
Pengumpulan data yang konstan membuat Anda selalu mengikuti perubahan yang sedang berlangsung dan memungkinkan Anda membuat keputusan yang tepat dan tepat waktu. Sebagai salah satu mesin pencari terpopuler, Google dapat menawarkan informasi terkini dan data paling relevan. Baik Anda mencari hotel atau agen real estate, Google menyediakan data yang relevan.
Ada banyak cara untuk melakukan scraping data: mulai dari pengumpulan data manual, memesan paket data di pasar, hingga menggunakan API web scraping dan membuat scraper khusus.
Daftar Isi
Apa yang bisa kami hapus dari Google?
Google memiliki banyak layanan di mana Anda dapat menemukan informasi yang Anda butuhkan. Ada halaman hasil mesin pencari (SERP), peta, gambar, berita dan banyak lagi. Scraping Google memungkinkan Anda melacak peringkat Anda sendiri dan peringkat pesaing Anda di halaman hasil pencarian Google. Anda dapat mengumpulkan informasi prospek dari Google Maps atau menggunakannya untuk berbagai tujuan.
Hasil Pencarian
Salah satu tugas yang paling banyak diminta adalah mengekstrak informasi dari SERP Google, termasuk judul, URL, deskripsi, dan cuplikan. Misalnya, menghapus SERP Google akan menjadi solusi yang baik jika Anda perlu menyusun daftar sumber daya atau penyedia layanan yang beroperasi di area tertentu.
Google Peta
Scraping Google Maps adalah target scraping yang kedua. Mengikis peta memungkinkan Anda dengan cepat mengumpulkan informasi tentang bisnis di area tertentu dan mengumpulkan informasi kontak, ulasan, dan penilaian mereka.
berita Google
Agregator berita biasanya menelusuri Google Berita untuk mengumpulkan peristiwa terkini. Google Berita menyediakan akses ke artikel berita, judul utama, dan detail publikasi, dan scraping dapat membantu Anda mengotomatiskan pengambilan data.
Layanan Google lainnya
Selain yang disebutkan di atas, Google juga menawarkan layanan lain, seperti Google Gambar dan Google Shopping. Mereka juga dapat di-scrap, meskipun informasi yang mereka berikan mungkin kurang menarik untuk tujuan web scraping.
Mengapa kami harus menghapus Google?
Ada berbagai alasan mengapa orang dan perusahaan menggunakan pengikisan data Google. Misalnya, peneliti dapat menggunakan Google Scraping untuk mengakses sejumlah besar data untuk penelitian dan analisis akademis. Perusahaan juga dapat menggunakan data yang dihasilkan untuk riset pasar, analisis persaingan, atau akuisisi pelanggan potensial.
Selain itu, web scraping juga akan berguna bagi pakar SEO. Dengan data yang dikumpulkan, mereka dapat menganalisis peringkat dan tren mesin pencari dengan lebih baik. Dan pembuat konten bahkan dapat menggunakan Google scraping untuk mengumpulkan informasi dan membuat konten yang berharga.
Cara mengikis data Google
Seperti yang telah disebutkan, ada beberapa cara untuk mendapatkan data yang diperlukan. Kami tidak akan mempelajari pengumpulan data manual atau pembelian kumpulan data yang sudah dibuat sebelumnya. Sebaliknya, kami ingin mendiskusikan sendiri cara mendapatkan data yang diinginkan. Jadi, Anda memiliki dua opsi di sini:
- Gunakan alat pengikis khusus seperti program, pengikis tanpa kode, dan plug-in.
- Buat pengikis Anda. Di sini Anda dapat membangunnya dari awal dan menyelesaikan tantangan seperti melewati blok, menyelesaikan captcha, rendering JS, menggunakan proxy, dan banyak lagi. Alternatifnya, Anda dapat menggunakan API untuk mengotomatiskan proses dan menyelesaikan masalah ini dengan satu solusi.
Mari kita lihat lebih dekat masing-masing opsi ini.
Cara menggunakan Google Scraper tanpa kode
Cara termudah untuk mendapatkan data adalah dengan menggunakan Google Maps atau pencakar tanpa kode Google SERP. Anda tidak memerlukan pengetahuan atau keterampilan pemrograman apa pun untuk ini. Untuk mendapatkan data dari Google SERP atau Maps, masuk ke situs web kami dan buka pengikis tanpa kode yang diperlukan. Misalnya, untuk menggunakan scraper tanpa kode Google Maps, cukup isi kolom yang wajib diisi dan klik tombol Jalankan Scraper.
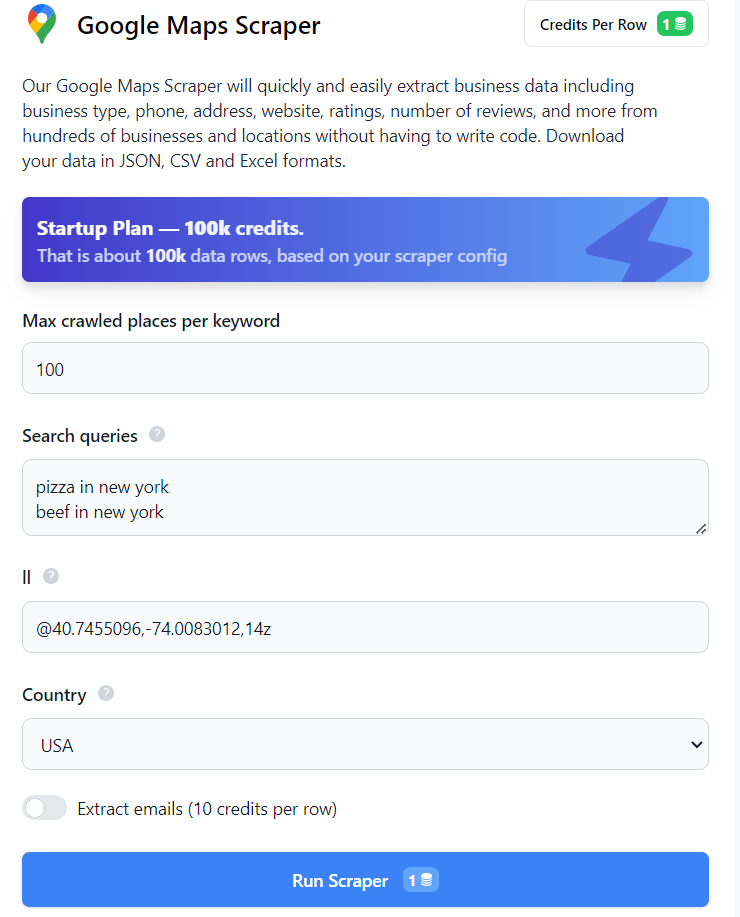
Anda kemudian dapat mengunduh data dalam format yang diinginkan. Dengan cara yang sama, Anda bisa mendapatkan data dari SERP Google. Anda juga bisa mendapatkan data tambahan dari layanan Google menggunakan alat seperti Google Trends atau pengikis tanpa kode Google Review.
Buat alat pengikis web Google Anda sendiri
Opsi kedua memerlukan pengetahuan pemrograman tetapi memungkinkan Anda membuat alat fleksibel yang memenuhi kebutuhan Anda. Untuk membuat scraper, Anda dapat menggunakan salah satu bahasa pemrograman populer seperti NodeJS, Python, atau R.
NodeJS menawarkan beberapa keunggulan dibandingkan bahasa pemrograman lainnya. Ini memiliki berbagai paket NPM yang memungkinkan Anda menyelesaikan tugas apa pun, termasuk web scraping. Selain itu, NodeJS sangat cocok untuk menangani halaman yang dihasilkan secara dinamis seperti halaman Google.
Namun pendekatan ini juga mempunyai kelemahan. Misalnya, jika Anda sering memindai situs web, tindakan Anda mungkin dianggap mencurigakan dan layanan mungkin menawarkan Anda untuk memecahkan CAPTCHA atau bahkan memblokir alamat IP Anda. Dalam hal ini, Anda sering kali harus mengubah IP melalui proxy.
Saat merancang scraper Anda, penting untuk mempertimbangkan potensi tantangan ini untuk menciptakan alat yang efektif.
Persiapan untuk menggores
Sebelum Anda memulai web scraping, penting untuk melakukan persiapan yang diperlukan. Mari kita mulai dengan menyiapkan lingkungan, menginstal paket npm yang diperlukan, dan memeriksa halaman yang ingin kita jelajahi.
Instal lingkungan
NodeJS adalah shell yang memungkinkan Anda menjalankan dan memproses JavaScript di luar browser web. Keuntungan utama NodeJS adalah mengimplementasikan arsitektur asynchronous dalam satu thread, sehingga aplikasi Anda berjalan dengan cepat.
Untuk mulai menulis scraper dengan NodeJS, mari instal dan perbarui NPM. Unduh NodeJS versi stabil terbaru dari situs resminya dan ikuti petunjuk instalasi. Untuk memastikan semuanya berhasil diinstal, Anda dapat menjalankan perintah berikut:
node -vAnda harus mendapatkan string yang menunjukkan versi NodeJS yang diinstal. Sekarang mari kita beralih ke memperbarui NPM.
npm install -g npmSetelah ini selesai, kita dapat melanjutkan ke instalasi perpustakaan.
Menginstal perpustakaan
Tutorial ini menggunakan NPM Axios, Cheerio, Puppeteer, dan Scrape-It.Cloud. Kami telah menulis tentang cara menggunakan Axios dan Cheerio untuk mengikis data karena cocok untuk pemula. Dalang adalah paket NPM yang lebih kompleks namun juga lebih fungsional. Kami juga menawarkan paket NPM berdasarkan Google Maps dan Google SERP API kami, jadi kami akan melihatnya juga.
Pertama, buat folder untuk menyimpan proyek dan buka Command Prompt di folder itu (buka folder tersebut, ketik “cmd” di bilah alamat dan tekan Enter). Kemudian inisialisasi npm:
npm init -yIni menciptakan ketergantungan daftar file. Sekarang Anda dapat menginstal sendiri perpustakaannya:
npm i axios
npm i cheerio
npm i puppeteer puppeteer-core chromium
npm i @scrapeit-cloud/google-maps-api
npm i @scrapeit-cloud/google-serp-apiSekarang elemen-elemen yang diperlukan sudah terpasang, mari kita periksa situs web yang akan kita jelajahi. Misalnya, kami memilih yang paling populer – Google SERP dan Google Maps.
Analisis halaman SERP Google
Mari kita cari “cafe new york” menggunakan Google dan temukan hasilnya. Lalu buka DevTools (F12 atau klik kanan pada layar dan pilih “Inspeksi”) dan periksa item dengan cermat. Seperti yang bisa kita lihat, semua elemen memiliki kelas yang dibuat secara otomatis. Namun demikian, keseluruhan strukturnya tetap konstan dan elemen-elemennya, terlepas dari kelasnya yang berubah, memiliki kelas yang disebut “g”.
Misalnya, kami mengambil judul dan tautan ke sumber daya. Elemen lainnya dikikis dengan cara yang sama, jadi kami tidak akan fokus pada elemen tersebut.
Judul ada di tag h3 dan linknya disimpan di tag “a” di dalam atribut href.
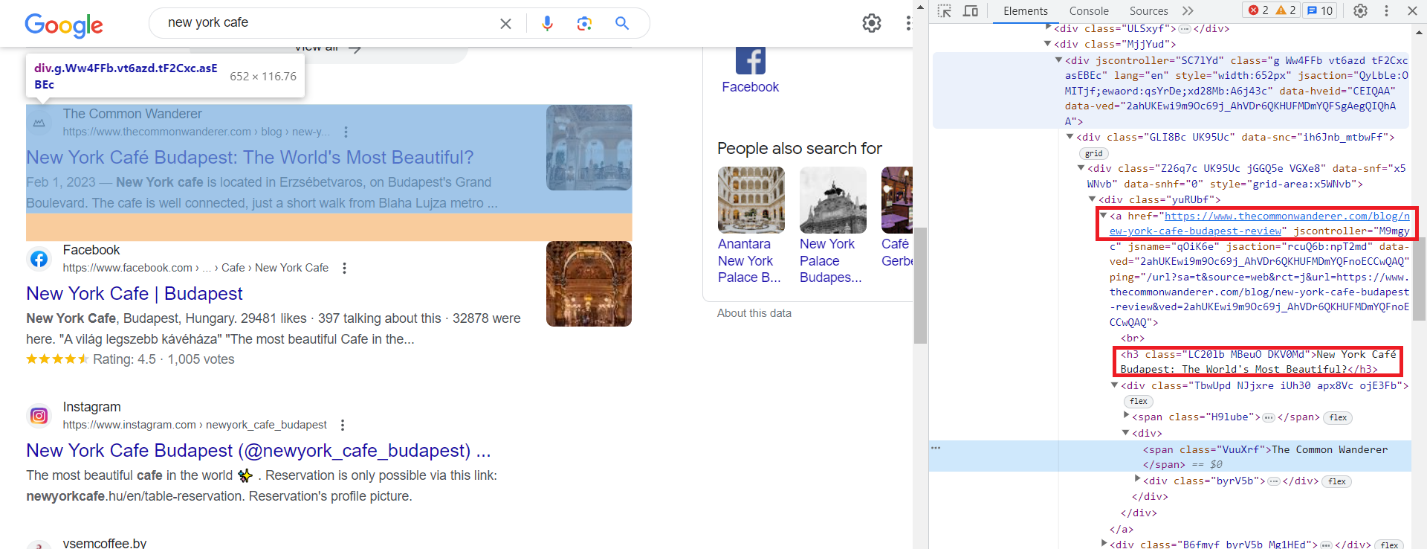
Jika Anda memerlukan lebih banyak data, carilah di halaman, di kode, dan temukan pola yang membantu Anda mengidentifikasi elemen tertentu.
Analisis halaman Google Map
Sekarang mari kita lakukan hal yang sama untuk Google Maps. Buka tab Google Maps dan buka DevTools. Kali ini mari kita buat judul, rating dan deskripsi. Anda bisa mendapatkan data dalam jumlah besar dari Google Maps. Kami akan menunjukkannya menggunakan contoh scraping dengan API. Namun, jika Anda membuat scraper lengkap untuk mengumpulkan semua data yang tersedia dari Google Maps, bersiaplah untuk kerja keras dan panjang.
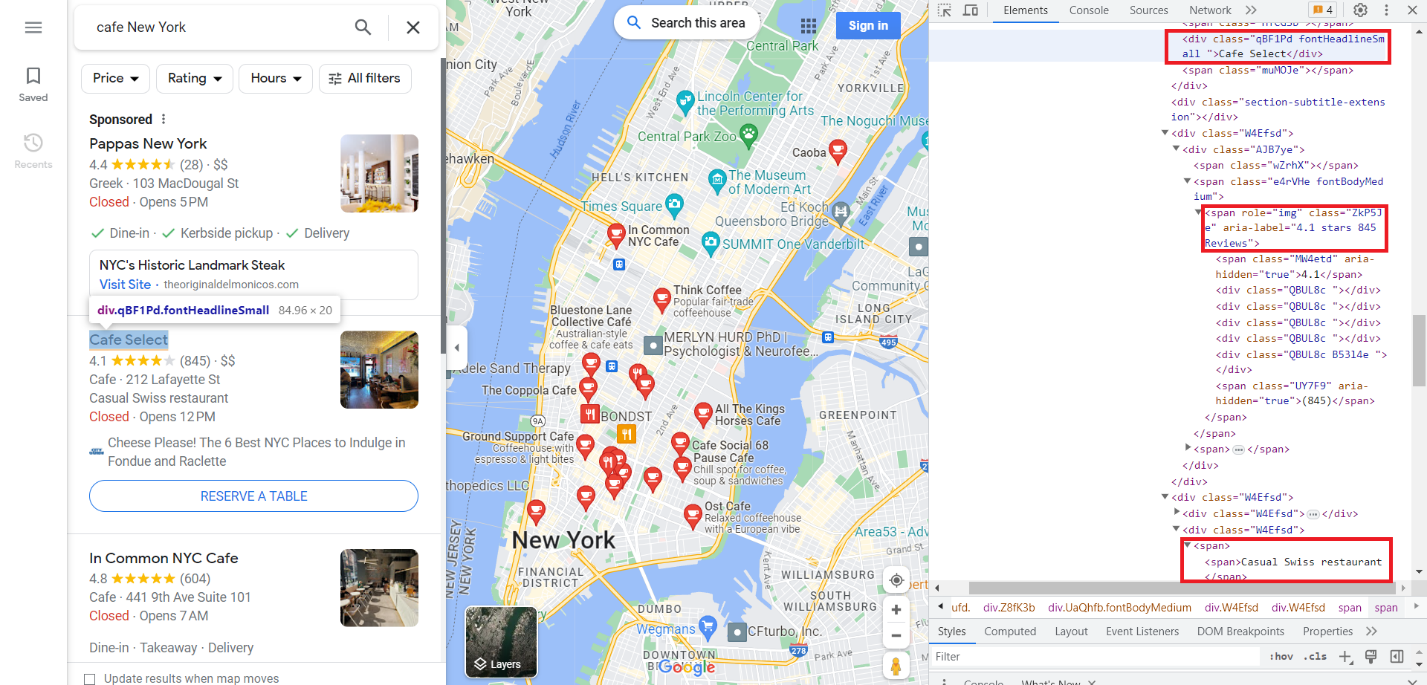
Seperti yang bisa kita lihat, kita memerlukan data dari kelas "fontHeadlineSmall", dari tag span dengan atribut Role="img" dan dari tag span.
Mengikis SERP Google dengan NodeJS
Mari kita mulai menghapus SERP Google. Kita telah menguraikan halaman tersebut sebelumnya, jadi kita hanya perlu mengimpor paket dan menggunakannya untuk membuat scraper.
Gosok SERP Google dengan Axios dan Cheerio
Ayo impor paket Axios dan Cheerio. Untuk melakukan ini, buat file *.js dan tulis:
const axios = require('axios');
const cheerio = require('cheerio');Sekarang mari kita jalankan kueri untuk mendapatkan data yang diperlukan:
axios.get('https://www.google.com/search?q=cafe+in+new+york') Ingatlah bahwa semua elemen yang kita butuhkan adalah kelas “g”. Kami memiliki kode HTML halaman tersebut, jadi kami perlu memprosesnya dan memilih semua elemen dengan kelas "g".
.then(response => {
const html = response.data;
const $ = cheerio.load(html);
console.log($.text())
const elements = $('.g'); Setelah itu kita tinggal menelusuri semua elemen dan memilih judul dan link. Kemudian kita bisa menampilkannya di layar.
elements.each((index, element) => {
const title = $(element).find('h3').text();
const link = $(element).find('a').attr('href');
console.log('Title:', title);
console.log('Link:', link);
console.log('');
});Kode siap digunakan. Dan itu akan berfungsi jika halaman tidak dibuat secara dinamis oleh Google. Sayangnya, meskipun kita menjalankan kode ini, kita tidak bisa mendapatkan data yang kita inginkan. Hal ini karena Axios dan Cheerio hanya bekerja dengan halaman statis. Yang bisa kami lakukan hanyalah menampilkan HTML permintaan yang kami terima di layar dan memastikan bahwa permintaan tersebut terdiri dari sekumpulan skrip yang akan menghasilkan konten saat dimuat.
Kikis SERP Google dengan Dalang
Mari gunakan Puppeteer, yang sangat bagus untuk bekerja dengan halaman dinamis. Kami menulis scraper yang meluncurkan browser, menavigasi ke halaman yang diinginkan dan mengumpulkan data yang diperlukan. Jika Anda ingin mempelajari lebih lanjut tentang paket npm ini, Anda dapat menemukan banyak contoh penggunaan Puppeteer di sini.
Sekarang sambungkan perpustakaan dan siapkan file untuk scraper kami:
const puppeteer = require('puppeteer');
(async () => {
//Here will be the code of our scraper
})();Sekarang mari kita mulai browser dan pergi ke halaman yang diinginkan:
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.google.com/search?q=cafe+in+new+york');Kemudian tunggu halaman dimuat dan ambil semua elemen dengan kelas “g”.
await page.waitForSelector('.g');
const elements = await page.$$('.g');Sekarang mari kita lihat semua elemen satu per satu dan pilih judul dan tautan untuk masing-masing elemen. Kemudian tampilkan datanya di layar.
for (const element of elements) {
const title = await element.$eval('h3', node => node.innerText);
const link = await element.$eval('a', node => node.getAttribute('href'));
console.log('Title:', title);
console.log('Link:', link);
console.log('');
}Dan pada akhirnya jangan lupa menutup browser.
await browser.close();Dan kali ini kita akan mendapatkan data yang kita perlukan ketika kita menjalankan script ini.
D:\scripts>node serp_pu.js
Title: THE 10 BEST Cafés in New York City (Updated 2023)
Link: https://www.tripadvisor.com/Restaurants-g60763-c8-New_York_City_New_York.html
Title: Cafés In New York You Need To Try - Bucket Listers
Link: https://bucketlisters.com/inspiration/cafes-in-new-york-you-need-to-try
Title: Best Places To Get Coffee in New York - EspressoWorks
Link: https://espresso-works.com/blogs/coffee-life/new-york-coffee
Title: Caffe Reggio - Wikipedia
Link: https://en.wikipedia.org/wiki/Caffe_Reggio
...Sekarang setelah Anda mengetahui cara mendapatkan data yang Anda perlukan, Anda dapat dengan mudah memodifikasi skrip menggunakan pemilih CSS untuk elemen yang Anda inginkan.
Mengikis dengan Google SERP API
Dengan Google SERP API, scraping menjadi lebih mudah. Untuk melakukan ini, cukup masuk ke situs web kami, salin kunci API dari dasbor Anda di akun dan buat permintaan GET dengan parameter yang diperlukan.
Mari kita mulai dengan menghubungkan perpustakaan yang diperlukan dan menyediakan tautan API. Berikan juga judul di mana Anda perlu menempelkan kunci API Anda.
const fetch = require('node-fetch');
const url="https://api.scrape-it.cloud/scrape/google?";
const headers = {
'x-api-key': 'YOUR-API-KEY'
};Sekarang mari kita atur pengaturan permintaan. Hanya satu yang diperlukan - "q", sisanya opsional. Untuk informasi selengkapnya tentang pengaturan, lihat dokumentasi kami.
const params = new URLSearchParams({
q: 'Coffee',
location: 'Austin, Texas, United States',
domain: 'google.com',
deviceType: 'desktop',
num: '100'
});Dan terakhir kami menampilkan semua hasilnya di konsol.
fetch(`${url}${params.toString()}`, { headers })
.then(response => response.text())
.then(data => console.log(data))
.catch(error => console.error(error));Anda dapat dengan mudah menggunakan API dan mendapatkan data yang sama tanpa batasan atau memerlukan proxy.
Mengikis Google Maps dengan NodeJS
Sekarang kita telah membahas cara mengikis data dari SERP Google, mengikis data dari Google Maps akan jauh lebih mudah bagi Anda karena tidak jauh berbeda.
Gosok Google Maps dengan Axios dan Cheerio
Seperti disebutkan sebelumnya, Axios dan Cheerio tidak mengizinkan Anda mengekstrak data dari Google SERP atau Maps. Ini karena konten dihasilkan secara dinamis. Saat kami mencoba mengekstrak data menggunakan paket NPM ini, kami mendapatkan dokumen HTML dengan skrip untuk menghasilkan konten halaman. Oleh karena itu, meskipun kita menulis skrip untuk mengekstrak data yang diperlukan, itu tidak akan berhasil.
Jadi mari beralih ke Puppeteer Library, yang memungkinkan kita menggunakan browser tanpa kepala dan berinteraksi dengan konten dinamis. Dengan Dalang kita dapat mengatasi keterbatasan dan menghapus data dari Google Maps secara efektif.
Mengikis Google Maps dengan Dalang
Kali ini mari kita gunakan Google Maps untuk mendapatkan daftar kafe di New York, ratingnya, dan jumlah ulasannya. Kami menggunakan Dalang untuk meluncurkan browser dan menavigasi ke halaman untuk melakukan ini. Bagian ini mirip dengan contoh penggunaan SERP Google, jadi kami tidak akan membahasnya secara detail. Tutup juga browser dan keluar dari fungsinya.
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.google.com/maps/search/cafe+near+New+York,+USA', { timeout: 60000 });
// Here will be information about data to scrape
await browser.close();
})();Sekarang yang perlu kita lakukan adalah mengidentifikasi tag induk dari semua elemen dan menelusuri setiap elemen untuk mengumpulkan data tentang rating dan jumlah ratingnya.
const elements = await page.$$('div(role="article")');
for (const element of elements) {
const title = await element.$eval('.fontHeadlineSmall', node => node.innerText);
const rating = await element.$eval('(role="img")(aria-label*=stars)', node => node.getAttribute('aria-label'));
console.log('Title:', title);
console.log('Rating:', rating);
console.log('');
}Hasilnya, kami mendapatkan daftar nama kafe dan ratingnya.
D:\scripts>node maps_pu.js
Title: Victory Sweet Shop/Victory Garden Cafe
Rating: 4.5 stars 341 Reviews
Title: New York Booze Cruise
Rating: 3.0 stars 4 Reviews
Title: In Common NYC Cafe
Rating: 4.8 stars 606 Reviews
Title: Cafe Select
Rating: 4.1 stars 845 Reviews
Title: Pause Cafe
Rating: 4.6 stars 887 Reviews
...Sekarang setelah kita menjelajahi perpustakaan, mari kita lihat betapa mudahnya mendapatkan semua data menggunakan Google Maps API.
Mengikis menggunakan Google Map API
Untuk menggunakan API web scraping, Anda memerlukan kunci API unik Anda, yang akan Anda terima secara gratis setelah mendaftar di situs web kami, bersama dengan sejumlah kredit gratis tertentu.
Sekarang mari kita hubungkan perpustakaan ke proyek kita.
const ScrapeitSDK = require('@scrapeit-cloud/google-serp-api');Selanjutnya, kita membuat fungsi untuk menjalankan permintaan HTTP dan menambahkan kunci API kita. Untuk menghindari pengulangan contoh sebelumnya, kami memodifikasinya dan menambahkan blok try…catch untuk menangkap kesalahan yang mungkin terjadi selama eksekusi skrip.
(async() => {
const scrapeit = new ScrapeitSDK('YOUR-API-KEY');
try {
//Here will be a request
} catch(e) {
console.log(e.message);
}
})();Sekarang yang harus kita lakukan adalah membuat permintaan ke API Scrape-It.Cloud dan menampilkan datanya di layar.
const response = await scrapeit.scrape({
"keyword": "pizza",
"country": "US",
"num_results": 100,
"domain": "com"
});
console.log(response);Hasilnya, kami mendapatkan respons JSON yang menampilkan informasi tentang seratus artikel pertama dan beberapa informasi lainnya:
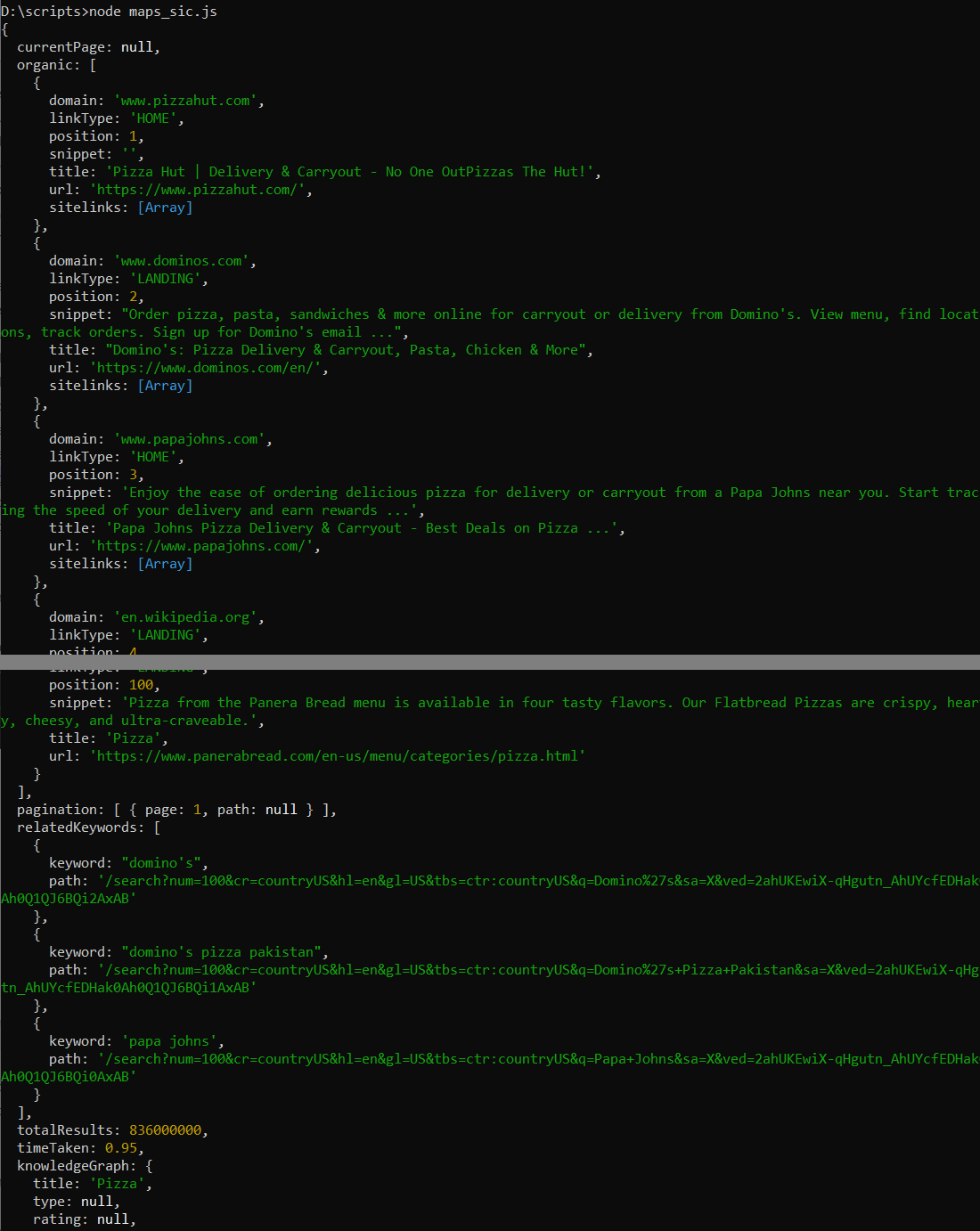
Karena proses sebelumnya terlalu sederhana dan kami memiliki data dalam jumlah besar, kami juga menyimpannya dalam file CSV. Untuk melakukan ini, kita perlu menginstal paket NPM “csv-writer”, yang belum kita instal sebelumnya.
npm i csv-writerSekarang mari tambahkan impor paket NPM ke skrip.
const createCsvWriter = require('csv-writer').createObjectCsvWriter;Sekarang kita hanya perlu membuat blok try lebih efisien. Pertama-tama tentukan penulis CSV dengan titik koma sebagai pemisah setelah respons.
const csvWriter = createCsvWriter({
path: 'scraped_data.csv',
header: (
{ id: 'position', title: 'Position' },
{ id: 'title', title: 'Title' },
{ id: 'domain', title: 'Domain' },
{ id: 'url', title: 'URL' },
{ id: 'snippet', title: 'Snippet' }
),
fieldDelimiter: ';'
});Kemudian ekstrak data yang relevan dari respons:
const data = response.organic.map(item => ({
position: item.position,
title: item.title,
domain: item.domain,
url: item.url,
snippet: item.snippet
}));Dan pada akhirnya tulis data ke file CSV dan tampilkan pesan tentang penyimpanan yang berhasil:
await csvWriter.writeRecords(data);
console.log('Data saved to CSV file.');Setelah menjalankan skrip ini, kami membuat file CSV yang berisi informasi rinci tentang seratus posisi pertama di Google Maps untuk kata kunci yang diinginkan.
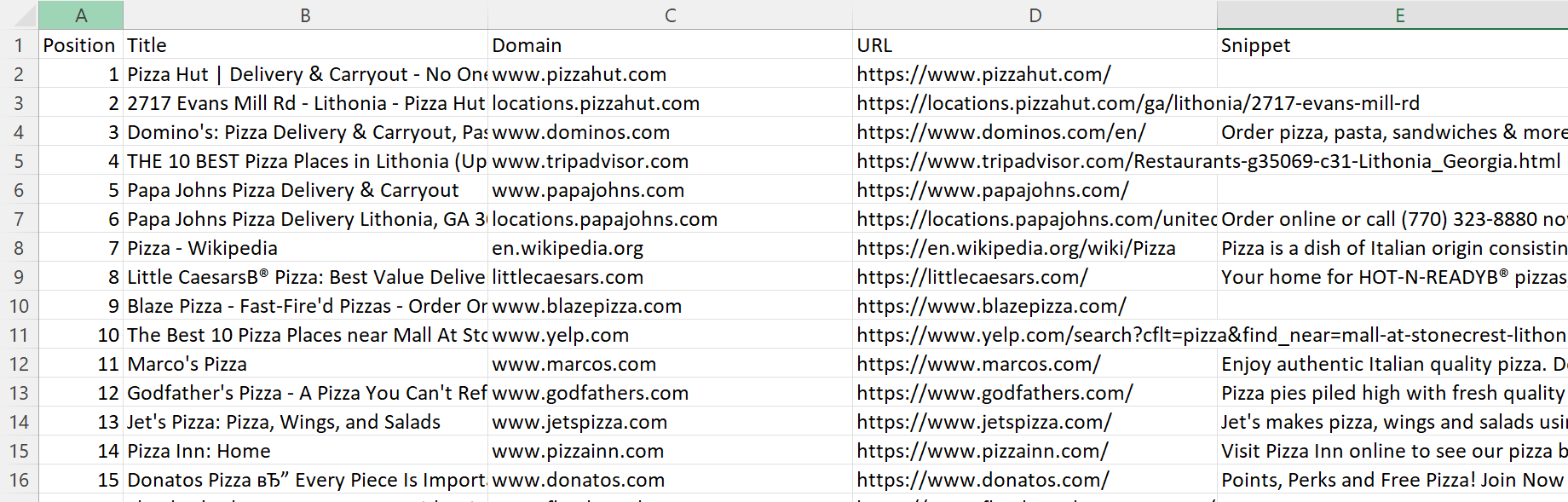
Kode lengkap:
const ScrapeitSDK = require('@scrapeit-cloud/google-serp-api');
const createCsvWriter = require('csv-writer').createObjectCsvWriter;
(async() => {
const scrapeit = new ScrapeitSDK('YOUR-API-KEY');
try {
const response = await scrapeit.scrape({
"keyword": "pizza",
"country": "US",
"num_results": 100,
"domain": "com"
});
const csvWriter = createCsvWriter({
path: 'scraped_data.csv',
header: (
{ id: 'position', title: 'Position' },
{ id: 'title', title: 'Title' },
{ id: 'domain', title: 'Domain' },
{ id: 'url', title: 'URL' },
{ id: 'snippet', title: 'Snippet' }
),
fieldDelimiter: ';'
});
const data = response.organic.map(item => ({
position: item.position,
title: item.title,
domain: item.domain,
url: item.url,
snippet: item.snippet
}));
await csvWriter.writeRecords(data);
console.log('Data saved to CSV file.');
} catch(e) {
console.log(e.message);
}
})();Jadi kita dapat melihat bahwa menggunakan web scraping API membuat ekstraksi data dari Google Maps menjadi sangat mudah.
Tantangan pengikisan web Google
Tidaklah cukup hanya membuat scraper yang mengumpulkan semua data yang diperlukan. Penting juga untuk berhati-hati untuk menghindari kesulitan saat mengikis. Anda harus memikirkan untuk menyelesaikan beberapa tantangan terlebih dahulu dan mengambil tindakan pencegahan untuk mengatasinya jika tantangan tersebut muncul.
Mekanisme anti gores
Banyak situs web menggunakan metode berbeda untuk melindungi dari bot, termasuk scraper. Mengeksekusi permintaan ke situs secara terus-menerus akan memberikan terlalu banyak tekanan pada sumber daya, menyebabkan respons tertunda dan kemudian dikembalikan secara tidak berurutan. Oleh karena itu, situs web mengambil tindakan untuk melindungi dari permintaan bot yang sering terjadi. Misalnya, salah satu opsi perlindungan ini adalah jebakan khusus, elemen yang tidak terlihat di halaman, namun di kode halaman. Membagikan item tersebut dapat mengakibatkan Anda diblokir atau dialihkan ke halaman yang tidak ada dalam satu lingkaran.
CAPTCHA
Cara umum lainnya untuk melindungi diri Anda dari bot adalah dengan menggunakan captcha. Untuk mengatasi masalah ini, Anda dapat menggunakan layanan khusus untuk memecahkan captcha atau API yang mengembalikan data yang sudah jadi.
Pembatasan tarif
Seperti disebutkan, terlalu banyak pertanyaan dapat merusak halaman arahan. Selain itu, kecepatan permintaan bot jauh lebih cepat dibandingkan manusia. Hal ini memudahkan layanan untuk menentukan apakah bot sedang melakukan tindakan.
Demi keamanan scraper Anda dan untuk menghindari kerusakan pada sumber daya target, sebaiknya kurangi kecepatan scraping menjadi setidaknya 30 permintaan per menit.
Mengubah struktur HTML
Tantangan lain dalam web scraping adalah perubahan struktur situs web. Anda telah melihatnya dengan contoh Google. Nama kelas dan anggota dibuat secara otomatis, sehingga sulit untuk mengambil data. Namun, struktur halamannya tetap tidak berubah. Kuncinya adalah menganalisisnya dengan cermat dan menggunakannya secara efektif.
pemblokiran IP
Pemblokiran IP adalah cara lain untuk melindungi diri Anda dari bot dan spam. Jika tindakan Anda tampak mencurigakan di suatu situs web, Anda mungkin diblokir. Inilah sebabnya mengapa Anda mungkin perlu menggunakan proxy. Proksi bertindak sebagai perantara antara Anda dan situs web target. Ini bahkan memungkinkan Anda mengakses sumber daya yang diblokir di negara Anda atau khusus untuk alamat IP Anda.
Kesimpulan dan temuan
Pengambilan data dari Google Maps bisa rumit dan sederhana bergantung pada alat yang Anda pilih. Karena tantangan seperti rendering JavaScript dan perlindungan bot yang kuat, mengembangkan scraper khusus bisa jadi cukup sulit.
Selain itu, contoh hari ini menunjukkan bahwa tidak semua perpustakaan cocok untuk melakukan scraping Google SERP dan Google Maps. Namun demikian, kami juga telah menunjukkan bagaimana kami dapat mengatasi tantangan-tantangan ini. Misalnya, untuk mengatasi tantangan pembuatan struktur dinamis, kami menggunakan Dalang NPM. Selain itu, untuk pemula atau mereka yang lebih suka menghemat waktu dan tenaga dalam menangani captcha dan proxy, kami akan menunjukkan cara menggunakan API web scraping untuk mengekstrak data yang Anda inginkan.