
Pengikisan web adalah salah satu metode pengumpulan data yang paling populer. Ini merupakan pengganti yang sangat baik untuk pengumpulan data manual karena menghilangkan kemungkinan kesalahan, mengurangi waktu dan menyediakan data dalam jumlah besar dengan cepat.
Kami telah berbicara banyak tentang cara mengumpulkan data dari toko online untuk melacak pesaing dan cara mengevaluasi layanan Google seperti Maps dan SERP (halaman hasil mesin pencari). Hari ini kita akan membahas cara mengumpulkan gambar dengan cepat dan efisien menggunakan web scraping.
Daftar Isi
Manfaat Pengikisan Gambar
Meskipun scraping gambar Google tidak sepopuler layanan Google lainnya, hal ini masih menjadi kebutuhan di beberapa area bisnis. Misalnya, Anda dapat menggunakan gambar bekas untuk meningkatkan kualitas konten visual dan interaksi pengguna. Menemukan gambar yang sedang tren dan relevan juga berguna. Dan tentu saja, ini cara yang bagus untuk mengumpulkan gambar dalam jumlah besar jika Anda ingin membuat galeri gambar berbeda untuk situs web atau bahkan pembelajaran mesin.
Ketika kita berbicara tentang metode pengikisan gambar, kita dapat membaginya menjadi dua bagian: manual dan otomatis. Karena pengikisan manual melibatkan pengunduhan gambar secara manual, yang memerlukan banyak waktu dan tenaga, kami tidak akan mempelajari metode ini secara mendetail.
Sebagai gantinya, mari kita lihat cara mengotomatiskan pengikisan gambar Google.
Membuat scraper web khusus
Anda dapat mencoba membuat pengikis gambar jika Anda memiliki pengetahuan pemrograman dasar. Anda dapat menggunakan hampir semua bahasa pemrograman untuk tujuan ini. Jika Anda ingin mempelajari perpustakaan mana yang harus Anda gunakan dan mendapatkan pengetahuan dasar, Anda dapat membaca artikel kami tentang web scraping dengan Python, NodeJS, PHP, Ruby, R atau C#. Misalnya, Anda dapat dengan mudah mengumpulkan data dengan Python menggunakan Beautiful Soup® UrlLib atau perpustakaan Selenium menggunakan Webdriver. Kami telah menulis tentang cara mengikis hasil pencarian Google menggunakan perpustakaan dan pemilih CSS ini, dan menggores gambar tidak jauh berbeda.
Meskipun hal ini mungkin tampak sulit pada awalnya dan Anda akan menghadapi beberapa tantangan, ada cara untuk mengatasinya. Misalnya, Anda dapat menggunakan API web scraping untuk menyederhanakan proses scraping dan mengurangi risiko pemblokiran.
Penggunaan layanan online
Cara kedua untuk mengotomatiskan proses pengikisan Gambar Google adalah dengan menggunakan layanan pengikisan web khusus untuk mengumpulkan data. Di sini Anda tidak memerlukan pengetahuan pemrograman apa pun, Anda hanya dapat mengumpulkan data yang disediakan layanan. Artinya layanan ini tidak cocok untuk Anda jika Anda tidak memiliki data yang Anda perlukan di antara yang disediakan.
Selain layanan khusus, tersedia juga berbagai plug-in untuk browser. Namun, mereka kurang fleksibel atau memerlukan penyesuaian, yang memerlukan pengetahuan pemrograman.
Dengan pemikiran ini, kami ingin meminimalkan kebutuhan akan pengetahuan pemrograman sambil tetap mempertahankan solusi paling serbaguna dengan beragam fungsi. Oleh karena itu, kami menggunakan Pembuat Permintaan untuk Web Scraping API. Dengan cara ini kami mengonfigurasi semua parameter, termasuk pelokalan, dan menjalankan permintaan di situs.
Dapatkan data gambar dengan Scrape-It.Cloud Request Builder
Kami akan membahas pengikisan gambar dengan Python menggunakan API Scrape-It.Cloud nanti. Namun, kami ingin menunjukkan cara mendapatkan tautan ke gambar tanpa pemrograman. Demi kenyamanan Anda, kami telah membagi proses ini menjadi beberapa langkah.
Langkah 1: Dapatkan kunci API
Masuk ke situs web untuk mendapatkan akses ke Google SERP API dan akun pribadi yang dapat Anda gunakan untuk menjawab pertanyaan. Anda juga mendapatkan kredit gratis sehingga Anda dapat mencoba fungsinya tanpa membayar.
Kunci API terletak di tab Dasbor.
Kita memerlukan kunci API ini dalam contoh berikut.
Langkah 2: Buka tab API SERP Google
Untuk mengumpulkan gambar, klik tab SERP Google di akun Anda.
Alat ini memungkinkan Anda mengumpulkan data dari hasil pencarian, gambar, berita, penduduk lokal, dan pembelian.
Langkah 3: Tambahkan parameter kueri untuk pencarian
Sekarang lihat bidang utama yang dapat Anda siapkan untuk menyesuaikan kueri Anda. Dan hal pertama yang harus dilakukan adalah menentukan letak geografis.
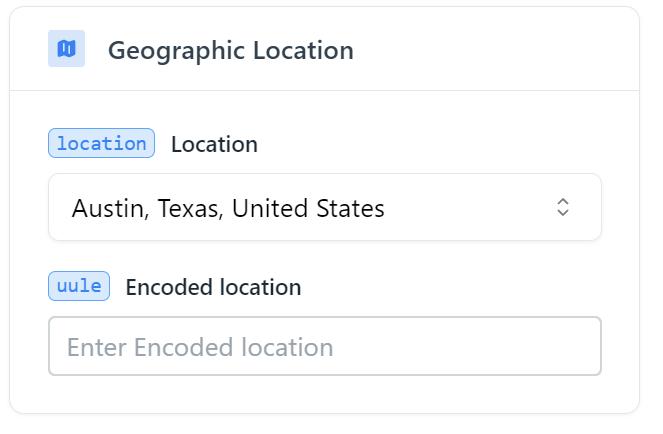
Anda harus memilih kota atau negara tempat Anda ingin mendapatkan hasilnya. Anda juga dapat menentukan kode wilayah sebagai pengganti nama tempat. Tergantung pada pengaturan Anda, hasilnya akan bervariasi.
Kemudian sesuaikan lokalisasinya. Jika Anda puas dengan pengaturan default, Anda tidak perlu mengubah apa pun.
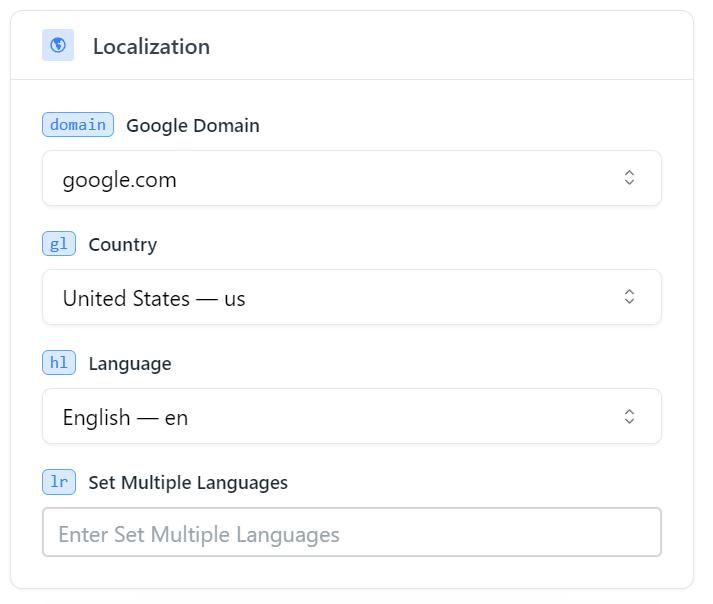
Parameter utama di sini adalah domain, negara, dan bahasa, jadi Anda hanya dapat menentukannya saja. Kemudian muncul blok dengan parameter yang diperluas. Anda dapat membiasakan diri dengannya dan menggunakannya jika perlu, tetapi kami ingin melangkah lebih jauh dan mempertimbangkan parameter penting berikut ini.
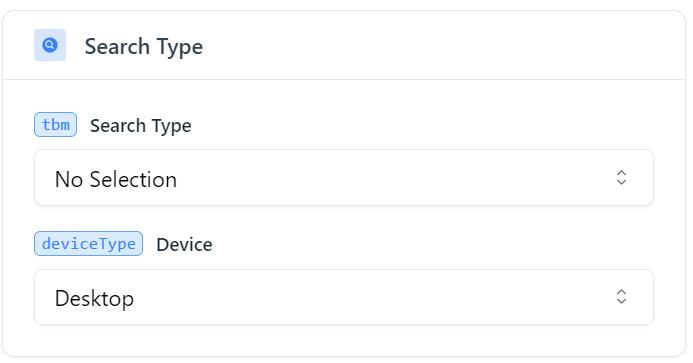
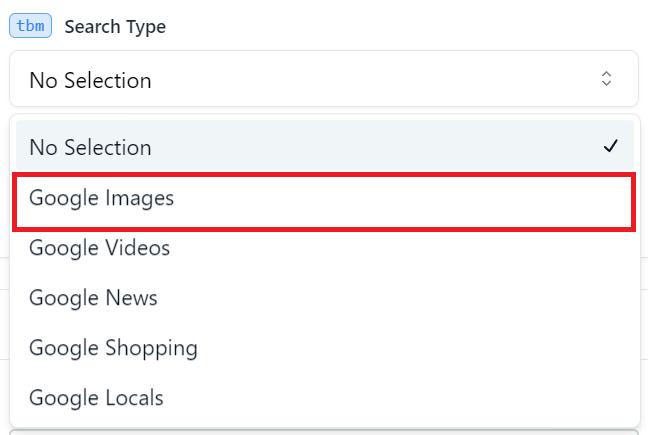
Untuk mencari Gambar Google, Anda harus menentukan jenis pencarian yang sesuai (tbm) sebagai Gambar Google (isch).
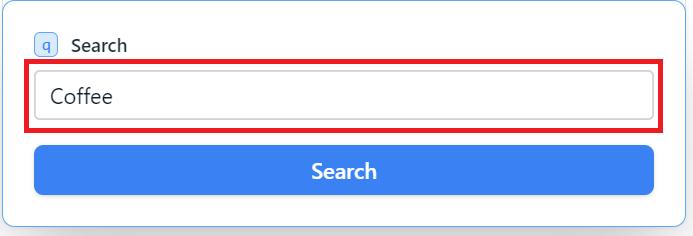
Dan parameter terakhir yang harus ditentukan adalah kata kunci yang ingin Anda dapatkan gambarnya.
Parameter lainnya juga sangat membantu. Namun, tujuannya bersifat intuitif, sehingga Anda dapat membiasakan diri dengannya jika perlu. Misalnya, mereka memungkinkan Anda menentukan jumlah gambar yang ingin Anda terima.
Langkah 4: Kirim permintaan API
Sekarang semua parameter telah ditentukan, jalankan kueri.

Menyelesaikan permintaan seperti itu membutuhkan lima kredit. Saat Anda mendaftar, Anda mendapatkan 1000 kredit gratis, yang setara dengan 200 permintaan tersebut. Dengan menggunakan API kami, Anda dapat menggunakan pengaturan fleksibel untuk menyesuaikan permintaan Anda. Selain itu, proxy digunakan, captcha dihindari, dan rendering JS digunakan untuk mengurangi risiko pemblokiran.
Langkah 5: Simpan URL gambar yang diambil
Hasilnya adalah respon JSON dengan semua konten yang tersedia, termasuk judul dan link gambar. Anda dapat menyalin seluruh respons JSON atau hanya bagian yang diperlukan.
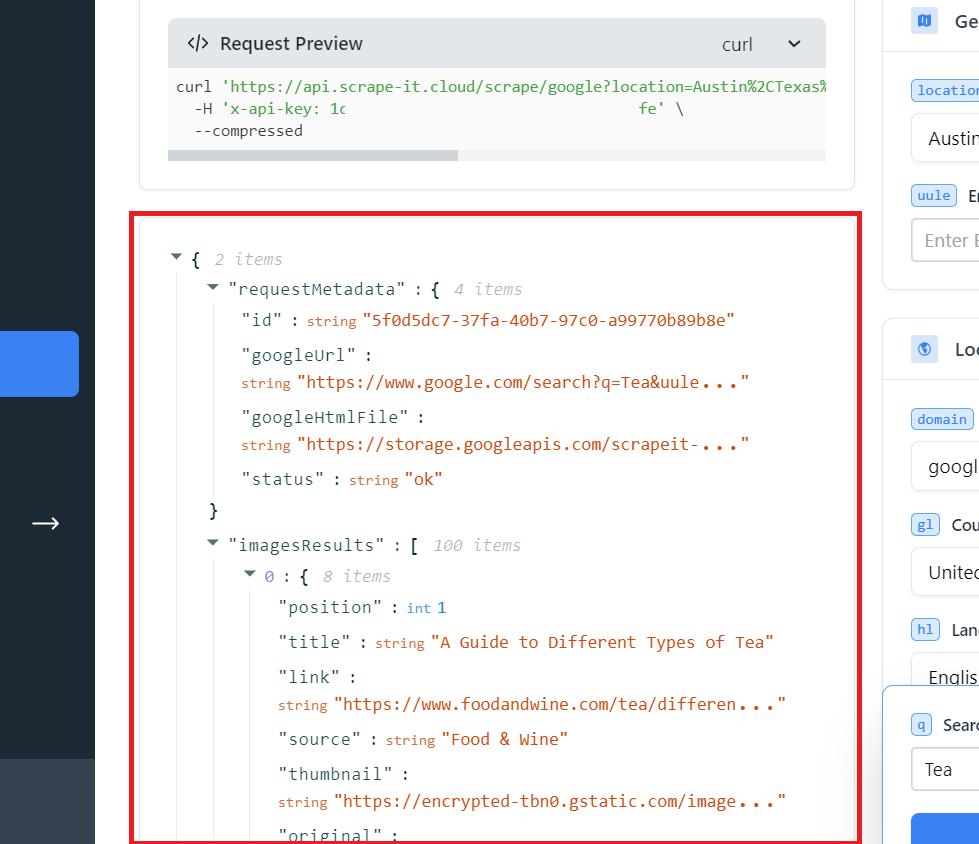
Untuk menyimpan data ini sebagai file Excel, Anda dapat menggunakan impor data bawaan atau mengonversi JSON ke XLSX menggunakan layanan khusus. Hasilnya, Anda akan menerima data dalam bentuk berikut:
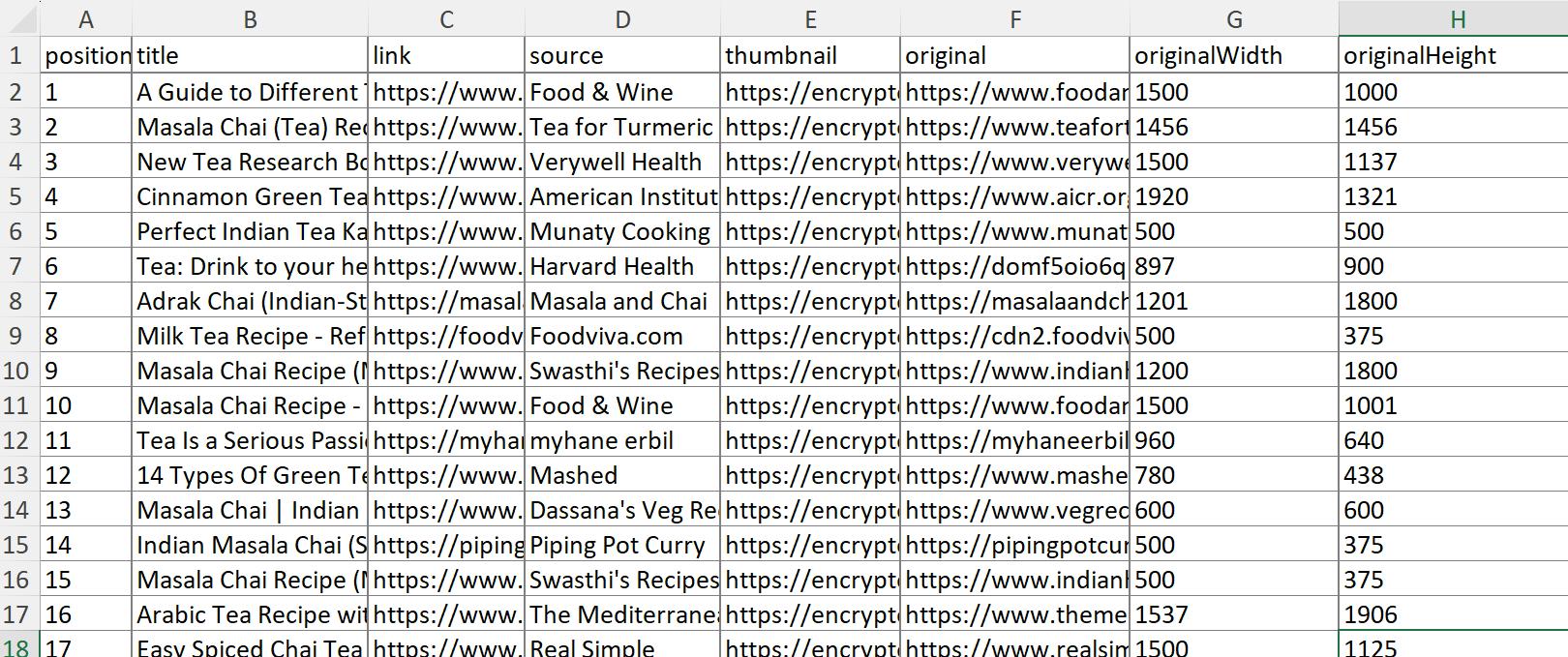
Seperti yang Anda lihat dari tabel, Anda mendapatkan posisi gambar, judul, sumber, thumbnail, tautan, dan bahkan dimensi.
Scraper Gambar Google Sederhana dengan Python dengan API
Mari kita lihat cara mengikis gambar menggunakan Python. Kami akan menggunakan Python 3. Jika Anda tidak tahu cara mempersiapkan lingkungan dan mengonfigurasi semua yang Anda perlukan, Anda dapat membaca artikel kami: “Web Scraping dengan Python: Dari Dasar hingga Latihan”.
Langkah 1: Instal perpustakaan yang diperlukan
Pertama kita perlu menginstal perpustakaan. Yang kita butuhkan hanyalah perpustakaan Permintaan untuk mengekstrak data dari Pencarian Gambar Google. Untuk menginstal perpustakaan Permintaan, Anda dapat mengetikkannya ke dalam prompt perintah:
pip install requestsSekarang mari kita beralih ke pembuatan skrip.
Langkah 2: Impor modul yang diperlukan
Buat file baru dengan ekstensi *.py dimana kita akan menulis scriptnya. Impor perpustakaan persyaratan termasuk:
import requestsKita memerlukan perpustakaan Permintaan untuk membuat permintaan ke API Scrape-It.Cloud dan menerima respons dari API.
Langkah 3: Siapkan kunci dan parameter API
Mari kita sesuaikan parameter yang akan kita gunakan. Jika memungkinkan untuk memasukkan data ke dalam variabel, lebih baik melakukannya saat kita menggunakannya di banyak tempat. Jadi mari kita mulai dengan membuat variabel yang akan kita masukkan titik akhir API dan kata kuncinya.
keyword = 'Coffee'
api_url="https://api.scrape-it.cloud/scrape/google"Sekarang kita membuat header permintaan dan memasukkan kunci API yang kita dapatkan pada contoh terakhir.
headers = {'x-api-key': 'YOUR-API-KEY'}Langkah terakhir adalah membuat isi permintaan dan memasukkan parameter yang diperlukan. Pada parameter “q”, kita memasukkan kata kunci yang disimpan sebelumnya ke dalam variabel. Selanjutnya, tentukan domain Google untuk melakukan pencarian. Dan parameter terakhir, “tbm”, harus memiliki nilai “isch” untuk mencari gambar.
params = {
'q': keyword,
'domain': 'google.com',
'tbm': 'isch'
}Seperti yang kami katakan di contoh terakhir, parameter jauh lebih penting. Anda dapat menemukan semuanya di dokumentasi kami.
Langkah 4: Buat dan kirim permintaan API
Sekarang yang harus kita lakukan adalah menggabungkan semua data di atas ke dalam satu query dan menjalankannya. Gunakan blok try..exclusive jika kueri berjalan dengan kesalahan.
try:
response = requests.get(api_url, params=params, headers=headers)
# Here will be the future code
except Exception as e:
print("Failed to make the API request:", e)Pendekatan ini memungkinkan Anda untuk melanjutkan eksekusi kode meskipun terjadi kesalahan. Jika tidak, eksekusi program akan dibatalkan.
Langkah 5: Analisis dan proses respons API
Menerima dan memproses respons juga mudah. Untuk melakukannya, pastikan permintaan tersebut memberikan respons positif. Dan kemudian memasukkan data dalam format JSON ke dalam variabel.
if response.status_code == 200:
# Parse the JSON response
data = response.json()Anda dapat menetapkan tindakan yang harus diambil jika permintaan tidak berhasil, seperti: B. keluaran dari kode respons. Atau Anda tidak dapat menambahkan apa pun, maka kode hanya akan dieksekusi jika jawaban positif.
Langkah 6: Ekstrak URL gambar dan data
Sekarang pastikan skrip berfungsi dengan baik. Dapatkan daftar nama gambar dan tautan ke sana, lalu tampilkan.
images_results = data('imagesResults')
for image in images_results:
print(image('title'),str(": "), image('original'))Karena respons dikembalikan dalam format JSON, maka relatif mudah untuk dikerjakan. Jalankan skrip dan pastikan semuanya sudah benar.
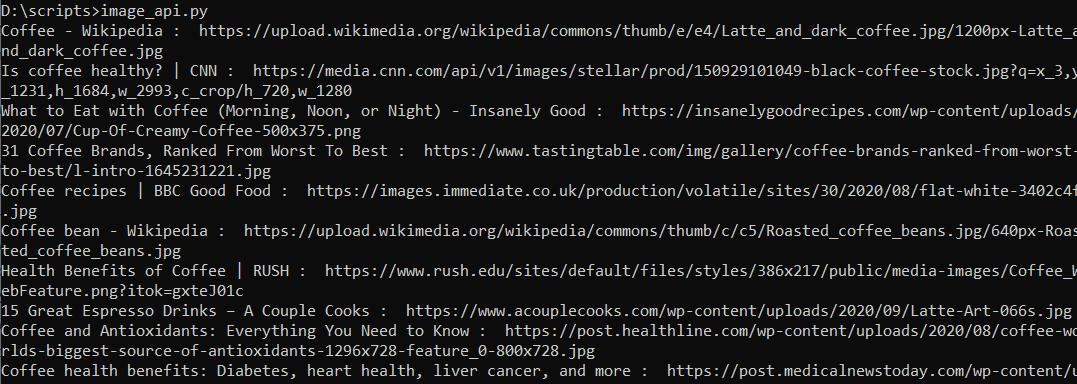
Kami memiliki semua data yang kami perlukan untuk mengumpulkan gambar. Mari lanjutkan ke langkah berikutnya dan simpan gambar yang diperoleh.
Langkah 7: Unduh gambar
Ada banyak cara untuk menyimpan gambar, tetapi kami tidak akan membahasnya secara detail. Mari gunakan perpustakaan Permintaan yang sudah terhubung untuk menyimpan data. Pertama, mari buat algoritme untuk apa yang perlu kita lakukan:
- Buat folder tempat gambar akan disimpan. Kami tidak dapat melakukan ini, tetapi semua gambar akan berada di folder bersama, dan ini merepotkan. Jadi kita buat folder yang identik dengan kata kunci tersebut.
- Dapatkan ekstensi gambar. Sayangnya, perpustakaan Permintaan mengharuskan kita menentukan format file yang akan disimpan. Mari kita ambil dari kolom "Asli".
- Tetapkan nama file. Untuk melakukan ini kami menggunakan judul dan ekstensi file.
- Simpan semua file satu per satu.
Untuk menyelesaikan tugas ini, kita memerlukan dua perpustakaan tambahan: re (untuk menggunakan ekspresi reguler) dan os (untuk menangani operasi sistem seperti membuat folder). Mereka sudah diinstal sebelumnya sehingga kami dapat segera mengintegrasikannya ke dalam skrip.
import os
import reMari ikuti algoritme dan buat folder. Untuk menghindari kesalahan, hapus kemungkinan spasi dan karakter lain:
folder_name = re.sub(r'(^\w\-)+', '_', keyword)
os.makedirs(folder_name, exist_ok=True)Dapatkan data perluasan dan hapus karakter yang tidak perlu dari judul di setiap gambar:
images_results = data('imagesResults')
for image in images_results:
image_title = re.sub(r'(^\w\-)+', '_', image('title'))
image_url = image('original')
image_extension = image_url.split('.')(-1)Tetapkan nama dan jalur file:
image_file_name = f"{image_title}.{image_extension}"
image_path = os.path.join(folder_name, image_file_name)Sekarang kita memuat gambar dan menyimpannya sebagai file. Kami juga menampilkan pesan apakah berhasil:
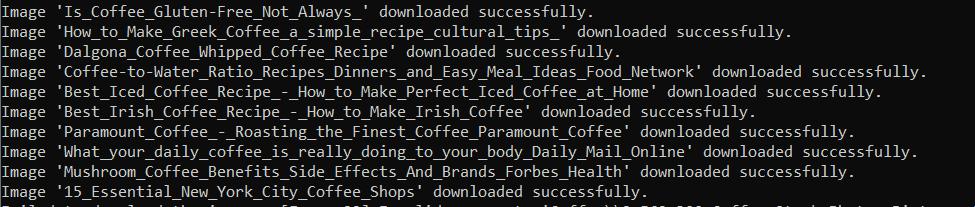
with open(image_path, "wb") as file:
image_response = requests.get(image_url)
if image_response.status_code == 200:
file.write(image_response.content)
print(f"Image '{image_title}' downloaded successfully.")
else:
print(f"Failed to download the image '{image_title}'. Status code:", image_response.status_code)Jalankan skrip dan periksa apakah semuanya berfungsi dengan benar:
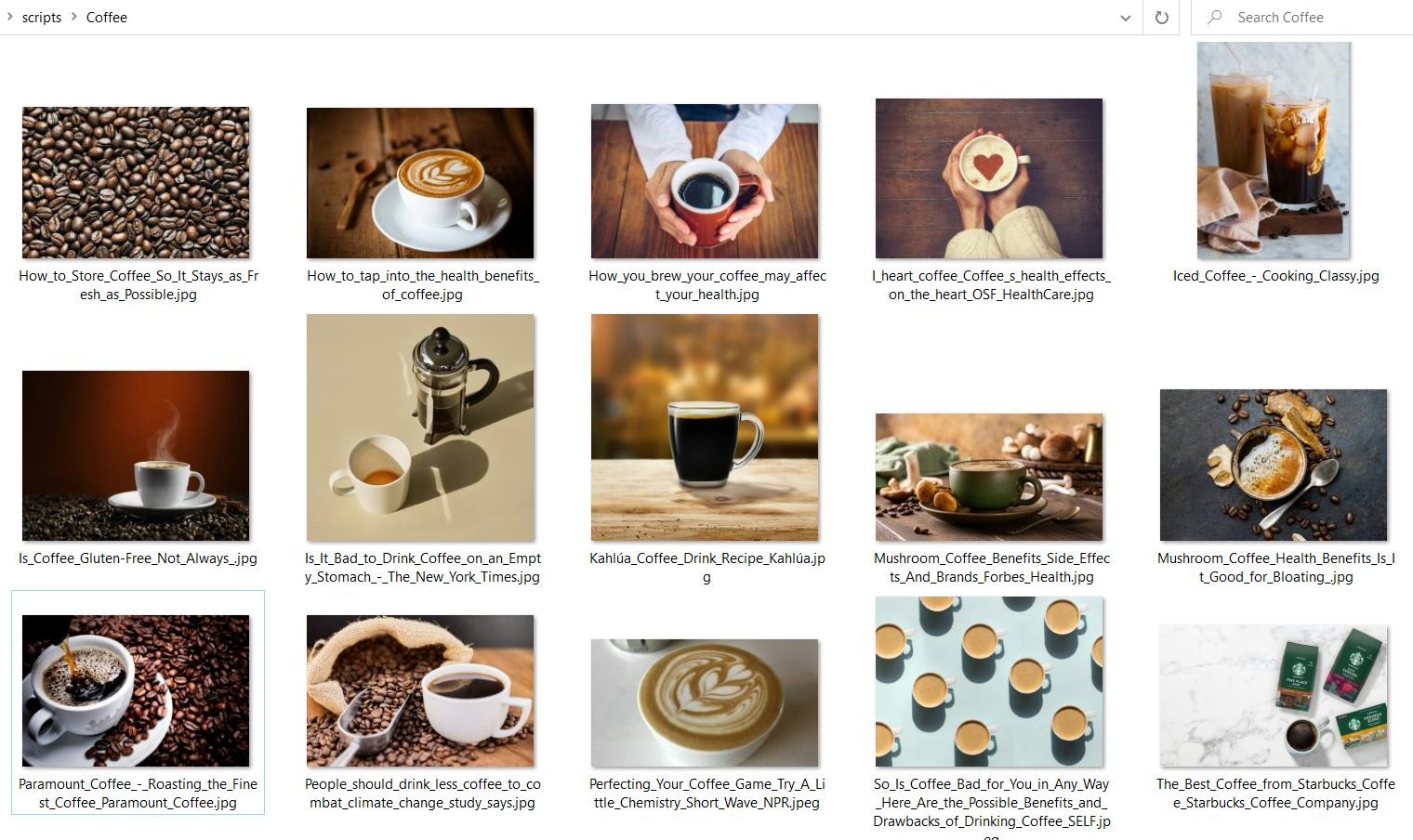
Sebagai hasil eksekusi, kami menerima folder Coffee dengan semua gambar yang dihasilkan:
Kode lengkap:
import requests
import os
import re
keyword = 'Coffee'
api_url="https://api.scrape-it.cloud/scrape/google"
headers = {'x-api-key': 'YOUR-API-KEY'}
params = {
'q': keyword,
'domain': 'google.com',
'tbm': 'isch'
}
try:
response = requests.get(api_url, params=params, headers=headers)
if response.status_code == 200:
# Parse the JSON response
data = response.json()
# Create a folder with the keyword name
folder_name = re.sub(r'(^\w\-)+', '_', keyword)
os.makedirs(folder_name, exist_ok=True)
# Save the images to the folder
images_results = data('imagesResults')
for image in images_results:
print(image('title'),str(": "), image('original'))
try:
image_title = re.sub(r'(^\w\-)+', '_', image('title'))
image_url = image('original')
image_extension = image_url.split('.')(-1)
image_file_name = f"{image_title}.{image_extension}"
image_path = os.path.join(folder_name, image_file_name)
with open(image_path, "wb") as file:
image_response = requests.get(image_url)
if image_response.status_code == 200:
file.write(image_response.content)
print(f"Image '{image_title}' downloaded successfully.")
else:
print(f"Failed to download the image '{image_title}'. Status code:", image_response.status_code)
except Exception as e:
print("Failed to download the image: ", e)
else:
print("Failed to get the API response. Status code:", response.status_code)
except Exception as e:
print("Failed to make the API request:", e)Dengan menggunakan API, Anda dapat dengan cepat dan mudah mengambil sampel gambar berukuran besar dan menangani tugas penghindaran captcha, penggunaan proxy, dan penghindaran blok.
Cara mengikis gambar Google dengan Python dengan BeautifulSoup
Sekarang mari kita lihat cara mengikis gambar tanpa menggunakan API. Kita dapat menggunakan perpustakaan scraping apa pun untuk ini. Jadi mari kita lihat opsi paling sederhana: gunakan pustaka Permintaan yang sudah familiar dan pustaka BeautifulSoup untuk mengurai data halaman.
Opsi ini tidak memungkinkan kita menerapkan peralihan halaman atau menyimulasikan perilaku pengguna, tetapi perpustakaan BeautifulSoup sangat bagus untuk pemula dan mudah dipelajari. Jika Anda ingin meniru browser, periksa perpustakaan Selenium. Ia menggunakan driver web, misalnya Chromedriver, dan memungkinkan kontrol browser tanpa kepala.
Langkah 1: Teliti halaman Gambar Google
Sebelum kita melanjutkan membuat skrip, kita perlu memeriksa halamannya. Pada contoh sebelumnya, hal ini tidak diperlukan karena kami menggunakan API dan mendapatkan hasil yang selesai dan terstruktur dengan baik.
Buka Gambar Google dan telusuri gambar untuk kueri “kopi”. Perhatikan struktur tautan. Sangat membantu untuk mendapatkan data bukan untuk satu kata kunci, tetapi untuk keseluruhan daftar.
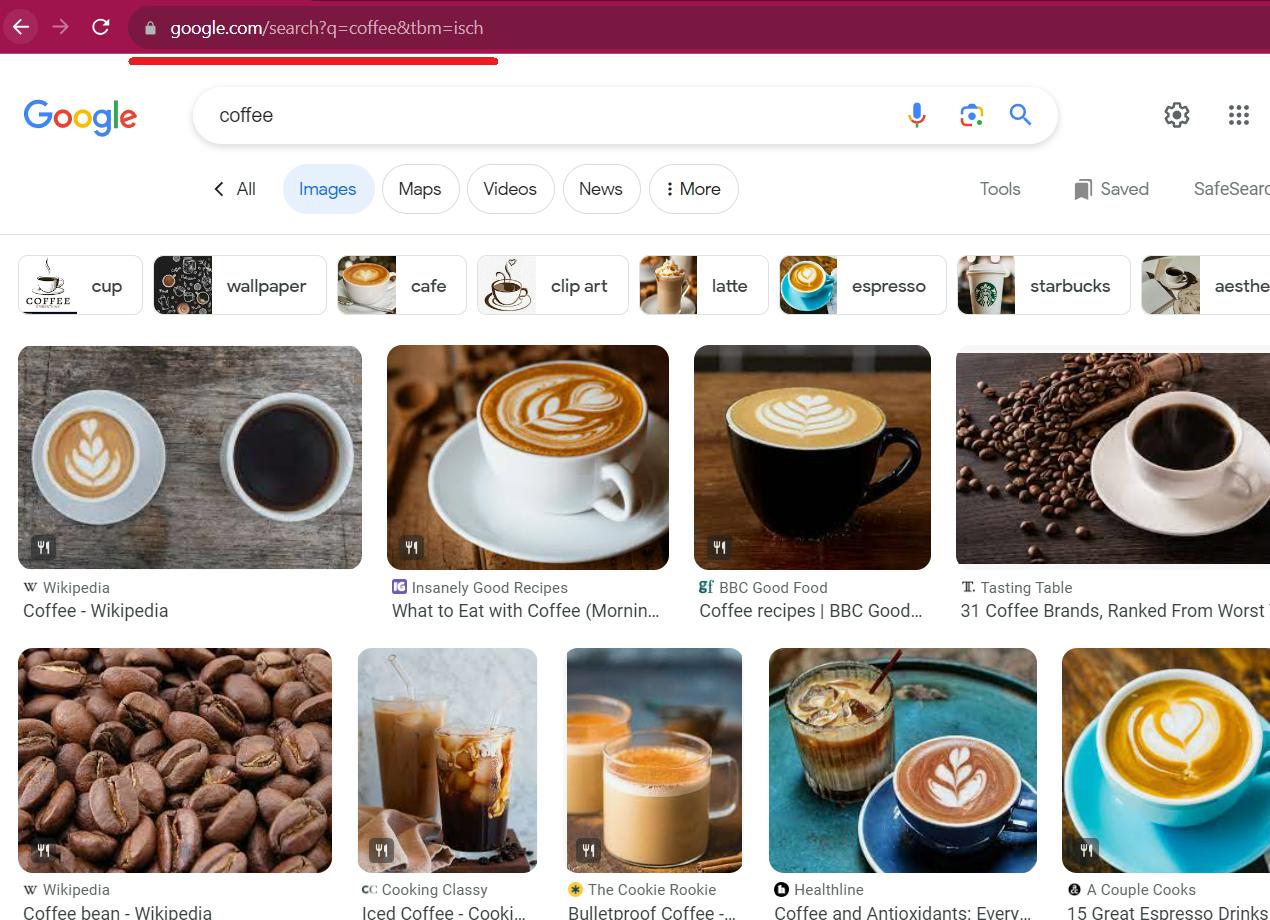
Kita dapat menggunakan variabel untuk membuat permintaan pencarian yang diperlukan:
https://www.google.com/search?q={KEYWORD}&tbm=ischBuka DevTools (F12 atau klik kanan pada halaman dan buka Inspect) dan temukan kode yang cocok dengan gambar. Gunakan alat ini untuk mencari item di halaman.
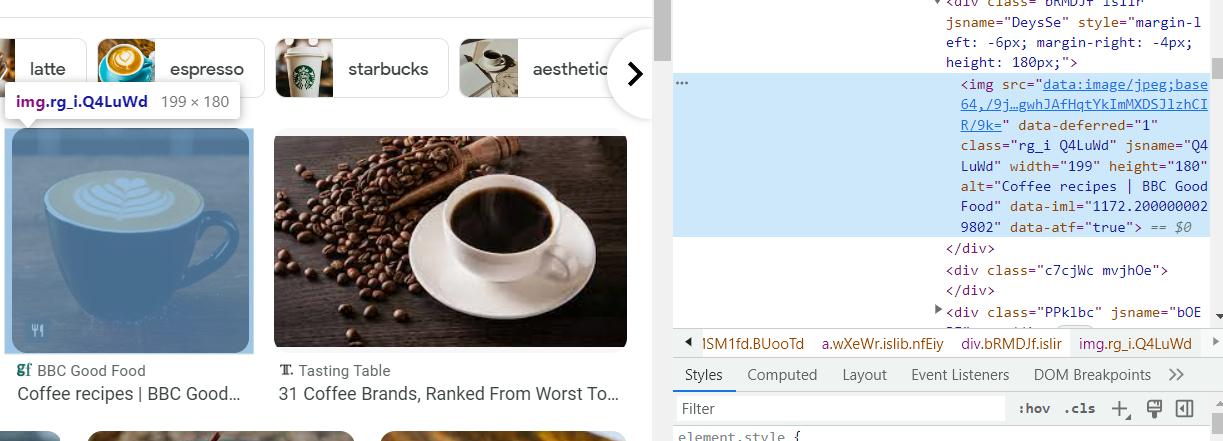
Di sini kita dapat melihat kode setiap elemen dan menemukan data yang kita butuhkan. Jika kita langsung menggunakan data yang tersimpan di tag img, kita akan mendapatkan preview gambar. Untuk mendapatkan gambar asli, ekstrak kode Javascript, jalankan dan analisis hasilnya. Karena ini adalah contoh sederhana, kita akan mendapatkan pratinjau gambar.
Langkah 2: Instal perpustakaan yang diperlukan
Seperti disebutkan sebelumnya, kita memerlukan perpustakaan BeautifulSoup. Anda dapat menginstalnya dengan perintah ini:
pip install requests bs4Mari beralih ke pembuatan skrip.
Hubungkan semua perpustakaan yang diperlukan dan atur variabelnya. Di sini kami menggunakan User-Agent di header untuk mengurangi risiko pemblokiran. Anda dapat membuka browser Anda dan menemukan browser Anda sendiri atau menggunakan browser kami.
import requests, re, os
from bs4 import BeautifulSoup
keyword = "coffee"
url = f"https://www.google.com/search?q={keyword}&tbm=isch"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}Kemudian kita membuat blok try…catch dan mengeksekusi query di dalamnya:
try:
response = requests.get(url, headers=headers)
#Here will be code
except Exception as e:
print("Failed to make the request:", e)Sekarang pastikan permintaan berhasil dan buat folder yang diperlukan. Kami akan mengambil blok ini dari contoh sebelumnya dan oleh karena itu tidak akan memasukkannya lagi.
Langkah 4: Parsing respons HTML dengan BeautifulSoup
Untuk mengambil elemen tertentu dari halaman HTML, kami menggunakan pemilih CSS dan perpustakaan sup yang indah:
images = soup.find_all('img')
img_src_list = (img('src') for img in images if 'src' in img.attrs)Kami memiliki daftar tautan ke pratinjau gambar dan kami dapat melanjutkan ke langkah berikutnya.
Langkah 5: Unduh gambar
Mari kita atur variabel penghitung untuk memberi nomor pada gambar yang disimpan. Kemudian telusuri seluruh daftar gambar secara berurutan dan simpan. Proses penyimpanannya identik dengan contoh sebelumnya.
сount = 0
for img in img_src_list:
count=count+1
image_path = os.path.join(folder_name, f"{str(count)}_{folder_name}.jpg")Sebagai hasil dari menjalankan skrip, kami menerima folder dengan gambar pratinjau.
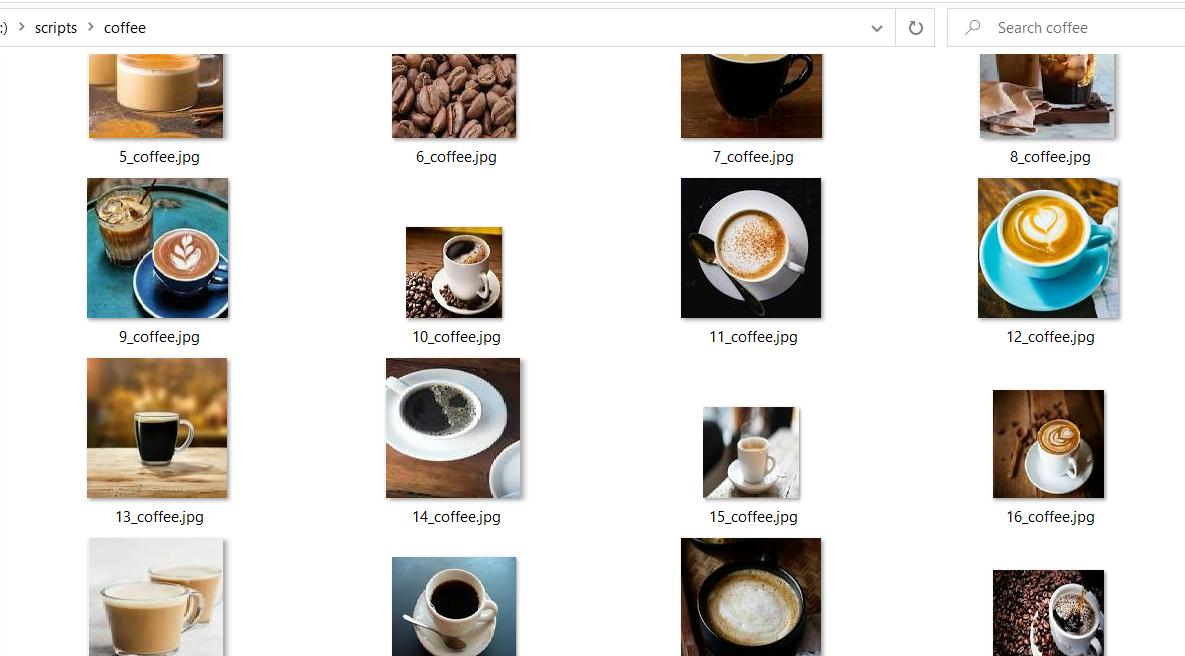
Berikut kode lengkapnya jika Anda mengalami masalah:
import requests, re, os
from bs4 import BeautifulSoup
keyword = "coffee"
url = f"https://www.google.com/search?q={keyword}&tbm=isch"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
count = 0
folder_name = re.sub(r'(^\w\-)+', '_', keyword)
os.makedirs(folder_name, exist_ok=True)
soup = BeautifulSoup(response.content, 'html.parser')
images = soup.find_all('img')
img_src_list = (img('src') for img in images if 'src' in img.attrs)
for img in img_src_list:
count=count+1
image_path = os.path.join(folder_name, f"{str(count)}_{folder_name}.jpg")
with open(image_path, "wb") as file:
try:
image_response = requests.get(img)
if image_response.status_code == 200:
file.write(image_response.content)
print(f"Image '{img}' downloaded successfully.")
else:
print(f"Failed to download the image '{img}'. Status code:", image_response.status_code)
except Exception as e:
print("Oops!")
else:
print("Failed to fetch the webpage. Status code:", response.status_code)
except Exception as e:
print("Failed to make the request:", e)Setelah menjalankan skrip kami hanya mendapat 20 gambar. Sayangnya kami tidak dapat lagi mengambil gambar menggunakan perpustakaan ini. Untuk mendapatkan lebih dari 20 gambar gunakan perpustakaan Selenium. Dengan bantuannya, Anda dapat menyesuaikan pengguliran sehingga Anda tidak dibatasi jumlah gambar yang akan diunduh.
Kesimpulan dan temuan
Untuk mengikis gambar Google, Anda dapat menggunakan API atau perpustakaan pengikisan. Pilihan Anda harus didasarkan pada keterampilan, tujuan, dan sasaran Anda. Menggunakan API untuk scraping jauh lebih mudah. Selain itu, Anda tidak perlu khawatir tentang pemblokiran, CAPTCHA, atau penggunaan proxy. Di sisi lain, jika Anda mahir dalam pemrograman, Anda dapat membuat alat yang akan menyelesaikan tugas Anda sepenuhnya.
Dengan panduan langkah demi langkah ini, Anda dapat mencoba dasar-dasar menyalin gambar Google, memilih alat, dan mengambil langkah pertama dalam mengumpulkan gambar. Kami telah menggunakan contoh sederhana sehingga Anda dapat memahami dan mempelajari dasar-dasarnya.