
Lebih dari 7,59 juta situs web aktif menggunakan Cloudflare. Jika Anda tidak tahu, itu angka yang besar! Dan kemungkinan Anda menemukan situs web yang dilindungi Cloudflare sangat tinggi.
Jika Anda telah mencoba memindai situs web tersebut, Anda mungkin sudah tahu betapa sulitnya melewati sistem deteksi bot otomatis Cloudflare. Hari ini Anda beruntung karena Anda akan belajar cara menggunakan Python untuk menelusuri situs web yang dilindungi Cloudflare.
Untuk melakukan ini, Anda menggunakan proyek sumber terbuka yang luar biasa, Cloudscraper. Pada akhirnya, Anda juga akan melihat keterbatasan proyek ini dan mengapa ScraperAPI merupakan alternatif yang lebih kuat dan andal dibandingkan Cloudscraper.
catatan: Cloudflare terus-menerus mengubah sistem deteksi botnya dan menghancurkan proyek sumber terbuka seperti Cloudscraper. Jika Anda menghargai waktu Anda dan memiliki pekerjaan scraping berukuran besar yang memerlukan penskalaan atau penjadwalan interval, pertimbangkan untuk menggunakan ScraperAPI. Alat ini memungkinkan Anda menelusuri domain di banyak thread secara bersamaan tanpa diblokir oleh pemblokir Cloudflare.
Daftar Isi
Cara menggunakan Cloudscraper untuk mengikis situs web yang dilindungi Cloudflare
Mari kita lihat cara menyiapkan proyek cloud scraper untuk mengikis halaman Glassdoor dalam skala kecil.
Jika Anda adalah pengguna web scraping tingkat lanjut, Anda harus beralih ke metode lain yang dijelaskan dalam artikel – menggunakan ScraperAPI. Dengan menggunakan API, Anda dapat mencapai skalabilitas yang lebih besar, menjadwalkan pekerjaan, dan mengotomatiskan scraping situs web yang dilindungi Cloudflare.
Langkah 1. Menyiapkan prasyarat
Pastikan Python diinstal pada sistem Anda. Untuk tutorial ini Anda dapat menggunakan Python versi 3.6 atau lebih tinggi. Buat direktori baru untuk menyimpan semua kode untuk proyek ini dan buat a app.py Berkas di:
$ mkdir web_scraper
$ cd web_scraper
$ touch app.py
Selanjutnya Anda perlu menginstal cloudscraper Dan requests. Ini mudah dilakukan melalui PIP:
$ pip install cloudscraper requests
Langkah 2. Buat permintaan sederhana menggunakan Permintaan
Dalam tutorial ini Anda akan mengikis Glassdoor. Seperti inilah tampilan beranda Glassdoor:
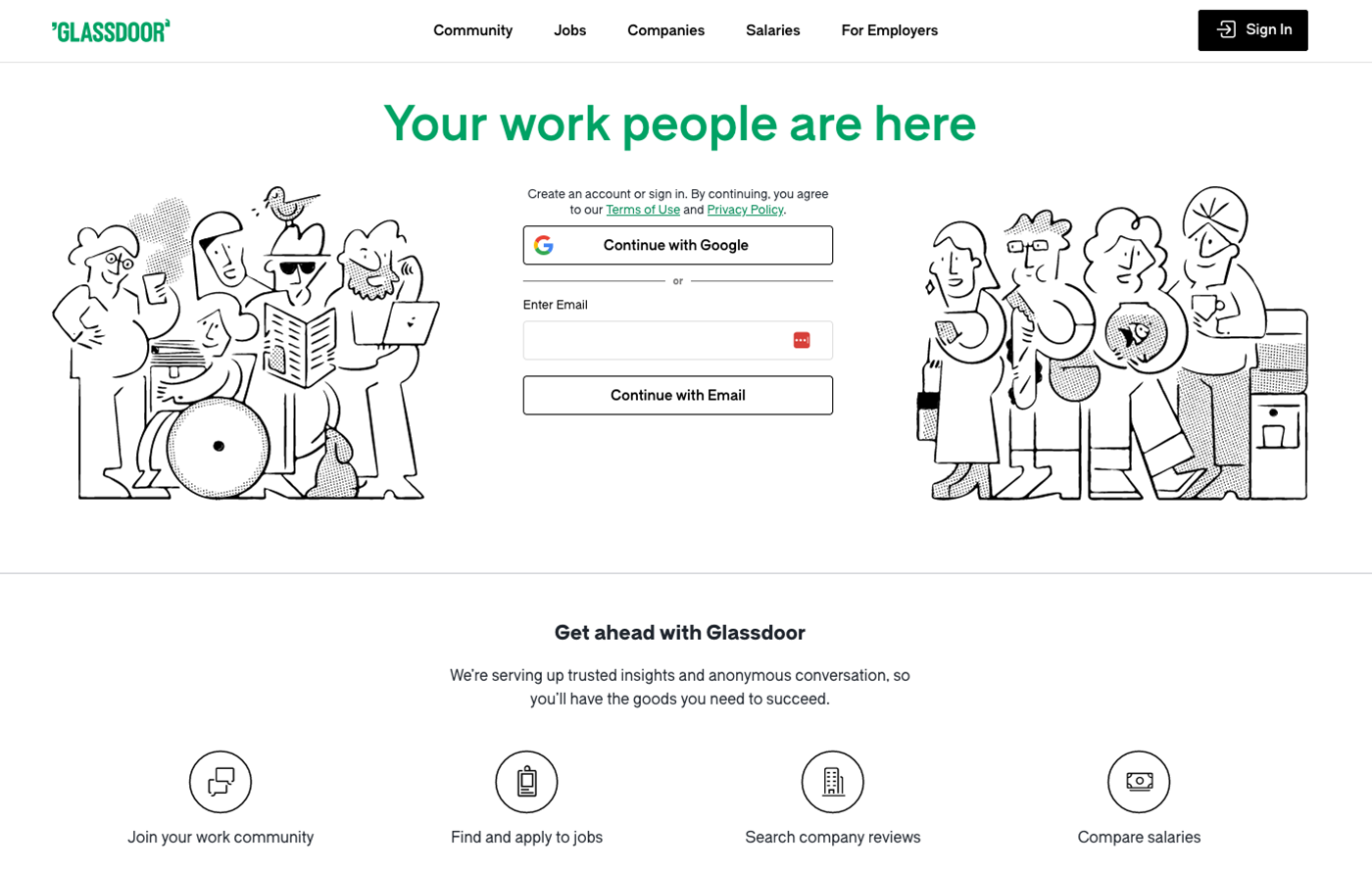
Situs web ini dilindungi oleh Cloudflare dan tidak dapat dihapus dengan mudah melalui permintaan. Anda dapat mengonfirmasi hal ini dengan membuat yang sederhana GET Pertanyaan dengan requests seperti ini:
import requests
html = requests.get("https://www.glassdoor.com/")
print(html.status_code)
# 403
Seperti yang diharapkan, Glassdoor mengembalikan kode status 403 Terlarang dan bukan hasil pencarian sebenarnya. Kode status ini dikembalikan oleh sistem deteksi bot Cloudflare yang digunakan Glassdoor. Anda dapat menyimpan jawabannya ke file lokal dan membukanya di browser Anda untuk lebih memahami apa yang terjadi.
Anda dapat menyimpan jawabannya menggunakan kode ini:
with open("response.html", "wb") as f:
f.write(html.content)
Saat Anda membuka response.html Saat Anda membuka file di browser Anda, Anda akan melihat sesuatu seperti ini:
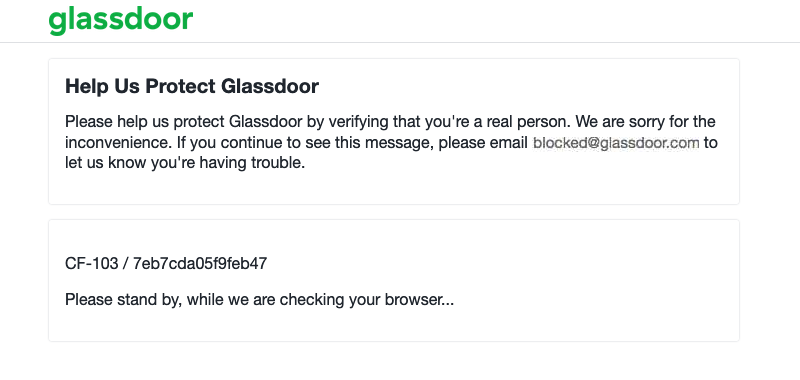
Sekarang setelah Anda mengetahui bahwa situs web target Anda dilindungi oleh Cloudflare, apakah Anda memiliki cara yang tepat untuk menyiasatinya?
Langkah 3. Kikis Glassdoor.com dengan Cloudscraper
Untungnya, di sinilah Cloudscraper berperan. Ini berbasis permintaan dan memiliki logika cerdas untuk mengurai halaman tantangan yang dikembalikan oleh Cloudflare dan mengirimkan respons yang sesuai agar berhasil mengatasi masalah tersebut. Batasan terbesarnya adalah ia hanya dapat melewati deteksi bot Cloudflare versi 1 dan bukan versi 2. Namun jika website target Anda menggunakan deteksi bot versi 1, ini adalah solusi yang sangat masuk akal. Kami akan membahas batasan ini secara rinci pada langkah berikutnya.
Fakta penting lainnya adalah Cloudscraper tidak menjalankan mesin browser lengkap secara default. Oleh karena itu, ini jauh lebih cepat dibandingkan solusi serupa lainnya berdasarkan browser tanpa kepala atau emulasi browser.
catatan: Jika Anda mencoba merayapi situs web yang menggunakan sistem deteksi bot Cloudflare versi 2, Anda dapat menghemat waktu dan melompat ke akhir tutorial ini dan mempelajari tentang ScraperAPI karena ini adalah solusi yang mungkin untuk kasus penggunaan Anda.
Mari kita ulangi hal yang sama GET Permintaan ke Glassdoor.com, tapi kali ini dengan Cloudscraper. Buka REPL Python dan masukkan kode ini:
import cloudscraper
scraper = cloudscraper.create_scraper()
html = scraper.get("https://www.glassdoor.com/")
print(html.status_code)
# 200
Manis! Cloudflare tidak memblokir permintaan kami kali ini. Seperti pada langkah sebelumnya, simpan HTML ke file lokal dan buka di browser Anda. Anda akan melihat beranda Glassdoor. UI-nya agak aneh karena tautan CSS dan JS rusak (karena kami tidak menyimpan CSS dan JSON secara lokal), tetapi semua data ada di sana:

Dengan mengubah beberapa baris kode, Anda dapat melewati sistem deteksi bot Cloudflare!
Langkah 4. Gunakan opsi lanjutan Cloudscraper
Cloudscraper menawarkan berbagai opsi yang dapat dikonfigurasi. Mari kita lihat beberapa di antaranya.
4.1 Dukungan bawaan untuk pemecah captcha
Cloudscraper memiliki dukungan bawaan untuk beberapa pemecah captcha pihak ketiga jika Anda membutuhkannya. Misalnya, jika permintaan Anda mencapai halaman captcha, Anda dapat dengan mudah menghubungkan 2captcha dengan Cloudscraper sebagai penyedia solusi captcha:
scraper = cloudscraper.create_scraper(
captcha={
'provider': '2captcha',
'api_key': 'your_2captcha_api_key'
}
)
Hingga saat ini, Cloudscraper mendukung layanan Captcha berikut:
4.2 Menggunakan Proksi Khusus
Dalam kebanyakan kasus, Anda ingin merutekan semua lalu lintas yang tergores melalui proxy. Ini memastikan bahwa alamat IP asli Anda disamarkan dan tidak diblokir oleh situs web target karena permintaan yang berlebihan. Untungnya, Cloudscraper menyediakan dukungan untuk menggunakan proxy khusus. Ini adalah efek samping dari fakta bahwa Cloudscraper didasarkan pada hal yang menakjubkan requests Perpustakaan.
Jika Anda ingin menggunakan proksi khusus dengan Cloudscraper, Anda dapat menentukan kamus yang berisi titik akhir proksi HTTP dan HTTPS dan Cloudscraper akan memastikan bahwa semua permintaan di masa mendatang menggunakan kamus yang sesuai. Berikut ini beberapa kode yang menunjukkan hal ini:
import cloudscraper
proxies = {"http": "http://localhost:8080", "https": "http://localhost:8080"}
scraper = cloudscraper.create_scraper()
scraper.proxies.update(proxies)
html = scraper.get("https://www.glassdoor.com/")
print(html.status_code)
# 200
Anda dapat lebih meningkatkan pengaturan proksi khusus ini dengan menambahkan logika untuk merotasi proksi. Lihat artikel lain di situs web kami untuk mempelajari cara melakukan ini.
4.3 Ekstrak token Cloudflare saja
Jika Anda melewati deteksi bot Cloudflare, Cloudflare merespons dengan cookie yang harus diteruskan ke situs web target di semua permintaan berikutnya. Cookie ini memberi tahu Cloudflare bahwa browser Anda telah melewati tantangan deteksi bot dan seharusnya lulus tanpa tantangan lebih lanjut. Cloudscraper menyediakan metode mudah untuk mengekstraksi cookie ini (atau token yang dikandungnya). Inilah cara Anda menggunakannya:
import cloudscraper
tokens, user_agent = cloudscraper.get_tokens("https://www.glassdoor.com/")
print(tokens)
# {
# 'cf_clearance': 'c8f913c707b818b47aa328d81cab57c349b1eee5-1426733163-3600',
# '__cfduid': 'dd8ec03dfdbcb8c2ea63e920f1335c1001426733158'
# }
cookie_value, user_agent = cloudscraper.get_cookie_string("https://www.glassdoor.com/")
print(cookie_value)
# cf_clearance=c8f913c707b818b47aa328d81cab57c349b1eee5-1426733163-3600; __cfduid=dd8ec03dfdbcb8c2ea63e920f1335c1001426733158
Ini sangat berguna karena Cloudscraper memungkinkan Anda melewati sistem deteksi bot dan kemudian menggunakan cookie yang dihasilkan dengan permintaan tindak lanjut dari kode web scraping yang sudah ada. Yang perlu Anda lakukan adalah memastikan bahwa permintaan tindak lanjut dihasilkan dari IP yang sama yang digunakan untuk melewati sistem deteksi bot. Jika IP berbeda, Cloudflare akan memblokir permintaan Anda dan meminta Anda mengonfirmasi ulang.
Batasan Cloudscraper: Saat menggores situs web yang dilindungi Cloudflare tidak dapat dilakukan
Kami telah menyebutkan bahwa Cloudscraper memiliki beberapa keterbatasan dan fakta bahwa Cloudscraper tidak dapat memindai situs web yang dilindungi oleh Cloudflare Bot Detection v2 merupakan kelemahan utama. Ini adalah versi terbaru dari deteksi bot Cloudflare dan saat ini digunakan oleh banyak situs web. Salah satu situs web tersebut adalah Penulis.
Berikut tampilan beranda penulis:
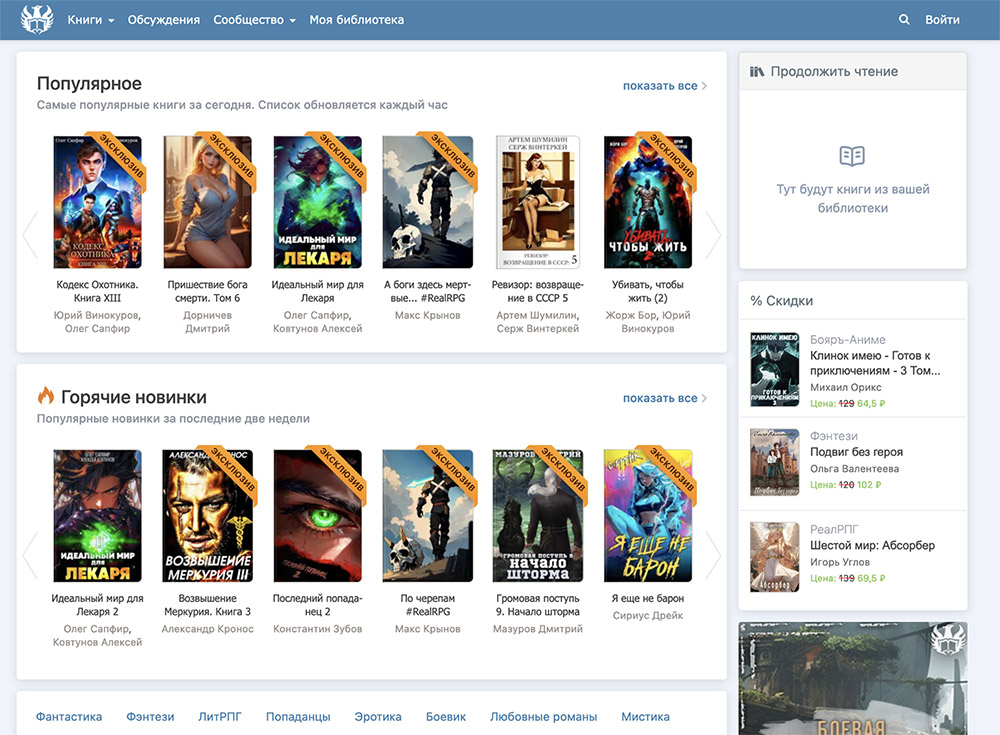
Saat Anda mencoba mengekstrak data dari situs web ini menggunakan Cloudscraper, Anda menerima pengecualian berikut:
cloudscraper.exceptions.CloudflareChallengeError: Detected a Cloudflare version 2 challenge, This feature is not available in the opensource (free) version.
Meskipun pengecualian ini menunjukkan adanya Cloudscraper versi berbayar, sebenarnya tidak ada. Sayangnya, Cloudscraper benar-benar rusak karena algoritma pendeteksian bot terbaru yang digunakan oleh Cloudflare.
Alternatif untuk Cloudscraper
Jika Anda ingin mengikis situs web yang saat ini tidak dapat dikikis oleh Cloudscraper, atau jika Anda menginginkan skalabilitas dan kinerja yang lebih baik, Anda harus mencari alternatif Cloudscraper. Salah satu alternatif terbaik yang tersedia saat ini adalah ScraperAPI.
Ini dapat menangani versi terbaru dari algoritma deteksi bot yang digunakan oleh Cloudflare dan diperbarui secara berkala dengan teknik penghindaran anti-bot baru untuk menjaga pekerjaan scraping Anda berjalan lancar.
Bagian terbaiknya adalah ScraperAPI menyediakan 5.000 kredit API gratis selama 7 hari sebagai uji coba, dan kemudian memberikan paket gratis yang berlimpah dengan 1.000 kredit API berulang untuk membuat Anda terus maju.
Anda dapat memulai dengan cepat dengan membuka halaman dasbor ScraperAPI dan mendaftar akun baru:
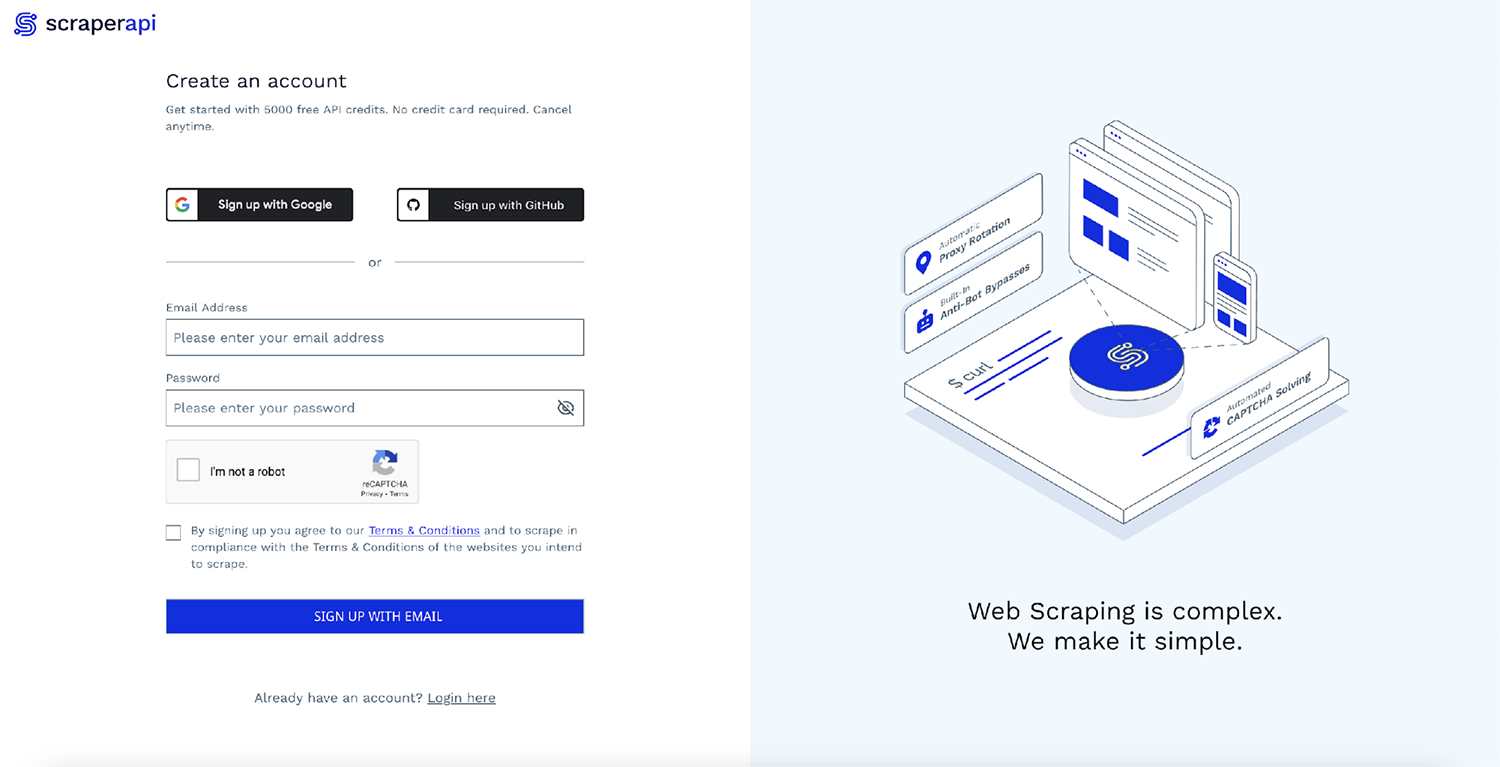
Setelah masuk, Anda akan melihat kunci API dan beberapa kode contoh:
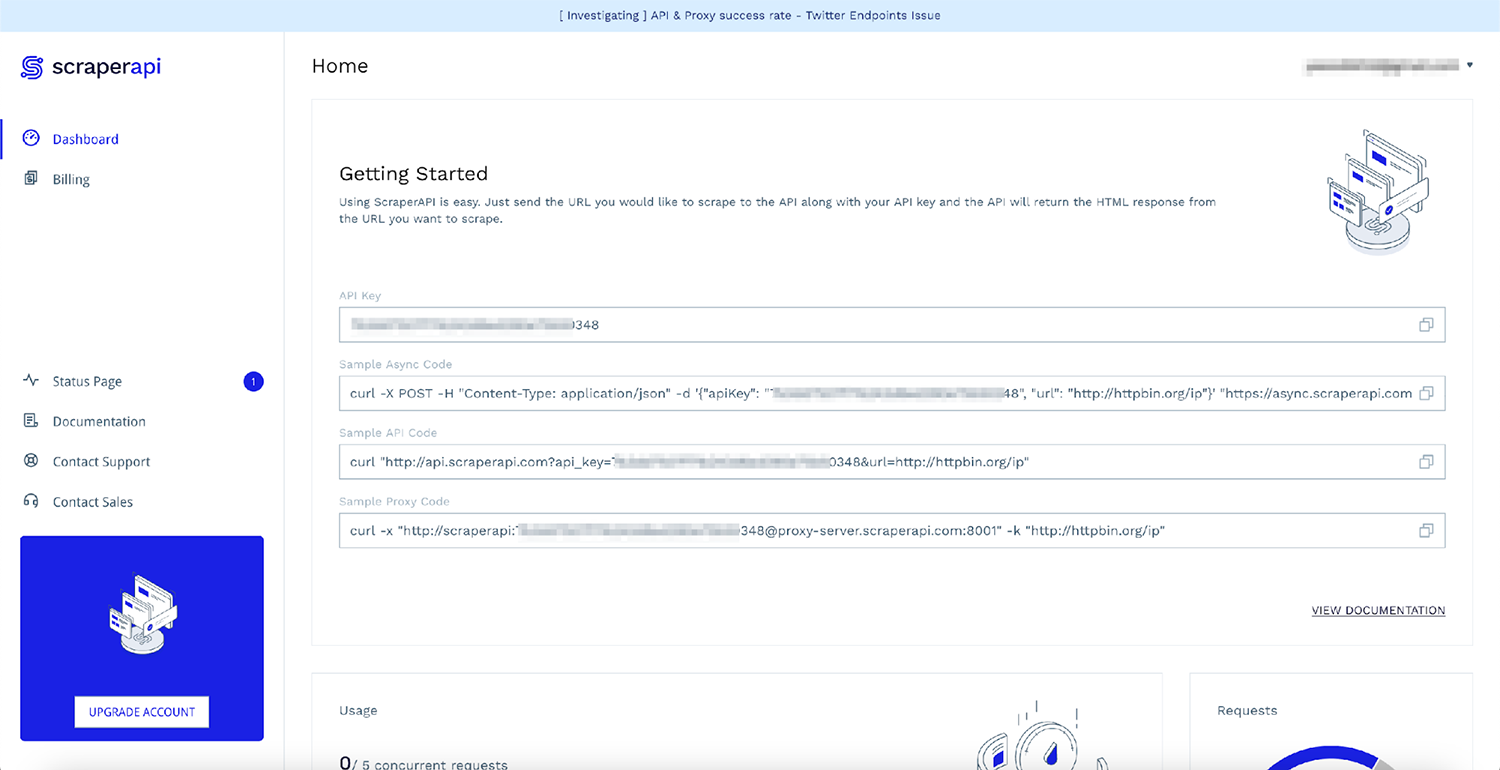
Cara tercepat untuk menggunakan ScraperAPI tanpa mengubah kode yang ada adalah dengan menggunakan ScraperAPI sebagai proxy untuk permintaan. Inilah cara Anda melakukannya:
import requests
proxies = {
"http": "http://scraperapi:[email protected]:8001"
}
r = requests.get('https://author.today/', proxies=proxies, verify=False)
print(r.text)
catatan: Jangan lupa ganti APIKEY dengan API key pribadi Anda dari dashboard.
Itu dia! Hanya dengan beberapa baris kode, Anda tidak perlu lagi memikirkan sistem deteksi bot Cloudflare. ScraperAPI memastikan bahwa ia menggunakan proxy yang tidak diblokir dan teknik canggih untuk melewati sistem deteksi bot yang ada. Sekarang Anda dapat menghabiskan lebih banyak waktu untuk fokus pada logika bisnis inti Anda.