
Data Scraping ist ein wesentlicher Bestandteil jedes Unternehmens. Um aktuelle Informationen anzubieten, ist es notwendig, die Interessen und Trends von Kunden und normalen Nutzern zu verfolgen.
Eine der wertvollsten Anwendungen von Scrapern ist das Scrapen von Google-Suchergebnissen. Mit dem Scraping von Suchmaschinenergebnissen können Sie verfolgen, welche Daten Benutzer erhalten, und Leads sammeln.
Nach unserer Erfahrung ist Python eine der am besten geeigneten Programmiersprachen für Scraping. Es ermöglicht Ihnen, einfach und schnell Skripte zum Sammeln von Daten zu schreiben. In diesem Tutorial schauen wir uns also an, wie man die Google-Suchergebnisseite in Python durchsucht, welche Herausforderungen auf Sie zukommen und wie Sie diese umgehen können.
Google SERP-Seitenanalyse
Bevor Sie einen Google Scraper erstellen, müssen Sie die Seite, die Sie scrapen möchten, analysieren, um herauszufinden, wo sich die erforderlichen Elemente befinden. Sie müssen zunächst den Link berücksichtigen, den Google während einer Suchanfrage generiert.
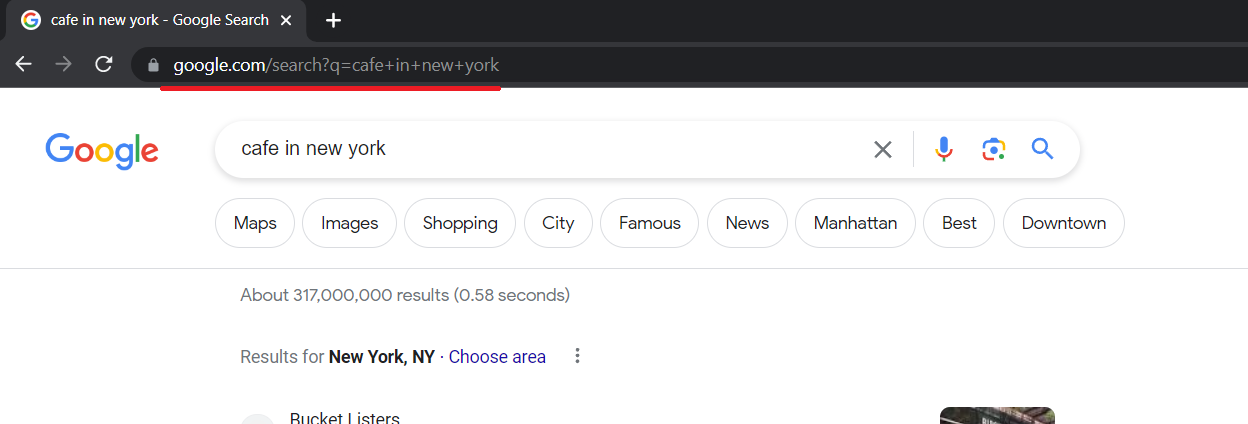
Der Link ist ganz einfach und wir können ihn selbst generieren. Der Teil „https://www.google.com/search?q=“ bleibt unverändert, gefolgt vom Abfragetext mit einem „+“ anstelle eines Leerzeichens.
Jetzt müssen wir verstehen, wo sich die Daten befinden, die wir benötigen. Öffnen Sie dazu DevTools (klicken Sie mit der rechten Maustaste auf den Bildschirm und drücken Sie „Inspizieren“ oder drücken Sie einfach F12).
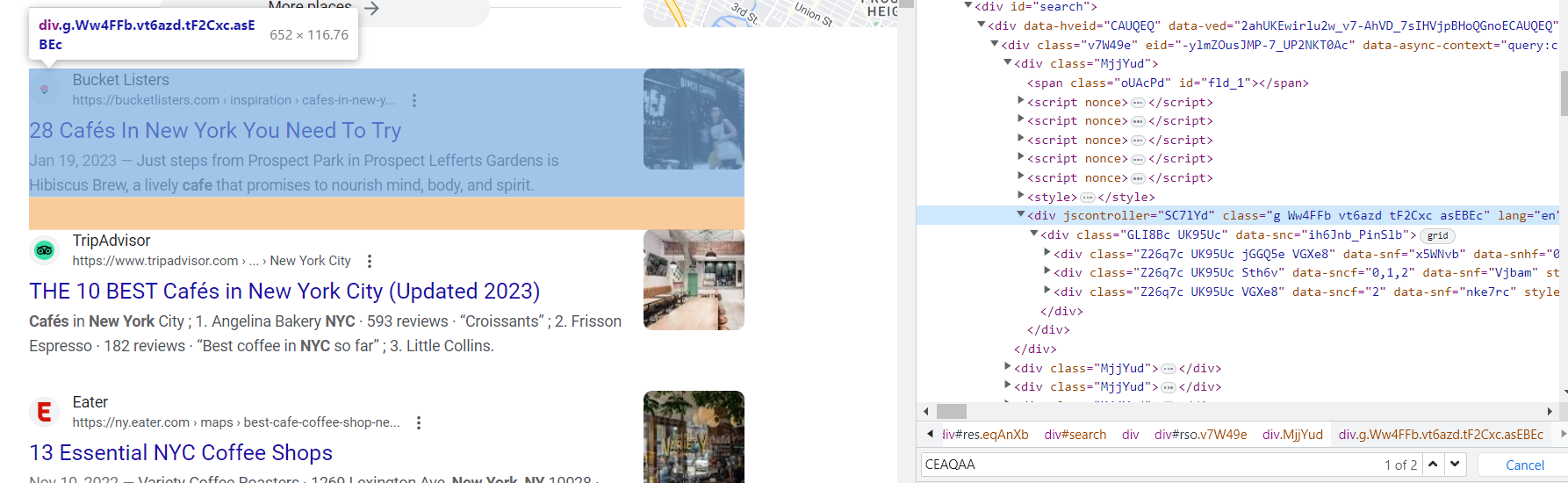
Leider werden fast alle Klassen auf den Ergebnisseiten der Suchmaschinen automatisch generiert. Daher ist es schwierig, die Daten anhand des Klassennamens abzurufen. Die Struktur der Seite bleibt jedoch unverändert. Auch die Klasse „g“ der Suchergebnisse bleibt unverändert.
Wenn wir uns die Elemente in dieser Klasse genau ansehen, können wir die Tags identifizieren, in denen sich der Link, der Titel und die Beschreibung des Elements befinden:
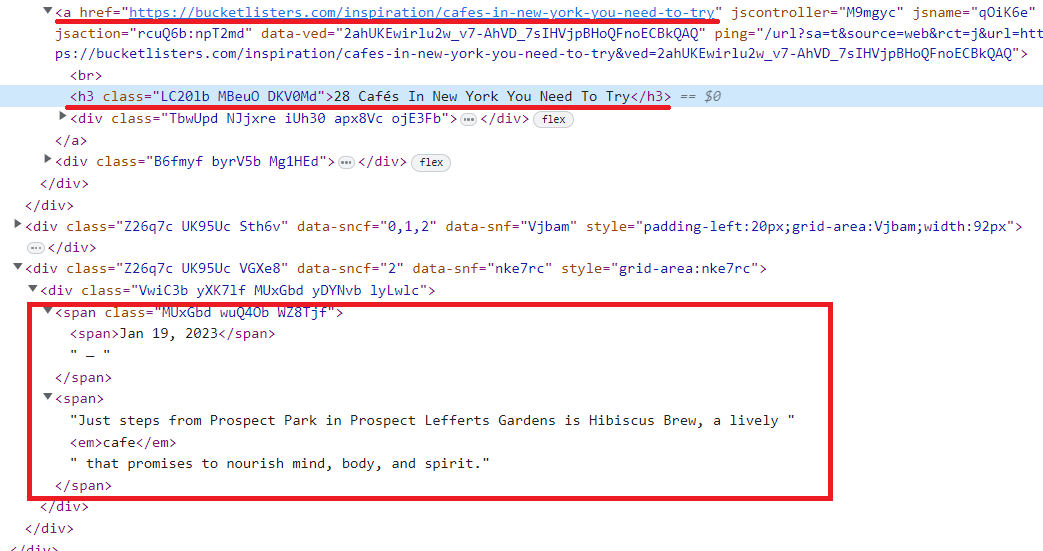
Nachdem wir uns nun die Seite angesehen und die Elemente gefunden haben, die wir scrapen werden, können wir uns an die Erstellung des Scrapers machen.
Einrichten der Entwicklungsumgebung
Bevor wir uns mit dem Web-Scraping von Google-Suchergebnissen befassen, ist es wichtig, eine geeignete Entwicklungsumgebung in Python einzurichten. Dazu gehört die Installation der notwendigen Bibliotheken und Tools, die es uns ermöglichen, Anfragen an Google zu senden, HTML-Antworten zu analysieren und die Daten effektiv zu verarbeiten.
Stellen Sie zunächst sicher, dass Python auf Ihrem Computer installiert ist. Um dies zu überprüfen, können Sie Folgendes verwenden:
python -vWenn Sie eine Version von Python haben, dann haben Sie sie. Wir werden Python Version 3.10.7 verwenden. Wenn Sie Python nicht installiert haben, besuchen Sie die offizielle Python-Website und laden Sie die neueste Version herunter, die mit Ihrem Betriebssystem kompatibel ist. Befolgen Sie die Installationsanweisungen und fügen Sie Python zur PATH-Variablen Ihres Systems hinzu.
Um die verschiedenen Möglichkeiten zum Scrapen des Google SERP zu zeigen, installieren wir die folgenden Bibliotheken:
pip install beautifulsoup4
pip install selenium
pip install google-serp-apiWir werden auch die Requests-Bibliothek in unserem Python-Skript verwenden, eine vorinstallierte Python-Bibliothek. Wenn Sie es jedoch aus irgendeinem Grund nicht haben, können Sie den folgenden Befehl verwenden:
pip install requestsSie können anstelle der Requests-Bibliothek auch die URL-Bibliothek verwenden.
Um den Selenium Headless-Browser verwenden zu können, müssen Sie außerdem die entsprechende ausführbare WebDriver-Datei für Ihren Browser herunterladen. Selenium benötigt einen separaten WebDriver für die Verbindung mit jedem Browser. Wenn Sie beispielsweise Google Chrome verwenden, benötigen Sie den ChromeDriver. Sie können es von der offiziellen Website herunterladen.
Scraping der Google-Suche mit Python mit BeautifulSoup
Nachdem wir nun die Entwicklungsumgebung eingerichtet haben, tauchen wir in den Prozess des Parsens und Extrahierens von Daten aus Google-Suchergebnissen ein. Wir verwenden die Requests-Bibliothek, um HTTP-Anfragen zu senden und die HTML-Antwort abzurufen, sowie die BeautifulSoup-Bibliothek, um die HTML-Struktur zu analysieren und zu navigieren. Lassen Sie uns eine neue Datei erstellen und die Bibliotheken verbinden:
import requests
from bs4 import BeautifulSoupUm unseren Scraper zu verschleiern und die Wahrscheinlichkeit einer Blockierung zu verringern, legen wir Abfrageheader fest:
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'}Es ist wünschenswert, in der Anfrage die vorhandenen Rubriken anzugeben. Sie können beispielsweise Ihr eigenes verwenden, das Sie in DevTools auf der Registerkarte „Netzwerk“ finden. Dann führen wir die Abfrage aus und schreiben die Antwort in eine Variable:
data = requests.get('https://www.google.com/search?q=cafe+in+new+york', headers=header)Zu diesem Zeitpunkt erhalten wir bereits den Code der Seite und müssen ihn dann verarbeiten. Erstellen Sie ein BeautifulSoup-Objekt und analysieren Sie den resultierenden HTML-Code der Seite:
soup = BeautifulSoup(data.content, "html.parser")Erstellen wir auch eine Ergebnisvariable, in die wir die Daten zu den Elementen schreiben:
results = ()Damit wir die Daten Element für Element verarbeiten können, erinnern wir uns daran, dass jedes Element eine Klasse „g“ hat. Das heißt, alle Elemente durchzugehen und Daten von ihnen zu erhalten, alle Elemente mit der Klasse „g“ abzurufen und sie einzeln durchzugehen, um die erforderlichen Daten zu erhalten. Dazu erstellen wir eine for-Schleife:
for g in soup.find_all('div', {'class':'g'}):Wenn wir uns den Code der Seite genau ansehen, sehen wir außerdem, dass alle Elemente untergeordnete Elemente des -Tags sind, in dem der Seitenlink gespeichert ist. Lassen Sie uns das nutzen und die Titel-, Link- und Beschreibungsdaten abrufen. Wir berücksichtigen, dass die Beschreibung leer sein kann, und fügen sie in den try…except-Block ein:
if anchors:
link = anchors(0)('href')
title = g.find('h3').text
try:
description = g.find('div', {'data-sncf':'2'}).text
except Exception as e:
description = "-"Geben Sie die Daten zu den Elementen in die Ergebnisvariable ein:
results.append(str(title)+";"+str(link)+';'+str(description))Jetzt könnten wir die Variable auf dem Bildschirm anzeigen, aber komplizieren wir die Sache und speichern die Daten in einer Datei. Erstellen oder überschreiben Sie dazu eine Datei mit den Spalten „Titel“, „Link“, „Beschreibung“:
with open("serp.csv", "w") as f:
f.write("Title; Link; Description\n")Und geben wir die Daten aus der Ergebnisvariablen Zeile für Zeile ein:
for result in results:
with open("serp.csv", "a", encoding="utf-8") as f:
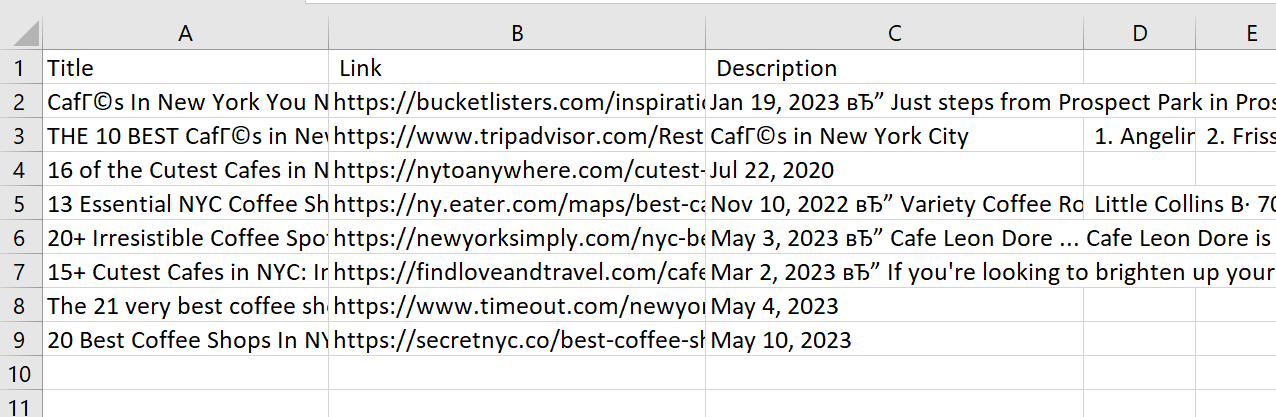
f.write(str(result)+"\n")Derzeit verfügen wir über einen einfachen Suchmaschinen-Scraper, der Ergebnisse in einer CSV-Datei sammelt.
Vollständiger Code:
import requests
from bs4 import BeautifulSoup
url="https://www.google.com/search?q=cafe+in+new+york"
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'}
data = requests.get(url, headers=header)
if data.status_code == 200:
soup = BeautifulSoup(data.content, "html.parser")
results = ()
for g in soup.find_all('div', {'class':'g'}):
anchors = g.find_all('a')
if anchors:
link = anchors(0)('href')
title = g.find('h3').text
try:
description = g.find('div', {'data-sncf':'2'}).text
except Exception as e:
description = "-"
results.append(str(title)+";"+str(link)+';'+str(description))
with open("serp.csv", "w") as f:
f.write("Title; Link; Description\n")
for result in results:
with open("serp.csv", "a", encoding="utf-8") as f:
f.write(str(result)+"\n")Leider hat dieses Skript mehrere Nachteile:
- Es werden nur wenige Daten erfasst.
- Es werden keine dynamischen Daten erfasst.
- Es werden keine Proxys verwendet.
- Es werden keine Aktionen auf der Seite ausgeführt.
- Es löst kein Captcha.
Schreiben wir ein neues Skript basierend auf der Selenium-Bibliothek, um einige dieser Probleme zu lösen.
Verwenden Sie den Headless Browser, um Daten aus Suchergebnissen abzurufen
Ein Headless-Browser kann von Vorteil sein, wenn Sie mit Websites arbeiten, die dynamische Inhalte verwenden, CAPTCHA-Herausforderungen erfordern oder JavaScript-Rendering erfordern. Selenium, ein leistungsstarkes Web-Automatisierungstool, ermöglicht es uns, über einen Headless-Browser mit Webseiten zu interagieren und Daten daraus zu extrahieren.
Erstellen Sie eine neue Datei und verbinden Sie die Bibliotheken:
from selenium import webdriver
from selenium.webdriver.common.by import ByLassen Sie uns nun darauf hinweisen, wo sich der zuvor heruntergeladene Webtreiber befindet:
DRIVER_PATH = 'C:\chromedriver.exe'
driver = webdriver.Chrome(executable_path=DRIVER_PATH)Im vorherigen Skript haben wir die Abfrage mit einem Link angegeben. Aber wir haben gesehen, dass alle Abfragen gleich aussahen. Lassen Sie uns das also verbessern und es ermöglichen, einen Link basierend auf einer Textabfrage zu generieren:
search_query = "cafe in new york"
base_url = "https://www.google.com/search?q="
search_url = base_url + search_query.replace(" ", "+")Jetzt können wir zu der Seite gehen, die wir brauchen:
driver.get(search_url)Extrahieren wir die Daten mithilfe der CSS-Selektoren aus dem vorherigen Skript:
results = ()
result_divs = driver.find_elements(By.CSS_SELECTOR, "div.g")
for result_div in result_divs:
result = {}
anchor = result_div.find_elements(By.CSS_SELECTOR, "a")
link = anchor(0).get_attribute("href")
title = result_div.find_element(By.CSS_SELECTOR, "h3").text
description_element = result_div.find_element(By.XPATH, "//div(@data-sncf="2")")
description = description_element.text if description_element else "-"
results.append(str(title)+";"+str(link)+';'+str(description))Schließen Sie den Browser:
driver.quit()Und dann die Daten in einer Datei speichern:
with open("serp.csv", "w") as f:
f.write("Title; Link; Description\n")
for result in results:
with open("serp.csv", "a", encoding="utf-8") as f:
f.write(str(result)+"\n")Mit Selen haben wir einige der mit dem Schaben verbundenen Probleme gelöst. So haben wir beispielsweise das Blockierungsrisiko deutlich reduziert, da der Headless-Browser die Arbeit eines echten Benutzers vollständig simuliert und das Skript somit nicht von einer Person zu unterscheiden ist.
Dieser Ansatz ermöglicht es uns außerdem, mit verschiedenen Elementen auf der Seite zu arbeiten und dynamische Seiten zu löschen.
Allerdings können wir unseren Standort immer noch nicht kontrollieren, wir können das Captcha nicht lösen, falls es auftritt, und wir verwenden keine Proxys. Fahren wir mit der folgenden Bibliothek fort, um diese Probleme zu lösen.
Web Scraping mit der Google Search API
Um mit unserer Bibliothek arbeiten zu können, benötigen Sie einen API-Schlüssel, den Sie in Ihrem Konto finden. Um also einen funktionsreichen Google SERP Scraper zu erstellen, verwenden wir unsere Bibliothek:
from google_serp_api import ScrapeitCloudClientVerbinden wir auch die integrierte JSON-Bibliothek, um die Antwort zu verarbeiten, die im JSON-Format vorliegt:
import jsonLassen Sie uns den API-Schlüssel angeben und die Parameter festlegen:
client = ScrapeitCloudClient(api_key='YOUR-API-KEY')
response = client.scrape(
params={
"q": search_key,
"location": "Austin, Texas, United States",
"domain": "google.com",
"deviceType": "desktop",
"num": 100
}
)Sie können das Suchwort, das Land, aus dem Sie Daten abrufen möchten, die Anzahl der zu scannenden Ergebnisse und die Google-Domain festlegen. Wenn Sie diesen Code ausführen, wird eine JSON-formatierte Antwort mit Daten in der folgenden Ansicht zurückgegeben:
- requestMetadata (request metadata)
- id (request ID)
- googleUrl (Google search URL)
- googleHtmlFile (URL of the Google HTML file)
- status (request status)
- organicResults (organic results)
- position (result position)
- title (result title)
- link (result link)
- displayedLink (displayed result link)
- source (result source)
- snippet (result snippet)
- snippetHighlitedWords (highlighted words in the result snippet)
- sitelinks (site links embedded in the result)
- localResults (local results)
- places (places)
- position (place position)
- title (place title)
- rating (place rating)
- reviews (number of reviews for the place)
- reviewsOriginal (original format of the number of reviews for the place)
- price (place price)
- address (place address)
- hours (place hours of operation)
- serviceOptions (service options)
- placeId (place ID)
- description (place description)
- moreLocationsLink (link to more locations)
- relatedSearches (related searches)
- query (related query)
- link (link to related search results)
- relatedQuestions (related questions)
- question (related question)
- snippet (snippet of the answer to the related question)
- link (link to related question results)
- title (title of the related question result)
- displayedLink (displayed link of the related question result)
- pagination (pagination)
- next (link to the next page of results)
- knowledgeGraph (knowledge graph)
- title (title)
- type (type)
- description (description)
- source (source)
- link (source link)
- name (source name)
- peopleAlsoSearchFor (people also search for)
- name (name)
- link (link to related search results)
- searchInformation (search information)
- totalResults (total number of results)
- timeTaken (time taken for the request)Speichern wir die Daten von „organicResults“ und „relatedSearches“ in separaten Dateien. Formatieren Sie zunächst die erhaltene Antwort aus der Zeichenfolge in JSON und fügen Sie die Daten aus den gewünschten Attributen in Variablen ein.
data = json.loads(response.text)
organic_results = data('organicResults')
keywords = data('relatedSearches')Erstellen Sie Variablen mit dem gewünschten Ergebnis.
rows_organic = ()
rows_keys =()Gehen Sie alle Spuren Element für Element durch und fügen Sie sie in der richtigen Form in die Variablen ein:
for result in organic_results:
rows_organic.append(str(result('position'))+";"+str(result('title'))+";"+str(result('link'))+";"+str(result('source'))+";"+str(result('snippet')))
for result in keywords:
rows_keys.append(str(result('query'))+";"+str(result('link')))Speichern wir die Daten in Dateien:
with open("data_organic.csv", "w") as f:
f.write("position; title; url; domain; snippet'\n")
for row in rows_organic:
with open("data_organic.csv", "a", encoding="utf-8") as f:
f.write(str(row)+"\n")
with open("data_keys.csv", "w") as f:
f.write("keyword; path'\n")
for row in rows_keys:
with open("data_keys.csv", "a", encoding="utf-8") as f:
f.write(str(row)+"\n")Als Ergebnis der Ausführung des Skripts haben wir zwei Dateien erhalten:
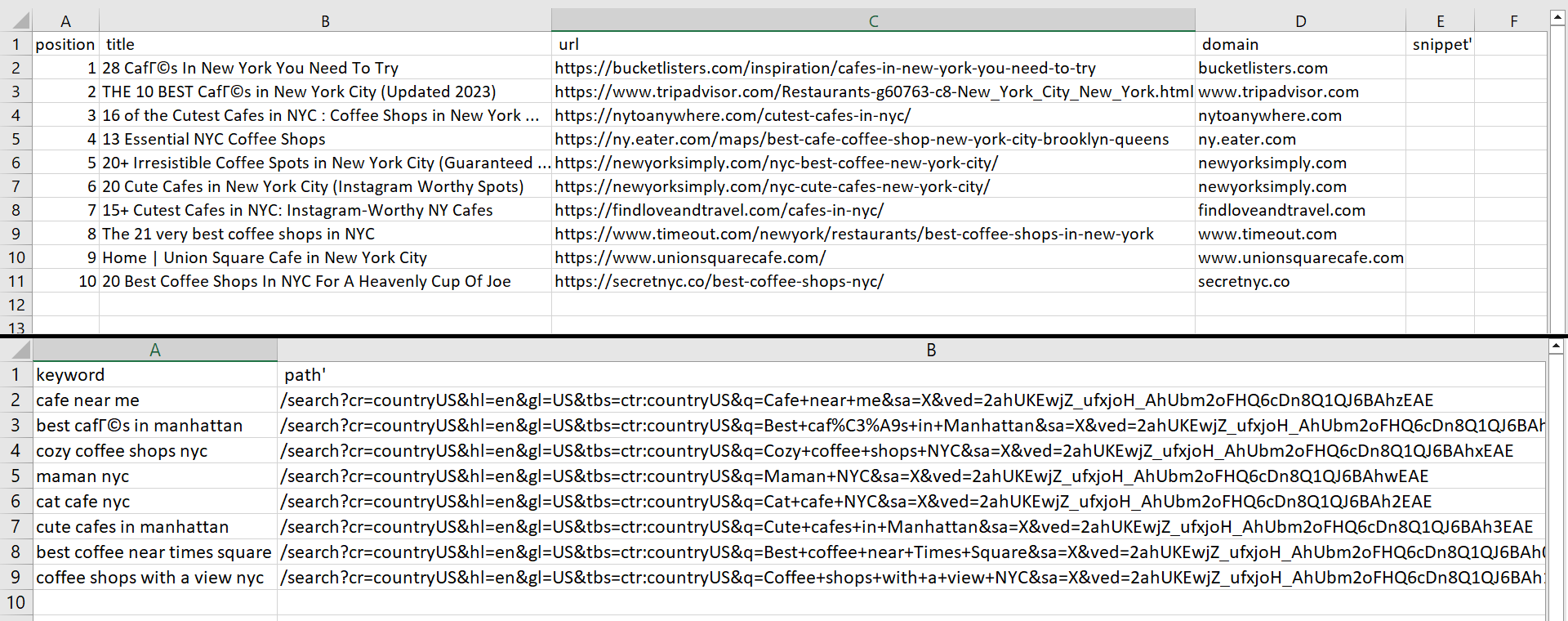
Wir können die Anzahl der Ergebnisse ändern, indem wir den Parameter num_results in „params“ ändern. Nehmen wir jedoch an, wir haben eine Datei, die alle Schlüsselwörter speichert, die wir zum Scrapen von Daten benötigen. Wir müssen die Datei zuerst öffnen und sie dann Zeile für Zeile mit einem neuen Schlüsselwort durchgehen:
with open("keywords.csv") as f:
lines = f.readlines()
with open("data_keys.csv", "w") as f:
f.write("search_key; keyword; path'\n")
with open("data_organic.csv", "w") as f:
f.write("search_key; position; title; url; domain; snippet'\n")
for line in lines:Wir haben Spaltenüberschriften für neue Dateien angegeben, bevor das Schlüsselwort übergeben wird. Dies bedeutet, dass die Datei nicht überschrieben wird, wenn Sie nach einem neuen Schlüsselwort suchen. Stattdessen wird die Datei um weitere Daten ergänzt. Wir haben außerdem eine weitere Spalte hinzugefügt, die die Textsuchabfrage enthält, mit der die Ergebnisse übereinstimmen.
Jetzt ändern wir die Antwort und geben das Schlüsselwort an, das mit der Variablenzeile identisch sein soll:
response = client.scrape(
params={
"q": search_key,
"location": "Austin, Texas, United States",
"domain": "google.com",
"deviceType": "desktop",
"num": 100
}
)Der Rest des Codes wird ähnlich sein. Es wird lediglich eine neue Spalte mit der Variablenzeile hinzugefügt. Als Ergebnis erhalten wir die folgenden zwei Dateien:
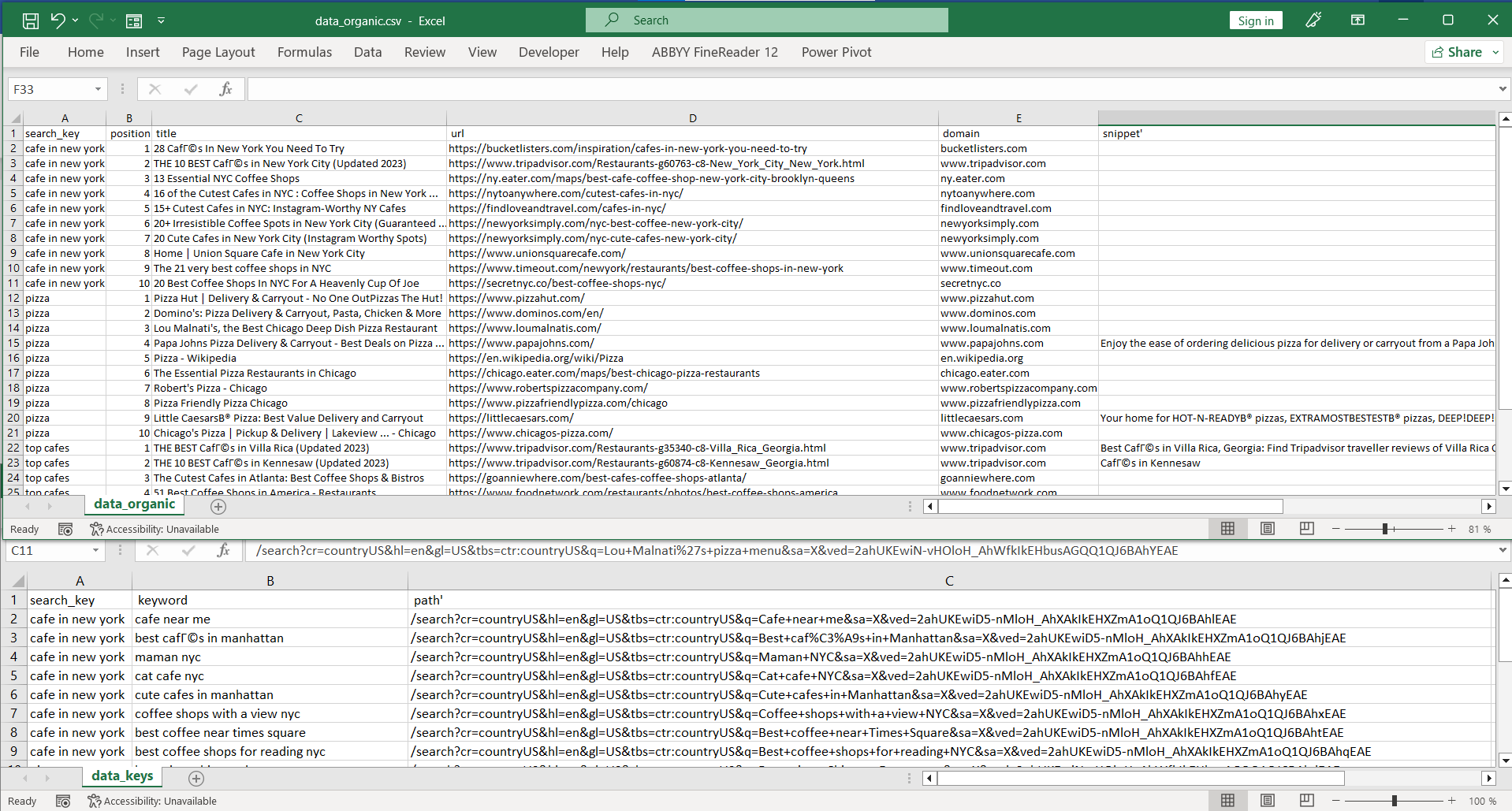
Vollständiger Python-Code:
from google_serp_api import ScrapeitCloudClient
import json
with open("keywords.csv") as f:
lines = f.readlines()
with open("data_keys.csv", "w") as f:
f.write("search_key; keyword; path'\n")
with open("data_organic.csv", "w") as f:
f.write("search_key; position; title; url; domain; snippet'\n")
for line in lines:
search_key = str(line.replace("\n", ""))
client = ScrapeitCloudClient(api_key='YOUR-API-KEY')
response = client.scrape(
params={
"q": search_key,
"location": "Austin, Texas, United States",
"domain": "google.com",
"deviceType": "desktop",
"num": 100
}
)
data = json.loads(response.text)
organic_results = data.get('organicResults', ())
keywords = data.get('relatedSearches', ())
rows_organic = ()
rows_keys = ()
for result in organic_results:
rows_organic.append(f"{search_key};{result.get('position', '')};{result.get('title', '')};{result.get('link', '')};{result.get('source', '')};{result.get('snippet', '')}")
for result in keywords:
rows_keys.append(f"{search_key};{result.get('query', '')};{result.get('link', '')}")
for row in rows_organic:
with open("data_organic.csv", "a", encoding="utf-8") as f:
f.write(row + "\n")
for row in rows_keys:
with open("data_keys.csv", "a", encoding="utf-8") as f:
f.write(row + "\n")Der Hauptvorteil der Nutzung der Scrape-It.Cloud-Bibliothek besteht darin, dass Sie sich keine Gedanken über Proxy-Rotation, JavaScript-Rendering oder Captcha-Lösung machen müssen – die API stellt vorbereitete Daten bereit.
Scraping der Google-Suche mit Python: Herausforderungen und Einschränkungen
Das Scrapen von Google-Suchergebnissen mit Python kann schwierig sein. Beim Scraping von Google-Suchergebnissen müssen mehrere Herausforderungen bewältigt werden, von der technischen Komplexität, die mit dem sich ständig ändernden Algorithmus der Suchmaschine verbunden ist, bis hin zu den integrierten Anti-Scraping-Schutzmaßnahmen. Es besteht auch die Möglichkeit der IP-Adressblockierung und der Captcha-Eingabe sowie viele andere Herausforderungen, auf die wir weiter unten eingehen.
Einschränkungen der Geolokalisierung
Die Google-Suchergebnisse können je nach Standort variieren. Wenn Sie beispielsweise in den USA suchen, können Ihre Ergebnisse anders ausfallen als bei jemandem, der in Kanada sucht. Wenn Sie über die Berechtigung zum Zugriff auf Standortdaten verfügen oder von einem Ort aus genügend Suchanfragen gestellt haben, stellt Google lokalisierte Suchergebnisse nur für diesen Bereich bereit. Um herauszufinden, wie Suchergebnisse für andere Länder oder Städte aussehen, müssen Sie einen Proxyserver von diesem Standort aus verwenden oder Sie können eine vorgefertigte Web Scraping API verwenden, die all dies erledigt.
Länderspezifische Domains
Google unterstützt verschiedene Suchdomänen für verschiedene Länder. Zum Beispiel google.co.uk für Großbritannien oder google.de für Deutschland. Jedes hat seine eigenen Funktionen, sein eigenes Google SERP und sein eigenes Google Maps, die beim Scraping berücksichtigt werden müssen.
Einschränkungen auf Ergebnisseiten
Die Seite zeigt eine begrenzte Anzahl von Ergebnissen an. Um den nächsten Satz anzuzeigen, müssen Sie entweder durch die vorhandenen Suchergebnisse scrollen oder zur nächsten Seite wechseln. Denken Sie daran, dass jedes Mal, wenn Sie die Seite wechseln, eine neue Anfrage von Google betrachtet wird und bei zu vielen Anfragen Ihre IP-Adresse möglicherweise blockiert wird oder Sie zu Überprüfungszwecken eine Captcha-Herausforderung durchführen müssen.
Captcha- und Anti-Scraping-Maßnahmen
Wie bereits erwähnt, verfügt Google über verschiedene Methoden zum Umgang mit Web Scraping. Captcha- und IP-Adressblockierung sind zwei der gängigsten Strategien.
Um Captcha-Herausforderungen zu lösen, können Sie Dienste von Drittanbietern nutzen, bei denen echte Menschen sie gegen eine geringe Gebühr lösen. Allerdings müssen Sie dies in Ihre eigene Anwendung integrieren und richtig einrichten.
Gleiches gilt für die IP-Blockierung. Sie können diese Herausforderung vermeiden, indem Sie Proxys mieten, um Ihre IP-Adresse zu verbergen und auch diese Blockaden zu umgehen – aber nur, wenn Sie einen entsprechenden Proxy-Anbieter finden, der zuverlässig genug ist, um diese Aufgabe anzuvertrauen. Sie können sich auch unsere Liste kostenloser Proxys ansehen.
Dynamische HTML-Struktur
JavaScript-Rendering ist eine weitere Möglichkeit, sich vor Scrapern und Bots zu schützen. Das bedeutet, dass der Seiteninhalt dynamisch erstellt wird und sich bei jedem Laden der Seite ändert. Beispielsweise können Klassen auf einer Webseite jedes Mal, wenn Sie sie öffnen, unterschiedliche Namen haben – die Gesamtstruktur der Webseite bleibt jedoch konsistent. Dies erschwert das Scrapen der Seite, ist aber dennoch möglich.
Unvorhersehbare Veränderungen
Google entwickelt und verbessert seine Algorithmen und Prozesse ständig weiter. Dies bedeutet, dass nicht alle Web-Scraping-Tools dauerhaft ohne Wartung verwendet werden können – sie müssen mit den neuesten Änderungen von Google auf dem neuesten Stand gehalten werden.
Fazit und Erkenntnisse
Verschiedene Möglichkeiten und Bibliotheken können bei der Datenextraktion aus Google SERPs in Python helfen. Jeder wählt die Option, die am besten zu seinem Projekt und seinen Fähigkeiten passt.
Wenn Sie neu im Scraping sind und eine kleine Datenmenge erhalten möchten, sind Sie möglicherweise mit der Requests-Bibliothek zum Ausführen von Abfragen und der BeautifulSoup-Bibliothek zum Parsen der erhaltenen Daten zufrieden. Wenn Sie mit Headless-Browsern und Automatisierungstools vertraut sind, ist Selenium genau das Richtige für Sie.
Und wenn Sie die Anbindung von Drittanbieterdiensten zum Lösen von Captchas vermeiden, Proxys mieten und nicht darüber nachdenken möchten, wie Sie das Blockieren oder Abrufen der gewünschten Daten vermeiden möchten, können Sie die Bibliothek google_serp_api verwenden.
