
PHP adalah bahasa pemrograman yang banyak digunakan dan dikenal karena kemudahan penggunaan dan kemampuan eksekusi sisi server. Hal ini menjadikannya pilihan ideal untuk pengembangan web scraper karena Anda dapat memindahkan eksekusi scraper dari komputer lokal Anda ke sumber daya server. Selain itu, mengintegrasikan PHP dengan alat penjadwalan seperti Crontab memungkinkan Anda mengatur tugas pengikisan otomatis untuk dijalankan secara berkala.
Artikel ini membahas proses komprehensif pembuatan scraper web PHP, mencakup semuanya mulai dari menyiapkan lingkungan pengembangan dan menginstal komponen yang diperlukan hingga membuat permintaan web, menganalisis data, dan menyimpan informasi yang diekstrak ke file. Kami juga mengeksplorasi teknik pengikisan dasar dan strategi lanjutan untuk meningkatkan efisiensi dan kegunaan pengikis Anda.
Daftar Isi
Mengapa menggunakan PHP untuk web scraping?
PHP adalah bahasa pemrograman berorientasi objek kuat yang dirancang khusus untuk pengembangan web. Sintaksnya yang ramah pengguna membuatnya mudah dipelajari dan dipahami bahkan untuk pemula. Selain ramah pengguna, PHP juga menawarkan performa luar biasa, sehingga skrip PHP dapat dijalankan dengan cepat dan efisien.
Secara keseluruhan, PHP menawarkan kombinasi sempurna antara kesederhanaan, kecepatan dan fleksibilitas. PHP memiliki komunitas yang besar dan aktif serta koleksi perpustakaan sumber terbuka yang luas untuk web scraping, seperti Simple HTML DOM Parser, Goutte dan Symfony Panther.
Aspek penting adalah eksekusi sisi server (skrip PHP dapat dijalankan langsung di server, menghilangkan kebutuhan akan instalasi lokal atau otomatisasi browser), sehingga ideal untuk tugas web scraping yang perlu dilakukan secara efisien tanpa bergantung pada komputer lokal Anda. .
Menyiapkan lingkungan
Untuk membuat scraper PHP, kita perlu menyiapkan PHP dan mengunduh perpustakaan yang nantinya akan kita sertakan dalam proyek kita. Namun, ada dua cara yang bisa kita lakukan. Anda dapat mengunduh semua perpustakaan secara manual dan mengonfigurasi file inisialisasi atau mengotomatiskannya menggunakan Komposer.
Karena tujuan kami adalah membuat skrip semudah mungkin dan menunjukkan cara melakukannya, kami akan menginstal Komposer dan menjelaskan cara menggunakannya.
Instal PHP di Linux dan MacOS
Proses instalasi PHP di Linux dan macOS sangat mirip. Pertama, buka jendela terminal dan pastikan informasi paket sistem Anda mutakhir dengan perintah berikut:
sudo apt updateSetelah informasi paket diperbarui, lanjutkan untuk menginstal PHP menggunakan perintah berikut:
sudo apt install php-cliPerintah ini menginstal versi terbaru PHP beserta dependensi yang diperlukan.
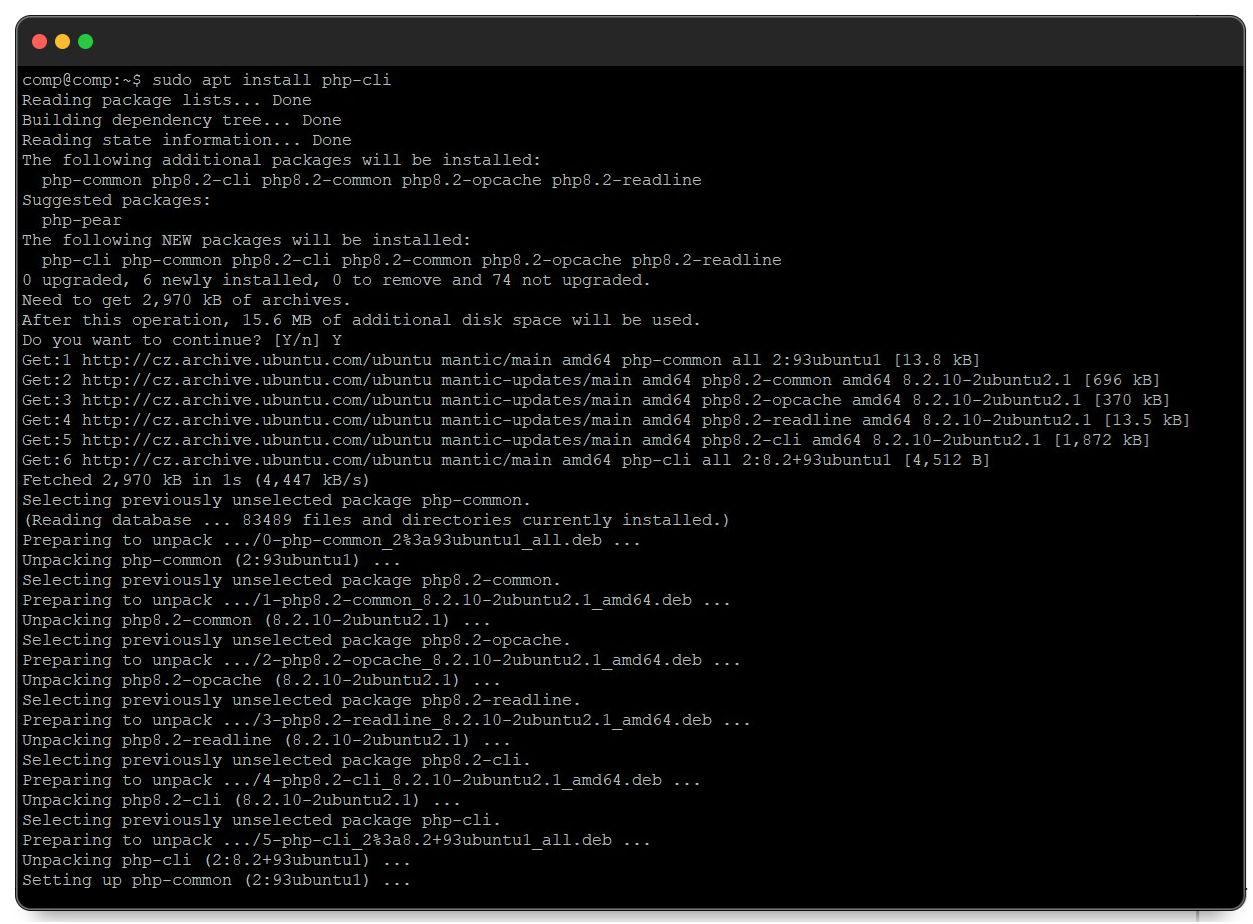
Setelah itu, Anda dapat menggunakan PHP yang terinstal untuk menjalankan skrip.
Instal PHP di Windows
Pertama, unduh PHP dari situs resminya. Jika Anda menggunakan Windows, unduh versi stabil terbaru sebagai arsip zip. Kemudian unzip ke lokasi yang mudah diingat, seperti folder “PHP” di drive C Anda.
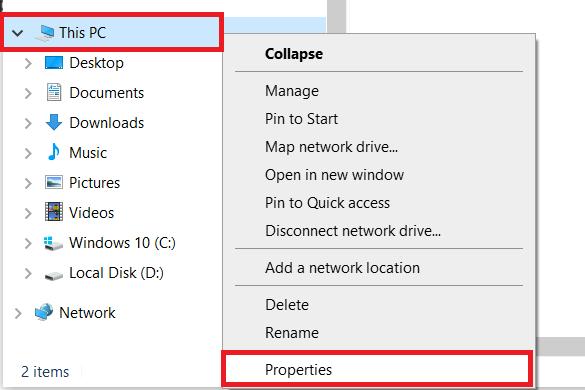
Jika Anda menggunakan Windows, Anda perlu mengatur jalur ke file PHP di sistem Anda. Untuk melakukan ini, buka folder mana pun di komputer Anda dan buka Pengaturan Sistem (klik kanan pada PC ini dan buka Properti).
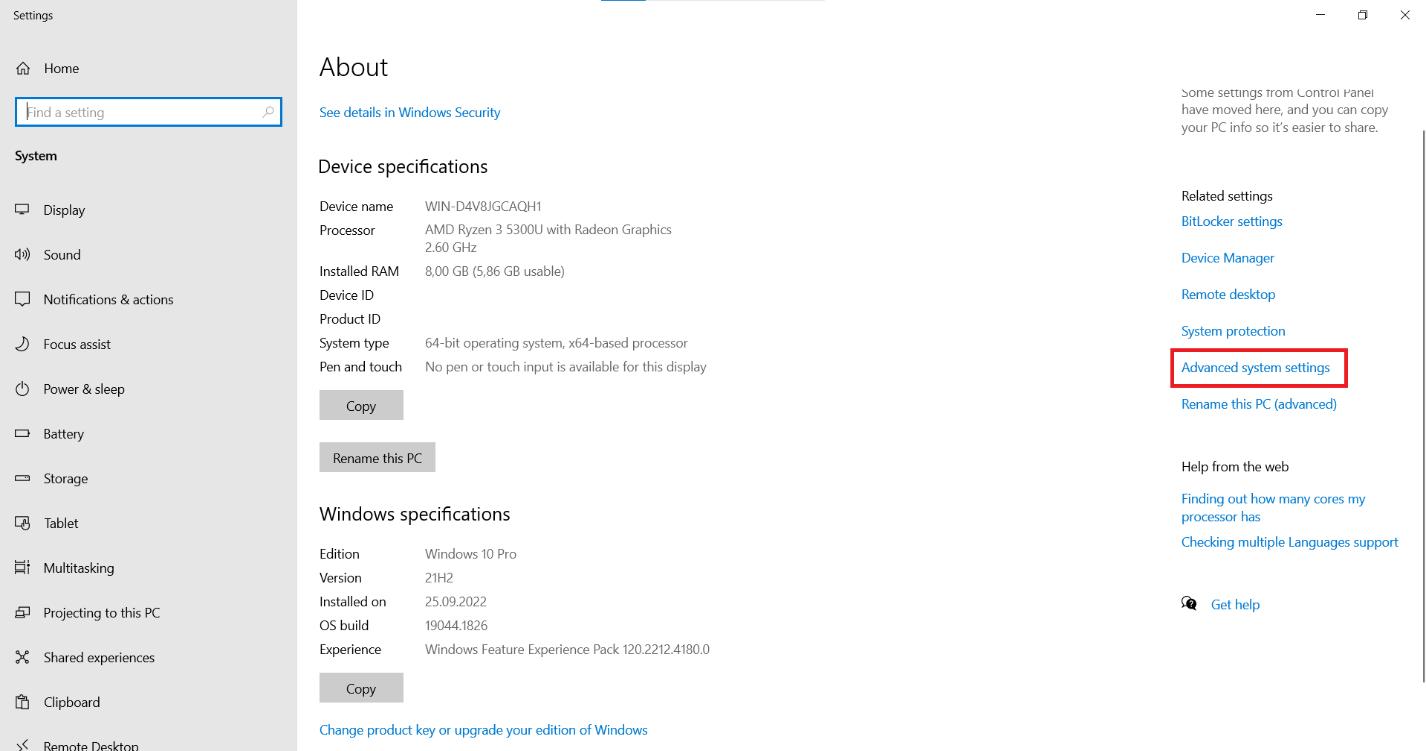
Di halaman tersebut, cari opsi “Pengaturan Sistem Lanjutan” dan klik di atasnya.
Pada tab Advanced, cari tombol Environment Variables dan klik.
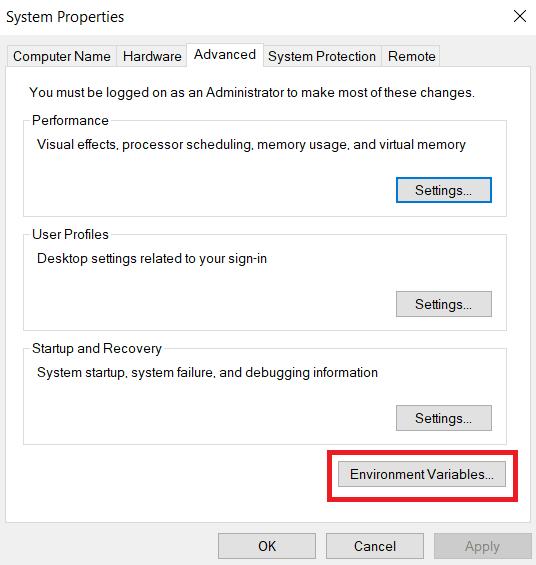
Di bagian “Variabel Pengguna untuk Pengguna”, temukan variabel “Jalur” dan klik tombol “Edit”.
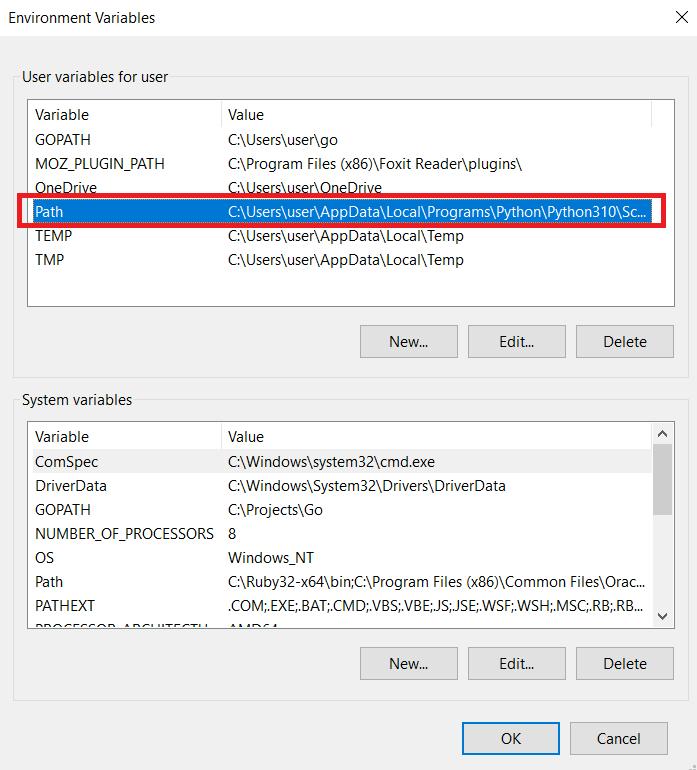
Jendela baru terbuka di mana Anda dapat mengedit nilai variabel “Jalur”. Di akhir nilai yang ada, tambahkan path ke file PHP. Klik tombol OK untuk menyimpan perubahan. Jika Anda masih memiliki pertanyaan, Anda dapat membaca dokumentasinya.
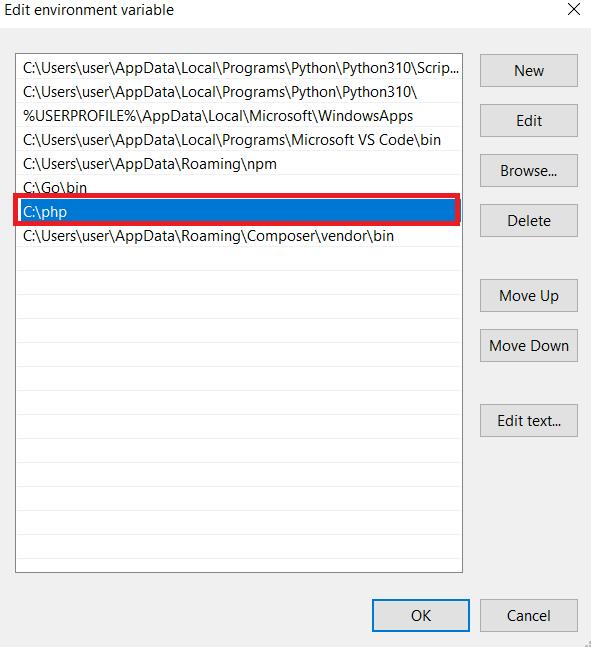
Sekarang mari kita instal Composer, manajer ketergantungan untuk PHP yang memudahkan pengelolaan dan instalasi perpustakaan pihak ketiga di proyek Anda. Anda dapat mengunduh semua paket dari github.com, tetapi menurut pengalaman kami, Komposer lebih nyaman.
Untuk memulai, buka situs web resmi dan unduh Komposer. Kemudian ikuti petunjuk di file instalasi. Anda juga perlu menentukan jalur dimana PHP berada. Oleh karena itu, pastikan ini diatur dengan benar.
Di root proyek Anda, buat file baru bernama composer.json. File ini berisi informasi tentang dependensi proyek Anda. Kami telah menyiapkan satu file yang berisi semua perpustakaan yang digunakan dalam tutorial hari ini sehingga Anda dapat melihat pengaturan kami.
{
"require": {
"guzzlehttp/guzzle": "^7.7",
"sunra/php-simple-html-dom-parser": "^1.5"
},
"config": {
"platform": {
"php": "8.2.7"
},
"preferred-install": {
"*": "dist"
},
"minimum-stability": "stable",
"prefer-stable": true,
"sort-packages": true
}
}Pertama, navigasikan ke direktori yang berisi file composer.json pada baris perintah dan jalankan perintah berikut:
composer install Komposer mengunduh dependensi tertentu dan menginstalnya ke direktori vendor proyek Anda.
Anda sekarang dapat mengimpor perpustakaan ini ke proyek Anda menggunakan perintah di file dengan kode Anda.
require 'vendor/autoload.php';Sekarang Anda dapat menggunakan kelas dari perpustakaan yang diinstal hanya dengan memanggilnya dalam kode Anda
Pengikisan web dasar dengan PHP
Mengurai situs web sederhana biasanya melibatkan penggunaan permintaan dasar dan perpustakaan parse. Untuk permintaan kami menggunakan perpustakaan cURL (Perpustakaan URL Klien) dan untuk menguraikan halaman HTML yang diambil kami menggunakan perpustakaan Simple HTML DOM Parser. Pendekatan ini memperkenalkan contoh-contoh dasar dan membantu memahami teknik pengikisan halaman sederhana.
Sayangnya, tidak semua situs web mengizinkan pengumpulan data dengan mudah. Oleh karena itu, Anda mungkin perlu menggunakan perpustakaan yang lebih canggih di masa mendatang. Untuk memudahkan Anda memilih perpustakaan yang paling sesuai dengan kebutuhan Anda, kami telah menyusun artikel terpisah yang menjelaskan semua perpustakaan scraping PHP yang populer.
Analisis halaman
Sekarang kita sudah menyiapkan lingkungan dan menyiapkan semua komponen, mari kita analisa website yang akan kita scrap. Kami akan menggunakan situs demo ini sebagai contoh. Buka situs web dan buka konsol pengembang (F12 atau klik kanan dan buka "Periksa").
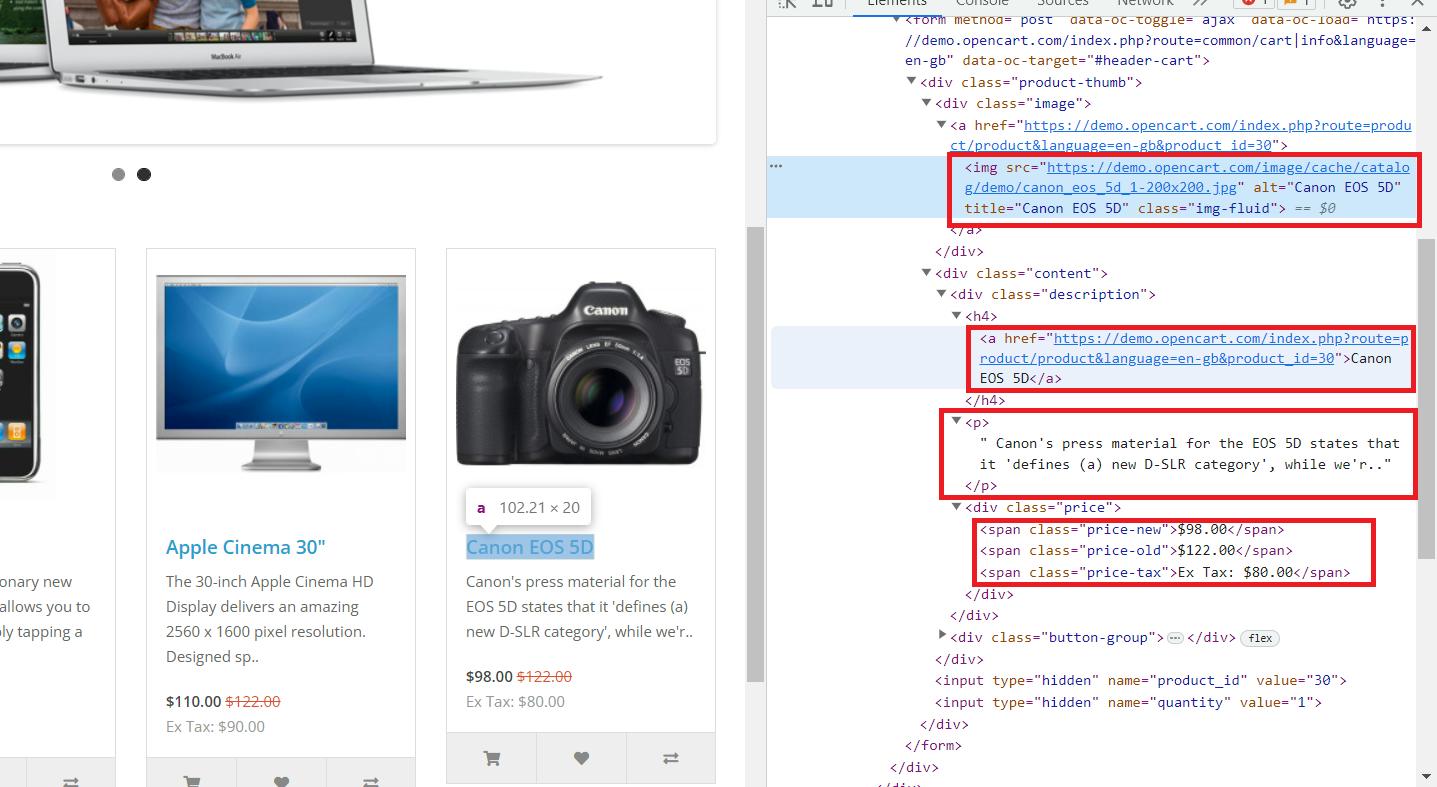
Di sini kita melihat bahwa semua data yang diperlukan disimpan dalam tag induk “div” dengan nama kelas “col”, yang berisi semua produk di halaman. Ini berisi informasi berikut:
- Tag “img” berisi link ke gambar produk di atribut “src”.
- Tag “a” berisi link produk di atribut “href”.
- Tag “h4” berisi judul produk.
- Tag “p” berisi deskripsi produk.
- Harga disimpan dalam tag span dengan kelas yang berbeda:
- “Harga lama” dengan harga aslinya.
- “Harga baru” dengan harga promosi.
- “Pajak harga” untuk pajak.
Sekarang kita tahu di mana informasi yang kita butuhkan disimpan, kita bisa mulai melakukan scraping.
Menggunakan cURL untuk mengambil halaman web
Pustaka cURL menawarkan berbagai fungsi untuk mengelola permintaan. Sangat bagus untuk mendapatkan kode dari halaman yang datanya perlu dikumpulkan. Selain itu, Anda dapat menggunakannya untuk mengelola data, misalnya. B. dengan menggunakan verifikasi sertifikat SSL saat membuat permintaan atau menambahkan opsi tambahan seperti agen pengguna.
Untuk lebih memahami kemampuan perpustakaan ini, mari kita ambil kode HTML dari website yang telah dibahas sebelumnya. Untuk melakukan ini, buat file baru dengan *.php Ekstensi dan inisialisasi cURL:
Kemudian tentukan alamat website dan tipe data sebagai parameternya, misalnya dalam bentuk string:
curl_setopt($ch, CURLOPT_URL, "https://demo.opencart.com");
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);Anda juga dapat menentukan berbagai parameter lain sebagai opsi pada langkah ini, seperti:
1. Agen pengguna. Anda dapat mengambil salah satu agen pengguna terbaru dari situs kami dan menentukannya dalam skrip Anda.
curl_setopt($ch, CURLOPT_USERAGENT, "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36");2. Kelola sertifikat SSL dan nonaktifkan verifikasinya:
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);Atau tentukan jalur ke bundel CA:
curl_setopt($ch, CURLOPT_CAINFO, "/cacert.pem");3. Konfigurasikan batas waktu.
curl_setopt($ch, CURLOPT_TIMEOUT, 30); // Maximum time in seconds to allow cURL functions to execute
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10); // Maximum time in seconds to wait while trying to connect4. Sesuaikan cookie. Anda dapat menyimpannya ke file:
curl_setopt($ch, CURLOPT_COOKIEJAR, "cookies.txt");Anda juga dapat menggunakannya dari file:
curl_setopt($ch, CURLOPT_COOKIEFILE, "cookies.txt");Setelah mengonfigurasi permintaan Anda, Anda perlu menjalankannya:
$response = curl_exec($ch);Selanjutnya, kami menampilkan hasil query atau pesan kesalahan jika perlu di layar:
if ($response === false) {
echo 'cURL error: ' . curl_error($ch);
} else {
echo $response;
}Pastikan untuk menutup koneksi di akhir:
curl_close($ch);Mari kita pertahankan hanya parameter yang diperlukan dan berikan contoh skrip akhir:
Ini akan mengambil semua HTML dari halaman yang diminta. Kita perlu mengurai kode yang diambil untuk mengekstrak data tertentu dan untuk itu kita memerlukan perpustakaan lain.
Parsing HTML dengan Parser DOM HTML Sederhana
Mari kita perbaiki skrip yang kita diskusikan sebelumnya untuk mengekstrak hanya data yang relevan dari halaman. Untuk melakukan hal ini, kami menyertakan perpustakaan tambahan sebelum menginisialisasi sesi cURL:
require 'simple_html_dom.php';Jika Anda menggunakan Composer untuk manajemen ketergantungan, Anda perlu menambahkan Simple HTML DOM Parser ke file composer.json Anda:
"require": {
"sunra/php-simple-html-dom-parser": "^1.5.2"
}Kemudian perbarui dependensi Anda menggunakan perintah berikut:
composer updateSetelah ini selesai, Anda dapat mengimpor perpustakaan ke dalam skrip Anda:
require 'vendor/autoload.php';
use Sunra\PhpSimple\HtmlDomParser;Langkah inisialisasi permintaan dan konfigurasi tetap sama. Kami hanya mengubah bagian pemrosesan respons:
if ($response === false) {
echo 'cURL error: ' . curl_error($ch);
} else {
// Here will be parsing process
}Parsing seluruh halaman sebagai kode HTML:
$html = HtmlDomParser::str_get_html($response);Selanjutnya, ekstrak dan tampilkan semua data produk:
$products = $html->find('.col');
foreach ($elements as $element) {
$image = $element->find('img', 0)->src;
$title = $element->find('h4', 0)->plaintext;
$link = $element->find('h4 > a', 0)->href;
$desc = $element->find('p', 0)->plaintext;
$old_p_element = $element->find('span.price-old', 0);
$old_p = $old_p_element ? $old_p_element->plaintext : '-';
$new_p = $element->find('span.price-new', 0)->plaintext;
$tax = $element->find('span.price-tax', 0)->plaintext;
echo 'Image: ' . $image . "\n";
echo 'Title: ' . $title . "\n";
echo 'Link: ' . $link . "\n";
echo 'Description: ' . $desc . "\n";
echo 'Old Price: ' . $old_p . "\n";
echo 'New Price: ' . $new_p . "\n";
echo 'Tax: ' . $tax . "\n";
echo "\n";
}Pada akhirnya kami akan merilis sumber daya:
$html->clear();Ini memberi kami informasi tentang semua produk di situs dan memungkinkan kami menampilkannya dalam format yang mudah digunakan. Selanjutnya, kami akan menjelaskan cara menyimpan data ini ke file untuk memudahkan akses dan pengeditan.
Penyimpanan dan pemrosesan data
Penyimpanan data merupakan aspek penting dalam proses pengumpulan data. Data yang diambil biasanya disimpan dalam format JSON, database, atau CSV, bergantung pada tujuan penggunaan. JSON cocok untuk pemrosesan atau transmisi lebih lanjut, database memungkinkan penyimpanan dan pengambilan terorganisir, dan CSV menawarkan kesederhanaan dan kompatibilitas.
Membersihkan dan memproses data
Pembersihan data merupakan langkah penting dalam prapemrosesan data. Ini memastikan keakuratan dan konsistensi data sebelum disimpan atau dianalisis. Kesalahan, inkonsistensi dan pola yang tidak diinginkan dalam data diidentifikasi dan diperbaiki. Hal ini dapat membantu menghindari kesalahan penghitungan, analisis data, dan model pembelajaran mesin.
Pertama-tama, penting untuk membersihkan teks dari tag HTML yang tidak perlu yang mungkin tersisa dari pemformatan. Ini dapat dilakukan dengan menggunakan strip_tags() Fungsi:
$cleanText = strip_tags($dirtyText);Selain itu, Anda dapat menghapus semua spasi di awal dan akhir teks atau string:
$cleanText = trim($dirtyText);Fungsi penggantian karakter berguna untuk menghilangkan atau mengganti karakter yang tidak diinginkan, seperti karakter khusus:
$cleanText = preg_replace('/(^A-Za-z0-9\-)/', '', $dirtyText);Terkadang kesalahan bisa terjadi jika variabel tidak berisi data. Dalam kasus seperti ini, Anda dapat mengganti nilai kosong dengan nilai default:
$cleanText = empty($dirtyText) ? 'default' : $dirtyText;Dengan menggunakan teknik ini, Anda dapat secara efektif menyiapkan kumpulan data mentah untuk penyimpanan nanti. Hal ini sangat penting karena ruang yang tertinggal di akhir baris secara tidak sengaja dapat menyebabkan kesalahan penghitungan atau kerusakan data.
Menyimpan data yang tergores
Daripada mengeluarkan data yang diambil ke layar, kita bisa menyimpannya ke file CSV dengan membuat array data dan menulisnya. Mari kita ubah bagian pengambilan data untuk menyimpan data dalam variabel alih-alih menampilkannya:
$products = $html->find('.col');
$data = ();
foreach ($products as $element) {
$image = $element->find('img', 0)->src;
$title = $element->find('h4', 0)->plaintext;
$link = $element->find('h4 > a', 0)->href;
$desc = $element->find('p', 0)->plaintext;
$old_p_element = $element->find('span.price-old', 0);
$old_p = $old_p_element ? $old_p_element->plaintext : '-';
$new_p = $element->find('span.price-new', 0)->plaintext;
$tax = $element->find('span.price-tax', 0)->plaintext;
$data() = (
'image' => $image,
'title' => $title,
'link' => $link,
'description' => $desc,
'old_price' => $old_p,
'new_price' => $new_p,
'tax' => $tax
);
}Buat file CSV dan tulis datanya:
$csvFile = fopen('products.csv', 'w');
fputcsv($csvFile, ('Image', 'Title', 'Link', 'Description', 'Old Price', 'New Price', 'Tax'));
foreach ($data as $row) {
fputcsv($csvFile, $row);
}
fclose($csvFile);Untuk menyimpan data dalam format JSON, kita bisa menggunakan array data yang sama yang dibuat sebelumnya:
file_put_contents('products.json', json_encode($data, JSON_PRETTY_PRINT));Untuk menyimpan data dalam database, Anda perlu menyambungkan dan memasukkan data satu baris dalam satu waktu. Metode penulisan dan koneksi yang tepat bergantung pada sistem manajemen basis data (DBMS) yang Anda pilih.
Teknik tingkat lanjut
Untuk mengikis data dengan lebih efisien, Anda perlu menggunakan metode dan pustaka yang lebih canggih yang memungkinkan Anda mengumpulkan data dari sumber yang lebih luas. Bagian ini membahas teknik tambahan dan memberikan contoh untuk mengambil data dari halaman web dinamis, menggunakan proxy, dan meningkatkan kecepatan pengikisan.
Berurusan dengan konten dinamis
Mengikis konten dinamis yang dihasilkan JavaScript dapat menjadi tantangan jika menggunakan teknik pengikisan web tradisional. Berikut adalah dua pendekatan umum:
- Peramban tanpa kepala. Gunakan perpustakaan yang memungkinkan interaksi dengan browser tanpa kepala. Hal ini memungkinkan Anda mengontrol proses pengikisan dan menyimulasikan perilaku pengguna, sehingga mengurangi risiko pemblokiran. Namun, PHP memerlukan pengetahuan tingkat lanjut dan bukan bahasa yang paling cocok untuk browser tanpa kepala.
- API pengikisan web. Gunakan API khusus yang dirancang untuk pengikisan konten dinamis. API ini sering kali memberikan dukungan proxy, yang memungkinkan akses ke data spesifik wilayah. Selain itu, pengumpulan data terjadi di sisi penyedia API, memastikan keamanan dan anonimitas Anda.
Misalnya, mari kita membuat skrip untuk mengumpulkan data yang sama, tetapi hanya menggunakan API web scraping HasData. Untuk melakukan ini, masuk ke situs web kami dan salin kunci API dari akun Anda.
Buat skrip PHP baru dan inisialisasi sesi baru:
$curl = curl_init();Tetapkan parameter permintaan, termasuk pemilih CSS dan kunci API Anda:
curl_setopt_array($curl, (
CURLOPT_URL => "https://api.hasdata.com/scrape/web",
CURLOPT_RETURNTRANSFER => true,
CURLOPT_CUSTOMREQUEST => "POST",
CURLOPT_POSTFIELDS => json_encode((
'url' => 'https://demo.opencart.com/',
'proxyCountry' => 'US',
'proxyType' => 'datacenter',
'extractRules' => (
'Image' => 'img @src',
'Title' => 'h4',
'Link' => 'h4 > a @href',
'Description' => 'p',
'Old Price' => 'span.price-old',
'New Price' => 'span.price-new',
'Tax' => 'span.price-tax'
)
)),
CURLOPT_HTTPHEADER => (
"Content-Type: application/json",
"x-api-key: PUT-YOUR-API-KEY"
),
));Buat permintaan dan lihat hasilnya:
$response = curl_exec($curl);
$err = curl_error($curl);
curl_close($curl);
if ($err) {
echo "cURL Error #:" . $err;
} else {
echo $response;
}Contoh ini menunjukkan cara menggunakan scraping API untuk mengumpulkan data dari situs web mana pun. Namun, jika situs web yang Anda minati memiliki API scraping khusus, biasanya disarankan untuk menggunakannya. Ini biasanya memberi Anda data terlengkap dengan cara paling sederhana.
Pengikisan paralel
Anda memerlukan perpustakaan lain yang menyediakan fungsionalitas yang diperlukan untuk bekerja dengan aliran. Misalnya, kami menggunakan perpustakaan Guzzle, yang bagus untuk membuat kueri dan menguraikan data. Pertama tambahkan impor ke Komposer atau impor perpustakaan secara langsung:
"require": {
"guzzlehttp/guzzle": "^7.7"
}Perbarui Komposer dan tentukan impor dalam skrip:
require 'vendor/autoload.php';
use GuzzleHttp\Client;
use GuzzleHttp\Pool;
use GuzzleHttp\Psr7\Request;
use GuzzleHttp\Exception\RequestException;Tempatkan URL halaman yang ingin Anda kikis ke dalam variabel:
$urls = (
"https://demo.opencart.com",
"https://example.com"
);Buat klien HTTP untuk memproses permintaan:
$client = new Client();
$requests = function ($urls) {
foreach ($urls as $url) {
yield new Request('GET', $url);
}
};Buat kumpulan multiproses dengan 2 thread:
$pool = new Pool($client, $requests($urls), (
'concurrency' => 2,
'fulfilled' => function ($response, $index) {
echo "Response received from request #$index: " . $response->getBody() . "\n";
},
'rejected' => function (RequestException $reason, $index) {
echo "Request #$index failed: " . $reason->getMessage() . "\n";
},
));Memulai transfer dan membuat janji:
$promise = $pool->promise();Kemudian tunggu hingga kumpulan permintaan selesai:
$promise->wait();Secara keseluruhan, pendekatan multiprosesor ini secara signifikan meningkatkan kecepatan dan efisiensi tugas pengumpulan data.
Memutar proxy
Untuk menutupi alamat IP Anda saat melakukan scraping dan melewati berbagai batasan, Anda dapat menggunakan proxy. Kita sudah membahas apa itu proxy, mengapa Anda harus menggunakannya, dan di mana menemukan proxy berbayar dan gratis. Jadi mari kita ke aplikasi praktis dalam tutorial ini.
Kami mengambil skrip yang telah dibahas sebelumnya sebagai dasar dan menambahkan penggunaan proxy acak dari daftar. Untuk melakukan ini, kita membuat variabel dan menambahkan proxy ke dalamnya:
$proxies = (
'http://38.10.90.246:8080',
'http://103.196.28.6:8080',
'http://79.174.188.153:8080',
);Kami kemudian memodifikasi sedikit eksekusi permintaan untuk memperhitungkan proxy:
$requests = function ($urls, $proxies) {
foreach ($urls as $url) {
$proxy = $proxies(array_rand($proxies));
yield new Request('GET', $url, ('proxy' => $proxy));
}
};
$pool = new Pool($client, $requests($urls, $proxies), (
'concurrency' => 2,
'fulfilled' => function ($response, $index) {
echo "Response received from request #$index: " . $response->getBody() . "\n";
},
'rejected' => function (RequestException $reason, $index) {
echo "Request #$index failed: " . $reason->getMessage() . "\n";
},
));Kode lainnya tetap sama, tetapi sekarang untuk setiap permintaan, baris acak dengan proxy dipilih dari daftar yang disimpan dalam variabel. Pendekatan ini memungkinkan Anda menghindari pemblokiran setiap proxy lebih lama dan meningkatkan keandalan skrip secara keseluruhan.
Tambahkan tugas pengikisan ke cron
PHP adalah bahasa scripting dan tidak cocok untuk penggunaan terus-menerus. Ini lebih cocok untuk eksekusi berkala, di mana tugas dijalankan dan kemudian skrip ditutup. Jadi, jika Anda perlu terus-menerus mengumpulkan data, akan lebih mudah jika Anda mengatur eksekusi otomatis pada waktu tertentu atau setelah interval tertentu.
Untuk mengatasi tugas ini di sistem Linux, Anda dapat menggunakan Crontab, yang memungkinkan Anda membuat jadwal tugas. Untuk menambahkan eksekusi skrip ke jadwal, luncurkan Terminal dan jalankan perintah berikut:
crontab -eIni akan memulai tugas cron untuk mengedit. Di akhir file, Anda perlu menulis data dalam format "Kapan dijalankan - Alat untuk dijalankan - Apa yang dijalankan". Misalnya untuk menjalankan script /home/comp/php_scripts/scraper.php dengan /usr/bin/php setiap menit Anda perlu menambahkan yang berikut ini ke akhir file:
* * * * * /usr/bin/php /home/comp/php_scripts/scraper.phpSeharusnya terlihat seperti ini:
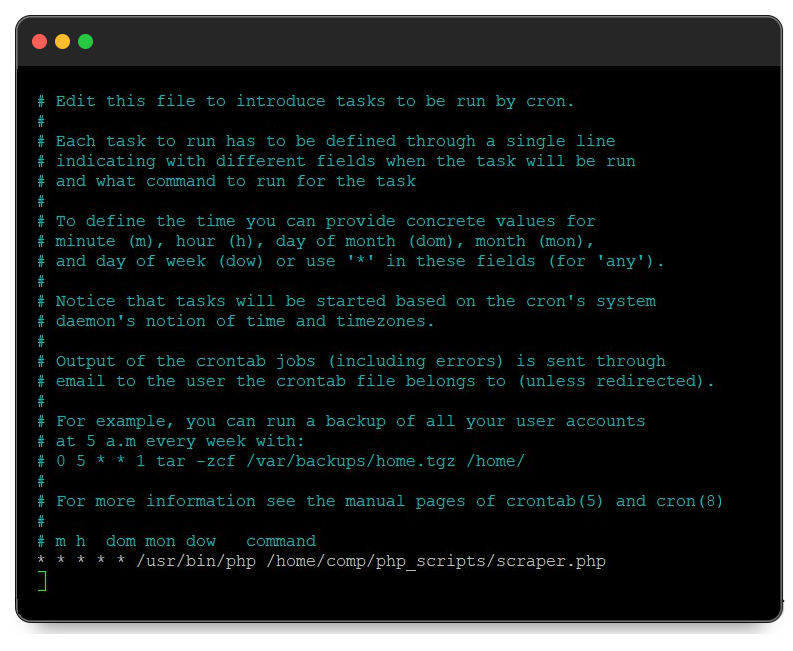
Setelah Anda melakukan perubahan, simpan file menggunakan pintasan keyboard Ctrl+O. Script kemudian dieksekusi pada frekuensi yang diinginkan.
Diploma
PHP menyediakan platform yang kuat dan fleksibel untuk web scraping, didukung oleh alat canggih seperti cURL dan Simple HTML DOM Parser. Saat Anda menulis scraper di PHP, skrip dapat dijalankan di server, bukan di PC, sehingga memanfaatkan sumber daya server untuk kenyamanan. Selain itu, skrip dapat diatur agar berjalan secara berkala menggunakan alat penjadwalan seperti Crontab, membuat ekstraksi data berkelanjutan menjadi sangat nyaman.
Artikel ini membahas seluruh proses pembuatan pengikis semacam itu. Kami memulai dengan menyiapkan lingkungan dan menginstal komponen yang diperlukan. Kami kemudian membuat permintaan HTTP, menguraikan data yang diambil, dan menyimpannya ke file. Kami juga membahas pembuatan alat dan teknik sederhana untuk membuat skrip Anda lebih efisien dan berguna.
Dengan menggunakan PHP untuk web scraping, Anda dapat mengotomatiskan pengumpulan dan pemrosesan data, memastikan bahwa tugas Anda dilakukan secara efisien dan andal pada sumber daya server.