
Was Sie vor dem Scraping in Node.js wissen müssen
Gekratzte Daten sind nicht gleich und Sie sollten eine klare Grenze zwischen dem ziehen, was Sie kratzen können und was nicht. Was können Sie also nicht tun?
- Vermeiden Sie den Weiterverkauf personenbezogener Daten zu kommerziellen Zwecken. Es verstößt gegen die Ethik und Standards der DSGVO und des California Consumer Privacy Act
- Scrapen Sie keine Unternehmensdaten, wenn es Bestimmungen für APIs gibt, da immer empfohlen wird, diese zu verwenden, anstatt Webdaten zu scrapen
- Stellen Sie sicher, dass Sie nur relevante Endpunkte von der User-Agent-Seite entfernen dürfen. Um zu erfahren, welche Endpunkte richtig zulässig sind, überprüfen Sie die robots.txt-Datei der Website, etwa so: https://amazon.com/robots.txt
Die besten Node.js-Web-Scraping-Tools und -Bibliotheken
Wie bereits erwähnt, erledigen diese Bibliotheken alles, was Sie aus dem Web entfernen möchten, und erfüllen Ihre Datenerfassungsanforderungen.
Bevor Sie eine Codezeile schreiben, müssen Sie die folgenden Voraussetzungen berücksichtigen:
- Installieren Sie Node.js auf Ihrem lokalen Computer, das im Paketmanager npm enthalten ist
- Sie verfügen über mindestens grundlegende Kenntnisse von JavaScript
- Kenntnisse in der Verwendung der DevTools im Browser zum Überprüfen der Elemente von Websites
Erledigt? Kommen wir nun zur Übersicht der verfügbaren Tools und Bibliotheken, die Sie für Web Scraping verwenden können.
1. Axios und Cheerio
Axios ist ein auf Versprechen basierender HTTP-Client, den Entwickler verwenden, um Anfragen von Client-Browsern und Node.js-Anwendungen zu senden, wobei der Seiteninhalt als Antwort empfangen wird.
Dank seiner Einfachheit ist Axios eine der einfachsten Implementierungen zum Abrufen von HTML-Code von einer Webseite in JavaScript-Projekten.
Andererseits ist Cheerio ein Abhängigkeitspaket, das Markup in DOM-ähnliche Objekte analysiert und eine API mit Methoden zum Durchlaufen und Bearbeiten der Datenstruktur des Codes bietet. Die Implementierung von Cheerio erinnert an jQuery.
Um es zu verwenden, installieren Sie das Paket mit dem folgenden Befehl in einem initialisierten Projekt:
</p>
npm install cheerio axios
<p>
Kopieren Sie diesen Code und fügen Sie ihn in die Einstiegspunktdatei ein:
</p>
const express = require('express');
const axios = require('axios');
const cheerio = require('cheerio');
const app = express();
const PORT = process.env.PORT || 3000;
const website = 'https://news.sky.com';
try {
axios(website).then((res) => {
const data = res.data;
const $ = cheerio.load(data);
let content = ();
$('.sdc-site-tile__headline', data).each(function () {
const title = $(this).text();
const url = $(this).find('a').attr('href');
content.push({
title,
url,
});
app.get('/', (req, res) => {
res.json(content);
});
});
});
} catch (error) {
console.log(error, error.message)
}
app.listen(PORT, () => {
console.log(`server is running on PORT:${PORT}`);
});
<p>
Im bereitgestellten Beispielcode:
- Das Node.js-Framework Express wird verwendet, um die Antworten von Axios und Cheerio über den Home-Route-Endpunkt („/“) mithilfe der GET-Methode anzuzeigen
- Die Antwortdaten von Axios werden abgerufen und in Cheerio geladen
- Cheerio führt dann eine Suche auf der Website durch und wählt Elemente innerhalb des Dokuments aus
- Es durchläuft diese Elemente und kompiliert den Inhalt in einer Reihe von Objekten, die den Titel und die URL der Seite darstellen
Das erwartete Ergebnis sieht wie folgt aus:
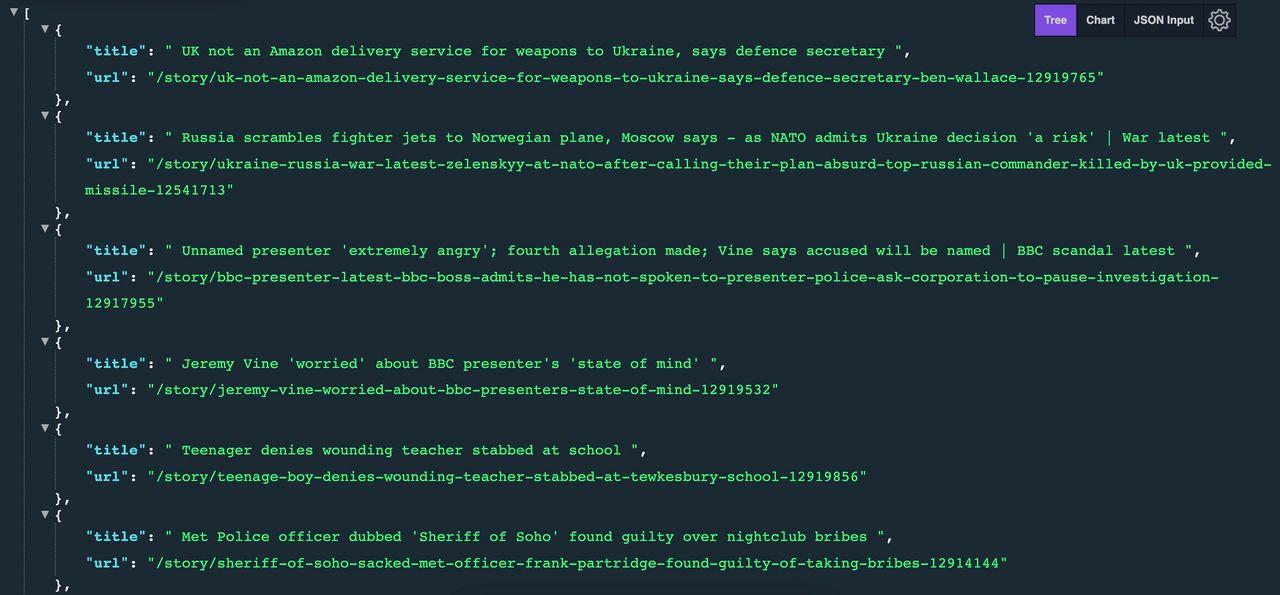
Wenn Sie mehr über die Verwendung von Axios und Cheerio zum Sammeln von Webdaten erfahren möchten, sehen Sie sich unser LinkedIn-Scraper-Tutorial mit Node.js an.
2. Puppenspieler
Puppeteer, eine Headless-Version von Chrome oder Chromium, stellt eine Node.js-Bibliothek dar, die programmgesteuert über die CLI (Befehlszeilenschnittstelle) oder direkt in einer Node.js-Umgebung verwendet wird.
Es emuliert die Aktionen eines echten Benutzers und umfasst Aktivitäten wie Scrollen, Klicken, Erstellen von Screenshots, die Erleichterung automatisierter Tests und mehr.
Um Puppeteer in Ihrem Projektverzeichnis zu installieren, verwenden Sie den folgenden Befehl:
</p>
npm install puppeteer
<p>
Für dieses Tutorial verwenden wir die Website freeCodeCamp, um den Blogtitel mit Puppeteer zu extrahieren.
Fahren Sie fort, indem Sie den bereitgestellten Code kopieren und einfügen:
</p>
index.js
const puppeteer = require("puppeteer");
async function run() {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto("https://www.freecodecamp.org/news/tag/blog/");
// Get all blog title
const titles = await page.evaluate(() =>
Array.from(document.querySelectorAll(".post-feed .post-card"), (e) => ({
blog: e.querySelector(".post-card-content .post-card-title a").innerText,
}))
);
console.log(titles);
await browser.close();
}
run();
<p>
Die gerenderte Seite fragt alle H2-Titel mit der Methode querySelectorAll ab und zeigt die Ergebnisse als Objekt an.
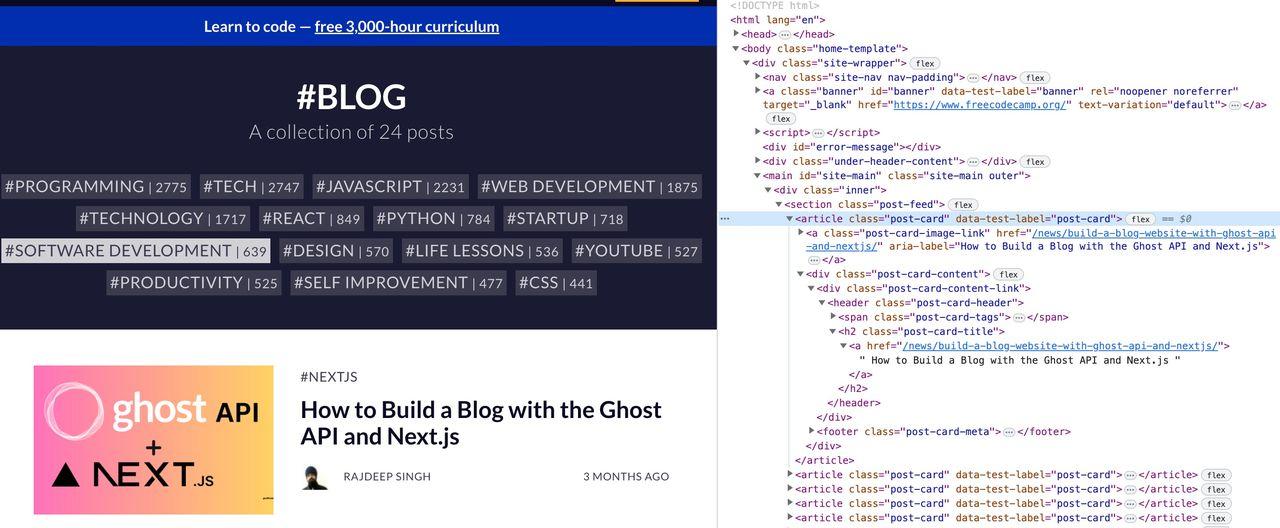
Das Ergebnis der Ausführung dieses Skripts im Terminal sieht folgendermaßen aus:

Der Nachteil der Verwendung von Puppeteer ist die langsame Leistung und der Zeitaufwand bei komplexen Webseiten.
Als Faustregel gilt, dass die Verwendung eines Headless-Browsers die letzte Methode sein sollte, wenn es keine andere Möglichkeit gibt, auf die Daten zuzugreifen.
Möchten Sie mehr erfahren? In diesem Tutorial zeigen wir Ihnen, wie Sie mit Node.js und Puppeteer Hunderte von Hotelpreisen sammeln – mit einem einfachen Trick, um die Erfolgsquote auf 99,99 % zu steigern.
3. ScraperAPI
ScraperAPI ist ein Tool, das sich mit der Proxy-Rotation, der Verarbeitung von CAPTCHAs, IP-Blöcken und dem JS-Rendering befasst. Dadurch können Sie selbst die schwierigsten und unvorhersehbarsten Domänen mit hoher Geschwindigkeit und in großem Maßstab durchsuchen. Durch das Hinzufügen weiterer Parallelitäten zu Ihren Scrapern können Sie Seiten asynchron durchsuchen, ohne blockiert zu werden.
Um auf das Tool zuzugreifen, registrieren Sie sich für ein Konto, um auf Ihr Dashboard zuzugreifen. Dort finden Sie Ihren API-Schlüssel und einige Beispielcodes zum Testen:
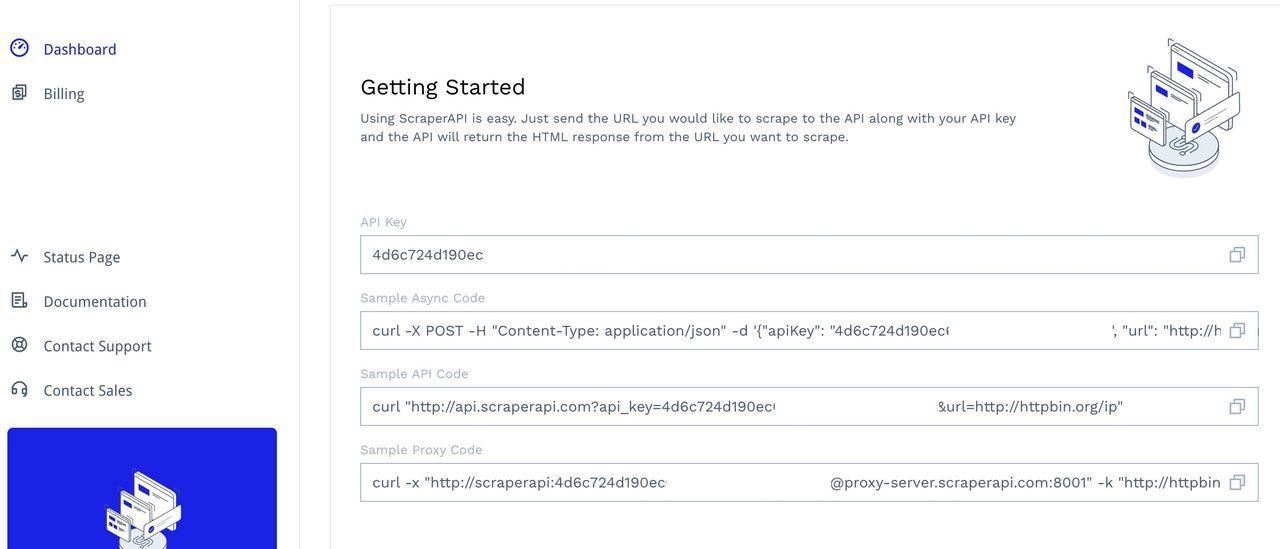
Erfahren Sie in diesem Handbuch und im Beispielcode mit Puppeteer in Node.js, wie Sie ScraperAPI mit Axios-Anfragen integrieren und implementieren.
Notiz: Es wird empfohlen, in Ihrer Anwendung ein Navigations-Timeout festzulegen, wenn Sie Endpunkte erreichen oder die Websites scannen, um die besten Erfolgsraten zu erzielen und eine Blockierung auf schwer zu scannenden Domänen zu vermeiden.
Was sind die Anwendungsfälle von ScraperAPI und seine Vorteile?
ScraperAPI kann die folgenden Herausforderungen bewältigen:
- Proxy-Verwaltung
- JavaScript-Rendering
- Browser- und CAPTCHA-Verwaltung
- Downloads in HTML oder JSON
- Strukturierte Datenendpunkte (z. B. Amazon und Google Scraping)
- Asynchroner Scraper und gleichzeitige Anfragen
- Low-Code-Scraper (DataPipeline)
