
XPath (XML Path Language) adalah bahasa kueri yang dirancang khusus untuk navigasi dan mengekstraksi elemen dari dokumen XML. Ini memberikan cara yang tepat untuk mengidentifikasi dan memilih node tertentu dalam struktur XML, menjadikannya alat yang berharga untuk analisis dan pemrosesan data.
Dibandingkan dengan penyeleksi CSS, XPath memberikan fleksibilitas dan fungsionalitas yang lebih besar untuk pengeditan dan pengambilan data. Meskipun sebelumnya kita telah menjelajahi kemampuan dan manfaat XPath, artikel ini berfokus pada penerapannya pada pemrosesan teks dan pencarian.
Pemilihan teks adalah operasi mendasar di XPath karena sebagian besar data dalam dokumen XML berbentuk teks. Dengan menguasai pemilihan teks, Anda dapat mengekstrak data yang diperlukan dari XML dan memprosesnya lebih lanjut berdasarkan persyaratan aplikasi atau tugas.
Daftar Isi
Metode dasar untuk memilih item berdasarkan teks
XPath menyediakan beberapa metode inti untuk bekerja dengan teks dan beberapa di antaranya pada awalnya tidak dirancang untuk tujuan ini, namun masih sangat ramah pengguna. Mari kita mulai dengan membicarakan metode dasar pencarian teks. Kami akan mengujinya sebagai contoh di halaman demo ini.
text(): Pilih elemen dengan teks yang sama persis
Cara yang pertama adalah text(), yang memungkinkan Anda menemukan elemen berdasarkan konten teks lengkapnya. Ini menjadikannya cara yang tepat untuk menargetkan elemen berdasarkan konten tekstualnya. Misalnya, untuk memilih item ini:
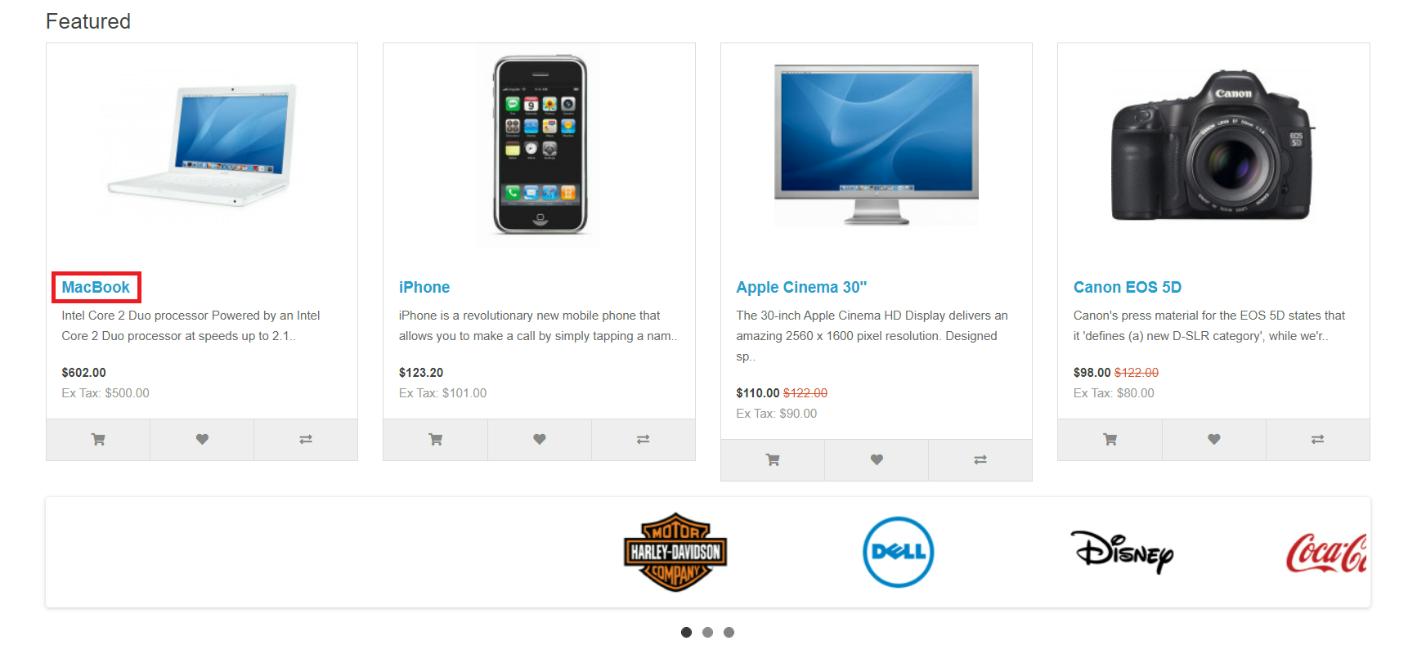
Kita dapat menggunakan XPath berikut:
//*(text()='MacBook')Untuk memeriksanya di browser, kita dapat menggunakan fungsi pencarian browser dan memberi tanda titik (.) di depan XPath atau menggunakan konsol dan menjalankannya $x() atau $$() Berfungsi untuk mencari elemen.
Mari kita periksa elemennya dan coba menemukannya:
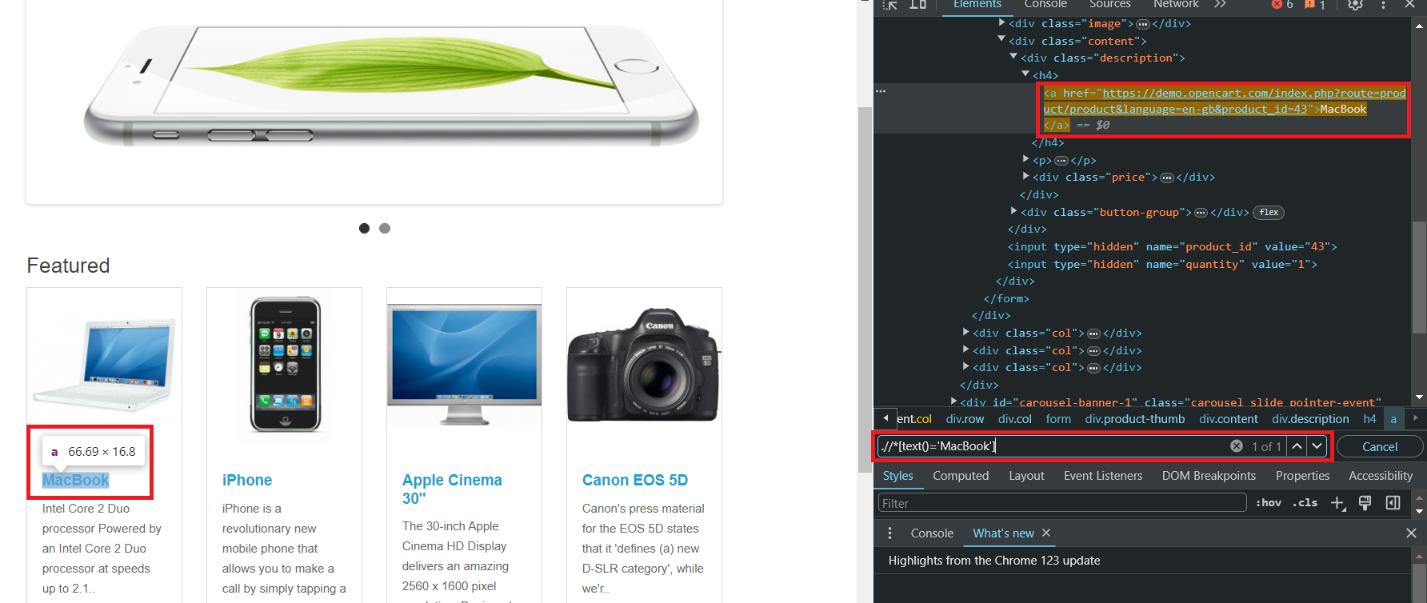
Ketika text() Metode ini cocok untuk memilih elemen berdasarkan teks yang tepat, namun penggunaannya mungkin terbatas karena beberapa kelemahan:
- Itu
text()Metode ini memerlukan pencocokan teks yang tepat. Jika elemen berisi format atau spasi tambahan, teks mungkin tidak cocok dengan string pencarian yang tepat. - Ini juga peka terhadap huruf besar-kecil, artinya teks harus sama persis dalam hal kapitalisasi dan huruf kecil. Misalnya, “MacBook” dan “macbook” akan dianggap sebagai teks yang berbeda.
- Terakhir ini
text()Metode ini mengabaikan elemen anak dan konten teksnya. Ini mungkin tidak dipilih jika suatu elemen berisi elemen turunan dengan teks.
Oleh karena itu, dalam beberapa kasus mungkin perlu menggunakan strategi pemilihan elemen yang lebih kompleks berdasarkan properti elemen lain atau konteksnya.
berisi(): Pilih elemen yang berisi substring
Metode ini memungkinkan Anda mencari substring dalam teks atau nilai atribut suatu elemen. Berbeda dengan cara sebelumnya, Anda tidak perlu mengetahui keseluruhan teks suatu elemen, melainkan hanya sebagian saja. Metode ini sangat berguna ketika memilih item yang mengandung kata kunci atau potongan teks tertentu.
Namun, penting untuk dicatat bahwa contains() Metode ini peka huruf besar-kecil secara default. Artinya kecocokan hanya akan ditemukan jika substring yang Anda cari memiliki huruf besar/kecil yang sama dengan teks pada elemen.
Mari kembali ke situs demo dan coba temukan semua baris yang berisi substring "EOS". Kita dapat menggunakan XPath berikut untuk ini:
.//*(contains(text(), 'EOS'))Hasilnya kami menemukan dua elemen:
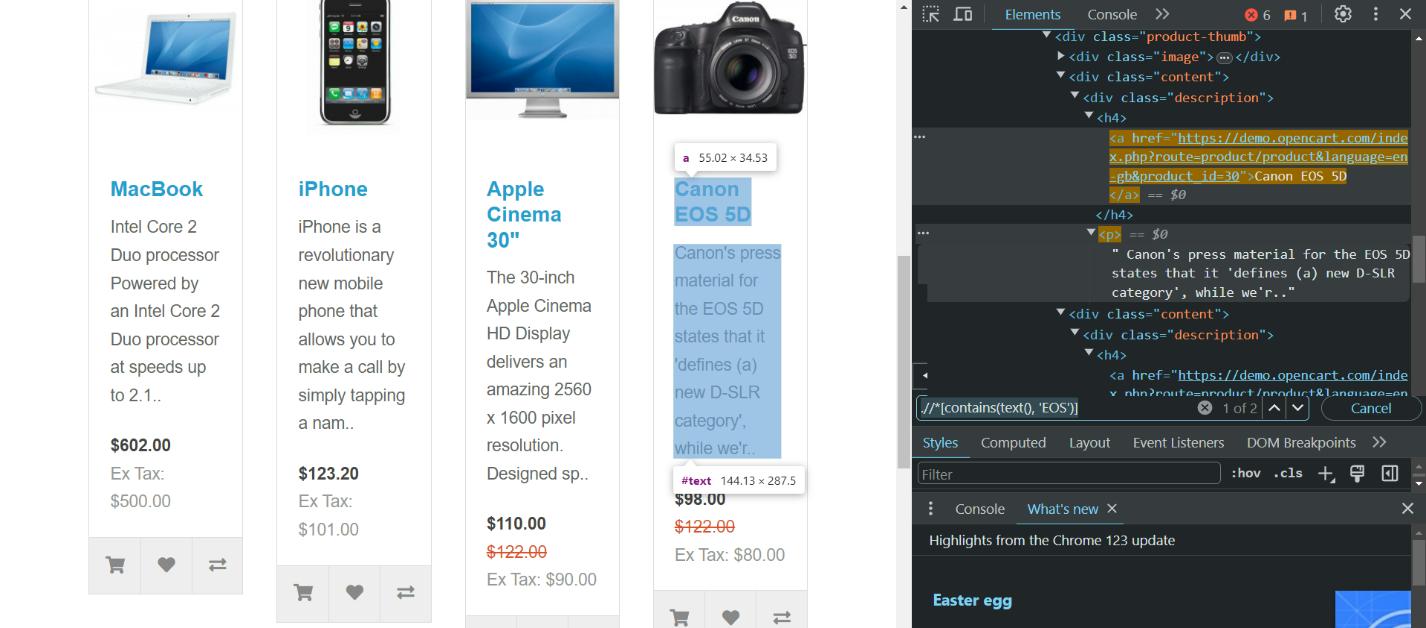
Jika Anda ingin mendapatkan hasil yang lebih akurat, Anda dapat sedikit memodifikasi XPath yang kita lihat sebelumnya dan menentukan tag tertentu, misalnya:
.//p(contains(text(), 'EOS'))Varian ini hanya memberikan satu hasil – deskripsi produk.
Dimulai dengan(): Pilih elemen yang dimulai dengan substring
Jika Anda perlu menemukan item yang dimulai dengan kata atau suku kata tertentu, itu saja starts-with() metode adalah pilihan yang paling sesuai. Metode ini sangat berguna ketika mencari elemen dengan awalan atau string awal tertentu.
Yuk cari produk yang dimulai dengan karakter tertentu:
.//*(starts-with(text(), 'Ap'))Oleh karena itu hanya akan ada satu:
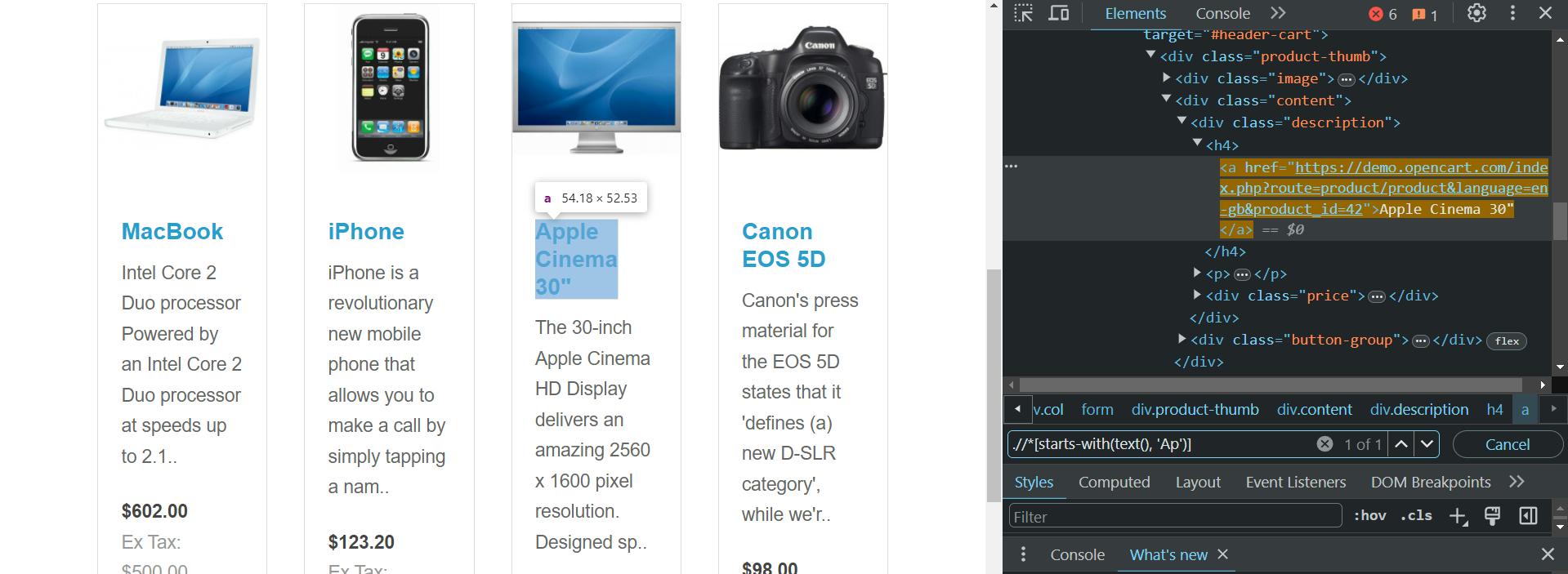
Perhatikan bahwa metode ini juga peka huruf besar-kecil. Jika Anda ingin XPath Anda tidak peka huruf besar-kecil, Anda dapat melompat ke bagian berikutnya di mana kita akan membahas cara mewujudkannya.
berakhir dengan(): Pilih elemen yang diakhiri dengan substring
Cara ini kebalikan dari cara sebelumnya dan mencari kecocokan bukan di awal teks, melainkan di akhir. Ini bisa sangat berguna ketika Anda perlu memilih elemen yang diidentifikasi berdasarkan atributnya yang diakhiri dengan string tertentu.
Sayangnya metode ini tidak berfungsi untuk XPath 1.0. Meskipun sebagian besar alat mendukungnya, ia memiliki sintaks terbatas untuk bekerja dengan data teks:
.//*(ends-with(text(), 'ok'))Daripada mencari seluruh teks, Anda dapat menentukan tag atau atribut tertentu, atau menentukan cakupan pencarian yang diinginkan.
Metode pemilihan teks tambahan
Seperti yang telah disebutkan, selain metode dasar, ada metode lain untuk mencari dan memproses teks. Bagian ini menjelaskan cara mengidentifikasi elemen yang diperlukan dengan lebih tepat menggunakan metode XPath tambahan yang cocok untuk bekerja dengan string.
Translate(): Huruf besar/kecil diabaikan
Untuk menemukan elemen apa pun hurufnya, kita dapat menormalkan teks dengan mengubah semua huruf menjadi huruf kecil. Inilah cara kita melakukannya:
//*(starts-with(translate(text(), 'ABCDEFGHIJKLMNOPQRSTUVWXYZ', 'abcdefghijklmnopqrstuvwxyz'), 'mac'))Kode ini menggunakan translate() Cara mengganti semua huruf besar dengan huruf kecil. Lalu kita menggunakannya starts-with() Berfungsi untuk mencari item yang diawali dengan string huruf kecil “mac”.
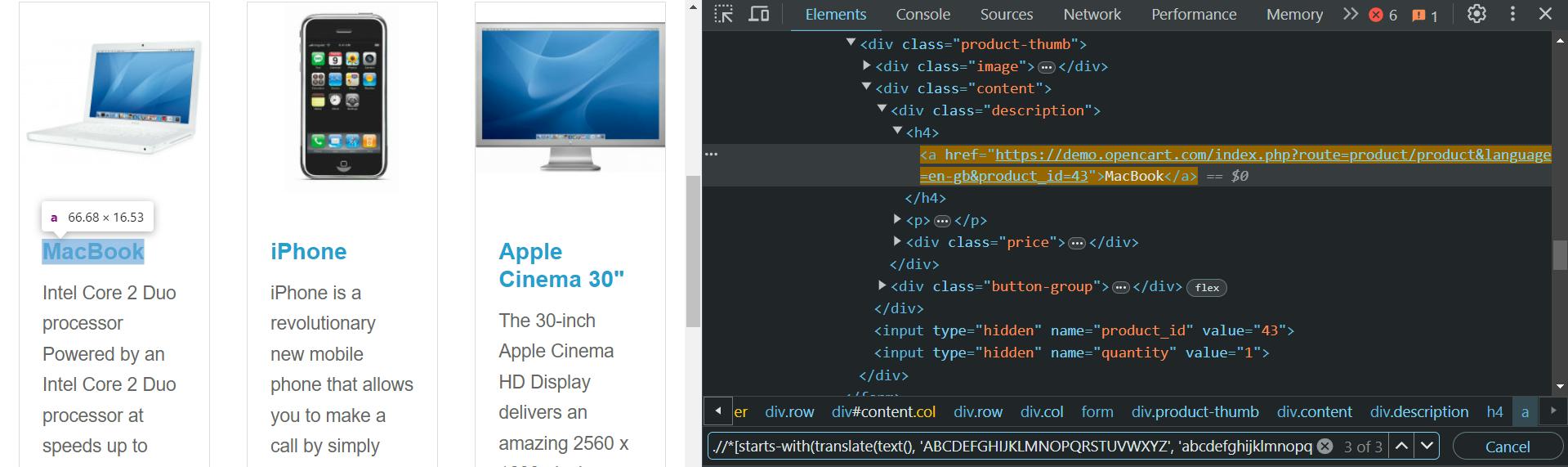
Selain itu, Anda dapat menggunakan lower-case() Dan upper-case() Fungsinya, tapi seperti itu ends-with() metode ini, mereka tidak selalu berhasil.
not(): Kecualikan elemen yang cocok dengan teks tertentu
Metode XPath, not() digunakan untuk mengecualikan elemen yang cocok dengan teks atau pola tertentu. Ini memungkinkan Anda memfilter elemen dalam dokumen dan memilih hanya elemen yang tidak berisi teks tertentu atau cocok dengan pola tertentu.
Penggunaan not() Metode ini sangat berguna ketika Anda mengecualikan item tertentu dari hasil kueri Anda. Misalnya, mari kita perbaiki tag produk dan kecualikan MacBook:
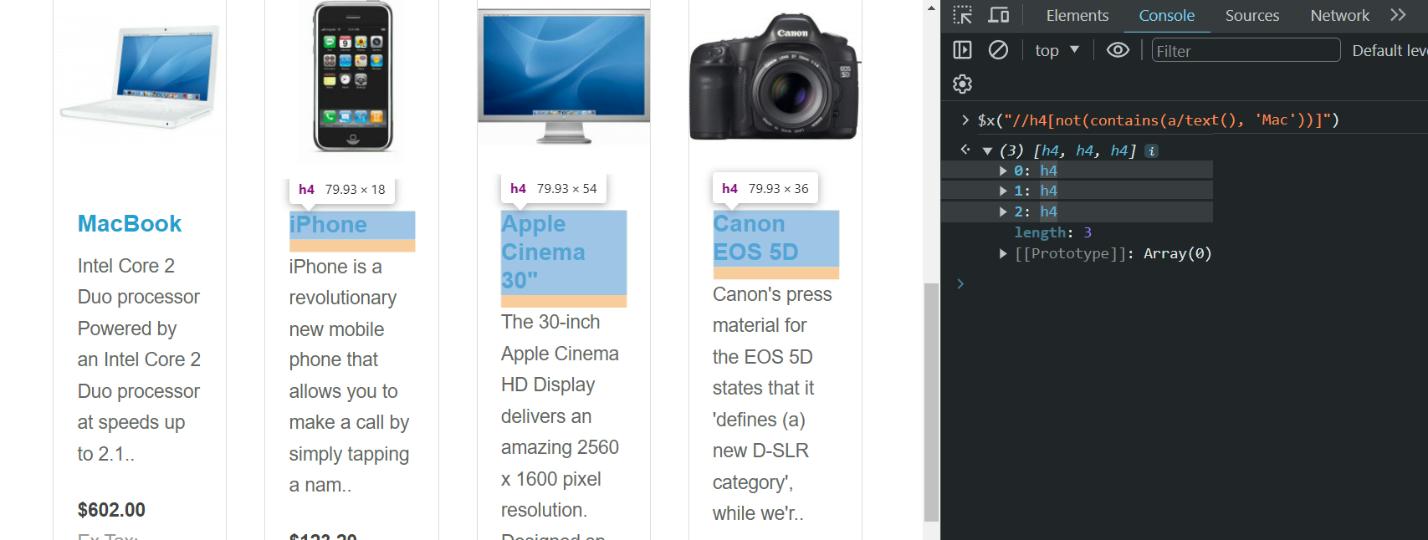
Kami menggunakan ekspresi XPath berikut untuk memilih semua elemen h4 yang tidak mengandung teks "Mac" di elemen turunannya:
//h4(not(contains(a/text(), 'Mac')))Agar hasilnya lebih jelas, kami menjalankan query di konsol browser sehingga kami dapat mengakses hasilnya secara langsung. Untuk membuat contoh ini lebih ringkas, kami hanya akan menampilkan teks dari elemen yang dipilih dan bukan keseluruhan elemen itu sendiri:
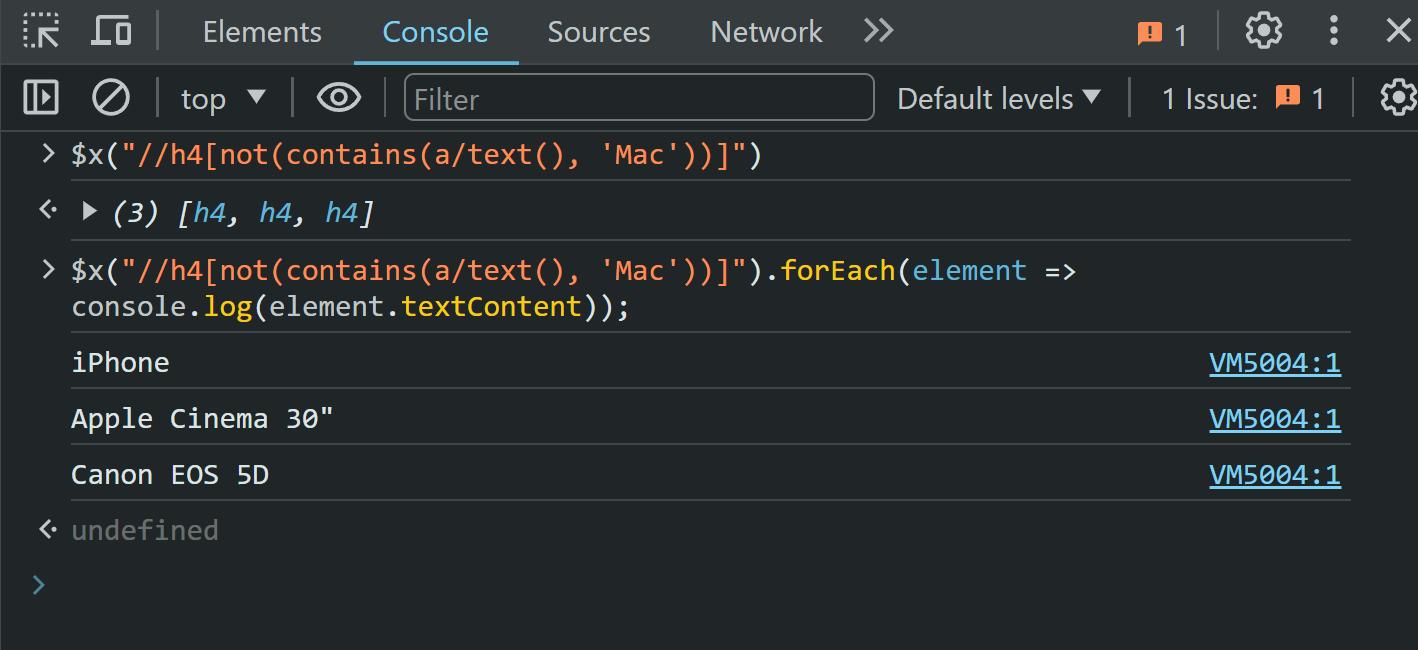
Berikut cara menggunakannya not() Metode kami mendapatkan semua item kecuali MacBook.
position(): Pilih elemen berdasarkan posisinya dalam daftar
XPath position() Metode ini memilih item berdasarkan posisinya dalam daftar. Predikat sering menggunakannya untuk memilih elemen tertentu berdasarkan nomor urutnya. Ini sangat mudah, misalnya, ketika kita hanya ingin mengambil elemen pertama dari sebuah daftar dan bukan seluruh daftar.
Untuk mendapatkan data tentang elemen pertama, Anda dapat menggunakan XPath berikut:
//h4(position() = 1)Untuk mendapatkan elemen terakhir:
//h4(position() = last())Anda juga dapat menentukan serangkaian elemen:
//h4(position() >= 2 and position() <= 4)Hal ini membuat metode ini sangat berguna ketika Anda ingin bekerja dengan elemen tertentu berdasarkan posisinya dalam dokumen.
Itu normalize-space() Metode ini adalah alat yang ampuh di XPath yang memungkinkan Anda bekerja dengan data teks dengan lebih efisien. Meskipun tidak secara langsung menemukan atau mengecualikan elemen, ini memainkan peran penting dalam pemrosesan teks dengan menghilangkan spasi yang tidak diperlukan.
Ini bisa sangat berguna ketika bekerja dengan data teks yang berisi spasi, tab, atau jeda baris tambahan, yang dapat mempersulit pemrosesan data. Menggunakan normalize-space()XPath secara otomatis menghapus semua spasi di awal dan akhir teks dan mengganti setiap string spasi dalam teks dengan satu spasi. Hal ini menghasilkan data teks yang lebih bersih dan konsisten sehingga lebih mudah untuk diproses lebih lanjut.
normalize-space(" This is an example")Saat kita menggunakan normalize-space() Untuk teks ini kita mendapatkan hasil sebagai berikut:
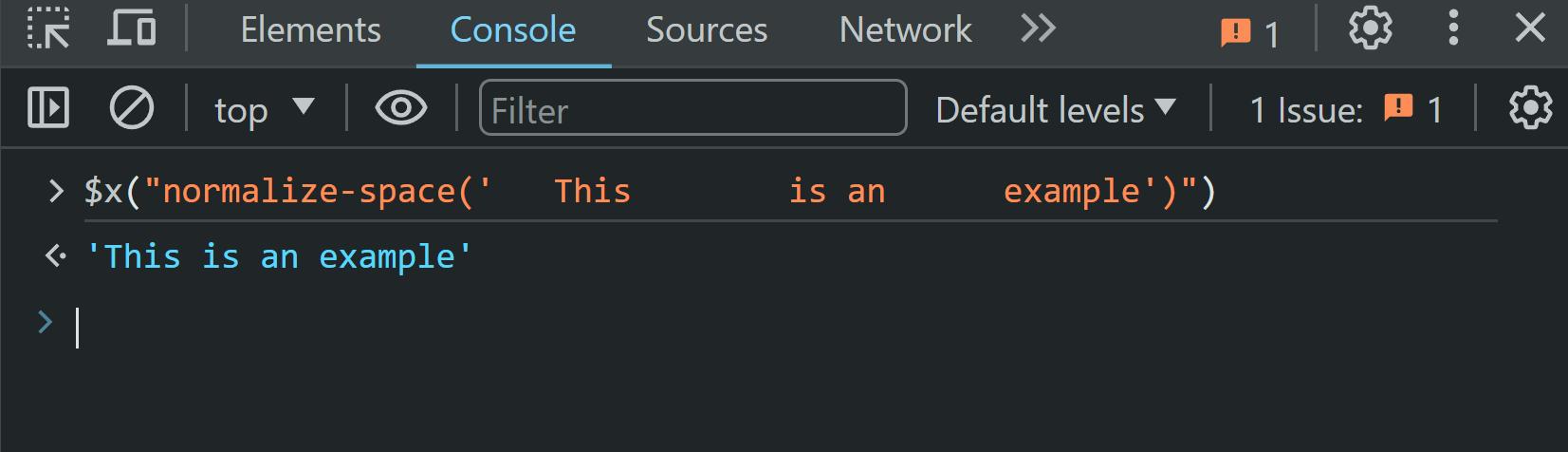
Seperti yang Anda lihat, spasi tambahan, tab, dan baris baru telah dihapus, meninggalkan kita dengan string yang bersih dan ringkas.
Teknik pemilihan teks tingkat lanjut
Sekarang kita telah membahas metode utama untuk mencari dan memproses teks, mari beralih ke teknik XPath yang lebih canggih untuk bekerja dengan teks. Kita akan mulai dengan menjelajahi cara menggunakan ekspresi reguler untuk menemukan elemen.
Menggunakan ekspresi reguler untuk pencocokan teks
Ekspresi reguler (Regex) adalah alat yang ampuh untuk menemukan dan mencocokkan pola dalam teks. Mereka menawarkan lebih banyak fleksibilitas dari itu contains() Metode yang memungkinkan Anda mencari pola, bukan string yang sama persis.
Misalnya, mari pertimbangkan alamat email. Semuanya memiliki struktur yang sama: (email protected). Kita dapat menggunakan Regex untuk menemukan semua alamat email di suatu halaman meskipun kita tidak mengetahui alamat spesifiknya:
//*(matches(text(), '(\w\.-)+@(\w\.-)+'))XPath standar (digunakan di browser dan alat otomatisasi) seringkali hanya mendukung XPath 1.0, yang tidak memiliki fungsi match(). Untuk menggunakan Regex dengan XPath, Anda memerlukan XPath 2.0 atau lebih baru.
Ekspresi reguler adalah alat pengeditan teks canggih yang memungkinkan Anda melakukan berbagai pencarian dan manipulasi pada data teks. Namun, penggunaan praktisnya memerlukan pemahaman tentang sintaksis dan konsep dasarnya.
Meskipun ekspresi reguler dapat digunakan dalam banyak konteks berbeda, ekspresi reguler sering kali digunakan bersama dengan bahasa pemrograman seperti JavaScript atau Python. Ini karena bahasa pemrograman menyediakan cara mudah untuk menulis dan mengeksekusi kode menggunakan ekspresi reguler. Jika Anda ingin mengikis data, Anda akan menemukan sesuatu yang berguna di artikel kami tentang penggunaan XPath di webdriver Selenium.
Kombinasi metode XPath yang berbeda untuk seleksi yang kompleks
Seperti yang telah disebutkan, fungsi pencocokan hanya didukung di XPath 2.0+ dan oleh karena itu tidak berfungsi di sebagian besar browser. Sebagai gantinya, kita dapat menggabungkan metode yang telah dibahas sebelumnya untuk mengekstrak alamat email menggunakan ekspresi XPath berikut:
//div(contains(text(),'@') and contains(text(),'.') and not(contains(text(),' ')))/text()Ekspresi ini menggunakan beberapa kriteria untuk menentukan apakah suatu string adalah alamat email:
- Itu harus berisi simbol @.
- Harus mengandung setidaknya satu titik (.).
- Itu tidak boleh berisi spasi.
Item tersebut akan diabaikan jika salah satu kondisi ini tidak terpenuhi.
Praktik dan tip terbaik
Kami telah mengumpulkan beberapa tip dan trik untuk menjadikan penggunaan XPath Anda lebih efisien dan produktif. Di sini kita melihat masalah umum dan solusinya.
Memilih metode pemilihan teks yang tepat berdasarkan konteks
Metode pemilihan teks di XPath harus disesuaikan dengan struktur dokumen spesifik dan kebutuhan tugas Anda. Misalnya, jika teks berada di dalam tag, Anda dapat menggunakan metode seperti text(), string()atau normalize-space()tergantung pada konteksnya.
Saat memilih XPath, penting untuk memvisualisasikan hasil yang diinginkan dan memahami level yang sesuai untuk setiap metode. Misalnya, Anda dapat menggunakan beberapa metode pada tingkat yang sama untuk menyempurnakan suatu elemen:
//h4(not(contains(a/text(), 'Mac')))(position() = 1)Di sini kita menggunakannya satu per satu untuk menghapus semua elemen yang tidak mengandung "Mac" dan kemudian mengidentifikasi elemen pertama di antara elemen lainnya. Jika Anda ingin menyempurnakan elemen ini lebih lanjut, misalnya menentukan bahwa elemen tersebut harus menjadi yang pertama dan tidak mengandung substring "Mac", XPath akan berbeda:
//h4(not(contains(a/text(), 'Mac')) and position() = 1)Ingatlah bahwa menyesuaikan XPath dengan struktur dokumen dan kebutuhan tugas Anda sangatlah penting.
Hindari kesalahan umum dalam pemilihan teks XPath
Penggunaan sumbu atau kondisi yang salah adalah kesalahan umum XPath yang dapat menyebabkan pemilihan data yang salah atau hasil yang tidak diinginkan. Analisis strukturnya dengan cermat dan periksa kebenaran ekspresi XPath Anda.
Misalnya, varian contoh sebelumnya berikut ini salah:
//h4(not(contains(a/text(), 'Mac'))) and (position() = 1)Ini karena XPath tidak mengizinkan operator “dan” menggabungkan dua kondisi berbeda dalam format ini. Agar dapat berfungsi dengan baik, kita harus menggabungkan kedua kondisi tersebut menjadi satu predikat.
Menguji ekspresi XPath untuk akurasi dan efisiensi
Ada banyak alat dan sumber daya yang tersedia untuk membantu Anda membuat dan menguji ekspresi XPath. Beberapa alat pengembang browser seperti Chrome DevTools atau Alat Pengembang Firefox menyediakan cara mudah untuk menguji XPath di halaman web nyata. Ada juga alat dan perpustakaan online untuk menguji dan men-debug ekspresi XPath.
Kami menggunakan Chrome DevTools untuk meninjau dan mendemonstrasikan ekspresi XPath yang dibuat. Kami sangat menyarankan penggunaan pendekatan ini sebelum mengimplementasikan ekspresi XPath di skrip Anda. Ini jauh lebih cepat daripada metode lain dan memungkinkan Anda untuk segera melacak elemen yang diperlukan dan melihat eksekusi ekspresi Anda secara real-time. Anda juga bisa mendapatkan informasi detail tentang setiap item yang ditemukan.
Kesimpulan dan temuan
Dalam tutorial ini, kita menjelajahi berbagai metode untuk menemukan elemen pada halaman web berdasarkan konten teksnya menggunakan ekspresi XPath. XPath adalah alat standar untuk bekerja dengan dokumen XML dan HTML, menjadikannya alat serbaguna untuk pengikisan dan otomatisasi web, apa pun teknologi atau platform yang digunakan.
Mengotomatiskan tindakan web seperti mengisi formulir, mengklik tombol, dan mengumpulkan informasi sering kali memerlukan penargetan elemen teks tertentu pada halaman. XPath membantu menemukan dan berinteraksi dengan elemen-elemen ini, menyederhanakan proses otomatisasi.
Pengikisan web sering kali memerlukan penggalian data spesifik dari halaman web, seperti judul, harga, dan deskripsi. XPath memungkinkan penargetan elemen yang tepat pada halaman web, menjadikan proses ekstraksi data lebih efisien dan akurat dibandingkan pemilih CSS atau metode lainnya.