
Sind Sie es leid, bei Ihren Web-Scraping-Projekten blockiert oder auf die schwarze Liste gesetzt zu werden? Es gibt mehrere Best Practices, die Sie befolgen können, um einen erfolglosen Web-Datenextraktionsprozess zu vermeiden.
In diesem Web-Scraping-Basisleitfaden zeigen wir Ihnen 10 intelligente Tipps und empfohlene Tools, um sicherzustellen, dass Ihr Web-Scraping-Projekt reibungslos verläuft und Sie selbst die härtesten Anti-Bot-Scraping-Maßnahmen umgehen können.
Häufige Hürden beim Website-Scraping
Bevor wir direkt zu den Web-Scraping-Tipps übergehen, müssen Sie zunächst verstehen, mit welchen gängigen Anti-Bot-Maßnahmen Sie beim Scraping von Webdaten wahrscheinlich konfrontiert werden.
Im Allgemeinen schützen Websites ihre Daten mithilfe verschiedener Methoden vor der Extraktion, darunter:
- Erkennung der IP-Adresse
- Überprüfung des HTTP-Anfrageheaders
- CAPTCHAs
- JavaScript-Prüfungen
Nun, wann Bau eines großen Web Scraperssollten Sie besonders darauf achten, dieses Anti-Bot-System zu umgehen. Das Befolgen der folgenden 10 Web-Scraping-Tipps wird Ihnen zu einem erfolgreichen Web-Scraping verhelfen. Es gibt jedoch eine einfachere Möglichkeit, eine Erfolgsquote bei der Datenextraktion von 99,9 % zu garantieren, indem Sie ein Web-Scraping-Tool wie ScraperAPI verwenden.
Mit ScraperAPI können Sie Daten von jeder öffentlichen Website sammeln. Es übernimmt für Sie die Proxy-, Browser- und CAPTCHA-Verwaltung. Sie können das Web-Scraping-Projekt sogar so einstellen, dass es nach einem Zeitplan ausgeführt wird DataPipeline von ScraperAPI Lösung oder rufen Sie die Daten im JSON-Format direkt mit dem Special von ScraperAPI ab APIs für Google, Amazon und Walmart. Wenn Sie daran interessiert sind, es auszuprobieren, Melden Sie sich hier für eine 7-tägige kostenlose Testversion an (5.000 API-Credits).
10 Best Practices für erfolgreiche Web Scraping-Projekte
Hier sind einige nützliche Web-Scraping-Tipps, die Ihnen dabei helfen, Webdaten zu extrahieren, ohne blockiert oder auf die schwarze Liste gesetzt zu werden.
1. IP-Rotation
Die beste Möglichkeit für Websites, Web Scraper zu erkennen, besteht darin, ihre IP-Adresse zu untersuchen und deren Verhalten zu verfolgen.
Wenn der Server ein Muster, seltsame Verhaltensweisen oder eine unmögliche Anforderungshäufigkeit (um nur einige zu nennen) für einen echten Benutzer feststellt, kann der Server den erneuten Zugriff der IP-Adresse auf die Website blockieren.
Um zu vermeiden, dass alle Ihre Anfragen über dieselbe IP-Adresse gesendet werden, können Sie einen IP-Rotationsdienst wie ScraperAPI oder andere Proxy-Dienste verwenden, um Ihre Anfragen über einen Proxy-Pool weiterzuleiten und so Ihre tatsächliche IP-Adresse beim Scraping der Website zu verbergen. Auf diese Weise können Sie die meisten Websites problemlos durchsuchen.
Allerdings sind nicht alle Proxys gleich. Bei Websites, die erweiterte Proxy-Anti-Scraping-Mechanismen verwenden, müssen Sie möglicherweise versuchen, private Proxys zu verwenden.
Wenn Sie nicht wissen, was das bedeutet, können Sie unseren Artikel über die verschiedenen Arten von Proxys lesen, um den Unterschied zu erfahren.
Letztendlich kann Ihr Scraper mithilfe der IP-Rotation den Anschein erwecken, dass Anfragen von verschiedenen Benutzern stammen, und das normale Verhalten des Online-Verkehrs nachahmen.
Wenn Sie ScraperAPI verwenden, nutzt unser intelligentes IP-Rotationssystem jahrelange statistische Analysen und maschinelles Lernen, um Ihre Proxys nach Bedarf aus einem Pool von Rechenzentrums-, Privat- und Mobil-Proxys zu rotieren, um eine Erfolgsquote von 99,99 % zu gewährleisten.
Testen Sie es 7 Tage lang kostenlos mit 5.000 API-Credits.
2. Legen Sie einen echten Benutzeragenten fest
Benutzeragenten sind eine spezielle Art von HTTP-Header, der der von Ihnen besuchten Website mitteilt, welchen Browser Sie genau verwenden.
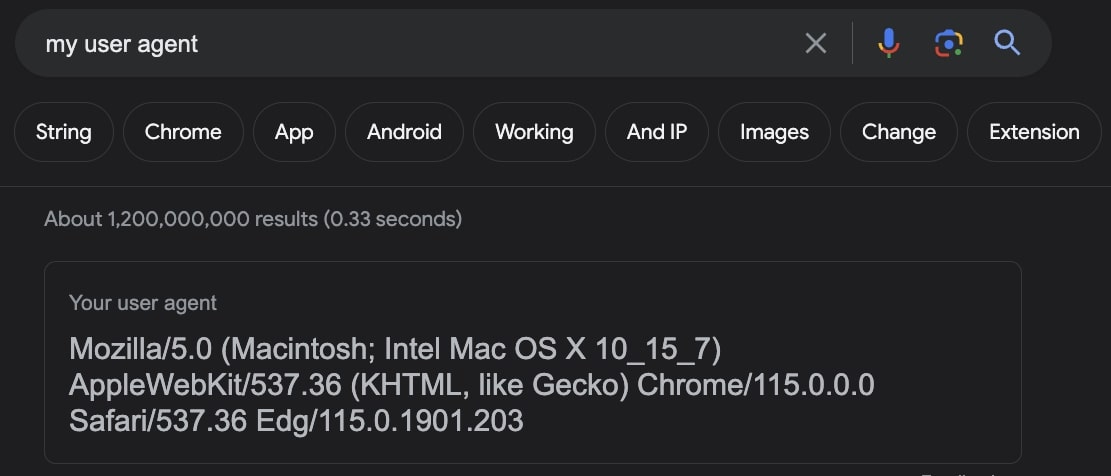
Einige Websites untersuchen User-Agents und blockieren Anfragen von User-Agents, die nicht zu einem großen Browser gehören. Da sich die meisten Web-Scraper nicht die Mühe machen, den User-Agent festzulegen, sind sie leicht zu erkennen.
Seien Sie nicht einer dieser Entwickler!
Denken Sie daran, einen beliebten Benutzeragenten für Ihren Webcrawler festzulegen (hier finden Sie eine Liste beliebter Benutzeragenten, die Sie verwenden können).
Für fortgeschrittene Benutzer können Sie Ihren User-Agent auch auf den Googlebot-User-Agent einstellen, da die meisten Websites bei Google gelistet werden möchten und daher Googlebot Zugriff auf ihre Inhalte gewähren möchten.
Notiz: Ja, Google verwendet Web Scraping.
Es ist wichtig, daran zu denken, die von Ihnen verwendeten Benutzeragenten relativ aktuell zu halten. Jedes neue Update von Google Chrome, Safari, Firefox usw. verfügt über einen völlig anderen Benutzeragenten. Wenn Sie also jahrelang den Benutzeragenten Ihrer Crawler nicht ändern, werden diese immer misstrauischer.
Es kann auch sinnvoll sein, zwischen mehreren verschiedenen Benutzeragenten zu wechseln, damit es nicht zu einem plötzlichen Anstieg der Anfragen von einem genauen Benutzeragenten an eine Site kommt (dies wäre auch ziemlich leicht zu erkennen).
Die gute Nachricht ist, dass Sie sich darüber keine Sorgen machen müssen, wenn Sie ScraperAPI verwenden.
3. Legen Sie andere Anforderungsheader fest
Echte Webbrowser verfügen über eine ganze Reihe von Headern, die von sorgfältigen Websites überprüft werden können, um Ihren Web Scraper zu blockieren.
Damit Ihr Scraper wie ein echter Browser aussieht, können Sie zu https://httpbin.org/anything navigieren und einfach die dort angezeigten Header kopieren (das sind die Header, die Ihr aktueller Webbrowser verwendet).
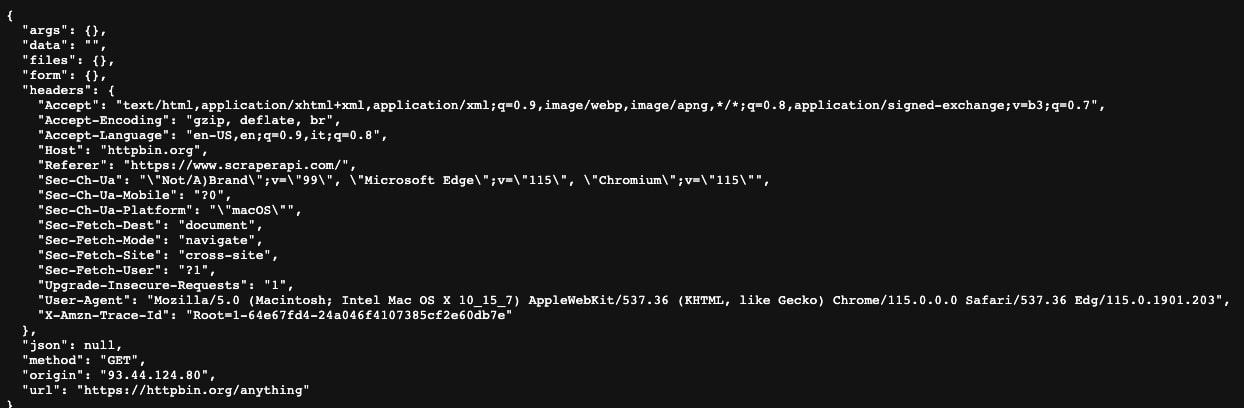
Wenn Dinge wie „Accept“, „Accept-Encoding“, „Accept-Language“ und „Upgrade-Insecure-Requests“ festgelegt sind, sehen Ihre Anfragen so aus, als kämen sie von einem echten Browser, sodass Sie kein Web-Scraping bekommen blockiert.
Indem Sie eine Reihe von IP-Adressen durchlaufen und die richtigen HTTP-Anforderungsheader (insbesondere User-Agents) festlegen, sollten Sie in der Lage sein, die Erkennung durch 99 % der Websites zu vermeiden.
Hier finden Sie eine vollständige Anleitung zum Erhalten der besten Header und Cookies für Web Scraping.
4. Legen Sie zufällige Intervalle zwischen den Scraping-Anfragen Ihrer Website fest
Es ist leicht, einen Web-Scraper zu erkennen, der 24 Stunden am Tag jede Sekunde genau eine Anfrage sendet! Keine reale Person würde jemals eine solche Website nutzen – außerdem ist ein offensichtliches Muster wie dieses leicht zu erkennen.
Verwenden Sie zufällige Verzögerungen (z. B. zwischen 2 und 10 Sekunden), um einen Web-Scraper zu erstellen, der eine Blockierung vermeiden kann.
Denken Sie auch daran, höflich zu sein. Wenn Sie Anfragen zu schnell senden, kann dies die Website für alle zum Absturz bringen. Wenn Sie feststellen, dass Ihre Anfragen immer langsamer werden, möchten Sie vielleicht Anfragen langsamer senden, damit Sie den Webserver nicht überlasten (dies sollten Sie auf jeden Fall tun, um Frameworks wie Scrapy vor dem Verbot zu schützen).
Stellen Sie sicher, dass Sie die Best Practices für Web Scraping anwenden, um solche Probleme zu vermeiden.
Für besonders höfliche Crawler können Sie die robots.txt-Datei einer Website (diese befindet sich unter http://example.com/robots.txt oder http://www.example.com/robots.txt) nach einer beliebigen Zeile durchsuchen Dort steht „Crawl-Delay“ und gibt an, wie viele Sekunden Sie zwischen den Anfragen warten sollen.
 Denken Sie daran, das Internet ist für alle da!
Denken Sie daran, das Internet ist für alle da!
5. Legen Sie einen Referrer fest
Der Referer-Header ist ein HTTP-Anfrage-Header, der der Site mitteilt, von welcher Site Sie kommen.
Im Allgemeinen ist es eine gute Idee, dies so einzustellen, dass es aussieht, als kämen Sie von Google.
Sie können dies mit der Kopfzeile tun:
“Referer”: “https://www.google.com/”
Sie können dies auch für Websites in anderen Ländern ändern. Zum BeispielWenn Sie versuchen, eine Website im Vereinigten Königreich zu durchsuchen, sollten Sie „https://www.google.co.uk/“ anstelle von „https://www.google.com/“ verwenden.
Sie können auch mit einem Tool wie https://www.similarweb.com nach den häufigsten Verweisen auf eine Website suchen. Häufig handelt es sich hierbei um eine Social-Media-Website wie YouTube.
Durch das Festlegen dieses Headers können Sie Ihrer Anfrage ein noch authentischeres Aussehen verleihen, da es sich scheinbar um Datenverkehr von einer Website handelt, von der der Webmaster bei normaler Nutzung viel Datenverkehr erwarten würde.
Die nächsten fünf Strategien sind etwas komplexer in der Umsetzung, aber wenn Sie immer noch nicht auf die Daten zugreifen können, ist es einen Versuch wert.
6. Verwenden Sie einen Headless-Browser
Die am schwierigsten zu scannenden Websites können subtile Tells wie Web-Schriftarten, Erweiterungen, Browser-Cookies und Javascript-Ausführung erkennen, um festzustellen, ob die Anfrage von einem echten Benutzer stammt oder nicht.
Um diese Websites zu crawlen, müssen Sie möglicherweise Ihren eigenen Headless-Browser bereitstellen (oder ScraperAPI dies für Sie erledigen lassen!).
Tools wie Selenium und Puppeteer ermöglichen es Ihnen, ein Programm zur Steuerung eines echten Webbrowsers zu schreiben, der mit dem identisch ist, was ein echter Benutzer verwenden würde, um eine Erkennung vollständig zu vermeiden.
Bildquelle: Toptal
Es ist zwar ziemlich aufwändig, Selenium oder Puppeteer unentdeckbar zu machen, aber dies ist die effektivste Methode zum Scrapen von Websites, die andernfalls unmöglich wären.
Allerdings sollte dies die letzte Ressource sein, da es viele Möglichkeiten gibt, selbst dynamische Inhalte zu umgehen.
Wenn die Website beispielsweise die Ausführung von JavaScript erfordert, bevor der Inhalt eingefügt wird, können Sie ScraperAPI verwenden, um die Seite zu rendern, bevor der resultierende HTML-Code zurückgegeben wird.
Eine weitere mögliche Lösung besteht darin, die versteckte API zu finden, von der die Website ihre Daten bezieht. Mit diesem Ansatz haben wir Jobdaten von LinkedIn erfasst.
Ein mögliches Szenario für die Verwendung eines Headless-Browsers besteht darin, dass die Interaktion mit der Website zu 100 % erforderlich ist (z. B. das Klicken auf eine Schaltfläche) und Sie die Datei, aus der die Anwendung die Daten bündelt, nicht finden können.
7. Vermeiden Sie Honeypot-Fallen
Viele Websites versuchen, Webcrawler zu erkennen, indem sie unsichtbare Links einfügen, denen nur ein Roboter folgen würde.
Um sie zu vermeiden, müssen Sie feststellen, ob für einen Link die CSS-Eigenschaft „display: none“ oder „visibility: versteckt“ festgelegt ist. Wenn dies der Fall ist, vermeiden Sie es, diesem Link zu folgen. Andernfalls kann der Server Ihren Scraper erkennen, die Eigenschaften Ihrer Anfragen mit einem Fingerabdruck versehen und Sie ganz einfach blockieren.
Honeypots sind für intelligente Webmaster eine der einfachsten Möglichkeiten, Crawler zu erkennen. Stellen Sie daher sicher, dass Sie diese Überprüfung auf jeder Seite durchführen, die Sie durchsuchen.
Fortgeschrittene Webmaster können die Farbe auch einfach auf Weiß einstellen (oder auf eine beliebige Farbe, die die Hintergrundfarbe der Seite hat). Sie sollten also prüfen, ob der Link etwa „Farbe: #fff;“ enthält. oder „color: #ffffff“ gesetzt, da dies den Link quasi unsichtbar machen würde.
8. Erkennen Sie Website-Änderungen
Viele Websites ändern aus vielen Gründen das Layout, was häufig dazu führt, dass Scraper kaputt gehen.
Darüber hinaus weisen einige Websites an unerwarteten Stellen unterschiedliche Layouts auf (Seite 1 der Suchergebnisse hat möglicherweise ein anderes Layout als Seite 4). Dies gilt selbst für überraschend große Unternehmen, die weniger technisch versiert sind, z. B. große Einzelhandelsgeschäfte, die gerade den Übergang zum Online-Geschäft vollziehen.
Sie müssen diese Änderungen beim Erstellen Ihres Scrapers richtig erkennen und eine kontinuierliche Überwachung erstellen, damit Sie wissen, dass Ihr Crawler noch funktioniert (normalerweise reicht es aus, nur die Anzahl erfolgreicher Anfragen pro Crawl zu zählen).
Eine weitere einfache Möglichkeit, die Überwachung einzurichten, besteht darin, Folgendes zu tun: Schreiben Sie einen Komponententest für eine bestimmte URL auf der Website oder eine URL jedes Typs.
Auf einer Bewertungsseite könnten Sie beispielsweise Folgendes schreiben:
- Ein Unit-Test für die Suchergebnisseite
- Ein Unit-Test für die Rezensionsseite
- Ein Unit-Test für die Hauptproduktseite
Und so weiter.
Auf diese Weise können Sie mit nur wenigen Anfragen etwa alle 24 Stunden nach wichtigen Website-Änderungen suchen, ohne einen vollständigen Crawl durchlaufen zu müssen, um Fehler zu erkennen.
9. Nutzen Sie einen CAPTCHA-Lösungsdienst
Eine der häufigsten Methoden für Websites, gegen Crawler vorzugehen, ist die Anzeige eines CAPTCHAs.
Glücklicherweise gibt es Dienste, die speziell darauf ausgelegt sind, diese Einschränkungen auf wirtschaftliche Weise zu überwinden, egal, ob es sich um vollständig integrierte Lösungen wie ScraperAPI oder um schmale CAPTCHA-Lösungslösungen handelt, die Sie nur für die CAPTCHA-Lösungsfunktionalität integrieren können, wie 2Captcha oder AntiCAPTCHA.
Wie Sie sich vorstellen können, gibt es keine Möglichkeit, diese Probleme mit einfachen Skripten zur Datenerfassung zu lösen. Sie sind daher sehr effektiv, um die meisten Scraper zu blockieren.
Einige dieser CAPTCHA-Lösungsdienste sind ziemlich langsam und teuer, daher müssen Sie möglicherweise überlegen, ob es immer noch wirtschaftlich ist, Websites zu durchsuchen, die eine kontinuierliche CAPTCHA-Lösung im Laufe der Zeit erfordern.
Notiz: ScraperAPI verarbeitet CAPTCHAS automatisch und ohne zusätzliche Kosten für Sie.
10. Aus dem Google-Cache kratzen
Als wirklich letzten Ausweg, insbesondere bei Daten, die sich nicht allzu oft ändern, können Sie möglicherweise Daten aus der zwischengespeicherten Kopie der Website von Google extrahieren und nicht aus der Website selbst.
Einfach voranstellen “http://webcache.googleusercontent.com/search?q=cache:” an den Anfang der URL.
Um beispielsweise die Dokumentation von ScraperAPI zu durchsuchen, können Sie Ihre Anfrage an folgende Adresse senden:
“http://webcache.googleusercontent.com/search?q=cache:https://www.scraperapi.com/documentation/”.
Dies ist eine gute Problemumgehung für nicht zeitkritische Informationen, die sich auf extrem schwer zu scannenden Websites befinden.
Während das Scrapen aus dem Google-Cache etwas zuverlässiger sein kann als das Scrapen einer Website, die aktiv versucht, Ihre Scraper zu blockieren, denken Sie daran, dass dies keine narrensichere Lösung ist.
Einige Websites wie LinkedIn weisen Google aktiv an, ihre Daten nicht zwischenzuspeichern, und die Daten für unbeliebte Websites können ziemlich veraltet sein, da Google bestimmt, wie oft eine Website gecrawlt werden soll, basierend auf der Beliebtheit der Website und der Anzahl der Seiten auf dieser Website .
Umgehen Sie Web-Scraping-Blöcke mühelos mit ScraperAPI
Hoffentlich haben Sie ein paar nützliche Tipps für das Web-Scraping beliebter Websites gelernt, ohne blockiert, auf die schwarze Liste gesetzt oder IP-gesperrt zu werden.
Wenn Sie nicht alle diese Techniken von Grund auf implementieren möchten oder an einem zeitkritischen Projekt arbeiten, erstellen Sie ein kostenloses ScraperAPI-Konto und beginnen Sie in wenigen Minuten mit der Datenerfassung.
Bis zum nächsten Mal, viel Spaß beim Web-Scraping!
