Di bawah Pengikisan web adalah ekstraksi otomatis informasi dari situs web. Ini adalah teknik canggih yang memungkinkan pengembang mengumpulkan data dari situs web dengan cepat dan mudah tanpa harus memasukkan atau mengunduhnya secara manual. Pengikisan web dapat digunakan untuk berbagai tujuan, seperti melacak harga produk, mengumpulkan informasi kontak, atau menganalisis tren di situs media sosial.
Salah satu bahasa pemrograman paling populer untuk web scraping adalah Ruby karena open source, fleksibilitas, dan kemudahan penggunaannya. Kita telah membahas web scraping dengan Python, C#, NodeJS dan R, namun pada artikel ini kita akan melihat Ruby. Dengan Ruby, Anda dapat menulis skrip kompleks yang mengotomatiskan seluruh proses pengumpulan data - mulai dari mengakses halaman situs web hingga menguraikan informasi yang relevan (seperti alamat email). Ruby juga memiliki berbagai perpustakaan tambahan yang dirancang khusus untuk tujuan web scraping. Di Github Anda akan menemukan banyak perpustakaan untuk dipilih. Namun, dalam artikel ini kami hanya akan fokus pada yang paling luas dan terkenal.
Daftar Isi
Mempersiapkan web scraping dengan Ruby
Sebelum kita mulai membuat web scraper berbasis Ruby, kita perlu mempersiapkan lingkungan, mempertimbangkan dan menginstal perpustakaan yang diperlukan. Pertama persiapkan lingkungan dan instal Ruby. Kami kemudian melihat perpustakaan dan menginstalnya.
Instal lingkungan
Website resmi Ruby menyediakan perintah untuk menginstal Ruby di semua sistem operasi utama, baik itu Debian, CentOS, Snap, MacOS, OpenBSD, Windows atau lainnya. Kami mencatat bahwa ada juga build untuk Windows yang menyertakan Ruby dan paket dasar. Opsi ini cocok bagi mereka yang ingin menyederhanakan instalasi Ruby mereka. Jika Anda memutuskan untuk menggunakan penginstal, jangan lupa untuk mencentang kotak di tempat yang diperlukan selama instalasi:

Hal ini diperlukan agar komputer mengetahui di mana lokasi executable dan dapat mengaitkan semua file berekstensi *.rb dan *.rbw dengan Ruby.
Setelah Anda menginstal Ruby, Anda dapat memeriksa apakah semuanya berjalan baik dengan menjalankan perintah berikut pada baris perintah:
ruby -vIni akan mengembalikan baris dengan versi Ruby:
ruby 3.2.2 (2023-03-30 revision e51014f9c0) (x64-mingw-ucrt)Sekarang putuskan di mana Anda ingin menulis kode. Sebenarnya hal ini tidak terlalu penting. Anda dapat menjalankan file kode dari baris perintah dan bahkan menulis kode di Notepad. Namun, lebih baik menggunakan alat khusus untuk ini yang menyorot sintaks dan memberi tahu Anda di mana letak kesalahannya. Untuk keperluan ini Anda bisa menggunakan Sublime, Visual Code atau yang lainnya.
Menginstal perpustakaan
Ketika bagian ini selesai, Anda dapat mulai menginstal perpustakaan. Dalam tutorial ini kita akan melihat perpustakaan berikut:
- pesta HTTP. Pustaka kueri berfitur lengkap yang memungkinkan Anda melakukan kueri GET, POST, PUT, dan DELETE. Meskipun tidak dirancang khusus untuk web scraping, ini dapat berguna untuk mengambil data dari situs web dan API.
- Bersih::HTTP. Pustaka lain yang memungkinkan Anda menjalankan dan memproses kueri.
- Nokogiri. Ini adalah perpustakaan lengkap untuk parsing dan pemrosesan dokumen XML dan HTML. Itu tidak bisa menjalankan kueri, tapi bagus untuk memproses data keluaran. Keuntungan utamanya adalah kemampuan untuk bekerja dengan pemilih CSS, tetapi tidak dengan XPath.
- Mekanisasi. Ini adalah perpustakaan terpopuler kedua yang digunakan untuk web scraping Ruby. Berbeda dengan Nokogiri, ia menawarkan kemampuan untuk meminta data sendiri.
- Watir. Ini adalah kerangka pengujian aplikasi web yang juga dapat digunakan untuk web scraping. Ini memungkinkan Anda untuk mengotomatiskan interaksi dengan halaman web dengan cara yang mirip dengan Mekanisasi. Namun, browser tanpa kepala juga bisa digunakan.
Selain yang disebutkan sebelumnya, masih banyak permata Ruby lainnya untuk web scraping, seperti PhantomJS, Capybara atau Kimurai Gemfile. Namun, perpustakaan yang disarankan di atas lebih populer dan terdokumentasi dengan lebih baik, jadi kami akan fokus pada perpustakaan tersebut di artikel ini.
Untuk menginstal paket di Ruby, gunakan Instal permata Memerintah:
gem install httparty
gem install nokogiri
gem install mechanize
gem install watirNet::HTTP tidak perlu diinstal karena sudah diinstal sebelumnya. Anda dapat menggunakan Ruby Gem untuk memeriksa ini:
Analisis halaman
Sebagai contoh, mari kita ambil situs pengujian dengan buku-buku yang bisa kita cari. Pertama, mari kita buka halamannya dan lihat kode HTMLnya. Untuk membuka kode halaman HTML, buka DevTools (tekan F12 atau klik kanan pada ruang kosong di halaman dan buka Inspect).
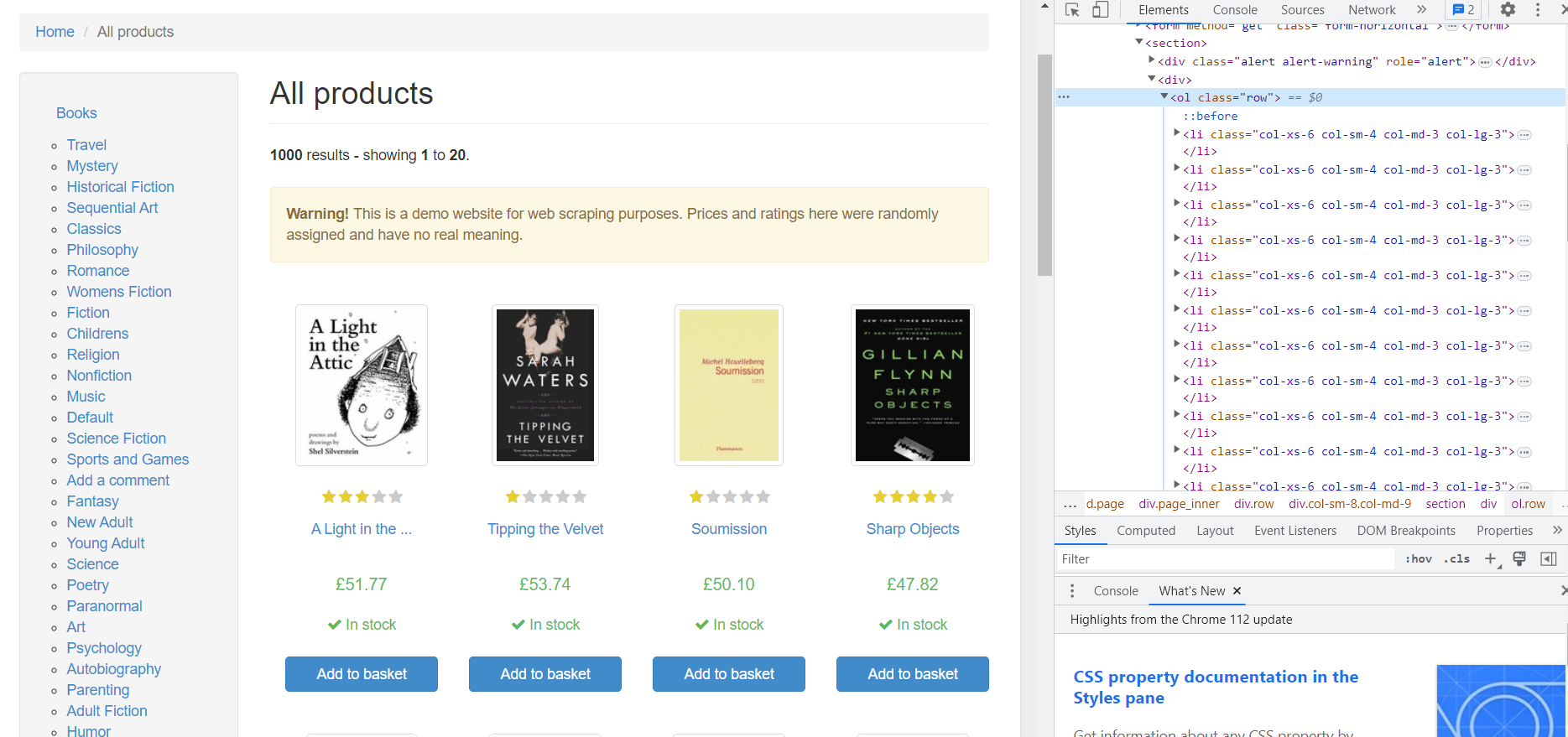
Semua produk di situs ada di
- -Tag dengan kelas "baris" dan setiap produk di sub-tag
- ditempatkan. Mari kita lihat lebih dekat salah satu produknya:

Berdasarkan kode HTML tersebut, kita dapat memperoleh data sebagai berikut:
- Tautan gambar. Terletak di tag dan merupakan konten dari atribut “href”.
- Evaluasi. Ada dua kelas di dalamnya
-Tag: peringkat bintang dan peringkat buku. Dalam contoh kita, rating buku adalah 3.
- Judul. Judul buku sudah masuk -Hari. Namun, itu tidak sepenuhnya ditentukan dalam tag. Judul lengkap ada pada atribut “title”.
- Harga. Di sini kita hanya perlu kontennya saja
-Dapatkan tag dengan kelas “harga_produk”.
- Ketersediaan. Di sini Anda harus memperhatikan kelas. Kelas “icon-ok” digunakan untuk buku yang tersedia.
Sekarang setelah Anda menginstal semua komponen yang diperlukan, saatnya mulai membuat scraper Anda. Dengan Ruby dan alat yang tepat, mengambil data dari situs web menjadi relatif mudah.
Buat pengikis web
Buat file *.rb baru, misalnya “scraper.rb” dan buka. Dalam file ini kita akan menulis kode untuk mengikis data menggunakan Ruby. Pertama, mari kita lihat masing-masing perpustakaan yang terinstal satu per satu untuk melihat bagaimana mereka dapat membantu kita mengambil informasi dari situs web atau sumber lain.
Buat permintaan HTTP dengan HTTParty
Perpustakaan pertama dalam daftar kami adalah perpustakaan HTTParty. Itu tidak memungkinkan Anda memproses atau menganalisis data, namun memungkinkan Anda menjalankan kueri. Mari kita hubungkan:
require "httparty"Mari jalankan kueri dan dapatkan kode halaman books.toscrape.com:
response = HTTParty.get("https://books.toscrape.com/catalogue/page-1.html")Untuk melihat hasilnya, Anda dapat menggunakannya menempatkan() Memerintah:
puts(response)Hasilnya, kami mendapatkan kode HTML halaman tersebut:
D:\scripts\ruby>ruby scraper.rb <!DOCTYPE html> <!--(if lt IE 7)> <html lang="en-us" class="no-js lt-ie9 lt-ie8 lt-ie7"> <!(endif)--> <!--(if IE 7)> <html lang="en-us" class="no-js lt-ie9 lt-ie8"> <!(endif)--> <!--(if IE 8)> <html lang="en-us" class="no-js lt-ie9"> <!(endif)--> <!--(if gt IE 8)><!--> <html lang="en-us" class="no-js"> <!--<!(endif)--> <head> <title> Semua produk | Buku untuk Dikikis - Kotak Pasir ... </title> </head> </html>Sayangnya, banyak situs web yang mencoba menolak akses scraper ke data mereka. Untuk menyamarkan scraper Anda agar tidak mengakses data, ada beberapa metode yang dapat Anda gunakan: menggunakan proxy dan API web scraping; mengatur penundaan acak antar permintaan; Menggunakan browser tanpa kepala. Penting juga untuk menyertakan agen pengguna dalam setiap permintaan yang dikirim. Hal ini meningkatkan kemungkinan scraper Anda terhindar dari pemblokiran.
response = HTTParty.get("https://books.toscrape.com/catalogue/page-1.html", { headers: { "User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36" }, })Ingatlah bahwa lebih baik menggunakan agen pengguna yang sebenarnya.
Mengikis data dengan HTTParty dan Web Scraping API
Seperti yang telah disebutkan, perpustakaan HTTParty dirancang hanya untuk mengirim permintaan. Namun, kita dapat menggunakan web scraping API untuk memproses data. Untuk melakukan ini kami memerlukan kunci API, yang akan Anda terima setelah mendaftar dengan Scrape-It.Cloud. Kami juga membutuhkan perpustakaan tambahan:
gem install jsonHubungkan perpustakaan ini di file kami:
require "json"Sekarang mari kita buat permintaan ke API. Kami perlu memberikan beberapa informasi yang mengungkapkan apa yang kami cari. Hal ini termasuk menentukan header permintaan (misalnya tipe data apa yang kami inginkan dan kunci API Anda) dan isi (konten sebenarnya dari permintaan kami):
url = "https://api.scrape-it.cloud/scrape" headers = { "x-api-key" => "YOUR-API-KEY", "Content-Type" => "application/json" } payload = { extract_rules: { title: "h3>a @title", price: "div.product_price>p.price_color", image: "div.image_container>a @href", rating: "p.star-rating @class", available: "p.availability>i @class" }, wait: 0, screenshot: true, block_resources: false, url: "https://books.toscrape.com/catalogue/page-1.html" }.to_jsonKemudian kami menjalankan kueri:
response = HTTParty.post(url, headers: headers, body: payload) parsed_page = JSON.parse(response.body)Sekarang kita dapat mereferensikan atribut respons JSON yang dikembalikan kepada kita oleh Scrape-It.Cloud API, yang berisi data yang diperlukan:
parsed_page = JSON.parse(response.body) extracted_data = parsed_page("scrapingResult")("extractedData")Sekarang kita sudah memiliki datanya, mari kita simpan dalam file CSV.
Simpan data dalam format CSV
Mari kita mulai dengan menginstal perpustakaan CSV:
gem install csvKaitkan perpustakaan dengan file:
require "csv"Untuk menyimpan data ke file, kita perlu membukanya dengan pengaturan yang benar. Kami menggunakan “w” – jika file belum ada, ini akan membuatkan file untuk kami. Jika ada, konten apa pun yang ada akan ditimpa. Kita juga dapat menentukan karakter mana yang memisahkan masing-masing informasi - kita menggunakan titik koma (;):
CSV.open("data.csv", "w", col_sep: ";") do |csv| … endMari kita atur judul kolom:
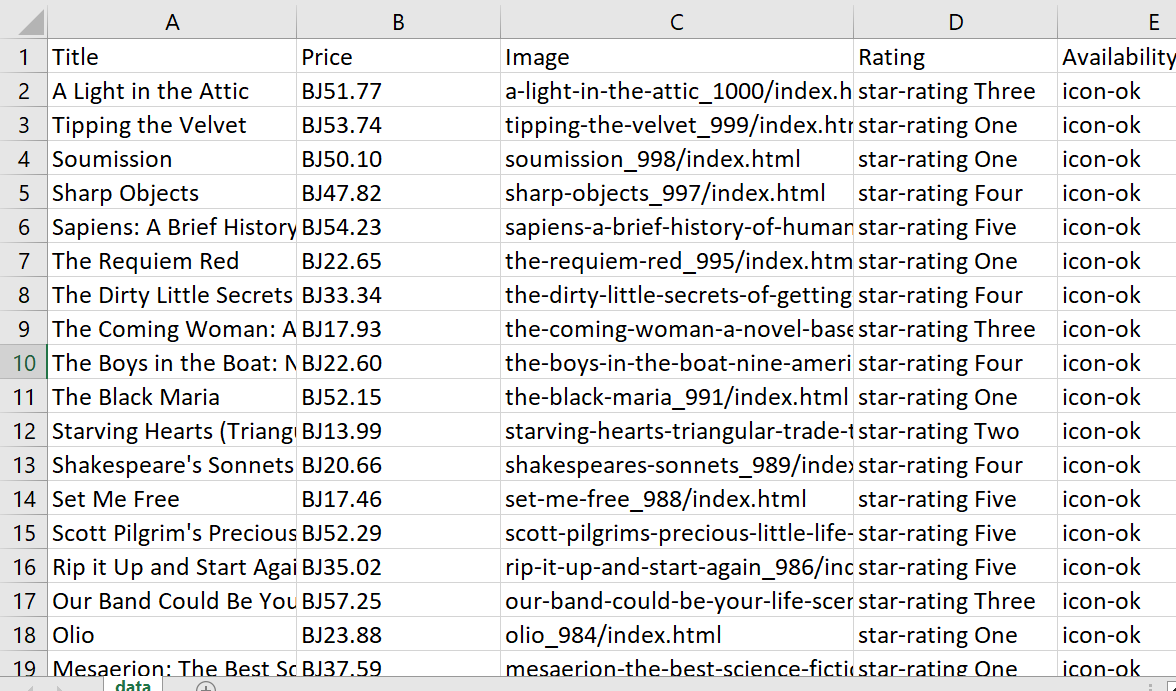
csv << ("Title", "Price", "Image", "Rating", "Availability")Terakhir, mari kita telusuri semua array yang kita terima baris demi baris dan menulis datanya ke file:
(extracted_data("title"), extracted_data("price"), extracted_data("image"), extracted_data("rating"), extracted_data("available")).transpose.each do |row| csv << row endHasilnya, kami mendapatkan tabel berikut:
Kelihatannya bagus, tapi kita bisa membuatnya lebih baik lagi dengan membersihkan data. Untungnya, hal ini mudah dilakukan dengan fitur bawaan Ruby. Kita bisa memulai dengan simbol pound (£) pada harga, yang muncul sebagai “BJ” saat disimpan ke file:
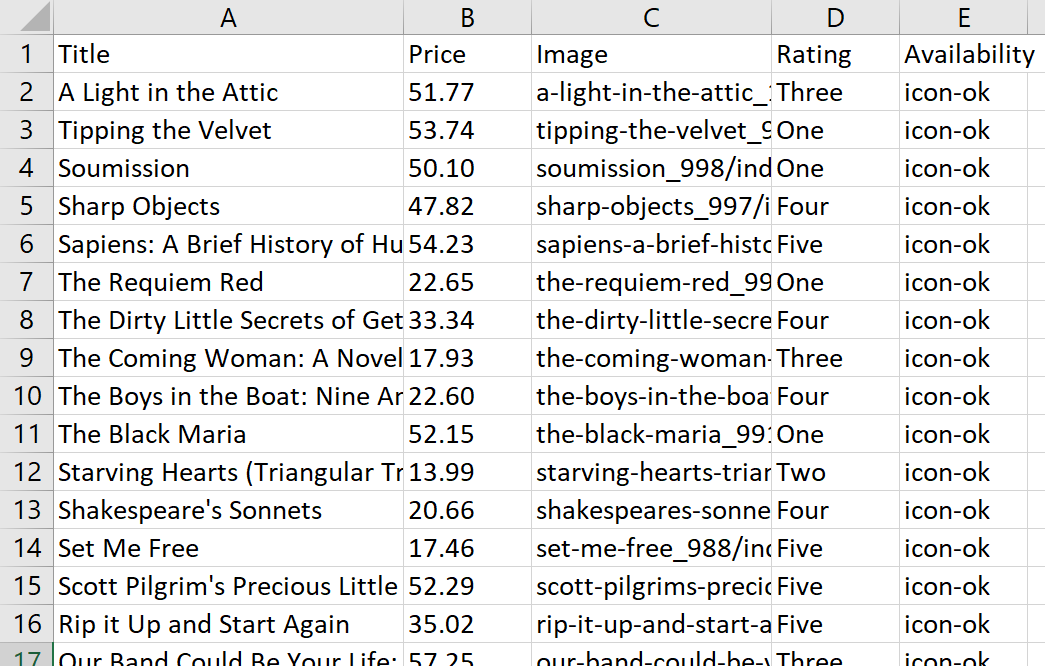
extracted_data("price") = extracted_data("price").map { |price| price.gsub("£", "") }Di kolom “Rating” kami memiliki dua kelas yang berbeda. Kita hanya membutuhkan yang kedua, jadi kita selesaikan masalah ini menggunakan metode split(). Ini mengambil string kita dan membaginya menjadi array string berdasarkan pola atau karakter tertentu:
extracted_data("rating") = extracted_data("rating").map { |rating| rating.split(" ").last }Sekarang mari kita jalankan query lagi dan lihat tabelnya:
Sekarang hasilnya terlihat lebih baik dan akan lebih mudah untuk diedit di kemudian hari.
Kode yang dihasilkan:
require "httparty" require "json" require "csv" url = "https://api.scrape-it.cloud/scrape" headers = { "x-api-key" => "YOUR-API-KEY", "Content-Type" => "application/json" } payload = { extract_rules: { title: "h3>a @title", price: "div.product_price>p.price_color", image: "div.image_container>a @href", rating: "p.star-rating @class", available: "p.availability>i @class" }, wait: 0, screenshot: true, block_resources: false, url: "https://books.toscrape.com/catalogue/page-1.html" }.to_json response = HTTParty.post(url, headers: headers, body: payload) parsed_response = JSON.parse(response.body) extracted_data = parsed_response("scrapingResult")("extractedData") # Remove pound symbol (£) from price values extracted_data("price") = extracted_data("price").map { |price| price.gsub("£", "") } # Extract only the second word from the rating values extracted_data("rating") = extracted_data("rating").map { |rating| rating.split(" ").last } CSV.open("data.csv", "w", col_sep: ";") do |csv| csv << ("Title", "Price", "Image", "Rating", "Availability") (extracted_data("title"), extracted_data("price"), extracted_data("image"), extracted_data("rating"), extracted_data("available")).transpose.each do |row| csv << row end end puts "Data saved to data.csv"Sekarang kita telah melihat perpustakaan HTTParty, mari kita lihat apa yang akan terlihat jika kita menggunakan Net::HTTP sebagai gantinya. Kita akan dapat memahami apa yang membuat perpustakaan ini unik dan mencari tahu mana yang terbaik untuk kebutuhan scraping kita.
Buat permintaan menggunakan NET::HTTP
Pustaka Net::HTTP yang disediakan oleh permata net-http dapat digunakan bersama dengan permata open-uri untuk fungsionalitas tambahan. Net::HTTP menyediakan akses ke protokol HTTP yang mendasarinya, sementara open-uri membuat permintaan data dari server jarak jauh menjadi lebih mudah dan efisien. Bersama-sama, mereka menyediakan cara yang efektif untuk mengambil informasi dari situs web dengan cepat.
Pertama, mari kita sambungkan perpustakaan:
require "uri" require "net/http"Kemudian kita perlu mengurai string URL menjadi objek Uniform Resource Identifier (URI):
url = URI.parse("https://books.toscrape.com/catalogue/page-1.html")Ini membantu memecah URL menjadi beberapa bagian komponennya, memungkinkan akses mudah dan pengeditan berbagai komponen sesuai kebutuhan. Dan akhirnya kita bisa menjalankan query dan menampilkannya ke baris perintah:
request = Net::HTTP.get_response(url) puts request.bodyIni memungkinkan Anda membuat permintaan “GET” sederhana untuk mengambil data dari web menggunakan perpustakaan Net::HTTP. Ini bisa menjadi cara terbaik untuk mengakses dan mengekstrak data dengan cepat dari situs web mana pun.
Mengikis data menggunakan Net::HTTP dan Web Scraping API
Untuk tugas ini kami menggunakan API Scrape-It.Cloud. Pertama kita perlu menentukan titik akhir API untuk mengirim permintaan kita. Kita juga perlu menentukan header dan isi permintaan POST. Pada dasarnya ini berarti kami menyediakan API dengan detail tentang apa yang ingin kami evaluasi. Kita perlu memberikan URL halaman yang ingin kita cari dan memberitahukan konten apa yang ingin kita ekstrak:
url = URI("https://api.scrape-it.cloud/scrape") https = Net::HTTP.new(url.host, url.port) https.use_ssl = true request = Net::HTTP::Post.new(url) request("x-api-key") = "YOUR-API-KEY" request("Content-Type") = "application/json" request.body = JSON.dump({ "extract_rules": { "title": "h3>a @title", "price": "div.product_price>p.price_color", "image": "div.image_container>a @href", "rating": "p.star-rating @class", "available": "p.availability>i @class" }, "wait": 0, "screenshot": true, "block_resources": false, "url": "https://books.toscrape.com/catalogue/page-1.html" })Kemudian jalankan kueri dan tampilkan data di layar:
response = https.request(request) puts response.bodySeperti yang bisa kita lihat, kegunaan perpustakaan ini tidak jauh berbeda dengan yang kita bahas sebelumnya. Jadi mari kita gunakan kode yang sama seperti contoh sebelumnya dan simpan datanya dalam format CSV. Untuk menghindari banyak pengulangan, kami menampilkan versi lengkap dari skrip yang sudah selesai:
require "uri" require "json" require "net/http" require "csv" url = URI("https://api.scrape-it.cloud/scrape") https = Net::HTTP.new(url.host, url.port) https.use_ssl = true request = Net::HTTP::Post.new(url) request("x-api-key") = "YOUR-API-KEY" request("Content-Type") = "application/json" request.body = JSON.dump({ "extract_rules": { "title": "h3>a @title", "price": "div.product_price>p.price_color", "image": "div.image_container>a @href", "rating": "p.star-rating @class", "available": "p.availability>i @class" }, "wait": 0, "screenshot": true, "block_resources": false, "url": "https://books.toscrape.com/catalogue/page-1.html" }) response = https.request(request) parsed_response = JSON.parse(response.body) extracted_data = parsed_response("scrapingResult")("extractedData") extracted_data("price") = extracted_data("price").map { |price| price.gsub("£", "") } extracted_data("rating") = extracted_data("rating").map { |rating| rating.split(" ").last } CSV.open("data.csv", "w", col_sep: ";") do |csv| csv << ("Title", "Price", "Image", "Rating", "Availability") (extracted_data("title"), extracted_data("price"), extracted_data("image"), extracted_data("rating"), extracted_data("available")).transpose.each do |row| csv << row end end puts "Data saved to data.csv"Sekarang kita telah melihat pustaka kueri, mari beralih menjelajahi pustaka yang menyediakan kemampuan pemrosesan data. Pustaka ini memungkinkan kami mengubah dan memanipulasi data yang kami kumpulkan dengan cara yang bermakna.
Analisis data menggunakan Nokogiri
Nokogiri adalah perpustakaan yang sangat berguna untuk memproses dan mengurai data. Mudah digunakan dan sangat populer di kalangan pengembang Ruby. Ini memberikan cara efektif untuk bekerja dengan dokumen HTML dan XML dan membuat pengikisan data menjadi cepat dan mudah.
Sayangnya, Nokogiri bukanlah perpustakaan scraping yang berdiri sendiri dan tidak memiliki kemampuan untuk mengirim permintaan. Selain itu, ini bagus untuk mengambil data dari halaman statis, tetapi Anda tidak dapat menggunakannya untuk menanyakan dan memproses data dari halaman dinamis. Pada contoh sebelumnya, kami memecahkan masalah ini menggunakan web scraping API. Dengan Nokogiri, semua masalah ini harus diselesaikan sendiri oleh pengembang.
Namun, jika Anda hanya perlu mengekstrak data dari halaman statis, tidak perlu melakukan tindakan apa pun pada halaman tersebut (misalnya, melakukan otorisasi) dan memerlukan perpustakaan sederhana, maka Nokogiri adalah yang Anda butuhkan.
Untuk menggunakannya kita memerlukan perpustakaan kueri. Di sini kami menggunakan HTTParty, tetapi Anda dapat menggunakan perpustakaan apa pun yang sesuai dengan kebutuhan Anda. Pertama, mari hubungkan kedua perpustakaan dan dapatkan semua kode halaman kita:
require 'httparty' require 'nokogiri' headers = { 'User-Agent' => 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36' } url = https://books.toscrape.com/catalogue/page-1.html" response = HTTParty.get(url, headers: headers)Sekarang berikan kode yang Anda terima ke objek Nokogiri. Kemudian struktur halaman dianalisis dan Anda dapat mengakses berbagai elemen di halaman ini dengan lebih mudah:
doc = Nokogiri::HTML(response.body)Sekarang kita bisa mendapatkan data yang diperlukan dari halaman menggunakan pemilih CSS:
titles = doc.css('h3 > a').map { |element| element('title') } prices = doc.css('div.product_price > p.price_color').map { |element| element.text.gsub("£", "") } images = doc.css('div.image_container > a').map { |element| element('href') } ratings = doc.css('p.star-rating').map { |element| element('class').split(' ').last } availabilities = doc.css('p.availability > i').map { |element| element('class').split('-').last }Kami telah menyempurnakan informasi yang kami miliki dengan menggunakan taktik untuk mengatasi masalah yang kami temui sebelumnya. Untuk memulai, kita memiliki fungsi yang disebut { |elemen| menggunakan elemen('Attributes') }, yang menggantikan "atribut" dengan nama atribut yang isinya ingin Anda akses. Hal ini memungkinkan kita untuk mendapatkan konten atribut setiap elemen, bukan teks.
Kami kemudian menggunakan perintah gsub(“£”, “”) untuk membersihkan setiap elemen dalam array harga. Kita perlu menghilangkan tanda nomor tersebut karena tidak muncul dengan benar saat menyimpan data ke file. Terakhir, kami menggunakan split(“”) untuk memisahkan susunan peringkat dan ketersediaan menjadi dua bagian. Kami kemudian menggunakan .last untuk setiap array, hanya menyisakan bagian kedua.
Seperti yang bisa kita lihat, penggunaan Nokogiri cukup sederhana dan tidak akan menimbulkan kesulitan bahkan bagi pemula sekalipun.
Menggaruk beberapa halaman
Sekarang setelah kita mengetahui cara mengekstrak data dari satu halaman, mari gunakan data tersebut untuk mengumpulkan informasi dari setiap halaman situs web. Terakhir, pembuatan scraper biasanya tidak hanya untuk satu situs; Mereka sering digunakan untuk mencari seluruh situs web atau toko online.
Sayangnya Nokogiri tidak mengizinkan kita untuk berpindah ke halaman berikutnya dengan menekan tombol tersebut. Namun, kami dapat mengidentifikasi pola pembuatan tautan di situs dan menyarankan seperti apa tampilan halaman berikutnya.
Perhatikan baik-baik tautan halaman:
https://books.toscrape.com/catalogue/page-1.html https://books.toscrape.com/catalogue/page-2.html ... https://books.toscrape.com/catalogue/page-50.htmlSeperti yang bisa kita lihat, pada halaman contoh ini hanya nomor halamannya saja yang berubah. Totalnya ada 50 halaman. Mari tambahkan bagian awal yang tidak diubah ke variabel base_url:
base_url="https://books.toscrape.com/catalogue/page-"Selain itu, kami memiliki agen pengguna yang konstan untuk semua permintaan:
headers = { 'User-Agent' => 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36' }Terakhir, kita perlu mengatur jumlah halaman dan variabel dimana data semua halaman akan disimpan:
total_pages = 50 data = ()Sebenarnya, kita bisa membawa scraper kita ke tingkat berikutnya dan tidak perlu menentukan secara manual berapa banyak halaman yang ada. Sebagai gantinya, kita dapat menggunakan kode yang mendapatkan jumlah halaman dari halaman itu sendiri atau mengulang hingga terjadi kesalahan 404 Not Found. Namun, dalam kasus ini, kerumitan kode seperti itu tidak diperlukan, karena tautan memiliki struktur yang jelas dan mudah diprediksi.
Sekarang mari kita buat loop untuk menelusuri setiap halaman dan menghasilkan link yang sesuai. Jumlah iterasi dalam perulangan sesuai dengan nomor halaman. Misalnya, pada lintasan pertama melalui perulangan kita membuat tautan untuk halaman pertama; pada iterasi kedua – halaman kedua; Dan seterusnya:
(1..total_pages).each do |page| url = "#{base_url}#{page}.html" response = HTTParty.get(url, headers: headers) doc = Nokogiri::HTML(response.body) endPemilih CSS dan variabel yang dapat diambil tetap tidak berubah. Jadi mari kita mulai memasukkan data ke dalam hash:
page_data = titles.zip(prices, images, ratings, availabilities).map do |title, price, image, rating, availability| { title: title, price: price, image: image, rating: rating, availability: availability } endTerakhir, kami menambahkan data di bagian akhir Data Variabel yang kita buat di awal:
data.concat(page_data)Disarankan juga untuk menambahkan penundaan acak untuk meningkatkan kemungkinan melewati blok:
sleep(rand(1..3))Setelah menjalankan siklus, simpan data ke file CSV:
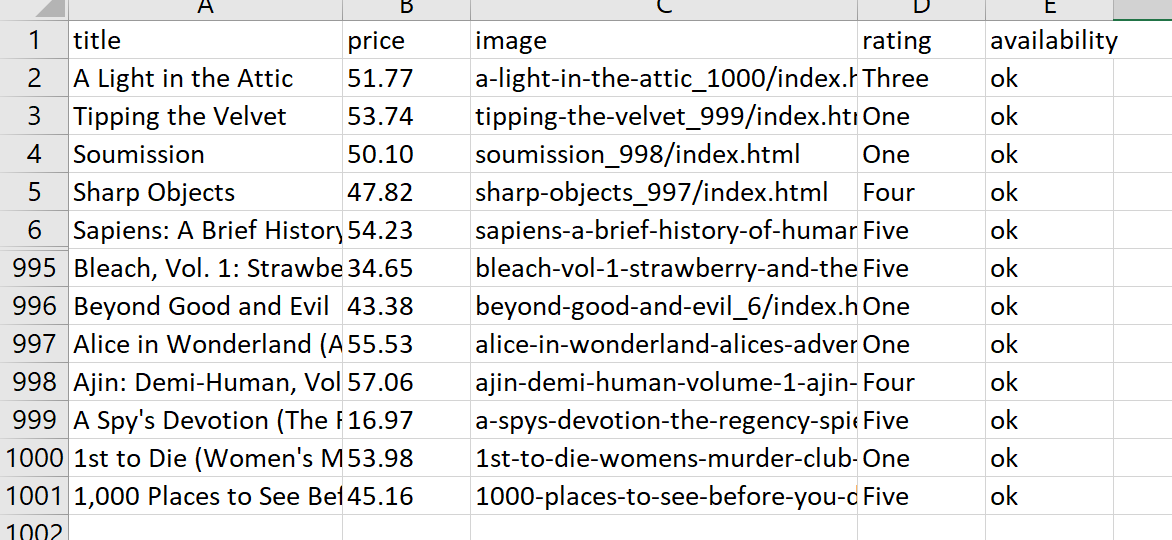
CSV.open('book_data.csv', 'w', col_sep: ";") do |csv| csv << data.first.keys # Write the headers data.each { |hash| csv << hash.values } # Write the data rows endHasilnya, skrip kami melewati semua halaman, mengumpulkan data, dan memasukkannya ke dalam file CSV:
Kode lengkap:
require 'httparty' require 'nokogiri' require 'csv' base_url="https://books.toscrape.com/catalogue/page-" headers = { 'User-Agent' => 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36' } total_pages = 50 data = () (1..total_pages).each do |page| url = "#{base_url}#{page}.html" response = HTTParty.get(url, headers: headers) doc = Nokogiri::HTML(response.body) # Extracting data titles = doc.css('h3 > a').map { |element| element('title') } prices = doc.css('div.product_price > p.price_color').map { |element| element.text.gsub("£", "") } images = doc.css('div.image_container > a').map { |element| element('href') } ratings = doc.css('p.star-rating').map { |element| element('class').split(' ').last } availabilities = doc.css('p.availability > i').map { |element| element('class').split('-').last } # Combine the extracted data into an array of hashes page_data = titles.zip(prices, images, ratings, availabilities).map do |title, price, image, rating, availability| { title: title, price: price, image: image, rating: rating, availability: availability } end data.concat(page_data) sleep(rand(1..3)) end # Save the data to a CSV file CSV.open('book_data.csv', 'w', col_sep: ";") do |csv| csv << data.first.keys # Write the headers data.each { |hash| csv << hash.values } # Write the data rows end puts 'Data saved to book_data.csv'Seperti yang bisa kita lihat, bahkan kemampuan perpustakaan Nokogiri cukup untuk menggores situs web.
Pengikisan web dengan Mekanisasi
Mechanize adalah perpustakaan lengkap untuk web scraping. Ini berarti Anda tidak memerlukan perpustakaan tambahan apa pun - semua alat yang diperlukan sudah disertakan. Anda dapat menggunakan Mechanize untuk mengirim kueri dan memproses hasilnya.
Untuk menggunakan perpustakaan Mechanize, kami menghubungkannya di file kami:
require 'mechanize'Kita juga bisa menggunakan fungsi bawaan perpustakaan untuk menjalankan permintaan:
agent = Mechanize.new page = agent.get('https://books.toscrape.com/catalogue/page-1.html')Menggunakan pemilih CSS yang sama seperti sebelumnya, Mechanize memungkinkan Anda mengakses dan mengekstrak data:
titles = page.css('h3 > a').map { |element| element('title') } prices = page.css('div.product_price > p.price_color').map { |element| element.text.gsub("£", "") } images = page.css('div.image_container > a').map { |element| element('href') } ratings = page.css('p.star-rating').map { |element| element('class').split(' ').last } availabilities = page.css('p.availability > i').map { |element| element('class').split('-').last }Kalau tidak, menggunakan perpustakaan ini sama dengan menggunakan Nokogiri.
Ambil kategori dengan Mekanisasi
Katakanlah kita ingin mengumpulkan data dari berbagai kategori. Kita akan mulai dengan menelusuri setiap kategori dan kemudian beralih ke halaman individual dalam kategori tersebut. Untuk setiap produk, kami menyimpannya dalam tabel beserta nama kategorinya.
Pertama, buka halaman beranda dan dapatkan nama dan tautan semua kategori:
base_url="https://books.toscrape.com" category_links = () category_names = () product_data = () agent = Mechanize.new agent.user_agent_alias="Mac Safari" # Set the User-Agent header page = agent.get(base_url) page.css('div.side_categories > ul > li > ul > li > a').each do |element| category_links << element('href') category_names << element.text.gsub(" ", "").strip endDi sini kami menggunakan gsub() untuk menghapus spasi ekstra dan strip untuk menghapus baris kosong. Untuk mengulangi semua kategori, kami menggunakan loop:
category_links.each_with_index do |category_link, index| … endPemilih CSS akan tetap sama, jadi kami tidak akan menduplikasinya, namun hashnya akan sedikit berubah sehingga kami dapat mempertahankan nama kategori:
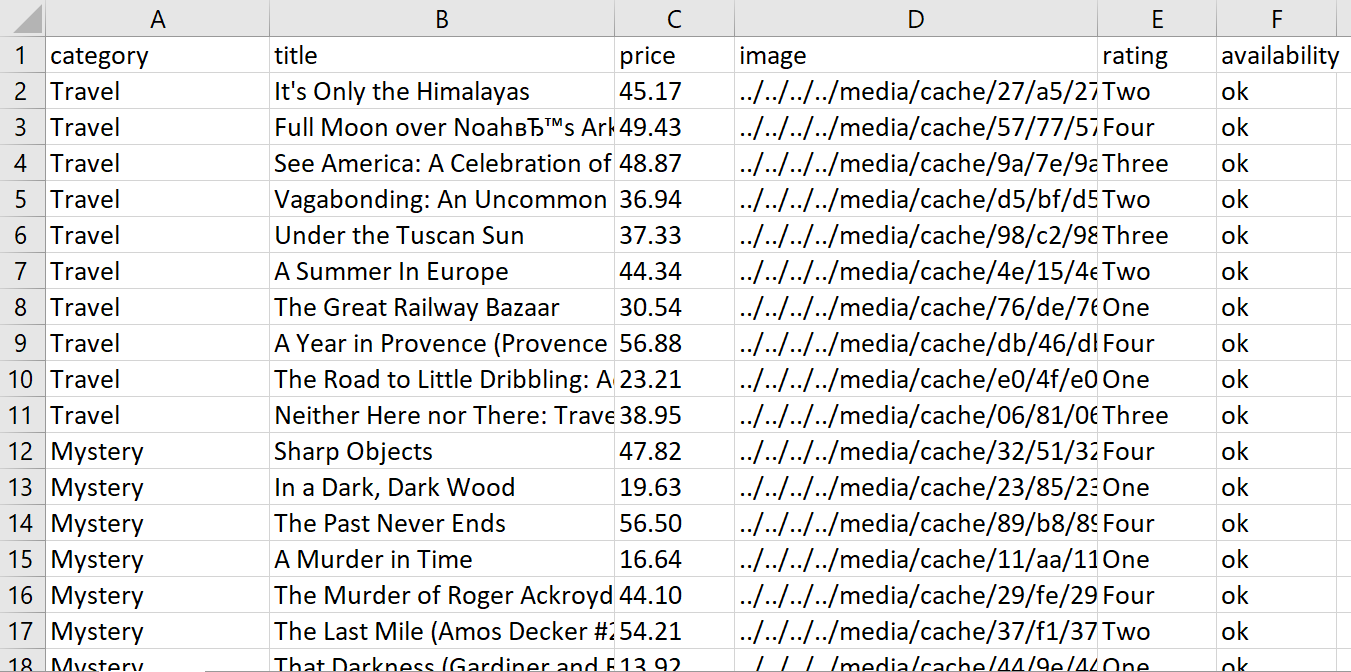
product_data << { category: category_names(index), title: title, price: price, image: image, rating: rating, availability: availability }Dengan menjalankan skrip kami, kami mendapatkan tabel data:
Kode lengkap:
require 'mechanize' require 'csv' base_url="https://books.toscrape.com" category_links = () category_names = () product_data = () agent = Mechanize.new agent.user_agent_alias="Mac Safari" # Set the User-Agent header # Get category links and names page = agent.get(base_url) page.css('div.side_categories > ul > li > ul > li > a').each do |element| category_links << element('href') category_names << element.text.gsub(" ", "").strip end # Iterate over each category category_links.each_with_index do |category_link, index| category_url = "#{base_url}/#{category_link}" page = agent.get(category_url) # Scrape product data page.css('article.product_pod').each do |product| title = product.css('h3 > a').first('title') price = product.css('div.product_price > p.price_color').text.gsub("£", "") image = product.css('div.image_container > a > img').first('src') rating = product.css('p.star-rating').first('class').split(' ').last availability = product.css('p.availability > i').first('class').split('-').last product_data << { category: category_names(index), title: title, price: price, image: image, rating: rating, availability: availability } end sleep(rand(1..3)) # Add a random delay between requests end # Save the data to a CSV file CSV.open('book_data.csv', 'w', col_sep: ";") do |csv| csv << product_data.first.keys # Write the headers product_data.each { |hash| csv << hash.values } # Write the data rows end puts 'Data saved to book_data.csv'Singkatnya, tidak terlalu sulit untuk mengekstrak detail produk seperti nama kategori dan menyimpannya ke file CSV jika Anda menggunakan perpustakaan Mechanize.
Mengikis data dinamis dengan Watir menggunakan browser tanpa kepala
Kerangka kerja Watir berbeda dari perpustakaan scraping lainnya karena dapat digunakan dengan browser tanpa kepala. Ini berarti kode kami bertindak seperti pengguna sebenarnya dan memiliki peluang lebih besar untuk tidak diblokir. Ini berfungsi dengan memungkinkan kita menampilkan atau menyembunyikan jendela browser saat mengakses semua fungsinya seperti: B. mengklik link dan mengisi formulir.
Untuk memulai kita perlu menginstal driver web. Ini adalah perangkat lunak yang membantu kita berinteraksi dengan Internet untuk mengekstrak data.
gem install webdriversUntuk tutorial ini kami akan menggunakan driver web Chrome, namun Anda juga dapat menggunakan driver web lain yang didukung oleh Watir seperti Firefox atau Safari. Jadi mari kita sambungkan perpustakaan yang diperlukan dan buat objek browser:
require 'watir' require 'webdrivers' browser = Watir::Browser.new(:chrome)Untuk hasil yang sama Anda juga dapat menggunakan Selenium:
browser = Selenium::WebDriver::Chrome::Options.newPerintah goto() digunakan untuk menavigasi ke halaman lain. Ini dapat digunakan untuk berpindah antar halaman dengan cepat sambil mengambil data dari berbagai sumber:
browser.goto(' https://books.toscrape.com/index.html')Mengikis dengan Watir memiliki satu keuntungan besar: Anda tidak perlu menambahkan parameter tambahan ke kueri. Karena skrip membuat jendela browser nyata dan menangani semua transisi antar halaman, sehingga sudah berisi semua informasi yang diperlukan.
Buka halaman berikutnya dengan Watir
Mari tingkatkan kode kita sebelumnya. Katakanlah kita masih ingin mengumpulkan semua artikel dari setiap kategori, namun kali ini kita akan menelusuri halaman-halaman kategori tersebut hingga tidak ada lagi tombol "Berikutnya".
Lihat tombol Berikutnya:
Ini menyimpan link ke halaman berikutnya dan memiliki kelas "berikutnya". Artinya kita dapat membuat loop dengan ketentuan sebagai berikut:
base_url="https://books.toscrape.com" loop do … next_link = browser.li(class: 'next').a break unless next_link.exists? browser.goto("#{base_url}/#{next_link.href}") endDengan menyematkan loop ke dalam loop kategori yang ada, kita dapat melakukan iterasi melalui halaman mana pun di semua kategori dengan cepat dan efisien. Hal ini memungkinkan kami menghindari tugas berat dalam menavigasi setiap halaman setiap kategori secara manual.
Akses data dengan Watir berbeda dari perpustakaan yang dibahas sebelumnya, tetapi membuatnya lebih mudah untuk berinteraksi dengan elemen dalam struktur Document Object Model (DOM). Misalnya, dapatkan data yang sama seperti sebelumnya:
product_data =() browser.articles(class: 'product_pod').each do |product| title = product.h3.a.title price = product.div(class: 'product_price').p(class: 'price_color').text.gsub('£', '') image = product.div(class: 'image_container').a.href rating = product.p(class: 'star-rating').class_name.split(' ').last availability = product.p(class: 'availability').i.class_name.split('-').last product_data << { category: category_names(index), title: title, price: price, image: image, rating: rating, availability: availability } endDi akhir skrip, pastikan untuk menyertakan perintah untuk menutup browser:
browser.quitKode lengkap:
require 'watir' require 'webdrivers' require 'csv' base_url="https://books.toscrape.com" category_links = () category_names = () product_data = () # Launch a browser (in this case, Chrome) browser = Watir::Browser.new(:chrome) # Navigate to the main page browser.goto(base_url) # Get category links and names browser.div(class: 'side_categories').ul(class: 'nav').li(class: 'active').ul.lis.each do |li| link = li.a.href name = li.a.text.gsub(' ', '') category_links << link category_names << name end # Iterate over each category category_links.each_with_index do |category_link, index| category_url = "#{base_url}/#{category_link}" browser.goto(category_url) loop do # Scrape product data from the current page browser.articles(class: 'product_pod').each do |product| title = product.h3.a.title price = product.div(class: 'product_price').p(class: 'price_color').text.gsub('£', '') image = product.div(class: 'image_container').a.href rating = product.p(class: 'star-rating').class_name.split(' ').last availability = product.p(class: 'availability').i.class_name.split('-').last product_data << { category: category_names(index), title: title, price: price, image: image, rating: rating, availability: availability } end # Check if there's a "Next" link next_link = browser.link(class: 'next') break unless next_link.exists? # Navigate to the next page browser.goto(next_link.href) sleep(rand(1..3)) # Add a random delay between requests end end # Close the browser browser.quit # Save the data to a CSV file CSV.open('book_data.csv', 'w', col_sep: ';') do |csv| csv << product_data.first.keys # Write the headers product_data.each { |hash| csv << hash.values } # Write the data rows end puts 'Data saved to book_data.csv'Setelah menggunakan Watir dalam praktiknya, kami dapat mengatakan bahwa ini adalah perpustakaan Ruby yang kuat yang menyediakan cara mudah untuk mengotomatisasi interaksi browser.
Meskipun ada alternatif web scraping lain di Ruby, seperti Nokogiri dan Mechanize, Watir menawarkan solusi yang lebih komprehensif untuk mengotomatiskan interaksi browser dan memberikan tingkat kontrol yang lebih tinggi atas tugas web scraping.
Kesimpulan dan temuan
Ruby menjadikan web scraping pilihan yang bagus bagi pengembang yang perlu mengumpulkan data dalam jumlah besar dengan cepat dan akurat. Pada artikel ini, kita telah membahas berbagai cara untuk mengikis data menggunakan Ruby. Kami memulai dengan opsi paling sederhana seperti pustaka kueri dan API pengikisan web sebelum beralih ke solusi yang lebih kompleks seperti menggunakan Watir dan driver web.
Saat memutuskan pustaka atau teknik mana yang akan digunakan, ingatlah untuk mempertimbangkan faktor-faktor seperti kompleksitas situs web target, kebutuhan rendering JavaScript, persyaratan otomatisasi browser, dan pemahaman Anda terhadap pustaka tersebut.
Jika Anda baru memulai dengan Ruby, menggunakan API untuk web scraping adalah pilihan yang baik. Dengan cara ini Anda tidak perlu khawatir tentang hal-hal rumit seperti rendering JavaScript, penyelesaian CAPTCHA, penggunaan proxy, atau menghindari pemblokiran. Jika hal ini tidak terjadi dan Anda memerlukan sesuatu yang sederhana, Nokogiri atau Mechanize ideal untuk membuang sumber daya statis. Namun, jika Anda memerlukan fitur-fitur canggih - seperti kemampuan untuk meniru perilaku pengguna nyata pada suatu halaman - maka Watir dan Webdriver (atau serupa, misalnya Ruby on Rails) adalah pilihan terbaik.