
Sebagian besar perusahaan (dan masyarakat) saat ini kurang lebih menyadari dampak data terhadap bisnis mereka.
Sistem ERP memungkinkan perusahaan untuk memproses data internal mereka dan mengambil keputusan yang sesuai.
Hal ini saja sudah cukup jika produksi data web tidak meningkat secara eksponensial pada saat itu. Beberapa sumber memperkirakan ada 328,77 juta terabyte data setiap hari!
Dan tentu saja, perusahaan Anda beroperasi dalam ruang hampa.
Pada Pengikisan web Data diambil dari web untuk memantau berbagai peristiwa yang mungkin berdampak pada bisnis Anda.
Jika Anda menjalankan perusahaan logistik, mengevaluasi data iklim dapat membantu Anda mengambil keputusan yang tepat. Pikirkan tentang informasi tentang badai dan badai yang akan datang dari berita.
Beberapa perusahaan menghasilkan sebagian besar pendapatannya secara online. Jika Anda termasuk dalam segmen ini, Anda dapat mengukur sentimen pelanggan dengan mengumpulkan dan memantau data media sosial.
Grepsr berspesialisasi dalam pengumpulan data terkelola dari Internet.
Dengan pengalaman lebih dari satu dekade di bidangnya, kami telah membuktikan keahliannya dalam memecahkan kasus penggunaan ekstraksi data yang paling memberatkan dan memungkinkan organisasi menyerap data dalam jumlah besar dalam potongan berukuran byte.
Baca lebih lanjut tentang ekstraksi data dengan PHP di sini:
Di salah satu artikel lama kami, kami menjelaskan bagaimana Anda dapat membuat crawler sendiri dan menelusuri web menggunakan PHP.
Kali ini kita akan fokus pada ekstraksi data menggunakan Python.
Python, mirip dengan PHP, adalah bahasa pemrograman yang digunakan di seluruh dunia untuk berbagai aplikasi.
Dari tujuan skrip sederhana hingga menghasilkan kecerdasan buatan yang kompleks dan model bahasa pembelajaran mesin (seperti ChatGPT dan berbagai LLM lainnya), pengembang sering kali beralih ke Python karena kesederhanaannya.
Sintaksnya mudah dipelajari, ramah bagi pemula, dan komunitas plugin dan perpustakaan yang kuat telah membantunya menangani tugas apa pun yang berhubungan dengan komputer.
Pengikisan web juga demikian. Ekstraksi data tentunya bisa kita lakukan dengan menggunakan Python.
Dalam pelajaran ini, kita akan menulis crawler menggunakan Python yang akan meng-crawl 250 film IMDB teratas dan menyimpan datanya ke file CSV.
Untuk navigasi yang efektif, kami telah membagi artikel ini menjadi beberapa bagian berikut:
- persyaratan
- Definisi
- Mempersiapkan
- Tulis pengikisnya
- kata-kata terakhir
Daftar Isi
Persyaratan untuk memulai web scraping dengan Python
Mirip dengan artikel PHP, kita memerlukan alat tertentu dan pengetahuan dasar tentang beberapa istilah sebelum memulai. Kami kemudian menyiapkan direktori proyek dan menginstal berbagai paket dan perpustakaan yang akan berguna dalam proyek ini.
Karena Python adalah bahasa yang serba bisa, berbagai fitur tersedia di hampir semua platform.
Setelah itu, kita akan membahas setiap baris kode Python dan memikirkan apa fungsinya dan mengapa ia melakukannya. Di akhir tutorial ini, Anda akan mempelajari dasar-dasar pemrograman Python, setidaknya yang berkaitan dengan web scraping. Anda membuat file CSV yang dapat Anda gunakan untuk analisis data dan pemrosesan data.
Dasar-dasar Python
Perpustakaan
Ini adalah program Python bawaan yang dirancang untuk melakukan operasi atau fungsi kecil. Anda dapat mendistribusikannya melalui Internet dengan lisensi, gratis, atau dengan hak kepemilikan.
Manajer Paket
Manajer paket membantu mengelola perpustakaan yang kami gunakan dalam program Python kami.
Perlu diingat bahwa menginstal paket Python secara sembarangan dengan mengganti atau menimpa sepenuhnya instalasi saat ini berpotensi merusak sistem Anda. Inilah sebabnya kami menggunakan konsep yang disebut “lingkungan”.
Berikut beberapa pengelola paket yang dapat Anda gunakan: pip, conda, pipenvdll. Anda juga dapat menggunakan manajer paket sistem operasi untuk menginstal paket Python.
Lingkungan
Sebagian besar sistem operasi modern menggunakan Python dalam proses dan aplikasi intinya. Instalasi berbagai paket yang tidak terkontrol dapat merusak sistem dan mencegahnya melakukan booting atau melakukan tugas rutin.
Untuk mencegah hal ini, kami menggunakan logika containerisasi yang disebut lingkungan. Lingkungan adalah wadah kotak pasir dalam sistem komputer tempat versi baru dari file (atau beberapa file) tertentu dapat diinstal. Lingkungan tidak berkomunikasi dengan instalasi, melainkan memenuhi persyaratan program tertentu.
Sederhananya, lingkungannya mirip dengan mesin virtual. Untuk mencegah sistem kami berantakan, kami membuat mesin virtual dan menjalankan program kami dengan menginstal paket pada mesin virtual tersebut.
Dengan cara ini, paket-paket baru tidak dapat menimpa sistem dan aplikasi menerima semua paket yang dibutuhkan. Conda, venvDan pipenv adalah beberapa contoh pengelola lingkungan untuk Python.
bak pasir
Kami menggunakan konsep sandboxing ketika kami ingin menjalankan suatu aplikasi tanpa gangguan dari sistem lain. Ini adalah langkah keamanan yang kami gunakan dalam pemrograman Python untuk meningkatkan keamanan aplikasi kami. Ini juga membantu memperkuat keamanan sistem kami secara keseluruhan.
Lxml
Kami menggunakan Lxml untuk mengurai dokumen HTML dan menghasilkan DOM dari dokumen HTML. Membuat DOM adalah masalah kenyamanan. Ini membantu kami menemukan data yang kami inginkan.
Panda
Pandas adalah pustaka Python lain yang biasa digunakan dalam ilmu data dan pemrosesan data. Ini berguna ketika Anda ingin memproses data dalam jumlah besar dan mendapatkan wawasan yang dapat ditindaklanjuti. Kami akan menggunakan perpustakaan ini untuk menghasilkan file CSV dari data yang kami ekstrak dari IMDB.
JSON
Ini memungkinkan program kami untuk mencari DOM HTML menggunakan pemilih CSS. Mereka adalah perpanjangan dari perpustakaan LXML. Anda dapat menggunakannya bersama-sama untuk dengan cepat menghasilkan DOM HTML yang dapat dicari menggunakan Pemilih CSS.
Kami membuat direktori tempat kami akan menyimpan program utama kami dan juga file keluaran CSV akhir. Untuk membuat direktori proyek, kita cukup membuat folder baru menggunakan sistem operasi kami dan membuka editor teks di dalamnya. Untuk tutorial ini kita akan menggunakan Visual Studio Code Microsoft.
Setelah ini selesai, kami akan menginstal pengelola lingkungan untuk mencegah paket baru mengganggu sistem kami.
Buka terminal di editor teks kami dan ketik yang berikut:
pip install pipenv
Ini akan menginstal manajer lingkungan bernama pipenv. Kami bisa menggunakannya conda dan lainnya, namun pengaturannya sedikit lebih rumit dibandingkan dengan pipenv.
Sekarang buat file baru bernama requirements.txt.
Pada file ini kita mencatat nama paket yang harus kita install. Isi dari persyaratan.txt Filenya akan menjadi:
pandasrequestsLxmlCssselect
Setelah langkah ini selesai, catat perintah berikut untuk menginstal semua ini sekaligus.
pipenv install -r requirements.txt
Perintah ini membaca requirements.txt File dan instal setiap perpustakaan setelah membuat lingkungan Python dengan nama yang sama dengan foldernya. Kami menghasilkan dua file baru: Pipfile Dan Pipfile.lock.
Ini menandakan bahwa paket kita telah terinstal dan kita siap untuk langkah berikutnya.
Sekarang program kita perlu mengetahui bahwa kita ingin menggunakan paket yang diinstal di lingkungan baru dan bukan oleh sistem. Oleh karena itu, kami menjalankan perintah berikut untuk mengatur lokasi executable.
pipenv shell
Sekarang buat file baru bernama imdb.py untuk akhirnya mulai menulis program.
Tulis perayap dengan Python
Berbeda dengan crawler PHP, teknik scraping kita kali ini akan sedikit berbeda. Daripada berhenti di 250 halaman pertama, mari melangkah lebih jauh dan mengekstrak sinopsis film untuk masing-masing 250 film yang terdaftar.
Jadi nama kolom kami untuk sesi scraping ini adalah: Judul, peringkat dan ringkasan.
Di halaman ini kami ingin mengekstrak 250 film IMDB teratas sepanjang masa. Silakan baca blog kami sebelumnya “Cara Melakukan Web Scraping dengan PHP” untuk mempelajari lebih lanjut tentang struktur detail halaman ini.
Di sini kami hanya fokus pada halaman berikutnya, yang darinya kami mengekstrak teks ringkasan untuk masing-masing 250 film.
Setelah kita mengklik salah satu film, kita dapat melihat bahwa kita membuka halaman web yang mirip dengan ini:
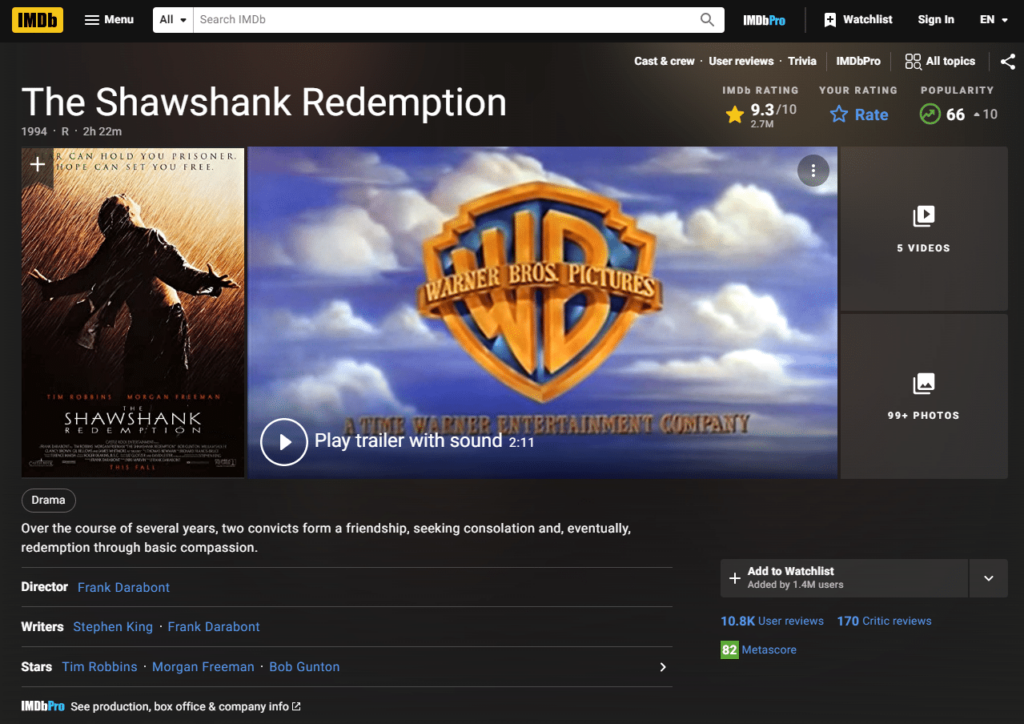
Di sini kita melihat ringkasan yang diperlukan di bagian bawah halaman web kita. Jika kami memeriksanya melalui alat konsol pengembang, kami dapat melihat tag CSS yang tepat di mana ringkasannya ada.
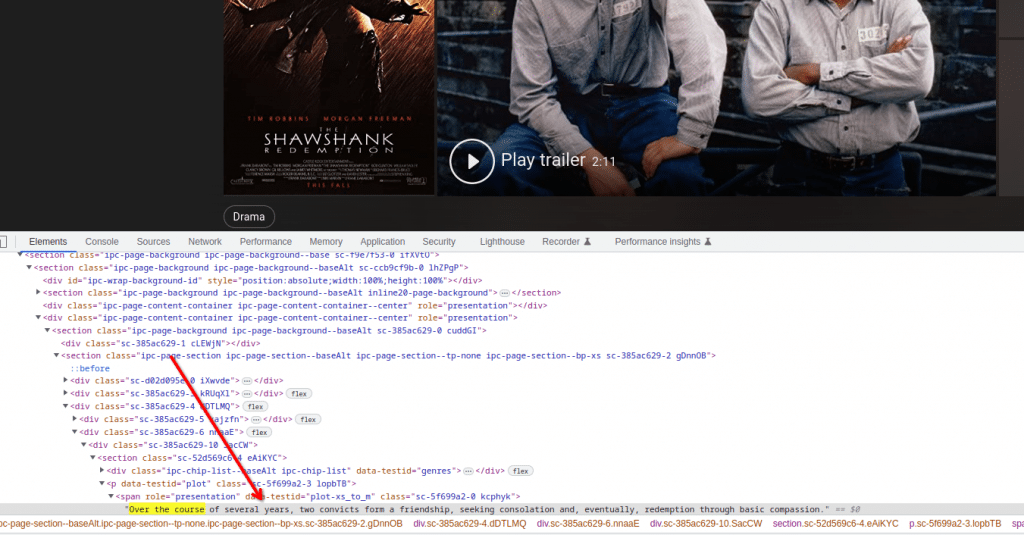
Kita dapat menggunakan informasi ini secara langsung selama proses scraping, tapi mari kita cari tahu apakah ada cara yang lebih mudah untuk menangani informasi ini. Mari kita cari teks ringkasan film ini di halaman sumber.

Selain itu, kami mencatat bahwa teks ringkasan diambil dari tag skrip yang berisi data dalam format JSON. Ini adalah format yang lebih diinginkan karena konten JSON selalu dalam format yang lebih diharapkan, tidak seperti teks HTML yang dapat berubah ketika halaman web diperbarui.
Oleh karena itu, yang terbaik adalah mengekstrak data dari objek JSON. Setelah Anda mengetahui alur kerja scraper, Anda dapat mulai menulis.
Mulailah skrip Python dengan mengimpor semua paket yang diinstal dengan kata kunci impor mirip dengan:
import pandas as pd
import requests as re
import lxml.html as ext
import jsonUntuk mulai melakukan scraping, kita mendefinisikan variabel header yang berisi semua header yang diperlukan untuk situs web.
Header penting karena menentukan format jabat tangan antara situs sumber dan kode kita sehingga transfer data dapat terjadi dengan lancar antara kedua agen.
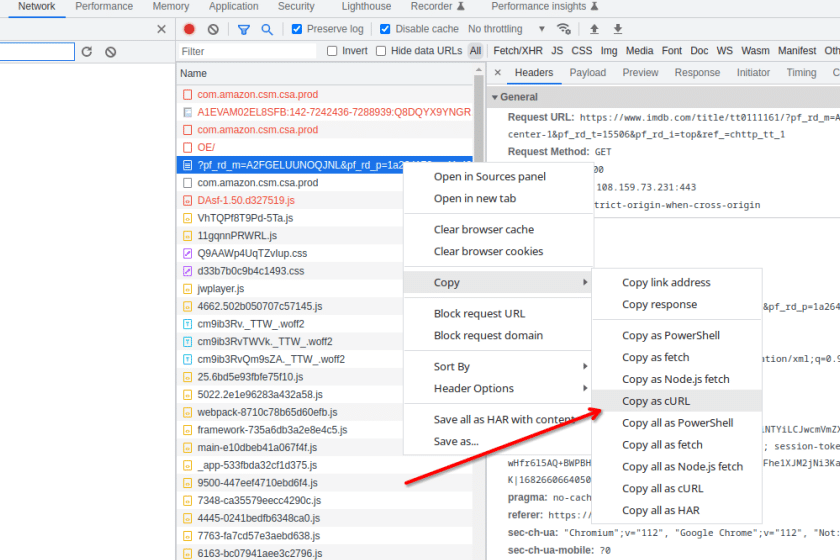
Hasilnya, kita bisa mendapatkan header yang sesuai dari tab Jaringan di konsol pengembang. Cukup cari halaman yang Anda inginkan, klik kanan halaman web tersebut, lalu klik dan salin sebagai cURL.
Tempelkan sementara konten ke file lain untuk memeriksa semua header.
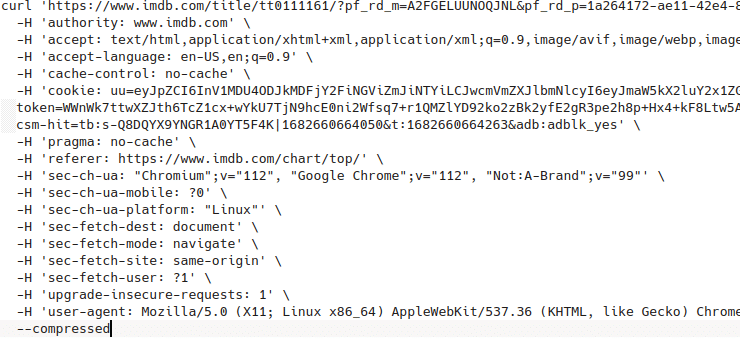
cURL headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36 Edg/111.0.1661.51',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'en-US,en;q=0.9'
}
Dengan mendefinisikan hal ini, kami menggunakan perpustakaan permintaan untuk mengirim permintaan get ke situs web IMDB yang berisi 250 film teratas.
response = re.get(‘https://www.imdb.com/chart/top/?ref_=nv_mp_mv250’, headers=headers)Bagian utama dari konten respon dimasukkan ke dalam variabel respon. Sekarang kita perlu membuat dokumen HTML DOM dari respon tertentu sehingga kita dapat menggunakannya dengan mudah lxml Dan cssselect untuk mencari data yang kami perlukan. Selanjutnya, kita dapat melakukannya dengan baris kode berikut:
tree = ext.fromstring(response.text)
movies = (ext.tostring(x) for x in tree.cssselect('table(data-caller-name="chart-top250movie") > tbody > tr'))Setelah ini selesai, semua informasi yang diperlukan tentang 250 film akan disimpan dalam variabel film sebagai daftar. Sekarang yang harus Anda lakukan adalah mengulangi variabel ini untuk masuk lebih jauh ke halaman web setiap film dan mendapatkan ringkasannya. Anda dapat melakukannya dengan blok kode berikut:
url="https://www.imdb.com{}".format(tree.cssselect('a')(1).get('href'))
response = req.get(url, headers=headers)Ini akan memunculkan halaman web yang berisi sinopsis film film kita. Sekarang, seperti yang disebutkan sebelumnya, kita perlu mengekstrak objek JSON dari tag skrip halaman web baru ini. Kita dapat melakukan ini dengan menggunakan perpustakaan JSON seperti yang ditunjukkan di bawah ini:
script = json.loads(tree.cssselect('script(type="application/ld+json")')(0).text_content())Selain itu, variabel skrip baru ini berisi objek JSON dari situs web. Tempatkan informasi dalam susunan yang rapi dan Anda mendapatkan data baris yang sesuai untuk sebuah film. Lakukan seperti ini:
row = {
'Title': script('name'),
'Rating': rating,
'Summary': script('description')
}Jika kita mengulangi proses ini lebih dari 250 kali kita akan mendapatkan data yang dibutuhkan. Namun, tanpa menyimpan data ini di lokasi perantara, kami tidak dapat menggunakan data tersebut untuk pemrosesan dan analisis lebih lanjut sesuai dengan tujuan kami pandas Perpustakaan masuk.
Selama setiap iterasi, kami menyimpan informasi baris di a Bingkai data seri milik kita Panda Objek dengan kode berikut:
all_data = pd.concat((all_data, pd.DataFrame((row))), ignore_index=True)Setelah iterasi selesai, kita dapat mengekspor objek Pandas ke file CSV untuk mengirim data untuk analisis hilir.
Di bawah ini adalah semua kode Python:
import pandas as pd
import requests as req
import lxml.html as ext
import json
url="https://www.imdb.com/chart/top/?ref_=nv_mp_mv250"
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36 Edg/111.0.1661.51',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'en-US,en;q=0.9'
}
response = req.get(url, headers=headers)
tree = ext.fromstring(response.text)
movies = (ext.tostring(x) for x in tree.cssselect('table(data-caller-name="chart-top250movie") > tbody > tr'))
all_data = pd.DataFrame()
for idx, movie in enumerate(movies):
print('Processing {}'.format(idx))
tree = ext.fromstring(movie)
url="https://www.imdb.com{}".format(tree.cssselect('a')(1).get('href'))
rating = tree.cssselect('td.ratingColumn.imdbRating strong')(0).text_content()
response = req.get(url, headers=headers)
tree = ext.fromstring(response.text)
script = json.loads(tree.cssselect('script(type="application/ld+json")')(0).text_content())
row = {
'Title': script('name'),
'Rating': rating,
'Summary': script('description')
}
all_data = pd.concat((all_data, pd.DataFrame((row))), ignore_index=True)
all_data.to_csv('final_data.csv', index = False)
Gunakan kumpulan data berikut sesuai keinginan Anda. Mungkin menonton pesta di akhir pekan?
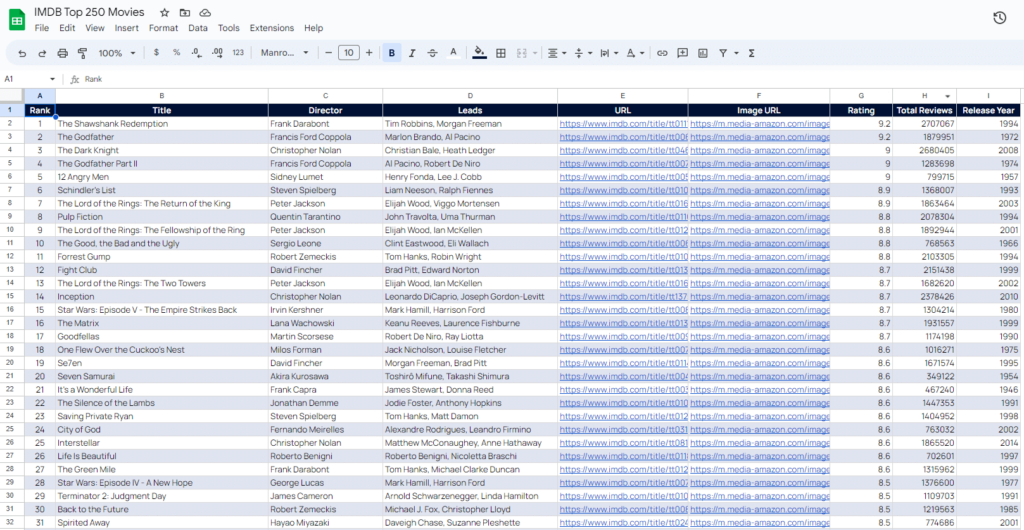
kata-kata terakhir
Dengan Python, kami memasukkan setiap halaman film dan mengekstrak ringkasan film.
Membatalkan tautan di PHP, kita tidak perlu mendefinisikan header dalam kode kita. Terutama karena halaman internal kali ini jauh lebih sulit dan selanjutnya dikupas oleh server web.
Pada artikel ini, kami telah menggunakan metode dasar untuk mengakses data tanpa menyebabkan kesalahan yang tidak perlu.
Saat ini, sebagian besar situs web di Internet menerapkan tindakan anti-bot yang ketat. Untuk proyek ekstraksi data jangka panjang yang serius, solusi sederhana seperti ini tidak akan berhasil.
Oleh karena itu, perusahaan yang secara rutin mengandalkan proyek ekstraksi data skala besar memilih Grepsr.
Bacaan Terkait: