
TL;DR: Verwenden von Requests und BeautifulSoup für Web Scraping
Installieren Sie zunächst beide Abhängigkeiten von Ihrem Terminal mit dem folgenden Befehl:
pip install requests beautifulsoup4Sobald die Installation abgeschlossen ist, importieren Sie
requestsUndBeautifulSoupzu Ihrer Datei:import requests from bs4 import BeautifulSoupSende ein
get()Anfrage mit Requests, um den HTML-Inhalt Ihrer Zielseite herunterzuladen und in einer Variable zu speichern – für dieses Beispiel senden wir eineget()Anfrage an BooksToScrape und Speicherung des HTML in einemresponseVariable:response = requests.get(“https://books.toscrape.com/catalogue/page-1.html”)Um bestimmte Datenpunkte aus dem HTML zu extrahieren, müssen wir die Antwort mit BS4 analysieren:
soup = BeautifulSoup(response.content, "lxml")Schließlich können wir Elemente mithilfe von CSS-Selektoren oder HTML-Tags wie folgt auswählen:
title = soup.find(“h1”) print(title)
Das Internet bietet eine unglaubliche Datenmenge und ist eine wertvolle Ressource für jedes Forschungsgebiet oder persönliches Interesse. Allerdings sind nicht alle diese Informationen auf herkömmliche Weise leicht zugänglich.
Einige Websites stellen keine API zum Abrufen ihrer Inhalte bereit; andere verwenden möglicherweise komplexe Technologien, die das Extrahieren von Daten mit herkömmlichen Methoden erschweren.
Um Ihnen den Einstieg zu erleichtern, zeigen wir Ihnen in diesem Tutorial, wie Sie mit den Python-Paketen „Requests“ und „BeautifulSoup“ Daten von beliebigen Websites extrahieren. Dabei werden die Grundlagen des Web Scraping behandelt, darunter das Senden von HTTP-Anfragen, das Parsen von HTML und das Extrahieren spezifischer Informationen.
Um die Dinge praktischer zu gestalten, lernen wir, wie man einen Scraper erstellt, um eine Liste mit technischen Artikeln von Techcrunch zu sammeln. Am Ende haben Sie gelernt, wie Sie:
- Webseiten herunterladen
- HTML-Inhalt analysieren
- Extrahieren Sie Daten mit den Methoden und CSS-Selektoren von BeautifulSoup
Voraussetzungen
Um diesem Tutorial zu folgen, müssen Sie installieren Python 3.7 oder höher auf Ihrem Computer. Sie können es von der offiziellen Website herunterladen, wenn Sie es nicht installiert haben.
Sie benötigen außerdem die folgenden Voraussetzungen:
Installieren einer virtuellen Umgebung
Es wird empfohlen, vor der Installation der erforderlichen Bibliotheken eine virtuelle Umgebung zu erstellen, um die Abhängigkeiten des Projekts zu isolieren.
Erstellen einer virtuellen Umgebung unter Windows
Öffnen Sie eine Eingabeaufforderung mit Administratorrechten und führen Sie den folgenden Befehl aus, um eine neue virtuelle Umgebung mit dem Namen zu erstellen venv:
Aktivieren Sie die virtuelle Umgebung mit dem folgenden Befehl:
Erstellen einer virtuellen Umgebung unter macOS/Linux
Öffnen Sie ein Terminal und führen Sie den folgenden Befehl aus, um eine neue virtuelle Umgebung mit dem Namen zu erstellen venv:
sudo python3 -m venv venv
Aktivieren Sie die virtuelle Umgebung:
Installieren von Requests, BeautifulSoup und Lxml
Nachdem Sie eine virtuelle Umgebung erstellt und aktiviert haben, können Sie die erforderlichen Bibliotheken installieren, indem Sie den folgenden Befehl auf Ihrem Terminal ausführen:
pip install requests beautifulsoup4 lxml
- Requests ist eine HTTP-Bibliothek für Python, die das Senden von HTTP-Anfragen und die Verarbeitung von Antworten vereinfacht.
- BeautifulSoup ist eine Bibliothek zum Parsen von HTML- und XML-Dokumenten.
- Lxml ist ein leistungsstarker und schneller XML- und HTML-Parser, der in C geschrieben ist. Lxml wird von BeautifulSoup verwendet, um XPath-Unterstützung bereitzustellen.
Laden Sie die Webseite mit Anfragen herunter
Der erste Schritt beim Scraping von Webdaten ist das Herunterladen der Webseite, die Sie scrapen möchten. Sie können dies mithilfe des get() Methode der Requests-Bibliothek.
import requests
url = 'https://techcrunch.com/category/startups/'
response = requests.get(url)
print(response.text)
Oben verwenden wir Requests, um die HTML-Antwort von TechCrunch zu erhalten. get() Methode gibt einen response Objekt, das das HTML der Webseite enthält. Wir verwenden BeautifulSoup, um die benötigten Daten aus dieser HTML-Antwort zu extrahieren.
Analysieren Sie die HTML-Antwort mit BeautifulSoup
Nachdem Sie die Webseite heruntergeladen haben, müssen Sie das HTML analysieren. Sie können dies mit der Bibliothek BeautifulSoup tun:
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, 'lxml)
Der BeautifulSoup-Konstruktor verwendet zwei Argumente:
- Das zu analysierende HTML
- Der zu verwendende Parser
In diesem Fall verwenden wir die lxml Parser, dann übergeben wir die HTML-Antwort an BeautifulSoup und erstellen eine Instanz namens soup.
Navigieren Sie mit BeautifulSoup durch die Antwort
Wenn eine HTML-Seite innerhalb einer BeautifulSoup-Instanz initialisiert wird, wandelt BS4 das HTML-Dokument in einen komplexen Baum aus Python-Objekten um und bietet dann mehrere Möglichkeiten, wie wir diesen DOM-Baum abfragen können:
- Python-Objektattribute: Jedes BeautifulSoup-Objekt verfügt über eine Reihe von Attributen, die zum Zugriff auf seine untergeordneten, übergeordneten und gleichgeordneten Objekte verwendet werden können. Beispielsweise das Kinder Attribut gibt eine Liste der untergeordneten Objekte des Objekts zurück, und das Elternteil Attribut gibt das übergeordnete Objekt des Objekts zurück.
- BeautifulSoup-Methoden ( z.B
.find()Und.find_all()): Diese können verwendet werden, um den DOM-Baum nach Elementen zu durchsuchen, die einem bestimmten Kriterium entsprechen..find()Methode gibt das erste passende Element zurück, während die.find_all()Methode gibt eine Liste aller übereinstimmenden Elemente zurück. - CSS-Selektoren (z.B
.select()Und.select_one()): Mit CSS-Selektoren können Sie Elemente basierend auf ihrer Klasse, ID und anderen Attributen auswählen.
Aber nach welchen Tags sollten Sie suchen?
Sie können dies herausfinden, indem Sie die Prüfoption in Ihrem Browser verwenden. Gehen Sie auf die Techcrunch-Website, suchen Sie das Element, das Sie scrapen möchten, klicken Sie mit der rechten Maustaste und wählen Sie „Prüfen„.
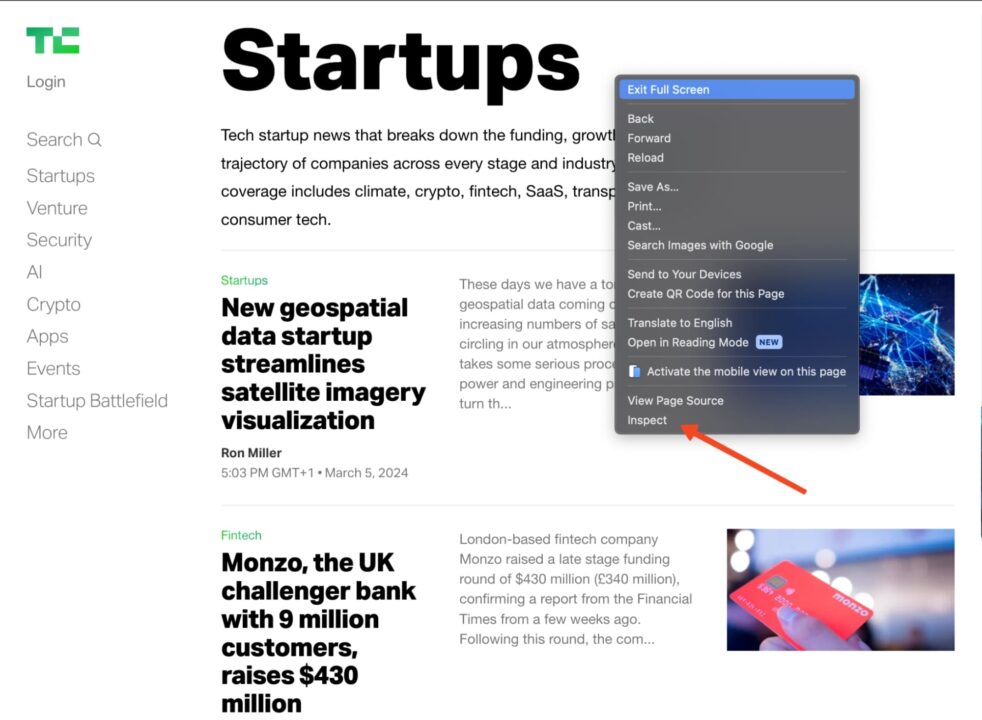
Dadurch wird das HTML-Dokument bei dem von Ihnen ausgewählten Element geöffnet.
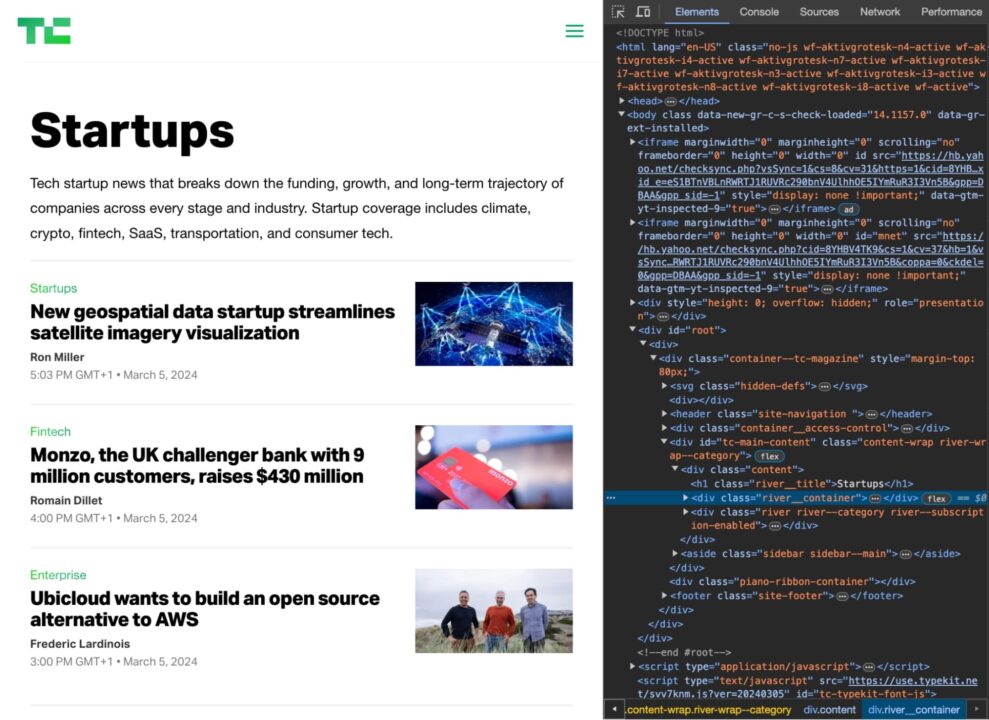
Jetzt müssen Sie eine Kombination aus HTML-Element-Tags und -Klassen finden, die die benötigten Elemente eindeutig identifizieren.
Wenn Sie beispielsweise die Titel der Artikel auf der TechCrunch-Homepage scrapen möchten, würden Sie das HTML untersuchen und feststellen, dass die Titel alle enthalten sind in h2 Tags mit der Klasse post-block__title.

Sie können zum Auswählen der Titel also den folgenden CSS-Selektor verwenden:
soup.select('h2.post-block__title')
Dies gibt eine Liste aller h2 Tags mit der Klasse post-block__title auf der Seite mit den Artikeltiteln.
Holen Sie sich ein Element per HTML-Tag
Syntax: element_name
Du kannst den … benutzen find() Und find_all() Methoden zum Suchen von Elementen anhand ihres HTML-Tags.
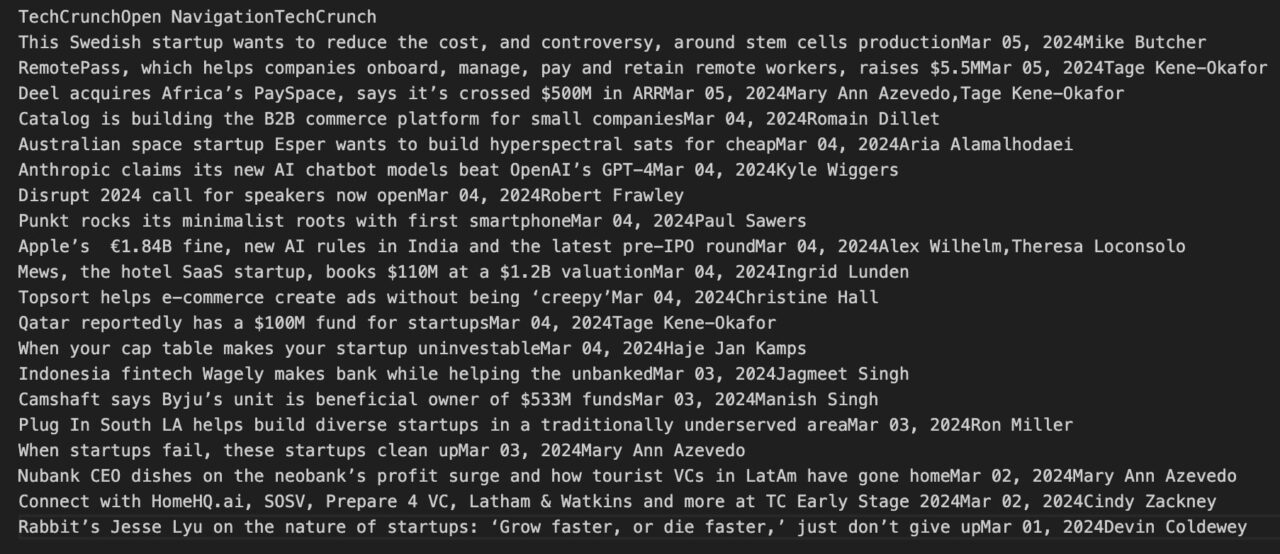
Der folgende Code findet beispielsweise alle header Tags auf der Seite:
header_tags = soup.find_all('header')
for header_tag in header_tags:
print(header_tag.get_text(strip=True))
Die Ausgabe in der Konsole sollte ungefähr so aussehen:
Holen Sie sich ein Element nach CSS-Klasse
Syntax: .class_name
Klassenselektoren ordnen Elemente basierend auf dem Inhalt ihrer class Attribut.
title = soup.select('.post-block__title__link')(0).text
print(title)
Der Punkt (.) vor dem Klassennamen zeigt BS4 an, dass es sich um eine CSS-Klasse handelt.
Abrufen eines Elements nach ID
Syntax: #id_value
ID-Selektoren gleichen ein Element auf der Grundlage des Wertes des Elements ab. id Attribut. Damit das Element ausgewählt werden kann, muss sein id Attribut muss genau mit dem im Selektor angegebenen Wert übereinstimmen.
element_by_id = soup.select('#element_id') # returns the element at "element_id"
print(element_by_id)
Das Hash-Symbol vor dem Namen der ID sagt BS4, dass wir nach einem id.
Abrufen eines Elements durch Attributselektoren
Syntax: (attribute=attribute_value) oder (attribute)
Attributselektoren gleichen Elemente basierend auf dem Vorhandensein oder Wert eines bestimmten Attributs ab. Der einzige Unterschied besteht darin, dass dieser Selektor eckige Klammern () anstelle eines Punkts (.) verwendet. class oder ein Raute-Symbol (#) als id.
# Get the URL of the article
url = soup.select('.post-block__title__link')(0)('href')
print(url)
Ausgabe:
Abrufen eines Elements mit XPath
XPath verwendet eine pfadähnliche Syntax, um Elemente in einem XML- oder HTML-Dokument zu lokalisieren. Es funktioniert ganz ähnlich wie ein herkömmliches Dateisystem.
So finden Sie den XPath für ein bestimmtes Element auf einer Seite:
- Klicken Sie mit der rechten Maustaste auf das Element auf der Seite und klicken Sie auf „Prüfen„, um die Registerkarte „Entwicklertools“ zu öffnen.
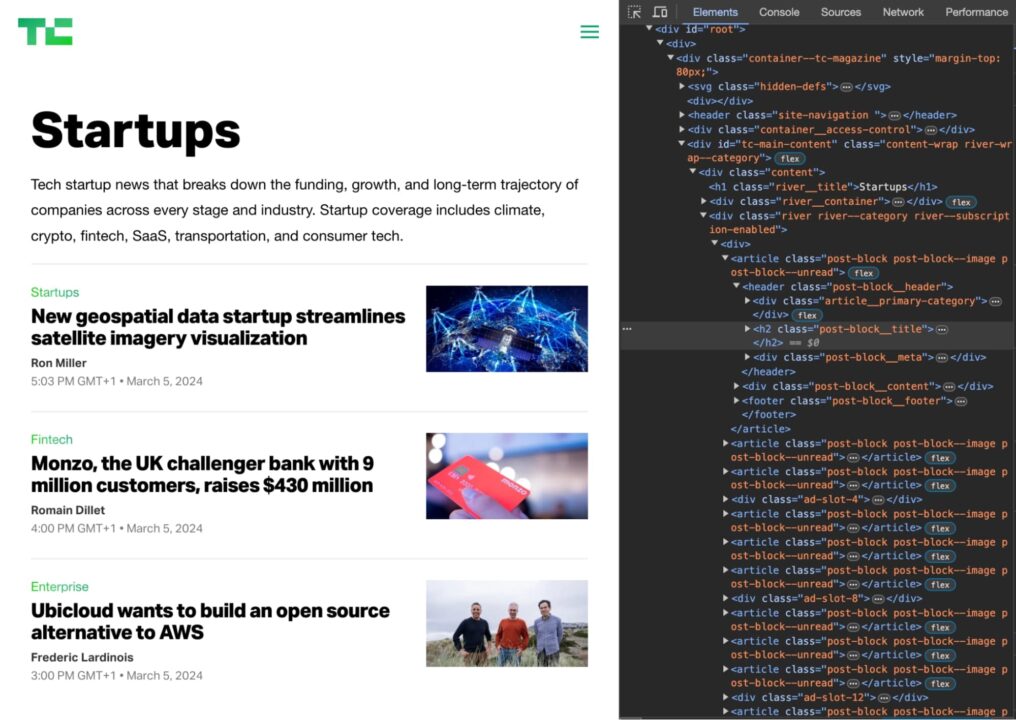
- Wählen Sie das Element auf der Registerkarte „Elemente“ aus.

- Klicke auf „Kopieren“ -> „XPath kopieren„.
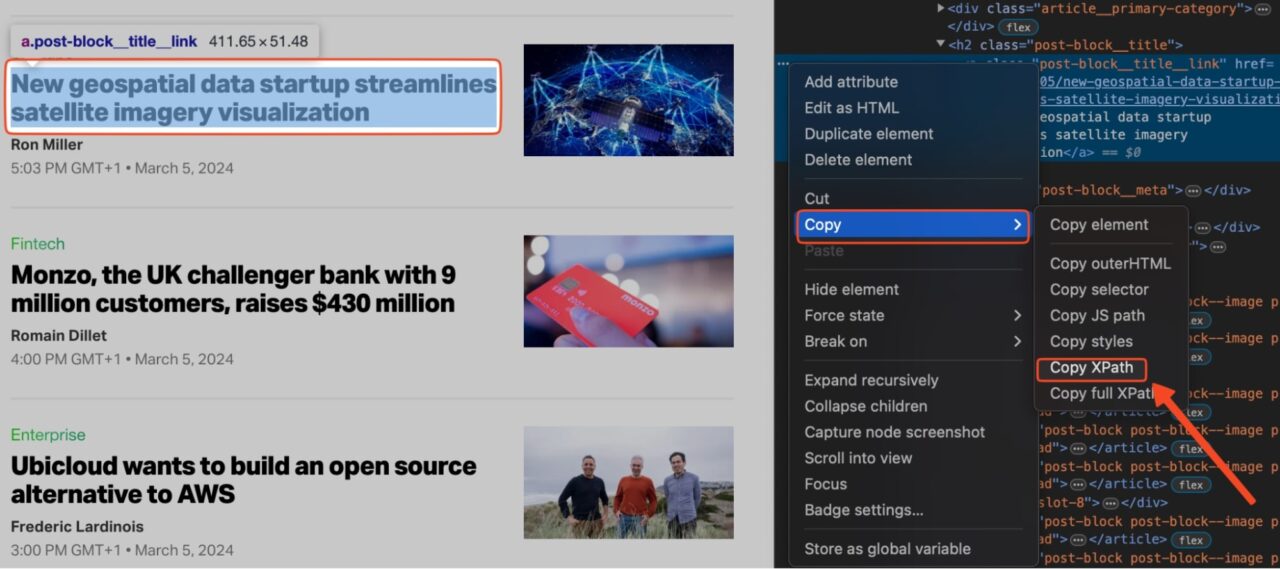
Notiz: Wenn XPath nicht das gewünschte Ergebnis liefert, kopieren Sie den vollständigen XPath statt nur den Pfad. Die restlichen Schritte sind dann gleich.
Wir können nun den folgenden Code ausführen, um den ersten Artikel auf der Seite zu extrahieren, indem wir XPath:
from bs4 import BeautifulSoup
import requests
from lxml import etree
url = 'https://techcrunch.com/category/startups/'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Accept-Language": "en-US, en;q=0.5",
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.content, "lxml")
dom = etree.HTML(str(soup))
print(dom.xpath('//*(@id="tc-main-content")/div/div(2)/div/article(1)/header/h2/a')(0).text)
Hier ist die Ausgabe:
New geospatial data startup streamlines satellite imagery visualization
Anfragen und BeautifulSoup Scraping-Beispiel
Lassen Sie uns all dies kombinieren, um TechCrunch nach einer Liste von Startup-Artikeln zu durchsuchen:
import requests
from bs4 import BeautifulSoup
url = 'https://techcrunch.com/category/startups/'
article_list = ()
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.content, "lxml")
articles = soup.find_all('header')
for article in articles:
title = article.get_text(strip=True)
url = article.find('a')('href')
print(title)
print(url)
Dieser Code druckt die Titel und URL jedes Startup-Artikels.
Speichern der Daten in einer CSV-Datei
Sobald Sie die gewünschten Daten aus der Webseite extrahiert haben, können Sie diese zur weiteren Analyse in einer CSV-Datei speichern. Verwenden Sie dazu den csv Modul, fügen Sie Ihrem Scraper diesen Code hinzu:
import requests
from bs4 import BeautifulSoup
import csv
url = 'https://techcrunch.com/category/startups/'
article_list = ()
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.content, "lxml")
articles = soup.find_all('header')
for article in articles:
title = article.get_text(strip=True)
url = article.find('a')('href')
article_list.append((title, url))
with open('startup_articles.csv', 'w', newline='') as f:
csvwriter = csv.writer(f)
csvwriter.writerow(('Title', 'URL'))
for article in article_list:
csvwriter.writerow(article)
Dadurch wird eine CSV-Datei mit dem Namen erstellt startup_articles.csv und schreiben Sie die Titel und URLs der Artikel in die Datei. Sie können die CSV-Datei dann in einem Tabellenkalkulationsprogramm wie Microsoft Excel oder Google Tabellen zur weiteren Analyse.
Lerne weiter
Herzlichen Glückwunsch, Sie haben gerade Ihre erste Website mit Requests und BeautifulSoup erstellt!
Möchten Sie mehr über Web Scraping erfahren? Besuchen Sie unseren Scraping Hub. Dort finden Sie alles, was Sie brauchen, um ein Experte zu werden.
Wenn Sie bereit sind, echte Projekte in Angriff zu nehmen, folgen Sie unseren Tutorials für Fortgeschrittene:
Erkunden Sie weiter und viel Spaß beim Scrapen!
