
Ein unkonventionelles Format – PDF, XML oder JSON – ist eine ebenso wichtige Datenquelle wie eine Webseite.
Grepsr ist seit mehr als zehn Jahren einer der Hauptakteure im Web-Scraping-Spiel. Als DaaS-Plattform extrahieren wir Daten sowohl aus einfachen als auch komplexen Quellen und wahren dabei höchste Qualitätsstandards jedes Mal.
Für die Datenextraktionsprojekte, die wir erhalten, sind Webseiten die häufigsten Datenquellen. Gelegentlich erhalten wir jedoch auch Anfragen einiger Kunden, die ihre Daten aus Offline- und unkonventionellen Quellen wie PDF-Dateien, XML und JSON wünschen.
Hier werfen wir einen Blick darauf, wie wir Daten aus diesen nicht-traditionellen Datenquellen und -formaten sammeln.
PDF-Dateien
PDF steht für Portable Document Format. Sie wurden ursprünglich von Adobe entwickelt und sind eine der beliebtesten digitalen Alternativen zu Taschenbuchdokumenten.
PDF-Dateien sind in Unternehmen eines der am häufigsten verwendeten Medien zum Speichern von Dokumenten und zum Kommunizieren von Informationen. Ihre Kompatibilität mit mehreren Geräten ermöglicht nicht nur eine einfache Portabilität von Dokumenten – wie der Name schon sagt –, sondern auch eine einfache Anzeige und Speicherung. Unabhängig davon, ob es sich um Text-, Grafik- oder gescannte Inhalte handelt, können Sie alle Informationen an einem einzigen Ort speichern, um sie mit PDF-Dokumenten einfach anzuzeigen und zu lesen.
Vorteile der Verwendung eines PDF-Dateiformats
PDF-Dateien sind äußerst nützlich und effizient und bieten zahlreiche Vorteile, darunter:
- Benutzerfreundlichkeit und Integrität auf mehreren Geräten
- Einfache Lesbarkeit und praktisches Format
- Möglichkeit, eine Vielzahl von Inhalten aufzunehmen – einschließlich Text, Bildern und sogar gescannten Taschenbuchdokumenten
- Geschütztes Layout, das Wasserzeichen, Signaturen und andere wichtige Inhalte bewahren kann
Datenerfassung aus PDF-Dateien
Im Gegensatz zu anderen Dokumentationsformen wie Word- und Excel-Dateien lassen sich PDF-Dateien nicht einfach bearbeiten, was zu zusätzlichem Aufwand bei der Datenextraktion führt. Da das ursprüngliche Ziel einer PDF-Datei darin besteht, ein geschütztes Layout zu haben, ist das Extrahieren von Daten daraus recht schwierig. Wenn dies nicht ordnungsgemäß durchgeführt wird, kann dies zu extrem unstrukturierten Daten führen, was das eigentliche Ziel der Datenextraktion – eine effektive Analyse – einschränkt. Schließlich möchten Sie nicht mit unklaren, unvollständigen und inkohärenten Daten enden, die nur den Zweck zunichte machen, mit qualitativ hochwertigen Daten zu spielen.
So handhabt Grepsr die PDF-Datenextraktion
- Wenn wir eine PDF-Scraping-Anfrage erhalten, analysieren wir zunächst die Formatierung des Dokuments und den Komplexitätsgrad für die Datenextraktion.
- Wir exportieren die Datei als textfreundliches Format, wie ein Word-Dokument.
- Beim Export fügt das Dokument am Ende jeder Zeile einen Zeilenumbruch ein. Obwohl diese neuen Zeilen optisch nicht erkennbar sind, erhöhen sie den Schwierigkeitsgrad für den Scraper beim Parsen des Dokuments.
Um dem entgegenzuwirken, identifizieren und entfernen wir jede neue Zeile mithilfe regulärer Ausdrücke (RegEx) und lassen die Absatz- und Abschnittsumbrüche unverändert.
- Beim Export fügt das Dokument am Ende jeder Zeile einen Zeilenumbruch ein. Obwohl diese neuen Zeilen optisch nicht erkennbar sind, erhöhen sie den Schwierigkeitsgrad für den Scraper beim Parsen des Dokuments.
- Je nach Struktur extrahieren wir dann die gewünschten Datenfelder.
- Einige Dokumentlayouts (z. B. Spalten) stellen eine zusätzliche Herausforderung dar. Wenn sich die von uns benötigten Daten in einer der Zeilen in der ersten Spalte befinden, werden auch Teile derselben Zeile in den anderen Spalten mit einer Reihe von Leerzeichen dazwischen erfasst (wie bei einem Tabulator – 4–5 Zeichen).
In solchen Fällen teilen wir die gesammelte Zeichenfolge mit dem Leerzeichen als Trennzeichen auf und sammeln die resultierenden Daten als Arrays. Anschließend wird jede einzelne Zeichenfolge basierend auf dem Array-Index ihrem übergeordneten Feld zugeordnet. - Wenn ein PDF eine lange Liste mit Informationen zu Produkten enthält, wären für die Extraktion ebenfalls komplexere und leistungsfähigere Scraper erforderlich. Dies würde mehr Ressourcen in Bezug auf RAM und Speicher erfordern, um den zusätzlichen Speicherbedarf zu decken.
- Einige Dokumentlayouts (z. B. Spalten) stellen eine zusätzliche Herausforderung dar. Wenn sich die von uns benötigten Daten in einer der Zeilen in der ersten Spalte befinden, werden auch Teile derselben Zeile in den anderen Spalten mit einer Reihe von Leerzeichen dazwischen erfasst (wie bei einem Tabulator – 4–5 Zeichen).
Datenanalyse aus XML-Quellen
XML steht für eXtensible Markup Language. Es definiert eine Reihe von Regeln, die ein Dokument sowohl für Menschen als auch für Maschinen lesbar machen.
In XML-Dateien werden Daten als Elementbäume gespeichert, mit a Wurzel (oder Elternteil) Element, in das verzweigt wird Kind Elemente, wie im Bild unten gezeigt. Diese Elemente werden dann basierend auf den Anforderungen extrahiert.
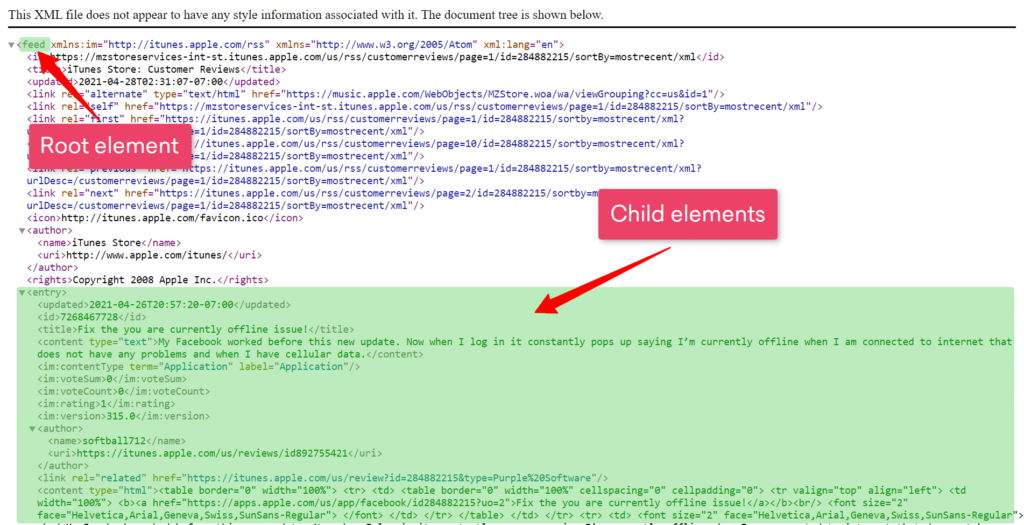
Darüber hinaus enthalten die XML-Dateien in einigen unserer Anwendungsfälle Sitemaps für Websites, die Links zu ihren Einträgen, wie z. B. Produkten, enthalten. Sobald wir die Produkt-URLs aufgelistet haben, ähnelt der anschließende Extraktionsprozess dem Sammeln anderer Webdaten.
Allerdings ist es nicht immer so einfach. Kategorien und Unterkategorien sind in manchen Sitemaps manchmal schlecht strukturiert. Dies fügt einer bereits schwierigen Datenextraktionsquelle eine zusätzliche Komplexitätsebene hinzu.
Analysieren von Daten aus dem JSON-Format
JSON – JavaScript Object Notation – ist ein leichtes Format zum Speichern und Transportieren von Daten. Es wird häufig verwendet, wenn Daten von einem Server an eine Webseite gesendet werden.
Da JSON-Dateien Daten in Form von Name-Wert-Paaren enthalten, können die Informationen nicht nur von Menschen leicht gelesen und geschrieben, sondern auch von Maschinen analysiert und generiert werden. Als völlig sprachunabhängiges Textformat ist JSON das ideale Datenaustauschformat.

Wie XML-Dateien sind Daten in JSON in übergeordnete und untergeordnete Elemente strukturiert, was die Datenerfassung erleichtert. Auf den meisten Websites werden auf dem Bildschirm sichtbare Details meist als JSON in die JavaScript-Datei der Webseite eingebettet. Durch die Analyse des Quellcodes der Website ist es möglich, die JSON-Ressource zu bestimmen, die erforderlichen Daten zu extrahieren und sie nach Bedarf in ihren jeweiligen Datenfeldern zu strukturieren und zu organisieren.
Lesen Sie auch:
Da sich immer mehr Unternehmen für unterschiedliche Methoden zur Speicherung ihrer Informationen entscheiden, möchten wir nicht, dass ein Unternehmen seine Ziele verpasst, nur weil die gesuchten Daten in einem unkonventionellen Format gespeichert sind. Niemand sollte Einnahmen verlieren, weil er die Daten nicht in einem strukturierten und bearbeitbaren Format extrahieren kann.
Mit der Concierge-Plattform von Grepsr können Sie uns einfach Ihre Anforderungen mitteilen und wir extrahieren die von Ihnen benötigten Daten sowohl aus traditionellen als auch nicht-traditionellen Quellen. Besuchen Sie unsere Website für weitere Informationen und kontaktieren Sie uns mit Ihren Projektanforderungen. Dann lehnen Sie sich zurück und entspannen Sie sich, während wir den gesamten Datenextraktionsprozess für Sie automatisieren.
