
Pelajari cara menggunakan Google Berita dan Python untuk berbagai aplikasi tingkat lanjut dengan panduan komprehensif kami. Baik untuk riset pasar, analisis sentimen, atau manajemen krisis, teknik yang mudah diterapkan ini dapat membantu Anda mengubah pendekatan pengumpulan berita.
Kami memberikan petunjuk mendetail tentang cara menggunakan Google SERP API dan pustaka web scraping seperti Beautiful Soup dan Selenium untuk pengumpulan informasi otomatis. Metode ini memungkinkan Anda menjelajahi kasus penggunaan lebih lanjut yang melampaui berita utama saat ini. Temukan cara yang lebih mudah untuk berinteraksi dengan pesan hari ini!
Daftar Isi
Pengikisan Google Berita dengan API
Ada dua cara untuk mengekstrak berita dari hasil penelusuran Google: menggunakan pustaka web scraping Python atau menggunakan Google News API. Opsi API adalah pilihan yang baik untuk pemula dan siapa saja yang ingin menghindari kerumitan pemblokiran, captcha, dan rotasi proxy.
Google News API memberi Anda data dalam format JSON yang mudah diproses dan diedit. Mari kita lihat cara mencari judul dan deskripsi Google Berita menggunakan API Google Berita, apa yang perlu Anda lakukan, dan cara menyimpan data yang diperoleh di Excel.
Daftar dan dapatkan kunci API
Untuk menggunakan API, Anda memerlukan kunci API. Untuk mendapatkannya, buka situs web Scrape-It.Cloud dan login.
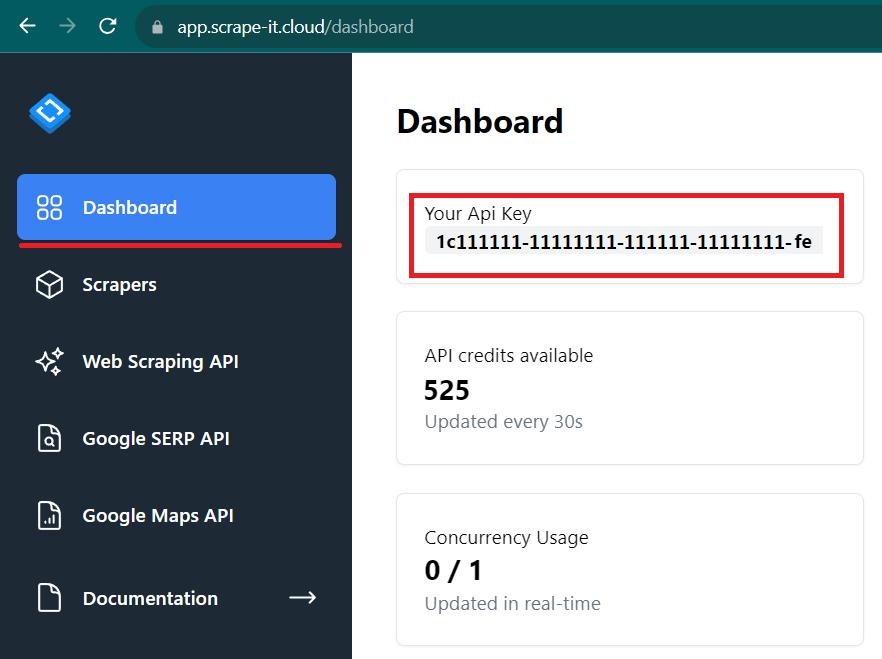
Buka tab Dasbor di akun Anda dan salin kunci API pribadi Anda. Kita akan membutuhkannya nanti.
Tetapkan parameternya
Pertama, mari kita instal perpustakaan yang diperlukan. Untuk melakukannya, ketikkan perintah berikut pada prompt perintah:
pip install requests
pip install pandasPustaka Permintaan adalah pustaka permintaan yang memungkinkan kita meminta API untuk mendapatkan data yang diperlukan. Dan untuk mengolah data kemudian menyimpannya sebagai file Excel, diperlukan perpustakaan Pandas.
Sekarang perpustakaan sudah terinstal, buat file dengan ekstensi *.py dan impor.
import requests
import pandas as pdSekarang mari kita atur parameter yang bisa dimasukkan ke dalam variabel. Hanya ada dua di antaranya: referensi ke titik akhir API dan kata kunci.
keyword = 'new york good news'
api_url="https://api.scrape-it.cloud/scrape/google"Hal terakhir yang perlu Anda lakukan adalah mengatur header dan isi permintaan. Header hanya berisi satu parameter - kunci API. Namun, isi permintaan dapat berisi banyak parameter, termasuk parameter pelokalan. Daftar lengkap parameter dapat ditemukan di dokumentasi kami.
Dalam contoh ini kami hanya menggunakan parameter yang diperlukan:
headers = {'x-api-key': 'YOUR-API-KEY'}
params = {
'q': keyword,
'domain': 'google.com',
'tbm': 'nws'
}Kami telah menentukan kata kunci, domain dan jenisnya. Parameter lainnya tidak dapat ditentukan, namun dapat digunakan untuk menyempurnakan kueri dan memperoleh hasil yang lebih spesifik.
Buat sebuah permintaan
Sekarang semua parameter yang diperlukan telah ditentukan, jalankan permintaan:
response = requests.get(api_url, params=params, headers=headers)API Google Berita Scrape-It.Cloud menggunakan permintaan GET dan memberikan respons JSON dalam format berikut:
{
"requestMetadata": {
"id": "57239e2b-02a2-4bfb-878d-9c36f5c21798",
"googleUrl": "https://www.google.com/search?q=Coffee&uule=w+CAIQICIaQXVzdGluLFRleGFzLFVuaXRlZCBTdGF0ZXM%3D&gl=us&hl=en&filter=1&tbm=nws&oq=Coffee&sourceid=chrome&num=10&ie=UTF-8",
"googleHtmlFile": "https://storage.googleapis.com/scrapeit-cloud-screenshots/57239e2b-02a2-4bfb-878d-9c36f5c21798.html",
"status": "ok"
},
"pagination": {
"next": "https://www.google.com/search?q=Coffee&gl=us&hl=en&tbm=nws&ei=sim9ZPe7Noit5NoP3_efgAU&start=10&sa=N&ved=2ahUKEwj33Jes9qSAAxWIFlkFHd_7B1AQ8NMDegQIAhAW",
"current": 1,
"pages": (
{
"2": "https://www.google.com/search?q=Coffee&gl=us&hl=en&tbm=nws&ei=sim9ZPe7Noit5NoP3_efgAU&start=10&sa=N&ved=2ahUKEwj33Jes9qSAAxWIFlkFHd_7B1AQ8tMDegQIAhAE"
},
// ... More pages ...
)
},
"searchInformation": {
"totalResults": "37600000",
"timeTaken": 0.47
},
"newsResults": (
{
"position": 1,
"title": "De'Longhi's TrueBrew Coffee Maker Boasts Simplicity, but the Joe Is Just So-So",
"link": "https://www.wired.com/review/delonghi-truebrew-drip-coffee-maker/",
"source": "WIRED",
"snippet": "The expensive coffee maker with Brad Pitt as its spokesmodel is better than a capsule-based machine but not as good as competing single-cup...",
"date": "1 day ago"
},
// ... More news results ...
)
}Anda dapat melihat data yang diterima di layar atau terus mengerjakannya.
Analisis datanya
Untuk mengolah data lebih lanjut, kita perlu menganalisisnya. Untuk tujuan ini, kami secara eksplisit menyatakan bahwa data akan disimpan dalam format JSON:
data = response.json()Sekarang kita dapat menggunakan nama atribut untuk mengambil data tertentu:
news = data('newsResults')Oleh karena itu, kami memasukkan semua pesan ke dalam variabel pesan.
Simpan data yang dikumpulkan
Kami menggunakan Pandas untuk menyimpan data yang diperoleh sebagai file Excel. Dengan menggunakan pustaka ini, kita dapat membuat bingkai data atau kumpulan data terorganisir sebagai tabel dari respons JSON.
df = pd.DataFrame(news)Judulnya identik dengan nama atribut. Sekarang kita cukup menyimpan bingkai data ke file:
df.to_excel("news_result.xlsx", index=False)Hasilnya adalah tabel seperti ini:

Untuk membuat kode lebih dapat diandalkan, kami menambahkan blok try..exclusive dan memeriksa apakah ada respons yang berhasil. Kode yang dihasilkan:
import requests
import pandas as pd
keyword = 'new york good news'
api_url="https://api.scrape-it.cloud/scrape/google"
headers = {'x-api-key': 'YOUR-API-KEY'}
params = {
'q': keyword,
'domain': 'google.com',
'tbm': 'nws'
}
try:
response = requests.get(api_url, params=params, headers=headers)
if response.status_code == 200:
data = response.json()
news = data('newsResults')
df = pd.DataFrame(news)
df.to_excel("news_result.xlsx", index=False)
except Exception as e:
print('Error:', e)Jadi kami mendapatkan datanya tanpa harus memproses halaman HTML, menggunakan proxy, atau mencari cara untuk melewati pemblokiran dan captcha.
Kikis hasil Google Berita dengan Selenium
Cara mengikis Google Berita berikutnya adalah dengan menggunakan perpustakaan Python. Dalam hal ini, ada baiknya menggunakan browser tanpa kepala untuk meniru perilaku pengguna sebenarnya dan dengan demikian mengurangi risiko pemblokiran.
Kami akan menggunakan Selenium untuk membuat Google News Scraper karena ia bekerja dengan bahasa pemrograman yang berbeda dan mendukung banyak driver web. Dalam tutorial ini kita akan menggunakan driver web Chrome.
Instal perpustakaan dan unduh webdriver
Untuk menginstal Selenium, ketikkan perintah berikut pada prompt perintah:
pip install seleniumLalu buka situs web Chrome Web Drivers dan unduh versi yang Anda butuhkan (harus sesuai dengan versi Google Chrome yang Anda instal).
Teliti struktur halaman Google Berita
Sebelum menulis kode, lihat halaman Google News dan teliti bagian-bagian yang akan kita gores. Hal pertama yang harus Anda lakukan adalah memeriksa link ke halaman Google News. Mari kita pergi ke sana dan melihat seperti apa bentuknya.
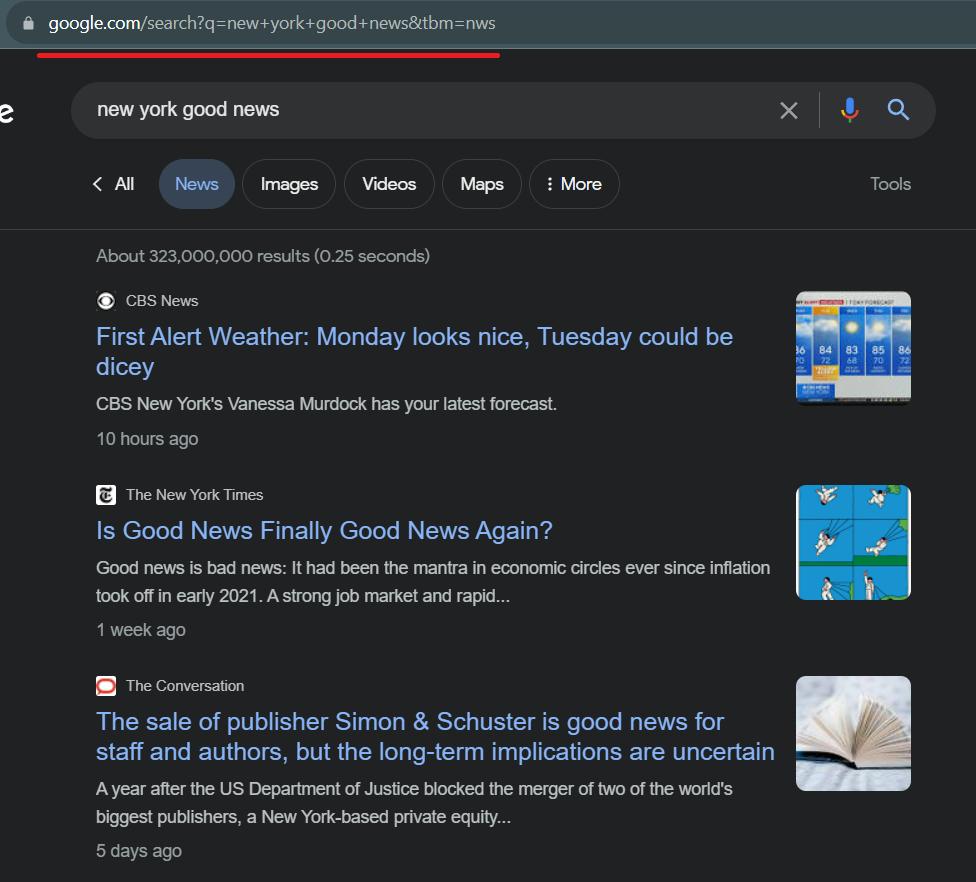
Seperti yang bisa kita lihat, kita dapat dengan mudah membuat link scraping dengan mengganti “kabar baik new york” dengan permintaan pencarian lainnya.
Sekarang mari kita pergi ke alat pengembang (F12 atau klik kanan pada layar dan "Periksa") dan lihat lebih dekat salah satu hasilnya.

Semua pesan memiliki tag div dengan id=“rso”. Kita dapat menggunakan ini dan struktur halaman HTML untuk mendapatkan data yang kita butuhkan. Untuk mengambil elemennya sendiri, kita bisa menggunakan selector “div#rso > div > div > div > div > div > div” yang mengambil data dalam tag div.
Dalam situasi lain, kita akan mengambil data dari elemen menggunakan kelas. Ini bisa menjadi kelas “SoaBEf”, yang umum untuk semua elemen. Namun, nama kelas di Google Berita sering berubah dan tidak konstan. Oleh karena itu, mari kita andalkan struktur dan elemen yang tidak akan berubah.
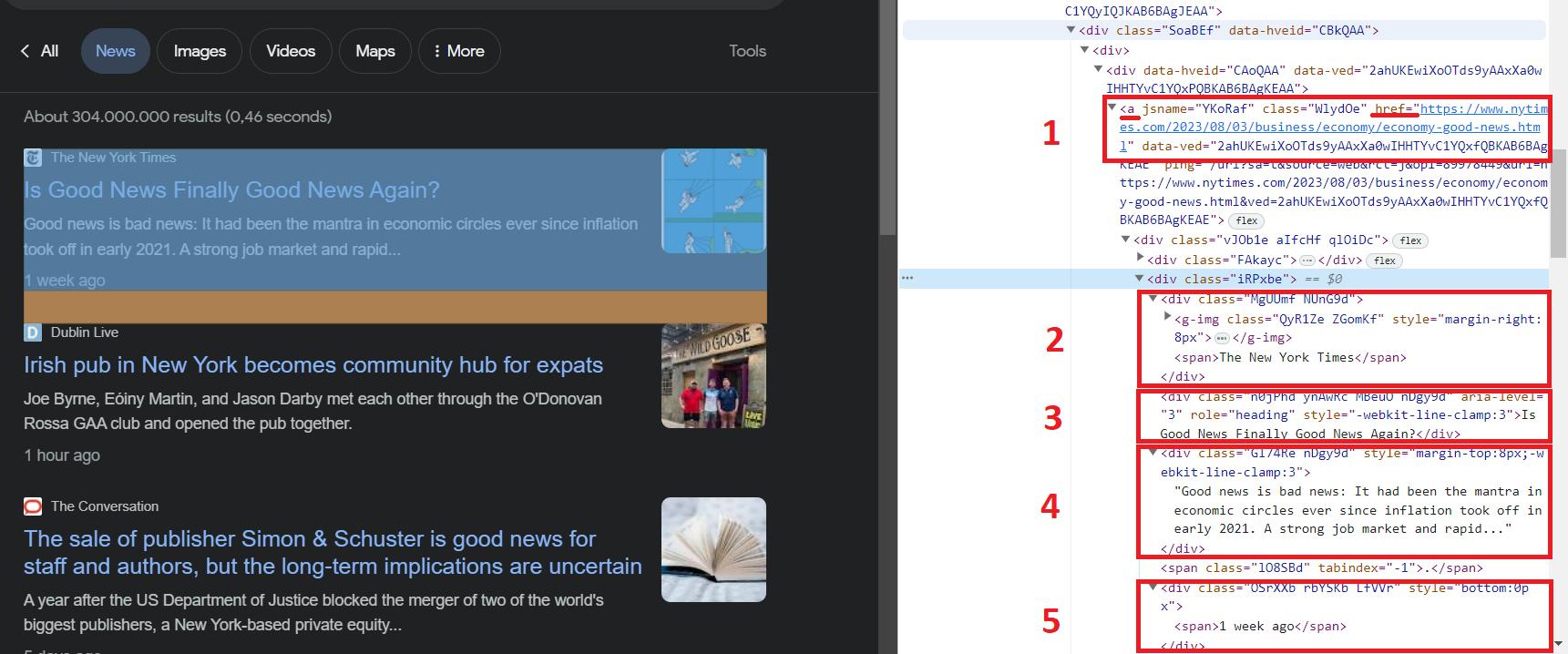
Di sini, seperti yang bisa kita lihat, kita bisa mendapatkan data berikut:
- Tautan ke berita.
- Nama sumber tempat berita akan dipublikasikan.
- Judul beritanya.
- Deskripsi berita.
- Sudah berapa lama sejak berita itu diterbitkan?
Sekarang kita tahu data apa yang kita butuhkan, kita bisa melanjutkan ke scraping.
Impor perpustakaan dan atur parameter
Buat file baru dengan ekstensi *.py dan rusak modul perpustakaan Selenium yang diperlukan:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import ServiceSekarang mari kita atur jalur ke file driver web yang diunduh sebelumnya dan tautan ke halaman Google Berita yang akan dikikis.
chromedriver_path="C://chromedriver.exe"
url="https://www.google.com/search?q=new+york+good+news&tbm=nws"Kita juga perlu menentukan parameter driver web yang akan dijalankan.
service = Service(chromedriver_path)
driver = webdriver.Chrome(service=service)Ini menyelesaikan persiapan dan Anda dapat melanjutkan pengumpulan data.
Buka Google Berita dan Gosok Data
Yang perlu kita lakukan hanyalah menjalankan kueri dan mengumpulkan data. Untuk melakukan ini, jalankan webdriver:
driver.get(url)Sekarang, saat Anda menjalankan skrip, jendela Google Chrome akan terbuka yang menavigasi ke permintaan pencarian.
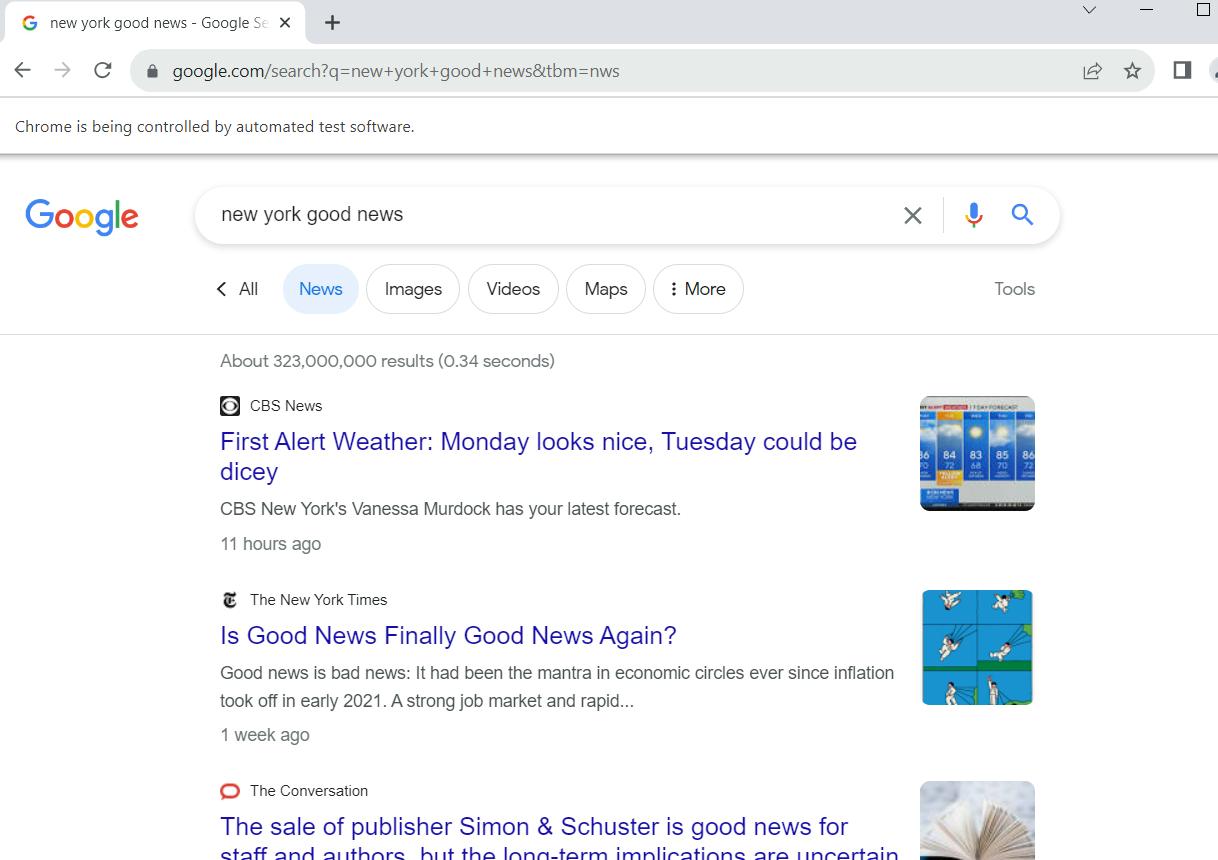
Sekarang mari kita menganalisis konten halaman yang kita buka. Untuk tujuan ini, kami sebelumnya memeriksa situs web dan memeriksa strukturnya. Sekarang kami menggunakannya dan mendapatkan semua berita di situs:
news_results = driver.find_elements(By.CSS_SELECTOR, 'div#rso > div > div > div > div')Kemudian kita menangani setiap elemen satu per satu:
for news_div in news_results:Pertama, mari kumpulkan tautannya dan tampilkan di layar:
news_link = news_div.find_element(By.TAG_NAME, 'a').get_attribute('href')
print("Link:", news_link)Lalu kita mendapatkan elemen yang tersisa:
divs_inside_news = news_div.find_elements(By.CSS_SELECTOR, 'a > div > div > div')
news_item = ()
for new in divs_inside_news:
news_item.append(new.text)Sekarang mari kita tampilkan nilai-nilai ini di layar:
print("Domain:", news_item(1))
print("Title:", news_item(2))
print("Description:", news_item(3))
print("Date:", news_item(4))Buatlah garis pemisah antara pesan-pesan yang berbeda sehingga terlihat jelas secara visual:
print("-"*50+"\n\n"+"-"*50)Dan terakhir tutup web drivernya.
driver.quit()Nah jika kita menjalankan script ini kita akan mendapatkan data berupa:
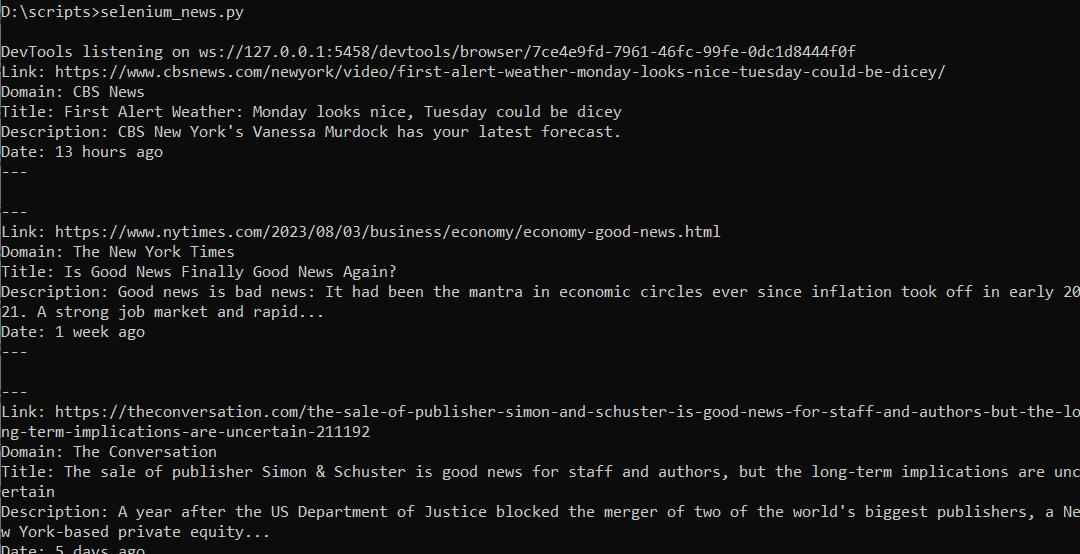
Kode lengkap:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
chromedriver_path="C://chromedriver.exe"
service = Service(chromedriver_path)
driver = webdriver.Chrome(service=service)
url="https://www.google.com/search?q=new+york+good+news&tbm=nws"
driver.get(url)
news_results = driver.find_elements(By.CSS_SELECTOR, 'div#rso > div >div>div>div')
for news_div in news_results:
news_item = ()
try:
news_link = news_div.find_element(By.TAG_NAME, 'a').get_attribute('href')
print("Link:", news_link)
divs_inside_news = news_div.find_elements(By.CSS_SELECTOR, 'a>div>div>div')
for new in divs_inside_news:
news_item.append(new.text)
print("Domain:", news_item(1))
print("Title:", news_item(2))
print("Description:", news_item(3))
print("Date:", news_item(4))
print("-"*50+"\n\n"+"-"*50)
except Exception as e:
print("No Elems")
driver.quit()Jika Anda ingin menyimpan data dalam format Excel, Anda dapat memasukkannya baris demi baris atau, seperti pada opsi sebelumnya, membuat bingkai data dan menyimpan semuanya sekaligus.
Kesimpulan dan temuan
Artikel ini membahas dua cara untuk melakukan scraping data Google Berita dengan Python: menggunakan Google News API dan menerapkan metode web scraping menggunakan perpustakaan Selenium. Google News API menawarkan pendekatan sederhana, menyediakan data dalam format JSON yang dapat diproses dan dianalisis dengan cepat. Dengan mendapatkan kunci API dan mengatur parameternya, Anda dapat dengan cepat memperoleh informasi pesan sesuai kebutuhan Anda.
Bagi yang membutuhkan kontrol dan fleksibilitas lebih, web scraping dengan Selenium bisa menjadi alternatif. Dengan meniru perilaku dan interaksi pengguna dengan halaman web, Selenium memungkinkan Anda mengekstrak elemen data tertentu. Metode ini cocok ketika diperlukan interaksi yang lebih kompleks dengan halaman web, seperti mengisi kolom.
Artikel ini menjelaskan proses langkah demi langkah untuk kedua metode dan memberikan contoh kode yang menunjukkan cara menggunakan setiap metode untuk mengambil data Google Berita. Dengan mengikuti petunjuk dan cuplikan kode, Anda akan mendapatkan gambaran yang jelas tentang cara mengumpulkan data berita dari Google Berita untuk pembelajaran mesin atau kebutuhan analisis dan penelitian Anda.