
Pengikisan web tidak hanya memungkinkan pembacaan berbagai data dari halaman web tetapi juga membantu mengaturnya untuk analisis lebih lanjut. Data keluaran dapat disimpan dalam format yang paling mudah digunakan, baik berupa tabel (misalnya dalam file CSV) atau API.
Pada saat yang sama, web scraping dengan Python tidak hanya mengekstrak data dari pemilih CSS. Ini adalah cara yang andal dan mudah untuk mengakses data dalam jumlah besar dengan cepat.
Daftar Isi
Dasar-dasar pengikisan situs web
Untuk menganalisis data, seseorang harus mengetahui dalam bentuk apa data tersebut disimpan dan memahami prinsip dasar transmisinya. Informasi ditransfer di browser melalui HTTP (Hyper Text Transfer Protocol), yang menggunakan komunikasi client-server. Artinya ada client (seseorang yang meminta data) dan server (seseorang yang menyediakan data).
Misalnya, server dapat mengirimkan halaman HTML. HTML adalah bahasa markup hypertext dari halaman web yang membantu browser memahami apa yang akan ditampilkan di situs yang dimuat.
Klien dapat berupa browser, parser, atau apa pun yang dapat meminta informasi. Server adalah sumber daya yang diakses klien untuk memperoleh informasi (misalnya server web Nginx atau Apache).
Ini terlihat seperti ini:
- Klien membuka koneksi.
- Klien meminta data.
- Server mengembalikan data yang diminta.
- Server menutup koneksi.
Permintaannya bisa terlihat seperti ini:
:authority: scrape-it.cloud
:method: GET
:path: /blog/
:scheme: https
accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
accept-encoding: gzip, deflate, br
accept-language: en-US,en;q=0.9,en;q=0.8;q=0.7
cookie: PHPSESSID=lj21547rbeor092lf7q1tbv2kj; _gcl_au=1.1.46260893.1654510660; _ga=GA1.1.87541067.1654500661; _clck=16uoci|1|f25|0; _ga_QSH330BHPP=GS1.1.1654773897.3.1.1654695637.58; _clsk=ac0mn0|1654695838342|7|1|h.clarity.ms/collect
dnt: 1
referer: https://scrape-it.cloud/
sec-ch-ua: " Not A;Brand";v="99", "Chromium";v="102", "Google Chrome";v="102"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Windows"
sec-fetch-dest: document
sec-fetch-mode: navigate
sec-fetch-site: same-origin
sec-fetch-user: ?1
upgrade-insecure-requests: 1
user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36Untuk melihat permintaan yang dihasilkan saat mengunjungi halaman web, buka DevTools (klik kanan halaman dan pilih Inspect atau tekan F12). Di DevTools, buka tab Jaringan, segarkan halaman dan pilih alamatnya dari daftar. Permintaan yang dihasilkan oleh browser kemudian dibuka.
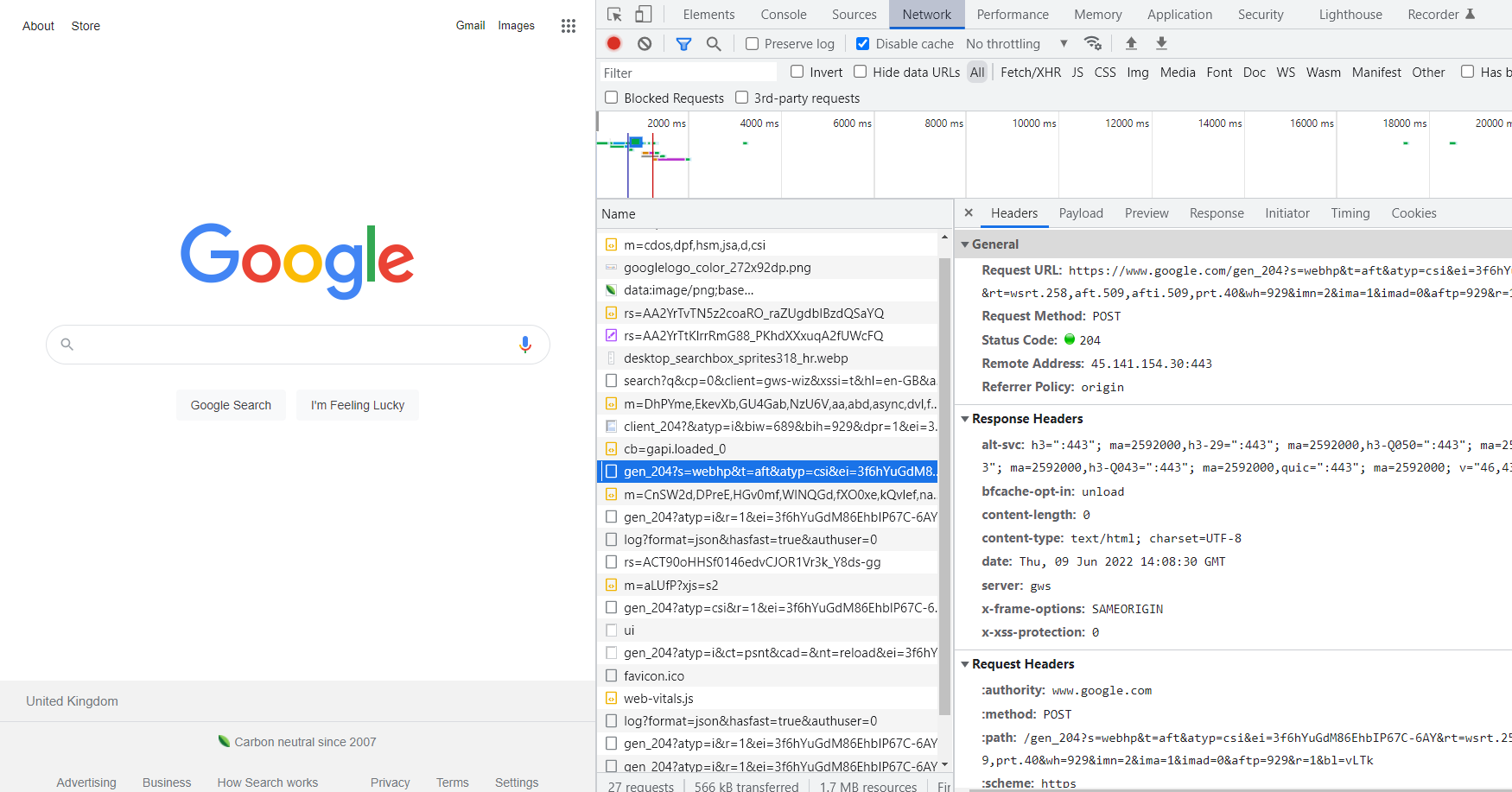
Data yang disimpan di bagian “Cookie” dan “Referrer” (tetapi di referrer browser) penting untuk parser. Cookie – untuk mengonfirmasi otentikasi, perujuk – jika situs web membatasi akses ke informasi tergantung dari halaman mana pengguna berasal.
Terima dan Agen-Pengguna juga akan berguna. Terima menampilkan jenis konten respons server (Teks/Biasa, Teks/HTML, Gambar/JPEG, dll.) dan Agen-Pengguna menyimpan informasi tentang klien.
Alat untuk menggores
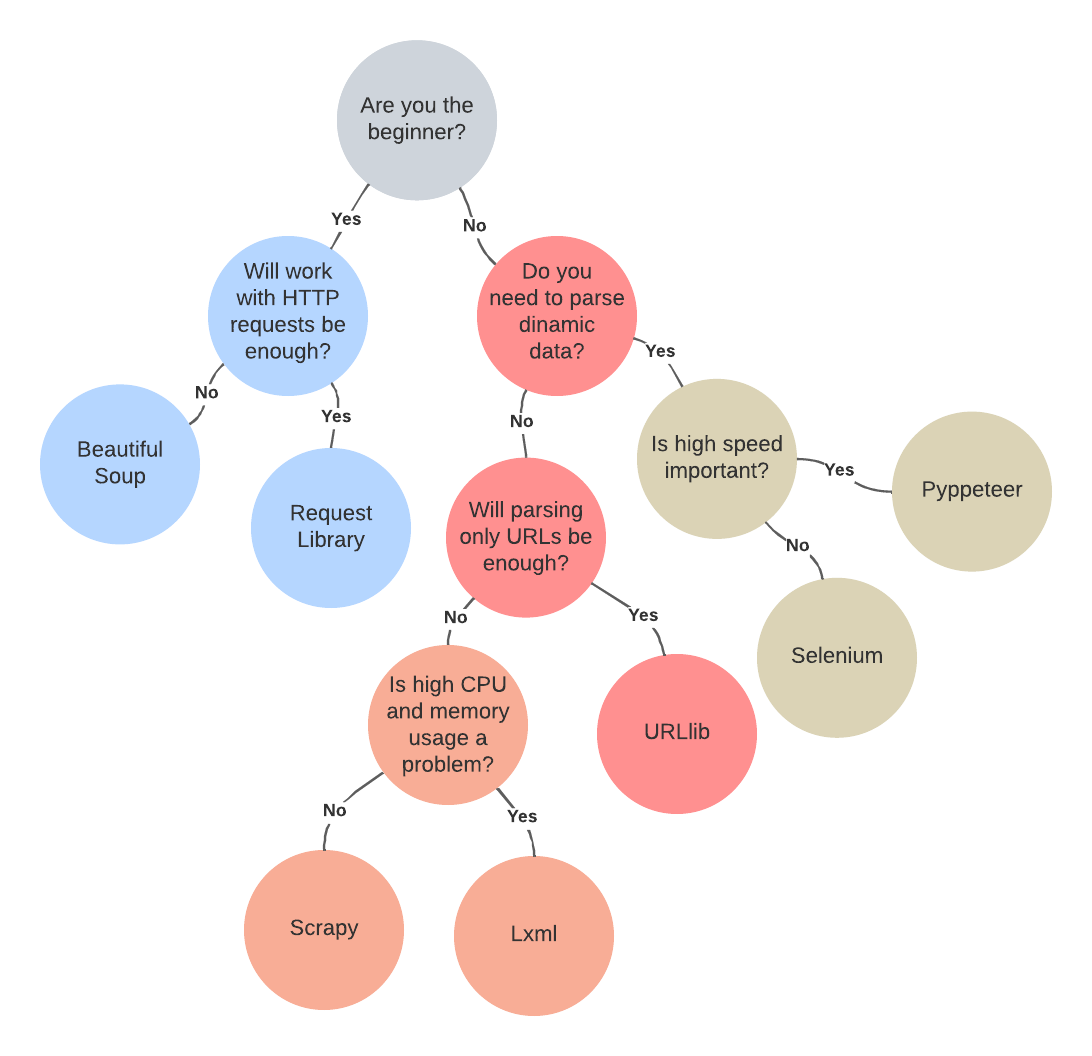
Seiring dengan semakin populernya web scraping, jumlah perpustakaan dan kerangka kerja scraping juga meningkat. Namun, yang paling populer, terlengkap, terdokumentasi terbaik, dan paling banyak digunakan hanyalah beberapa: Beautiful Soup, Requests, Scrapy, lxml, Selenium, URLlib, dan Pyppeteer.
Untuk menemukan yang paling cocok dan mengetahui kelebihan dan kekurangannya, ada baiknya mempertimbangkannya lebih detail.
Permintaan adalah pustaka pengikisan dasar yang ditemui semua orang dalam satu atau lain cara.
Apa itu Perpustakaan Permintaan?
Pustaka Permintaan dibuat untuk mempermudah pengiriman permintaan HTTP. Karena ini adalah perpustakaan sederhana, tidak memerlukan banyak latihan untuk menggunakannya. Ini mendukung seluruh Restful API dengan semua metodenya (PUT, GET, DELETE dan POST).
Saat menggunakan pustaka Permintaan, Anda tidak perlu memasukkan sendiri string kueri untuk URL. Selain itu, perpustakaan Permintaan telah memperoleh sejumlah besar dokumentasi berguna dan ditulis dengan baik selama bertahun-tahun.
Ini biasanya merupakan perpustakaan Python yang sudah terintegrasi. Namun jika karena alasan tertentu tidak ada, Anda bisa menginstalnya sendiri. Untuk melakukan ini, buka terminal dan masukkan baris:
pip install requestsSetelah perpustakaan diinstal, perpustakaan dapat digunakan dalam proyek:
import requestsUntuk mengambil halaman menggunakan metode request.get:
import requests
page = requests.get("example.com")
pageUntuk apa perpustakaan Permintaan?
Pustaka Permintaan mendukung pengunggahan file, batas waktu koneksi, cookie dan sesi, autentikasi, verifikasi browser SSL, dan semua metode interaksi dengan REST API (PUT, GET, DELETE, POST).
Namun, ada satu kelemahannya: tidak ada cara untuk menganalisis data dinamis karena Permintaan tidak berinteraksi dengan kode JavaScript.
Oleh karena itu, merupakan ide bagus untuk menggunakannya dalam semua kasus di mana tidak diperlukan analisis data dinamis.
Mulailah dengan sup yang enak
Saat ini, perpustakaan Beautiful Soup atau hanya BS4 adalah yang paling populer dari semua perpustakaan Python yang digunakan untuk scraping.
Apa itu perpustakaan Sup Cantik?
Perpustakaan Beautiful Soup dibuat untuk mengurai HTML. Karena banyak hal yang dilakukan secara otomatis (seperti memproses HTML yang tidak valid), cocok untuk pemula.
Outputnya dalam format pohon, sehingga memudahkan untuk menemukan item dan mengekstrak informasi yang Anda perlukan. BS4 juga menentukan pengkodean secara otomatis, yang berarti halaman HTML dengan karakter khusus juga dapat diproses.
Kerugian dari BS4 adalah fleksibilitas dan skalabilitasnya yang rendah serta kelambatannya. Namun, parser bawaan dapat dengan mudah diganti dengan yang lebih cepat.
Untuk menginstal BS4, cukup ketikkan baris tersebut di terminal
pip install beautifulsoup4Setelah itu bisa digunakan untuk mengikis. Misalnya, untuk mengikis semua judul, sedikit kode saja sudah cukup:
from bs4 import BeautifulSoup
soup = BeautifulSoup(contents, 'html.parser')
soup.find_all('title')Perhatikan bahwa untuk fungsionalitas yang tepat, perpustakaan permintaan harus disertakan dalam proyek.
Untuk menghasilkan kode halaman yang diformat dengan baik, kita dapat menggunakan:
print(soup.prettify())Katakanlah Anda perlu mengumpulkan semua judul produk yang disimpan di situs.
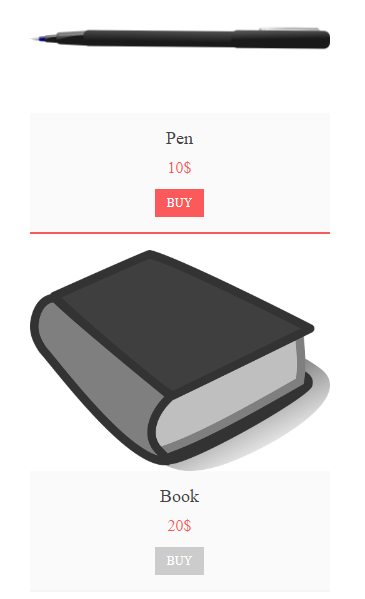
Pada saat yang sama, print(soup.prettify()) mengembalikan kode berikut:
<!DOCTYPE html>
<html>
<head>
<title>Toko sampel</title>
</head>
<body>
<div class="product-item">
<img src="https://scrape-it.cloud/blog/example.com\item1.jpg">
<div class="product-list">
<h3>Pena</h3>
<span class="price">10$</span>
<a href="/id/example.com\item1.html/" class="button">Membeli</a>
</div>
</div>
<div class="product-item">
<img src="example.com\item2.jpg">
<div class="product-list">
<h3>Buku</h3>
<span class="price">20$</span>
<a href="/id/example.com\item2.html/" class="button">Membeli</a>
</div>
</div>
</body>
</html>Selanjutnya, tentukan jenis semua elemen halaman:
(type(item) for item in list(soup.children))BS4 akan mengembalikan sesuatu seperti ini:
(bs4.element.Doctype, bs4.element.NavigableString, bs4.element.Tag)Dua yang pertama berisi informasi tentang halaman itu sendiri, dan hanya yang terakhir berisi informasi tentang elemen-elemennya. Untuk mendapatkan informasi nama produk, pilih semua data yang terkait dengan bs4.element.Tag:
html = list(soup.children)(2)
# items count from 0Untuk memeriksa nomor atom suatu unsur:
list(html.children)Pengembalian:
('N', <head> <title>Toko sampel</title> </head>, 'N', <body> <div>…</div> </body>, 'N')Inilah cara mendapatkan semuanya
-Elemen yang menempati peringkat keempat secara berurutan:body = list(html.children)(4)Item berikutnya diperiksa dengan cara yang sama:
divit = list(body.children)(1)
divli = list(divit.children)(2)
h3 = list(divli.children)(0)Untuk mengekstrak nama produk, kita harus melakukan hal berikut:
h3.get_text() Namun, Beautiful Soup memungkinkan otomatisasi sebagian besar proses dan semua kode di atas dapat diganti dengan yang lebih ringkas:
soup = BeautifulSoup(page.content, 'html.parser')
soup.find_all('h3')(0).get_text()Untuk apa perpustakaan Sup Cantik?
Beautiful Soup adalah pilihan terbaik bagi mereka yang baru memulai dengan scraper karena sebagian besar pekerjaannya dilakukan secara otomatis. Library ini juga cocok bagi mereka yang perlu mengekstrak data dari website tidak terstruktur.
Namun, Beautiful Soup kurang cocok untuk proyek web scraping yang besar.
Kumpulkan semua data menggunakan Scrapy
Scrapy adalah salah satu kerangka kerja terbaik untuk melakukan scraping dengan Python.
Apa itu kerangka Scrapy?
Scrapy adalah kerangka kerja sumber terbuka yang memungkinkan memuat halaman HTML dan menyimpannya dalam bentuk yang diinginkan (misalnya file CSV). Karena permintaan dieksekusi dan diproses secara paralel, kecepatan eksekusinya tinggi. Ini adalah pilihan paling cocok untuk menyelesaikan tugas pengumpulan dan pemrosesan data arsitektur yang kompleks.
Untuk menginstal Scrapy, cukup ketikkan perintah berikut ke terminal:
pip install scrapyUntuk memulai dengan Scrapy:
scrapy shell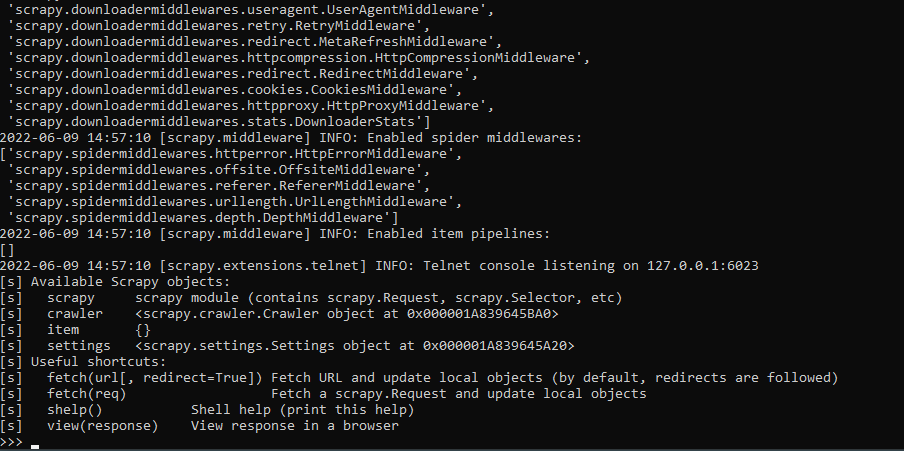
Untuk mengambil konten HTML suatu situs web, seseorang dapat menggunakan fungsi Ambil. Mari kita mencobanya:
Sekarang untuk memastikan Scrapy menyimpan halaman dan menampilkannya di browser, gunakan yang berikut ini:
view(response)
print(response.text)Untuk mendapatkan informasi lebih spesifik dengan Scrapy, Anda harus menggunakan pemilih CSS.
Untuk apa kerangka Scrapy?
Scrapy sangat bergantung pada sumber daya. Server terpisah mungkin diperlukan untuk mempertahankan kinerja yang memadai.
Selain itu, framework ini tidak cocok untuk pemula. Pemula dapat terhambat oleh segala hal mulai dari masalah instalasi pada beberapa sistem hingga banyaknya masalah sederhana.
Namun terlepas dari semua kekurangannya, Scrapy masih merupakan salah satu kerangka kerja terbaik untuk proyek besar. Ini dapat digunakan untuk manajemen permintaan, retensi sesi pengguna, pelacakan pengalihan, dan pemrosesan saluran keluaran.
Perpustakaan Lxml
Lxml adalah salah satu perpustakaan parsing yang cepat, kuat namun sederhana.
Apa itu perpustakaan Lxml?
Lxml adalah perpustakaan penguraian. Ini dapat bekerja dengan file HTML dan XML. Seperti Scrapy, Lxml sangat ideal untuk mengekstraksi data dari kumpulan data besar. Namun, tidak seperti Beautiful Soup, ia tidak dapat mengurai HTML yang dirancang dengan buruk.
Untuk menginstal perpustakaan Lxml, buka terminal dan tulis:
pip install lxmlMari kita kembali ke contoh dengan Pena dan Buku. Pertama, perpustakaan harus diintegrasikan ke dalam proyek:
from lxml import html
import requestsKemudian dapatkan halaman web dengan data:
page = requests.get('http://example.com/item1.html')
tree = html.fromstring(page.content)Informasi terdiri dari dua elemen – judul ada di
dan harganya sudah masuk :
<h3>Pena</h3>
<span class="price">10$</span>
Dapatkan datanya:
titles = tree.xpath('//h3/text()')
prices = tree.xpath('//span(@class="price")/text()')
Untuk ditampilkan di layar:
print('Titles: ', titles)
print('Prices: ', prices)
Berikut ini ditampilkan:
Titles: ('Pen', 'Book')
Prices: ('10$','20$')
Untuk apa perpustakaan Lxml?
<h3>Pena</h3>
<span class="price">10$</span>titles = tree.xpath('//h3/text()')
prices = tree.xpath('//span(@class="price")/text()')print('Titles: ', titles)
print('Prices: ', prices)Titles: ('Pen', 'Book')
Prices: ('10$','20$')Jika kinerja itu penting, Lxml adalah pilihan yang bagus. Hal ini juga berguna ketika sejumlah besar data perlu diproses.
Namun, terlepas dari fungsionalitas dan kecepatannya, perpustakaan ini tidak terlalu populer di kalangan pemula karena kurangnya dokumentasi, sehingga membuatnya cukup sulit.
Selenium untuk dikikis
Beberapa situs web ditulis menggunakan JavaScript, bahasa yang memungkinkan pengembang mengisi kolom dan menu secara dinamis. Meskipun sebagian besar pustaka Python hanya dapat mengambil data dari halaman web statis, Selenium memungkinkan pemrosesan data dinamis.
Apa itu perpustakaan Selenium?
Selenium adalah pustaka Python, juga dikenal sebagai driver web, yang memungkinkan simulasi perilaku pengguna di halaman dengan meluncurkan browser sebenarnya. Webdriver adalah protokol otomatisasi browser pertama yang dikembangkan oleh W3C yang berada di antara klien dan browser dan menerjemahkan perintah klien ke dalam tindakan browser web.
Ini memungkinkan Anda memproses data di situs sepenuhnya. Meskipun demikian, Selenium adalah alat yang ramah bagi pemula. Untuk menginstal, buka terminal dan tulis:
pip install seleniumKemudian aktifkan ChromeDriver untuk browser Chrome atau pengemudi tokek untuk Mozilla Firefox. Sekarang selenium siap digunakan.
Untuk mendapatkan URL halaman tersebut, jalankan skrip:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.example.com/items")Skrip ini memulai browser dan mendapatkan URL-nya. Namun, sebaiknya tetap menyembunyikan proses parsing dari pengguna. Untuk tujuan ini, apa yang disebut mode tanpa kepala digunakan, yang menghapus shell grafis dari browser dan memungkinkannya bekerja di latar belakang.
Di Selenium dapat diaktifkan dengan Pilihan Argumen kata kunci Jadi contoh kode terakhirnya adalah:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.headless = True # hide GUI
options.add_argument("--window-size=1920,1080")
# set window size to native GUI size
options.add_argument("start-maximized")
# ensure window is full-screen
driver = webdriver.Chrome(options=options)
driver.get("https://www.example.com/items")Untuk menganalisis data dinamis, seseorang harus memulai browser dan memerintahkannya untuk membuka example.com. Kemudian tunggu hingga halaman dimuat dan menerima kontennya.
Untuk mengurai tag HTML (misalnya judul) menggunakan penyeleksi, berikut ini dapat digunakan:
titles = driver.get_elements_by_css_selector('h3')
for title in tiles:
print(title.text)Ingatlah bahwa parser akan terus berfungsi hingga perintah close digunakan:
driver.quit() Untuk apa perpustakaan Selenium?
Kerugian utamanya adalah alat ini sangat lambat dan menghabiskan banyak memori serta waktu CPU. Namun, ini adalah alat terbaik untuk mengurai data dari halaman yang dihasilkan JavaScript.
Parsing URL menjadi komponen dengan URLlib
Sebelum melakukan scraping data, perlu dilakukan analisa link yang akan digunakan untuk scraping selanjutnya. Dan Urllib adalah salah satu alat terbaik untuk bekerja dengan URL. Baca juga tentang itu Cara menggunakan cULR dengan Python di sini.
Apa itu perpustakaan URLlib?
URLlib adalah paket multi-modul. Menyediakan fungsi penguraian halaman web dasar seperti autentikasi, pengalihan, cookie, dll. Cocok untuk mengurai halaman dalam jumlah terbatas, diikuti dengan pemrosesan data sederhana.
Ini adalah perpustakaan Python bawaan. Namun jika belum terinstal, tulis saja di terminal:
pip install urllibIni mendukung skema URL berikut: File, FTP, Gopher, HDL, http, https, IMAP, Mailto, MMS, News, NNTP, Prospero, Rsync, RTSP, RTSPU, SFTP, Shttp, SIP, Sips, Snews, SVN, SVN +ssh, telnet, wais, ws, wss.
Permintaan untuk mengambil data menggunakan URLlib umumnya terlihat seperti ini:
urllib.request.urlopen(url, data=None, (timeout, )*, cafile=None, capath=None, cadefault=False, context=None)Di mana:
- URL: alamat halaman;
- Data: untuk GET kosong; untuk POST, jenis byte;
- Batas Waktu: Batas waktu dalam hitungan detik;
- cafile: Sertifikat CA diperlukan saat mengambil tautan HTTPS;
- capath: jalur ke sertifikat CA;
- konteks: bertipe ssl.SSLContext dan digunakan untuk menentukan pengaturan SSL.
Untuk apa perpustakaan URLlib?
URLlib memberikan kontrol yang lebih baik atas permintaan di perpustakaan Permintaan, tetapi juga lebih rumit.
Dan terlepas dari semua pro dan kontranya, URLLib adalah perpustakaan terbaik untuk mengumpulkan tautan.
Solusi alternatif: Pyppeteer
Dalang adalah alat yang dikembangkan oleh Google berdasarkan Node.js. Dan Pyppeteer adalah sesuatu seperti Dalang untuk Python.
Apa itu Pyppeteer?
Pyppeteer adalah pembungkus Python untuk perpustakaan Puppeteer JavaScript (Node). Ia bekerja mirip dengan Selenium dan mendukung mode tanpa kepala dan tanpa kepala. Namun, dukungan Pyppeteer terbatas pada browser Chromium.
Pyppeteer menggunakan mekanisme asinkron Python dan oleh karena itu memerlukan Python 3.5 atau lebih baru untuk dijalankan. Untuk menginstal cukup tulis:
pip3 install pyppeteerKemudian coba jalankan ini di penerjemah:
import pyppeteerJika Pyppeteer berhasil diinstal, tidak ada kesalahan. Jadi contoh paling sederhana penggunaan Pyppeteer adalah:
import asyncio
import pyppeteer
async def main():
browser = await pyppeteer.launch()
page = await browser.newPage()
await page.goto('https://example.com/')
await page.screenshot({'path': 'items/item1/item1.png'})
await browser.close()
asyncio.get_event_loop().run_until_complete(main()) Untuk apa Pyppeteer digunakan?
Pyppetter sudah memiliki browser Chromium bawaan. Selain itu, ia menggunakan lebih sedikit waktu CPU dan RAM dibandingkan Selenium. Namun, ini tidak berfungsi dengan browser lain dan tidak memiliki dokumentasi lengkap karena merupakan shell Puppeteer tidak resmi dari pengembang Jepang.
Jadi Pyppeteer adalah pilihan terbaik ketika Selenium tidak dapat digunakan karena konsumsi sumber daya, tetapi pada saat yang sama Anda perlu menulis scraper yang kuat.
Ringkasan
Jadi perpustakaan apa yang terbaik? Sayangnya, tidak ada jawaban yang jelas untuk pertanyaan ini. Pemilihan perpustakaan tergantung pada tujuan, ruang lingkup, dan kemampuan sumber daya setiap orang.
Misalnya untuk pemula, Requests Library dan Beautiful Soup sudah cukup untuk menyelesaikan masalah sederhana. Jika Anda ingin mencoba sesuatu yang lebih kompleks dan proyek Anda cukup besar, Anda dapat memilih Pyppeteer atau Selenium.
Jadi ada tabel yang dapat membantu seseorang dalam mengambil keputusan dan memilih perpustakaan atau framework yang paling sesuai.
| Ciri | Permintaan | Sup yang indah | Tdk lengkap | lxml | selenium | URLlib | orang pyppeteer |
|---|---|---|---|---|---|---|---|
| Tujuan | Sederhanakan pembuatan permintaan HTTP | penguraian | Mengikis | penguraian | Sederhanakan pembuatan permintaan HTTP | Mengurai URL | penguraian |
| Ramah bagi pemula | Ya | Ya | TIDAK | TIDAK | Ya | TIDAK | TIDAK |
| kecepatan | Cepat | Cepat | Lambat | Sangat cepat | Lambat | Cepat | Cepat |
| dokumentasi | Bagus sekali | Bagus sekali | Bagus | Bagus | Bagus | Mungkin lebih baik | Mungkin lebih baik |
| dukungan JavaScript | TIDAK | TIDAK | TIDAK | TIDAK | Ya | TIDAK | Ya |
| Penggunaan CPU dan memori | Rendah | Rendah | Tinggi | Rendah | Tinggi | Rendah | Tinggi |
| Berguna untuk proyek | Besar dan kecil | Kecil | Besar dan kecil | Besar dan kecil | Besar dan kecil | Besar dan kecil | Besar dan kecil |
Trik dan tip untuk pengikisan yang lebih baik
Saat mengurai data, selalu ada beberapa tugas umum yang dihadapi setiap orang. Ini cukup umum, begitu pula solusinya. Menggunakannya menghemat waktu dan menyederhanakan tugas.
Dapatkan tautan internal
Pustaka BeautifulSoup dapat digunakan untuk mengambil konten yang relevan. Misalnya, mengekstrak tautan internal dari suatu halaman. Untuk menyederhanakan tugas, kami berasumsi bahwa tautan internal adalah tautan yang dimulai dengan garis miring.
internalLinks = (
a.get('href') for a in soup.find_all('a')
if a.get('href') and a.get('href').startswith("https://scrape-it.cloud/"))
print(internalLinks) Setelah Anda memiliki tautan, Anda dapat menghapus duplikatnya dan menghapusnya juga
Terima media sosial dan tautan email
Tugas umum lainnya adalah mengumpulkan alamat email dan tautan jejaring sosial. Untuk melakukan ini, Anda perlu menelusuri semua tautan dan memeriksa apakah Mailto (di mana Anda dapat mengambil email) dan domain jejaring sosial ada. URL tersebut harus ditambahkan ke daftar dan ditampilkan.
links = (a.get('href') for a in soup.find_all('a'))
to_extract = ("facebook.com", "twitter.com", "mailto:")
social_links = ()
for link in links:
for social in to_extract:
if link and social in link:
social_links.append(link)
print(social_links)Pengikisan meja otomatis
Biasanya, tabel diformat dan terstruktur dengan baik sehingga mudah dicari. Barisan tabel terletak di tr Hari, dan kolomnya ada di td atau th. Secara umum, tabel HTML terlihat seperti ini:
<table>
<tr>
<td>1 baris 1 kolom</td>
<td>1 baris 2 kolom</td>
</tr>
<tr>
<td>2 baris 1 kolom</td>
<td>2 baris 2 kolom</td>
</tr>
</table>Untuk mengumpulkan data dari tabel, perlu memeriksa semua baris, memeriksa kolom di masing-masing baris dan menampilkan konten di layar:
table = soup.find("table", class_="sortable")
output = ()
for row in table.findAll("tr"):
new_row = ()
for cell in row.findAll(("td", "th")):
collapsible.extract()
new_row.append(cell.get_text().strip())
output.append(new_row)
print(output)Memperoleh informasi dari metadata
Tidak semua data disimpan dalam kode, beberapa dapat ditemukan melalui Schema.org. Dan metadata ini dapat diambil seperti ini:
metaDescription = soup.find("meta", {'name': 'description'})
print(metaDescription('content'))Ini akan mengurai data dari deskripsi meta.
Ambil informasi produk yang tersembunyi
Untuk mendapatkan informasi tersembunyi, Anda perlu menemukannya melalui elemen dalam kode HTML dan menguraikannya seperti elemen lainnya. Misalnya, Anda menganalisis pada hari itu
brand = soup.find('meta', itemprop="brand")
print(brand('content'))Kesimpulan dan temuan
Ada banyak alat untuk mengurai data dengan Python, mulai dari perpustakaan hingga kerangka kerja yang memungkinkan penyimpanan data dalam tabel, API, atau cara lainnya.
Namun, setiap orang memutuskan sendiri alat mana yang lebih cocok untuk mereka. Untuk kesederhanaan dan kenyamanan Anda harus membayar dengan fungsionalitas atau kecepatan terbatas, untuk kecepatan dan fungsionalitas lebih dengan intensitas sumber daya.
Namun, jika Anda memilih alat untuk setiap proyek, Anda dapat mencapai hasil terbaik.
Baca juga tentang Google Maps Scraper