
Daftar Isi
Apa yang perlu Anda ketahui sebelum melakukan scraping di Node.js
Tidak semua data yang dikikis sama dan Anda harus menarik garis yang jelas antara apa yang bisa dan tidak bisa Anda kikis. Jadi apa yang tidak bisa kamu lakukan?
- Hindari menjual kembali informasi pribadi untuk tujuan komersial. Hal ini melanggar etika dan standar GDPR dan Undang-Undang Privasi Konsumen California
- Jangan mengikis data perusahaan jika ada peraturan untuk API karena selalu disarankan untuk menggunakannya daripada mengikis data web
- Pastikan Anda hanya diperbolehkan menghapus titik akhir yang relevan dari sisi agen pengguna. Untuk mengetahui titik akhir mana yang diizinkan dengan benar, periksa file robots.txt situs, seperti ini: https://amazon.com/robots.txt
Alat dan pustaka web scraping Node.js terbaik
Seperti disebutkan sebelumnya, perpustakaan ini menangani semua yang ingin Anda hapus dari web dan memenuhi kebutuhan pengumpulan data Anda.
Sebelum menulis sebaris kode, Anda harus mempertimbangkan prasyarat berikut:
- Instal Node.js di mesin lokal Anda, yang disertakan dalam manajer paket npm
- Anda setidaknya memiliki pengetahuan dasar tentang JavaScript
- Pengetahuan tentang penggunaan DevTools di browser untuk memeriksa elemen situs web
Lengkap? Sekarang mari kita lihat ikhtisar alat dan pustaka yang tersedia yang dapat Anda gunakan untuk web scraping.
1. Aksio dan Cheerio
Axios adalah klien HTTP berbasis janji yang digunakan pengembang untuk mengirim permintaan dari browser klien dan aplikasi Node.js, menerima konten halaman sebagai tanggapan.
Berkat kesederhanaannya, Axios adalah salah satu implementasi termudah untuk mengambil kode HTML dari halaman web dalam proyek JavaScript.
Di sisi lain, Cheerio adalah paket ketergantungan yang mem-parsing markup menjadi objek mirip DOM dan menyediakan API dengan metode untuk melintasi dan memanipulasi struktur data kode. Implementasi Cheerio mengingatkan pada jQuery.
Untuk menggunakannya, instal paket ke dalam proyek yang diinisialisasi menggunakan perintah berikut:
</p>
npm instal aksio cheerio
<p>
Salin dan tempel kode ini ke file titik masuk:
</p>
const express = memerlukan('ekspres'); const aksio = memerlukan('aksios'); const cheerio = memerlukan('cheerio'); const aplikasi = ekspres(); const PORT = proses.env.PORT || 3000; const situs web = 'https://news.sky.com'; coba { axios(situs web).lalu((res) => { const data = res.data; const $ = cheerio.load(data); biarkan konten = (); $('.sdc-site-tile__headline', data ).each(fungsi () { const title = $(ini).teks(); const url = $(ini).find('a').attr('href'); content.push({ judul, url , }); app.get('/', (req, res) => { res.json(konten); }); }); }); } catch (kesalahan) { console.log(error, error.message) } app.listen(PORT, () => { console.log(`server berjalan di PORT:${PORT}`); });
<p>
Dalam kode contoh yang disediakan:
- Node.js Framework Express digunakan untuk menampilkan respons dari Axios dan Cheerio melalui titik akhir rute asal (“/”) menggunakan metode GET
- Data respons dari Axios diambil dan dimuat ke Cheerio
- Cheerio kemudian melakukan pencarian di situs web dan memilih item dalam dokumen
- Itu mengulang elemen-elemen ini dan mengkompilasi konten menjadi serangkaian objek yang mewakili judul dan URL halaman
Hasil yang diharapkan terlihat seperti ini:
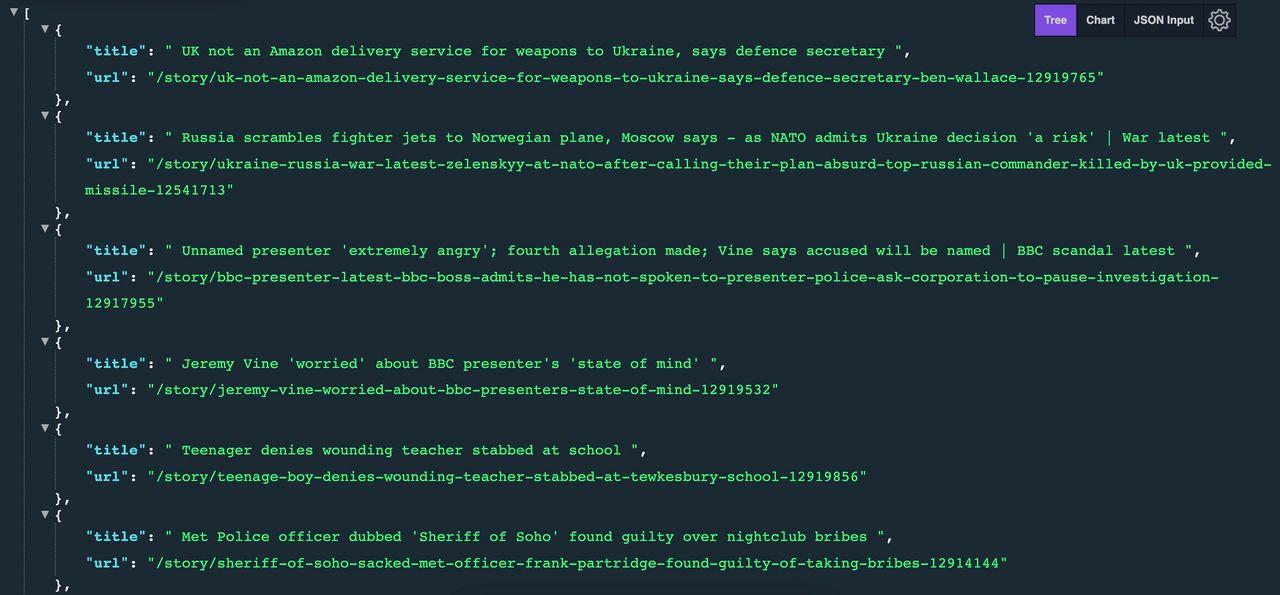
Jika Anda ingin mempelajari lebih lanjut tentang penggunaan Axios dan Cheerio untuk mengumpulkan data web, lihat tutorial scraper LinkedIn kami dengan Node.js.
2. Dalang
Puppeteer, versi Chrome atau Chromium tanpa kepala, mewakili pustaka Node.js yang digunakan secara terprogram melalui CLI (Command Line Interface) atau langsung di lingkungan Node.js.
Ini mengemulasi tindakan pengguna sebenarnya dan mencakup aktivitas seperti menggulir, mengklik, mengambil tangkapan layar, memfasilitasi pengujian otomatis, dan banyak lagi.
Untuk menginstal Puppeteer ke direktori proyek Anda, gunakan perintah berikut:
</p>
npm install dalang
<p>
Untuk tutorial ini, kita akan menggunakan website freeCodeCamp untuk mengekstrak judul blog menggunakan Puppeteer.
Lanjutkan dengan menyalin dan menempelkan kode yang disediakan:
</p>
index.js const dalang = require("dalang"); fungsi async run() { const browser = menunggu dalang.launch(); halaman const = menunggu browser.newPage(); menunggu halaman.goto("https://www.freecodecamp.org/news/tag/blog/"); // Dapatkan semua judul blog const title = menunggu halaman.evaluate(() => Array.from(document.querySelectorAll(".post-feed .post-card"), (e) => ({ blog: e.querySelector (".post-card-content .post-card-title a").innerText, })) ); console.log(judul); menunggu browser.close(); } berlari();
<p>
Halaman yang dirender menanyakan semua judul H2 menggunakan metode querySelectorAll dan menampilkan hasilnya sebagai objek.
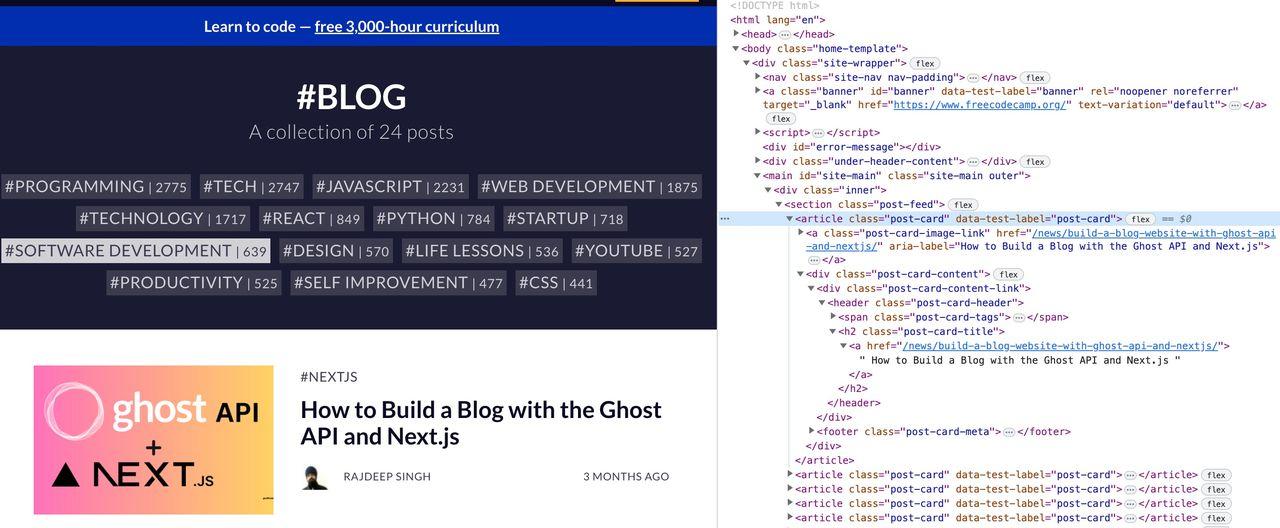
Hasil menjalankan skrip ini di terminal terlihat seperti ini:

Kelemahan menggunakan Puppeteer adalah kinerjanya yang lambat dan konsumsi waktu pada halaman web yang kompleks.
Sebagai aturan praktis, menggunakan browser tanpa kepala harus menjadi pilihan terakhir jika tidak ada cara lain untuk mengakses data.
Apakah Anda ingin mengetahui lebih lanjut? Dalam tutorial ini, kami akan menunjukkan cara mengumpulkan ratusan hadiah hotel menggunakan Node.js dan Puppeteer - dengan trik sederhana untuk meningkatkan tingkat keberhasilan hingga 99,99 %.
3. API Pengikis
ScraperAPI adalah alat yang berhubungan dengan rotasi proxy, pemrosesan CAPTCHA, blok IP, dan rendering JS. Hal ini memungkinkan Anda mencari domain yang paling sulit dan tidak dapat diprediksi sekalipun dengan kecepatan tinggi dan dalam skala besar. Menambahkan lebih banyak paralelisme ke scraper memungkinkan Anda mencari halaman secara asinkron tanpa diblokir.
Untuk mengakses alat ini, daftarkan akun untuk mengakses dasbor Anda. Di sana Anda akan menemukan kunci API dan beberapa kode contoh untuk pengujian:
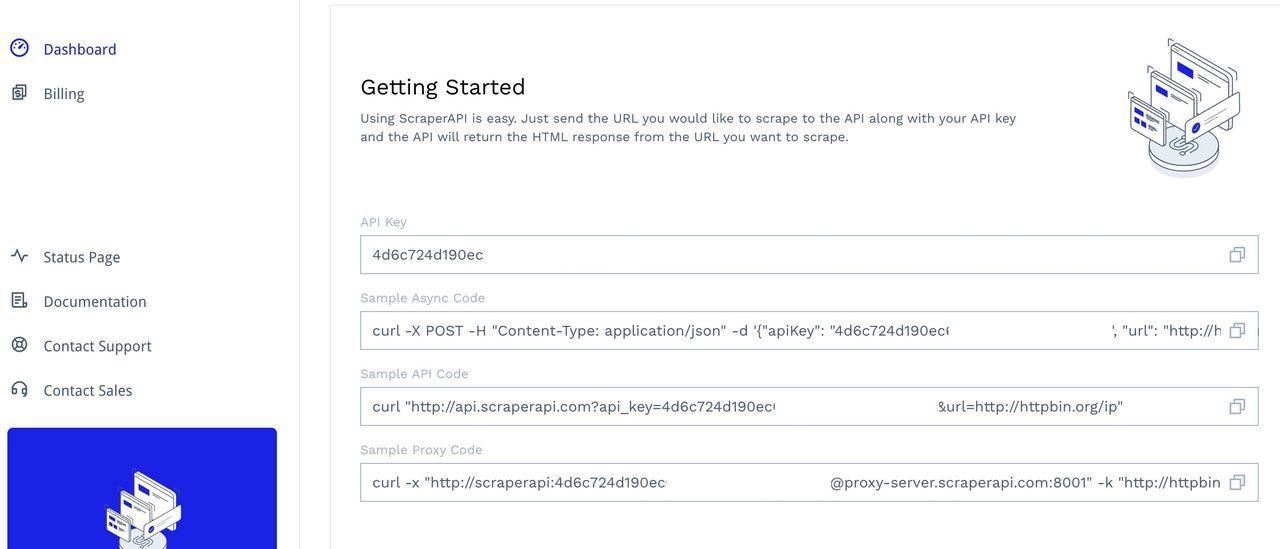
Pelajari cara mengintegrasikan dan mengimplementasikan ScraperAPI dengan permintaan Axios dalam panduan ini dan contoh kode menggunakan Puppeteer di Node.js.
Catatan: Disarankan untuk menetapkan batas waktu navigasi di aplikasi Anda saat mencapai titik akhir atau memindai situs web untuk mencapai tingkat keberhasilan terbaik dan menghindari pemblokiran pada domain yang sulit dipindai.
Apa saja kasus penggunaan ScraperAPI dan manfaatnya?
ScraperAPI dapat mengatasi tantangan berikut:
- Manajemen proksi
- Rendering JavaScript
- Manajemen peramban dan CAPTCHA
- Unduhan dalam HTML atau JSON
- Titik akhir data terstruktur (misalnya Amazon dan Google scraping)
- Scraper asinkron dan permintaan bersamaan
- Scraper kode rendah (DataPipeline)