
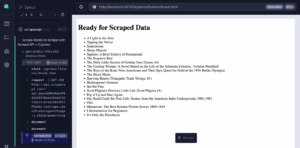
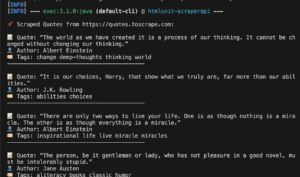
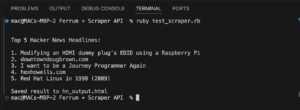

Kopfloser Browser in Python
Headless-Browser sind eine entscheidende Komponente sowohl beim Web Scraping als auch beim automatisierten Testen. Sie führen alle üblichen Browseroperationen aus,...
So scrapen Sie Idealista.com mit Python
So scrapen Sie Idealista.com mit Python
RPA ist ein Replikator: eine organisatorische Glanzleistung
Richard Dawkins‘ Konzept des „Replikators“ in seinem Buch „The Selfish Gene“ bietet eine faszinierende Perspektive, durch die wir den Aufstieg...

Wie wähle ich Elemente nach Text in XPath aus?
XPath (XML Path Language) ist eine Abfragesprache, die speziell für die Navigation und das Extrahieren von Elementen aus XML-Dokumenten entwickelt...
Was ist proaktive Analyse? Wie Netflix, Spotify und Walmart Milliarden verdienen (2024)
Netflix, Spotify, Walmart und andere Giganten haben nicht auf ihr Milliardenvermögen gewettet, indem sie im Dunkeln geschossen haben. Die proaktiven...
So durchsuchen Sie die Immobilienliste von Homes.com (vollständige Anleitung und Code)
Schritt 4: Senden von Anfragen über ScraperAPI Die größte Herausforderung beim Scraping von Homes.com besteht darin, nicht durch die Anti-Scraping-Mechanismen...

Airbnb-Datenextraktion: Kein Code, keine API und keine Python-Methoden
Airbnb ist eine Online-Plattform zur Buchung von Unterkünften, die es Menschen ermöglicht, ihre Häuser, Wohnungen, Zimmer oder andere Arten von...

Integration von Web-Scraped-Daten mit Business-Intelligence-Tools
Jedes Unternehmen muss regelmäßig eine Geschäftsanalyse durchführen. Zu diesem Zweck müssen Ihre Daten strukturiert und zuverlässig sein. Eine der besten...

So durchsuchen Sie Zoopla-Immobilieneinträge
Zoopla stellt Daten zu Immobilien bereit. Sie können Daten über zum Verkauf oder zur Miete stehende Immobilien abrufen. Für jede...

Wie Walmarts Dateneinblicke Ihre Einzelhandelsstrategie vorantreiben können
Was wissen wir über Walmart? Wir wissen, dass es sich um den umsatzstärksten Einzelhändler der Welt handelt. Der weltweite Umsatz...

Amazon-Wettbewerbsanalyse: Schritt-für-Schritt-Anleitung
Schritt 4: Amazon-Produktdaten extrahieren Nachdem wir nun unsere ASIN-Listen haben, können wir den Structured Data Endpoint nutzen, um die detaillierten...

Wie man Quora-Fragen und -Antworten durchsucht (vollständiger Leitfaden)
Schritt 3: Scrollen zum Laden dynamischer Inhalte implementieren Um dynamisch geladene Antworten auf Quora vollständig zu erfassen, definieren wir als...

So extrahieren Sie Produktdaten aus WooCommerce-Shops
WordPress ist in Verbindung mit dem WooCommerce-Plugin eine beliebte und praktische Wahl für die Erstellung von Online-Marktplätzen. Es bietet eine...

Häufige Herausforderungen beim Web Scraping und ihre Lösungen mit RPA
Was fällt Ihnen ein, wenn ich an einen Detektiv denke? Ein scharfer Verstand, ein durchdringender Blick, dem nichts entgeht, eine...

So scrapen Sie Redfin-Eigenschaftsdaten mit Node.js
In diesem Tutorial zeigen wir Ihnen, wie Sie mit Node.js Immobilienlisten aus Redfin extrahieren und so den Datenerfassungsprozess automatisieren, ohne...
cURL mit Proxys verwenden: Eine Schritt-für-Schritt-Anleitung
In diesem Tutorial zeigen wir Ihnen, wie Sie Proxys in cURL verwenden, damit Sie unabhängig von der Größenordnung die gewünschten...

So maximieren Sie das Geschäftswachstum durch LinkedIn Scraping
Denken Sie daran, in Staffel 6 von Das Büroals Sabre 50.000 US-Dollar für neue Leads für sein Vertriebsteam ausgab? Quelle:...

Web Scraping Zillow: Ein moderner Ansatz für Immobilien
Was fällt uns ein, wenn wir das Wort „Immobilien“ sagen? Denken Sie an einen Makler im Hosenanzug und mit strahlend...
Web Scraping Zillow: Ein moderner Ansatz für Immobilien
Was fällt uns ein, wenn wir das Wort „Immobilien“ sagen? Denken Sie an einen Makler im Hosenanzug und mit strahlend...

Web Scraping mit Playwright und Node.js
Das Extrahieren von Daten aus Websites ist in verschiedenen Bereichen unverzichtbar geworden, von der Datenerfassung bis zur Wettbewerbsanalyse. Allerdings kann...