
Pengikisan web Pengikisan web dan perayapan web adalah dua proses berbeda namun terkait yang memungkinkan pengumpulan data dari seluruh Internet. Kedua metode tersebut melibatkan penggalian informasi spesifik melalui navigasi situs web dan mengidentifikasi pola dalam dokumen HTML. Namun keduanya mempunyai perbedaan yang mendasar.
Artikel ini akan mengeksplorasi perbedaan antara pendekatan-pendekatan ini dan menjelaskan kapan pendekatan-pendekatan tersebut paling cocok untuk situasi tertentu. Kami juga akan melihat beberapa contoh bagaimana web scraping dan crawling dapat diterapkan dalam aplikasi dunia nyata. Terakhir, kami akan mengulas tips memilih pendekatan yang tepat untuk kebutuhan proyek atau bisnis Anda.
Daftar Isi
Apa itu perayapan web?
Perayapan web, juga dikenal sebagai web spidering, secara otomatis mengambil konten dari situs web. Bot perangkat lunak digunakan untuk mencari situs web secara sistematis, mengindeks kontennya, dan mengikuti tautan ke situs web lain. Tidak seperti web scraping, yang melibatkan penggalian data tertentu dari situs web, perayapan web adalah cara otomatis menjelajahi seluruh Internet dengan mengunjungi setiap halaman yang ditemukan.
Perayap web, juga disebut laba-laba, robot, atau bot, adalah program komputer yang mencari serangkaian dokumen terkait di Internet untuk menemukan informasi atau data yang relevan untuk pengguna atau aplikasi tertentu. Contoh umumnya adalah laba-laba mesin pencari Google, yang mengunjungi semua halaman yang tersedia di web dan mengindeksnya berdasarkan kata kunci yang ditemukan di halaman tersebut, sehingga pencarian dapat memberikan hasil yang lebih komprehensif bagi pengguna yang menggunakan istilah tersebut dalam pencarian mereka.
Beginilah cara kerja perayapan web
Pada intinya, perayap web bekerja dengan mengirimkan permintaan melalui protokol HTTP/HTTPS untuk meminta informasi dari URL tertentu dan kemudian menguraikan file HTML yang dikembalikan untuk tautan ke URL lain - proses ini berulang hingga tidak ada koneksi unik baru antar dokumen yang ditemukan atau ketika salah satu dari itu ditemukan. mencapai batas yang ditentukan pengguna, mis. B. Hapus jumlah hop maksimum dari URL asli (untuk menghindari loop tak terbatas).
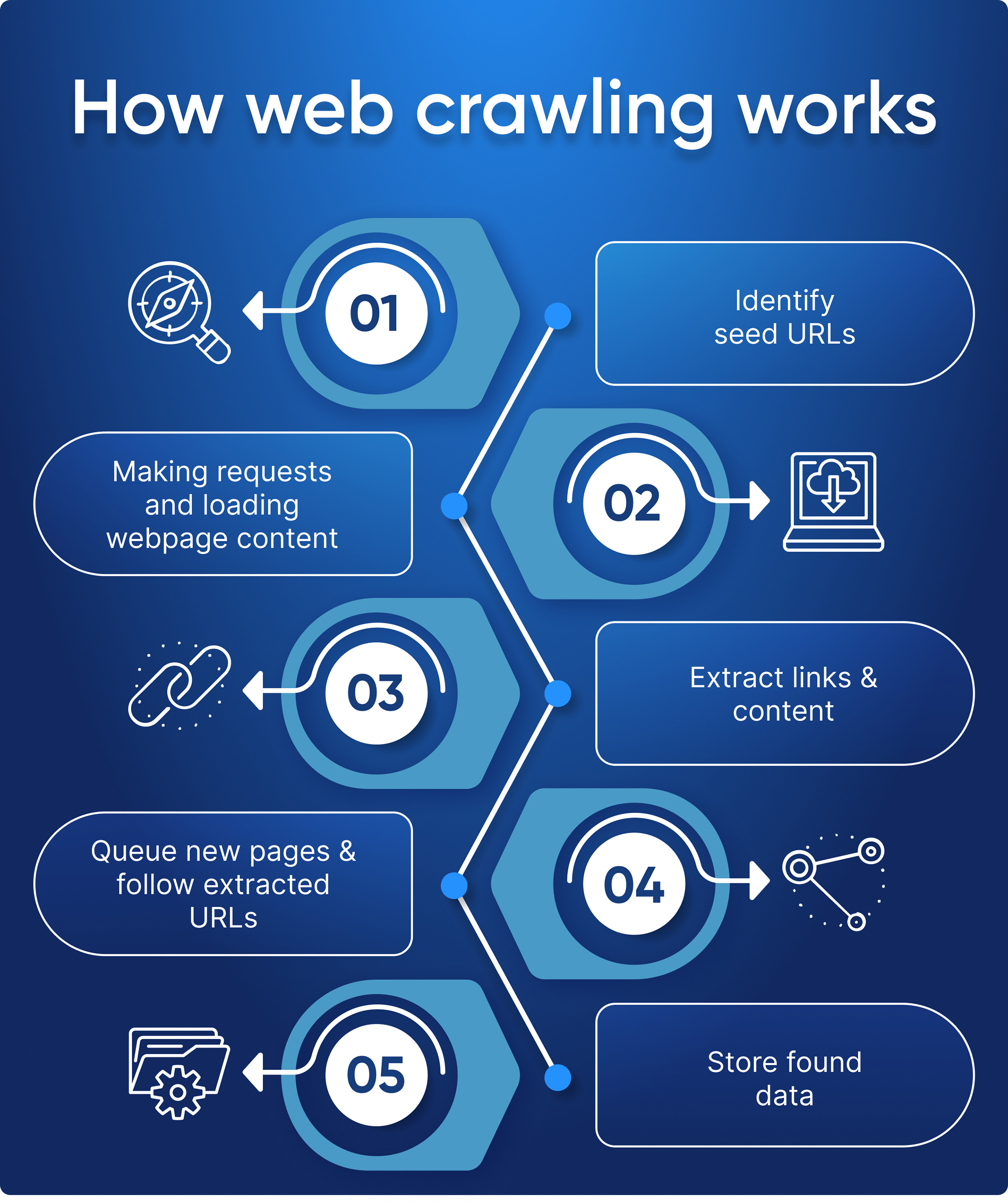
Berikut adalah proses langkah demi langkah yang menggambarkan cara kerja perayap web:
- Identifikasi URL awal: Di sinilah perayap web mulai mencari. URL awal adalah situs web pertama yang dipilih pengguna untuk dirayapi.
- Halaman Permintaan: Setelah daftar awal URL diidentifikasi, perayap mengirimkan permintaan HTTP untuk setiap halaman yang ditemukan di situs web ini untuk mengambil kontennya dan menganalisisnya lebih lanjut.
- Ekstrak tautan dan konten: Setelah perayap menerima dokumen HTML dari salah satu kuerinya, perayap mengekstrak semua tautan yang relevan dalam laman tersebut, serta konten relevan lainnya seperti gambar atau informasi berbasis teks (misalnya metadata).
- Antrean halaman baru dan ikuti URL yang diekstrak: Pada titik ini, link yang baru ditemukan dapat ditambahkan ke antrean prioritas jika belum dirayapi, atau dibuang jika sebelumnya sudah pernah dikunjungi oleh program lain - yang merupakan Penggunaan yang efisien memungkinkan eksplorasi tanpa perlu mengunjungi kembali area yang telah dieksplorasi sebelumnya! Selain itu, bergantung pada seberapa rumit algoritme perayapan, algoritme perayapan dapat memprioritaskan pola/kata kunci tertentu saat menentukan tautan mana yang akan digunakan selanjutnya berdasarkan hasil relevansi selama operasi analisis (yaitu teknik pembelajaran mesin seperti bahasa alami). sedang dalam proses).
- Simpan Data yang Ditemukan: Ketika semua sumber daya yang diperlukan telah dikumpulkan dan diantri dengan benar, kami akhirnya mencapai langkah terakhir yaitu menyimpan semua data yang dikumpulkan dan mengikuti instruksi.
Perayap web seperti turis yang antusias mengunjungi kota baru - ia memulai dengan beberapa URL awal (misalnya objek wisata utama kota tersebut) lalu mengikuti dan mengumpulkan semua tautan menarik yang ia temukan selama penjelajahannya sebanyak informasi mungkin. Pada titik tertentu, seperti yang harus dilakukan oleh teman turis kita pada suatu saat, ia akan menyimpan semua hasilnya dalam beberapa jenis database atau file untuk digunakan nanti.
Apa itu pengikisan web?
Di sisi lain, web scraping menunjukkan bahwa tautan ke situs web target sudah diketahui dan tidak perlu merayapi situs web untuk mengumpulkan tautan. Ini melibatkan penulisan atau penggunaan alat pengikis web yang mengumpulkan informasi seperti harga produk, gambar, informasi kontak, atau data lain untuk analisis atau pemrosesan lebih lanjut.
Beginilah cara kerja pengikisan web
Proses web scraping melibatkan pengiriman permintaan ke situs web target, mengekstraksi data dari HTML yang dikembalikan, dan kemudian memformat ulang menjadi informasi yang dapat digunakan.
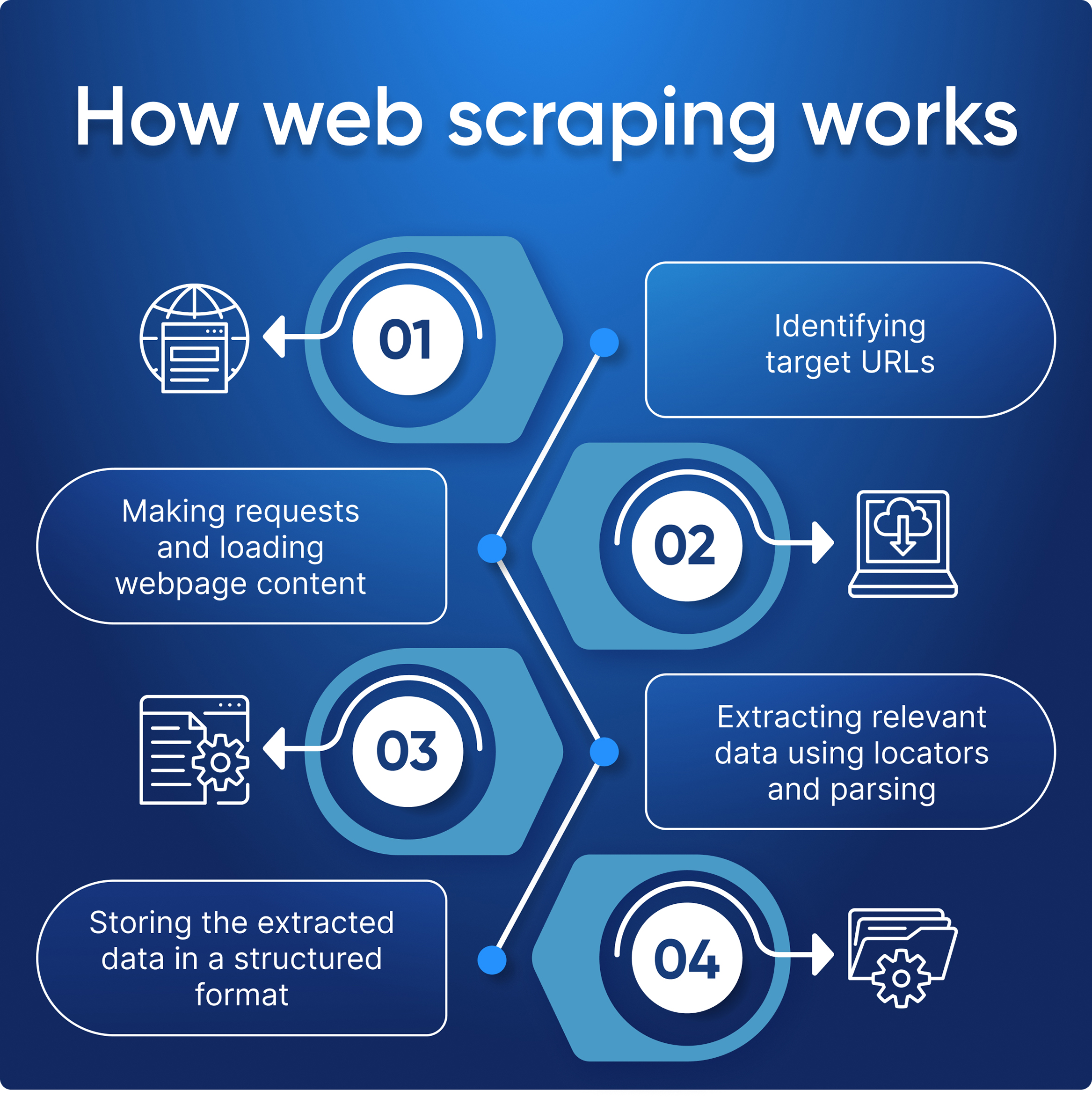
Berikut adalah proses langkah demi langkah yang menggambarkan cara kerja web scraping:
- Tentukan situs target dan strukturnya.
- Ambil tindakan untuk menghindari pemblokiran:
- Hubungkan proksi.
- Hubungkan layanan penyelesaian captcha.
- Siapkan header dan agen pengguna.
- Disarankan untuk menggunakan browser tanpa kepala.
- Scraper membuat permintaan dan menerima kode HTML-nya.
- Mengekstrak data dari halaman menggunakan pencari lokasi dan penguraian.
- Menyimpan data web dalam format yang mudah digunakan seperti JSON, Excel, atau CSV.
Beberapa link juga dapat digunakan untuk scraping, namun semuanya berasal dari situs web yang sama, artinya semua halaman memiliki struktur yang serupa.
Berbeda dengan “perayap turis” kami, web scraper seperti pembelanja yang cerdas. Mereka tahu persis apa yang mereka cari dan tidak membuang waktu menjelajahi seluruh toko. Mereka dengan cepat berpindah dari satu toko ke toko lainnya, meraih semua penawaran dan diskon yang tersedia di sana sebelum melanjutkan ke toko berikutnya.
Perbedaan Utama Antara Web Scraping dan Web Crawling
Seperti disebutkan sebelumnya, perayapan data untuk mengumpulkan tautan dan pengikisan data untuk mengumpulkan data. Biasanya keduanya digunakan bersama-sama: pertama crawler mengumpulkan tautan, kemudian scraper memprosesnya dan mengumpulkan data yang diperlukan.
Mari kita bandingkan perayapan web dan pengikisan web:
| kategori | Pengikisan web | Perayapan web |
|---|---|---|
| definisi | Mengekstraksi data dari situs web menggunakan perangkat lunak atau alat pengikis web yang menyimulasikan perilaku penjelajahan orang. | Proses otomatis menjelajahi Internet, mengindeks dan membuat katalog informasi, dan mengaturnya ke dalam database. |
| Tujuan | Ekstrak data spesifik dari halaman web untuk dianalisis dan digunakan | Jelajahi dan indeks situs web untuk mesin pencari dan analisis data |
| Metode ekstraksi data | Mengambil data dari struktur HTML situs web. | Merayapi halaman web dan mengikuti hyperlink untuk menemukan halaman baru untuk diindeks. |
| Cakupan | Terbatas pada situs web atau halaman tertentu. | Ini dapat mencakup lebih banyak situs web atau halaman. |
| Situs web yang ditargetkan | Umumnya ditargetkan pada situs web atau halaman tertentu. | Ini dapat mencakup berbagai situs web atau halaman. |
| Analisis data | Data dapat diekstraksi dalam format yang mudah dianalisis dan digunakan untuk berbagai tujuan, seperti perbandingan harga atau riset pasar. | Crawler tidak melakukan analisis data |
| Skalabilitas | Dilakukan baik dalam skala kecil maupun besar | Kebanyakan digunakan dalam skala besar |
| Persyaratan proses | Yang diperlukan untuk meminta dan mengambil halaman web hanyalah crawler | Memerlukan crawler untuk mengambil halaman web dan parser untuk mengekstrak data yang relevan dari halaman tersebut |
Jadi, perbedaan utama antara web crawling dan web scraping adalah web crawling secara otomatis mengunjungi setiap halaman yang dapat ditemukan, sedangkan web scraping berfokus pada penggalian data tertentu dari sebuah situs web. Perayap web menelusuri seluruh Internet dengan mengikuti tautan antar halaman, sedangkan pengikis web hanya menargetkan informasi yang terkait dengan kueri penelusuran mereka.
Gunakan kasus perayapan web dan pengikisan web
Pengikisan web dan pemindaian web adalah dua proses berbeda yang dapat digunakan bersama untuk menghasilkan efek yang signifikan. Namun, bergantung pada tugasnya, keduanya juga dapat digunakan secara independen.
Kasus penggunaan perayapan web
Perayapan web, seperti yang telah disebutkan, sangat bagus untuk proyek yang memerlukan pengumpulan tautan, mungkin tidak memiliki sumber daya yang ditargetkan, dan perlu mengambil seluruh kode halaman tanpa analisis dan pemrosesan lebih lanjut. Berikut adalah beberapa kasus penggunaan yang paling umum:
Pengindeksan mesin pencari
Mesin pencari seperti Google, Bing dan Yahoo menggunakan tim perayap mereka untuk menemukan konten yang baru diperbarui atau halaman baru. Para pencari kemudian menyimpan informasi yang mereka temukan dalam sebuah indeks, sebuah database besar yang berisi semua konten yang mereka anggap cukup baik untuk diberikan kepada pengguna.
Tingkatkan kinerja situs web Anda sendiri
Perayapan web adalah alat yang berharga untuk menganalisis situs web Anda dan meningkatkan kinerjanya. Dengan menjalankan perayap web, Anda dapat mendeteksi tautan atau gambar rusak, duplikat konten atau tag meta, dan masalah lain yang dapat berdampak negatif pada kinerja SEO situs web Anda. Perayapan web juga dapat membantu Anda mengidentifikasi peluang untuk mengoptimalkan struktur situs web secara keseluruhan.
Menganalisis situs web pesaing untuk tujuan SEO
Anda dapat memantau perubahan tidak hanya di situs web Anda tetapi juga di antara pesaing Anda. Hal ini memastikan bahwa Anda selalu mendapat informasi tentang perubahan baru dari pesaing Anda dan dapat bereaksi terhadapnya dengan sukses dan cepat.
Penambangan data
Perayap web dapat digunakan untuk mengumpulkan dan menganalisis data dalam jumlah besar dari berbagai sumber di Internet. Hal ini memudahkan peneliti, perusahaan, atau pihak berkepentingan lainnya untuk mendapatkan wawasan berharga mengenai topik tertentu dan membuat keputusan berdasarkan wawasan tersebut.
Temukan tautan rusak di situs web eksternal
Selain memeriksa halaman Anda, penting untuk selalu memperbarui semua link di halaman eksternal. Meskipun kesalahan pada laman Anda biasanya dapat ditemukan di area admin, menemukan tautan rusak ke situs web eksternal jauh lebih sulit. Untuk selalu memperbaruinya, Anda perlu memeriksanya secara manual atau menggunakan crawler.
Kurasi konten
Crawler juga bagus untuk menemukan topik terkait konten dengan cepat dan efisien, memungkinkan perusahaan atau individu untuk menyusunnya ke dalam koleksi berdasarkan kriteria tertentu, seperti kata kunci atau tag.
Kasus penggunaan untuk pengikisan web
Di sisi lain, web scraping sangat bagus jika Anda sudah mengetahui informasi spesifik apa yang ingin Anda ekstrak dari sebuah situs web. Beberapa kegunaan yang paling umum adalah:
- Pemantauan harga
- Agregasi konten
- Generasi pemimpin
- Analisis kompetitif
- Analisis media sosial
- Manajemen reputasi online
Untuk informasi lebih lanjut tentang web scraping dan kasus penggunaannya, lihat artikel kami yang menjelaskan beberapa penggunaan paling umum.
| Kasus penggunaan | Perayapan web | Pengikisan web |
|---|---|---|
| Pemantauan harga | ✔️ Dapat mengumpulkan harga dari berbagai situs web dan melacak perubahan seiring waktu | ✔️ Dapat mengekstrak harga dari situs web tertentu untuk dibandingkan dan dianalisis |
| Agregasi pekerjaan | ✔️ Dapat mengumpulkan tawaran pekerjaan dari berbagai situs web dan menyajikannya secara terpusat | ✔️ Dapat mengekstrak tawaran pekerjaan dari situs web tertentu dan menyajikannya secara terpusat |
| Agregasi konten | ✔️ Dapat mengumpulkan konten dari beberapa situs web untuk membuat repositori pusat | ❌ Tidak cocok karena memerlukan penggalian informasi spesifik dari setiap situs web |
| Optimasi SEO | ✔️ Dapat menganalisa struktur website dan backlink untuk optimasi mesin pencari | ❌ Tidak cocok karena memerlukan akses ke data website tertentu seperti kepadatan kata kunci dan metadata |
| Pemantauan berita | ✔️ Dapat memantau outlet berita dan RSS feed untuk pembaruan | ❌ Tidak cocok karena informasi spesifik perlu diambil dari setiap artikel berita |
| Agregasi ulasan produk | ✔️ Dapat mengumpulkan ulasan dari berbagai situs dan menganalisis sentimen | ✔️ Dapat mengekstrak ulasan dari situs web tertentu dan menganalisis sentimen |
| Penambangan data | ✔️ Dapat mengumpulkan data dalam jumlah besar untuk analisis dan pemodelan | ✔️ Dapat mengekstrak titik data tertentu untuk analisis dan pemodelan |
| Temukan tautan rusak di situs web eksternal | ✔️ Dapat merayapi situs web eksternal untuk mengidentifikasi tautan yang rusak | ❌ Tidak cocok karena memerlukan penggalian informasi spesifik dari setiap situs web |
| Generasi pemimpin | ✔️ Dapat mengumpulkan informasi kontak dari berbagai situs web | ✔️ Dapat mengekstrak informasi kontak dari situs web tertentu |
| Analisis kompetitif | ✔️ Dapat mengumpulkan data pada website kompetitor untuk dianalisis | ✔️ Dapat mengekstrak titik data spesifik di situs web pesaing untuk dianalisis |
| Manajemen reputasi online | ✔️ Dapat memantau penyebutan dan ulasan online untuk manajemen reputasi | ❌ Tidak cocok karena memerlukan penggalian informasi spesifik dari setiap situs web |
Tantangan dalam perayapan web dan pengikisan web
Terkait perayapan web dan pengikisan web, ada beberapa tantangan yang perlu dipertimbangkan. Tergantung pada ukuran proyek, masalah ini dapat berkisar dari masalah teknis sederhana seperti waktu pemuatan yang lambat atau permintaan yang diblokir (karena tindakan anti-scraping) hingga masalah hukum yang rumit seputar perlindungan data.
Blokir perayapan di robots.txt
Sebelum merayapi sumber daya, pastikan situs mengizinkannya. Jika file robots.txt menyatakan bahwa sumber daya melarang penggunaan data dari situs mana pun, Anda harus bersikap sopan dan mematuhi ketentuan.
pemblokiran IP
Saat merayapi, ingatlah bahwa seseorang tidak dapat mengeklik tautan setiap milidetik. Sumber daya Internet menganggap tindakan tersebut mencurigakan dan mungkin memblokir IP tempat tindakan tersebut dilakukan. Oleh karena itu, masuk akal untuk menjaga setidaknya jeda singkat antara permintaan dan menggunakan proxy yang menyembunyikan IP asli Anda. Namun, Anda juga tidak dapat menggunakan proxy yang sama tanpa batas waktu. Oleh karena itu, perayapan, seperti halnya scraping, mengharuskan Anda menggunakan beberapa proxy (kumpulan proxy) dan terus mengubahnya.
Untuk memastikan perayapan berhasil, Anda juga harus memeriksa pengaturan bot Anda. Tentukan header dan agen pengguna secara manual karena ini membantu situs mengenali bahwa pengguna sebenarnya sedang berinteraksi dengan situs. Ide yang bagus adalah menggunakan agen pengguna dan header yang sebenarnya, seperti header browser Anda.
CAPTCHA
Cobalah untuk menghindari captcha dengan mengikuti semua pedoman yang disebutkan di atas. Dan jika captcha tidak bisa dihindari, Anda bisa menggunakan layanan penyelesaian CAPTCHA.
Perangkap laba-laba
Beberapa sumber daya meninggalkan perangkap perayap yang disebut honeypots. Ini adalah tautan tersembunyi tambahan dalam kode yang tidak terlihat oleh pengguna normal di browser. Dan jika perayap mengikuti tautan ini, sumber daya akan mengenali bahwa itu adalah bot dan memblokirnya.
Merangkak
Kadang-kadang bot bisa terjebak dalam lingkaran tanpa akhir jika mereka tidak diprogram dengan benar atau merayapi terlalu keras dan memenuhi situs target dengan permintaan yang berlebihan - sehingga mengambil sumber daya dari pengguna lain yang mungkin mencoba mengaksesnya pada saat itu.
Praktik terbaik untuk perayapan web dan pengikisan web
Ada beberapa aturan yang harus diikuti saat melakukan crawling dan scraping untuk mempermudah perayapan bagi Anda dan situs web.
Bersikap sopan
Jika Anda memiliki opsi, jelajahi laman yang diizinkan sumber daya di robots.txt dan batasi frekuensi permintaan. Jika tidak, penggunaan sumber daya secara berlebihan dapat menyebabkan responsnya sangat lambat terhadap semua pengguna atau bahkan gagal.
Merangkak selama waktu penggunaan rendah
Mereka juga harus melakukan crawling ketika permintaan sumber daya lebih rendah, seperti pada malam hari. Dengan cara ini Anda mendapatkan data yang Anda perlukan dan menyebabkan kerusakan paling sedikit pada sumber daya.
Gunakan strategi cache
Menerapkan strategi caching untuk mengurangi jumlah permintaan yang dibuat pada setiap halaman dan menyimpan data yang dirayapi sebelumnya untuk titik referensi di masa mendatang ketika memutuskan konten apa yang akan dikikis selanjutnya.
Kesimpulan dan temuan
Pengikisan web dan perayapan web adalah alat penting untuk mengumpulkan data dari web. Pengikisan web digunakan untuk mengekstrak data dari situs web dan dapat dilakukan secara manual atau melalui skrip otomatis. Perayapan web melibatkan penggunaan bot untuk menjelajahi situs web, mengumpulkan informasi, dan mengindeks konten untuk mesin pencari.
Mari kita lihat beberapa tips memilih pendekatan yang sesuai dengan kebutuhan proyek atau bisnis Anda:
- Tentukan tujuannya: Langkah pertama adalah memahami mengapa Anda ingin mengumpulkan data melalui web scraping atau crawling. Ini akan membantu Anda memilih metode yang tepat yang sesuai dengan kebutuhan bisnis Anda.
- Identifikasi data: Anda harus mengidentifikasi jenis data yang Anda perlukan dan lokasinya. Ini akan membantu Anda menentukan apakah web scraping atau crawling adalah metode terbaik untuk pengambilan data.
- Analisis kompleksitas data: Penting untuk menilai kompleksitas data yang ingin Anda kumpulkan. Jika kumpulan datanya rumit, perayapan web mungkin lebih cocok karena dapat mengumpulkan lebih banyak data secara efisien dalam waktu yang lebih singkat.
- Pertimbangkan frekuensi penyegaran data: Jika data yang Anda perlukan sering diperbarui, perayapan web mungkin merupakan pilihan yang lebih baik karena dapat diotomatisasi untuk menjaga data tetap mutakhir.
Kedua metode ini penting untuk mengekstraksi data dari Internet, namun teknik mana yang terbaik untuk Anda bergantung pada kebutuhan Anda.