEY',
'Content-Type': 'application/json'
}Untuk menambahkan kueri dinamis:
temp = """{
"url": """+"\""+str(link)+"\""+""",
"block_resources": False,
"wait": 0,
"screenshot": True,
"proxy_country": "US",
"proxy_type": "datacenter"
}"""
payload = json.dumps(temp)
response = requests.request("POST", url, headers=headers, data=payload)Ambil data dalam “konten” yang menyimpan kode halaman Walmart:
html_text = json.loads(response.text)("scrapingResult")("content")Mari kita lihat kode lengkapnya:
from bs4 import BeautifulSoup
import requests
import json
url = "https://api.scrape-it.cloud/scrape"
headers = {
'x-api-key': 'YOUR-API-KEY',
'Content-Type': 'application/json'
}
with open("result.csv", "w") as f:
f.write("title; price; rating; reviews; image\n")
with open("links.csv", "r+") as links:
for link in links:
html_text = requests.get(link).text
soup = BeautifulSoup(html_text, 'lxml')
data = (json.loads(soup.find('script', attrs={'type': 'application/ld+json'}).text))
title = data('name')
price = data('offers')('price')
reviews = data('aggregateRating')('reviewCount')
rating = data('aggregateRating')('ratingValue')
image = data('image')
try:
with open("result.csv", "a") as f:
f.write(str(title)+"; "+str(price)+"; "+str(reviews)+"; "+str(rating)+"; "+str(image)+"\n")
except Exception as e:
print("There is no data")Selain atribut yang ditentukan, atribut lain dapat ditentukan di isi permintaan. Cari tahu lebih lanjut di dokumentasi Atau cobalah di bawah tab Web Scraping API di akun Anda.
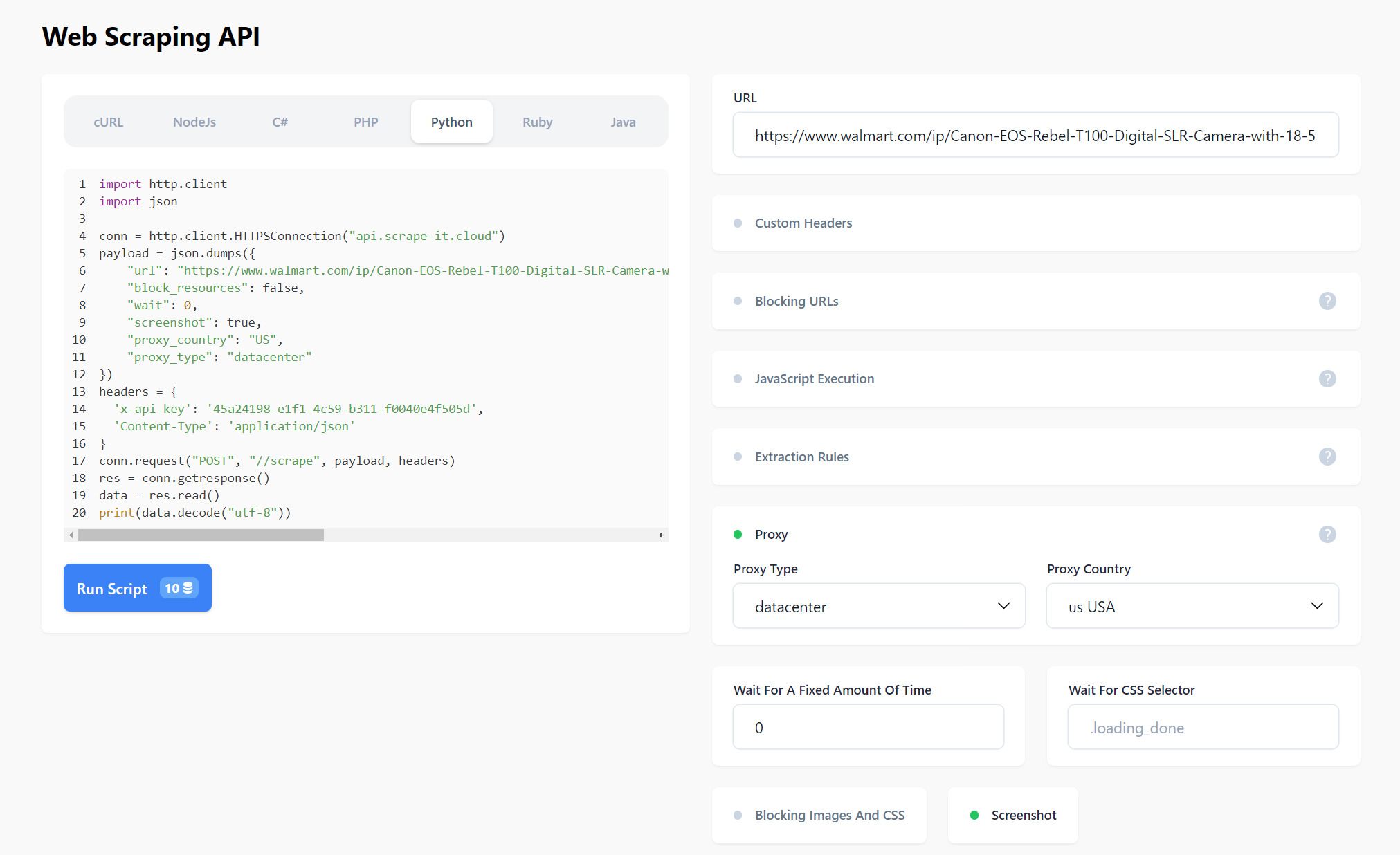
Anda dapat membuat permintaan secara visual dan kemudian menerima kode dalam salah satu bahasa pemrograman yang didukung.
Kesimpulan dan temuan
Menemukan dan mengambil data untuk eCommerce adalah tugas yang memakan waktu, terutama jika dilakukan secara manual. Sulit juga untuk mengetahui apakah data tersebut akurat dan objektif yang akan membantu Anda mengambil keputusan bisnis yang tepat.
Tanpa data berkualitas tinggi, sulit untuk mengembangkan dan menerapkan strategi pemasaran yang dibutuhkan bisnis Anda untuk tumbuh, sukses, dan memenuhi kebutuhan pelanggan. Hal ini juga dapat memengaruhi reputasi Anda karena Anda mungkin dianggap tidak dapat diandalkan jika pelanggan atau mitra Anda menganggap data Anda tidak dapat diandalkan.
Mengikis data produk Walmart dengan Python adalah cara terbaik untuk mengumpulkan informasi berharga dalam jumlah besar dengan cepat tentang produk yang tersedia di situs. Dengan menggunakan perpustakaan canggih seperti Beautiful Soup dan Selenium bersama dengan kueri atau regex XPath, pengembang dapat dengan mudah mengekstrak informasi spesifik dari halaman web mana pun yang mereka inginkan dan mengubahnya menjadi kumpulan data terstruktur yang dapat mereka gunakan dalam aplikasi atau proyek analisis mereka. Dan ketika Anda menggunakan web scraping API untuk mengotomatiskan proses pengumpulan data, Anda tidak perlu khawatir tentang pemblokiran, captcha, proksi, penggunaan header, dan banyak lagi.