
JavaScript adalah salah satu bahasa pemrograman paling populer untuk bekerja di Internet. Ia memiliki sumber daya yang terdokumentasi dengan baik, komunitas yang aktif, dan banyak perpustakaan untuk berbagai tujuan.
Namun, jika Anda ingin menggunakan JavaScript di luar browser web, Anda perlu menggunakan wrapper bernama Node.js. Itu sebabnya hari ini kami juga akan menjelaskan kepada Anda cara menyiapkan dan mempersiapkan lingkungan untuk pengikisan JavaScript.
Daftar Isi
Persiapan untuk web scraping dengan JavaScript
Sebelum membandingkan perpustakaan, mari kita persiapkan lingkungan di mana kita dapat menggunakan perpustakaan ini. Memilih perpustakaan akan lebih mudah jika Anda mengetahui fitur, kelebihan dan kekurangannya. Oleh karena itu, kami menunjukkan cara menggunakan setiap perpustakaan yang diulas. Namun Anda juga dapat membaca artikel kami yang lain jika Anda ingin mengekstrak data dalam bahasa lain seperti C# atau Python.
Menginstal lingkungan
Kami sebelumnya telah membahas pengaturan lingkungan untuk web scraping dengan NodeJS. Jadi kami tidak akan membahasnya lagi, cukup ingatkan Anda apa yang perlu Anda lakukan:
- Unduh NodeJS versi stabil terbaru dari situs resminya.
- Pastikan instalasi berhasil dengan memeriksa versi NodeJS yang diinstal:
node -v- Perbarui NPM:
npm install -g npm- Inisialisasi NPM:
npm init -yKami tidak membutuhkan apa pun lagi. Kami akan menggunakan Visual Studio Code sebagai editor kode, tetapi editor teks apa pun juga bisa berfungsi, misalnya Sublime.
Meneliti struktur situs web
Kami menggunakan situs demo ini untuk membuat contoh penggunaan perpustakaan lebih jelas. Mari kita lihat secara detail. Untuk melakukan ini, buka situs web dan buka DevTools (F12 atau klik kanan pada halaman dan pilih “Inspeksi”).
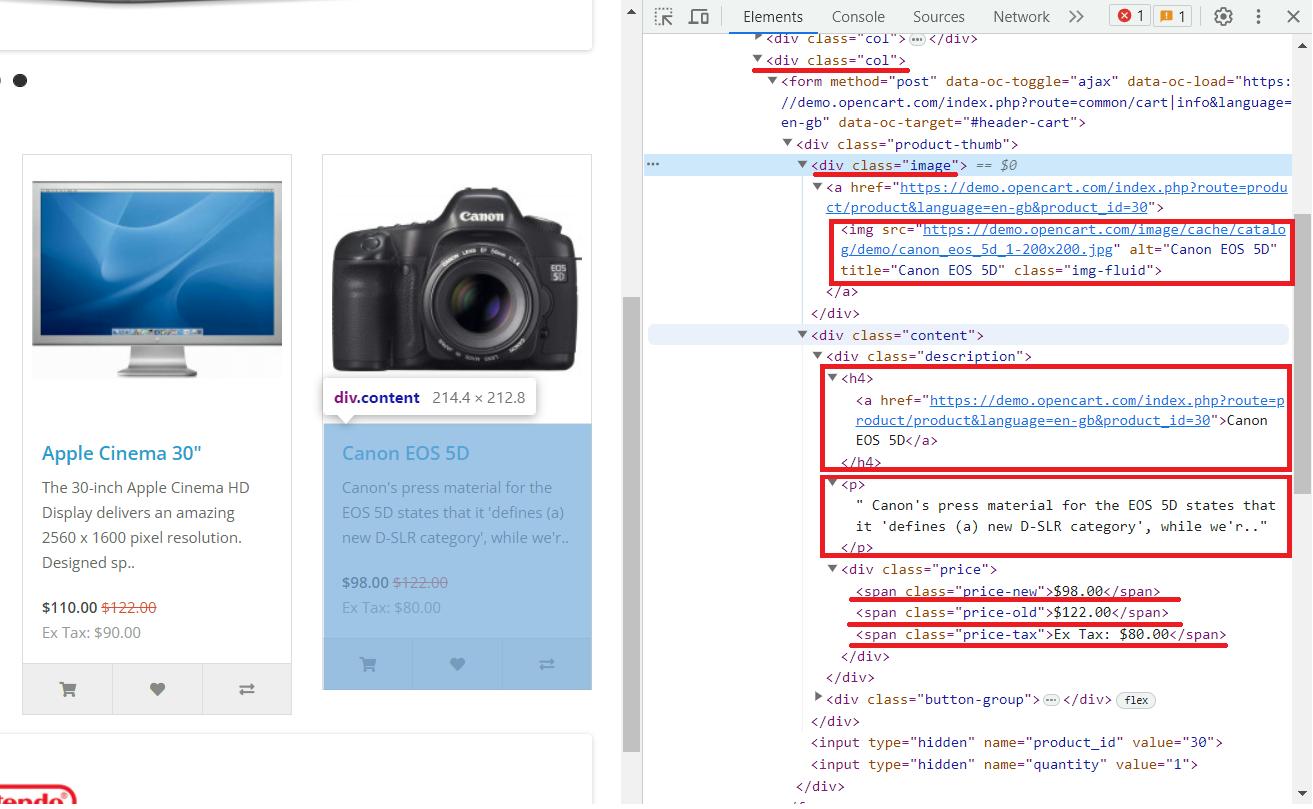
Setelah menganalisis halaman tersebut, kita dapat menarik kesimpulan berikut:
- Setiap produk ada div tag dengan kelas “
col„. - Gambar produk terletak pada tag img pada atribut src.
- Nama produk ada di sana
<h4>Label. - Deskripsi produk disertakan
<p>Label. - Harga lama sudah masuk
<span>Hari bersama kelas “price-old„. - Harga baru sudah masuk
<span>Hari bersama kelas “price-new„. - Pajak ada di
<span>Hari bersama kelas “price-tax„.
Sekarang setelah lingkungan kita menyiapkan dan menganalisis halaman tempat kami menampilkan fungsi berbagai perpustakaan, kita dapat menjelajahi perpustakaan web scraping JavaScript.
Memilih perpustakaan JavaScript terbaik untuk web scraping

Ada terlalu banyak paket NPM yang dapat Anda gunakan untuk mengikis data dan kami tidak dapat meninjau semuanya. Namun jika kita memilih yang paling nyaman dan populer, ini dia:
- Aksio dengan Cheerio. Axios adalah perpustakaan JavaScript populer untuk mengirim permintaan HTTP dan Cheerio adalah perpustakaan yang cepat dan fleksibel untuk menguraikan HTML. Bersama-sama, mereka menyediakan cara mudah untuk mengeksekusi permintaan HTTP dan mengurai HTML dalam tugas web scraping. Alih-alih Axios, kita bisa menggunakan perpustakaan kueri apa pun, seperti Unirest. Ini adalah perpustakaan yang ringan dan mudah digunakan untuk menjalankan permintaan HTTP.
- Scrape-It.Cloud SDK. Ini adalah perpustakaan yang memungkinkan Anda mengikis situs web dinamis dan statis, menangani bypass captcha dan pemblokir, dan menawarkan kemungkinan menggunakan proxy.
- Dalang adalah perpustakaan otomatisasi browser yang banyak digunakan. Oleh karena itu, ini sangat berguna dalam web scraping.
- Selenium adalah sistem otomasi lintas browser yang mendukung berbagai bahasa pemrograman, termasuk JavaScript. Kami telah membicarakan hal ini dengan Python dan R.
- X-Ray adalah perpustakaan JavaScript untuk pengikisan web dan ekstraksi data.
- Playwright adalah otomatisasi browser tanpa kepala dan lingkungan pengujian yang dikembangkan oleh Microsoft.
Mari kita lihat setiap perpustakaan untuk mengetahui perpustakaan mana yang terbaik dan membuat keputusan yang tepat.
Axios dan Cheerio
Pustaka scraping JavaScript yang paling mudah diakses adalah Cheerio. Namun, karena tidak dapat menjalankan kueri situs, ini digunakan dengan pustaka kueri seperti Axios. Bersama-sama, perpustakaan ini banyak digunakan dan bagus untuk pemula.
Keuntungan
Ini adalah perpustakaan web scraping Javascript luar biasa yang bagus untuk pemula. Ia menawarkan fungsi parsing dan pemrosesan halaman web yang ekstensif. Mudah dipelajari, memiliki sumber daya yang terdokumentasi dengan baik, dan merupakan komunitas yang sangat aktif. Ini berarti Anda selalu dapat menemukan bantuan dan dukungan meskipun Anda menghadapi masalah.
Kekurangan
Sayangnya, perpustakaan ini hanya cocok untuk menggores halaman statis. Karena digunakan dengan pustaka kueri, tidak mungkin mengambil data dari halaman dengan konten yang dihasilkan secara dinamis. Jadi Anda bisa menggunakannya untuk membuat parser yang bagus.
Contoh alat pengikis
Sebelum menggunakan perpustakaan ini, mari instal paket npm yang diperlukan:
npm install axios
npm install cheerio Sekarang buat file *.js baru untuk menulis skrip kita. Impor perpustakaan terlebih dahulu:
const axios = require('axios');
const cheerio = require('cheerio');Sekarang mari kita menanyakan situs demo dan membuat penangan kesalahan.
axios.get('https://demo.opencart.com/')
.then(response => {
// Here will be code
})
.catch(error => {
console.log(error);
});Kami telah secara khusus menandai di mana kami akan terus menulis kode. Yang perlu kita lakukan hanyalah mengurai HTML halaman yang dihasilkan dan menampilkan datanya di layar. Mari kita mulai menguraikan:
const html = response.data;
const $ = cheerio.load(html);
console.log($.text())
const elements = $('.col'); Di sini kita telah memilih elemen dengan kelas “.col”. Kita telah membahas hal ini selama analisis halaman - semua produk memiliki kelas induk “.col”. Sekarang mari kita lihat setiap item yang ditemukan dan dapatkan data spesifik untuk setiap produk:
elements.each((index, element) => {
const image = $(element).find('img').attr('src');
const title = $(element).find('h4').text();
const link = $(element).find('h4 > a').attr('href');
const desc = $(element).find('p').text();
const old_p = $(element).find('span.price-old').text();
const new_p = $(element).find('span.price-new').text();
const tax = $(element).find('span.price-tax').text();
// Here will be code
});Hal terakhir yang perlu kita tambahkan adalah menampilkan item saat kita menelusurinya.
console.log('Image:', image);
console.log('Title:', title);
console.log('Link:', link);
console.log('Description:', desc);
console.log('Old Price:', old_p);
console.log('New Price:', new_p);
console.log('Tax:', tax);
console.log('');Sekarang ketika kita menjalankan skrip kita mendapatkan hasil sebagai berikut:
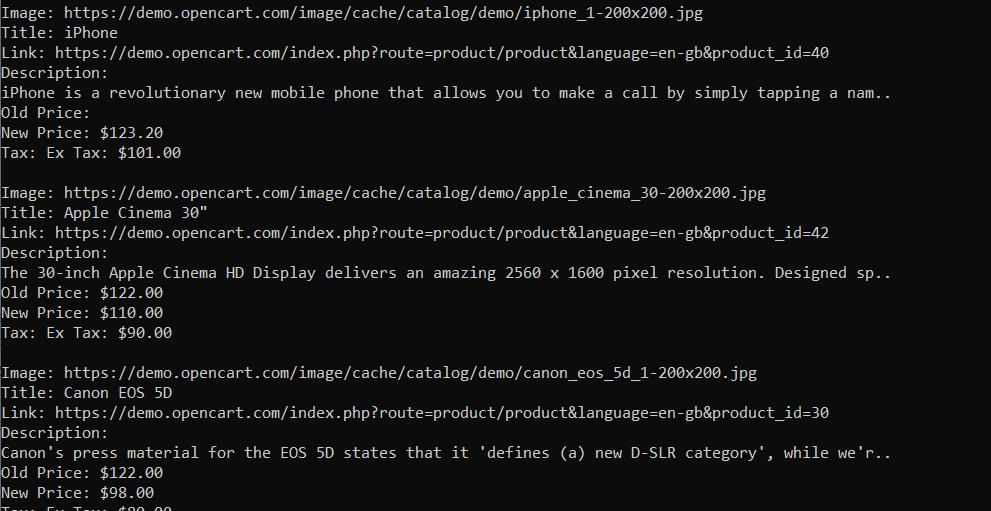
Seperti yang bisa kita lihat, kita telah memperoleh data pada semua elemen. Sekarang Anda dapat mengeditnya lebih lanjut atau, misalnya, menyimpannya dalam file CSV. Axios dan Cheerio menawarkan fungsionalitas pengikisan yang luar biasa. Dan jika Anda seorang pemula, memilih perpustakaan ini untuk web scraping adalah keputusan yang baik. Jika Anda ingin mempelajari lebih lanjut tentang alat ini, Anda dapat membaca artikel kami tentang scraping dengan Axios dan Cheerio.
Scrape-It.Cloud SDK
Opsi lain yang ideal untuk pemula adalah Scrape-It.Cloud SDK. Ini juga lebih sederhana (dan bahkan lebih sederhana) untuk digunakan daripada Axios dan Cheerio, sekaligus menawarkan lebih banyak fungsionalitas daripada perpustakaan yang akan kita lihat selanjutnya.
Keuntungan
Scrape-It.Cloud SDK sangat bagus untuk menyalin situs web statis dan dinamis. Karena kami mengembangkan perpustakaan web scraping ini menggunakan JavaScript dan didasarkan pada API web scraping, perpustakaan ini menawarkan beberapa keunggulan dibandingkan perpustakaan lain. Ini mengadopsi solusi captcha dan membantu menghindari pemblokiran dan penggunaan proxy.
Yang perlu dilakukan pengguna hanyalah masuk ke situs web kami dan menyalin kunci API dari akun mereka. Setelah mendaftar, Anda akan menerima kredit gratis untuk menguji fungsi dan fitur kami.
Kekurangan
Sulit bagi kami untuk membicarakan kekurangan perpustakaan kami karena kami terus mengembangkan dan menyempurnakannya. Namun, jika Anda menggunakan aturan ekstraksi untuk mengekstrak data, data tersebut akan dikembalikan dalam grup berbeda yang tidak terkait satu sama lain, yang mungkin tidak nyaman. Namun API juga mengembalikan semua kode halaman, sehingga selalu memungkinkan untuk mendapatkan data dalam bentuk yang benar.
Contoh alat pengikis
Jadi mari kita lihat contoh penggunaan perpustakaan kita. Pertama instal paket NPM yang sesuai.
npm i @scrapeit-cloud/scrapeit-cloud-node-sdkSekarang buat file skrip dan sambungkan perpustakaan:
const ScrapeitSDK = memerlukan('@scrapeit-cloud/scrapeit-cloud-node-sdk');
Tulis fungsi utama seperti contoh terakhir dan tulis blok untuk menangkap kesalahan.
(async() => {
const scrapeit = new ScrapeitSDK('YOUR-API-KEY');
try {
// Here will be code
} catch(e) {
console.log(e.message);
}
})();Sekarang yang harus Anda lakukan adalah menjalankan kueri dan menampilkan hasilnya:
const response = await scrapeit.scrape({
"extract_rules": {
"Image": "img @src",
"Title": "h4",
"Link": "h4 > a @href",
"Description": "p",
"Old Price": "span.price-old",
"New Price": "span.price-new",
"Tax": "span.price-tax"
},
"url": "https://demo.opencart.com/",
"screenshot": true,
"proxy_country": "US",
"proxy_type": "datacenter"
});
console.log(response);Outputnya adalah respon JSON dengan hasil yang sama seperti contoh terakhir. Dengan cara ini kami mendapatkan data yang sama tetapi dengan cara yang lebih sederhana.
Jika situs web berukuran kecil dan tidak memiliki perlindungan seperti captcha atau blokir, hal ini mungkin tidak terlalu terlihat. Namun, saat Anda mengekstrak data dalam jumlah besar dari situs seperti Google, Amazon, atau Zillow dalam waktu singkat, manfaat menggunakan API web scraping kami menjadi jelas.
Dalang
Dalang adalah pustaka JavaScript yang lebih kompleks untuk pengikisan web, otomatisasi, dan pengujian.
Keuntungan
Ini memungkinkan Anda memanggil browser tanpa kepala untuk mensimulasikan perilaku pengguna sebenarnya dan mengotomatiskan tugas browser. Selain itu, karena transisi halaman terjadi dan hasilnya diambil setelah halaman web dimuat, Anda tidak hanya dapat mengikis halaman web statis tetapi juga dinamis. Selain itu, Anda dapat melakukan tindakan pada halaman web, baik itu mengklik link, mengisi formulir, atau menggulir.
Kekurangan
Kekurangannya antara lain perpustakaan ini lebih sulit untuk pemula dibandingkan yang disebutkan di atas. Namun, berkat komunitas yang aktif dan beragam contoh, hal ini seharusnya tidak menjadi tantangan besar.
Contoh alat pengikis
Mari kita mulai dengan menyertakan perpustakaan, membuat fungsi dasar, dan menemukan kesalahan. Mari kita juga langsung menuju halaman tersebut dan menggunakan perintah Dalang untuk melakukan transisi. Gunakan browser “menunggu” untuk menunggu halaman web dimuat sepenuhnya.
const puppeteer = require('puppeteer');
(async function example() => {
try {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://demo.opencart.com/');
const elements = await page.$$('.col');
// Here will be code
await browser.close();
} catch (error) {
console.log(error);
}
})();Kami juga menambahkan pencarian elemen dengan kelas ".col" dan penutupan browser agar Anda tidak melupakannya di akhir. Sekarang kita dapat memeriksa semua produk dan memilih data yang kita perlukan:
for (const element of elements) {
const image = await element.$eval('img', img => img.getAttribute('src'));
const title = await element.$eval('h4', h4 => h4.textContent);
const link = await element.$eval('h4 > a', a => a.getAttribute('href'));
const desc = await element.$eval('p', p => p.textContent);
const new_p = await element.$eval('span.price-new', span => span ? span.textContent : '-');
const new_p = await element.$eval('span.price-new', span => span ? span.textContent : '-');
const tax = await element.$eval('span.price-tax', span => span ? span.textContent : '-');
console.log('Image:', image);
console.log('Title:', title);
console.log('Link:', link);
console.log('Description:', desc);
console.log('Old Price:', old_p);
console.log('New Price:', new_p);
console.log('Tax:', tax);
console.log('');
}Kami memiliki “rentang? span.textContent : '-'" digunakan untuk memeriksa konten. Misalnya, jika tidak ada harga baru, kita cukup memberi tanda “-” di elemen yang sesuai, bukan kesalahan.
Namun, jika struktur tidak memiliki pemilih seperti ".price-old", kami mendapatkan kesalahan, jadi kami mempertimbangkan opsi ini dan sedikit memperbaiki kodenya.
const old_p_element = await element.$('span.price-old');
const old_p = old_p_element ? await old_p_element.evaluate(span => span.textContent) : '-';Saat kami menjalankan kode, kami mendapatkan hasil terstruktur dengan baik tanpa kesalahan apa pun.
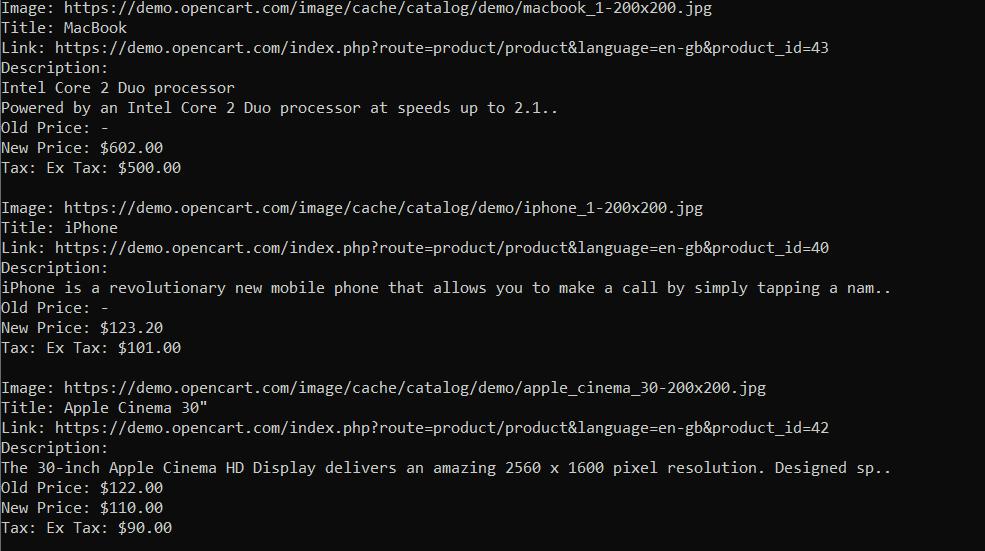
Dari pengalaman kami, menggunakan Puppeteer sangat nyaman. Ini memiliki banyak fitur, fungsi dan dokumentasi yang ditulis dengan baik dengan banyak contoh.
selenium
Selenium adalah platform sumber terbuka yang biasa digunakan untuk mengotomatisasi browser web. Selenium mendukung banyak bahasa pemrograman termasuk JavaScript, Python, Java dan C#, menjadikannya universal dan banyak digunakan.
Selenium menggunakan browser tanpa kepala yang memungkinkan Anda menyimulasikan perilaku pengguna dan melakukan tindakan di halaman web seperti yang dilakukan manusia. Hal ini membuatnya berguna dalam web scraping, pengujian aplikasi web, dan melakukan tugas situs web yang berulang.
Keuntungan
Karena popularitas dan kemudahan penggunaannya, Selenium memiliki komunitas luas dalam semua bahasa pemrograman yang didukung, termasuk JavaScript.
Pustaka JavaScript scraping web ini lebih mudah dipelajari oleh sebagian orang daripada Dalang. Ini mendukung berbagai cara untuk menemukan elemen, termasuk penyeleksi dan XPath.
Kekurangan
Kekurangannya antara lain mungkin terasa sulit untuk dipelajari sebagai programmer pemula.
Contoh alat pengikis
Pertama kita perlu menginstal paket NPM Selenium itu sendiri dan driver webnya:
npm install selenium
npm install chromedriver
npm install selenium-webdriverBerbeda dengan Puppeteer, di mana semuanya langsung diinstal dengan paket utama, Selenium memerlukan pemuatan tambahan elemen-elemen ini. Oleh karena itu, penting untuk tidak melupakan apa pun, jika tidak, kesalahan dapat terjadi saat menjalankan skrip.
Sekarang kita membuat file skrip dan mengimpor perpustakaan dan modul yang diperlukan:
const { Builder, By } = require('selenium-webdriver');
require('selenium-webdriver/chrome');
require('chromedriver');Jika tidak, penggunaan Selenium sangat mirip dengan Puppeteer, kecuali cara Anda mencari elemen tertentu. Oleh karena itu, kami segera menyarankan Anda melihat contoh yang sudah jadi:
(async () => {
try {
const driver = await new Builder().forBrowser('chrome').build();
await driver.get('https://demo.opencart.com/');
const elements = await driver.findElements(By.className('col'));
for (const element of elements) {
const image = await element.findElement(By.tagName('img')).getAttribute('src');
const title = await element.findElement(By.tagName('h4')).getText();
const link = await element.findElement(By.css('h4 > a')).getAttribute('href');
const desc = await element.findElement(By.tagName('p')).getText();
const old_p_element = await element.findElements(By.css('span.price-old'));
const old_p = old_p_element.length > 0 ? await old_p_element(0).getText() : '-';
const new_p = await element.findElement(By.css('span.price-new')).getText();
const tax = await element.findElement(By.css('span.price-tax')).getText();
console.log('Image:', image);
console.log('Title:', title);
console.log('Link:', link);
console.log('Description:', desc);
console.log('Old Price:', old_p);
console.log('New Price:', new_p);
console.log('Tax:', tax);
console.log('');
}
await driver.quit();
} catch (error) {
console.log(error);
}
})();Seperti yang Anda lihat, perbedaan dari penggunaan perpustakaan sebelumnya cukup kecil. Itu diungkapkan menggunakan modul khusus Oleh, yang memungkinkan Anda menentukan jenis pencarian elemen. Di Selenium, ada beberapa cara untuk mencari elemen menggunakan modul By:
- Oleh.className( nama )
- Oleh.css(pemilih)
- Oleh.id(id)
- Oleh.js( skrip, …var_args )
- Oleh.linkText( teks )
- Nama keluarga )
- Oleh.partialLinkText( teks )
- Oleh.tagName( nama )
- Oleh.xpath(XPath)
Ini berarti Selenium menawarkan lebih banyak pilihan pencarian dan merupakan alat yang lebih fleksibel.
rontgen
X-Ray adalah perpustakaan JavaScript lain yang digunakan untuk pengikisan web dan ekstraksi data. Ini memungkinkan Anda menentukan struktur data dari mana Anda ingin mengekstrak data dan menentukan elemen atau atribut HTML yang diinginkan. Ini mendukung berbagai skenario pengikisan web, termasuk pengikisan halaman HTML statis atau halaman dengan konten dinamis yang dirender menggunakan JavaScript.
Keuntungan
X-Ray menawarkan fleksibilitas dan kemudahan penggunaan, menjadikannya pilihan populer untuk tugas pengikisan web yang cepat atau saat Anda tidak memerlukan otomatisasi browser yang ekstensif. Ini menyederhanakan ekstraksi data dan menyediakan alat untuk analisis HTML.
Kekurangan
X-ray tidak sepopuler Selenium atau Puppeteer, jadi Anda mungkin kesulitan memahaminya.
Contoh alat pengikis
Namun, mari kita instal dan lihat dengan contoh apakah itu merepotkan atau patut diperhatikan. Pertama, instal paket NPM yang diperlukan:
npm install x-raySekarang buat file JavaScript dan impor perpustakaan ke dalamnya:
const Xray = require('x-ray');Buat penangan X-ray:
const x = Xray();Jalankan kueri dan temukan semua item di setiap produk.
x('https://demo.opencart.com/', '.col', ({
image: 'img@src',
title: 'h4',
link: 'h4 > a@href',
desc: 'p',
old_p: 'span.price-old',
new_p: 'span.price-new',
tax: 'span.price-tax'
}))Sekarang yang harus kita lakukan adalah menampilkan semua data yang dikumpulkan di layar:
.then(data => {
data.forEach(item => {
const { image, title, link, desc, old_p, new_p, tax } = item;
console.log('Image:', image);
console.log('Title:', title);
console.log('Link:', link);
console.log('Description:', desc);
console.log('Old Price:', old_p || '-');
console.log('New Price:', new_p);
console.log('Tax:', tax);
console.log('');
});
})Untuk mengetahui jenis kesalahan apa yang terjadi selama eksekusi, kami menambahkan blok penangkap kesalahan untuk berjaga-jaga:
.catch(error => {
console.log(error);
});Jadi kami mendapat hasil yang sama seperti pada contoh sebelumnya.

Dan meskipun kami mencapai hasil yang sama, penulisan skrip seperti itu memakan waktu jauh lebih sedikit karena kesederhanaannya.
dramawan
Perpustakaan terakhir dalam daftar kami adalah Penulis Drama. Ini adalah perpustakaan multifungsi yang dikembangkan oleh Microsoft yang menggunakan Chromium, Firefox atau WebKit untuk menjalankan kueri dan mengumpulkan data.
Keuntungan
Seperti disebutkan, Penulis Drama dapat meluncurkan browser untuk mensimulasikan aktivitas pengguna. Mendukung mode headless (menjalankan browser di latar belakang tanpa UI yang terlihat) dan mode headful (menampilkan UI browser).
Secara keseluruhan, Playwright menawarkan solusi lengkap untuk mengotomatiskan tugas browser dan web scraping.
Kekurangan
Meskipun Playwright adalah perpustakaan yang kuat dengan banyak kelebihan, penting untuk mempertimbangkan kekurangannya juga. Rangkaian fitur penulis naskah drama yang luas dapat menciptakan tantangan, terutama dengan tugas otomatisasi sederhana. Jika Anda memiliki kebutuhan otomatisasi sederhana, lebih baik menggunakan pustaka atau kerangka kerja yang lebih ringan karena Penulis Drama mungkin mubazir untuk tugas-tugas sederhana.
Karena Playwright mengelola seluruh browser, maka dibutuhkan lebih banyak sumber daya sistem dibandingkan alternatif yang lebih ringan. Meluncurkan browser dan memuat halaman web dapat menghabiskan banyak CPU dan memori, sehingga berdampak negatif terhadap kinerja saat Anda bekerja dengan banyak browser atau di lingkungan dengan sumber daya terbatas.
Contoh alat pengikis
Pertama, instal paket NPM yang diperlukan:
npm install playwrightBuat file JavaScript baru dan sertakan perpustakaan di dalamnya. Tentukan juga fungsi utama dan tambahkan blok penangkap kesalahan:
const { chromium } = require('playwright');
(async () => {
try {
// Here will be code
} catch (error) {
console.log(error);
}
})();Sekarang mulai browser dan buka situs web yang diinginkan. Mari kita tentukan juga perintah untuk menutup browser agar kita tidak lupa menentukannya di akhir.
const browser = await chromium.launch();
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('https://demo.opencart.com/');
// Here will be code
await browser.close();Dan terakhir, kami memproses semua barang, mengambil datanya dan menampilkannya di layar:
const elements = await page.$$('.col');
for (const element of elements) {
const image = await element.$eval('img', img => img.getAttribute('src'));
const title = await element.$eval('h4', h4 => h4.textContent);
const link = await element.$eval('h4 > a', a => a.getAttribute('href'));
const desc = await element.$eval('p', p => p.textContent);
const old_p_element = await element.$('span.price-old');
const old_p = old_p_element ? await old_p_element.textContent() : '-';
const new_p = await element.$eval('span.price-new', span => span.textContent);
const tax = await element.$eval('span.price-tax', span => span.textContent);
console.log('Image:', image);
console.log('Title:', title);
console.log('Link:', link);
console.log('Description:', desc);
console.log('Old Price:', old_p);
console.log('New Price:', new_p);
console.log('Tax:', tax);
console.log('');
}Contoh ini akan membantu Anda mempelajari dasar-dasar penggunaan perpustakaan Playwright dan menentukan apakah perpustakaan tersebut tepat untuk aplikasi Anda.
Pustaka pengikisan web JavaScript mana yang terbaik untuk Anda?
Memilih pustaka JavaScript yang tepat untuk web scraping bisa menjadi tugas yang menakutkan, terutama mengingat beragamnya pilihan yang tersedia. Pilihan ideal Anda bergantung pada berbagai faktor seperti:
- Tingkat keahlian: Apakah Anda seorang pemula atau pengembang berpengalaman? Beberapa perpustakaan lebih cocok untuk pemula, sementara yang lain menawarkan fitur-fitur canggih yang mungkin memerlukan kurva pembelajaran yang curam.
- Persyaratan proyek: Apa yang ingin kamu garuk? Konten statis atau dinamis? Apakah Anda perlu menavigasi halaman atau berinteraksi dengan situs web?
- Dukungan Komunitas: Apakah Anda mencari perpustakaan dengan komunitas yang kuat dan dokumentasi yang luas?
- Fitur spesial: Apakah Anda memerlukan perpustakaan yang dapat menangani CAPTCHA, rotasi proxy, otomatisasi browser, perayapan web, atau sekadar ekstraksi data?
Untuk membantu Anda memilih perpustakaan yang tepat, kami telah membuat tabel perbandingan semua perpustakaan yang dibahas hari ini.
|
perpustakaan |
karakteristik |
Pemrosesan konten dinamis |
Otomatisasi peramban |
Dukungan komunitas |
|---|---|---|---|---|
|
Aksio dengan Cheerio |
Permintaan HTTP sederhana dan penguraian DOM |
TIDAK |
TIDAK |
Aktif |
|
Scrape-It.Cloud SDK |
Render JS, hindari CAPTCHA, gunakan proxy |
Ya |
Ya |
Aktif |
|
Dalang |
Kerangka kerja pengikisan web untuk mengotomatisasi tugas browser |
Ya |
Ya |
Aktif |
|
selenium |
Dukungan lintas browser termasuk browser Chromium |
Ya |
Ya |
Aktif |
|
rontgen |
Pemilih CSS dan XPath, ekstraksi data |
TIDAK |
TIDAK |
Rendah |
|
dramawan |
Otomatisasi browser dan kerangka pengujian |
Ya |
Ya |
Aktif |
Bagi mereka yang baru memulai atau ingin menghindari tantangan web scraping, Scrape-It.Cloud SDK bisa menjadi pilihan yang baik. Dikembangkan oleh kami dan berdasarkan API web scraping kami, perpustakaan ini menawarkan beberapa keunggulan dibandingkan opsi lainnya. Ini dapat menangani halaman web statis dan dinamis dan memiliki fitur penghindaran CAPTCHA bawaan, manajemen rotasi proxy, dan pencegahan blok. Semua fitur ini menjadikannya titik awal yang sangat baik untuk proyek Anda.
Kini setelah Anda mengetahui lebih banyak tentang pustaka JavaScript yang tersedia, kami yakin Anda dapat membuat keputusan berdasarkan kegunaan, fungsionalitas, dan tugas yang ada.