
JavaScript ist eine der beliebtesten Programmiersprachen für die Arbeit im Internet. Es verfügt über gut dokumentierte Ressourcen, eine aktive Community und viele Bibliotheken für verschiedene Zwecke.
Wenn Sie JavaScript jedoch außerhalb eines Webbrowsers verwenden möchten, müssen Sie einen Wrapper namens Node.js verwenden. Deshalb erklären wir Ihnen heute auch, wie Sie die Umgebung für JavaScript-Scraping einrichten und vorbereiten.
Vorbereitung für Web Scraping mit JavaScript
Bevor wir Bibliotheken vergleichen, bereiten wir eine Umgebung vor, in der wir diese Bibliotheken verwenden können. Die Auswahl einer Bibliothek fällt leichter, wenn Sie deren Funktionen, Vor- und Nachteile kennen. Daher zeigen wir, wie jede der überprüften Bibliotheken verwendet wird. Sie können sich aber auch unsere anderen Artikel ansehen, wenn Sie Daten in anderen Sprachen wie C# oder Python extrahieren möchten.
Installieren der Umgebung
Wir haben zuvor die Einrichtung der Umgebung für Web Scraping mit NodeJS besprochen. Deshalb gehen wir nicht noch einmal darauf ein, sondern erinnern Sie lediglich daran, was Sie tun müssen:
- Laden Sie die neueste stabile Version von NodeJS von der offiziellen Website herunter.
- Stellen Sie sicher, dass die Installation erfolgreich ist, indem Sie die installierte NodeJS-Version überprüfen:
node -v- NPM aktualisieren:
npm install -g npm- Initialisieren Sie das NPM:
npm init -yWir brauchen nichts anderes. Wir werden Visual Studio Code als Code-Editor verwenden, aber jeder Texteditor ist auch geeignet, zum Beispiel Sublime.
Erforschung der Struktur der Website
Wir nutzen diese Demo-Site, um die Beispiele für die Bibliotheksnutzung anschaulicher zu gestalten. Schauen wir es uns im Detail an. Gehen Sie dazu auf die Website und öffnen Sie die DevTools (F12 oder klicken Sie mit der rechten Maustaste auf eine Seite und wählen Sie „Inspizieren“).
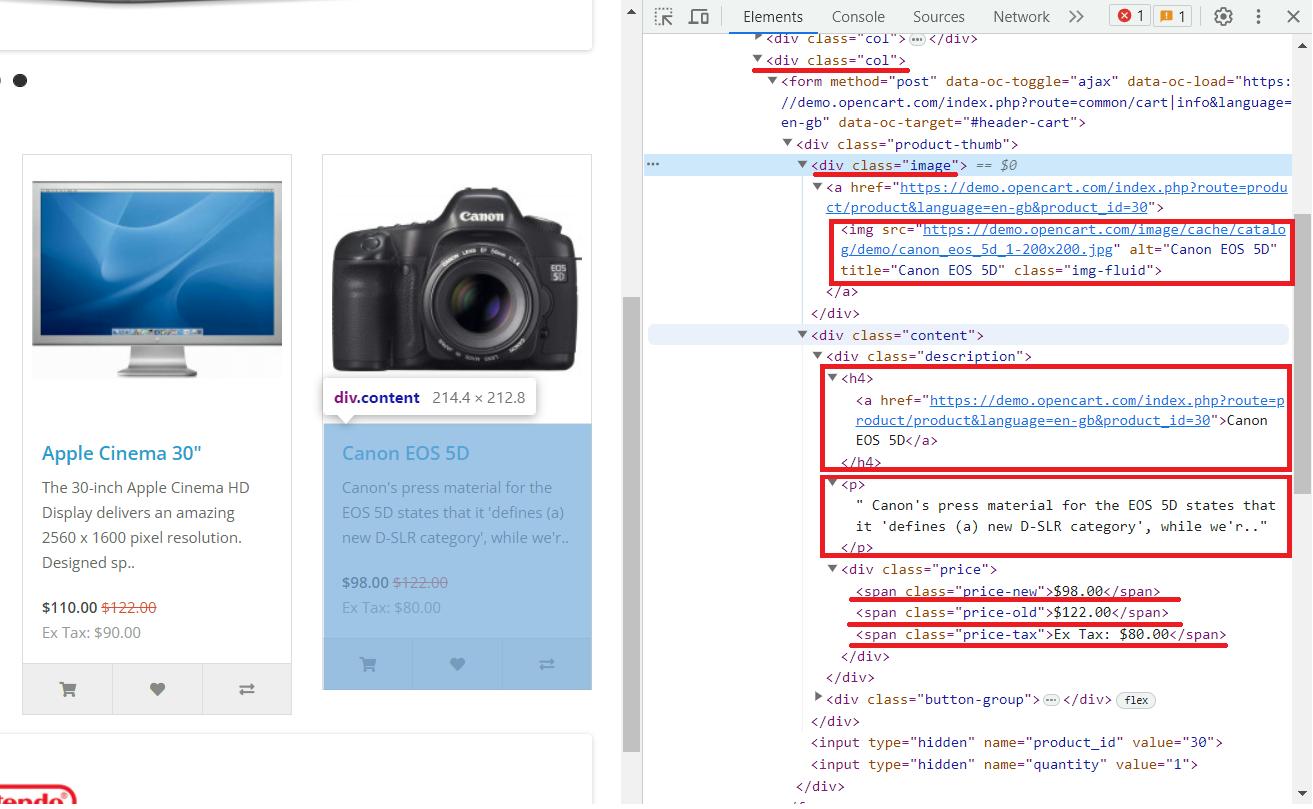
Nach der Analyse der Seite können wir folgende Schlussfolgerungen ziehen:
- Jedes Produkt befindet sich im div-Tag mit der Klasse „
col„. - Das Produktbild befindet sich im img-Tag im Attribut src.
- Produktname ist drin
<h4>Etikett. - Produktbeschreibung liegt bei
<p>Etikett. - Der alte Preis ist im
<span>Tag mit der Klasse „price-old„. - Neupreis ist im
<span>Tag mit der Klasse „price-new„. - Steuer ist in der
<span>Tag mit der Klasse „price-tax„.
Nachdem wir nun unsere Umgebung eingerichtet und die Seite analysiert haben, auf der wir die Funktionen der verschiedenen Bibliotheken zeigen, können wir JavaScript-Web-Scraping-Bibliotheken erkunden.
Auswahl der besten JavaScript-Bibliothek für Web Scraping

Es gibt zu viele NPM-Pakete, die Sie zum Scrapen von Daten verwenden können, und wir können sie nicht alle überprüfen. Wenn wir jedoch die bequemsten und beliebtesten auswählen, sind sie hier:
- Axios mit Cheerio. Axios ist eine beliebte JavaScript-Bibliothek zum Senden von HTTP-Anfragen und Cheerio ist eine schnelle und flexible Bibliothek zum Parsen von HTML. Zusammen bieten sie eine einfache Möglichkeit, HTTP-Anfragen auszuführen und HTML in Web-Scraping-Aufgaben zu analysieren. Anstelle von Axios können wir jede beliebige Abfragebibliothek verwenden, beispielsweise Unirest. Es handelt sich um eine leichte und benutzerfreundliche Bibliothek zum Ausführen von HTTP-Anfragen.
- Scrape-It.Cloud SDK. Es handelt sich um eine Bibliothek, die Ihnen das Scrapen dynamischer und statischer Webseiten ermöglicht, sich um Captchas und Blocker-Umgehung kümmert und die Möglichkeit bietet, Proxys zu verwenden.
- Puppeteer ist eine weit verbreitete Browser-Automatisierungsbibliothek. Daher ist es beim Web-Scraping sehr nützlich.
- Selenium ist ein browserübergreifendes Automatisierungssystem, das verschiedene Programmiersprachen, einschließlich JavaScript, unterstützt. Wir haben bereits in Python und R darüber gesprochen.
- X-Ray ist eine JavaScript-Bibliothek für Web-Scraping und Datenextraktion.
- Playwright ist eine leistungsstarke Headless-Browser-Automatisierungs- und Testumgebung, die von Microsoft entwickelt wurde.
Schauen wir uns die einzelnen Bibliotheken an, um herauszufinden, welche Bibliothek die beste ist, und um eine fundierte Entscheidung zu treffen.
Axios und Cheerio
Die am besten zugängliche JavaScript-Scraping-Bibliothek ist Cheerio. Da es jedoch keine Site-Abfragen durchführen kann, wird es mit einer Abfragebibliothek wie Axios verwendet. Zusammen werden diese Bibliotheken häufig verwendet und eignen sich hervorragend für Anfänger.
Vorteile
Dies ist eine hervorragende Javascript-Web-Scraping-Bibliothek, die sich gut für Anfänger eignet. Es bietet umfangreiche Parsing- und Webseitenverarbeitungsfunktionen. Es ist leicht zu erlernen, verfügt über gut dokumentierte Ressourcen und ist eine äußerst aktive Community. Dadurch finden Sie auch bei Problemen immer Hilfe und Unterstützung.
Nachteile
Leider eignet sich diese Bibliothek nur zum Scrapen statischer Seiten. Da es mit der Bibliothek der Anfrage verwendet wird, ist es unmöglich, Daten von Seiten mit dynamisch generiertem Inhalt abzurufen. Sie können damit also einen guten Parser erstellen.
Beispiel eines Schabers
Bevor wir diese Bibliothek verwenden, installieren wir die erforderlichen npm-Pakete:
npm install axios
npm install cheerio Erstellen Sie nun eine neue *.js-Datei, um unser Skript zu schreiben. Importieren Sie zunächst die Bibliotheken:
const axios = require('axios');
const cheerio = require('cheerio');Lassen Sie uns nun die Demo-Site abfragen und einen Fehlerhandler erstellen.
axios.get('https://demo.opencart.com/')
.then(response => {
// Here will be code
})
.catch(error => {
console.log(error);
});Wir haben ausdrücklich markiert, wo wir weiterhin Code schreiben werden. Wir müssen lediglich den resultierenden HTML-Code der Seite analysieren und die Daten auf dem Bildschirm anzeigen. Beginnen wir mit dem Parsen:
const html = response.data;
const $ = cheerio.load(html);
console.log($.text())
const elements = $('.col'); Hier haben wir Elemente mit der Klasse „.col“ ausgewählt. Wir haben dies bereits während der Seitenanalyse besprochen – alle Produkte haben die übergeordnete Klasse „.col“. Lassen Sie uns nun jedes der gefundenen Elemente durchgehen und spezifische Daten für jedes Produkt erhalten:
elements.each((index, element) => {
const image = $(element).find('img').attr('src');
const title = $(element).find('h4').text();
const link = $(element).find('h4 > a').attr('href');
const desc = $(element).find('p').text();
const old_p = $(element).find('span.price-old').text();
const new_p = $(element).find('span.price-new').text();
const tax = $(element).find('span.price-tax').text();
// Here will be code
});Als letztes müssen wir die Anzeige der Elemente hinzufügen, während wir sie durchgehen.
console.log('Image:', image);
console.log('Title:', title);
console.log('Link:', link);
console.log('Description:', desc);
console.log('Old Price:', old_p);
console.log('New Price:', new_p);
console.log('Tax:', tax);
console.log('');Wenn wir nun unser Skript ausführen, erhalten wir das folgende Ergebnis:
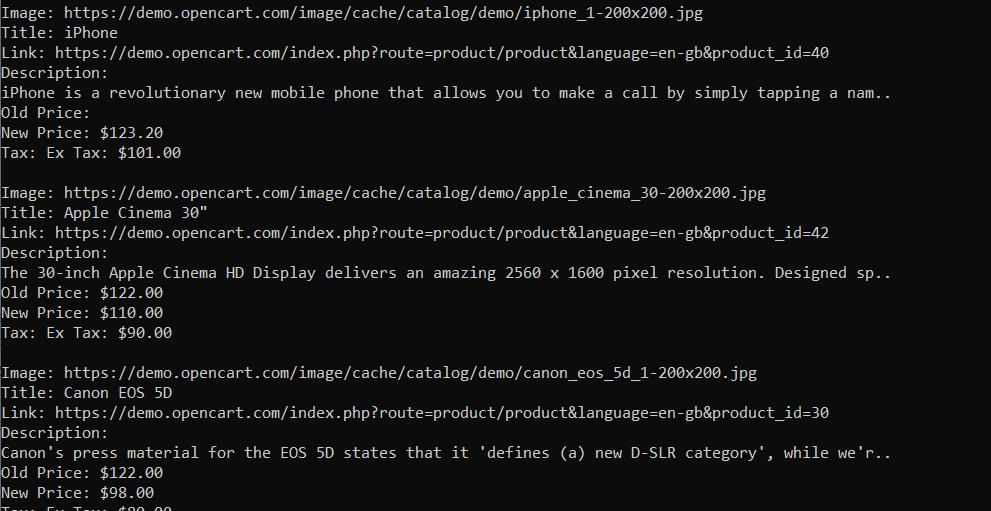
Wie wir sehen können, haben wir die Daten zu allen Elementen erhalten. Nun können Sie diese weiter bearbeiten oder beispielsweise in einer CSV-Datei speichern. Axios und Cheerio bieten hervorragende Scraping-Funktionalität. Und wenn Sie ein Anfänger sind, ist die Wahl dieser Bibliotheken für Web Scraping eine gute Entscheidung. Wenn Sie mehr über diese Tools erfahren möchten, können Sie unseren Artikel zum Scrapen mit Axios und Cheerio lesen.
Scrape-It.Cloud SDK
Eine weitere Option, die ideal für Anfänger ist, ist Scrape-It.Cloud SDK. Sie ist außerdem einfacher (und sogar einfacher) zu verwenden als Axios und Cheerio, bietet aber gleichzeitig mehr Funktionalität als die Bibliotheken, die wir als Nächstes betrachten.
Vorteile
Das Scrape-It.Cloud SDK eignet sich hervorragend zum Scrapen sowohl statischer als auch dynamischer Webseiten. Da wir diese Web-Scraping-Bibliothek mit JavaScript entwickelt haben und sie auf der Web-Scraping-API basiert, bietet sie mehrere Vorteile gegenüber anderen Bibliotheken. Es übernimmt die Captcha-Lösung und hilft, Blockierungen und die Verwendung von Proxys zu vermeiden.
Der Benutzer muss sich lediglich auf unserer Website anmelden und den API-Schlüssel von seinem Konto kopieren. Nach der Anmeldung erhalten Sie kostenlose Credits, um unsere Funktionalitäten und Features zu testen.
Nachteile
Es fällt uns schwer, über die Nachteile unserer Bibliothek zu sprechen, da wir sie ständig weiterentwickeln und verbessern. Wenn Sie jedoch Extraktionsregeln zum Extrahieren von Daten verwenden, werden diese in verschiedenen Gruppen zurückgegeben, die nicht miteinander verknüpft sind, was möglicherweise nicht sehr praktisch ist. Die API gibt aber auch den gesamten Code der Seite zurück, sodass es immer möglich ist, die Daten in der richtigen Form zu erhalten.
Beispiel eines Schabers
Schauen wir uns also ein Beispiel für die Verwendung unserer Bibliothek an. Installieren Sie zunächst das entsprechende NPM-Paket.
npm i @scrapeit-cloud/scrapeit-cloud-node-sdkErstellen Sie nun eine Skriptdatei und verbinden Sie die Bibliothek:
const ScrapeitSDK = require(‚@scrapeit-cloud/scrapeit-cloud-node-sdk‘);
Schreiben Sie die Hauptfunktion wie im letzten Beispiel und schreiben Sie einen Block, um Fehler abzufangen.
(async() => {
const scrapeit = new ScrapeitSDK('YOUR-API-KEY');
try {
// Here will be code
} catch(e) {
console.log(e.message);
}
})();Jetzt müssen Sie nur noch die Abfrage ausführen und das Ergebnis anzeigen:
const response = await scrapeit.scrape({
"extract_rules": {
"Image": "img @src",
"Title": "h4",
"Link": "h4 > a @href",
"Description": "p",
"Old Price": "span.price-old",
"New Price": "span.price-new",
"Tax": "span.price-tax"
},
"url": "https://demo.opencart.com/",
"screenshot": true,
"proxy_country": "US",
"proxy_type": "datacenter"
});
console.log(response);Die Ausgabe ist eine JSON-Antwort mit den gleichen Ergebnissen wie im letzten Beispiel. Auf diese Weise erhalten wir die gleichen Daten, jedoch auf viel einfachere Weise.
Wenn eine Website klein ist und über keinen Schutz wie Captcha oder Blöcke verfügt, fällt dies möglicherweise nicht sehr auf. Wenn Sie jedoch innerhalb kurzer Zeit große Datenmengen von Websites wie Google, Amazon oder Zillow extrahieren, werden die Vorteile der Verwendung unserer Web-Scraping-API offensichtlich.
Puppenspieler
Puppeteer ist eine komplexere JavaScript-Bibliothek für Web-Scraping, Automatisierung und Tests.
Vorteile
Damit können Sie den Headless-Browser aufrufen, um das Verhalten eines echten Benutzers zu simulieren und Browseraufgaben zu automatisieren. Da außerdem ein Seitenübergang stattfindet und das Ergebnis nach dem Laden der Webseite gescrapt wird, können Sie nicht nur statische, sondern auch dynamische Webseiten scrapen. Darüber hinaus können Sie Aktionen auf der Webseite ausführen, sei es das Klicken auf Links, das Ausfüllen von Formularen oder das Scrollen.
Nachteile
Zu den Nachteilen gehört, dass die Bibliothek für Anfänger schwieriger ist als die oben genannten. Dank der aktiven Community und der Vielzahl an Beispielen sollte dies jedoch keine große Herausforderung darstellen.
Beispiel eines Schabers
Beginnen wir mit dem Einbinden der Bibliothek, dem Erstellen einer Grundfunktion und dem Abfangen von Fehlern. Gehen wir auch direkt zur Seite und verwenden Puppeteer-Befehle, um den Übergang vorzunehmen. Verwenden Sie den Browser „await“, um zu warten, bis die Webseite vollständig geladen ist.
const puppeteer = require('puppeteer');
(async function example() => {
try {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://demo.opencart.com/');
const elements = await page.$$('.col');
// Here will be code
await browser.close();
} catch (error) {
console.log(error);
}
})();Wir haben auch eine Suche nach Elementen mit der Klasse „.col“ und ein Schließen des Browsers hinzugefügt, damit Sie dies am Ende nicht vergessen. Jetzt können wir alle Produkte durchgehen und die Daten auswählen, die wir benötigen:
for (const element of elements) {
const image = await element.$eval('img', img => img.getAttribute('src'));
const title = await element.$eval('h4', h4 => h4.textContent);
const link = await element.$eval('h4 > a', a => a.getAttribute('href'));
const desc = await element.$eval('p', p => p.textContent);
const new_p = await element.$eval('span.price-new', span => span ? span.textContent : '-');
const new_p = await element.$eval('span.price-new', span => span ? span.textContent : '-');
const tax = await element.$eval('span.price-tax', span => span ? span.textContent : '-');
console.log('Image:', image);
console.log('Title:', title);
console.log('Link:', link);
console.log('Description:', desc);
console.log('Old Price:', old_p);
console.log('New Price:', new_p);
console.log('Tax:', tax);
console.log('');
}Wir haben „span ? span.textContent : ‚-‚“ verwendet, um den Inhalt zu überprüfen. Liegt beispielsweise kein neuer Preis vor, setzen wir statt eines Fehlers einfach ein „-“ in das entsprechende Element.
Wenn die Struktur jedoch keinen solchen Selektor hat, wie bei „.price-old“, erhalten wir eine Fehlermeldung, also ziehen wir diese Option in Betracht und korrigieren den Code ein wenig.
const old_p_element = await element.$('span.price-old');
const old_p = old_p_element ? await old_p_element.evaluate(span => span.textContent) : '-';Wenn wir unseren Code ausführen, erhalten wir ein schön strukturiertes Ergebnis ohne Fehler.
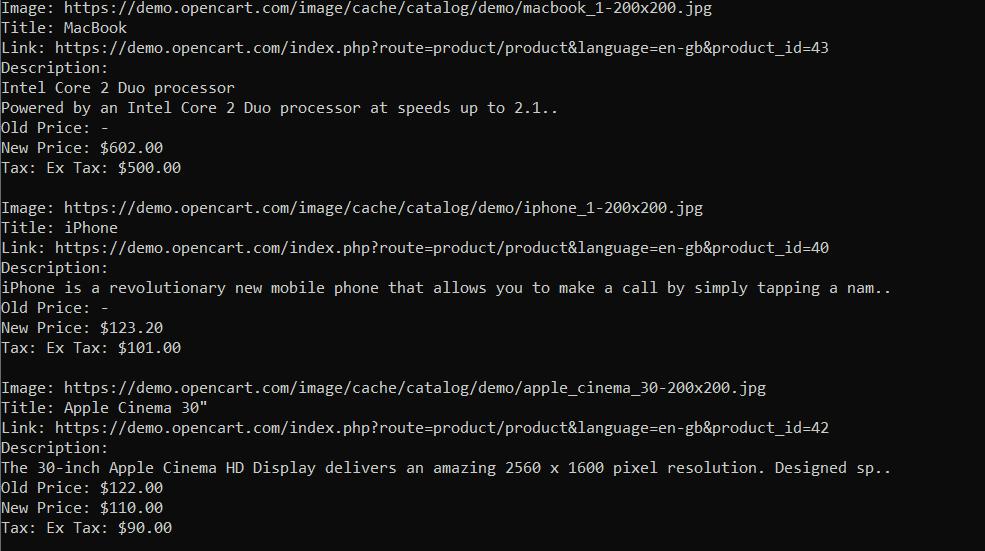
Aus unserer Erfahrung ist die Verwendung von Puppeteer sehr praktisch. Es verfügt über viele Features, Funktionen und eine gut geschriebene Dokumentation mit vielen Beispielen.
Selen
Selenium ist eine Open-Source-Plattform, die häufig zur Automatisierung von Webbrowsern verwendet wird. Selenium unterstützt viele Programmiersprachen, darunter JavaScript, Python, Java und C#, wodurch es universell und weit verbreitet ist.
Selenium verwendet einen Headless-Browser, mit dem Sie das Benutzerverhalten simulieren und Aktionen auf Webseiten ausführen können, wie es ein Mensch tut. Dies macht es hilfreich beim Web-Scraping, beim Testen von Webanwendungen und beim Ausführen sich wiederholender Website-Aufgaben.
Vorteile
Aufgrund seiner Beliebtheit und Benutzerfreundlichkeit verfügt Selenium über eine umfangreiche Community in allen unterstützten Programmiersprachen, einschließlich JavaScript.
Diese Web-Scraping-JavaScript-Bibliothek ist für manche leichter zu erlernen als Puppeteer. Es unterstützt eine Vielzahl von Möglichkeiten, Elemente zu finden, einschließlich Selektoren und XPath.
Nachteile
Zu den Nachteilen gehört, dass es als Programmieranfänger schwierig erscheinen kann, es zu lernen.
Beispiel eines Schabers
Zuerst müssen wir die NPM-Pakete von Selenium selbst und den Webtreiber installieren:
npm install selenium
npm install chromedriver
npm install selenium-webdriverIm Gegensatz zu Puppeteer, wo alles sofort mit dem Hauptpaket installiert wird, erfordert Selenium ein zusätzliches Laden dieser Elemente. Daher ist es wichtig, nichts zu vergessen, da es sonst beim Ausführen des Skripts zu Fehlern kommen kann.
Jetzt erstellen wir eine Skriptdatei und importieren die Bibliothek und die benötigten Module:
const { Builder, By } = require('selenium-webdriver');
require('selenium-webdriver/chrome');
require('chromedriver');Ansonsten ist die Verwendung von Selenium der von Puppeteer sehr ähnlich, mit Ausnahme der Art und Weise, wie Sie nach bestimmten Elementen suchen. Daher empfehlen wir Ihnen sofort, sich ein vorgefertigtes Beispiel anzusehen:
(async () => {
try {
const driver = await new Builder().forBrowser('chrome').build();
await driver.get('https://demo.opencart.com/');
const elements = await driver.findElements(By.className('col'));
for (const element of elements) {
const image = await element.findElement(By.tagName('img')).getAttribute('src');
const title = await element.findElement(By.tagName('h4')).getText();
const link = await element.findElement(By.css('h4 > a')).getAttribute('href');
const desc = await element.findElement(By.tagName('p')).getText();
const old_p_element = await element.findElements(By.css('span.price-old'));
const old_p = old_p_element.length > 0 ? await old_p_element(0).getText() : '-';
const new_p = await element.findElement(By.css('span.price-new')).getText();
const tax = await element.findElement(By.css('span.price-tax')).getText();
console.log('Image:', image);
console.log('Title:', title);
console.log('Link:', link);
console.log('Description:', desc);
console.log('Old Price:', old_p);
console.log('New Price:', new_p);
console.log('Tax:', tax);
console.log('');
}
await driver.quit();
} catch (error) {
console.log(error);
}
})();Wie Sie sehen, ist der Unterschied zur Verwendung der vorherigen Bibliothek recht gering. Es wird mit einem speziellen Modul By ausgedrückt, mit dem Sie die Art der Elementsuche definieren können. In Selenium gibt es mehrere Möglichkeiten, Elemente mithilfe des By-Moduls zu finden:
- By.className( name )
- By.css( Selektor)
- By.id( id )
- By.js( Skript, …var_args )
- By.linkText( text )
- Nach.name( name )
- By.partialLinkText( text )
- By.tagName( name )
- By.xpath( XPath)
Dadurch bietet Selenium mehr Suchmöglichkeiten und ist ein flexibleres Tool.
Röntgen
X-Ray ist eine weitere JavaScript-Bibliothek, die zum Web-Scraping und zur Datenextraktion verwendet wird. Sie können damit die Datenstruktur definieren, aus der Sie Daten extrahieren möchten, und die gewünschten HTML-Elemente oder -Attribute angeben. Es unterstützt verschiedene Web-Scraping-Szenarien, einschließlich des Scrapings statischer HTML-Seiten oder Seiten mit dynamischem Inhalt, der mit JavaScript gerendert wird.
Vorteile
X-Ray bietet Flexibilität und Benutzerfreundlichkeit und ist daher eine beliebte Wahl für schnelle Web-Scraping-Aufgaben oder wenn Sie keine umfassende Browser-Automatisierung benötigen. Es vereinfacht die Datenextraktion und bietet Tools für die HTML-Analyse.
Nachteile
Röntgen ist nicht so beliebt wie Selenium oder Puppenspieler, daher kann es sein, dass Sie Schwierigkeiten haben, es herauszufinden.
Beispiel eines Schabers
Lassen Sie uns es jedoch installieren und anhand eines Beispiels sehen, ob es unbequem ist oder Aufmerksamkeit verdient. Installieren Sie zunächst das erforderliche NPM-Paket:
npm install x-rayErstellen Sie nun eine JavaScript-Datei und importieren Sie die Bibliothek darin:
const Xray = require('x-ray');Erstellen Sie einen Röntgenhandler:
const x = Xray();Führen Sie eine Anfrage aus und finden Sie alle Elemente in jedem der Produkte.
x('https://demo.opencart.com/', '.col', ({
image: 'img@src',
title: 'h4',
link: 'h4 > a@href',
desc: 'p',
old_p: 'span.price-old',
new_p: 'span.price-new',
tax: 'span.price-tax'
}))Jetzt müssen wir nur noch alle gesammelten Daten auf dem Bildschirm anzeigen:
.then(data => {
data.forEach(item => {
const { image, title, link, desc, old_p, new_p, tax } = item;
console.log('Image:', image);
console.log('Title:', title);
console.log('Link:', link);
console.log('Description:', desc);
console.log('Old Price:', old_p || '-');
console.log('New Price:', new_p);
console.log('Tax:', tax);
console.log('');
});
})Um zu wissen, welche Art von Fehler während der Ausführung aufgetreten ist, fügen wir für alle Fälle einen Fehlerabfangblock hinzu:
.catch(error => {
console.log(error);
});Wir haben also das gleiche Ergebnis wie in den vorherigen Beispielen erhalten.

Und obwohl wir das gleiche Ergebnis erzielten, war es aufgrund der Einfachheit viel weniger zeitaufwändig, ein solches Skript zu schreiben.
Dramatiker
Die letzte Bibliothek auf unserer Liste ist Playwright. Es handelt sich um eine von Microsoft entwickelte multifunktionale Bibliothek, die Chromium, Firefox oder WebKit verwendet, um Abfragen auszuführen und Daten zu sammeln.
Vorteile
Wie bereits erwähnt, kann Playwright den Browser starten, um die Benutzeraktivität zu simulieren. Es unterstützt den Headless-Modus (Ausführung des Browsers im Hintergrund ohne sichtbare Benutzeroberfläche) und den Headful-Modus (Anzeige der Browser-Benutzeroberfläche).
Insgesamt bietet Playwright eine Komplettlösung zur Automatisierung von Browser- und Web-Scraping-Aufgaben.
Nachteile
Obwohl Playwright eine leistungsstarke Bibliothek mit vielen Vorteilen ist, ist es wichtig, auch ihre Nachteile zu berücksichtigen. Der breite Funktionsumfang von Playwright kann zu Herausforderungen führen, insbesondere bei einfachen Automatisierungsaufgaben. Wenn Sie einfache Automatisierungsanforderungen haben, ist die Verwendung einer leichteren Bibliothek oder eines leichteren Frameworks besser, da Playwright für einfache Aufgaben möglicherweise überflüssig ist.
Da Playwright eine ganze Browserinstanz verwaltet, sind mehr Systemressourcen erforderlich als bei leichteren Alternativen. Das Starten des Browsers und das Laden von Webseiten kann eine erhebliche Menge an CPU und Speicher beanspruchen, was sich negativ auf die Leistung auswirkt, wenn Sie mit vielen Browserinstanzen arbeiten oder in einer Umgebung mit begrenzten Ressourcen arbeiten.
Beispiel eines Schabers
Installieren Sie zunächst das erforderliche NPM-Paket:
npm install playwrightErstellen Sie eine neue JavaScript-Datei und fügen Sie die Bibliothek darin ein. Geben Sie außerdem die Hauptfunktion an und fügen Sie einen Fehlerabfangblock hinzu:
const { chromium } = require('playwright');
(async () => {
try {
// Here will be code
} catch (error) {
console.log(error);
}
})();Starten Sie nun den Browser und gehen Sie zur gewünschten Webseite. Geben wir auch den Befehl zum Schließen des Browsers an, damit wir nicht vergessen, ihn am Ende anzugeben.
const browser = await chromium.launch();
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('https://demo.opencart.com/');
// Here will be code
await browser.close();Und schließlich verarbeiten wir alle Waren, rufen die Daten ab und zeigen sie auf dem Bildschirm an:
const elements = await page.$$('.col');
for (const element of elements) {
const image = await element.$eval('img', img => img.getAttribute('src'));
const title = await element.$eval('h4', h4 => h4.textContent);
const link = await element.$eval('h4 > a', a => a.getAttribute('href'));
const desc = await element.$eval('p', p => p.textContent);
const old_p_element = await element.$('span.price-old');
const old_p = old_p_element ? await old_p_element.textContent() : '-';
const new_p = await element.$eval('span.price-new', span => span.textContent);
const tax = await element.$eval('span.price-tax', span => span.textContent);
console.log('Image:', image);
console.log('Title:', title);
console.log('Link:', link);
console.log('Description:', desc);
console.log('Old Price:', old_p);
console.log('New Price:', new_p);
console.log('Tax:', tax);
console.log('');
}In diesem Beispiel können Sie die Grundlagen der Verwendung der Playwright-Bibliothek erlernen und feststellen, ob sie für Ihre Anwendung geeignet ist.
Welche JavaScript-Web-Scraping-Bibliothek ist die beste für Sie?
Die Auswahl der richtigen JavaScript-Bibliothek für Web Scraping kann eine entmutigende Aufgabe sein, insbesondere angesichts der Vielzahl verfügbarer Optionen. Ihre ideale Wahl hängt von verschiedenen Faktoren ab, wie zum Beispiel:
- Fähigkeits Level: Sind Sie Einsteiger oder erfahrener Entwickler? Einige Bibliotheken sind eher für Anfänger geeignet, während andere erweiterte Funktionen bieten, die möglicherweise eine steile Lernkurve erfordern.
- Projektanforderungen: Was versuchst du zu kratzen? Statischer oder dynamischer Inhalt? Müssen Sie durch Seiten navigieren oder mit der Website interagieren?
- Gemeinschaftliche Unterstützung: Suchen Sie eine Bibliothek mit einer starken Community und umfangreicher Dokumentation?
- Spezielle Eigenschaften: Benötigen Sie eine Bibliothek, die CAPTCHA, Proxy-Rotation, Browser-Automatisierung, Web-Crawling oder einfach nur das Extrahieren von Daten verarbeiten kann?
Um Ihnen bei der Auswahl der richtigen Bibliothek zu helfen, haben wir eine Vergleichstabelle aller heute besprochenen Bibliotheken erstellt.
|
Bibliothek |
Merkmale |
Dynamische Inhaltsverarbeitung |
Browser-Automatisierung |
Gemeinschaftliche Unterstützung |
|---|---|---|---|---|
|
Axios mit Cheerio |
Einfache HTTP-Anfragen und DOM-Analyse |
NEIN |
NEIN |
Aktiv |
|
Scrape-It.Cloud SDK |
JS-Rendering, CAPTCHA vermeiden, Proxys verwenden |
Ja |
Ja |
Aktiv |
|
Puppenspieler |
Web-Scraping-Framework zur Automatisierung von Browser-Aufgaben |
Ja |
Ja |
Aktiv |
|
Selen |
Cross-Browser-Unterstützung, einschließlich Chromium-Browser |
Ja |
Ja |
Aktiv |
|
Röntgen |
CSS- und XPath-Selektoren, Datenextraktion |
NEIN |
NEIN |
Niedrig |
|
Dramatiker |
Browser-Automatisierungs- und Test-Framework |
Ja |
Ja |
Aktiv |
Für diejenigen, die gerade erst anfangen oder die Herausforderungen des Web Scrapings vermeiden möchten, kann das Scrape-It.Cloud SDK eine gute Wahl sein. Diese von uns entwickelte und auf unserer Web-Scraping-API basierende Bibliothek bietet mehrere Vorteile gegenüber anderen Optionen. Es kann sowohl statische als auch dynamische Webseiten verarbeiten und verfügt über integrierte Funktionen zur Vermeidung von CAPTCHA, zur Verwaltung der Proxy-Rotation und zur Verhinderung von Blockierungen. All diese Funktionen machen es zu einem hervorragenden Ausgangspunkt für Ihr Projekt.
Da Sie nun mehr über die verfügbaren JavaScript-Bibliotheken wissen, glauben wir, dass Sie eine fundierte Entscheidung treffen können, die auf Benutzerfreundlichkeit, Funktionalität und der jeweiligen Aufgabe basiert.
