
Dalam artikel ini, kami akan memandu Anda melalui panduan langkah demi langkah untuk mengambil data Realtor.com menggunakan Python (untuk menulis skrip kami) dan API ScraperAPI standar untuk menghindari pemblokiran.
Daftar Isi
TL;DR: Scraper Realtor.com lengkap
Bagi yang sedang terburu-buru, berikut skrip lengkap yang akan kita buat dalam tutorial ini:
import requests
from bs4 import BeautifulSoup
import json
output_data = ()
base_url = "https://www.realtor.com/realestateandhomes-search/Atlanta_GA/show-newest-listings/sby-6"
API_KEY = "API_KEY"
def scrape_listing(num_pages):
for page in range(1, num_pages + 1):
# To scrape page 1
if page == 1:
url = f"{base_url}"
else:
url = (
f"{base_url}/pg-{page}" # Adjust the URL structure based on the website
)
print(f"Scraping data from page {page}... {url}")
payload = {"api_key": API_KEY, "url": url}
# Make a request to the ScraperAPI
r = requests.get("http://api.scraperapi.com", params=payload)
html_response = r.text
# Parse the HTML response using BeautifulSoup
soup = BeautifulSoup(html_response, "lxml")
# scraping individual page
listings = soup.select("div(class^='BasePropertyCard_propertyCardWrap__')")
print("Listings found!")
for listing in listings:
price = listing.find("div", class_="card-price")
price = price.get_text(strip=True) if price else "nil"
full_address = listing.find("div", class_="card-address")
full_address = full_address.get_text(strip=True) if full_address else "nil"
address_parts = full_address.split(", ")
address = address_parts(0) if address_parts else "nil"
township = address_parts(1) if len(address_parts) > 1 else "nil"
property_url_elements = listing.select("a(class^='LinkComponent_anchor__')")
property_url = "nil" # Default value if property_url_elements is empty
for element in property_url_elements:
property_url = "https://www.realtor.com" + element("href")
break
beds = listing.find(
"li",
class_="PropertyBedMetastyles__StyledPropertyBedMeta-rui__a4nnof-0",
)
beds = (
beds.find("span", {"data-testid": "meta-value"}).text.strip()
if beds
else "nil"
)
baths = listing.find(
"li",
class_="PropertyBathMetastyles__StyledPropertyBathMeta-rui__sc-67m6bo-0",
)
baths = baths.find("span").text.strip() if baths else "nil"
sqft = listing.find(
"li",
class_="PropertySqftMetastyles__StyledPropertySqftMeta-rui__sc-1gdau7i-0",
)
sqft = (
sqft.find("span", {"data-testid": "screen-reader-value"}).text.strip()
if sqft
else "nil"
)
plot_size = listing.find(
"li",
class_="PropertyLotSizeMetastyles__StyledPropertyLotSizeMeta-rui__sc-1cz4zco-0",
)
plot_size = (
plot_size.find(
"span", {"data-testid": "screen-reader-value"}
).text.strip()
if plot_size
else "nil"
)
property_data = {
"price": price,
"address": address,
"township": township,
"url": property_url,
"beds": beds,
"baths": baths,
"square_footage": sqft,
"plot_size": plot_size,
}
output_data.append(property_data)
num_pages = 5 # Set the desired number of pages
# Scrape data from multiple pages
scrape_listing(num_pages)
# our property count
output_data.append({"num_hits": len(output_data)})
# Write the output to a JSON file
with open("Realtor_data.json", "w") as json_file:
json.dump(output_data, json_file, indent=2)
print("Output written to output.json")
Catatan: Pengganti API_KEY Masukkan kunci API Anda yang sebenarnya ke dalam kode sebelum menjalankan skrip.
Ingin mempelajari cara kami membangunnya? Baca terus untuk penjelasan langkah demi langkah.
Mengikis data produk dari Realtor.com
Sebelum Anda mulai melakukan scraping, penting untuk menentukan informasi spesifik apa yang ingin Anda ekstrak dari halaman web. Dalam tutorial ini kita akan fokus pada detail berikut:
- Harga jual properti
- Alamat real estat
- URL daftar properti
- Jumlah tempat tidur dan kamar mandi
- Kawasan properti
- Ukuran properti
persyaratan
Persyaratan utama untuk tutorial ini adalah pustaka Python, Requests, BeautifulSoup, dan Lxml. Jalankan perintah ini untuk melakukan instalasi yang sesuai.
pip install beautifulsoup4 requests lxml
Langkah 1: Menyiapkan proyek Anda
Catatan: Sebelum memulai, pastikan Anda mendaftar akun ScraperAPI gratis untuk mendapatkan kunci API Anda.
Pertama, kita mengimpor pustaka Python yang diperlukan di bagian atas pustaka kita .py Mengajukan.
import requests
from bs4 import BeautifulSoup
import json
Kami kemudian menginisialisasi variabel yang kami gunakan dalam skrip kami.
output_data = ()
base_url = "https://www.realtor.com/realestateandhomes-search/Atlanta_GA/show-newest-listings/sby-6"
API_KEY = "YOUR_API_KEY"
output_datamenyimpan datanyabase_urladalah URL halaman Realtor.com yang ingin kita cari - setidaknya URL asli - yang bisa Anda dapatkan dengan menavigasi ke situs dan melakukan pencarianAPI_KEYberisi kunci ScraperAPI kami sebagai string
Langkah 2: Tentukan fungsi pengikisan Anda
Kami mendefinisikan suatu fungsi, scrape_listing()yang menggunakan jumlah halaman untuk dipindai sebagai argumen, memungkinkan kita untuk mengikis beberapa halaman.
def scrape_listing(num_pages):
for page in range(1, num_pages + 1):
# To scrape page 1
if page == 1:
url = f"{base_url}"
else:
url = f"{base_url}/pg-{page}" # Adjust the URL structure based on the website
print(f"Scraping data from page {page}... {url}")
payload = {"api_key": API_KEY, "url": url}
# Make a request to the ScraperAPI
r = requests.get("http://api.scraperapi.com", params=payload)
html_response = r.text
soup = BeautifulSoup(html_response, "lxml")
Kita mengulang setiap halaman, membuat URL untuk halaman tersebut, membuat permintaan GET ke ScraperAPI, dan memunculkan objek BeautifulSoup untuk setiap halaman.
Catatan: Kami perlu mengirimkan permintaan kami melalui ScraperAPI untuk mencegah IP kami diblokir sehingga kami dapat mengumpulkan data dalam skala besar.
Langkah 3: Parsing respons HTML
Dengan mengurai respons HTML dengan BeautifulSoup, kita dapat mengubah HTML mentah menjadi pohon parsing yang dapat kita navigasikan menggunakan pemilih CSS.
Jika kita melihat halamannya, kita dapat melihat bahwa setiap entri dibungkus dengan sebuah kartu (div) dengan BasePropertyCard_propertyCardWrap__ Kelas.
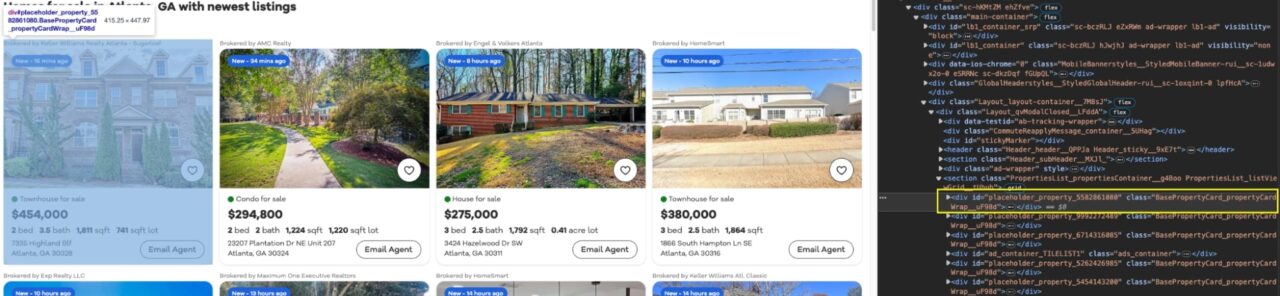
Dengan kelas ini kita sekarang dapat menyimpan semua properti listings menjadi variabel koleksi.
# Parse the HTML response using BeautifulSoup
soup = BeautifulSoup(html_response, "lxml")
# scraping individual page
listings = soup.select("div(class^='BasePropertyCard_propertyCardWrap__')")
print("Listings found!")
Kami mencetak pesan sukses ke konsol untuk mendapatkan masukan saat kode kami berjalan.
Langkah 4: Ekstrak data real estat
Untuk setiap listing yang ditemukan, kami mengekstrak data properti seperti harga, alamat, URL, jumlah kamar tidur, kamar mandi, ukuran luas dan ukuran lahan.
Untuk mengekstrak harga setiap penawaran, kami menggunakan pemilih div(class^='card-price'). Pemilih ini menargetkan div Elemen yang kelasnya dimulai card-price. Div ini berisi harga properti.

price = listing.find("div", class_="card-price")
price = price.get_text(strip=True) if price else "nil"
Untuk mengekstrak alamat dari daftar properti kami menggunakan pemilih div(class^='card-address'). Div ini berisi alamat properti.

full_address = listing.find("div", class_="card-address")
full_address = full_address.get_text(strip=True) if full_address else "nil"
address_parts = full_address.split(", ")
address = address_parts(0) if address_parts else "nil"
township = address_parts(1) if len(address_parts) > 1 else "nil"
Untuk mengetahui lebih banyak detail tentang daftar properti, mari kita lihat beberapa di antaranya li Elemen yang berisi penyeleksi PropertyBedMetastyles__StyledPropertyBedMeta-rui__a4nnof-0 Dan PropertySqftMetastyles__StyledPropertySqftMeta-rui__sc-1gdau7i-0.

Jumlah tempat tidur dan kamar mandi serta luas setiap properti yang terdaftar dapat ditemukan di pemilih CSS ini.
for listing in listings:
price = listing.find("div", class_="card-price")
price = price.get_text(strip=True) if price else "nil"
full_address = listing.find("div", class_="card-address")
full_address = full_address.get_text(strip=True) if full_address else "nil"
address_parts = full_address.split(", ")
address = address_parts(0) if address_parts else "nil"
township = address_parts(1) if len(address_parts) > 1 else "nil"
property_url_elements = listing.select("a(class^='LinkComponent_anchor__')")
property_url = "nil" # Default value if property_url_elements is empty
for element in property_url_elements:
property_url = "https://www.realtor.com" + element("href")
break
beds = listing.find(
"li",
class_="PropertyBedMetastyles__StyledPropertyBedMeta-rui__a4nnof-0",
)
beds = (
beds.find("span", {"data-testid": "meta-value"}).text.strip()
if beds
else "nil"
)
baths = listing.find(
"li",
class_="PropertyBathMetastyles__StyledPropertyBathMeta-rui__sc-67m6bo-0",
)
baths = baths.find("span").text.strip() if baths else "nil"
sqft = listing.find(
"li",
class_="PropertySqftMetastyles__StyledPropertySqftMeta-rui__sc-1gdau7i-0",
)
sqft = (
sqft.find("span", {"data-testid": "screen-reader-value"}).text.strip()
if sqft
else "nil"
)
plot_size = listing.find(
"li",
class_="PropertyLotSizeMetastyles__StyledPropertyLotSizeMeta-rui__sc-1cz4zco-0",
)
plot_size = (
plot_size.find(
"span", {"data-testid": "screen-reader-value"}
).text.strip()
if plot_size
else "nil"
)
property_data = {
"price": price,
"address": address,
"township": township,
"url": property_url,
"beds": beds,
"baths": baths,
"square_footage": sqft,
"plot_size": plot_size,
}
output_data.append(property_data)
Data ini disimpan dan ditambahkan ke kamus output_data Daftar. Setiap bagian data diekstraksi menggunakan .find() metode dan pemilih CSS yang sesuai.
Langkah 5: Ekstrak data dari beberapa halaman
Kami menyebutnya demikian scrape_listing() Berfungsi untuk mengikis data dari jumlah halaman yang diinginkan. Jangan ragu untuk mengubahnya num_pages Variabel untuk mengekstrak data dari beberapa halaman jika perlu.
num_pages = 5 # Set the desired number of pages
# Scrape data from multiple pages
scrape_listing(num_pages)