
Daftar Isi
Bagaimana cara mencari eBay dengan Python?
Python menonjol sebagai salah satu bahasa terbaik karena kemudahan penggunaannya, sintaksisnya yang sederhana, dan beragam perpustakaan yang tersedia Pengikisan web dari.
Untuk merayapi eBay dengan Python, kami menggunakan perpustakaan Permintaan dan BeautifulSoup untuk penguraian HTML. Selain itu, kami mengirimkan permintaan kami melalui ScraperAPI untuk menghindari tindakan anti-scraping.
persyaratan
Tutorial ini didasarkan pada Python 3.10tetapi itu harus bekerja dengan versi Python apa pun yang dimulai 3.8. Pastikan Anda menginstal versi Python yang kompatibel sebelum melanjutkan.
Sekarang mari kita memulai proyek Python di lingkungan virtual yang disebut "ebay-scraper". Jalankan perintah berikut satu per satu untuk menyiapkan struktur proyek Anda:
mkdir ebay-scraper
cd ebay-scraper
python -m venv env
Untuk pemahaman yang lebih baik, hal berikut terjadi pada setiap baris perintah yang tercantum di atas:
- Pertama, direktori bernama “ebay–scrapper” dibuat.
- Kemudian terminal Anda akan menuju ke direktori sebenarnya tempat Anda sedang membangun
- Terakhir, t secara lokal membuat lingkungan virtual Python untuk proyek tersebut
Masuk ke folder proyek dan tambahkan satu file utama.py. File ini akan segera berisi logika untuk menghapus eBay.
Anda juga perlu menginstal pustaka Python berikut:
- Permintaan: Pustaka ini secara luas dianggap sebagai pustaka klien HTTP paling populer untuk Python. Ini menyederhanakan pengiriman permintaan HTTP dan pemrosesan tanggapan, memungkinkan Anda mengunduh halaman hasil pencarian eBay.
- Sup yang enak: Ini adalah pustaka parsing Python HTML dan XML yang komprehensif. Ini membantu untuk menavigasi struktur situs web dan mengekstrak data yang diperlukan.
- lxml: Pustaka ini terkenal dengan kecepatan dan fiturnya yang kaya fitur untuk memproses XML dan HTML dengan Python.
Anda dapat dengan mudah menginstal perpustakaan ini bersama dengan Penginstal Paket Python (PIP):
pip install requests beautifulsoup4 lxml
Jika persyaratan ini terpenuhi, Anda dapat melanjutkan ke langkah berikutnya!
Memahami struktur halaman hasil pencarian eBay
Jika Anda mencari istilah tertentu seperti “Airpods Pro”, eBay akan menampilkan hasil yang mirip dengan halaman berikut:
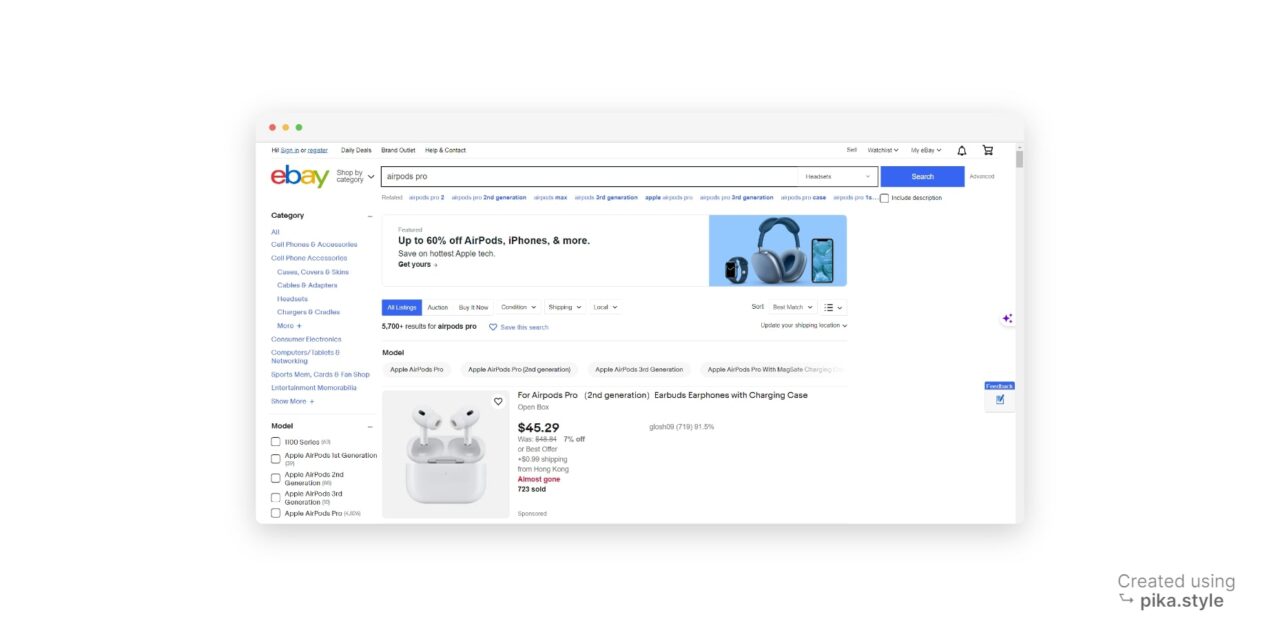
Semua produk yang terdaftar di bawah “airpods pro” dapat diekstraksi, begitu pula tautan, judul, harga, ulasan, dan gambarnya.
Sebelum Anda mulai menulis skrip, penting untuk menentukan data apa yang ingin Anda kumpulkan. Dalam proyek ini kami fokus pada penggalian detail produk berikut:
- Nama Produk
- Harga
- Gambar produk
- Deskripsi produk singkat
- URL produk
Pada tangkapan layar di bawah, Anda dapat melihat di mana atribut ini dapat ditemukan:

Sekarang kita tahu informasi apa yang kita minati dan di mana menemukannya, sekarang saatnya membuat scraper kita.
Langkah 1: Menyiapkan proyek kami
Buka editor kode Anda dan tambahkan baris kode berikut untuk mengimpor dependensi kami:
import requests
from bs4 import BeautifulSoup
import csv
Catatan: Kami juga mengimpor perpustakaan CSV karena kami ingin mengekspor data kami dalam format ini.
Selanjutnya, kita perlu menyiapkan URL halaman eBay yang ingin kita cari. Dalam contoh ini kami mencari “Airpods Pro“. URL Anda akan terlihat seperti ini:
url = "https://www.ebay.com/sch/i.html?_from=R40&_trksid=p4432023.m570.l1312&_nkw=airpods+pro&_sacat=0"
Langkah 2: Kirim permintaan dan parsing kode HTML
Sekarang kami mengirimkannya MENERIMA Kirim permintaan ke situs eBay dan parsing kode HTML dengan BeautifulSoup.
html = requests.get(url)
print(html.text)
Kode ini menggunakan requests Perpustakaan untuk mengirim "permintaan GET" ke halaman hasil pencarian eBay kami, mengambil konten HTML halaman web dan menyimpannya ke html Variabel.
Namun, setelah Anda menjalankan kode ini, Anda akan melihat bahwa eBay telah mengambil beberapa tindakan anti-bot.
Anda dapat melewati tindakan anti-bot ini dengan mengirimkan header Agen-Pengguna yang sesuai untuk meniru browser web sebagai bagian dari permintaan:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Accept-Language": "en-US, en;q=0.5",
}
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.text, "lxml")
Untuk mengurai konten HTML, kode membuat objek BeautifulSoup dengan meneruskannya html.text dan tipe parser (lxml) Untuk BeautifulSoup() Fungsi. Hal ini memungkinkan kita menavigasi dan mengekstrak data dari HTML dengan mudah.
Langkah 3: Temukan elemen produk di halaman
Secara umum, kita perlu memahami tata letak HTML suatu halaman untuk mendapatkan hasilnya. Ini adalah bagian penting dan kritis dari web scraping.
Namun, jika Anda belum terlalu paham dengan HTML, jangan khawatir.
Kami akan menggunakan alat pengembang, fitur yang tersedia di sebagian besar browser web utama, untuk mengekstrak data yang diperlukan.
Di halaman hasil pencarian, jalankan Inspect Item dan buka jendela alat pengembang. Cara lainnya, tekan “CTRL+SHIFT+I” untuk pengguna Windows atau “Opsi + ⌘ + I” di Mac
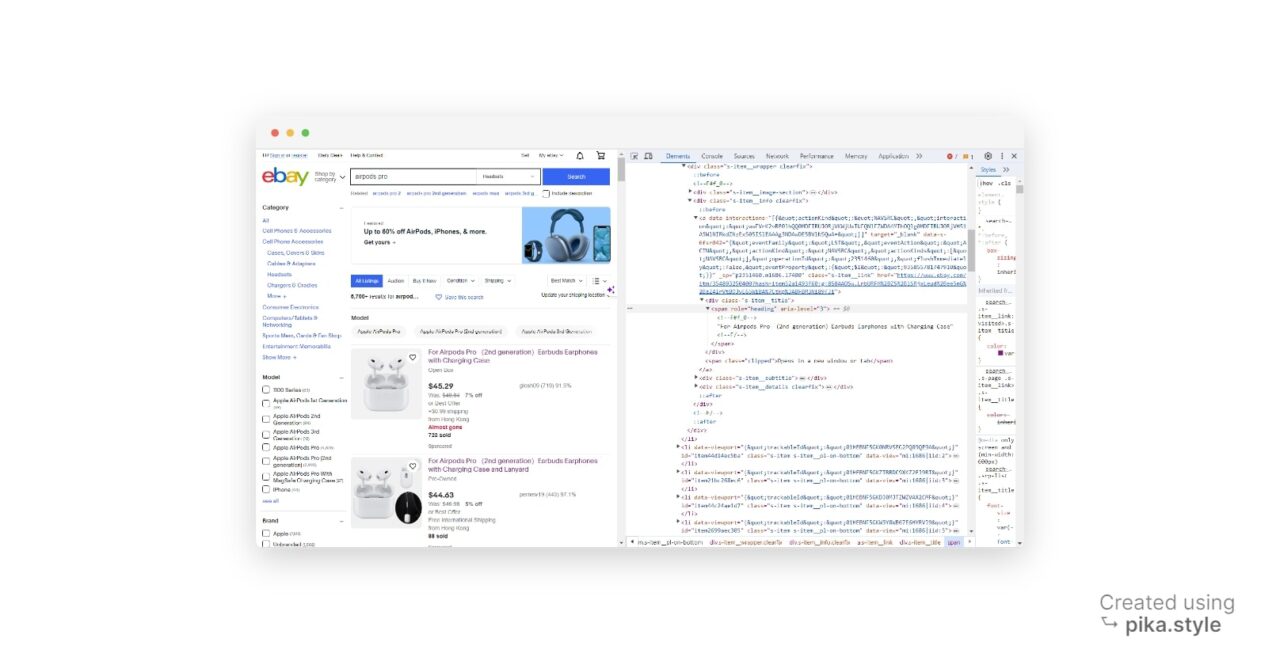
Di jendela baru Anda akan menemukan kode sumber situs target. Dalam kasus kita, semua produk disebutkan sebagai item daftar, jadi kita perlu mengambil semua daftar ini.
Untuk mengambil satu elemen HTML, kita memerlukan pengenal yang terkait dengannya. Ini bisa berupa a PENGENAL elemen ini, apa saja Nama kelasatau lainnya Atribut HTML dari elemen masing-masing.
Dalam kasus kami, kami menggunakan nama kelas sebagai pengenal. Semua daftar memiliki nama kelas yang sama, yaitu S-Item.
Setelah diperiksa lebih dekat, kami mendapatkan nama kelas untuk nama produk dan harga produk: “s-item__title" Dan "s-item__price", masing-masing.
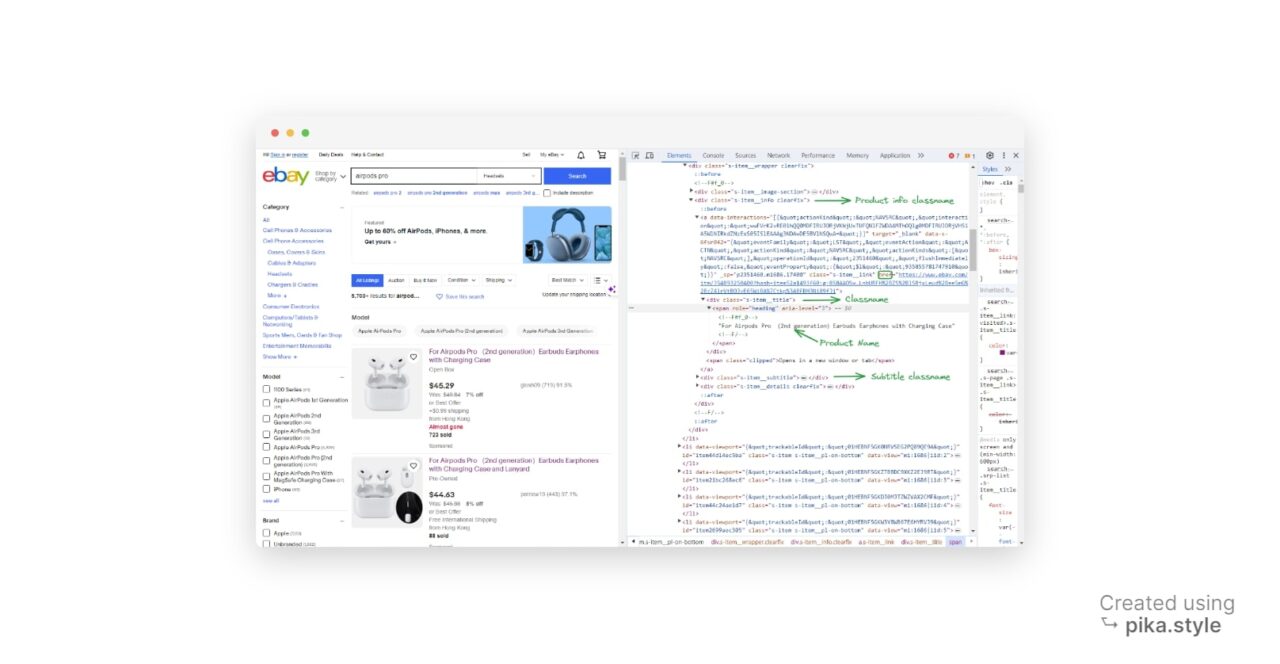
Langkah selanjutnya adalah menemukan item produk di halaman tersebut. Kode ini menggunakan find_all() Metode objek BeautifulSoup untuk menemukan semua elemen div dengan kelas “s-item__info clearfix“.
Elemen div ini mewakili elemen produk pada halaman. Dengan menggunakan pendekatan yang sama, program juga menemukan wadah gambar yang sesuai.
Tambahkan baris kode berikut ke file Anda:
import requests
from bs4 import BeautifulSoup
import csv
url = "https://www.ebay.com/sch/i.html?_from=R40&_trksid=p4432023.m570.l1312&_nkw=airpods+pro&_sacat=0"
html = requests.get(url)
print(html.text)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Accept-Language": "en-US, en;q=0.5",
}
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.text, "lxml")
listings = soup.find_all("div", class_="s-item__info clearfix")
images = soup.find_all("div", class_="s-item__wrapper clearfix")
Langkah 4: Ekstrak informasi yang diinginkan
Untuk setiap item produk, kami mengekstrak judul, harga, URL produk, status produk, dan URL gambar.
import requests
from bs4 import BeautifulSoup
import csv
url = "https://www.ebay.com/sch/i.html?_from=R40&_trksid=p4432023.m570.l1312&_nkw=airpods+pro&_sacat=0"
html = requests.get(url)
print(html.text)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Accept-Language": "en-US, en;q=0.5",
}
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.text, "lxml")
listings = soup.find_all("div", class_="s-item__info clearfix")
images = soup.find_all("div", class_="s-item__wrapper clearfix")
result_list = ()
for listing, image_container in zip(listings, images):
title = listing.find("div", class_="s-item__title").text
price = listing.find("span", class_="s-item__price").text
product_url = listing.find("a")
link = product_url("href")
product_status_element = listing.find("div", class_="s-item__subtitle")
product_status = (
product_status_element.text
if product_status_element is not None
else "No status available"
)
if title and price:
title_text = title.strip()
price_text = price.strip()
status = product_status.strip()
image = image_container.find("img")
image_url = image("src")
result_dict = {
"title": title_text,
"price": price_text,
"image_url": image_url,
"status": status,
"link": link,
}
result_list.append(result_dict)
Dalam satu putaran, kode mengekstrak judul, harga, URL produk, status produk, dan URL gambar untuk setiap item produk. Ini menggunakan find() Metode objek BeautifulSoup untuk menemukan item tertentu dalam setiap item produk.
Data yang diekstraksi kemudian disimpan dalam kamus yang disebut result_dict dan melekat pada result_list.
Langkah 5: Tulis hasilnya ke file CSV
Setelah mengekstrak data, kami membuat file CSV bernama “ebay_results.csv” dalam mode tulis dengan open() Fungsi.
with open("ebay_results.csv", "w", newline="", encoding="utf-8") as csv_file:
fieldnames = ("title", "price", "image_url", "status", "link")
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
# Write the header row
writer.writeheader()
# Write the data rows
for result in result_list:
writer.writerow(result)
A tercipta DictWriter Objek dari CSV Perpustakaan untuk menulis data ke file CSV. "fieldnamesParameter “menentukan nama kolom dalam file CSV.
Kami juga dapat mencetak data yang diekstraksi di konsol.
for result in result_list:
print("Title:", result("title"))
print("Price:", result("price"))
print("Image URL:", result("image_url"))
print("Status:", result("status"))
print("Product Link:", result("link"))
print("\n")
Kode di atas mengulang setiap elemen di result_list dan menampilkan nilai yang sesuai untuk setiap kunci. Dalam hal ini: judul, harga, URL gambar, status produk, dan URL produk.

Kode pengikisan lengkap
Sekarang semua potongan puzzle sudah terpasang, mari kita tulis kode pengikisan yang lengkap. Kode ini menggabungkan semua teknik dan langkah yang telah kita diskusikan dan memungkinkan Anda mengambil data produk eBay dalam satu langkah.
import requests
from bs4 import BeautifulSoup
import csv
url = "https://www.ebay.com/sch/i.html?_from=R40&_trksid=p4432023.m570.l1312&_nkw=airpods+pro&_sacat=0"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Accept-Language": "en-US, en;q=0.5",
}
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.text, "lxml")
result_list = ()
# Find all product items on the page
listings = soup.find_all("div", class_="s-item__info clearfix")
images = soup.find_all("div", class_="s-item__wrapper clearfix")
for listing, image_container in zip(listings, images):
title = listing.find("div", class_="s-item__title").text
price = listing.find("span", class_="s-item__price").text
product_url = listing.find("a")
link = product_url("href")
product_status_element = listing.find("div", class_="s-item__subtitle")
product_status = (
product_status_element.text
if product_status_element is not None
else "No status available"
)
if title and price:
title_text = title.strip()
price_text = price.strip()
status = product_status.strip()
image = image_container.find("img")
image_url = image("src")
result_dict = {
"title": title_text,
"price": price_text,
"image_url": image_url,
"status": status,
"link": link,
}
result_list.append(result_dict)
# Write the result_list to a CSV file
with open("ebay_results4.csv", "w", newline="", encoding="utf-8") as csv_file:
fieldnames = ("title", "price", "image_url", "status", "link")
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
# Write the header row
writer.writeheader()
# Write the data rows
for result in result_list:
writer.writerow(result)
# Print the result list
for result in result_list:
print("Title:", result("title"))
print("Price:", result("price"))
print("Image URL:", result("image_url"))
print("Status:", result("status"))
print("Product Link:", result("link"))
print("\n")
Menggunakan ScraperAPI untuk pengikisan data eBay
Mengikis data eBay bisa menjadi tugas yang menantang karena tindakan anti-bot eBay dan seringnya perubahan pada tekniknya.
Anda telah melihat ini di awal tutorial ini ketika permintaan tanpa header yang benar diblokir oleh eBay.
Namun, pendekatan ini hanya berfungsi untuk proyek kecil (mengikis beberapa lusin URL).
Untuk meningkatkan skala proyek kami dan mengumpulkan jutaan detail produk yang kami gunakan API pengikis. Solusi ini dirancang untuk membantu Anda mengatasi tantangan ini dengan mudah. Ini juga menangani rotasi IP, memastikan proses pengikisan Anda berjalan lancar dan tanpa gangguan apa pun.
Memulai ScraperAPI
Menggunakan ScraperAPI sangatlah mudah. Yang perlu Anda lakukan hanyalah mengirimkan URL situs web yang ingin Anda gores beserta kunci API Anda. Begini Cara kerjanya:
- Mendaftar ke ScraperAPI: Buka halaman dasbor ScraperAPI dan daftar akun baru. Ini termasuk 5.000 kredit API gratis selama 7 hari sehingga Anda dapat menjelajahi fitur-fitur layanan.
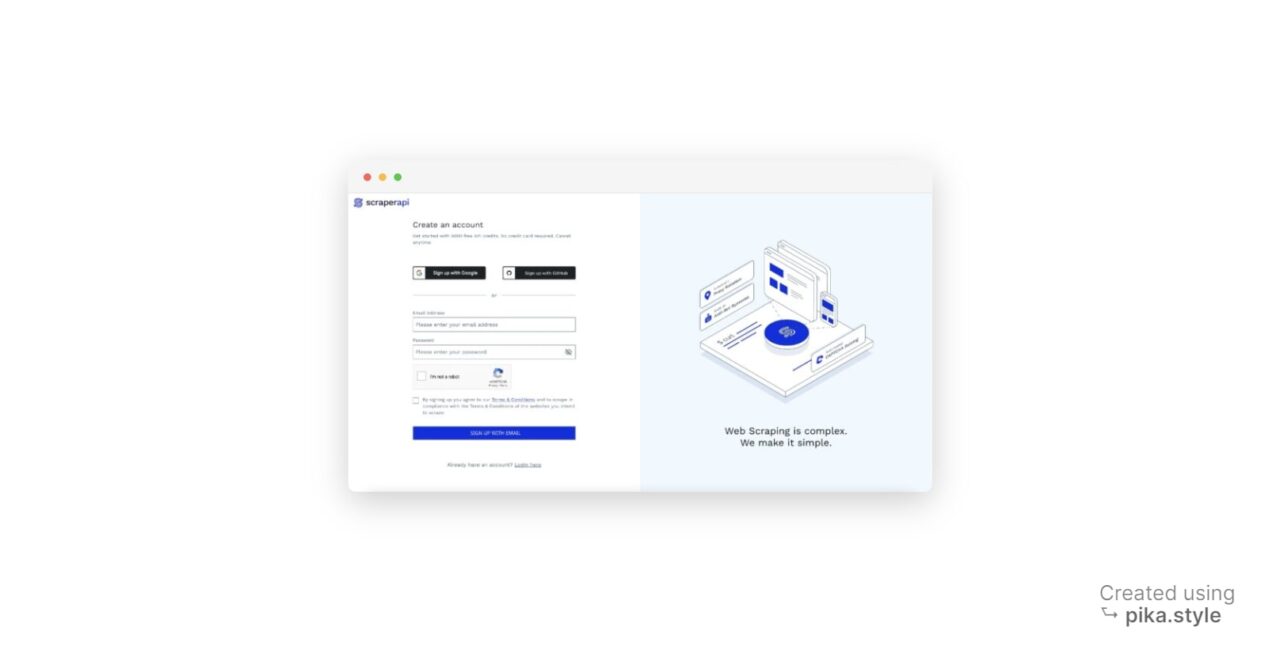
- Dapatkan kunci API Anda: Saat Anda mendaftar, Anda akan menerima kunci API Anda.
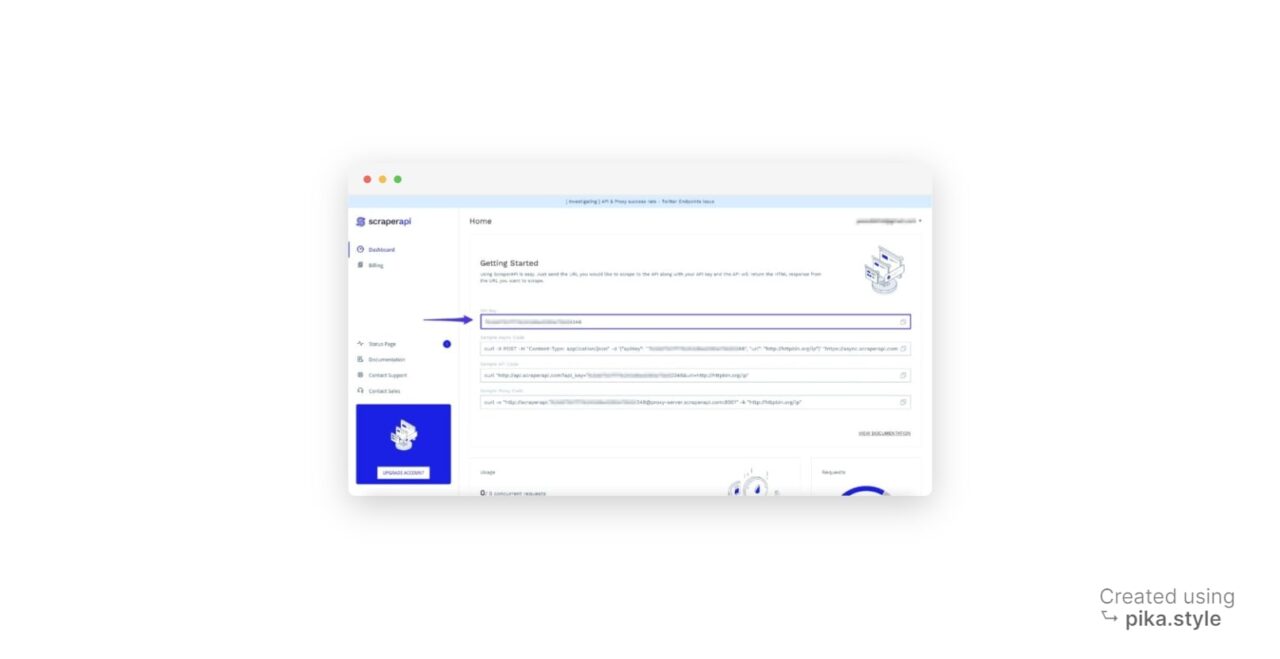
Sekarang Anda dapat mengakses hasil pencarian eBay menggunakan kode berikut.
catatan: Pengganti KUNCI API dalam kode dengan kunci API ScraperAPI Anda sendiri.
import requests
import json
from bs4 import BeautifulSoup
API_KEY = "YOUR_API_KEY"
url = "https://www.ebay.com/sch/i.html?_from=R40&_trksid=p4432023.m570.l1312&_nkw=airpods+pro&_sacat=0"
payload = {"api_key": API_KEY, "url": url}
r = requests.get("http://api.scraperapi.com", params=payload)
html_response = r.text
soup = BeautifulSoup(html_response, "lxml")
result_list = ()
# Find all product items on the page
listings = soup.find_all("div", class_="s-item__info clearfix")
images = soup.find_all("div", class_="s-item__wrapper clearfix")
for listing, image_container in zip(listings, images):
title = listing.find("div", class_="s-item__title").text
price = listing.find("span", class_="s-item__price").text
product_url = listing.find("a")
link = product_url("href")
product_status_element = listing.find("div", class_="s-item__subtitle")
product_status = (
product_status_element.text
if product_status_element is not None
else "No status available"
)
if title and price:
title_text = title.strip()
price_text = price.strip()
status = product_status.strip()
image = image_container.find("img")
image_url = image("src")
result_dict = {
"title": title_text,
"price": price_text,
"image_url": image_url,
"status": status,
"link": link,
}
result_list.append(result_dict)
# print(result_list)
# Output the result in JSON format
output_json = json.dumps(result_list, indent=2)
# Write the JSON data to a file
with open("ebay_results.json", "w", encoding="utf-8") as json_file:
json_file.write(output_json)
print("JSON data has been written to ebay_results.json")
Ini adalah output seperti yang ditunjukkan pada gambar ebay_results.json mengajukan
(
{
"title": "Apple AirPods Pro",
"price": "$200.00",
"image_url": "https://ir.ebaystatic.com/rs/v/fxxj3ttftm5ltcqnto1o4baovyl.png",
"status": "Brand New",
"link": "https://ebay.com/itm/123456?hash=item28caef0a3a:g:E3kAAOSwlGJiMikD&amdata=enc%3AAQAHAAAAsJoWXGf0hxNZspTmhb8%2FTJCCurAWCHuXJ2Xi3S9cwXL6BX04zSEiVaDMCvsUbApftgXEAHGJU1ZGugZO%2FnW1U7Gb6vgoL%2BmXlqCbLkwoZfF3AUAK8YvJ5B4%2BnhFA7ID4dxpYs4jjExEnN5SR2g1mQe7QtLkmGt%2FZ%2FbH2W62cXPuKbf550ExbnBPO2QJyZTXYCuw5KVkMdFMDuoB4p3FwJKcSPzez5kyQyVjyiIq6PB2q%7Ctkp%3ABlBMULq7kqyXYA"
},
{
"title": "Apple AirPods Pro 2nd Generaci\u00f3n PRECINTADOS",
"price": "USD213.60",
"image_url": "https://i.ebayimg.com/thumbs/images/g/uYUAAOSwAnRlOs3r/s-l300.webp",
"status": "Totalmente nuevo",
"link": "https://www.ebay.com/itm/296009215198?hash=item44eb862cde:g:uYUAAOSwAnRlOs3r&amdata=enc%3AAQAIAAAA4C51eeZHbaBu1XSPHR%2Fnwuf7F8cSg34hoOPgosNeYJP9vIn%2F26%2F3mLe8lCmBlOXTVzw3j%2FBwiYtJw9uw7vte%2FzAb35Chru0UMEOviXuvRavQUj8eTBCYWcrQuOMtx1qhTcAscv4IBqmJvLhweUPpmd7OEzGczZoBuqmb%2B9iUbmTKjD74NWJyVZvMy%2B02JG1XUhOjAp%2BVNNLH0dU%2Bke530dAnRZSd1ECJpxuqSJrH8jn6WcvuPHt4YRVzKuKzd8DBnu%2F0q%2FwkEkBBYy8AlLKj6RuRf4BOimd5C5QFRRey1p9D%7Ctkp%3ABFBMoLnxs_Ni"
},
{
"title": "Apple AirPods Pro 2da Generaci\u00f3n con Estuche de Carga Inal\u00e1mbrico MagSafe - SELLADO",
"price": "USD74.24",
"image_url": "https://i.ebayimg.com/thumbs/images/g/ce4AAOSwA6NlP5jN/s-l300.webp",
"status": "Totalmente nuevo",
"link": "https://www.ebay.com/itm/155859459163?hash=item2449f29c5b:g:ce4AAOSwA6NlP5jN&amdata=enc%3AAQAIAAAA4A9XuJkJREhc3yfSLaVZvBooRWQQJkXbWAXmnSwndqFI7UgsJgH2U98ZoS6%2BiExiDMoeL6W7E6l7y9KCZDHdxwCixGLPwJKvM7WiZNcXhuH5NsSgCjcvJt56K%2BXCLMuQhmJvfih%2BWeZlqRXTwfUKDE0NMNSXE98u1tAOMohQ1skdT%2FKS7RDJ7Dpo%2BcGb1ZCt9KRAoNMKOkmnr5BVTMHFpzAOOC6fQAlRFt8e5yXrlZYwbyMchnboMF3F3xODe5dEvxv3YiHinOAoLl93pNmz1Yn1ToO%2FrIef4ZCbsiECkfk3%7Ctkp%3ABFBMoLnxs_Ni"
},
{
"title": "AURICULARES BLUETOOTH APPLE AIRPODS PRO AURICULARES CON ESTUCHE DE CARGA INAL\u00c1MBRICA",
"price": "USD80.99",
"image_url": "https://i.ebayimg.com/thumbs/images/g/v78AAOSw-NFkS37t/s-l300.webp",
"status": "De segunda mano",
"link": "https://www.ebay.com/itm/144890564294?hash=item21bc268ec6:g:v78AAOSw-NFkS37t&amdata=enc%3AAQAIAAAA4LD7XbJuhs0J9HL02DzzbH8fZ7T5wxLjkMhC2%2B%2Bwg5WrsH3ni7TcbBIqImnuOYtcDKznUPm%2F2%2FHNoD43mA6%2Ffw23995rH3%2BW9Wb5QPimLoCn3cA1PUbPBO6zG99gyg04JbxmtGH6f%2FYaZlfXVo3vWLvSqwux3ZsP1okWWuuz5y1OjJvXQB9ACVoLSCC6au2RpqS3DdOPwi%2FGrP0Osj44XNbT8UHtSKF6N%2FmbqNTLXoaJVunBjlnpjvE%2BPTKAxSuFX3GvptHXOqFCKAkdKpmH8%2BW8hRTX0q9gVxv9Nw6epsC%2B%7Ctkp%3ABFBMoLnxs_Ni"
},
{
"title": "Auriculares AirPods Pro 2 Bluetooth con estuche de carga inal\u00e1mbrica MagSafe para tel\u00e9fonos",
"price": "USD58.53",
"image_url": "https://i.ebayimg.com/thumbs/images/g/ol8AAOSw~e9lLfXD/s-l300.webp",
"status": "Nuevo (otro)",
"link": "https://www.ebay.com/itm/295718525142?hash=item44da3298d6:g:ol8AAOSw~e9lLfXD&amdata=enc%3AAQAIAAAA4GHg1xYgyvcQRhTwQRVL2l5CvX3zSMsR281hXacuujxxm9F%2F5pYTo9aEp9ZL7e8jsJB9qlUMUF7kLuYgPHFoEh%2B0qQtajGFWTi3NqY3h8vYwhFCWqITUnrV%2BhJ0voFK4qvh3CmnzDVbYnkYPY36OehktFXjrS%2B6WWx24w7a1TXAJSCwEi0Oh9SWqDyrkSH19m7Ft0t2gMq3EpMYy7IidY2HOfQkZe7MUpHNqVoUnzaNiKv129JAfiWGkOPtwABqRt2b09iKMpoPjTfPUIHMj%2F5yL97%2B%2BCj5A4zGc5TRPsIrG%7Ctkp%3ABFBMoLnxs_Ni"
},
)
Dengan ScraperAPI, Anda dapat fokus mengekstrak data eBay yang berharga tanpa khawatir diblokir atau selalu memperbarui scraper Anda dengan teknik anti-bot eBay yang terus berkembang.
Anda dapat menggunakan data yang dikumpulkan untuk melakukan berbagai analisis dan menggunakannya untuk tujuan spesifik Anda, termasuk perbandingan harga dan riset pasar.
Ringkasan
Tutorial ini memberikan gambaran singkat tentang cara mengekstrak data dari eBay menggunakan Python. Sudah termasuk:
- Langkah-langkah yang terlibat dalam scraping eBay termasuk mengirimkan permintaan HTTP, menguraikan respons HTML dengan BeautifulSoup, dan menggunakan ScraperAPI untuk melakukan tindakan anti-bot.
- Pahami struktur situs eBay
- Gunakan header khusus untuk memastikan respons berhasil dengan volume lebih sedikit
- Cara Mengekstrak Detail Produk dari eBay
Jika Anda siap untuk meningkatkan pengumpulan data hingga ribuan atau bahkan jutaan halaman, pertimbangkan paket bisnis ScraperAPI, yang menawarkan fitur lanjutan, dukungan premium, dan manajer akun.
Apakah Anda memerlukan lebih dari 10 juta kredit API? Hubungi bagian penjualan untuk paket yang disesuaikan.
Jika Anda memiliki pertanyaan lebih lanjut atau butuh bantuan, jangan ragu untuk menghubungi kami!
Sampai jumpa lagi, selamat menggores!