
Format yang tidak konvensional – PDF, XML atau JSON – sama pentingnya dengan sumber data seperti halaman web.
Grepsr telah menjadi pemain utama dalam permainan web scraping selama lebih dari satu dekade. Sebagai platform DaaS, kami mengekstrak data dari sumber sederhana dan kompleks dengan tetap menjaga standar kualitas tertinggi setiap saat.
Untuk proyek ekstraksi data yang kami terima, situs web adalah sumber data yang paling umum. Namun, terkadang kami juga menerima permintaan dari beberapa pelanggan yang menginginkan datanya dari sumber offline dan tidak konvensional seperti file PDF, XML, dan JSON.
Di sini kita melihat cara kami mengumpulkan data dari sumber dan format data non-tradisional ini.
Daftar Isi
file PDF
PDF adalah singkatan dari Portable Document Format. Awalnya dikembangkan oleh Adobe, ini adalah salah satu alternatif digital paling populer untuk dokumen bersampul tipis.
File PDF adalah salah satu media yang paling umum digunakan dalam bisnis untuk menyimpan dokumen dan mengkomunikasikan informasi. Kompatibilitasnya dengan beberapa perangkat tidak hanya memudahkan portabilitas dokumen – seperti namanya – tetapi juga mudah dilihat dan disimpan. Baik itu teks, grafik, atau konten pindaian, Anda dapat menyimpan semua informasi di satu tempat agar mudah dilihat dan dibaca dengan dokumen PDF.
Manfaat menggunakan format file PDF
File PDF sangat berguna dan efisien serta menawarkan banyak manfaat termasuk:
- Kemudahan penggunaan dan integritas di beberapa perangkat
- Mudah dibaca dan format praktis
- Kemampuan untuk menangkap berbagai konten - termasuk teks, gambar, dan bahkan dokumen bersampul tipis yang dipindai
- Tata letak terlindungi yang dapat mempertahankan tanda air, tanda tangan, dan konten penting lainnya
Pengambilan data dari file PDF
Tidak seperti bentuk dokumentasi lain seperti file Word dan Excel, file PDF tidak mudah diedit, sehingga memerlukan upaya tambahan selama ekstraksi data. Karena tujuan awal file PDF adalah memiliki tata letak yang terlindungi, mengekstraksi data darinya cukup sulit. Jika tidak dilakukan dengan benar, hal ini dapat menghasilkan data yang sangat tidak terstruktur, sehingga membatasi tujuan akhir ekstraksi data – analisis yang efektif. Lagi pula, Anda tidak ingin berakhir dengan data yang tidak jelas, tidak lengkap, dan tidak koheren yang justru menggagalkan tujuan bermain-main dengan data berkualitas tinggi.
Beginilah cara Grepsr menangani ekstraksi data PDF
- Saat kami menerima permintaan pengikisan PDF, pertama-tama kami menganalisis format dokumen dan tingkat kerumitan ekstraksi data.
- Kami mengekspor file sebagai format ramah teks, seperti dokumen Word.
- Saat diekspor, dokumen menyisipkan jeda baris di akhir setiap baris. Meskipun baris-baris baru ini tidak terlihat secara visual, namun menambah kesulitan bagi pengikis untuk mengurai dokumen.
Untuk mengatasi hal ini, kami mengidentifikasi dan menghapus setiap baris baru menggunakan ekspresi reguler (RegEx) dan membiarkan hentian paragraf dan bagian tidak berubah.
- Saat diekspor, dokumen menyisipkan jeda baris di akhir setiap baris. Meskipun baris-baris baru ini tidak terlihat secara visual, namun menambah kesulitan bagi pengikis untuk mengurai dokumen.
- Bergantung pada strukturnya, kami kemudian mengekstrak bidang data yang diinginkan.
- Beberapa tata letak dokumen (misalnya kolom) menimbulkan tantangan tambahan. Jika data yang kita butuhkan ada di salah satu baris di kolom pertama, bagian dari baris yang sama juga diambil di kolom lain dengan banyak spasi di antaranya (seperti dengan tabulator – 4-5 karakter).
Dalam kasus seperti itu, kami membagi string yang dikumpulkan menggunakan spasi sebagai pembatas dan mengumpulkan data yang dihasilkan sebagai array. Kemudian setiap string dipetakan ke bidang induknya berdasarkan indeks array. - Jika PDF berisi daftar panjang informasi tentang produk, scraper yang lebih kompleks dan kuat juga diperlukan untuk mengekstraknya. Hal ini akan membutuhkan lebih banyak sumber daya dalam hal RAM dan penyimpanan untuk memenuhi kebutuhan penyimpanan tambahan.
- Beberapa tata letak dokumen (misalnya kolom) menimbulkan tantangan tambahan. Jika data yang kita butuhkan ada di salah satu baris di kolom pertama, bagian dari baris yang sama juga diambil di kolom lain dengan banyak spasi di antaranya (seperti dengan tabulator – 4-5 karakter).
Analisis data dari sumber XML
XML adalah singkatan dari eXtensible Markup Language. Ini mendefinisikan seperangkat aturan yang membuat dokumen dapat dibaca oleh manusia dan mesin.
Dalam file XML, data disimpan sebagai pohon elemen, dengan a akar (atau induk) Elemen untuk dicabangkan anak Barang seperti terlihat pada gambar di bawah ini. Item-item ini kemudian diekstraksi berdasarkan kebutuhan.
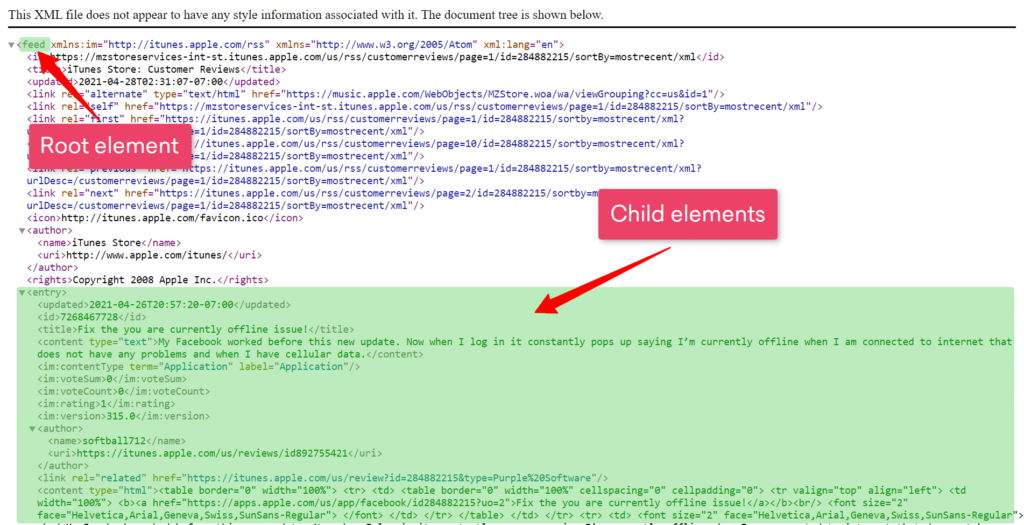
Selain itu, dalam beberapa kasus penggunaan kami, file XML berisi peta situs untuk situs web yang menyediakan tautan ke cantumannya, seperti: B. produk termasuk. Setelah kami mencantumkan URL produk, proses ekstraksi selanjutnya serupa dengan pengumpulan data web lainnya.
Namun, hal ini tidak selalu mudah. Kategori dan subkategori terkadang memiliki struktur yang buruk di beberapa peta situs. Hal ini menambah lapisan kompleksitas tambahan pada sumber ekstraksi data yang sudah sulit.
Mengurai data dari format JSON
JSON – Notasi Objek JavaScript – adalah format ringan untuk menyimpan dan mengangkut data. Ini sering digunakan saat mengirim data dari server ke halaman web.
Karena file JSON berisi data berupa pasangan nama-nilai, informasi tersebut tidak hanya dapat dengan mudah dibaca dan ditulis oleh manusia, tetapi juga diurai dan dihasilkan oleh mesin. Sebagai format teks yang sepenuhnya tidak bergantung pada bahasa, JSON adalah format pertukaran data yang ideal.

Seperti file XML, data di JSON disusun menjadi induk dan turunan, sehingga memudahkan pengumpulan data. Di sebagian besar situs web, detail yang terlihat di layar biasanya disematkan sebagai JSON di file JavaScript laman web. Dengan menganalisis kode sumber situs web, dimungkinkan untuk menentukan sumber daya JSON, mengekstrak data yang diperlukan, dan menyusun serta mengaturnya ke dalam bidang data masing-masing sesuai kebutuhan.
Baca juga:
Karena semakin banyak perusahaan memilih metode berbeda untuk menyimpan informasi mereka, kami tidak ingin perusahaan kehilangan tujuannya hanya karena data yang mereka cari disimpan dalam format yang tidak konvensional. Tidak seorang pun boleh kehilangan pendapatan karena mereka tidak dapat mengekstrak data dalam format yang terstruktur dan dapat diedit.
Dengan platform pramutamu Grepsr, Anda cukup memberi tahu kami kebutuhan Anda dan kami akan mengekstrak data yang Anda butuhkan dari sumber tradisional dan non-tradisional. Kunjungi situs web kami untuk informasi lebih lanjut dan hubungi kami dengan kebutuhan proyek Anda. Kemudian duduk dan bersantai saat kami mengotomatiskan seluruh proses ekstraksi data untuk Anda.