
Pengikisan web adalah teknik otomatis untuk mengekstraksi data dari situs web. Hal ini menjadi semakin penting dalam beberapa tahun terakhir karena jumlah data online yang tersedia tumbuh secara eksponensial. Pengikisan web dapat digunakan untuk berbagai tujuan, termasuk riset pasar dan persaingan, pemantauan harga, dan analisis data.
R adalah bahasa pemrograman yang sangat kuat yang memungkinkan pengguna mengekstrak informasi dari situs web dengan mudah menggunakan paket dan alat yang dirancang khusus untuk tujuan ini. Dengan pengetahuan yang benar, Anda dapat menggunakan R untuk mengumpulkan data dalam jumlah besar dengan cepat dari sumber web tanpa harus melakukannya secara manual.
Pada artikel ini, kita menjelajahi cara kerja web scraping di R. Mulai dari menyiapkan paket yang diperlukan hingga menyusun dan membersihkan catatan yang dihapus. Kita akan membahas teknik dasar seperti mengekstrak konten statis dan mempelajari metode lebih lanjut seperti menangani konten dinamis atau menggunakan API dengan kemampuan scraping R-Web.
Baik Anda seorang peneliti, analis, pengembang, atau ilmuwan, jika Anda ingin memanfaatkan ekstraksi situs web otomatis, panduan ini memberikan informasi yang cukup agar berhasil.
Daftar Isi
Memulai dengan web scraping di R
Untuk memulai, kita perlu menyiapkan lingkungan dan alat yang akan kita gunakan dalam tutorial ini. Hal pertama yang perlu Anda lakukan adalah mengunduh dan menginstal R. Untuk melakukan ini, buka situs web resmi R dan unduh paket yang diperlukan tergantung pada sistem operasi Anda (Windows, Linux, MacOS).
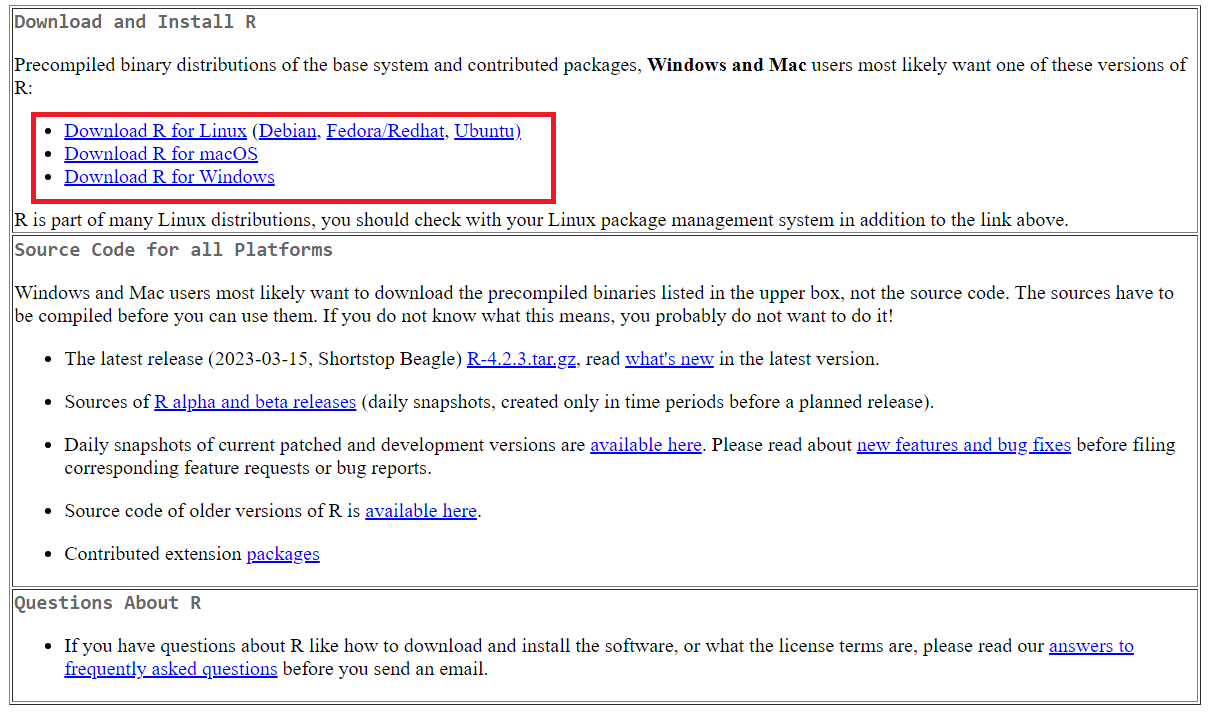
Kemudian unduh dan instal lingkungan pengembangan. Sebenarnya pilihannya cukup besar: Visual Studio Code, PyCharm atau lainnya yang mendukung bahasa R. Namun, kami merekomendasikan RStudio, yang dirancang khusus untuk bekerja dengan bahasa pemrograman ini, sangat fungsional dan memiliki banyak fitur bawaan yang berguna. Kami akan menggunakan lingkungan pengembangan ini dalam tutorial ini.
Untuk menginstal, buka situs resmi RStudio dan unduh file instalasi. Penting untuk diingat bahwa instalasi harus dilakukan dalam urutan yang ketat: pertama R, lalu RStudio.
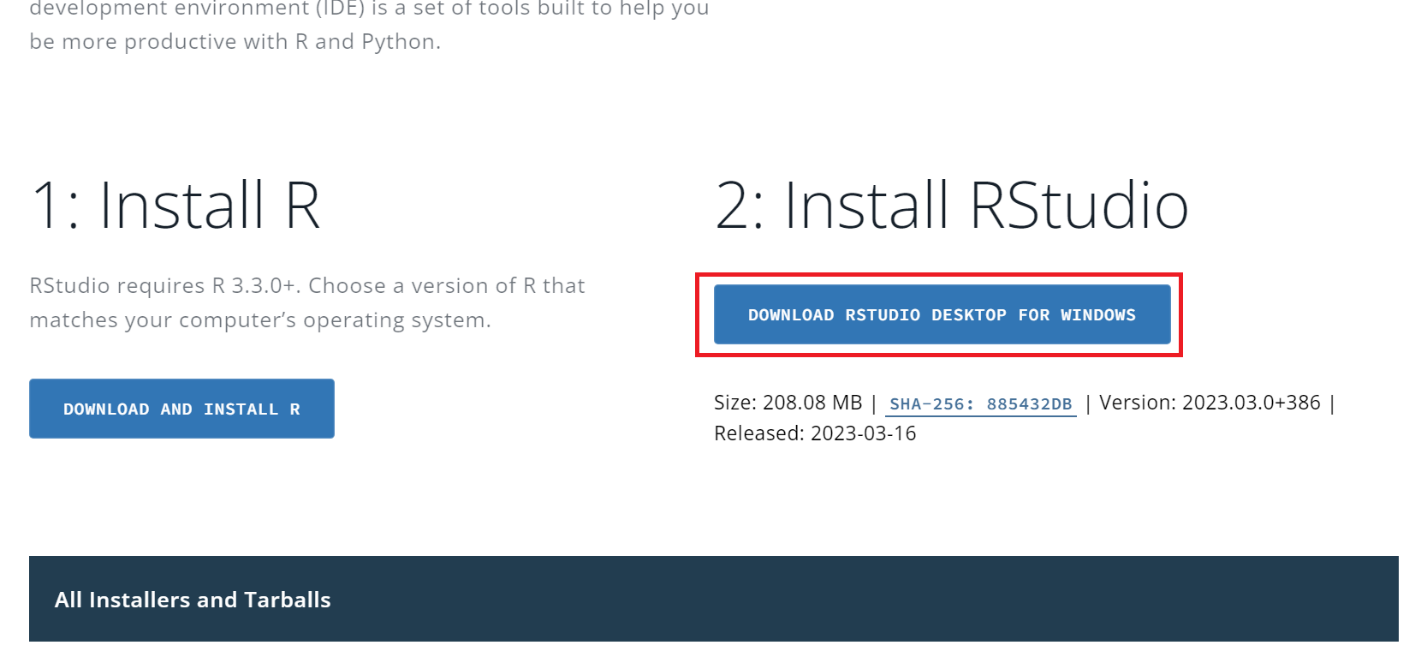
Untuk sistem operasi lain, Anda dapat menemukan file instalasi di bagian bawah halaman.
Karena Anda dapat menginstal paket di lingkungan RStudio itu sendiri, kami akan melakukannya nanti saat kami menggunakannya. Pertama, mari kita jelajahi situs web tempat kita akan mengumpulkan data.
Teliti struktur situs web
Sebelum menulis scraper, apa pun bahasa pemrogramannya, Anda perlu meneliti struktur situs dan memahami di mana dan dalam bentuk apa data yang diperlukan berada.
Mari kita ambil ini kutipan.toscrape.com Website sebagai contoh untuk melihat proses langkah demi langkah penulisan naskah. Pertama, mari kita masuk ke websitenya dan buka kode halamannya. Untuk membuka kode halaman HTML, buka DevTools (tekan F12 atau klik kanan pada ruang kosong di halaman dan buka Inspect).

Seperti yang bisa kita lihat, semua tanda kutip ada di
Mari kita periksa strukturnya lebih detail:
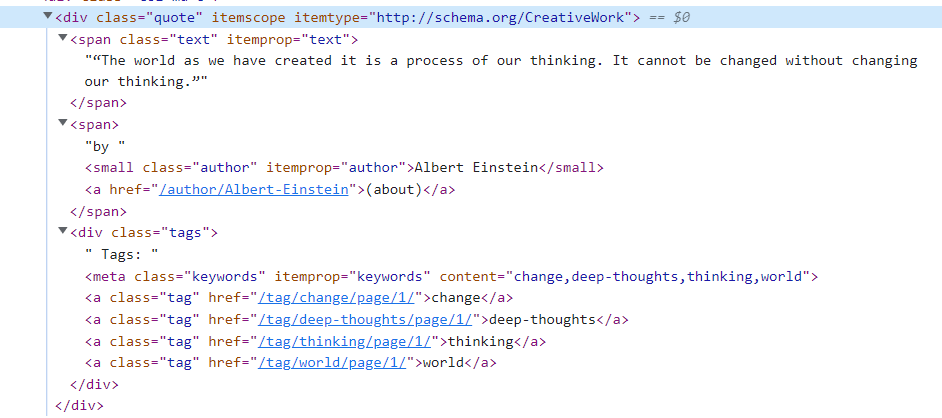
Sekarang kita melihat bahwa kutipan itu sendiri sudah masuk -Tag dengan kelas “teks” berada, penulis berada di dalamnya tag dengan kelas "penulis" dan tag kutipan di dalamnya -Tag dengan kelas "Label". Dengan struktur ini, Anda dapat mulai menulis scraper di R.
Mengambil data dari situs web
Mari kita lihat mengekstraksi data dari halaman dengan struktur berbeda: HTML, XML, dan JSON. Pertama, mari masuk ke RStudio dan buat proyek baru:
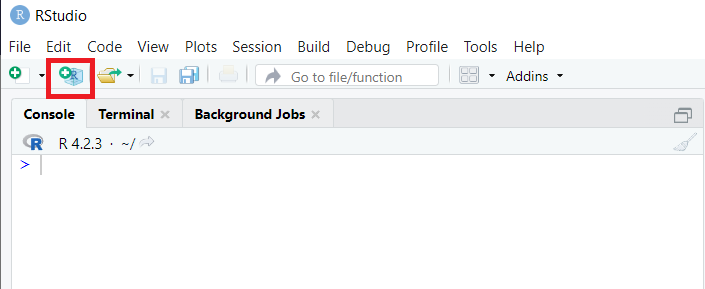
Kita dapat memilih dari tiga opsi: membuat folder baru, menempatkan proyek kita di folder yang sudah ada, atau menggunakan kontrol versi untuk mengelola proyek.
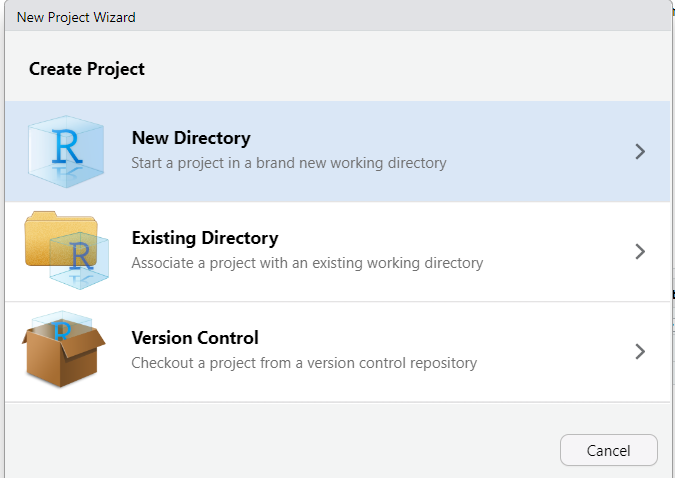
Buat folder baru untuk memudahkan pengelolaan file, lalu pilih “Buat proyek baru” dan masukkan namanya. Ruang kerja kemudian sepenuhnya disesuaikan dengan proyek baru.
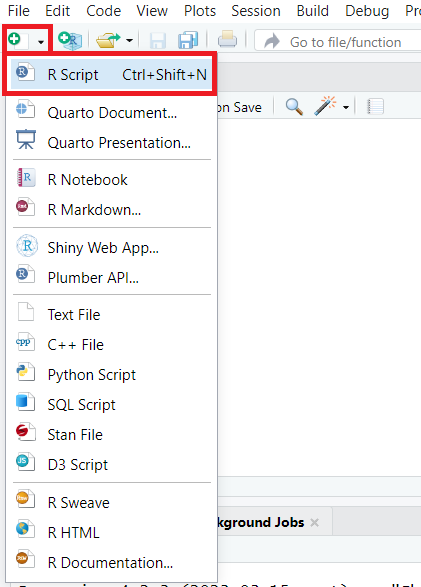
Mari kita juga membuat skrip baru dan menyimpannya ke proyek kita:
Pada tahap ini persiapan sudah selesai dan Anda dapat melanjutkan ke pembuatan scraper.
Menggores halaman HTML
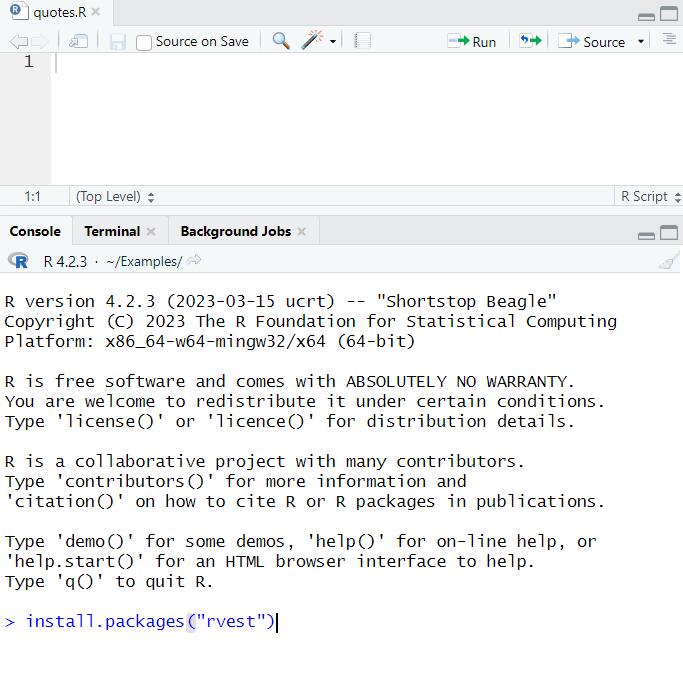
Untuk menulis scraper sederhana untuk mengekstrak data dari halaman web, kita memerlukan paket rvest. Untuk menginstalnya, jalankan perintah berikut di konsol RStudio:
install.packages("rvest")Setelah itu, tunggu pengunduhan, buka paket dan instal paket dan buka jendela atas - kami akan menulis skrip di dalamnya.
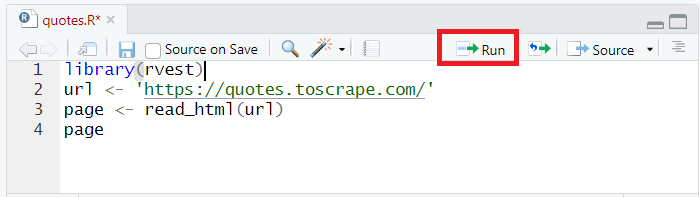
Pertama, mari sambungkan perpustakaan yang baru saja kita instal ke proyek:
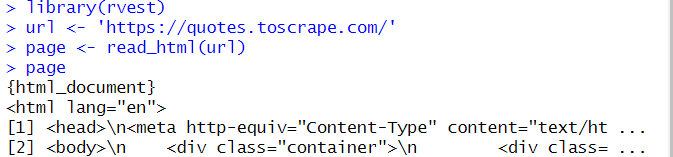
library(rvest)Mari kita query quotes.toscrape.com dan dapatkan semua kode halaman menggunakan baca_html perintah dan letakkan di Halaman Variabel:
url <- 'https://quotes.toscrape.com/'
page <- read_html(url)Untuk mengeluarkan data ke konsol, kita cukup menentukan nama variabel:
Halaman
Pastikan semuanya baik-baik saja dan jalankan skrip yang dihasilkan. Untuk melakukannya, tekan Ctrl+Enter atau klik tombol Jalankan.
Perhatikan bahwa kode dijalankan baris demi baris. Oleh karena itu, letakkan kursor pada baris pertama.
Skrip mengambil dan menampilkan semua kode di halaman:

Seperti yang telah disebutkan, data di quotes.toscrape.com adalah im
quotes <- page %>%
html_nodes("div.quote")Sekarang kami memiliki daftar yang menyimpan data tentang semua penawaran di halaman. Dari data ini, mari kita ambil kutipannya saja:
quote <- quotes %>%
html_nodes("span.text")%>%
html_text()Di sini kami menggunakan itu html_teks Memerintah. Jika hal ini tidak dilakukan, variabel Quote akan berisi informasi tambahan yang tidak diperlukan. Perintah html_teks digunakan untuk mengambil teks hanya dari tag HTML.
Kami juga menerima data tentang penulis kutipan dan memasukkannya ke dalam variabel:
author <- quotes %>%
html_nodes("small.author")%>%
html_text()Sekarang mari kita tampilkan isi variabel di layar:
quote
authorHasil:
>quote
(1) "The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.
(2) "It is our choices, Harry, that show what we truly are, far more than our abilities."
(3) "There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle."
(4) "The person, be it gentleman or lady, who has no pleasure in a good novel, must be intolerably stupid.
(5) "Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.
(6) "Try not to become a man of success. Rather become a man of value."
(7) "It is better to be hated for what you are than to be loved for what you are not.
(8) "'I have not failed. I've just found 10,000 ways that won't work."
(9) "A woman is like a tea bag; you never know how strong it is until it's in hot water."
(10) "A day without sunshine is like, you know, night.
> author
(1) "Albert Einstein" "J.K. Rowling"
(3) "Albert Einstein" "Jane Austen"
(5) "Marilyn Monroe" "Albert Einstein"
(7) "André Gide" "Thomas A. Edison"
(9) "Eleanor Roosevelt" "Steve Martin"
> Semua kode:
library(rvest)
url <- 'https://quotes.toscrape.com/'
page <- read_html(url)
quotes <- page %>%
html_nodes("div.quote")
quote <- quotes %>%
html_nodes("span.text")%>%
html_text()
author <- quotes %>%
html_nodes("small.author")%>%
html_text()
quote
authorKami akan kembali ke contoh ini nanti untuk membersihkan hasilnya, di mana kami akan menjelaskan secara rinci cara menghapus karakter tambahan dan melakukan operasi tambahan lainnya. Mari kita susun datanya dan simpan dalam file CSV terlebih dahulu.
Untuk membuat struktur, kami menggunakan bingkai data, metode standar untuk menyimpan data. Pertama, kita membuat bingkai data tempat kita memasukkan data Mengutip Dan pengarang Variabel:
all_quotes <- data.frame(quote, author)Sekarang atur judul kolom tabel masa depan:
names(all_quotes) <- c("quote", "author")Dan terakhir kita simpan datanya dalam file CSV:
write.csv(all_quotes, file = "./quotes.csv")File quotes.csv disimpan di folder proyek. Mari kita buka, susun teks menjadi kolom dan lihat hasilnya:
Seperti yang bisa kita lihat, ada karakter tambahan di kolom tanda kutip, tapi kita akan menghapusnya nanti.
Mengikis data XML dan JSON
Saat mengambil data dari situs web, Anda sering kali bekerja dengan data dalam format XML atau JSON. Format ini biasanya digunakan untuk pertukaran data antar aplikasi web dan juga untuk menyimpan dan mengangkut data. Untungnya, ada banyak alat untuk web scraping dengan R dalam kedua format.
Mengikis data XML
XML adalah singkatan dari “Extensible Markup Language” dan merupakan format populer untuk pertukaran data. Struktur data XML mirip dengan HTML, dengan elemen yang disarangkan di dalam elemen lainnya. Untuk mengikis data XML di R, kita bisa menggunakan paket XML atau xml2, yang menyediakan fungsionalitas untuk menguraikan dan menavigasi dokumen XML.
Untuk mendemonstrasikan cara bekerja dengan struktur XML, mari buat file dalam format *.xml dan masukkan contoh file tersebut ke dalamnya. Mari kita ambil contoh kode dari situs ini dan lihat penggunaan pustaka XML dan xml2 satu per satu.
Parsing XML dengan perpustakaan XML2
Mari gunakan konsol dan instal paket xml2 dengan perintah:
install.packages("xml2")Setelah itu, kami membuat skrip baru di proyek tempat kami menghubungkan perpustakaan xml2:
library(xml2)Masukkan konten seluruh file data XML ke dalam variabel:
doc <- read_xml("./example.xml")Sekarang kita perlu menjaga struktur dokumen ini dan memasukkan data ke dalam variabel menggunakan atribut:
plant <- xml_find_all(doc, ".//PLANT")
common <- xml_find_all(plant, ".//COMMON")
botanical <- xml_find_all(plant, ".//BOTANICAL")
zone <- xml_find_all(plant, ".//ZONE")
light <- xml_find_all(plant, ".//LIGHT")
price <- xml_find_all(plant, ".//PRICE")
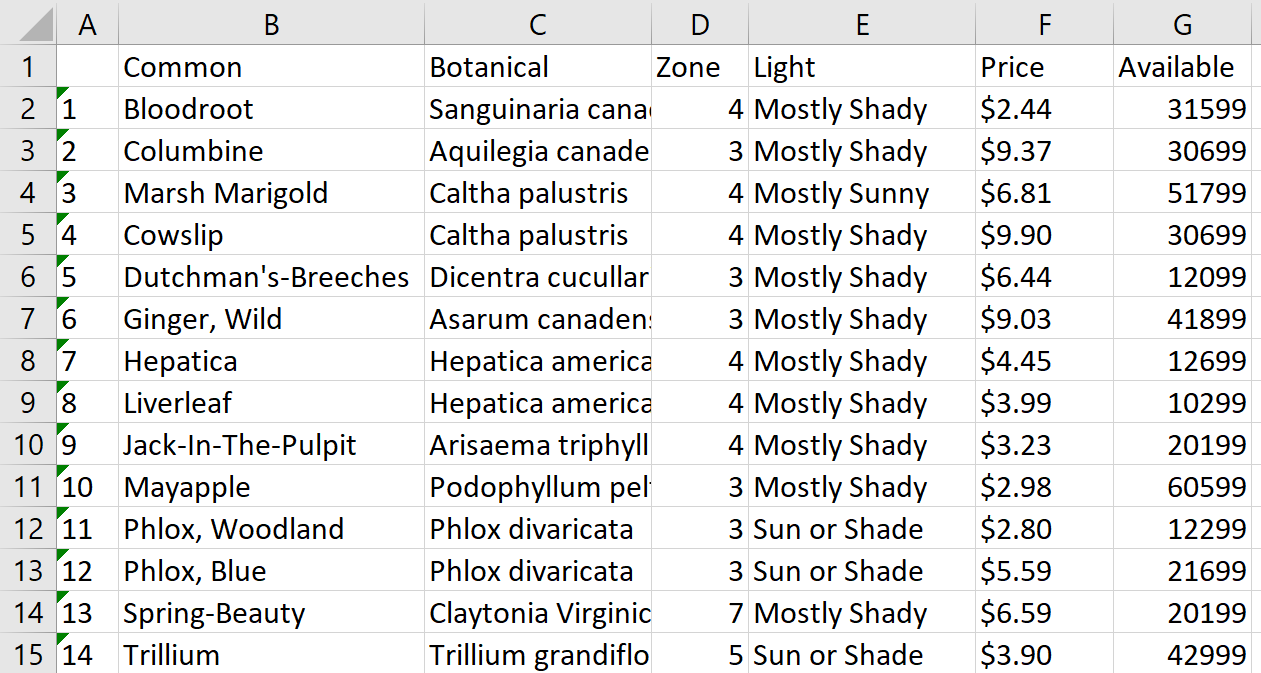
avail <- xml_find_all(plant, ".//AVAILABILITY") Untuk menyimpan data sebagai tabel, kami memasukkan data ke dalam bingkai data, mengatur header kolom dan menyimpannya ke file Tanaman.csv:
all_plants <- data.frame(xml_text(common), xml_text(botanical), xml_text(zone), xml_text(light), xml_text(price), xml_text(avail))
names(all_plants) <- c("Common", "Botanical", "Zone", "Light", "Price", "Available")
write.csv(all_plants, file = "./plants.csv")Mari kita buka file, overlay teks di atas kolom dan lihat hasilnya:

Dengan cara ini kita mendapatkan kemudahan untuk memproses file CSV dari struktur XML. Metode ini cocok untuk memproses file lokal dan halaman web dalam format XML. Untuk situs web, alamat halaman harus ditentukan, bukan alamat file:
doc <- read_xml("URL")Kode lengkapnya:
library(xml2)
doc <- read_xml("./example.xml")
plant <- xml_find_all(doc, ".//PLANT")
common <- xml_find_all(plant, ".//COMMON")
botanical <- xml_find_all(plant, ".//BOTANICAL")
zone <- xml_find_all(plant, ".//ZONE")
light <- xml_find_all(plant, ".//LIGHT")
price <- xml_find_all(plant, ".//PRICE")
avail <- xml_find_all(plant, ".//AVAILABILITY")
all_plants <- data.frame(xml_text(common), xml_text(botanical), xml_text(zone), xml_text(light), xml_text(price), xml_text(avail))
names(all_plants) <- c("Common", "Botanical", "Zone", "Light", "Price", "Available")
write.csv(all_plants, file = "./plants.csv")Itu adalah pilihan pertama, menggunakan perpustakaan XML2. Mari kita lihat hal yang sama tetapi dengan perpustakaan XML.
Proses XML dengan perpustakaan XML
Kami akan menggunakannya xml Perpustakaan dengan Metode Perpustakaan yang memperpendek dan menyederhanakan kode kita. Pertama kita menginstal perpustakaan XML di konsol:
> install.packages("XML")Impor perpustakaan yang diperlukan ke dalam skrip baru:
library("XML")
library("methods")Sekarang masukkan data dari file XML langsung ke dalam bingkai data:
all_plants <- xmlToDataFrame("./example.xml")Mari tambahkan header kolom dan simpan ke file CSV:
names(all_plants) <- c("Common", "Botanical", "Zone", "Light", "Price", "Available")
write.csv(all_plants, file = "./plants2.csv")Mari kita lihat kode lengkapnya:
library("XML")
library("methods")
all_plants <- xmlToDataFrame("./example.xml")
names(all_plants) <- c("Common", "Botanical", "Zone", "Light", "Price", "Available")
write.csv(all_plants, file = "./plants2.csv")Jadi kami mempunyai opsi yang sama, namun jauh lebih cepat dan mudah.
Mengikis data JSON
JSON adalah singkatan dari “JavaScript Object Notation” dan merupakan format ringan untuk pertukaran data. Data JSON disusun sebagai kumpulan pasangan nilai kunci, yang nilainya dapat berupa string, angka, array, atau objek lainnya. Untuk mengekstrak data JSON di R kita dapat menggunakan jsonlite Paket yang menyediakan fungsi untuk mengurai dan memanipulasi data JSON.
Pertama, mari gunakan konsol dan instal perpustakaan yang diperlukan:
> install.packages("jsonlite")Sekarang mari kita impor ke dalam proyek:
library(jsonlite)Sebagai contoh, kita akan menggunakan file JSON berikut:
{
"squadName": "Super hero squad",
"homeTown": "Metro City",
"formed": 2016,
"secretBase": "Super tower",
{ "active": true,
{ "members": (
{
"name": "Molecule Man",
"age": 29,
"secretIdentity": "Dan Jukes"
},
{
"name": "Madame Uppercut",
{ "age": 39,
"secretIdentity": "Jane Wilson"
},
{
"name": "Eternal Flame",
"age": 1000000,
"secretIdentity": "Unknown"
}
)
}Seperti dalam kasus xml perpustakaan, itu jsonlite Perpustakaan memiliki kemampuan untuk segera menyimpan data ke bingkai data. Mari gunakan fungsi ini dan dapatkan data yang sesuai untuk diproses lebih lanjut:
heroes <- fromJSON("./example.json")Mari simpan bingkai data ini ke file CSV:
write.csv(heroes, file = "./heroes.csv")Hasilnya, kami mendapatkan tabel dengan konten berikut:

Sekarang mari kita ubah tugasnya sedikit. Misalkan kita hanya ingin menyimpan data yang disematkan pada elemen atribut di tabel. Untuk melakukan ini, dalam perintah simpan kita menentukan tidak hanya bingkai data, tetapi juga atribut yang isinya ingin kita simpan:
write.csv(heroes$members, file = "./heroes.csv")Sekarang jika kita melihat filenya, terlihat berbeda:
Mengikis data dalam format XML atau JSON bisa lebih rumit daripada menggores data HTML, namun hal ini tidak sulit dilakukan di R dengan alat dan teknik yang tepat.
Jalankan konten dinamis dengan RSelenium
Kami telah menulis tentang scraping dengan Selenium dengan Python. Perpustakaan ini juga memiliki padanan untuk bahasa R – RSelenium. Hal ini diperlukan untuk mengumpulkan data dinamis dan menggunakan browser tanpa kepala, yang memungkinkan Anda mensimulasikan perilaku pengguna sebenarnya, sehingga mengurangi risiko pemblokiran.
Untuk menggunakan RSelenium, Anda perlu menginstal paket dan mendownload driver untuk browser web yang ingin Anda gunakan. Kami akan menggunakan driver web Chromium. Untuk menginstal perpustakaan, jalankan perintah di konsol RStudio:
> install.packages("RSelenium")Anda dapat mengunduh driver web dari situs resminya dan kemudian Anda perlu meletakkannya di folder proyek. Agar berfungsi dengan baik, Anda harus menginstal driver web dengan versi yang sama dengan browser Chrome.
Kita memerlukan bagian server dan bagian klien agar berfungsi. Untuk menjalankan bagian server kita membutuhkan Java. Jadi kalau di komputer belum terinstal, maka perlu diinstal.
Sekarang unduh Selenium Server Stadalone dari situs resminya. Versi apa pun bisa digunakan, tetapi lebih baik mengunduh yang terbaru. Kami akan menggunakan Selenium-Server-Standalone-4.0.0-Alpha-2. Itu harus diunduh dan ditempatkan di folder proyek.
Ketika semua persiapan selesai, buka folder proyek dan ketik cmd di bilah alamat untuk menjalankan baris perintah di bawah folder yang dipilih. Kita perlu memulai server. Untuk melakukan ini, gunakan perintah:
java -jar selenium-server-standalone-VERSION.jarMisalnya, dalam kasus kami, perintahnya akan terlihat seperti ini:
java -jar selenium-server-standalone-4.0.0-alpha-2.jarHasil eksekusinya, jika semuanya dilakukan dengan benar, akan memulai server (perhatikan port server, nanti kita membutuhkannya):
C:\Users\user\Documents\Examples>java -jar selenium-server-standalone-4.0.0-alpha-2.jar
17:16:24.873 INFO (GridLauncherV3.parse) - Selenium server version: 4.0.0-alpha-2, revision: f148142cf8
17:16:25.029 INFO (GridLauncherV3.lambda$buildLaunchers$3) - Launching a standalone Selenium Server on port 4444
17:16:25.529 INFO (WebDriverServlet.<init>) - Initialising WebDriverServlet
17:16:26.061 INFO (SeleniumServer.boot) - Selenium Server is up and running on port 4444Sekarang kembali ke RStudio dan buat skrip baru di proyek. Impor perpustakaan RSelenium ke dalamnya:
library(RSelenium)Selanjutnya kita atur pengaturan driver web: nama browser, port server dan versi driver web. Dalam kasus kami, pengaturannya terlihat seperti ini:
rdriver <- rsDriver(browser = "chrome",
port = 4444L,
chromever = "112.0.5615.28",
)Buat klien yang menavigasi halaman dan mencari data:
remDr <- rdriverKunjungi situs web tempat kami mengumpulkan data:
remDr$navigate("https://quotes.toscrape.com/")Setelah memasuki website, kami mengumpulkan semua kutipan ke dalam satu variabel:
html_quotes <- remDr$findElements(using = "css selector", value = "div.quote")Mari kita membuat variabel dari daftar Ketik dan tempel kutipan dan penulis:
quotes <- list()
authors <- list()
for (html_quote in html_quotes) {
quotes <- append(
quotes,
html_quote$findChildElement(using = "css selector", value = "span.text")$getElementText()
)
authors <- append(
authors,
html_quote$findChildElement(using = "css selector", value = "small.author")$getElementText()
)
}Sekarang mari kita masukkan data ke dalam data frame seperti sebelumnya, buat header kolom dan simpan data dalam format CSV:
all_qoutes <- data.frame(
unlist(quotes),
unlist(authors)
)
names(all_quotes) <- c("quote", "author")
write.csv(all_quotes, file = "./quotes.csv")Pada akhirnya, tutup driver web:
remDr$close()Hasilnya, kami menerima file yang persis sama seperti sebelumnya, tetapi dengan kemampuan untuk mengontrol elemen di halaman web, menjalankan browser tanpa kepala, meniru perilaku pengguna sebenarnya, dan mengurangi kemungkinan pemblokiran.
Kode skrip lengkap:
library(RSelenium)
rdriver <- rsDriver(browser = "chrome",
port = 4444L,
chromever = "112.0.5615.28",
)
remDr <- rdriver
remDr$navigate("https://quotes.toscrape.com/")
html_quotes <- remDr$findElements(using = "css selector", value = "div.quote")
quotes <- list()
authors <- list()
for (html_quote in html_quotes) {
quotes <- append(
quotes,
html_quote$findChildElement(using = "css selector", value = "span.text")$getElementText()
)
authors <- append(
authors,
html_quote$findChildElement(using = "css selector", value = "small.author")$getElementText()
)
}
all_quotes <- data.frame(
unlist(quotes),
unlist(authors)
)
names(all_quotes) <- c("quote", "author")
write.csv(all_quotes, file = "./quotes.csv")
remDr$close()Secara keseluruhan, RSelenium adalah alat yang ampuh untuk mengambil data dari halaman web dengan konten dinamis dan membuka kemungkinan dunia baru untuk web scraping di R.
Misalkan Anda ingin mengekstrak data dari halaman web yang mengharuskan Anda mengklik tombol “Muat Lebih Banyak” untuk menampilkan konten tambahan. Tanpa RSelenium, Anda harus mengklik tombol secara manual setiap kali ingin memuat lebih banyak data. Namun, RSelenium memungkinkan Anda mengotomatiskan proses ini.
Tip dan trik untuk web scraping yang efektif di R
Berikut beberapa tip dan trik untuk membantu Anda meningkatkan keterampilan web scraping dengan R. Kiat-kiat ini akan membantu Anda mengikis beberapa halaman dan situs web, mengekstrak jenis data tertentu, menangani otentikasi, menangani data yang hilang atau salah, dan menghapus elemen atau ikon yang tidak diinginkan.
Gunakan penundaan untuk mengikis beberapa halaman dan situs web
Saat mengekstrak data dari beberapa situs web, penting untuk menghormati pemilik situs web dan menghindari membebani server mereka secara berlebihan. Anda dapat menggunakan untuk ini Sys.tidur() Berfungsi di R untuk menambahkan penundaan antar permintaan. Namun, disarankan untuk mengatur waktu tunda secara acak. Hal ini mengurangi kemungkinan scraper Anda terdeteksi dan alamat IP Anda diblokir.
Itu runif(n,x,y) Fungsi ini mengembalikan nomor acak di R yang dapat digunakan untuk mengatur penundaan antar permintaan:
Sys.sleep(runif(1, 0.3, 10))Kode ini menambahkan penundaan antara 0,3 dan 10 detik sebelum permintaan lain dibuat. N (di sini sama dengan 1) menunjukkan berapa banyak nilai yang ada runif harus kembali sebagai output.
Terkadang Anda mungkin tertarik untuk mengekstrak tipe data tertentu dari halaman web, seperti gambar atau tabel. Untuk melakukan ini, Anda perlu mengidentifikasi tag atau fungsi HTML spesifik yang terkait dengan data yang ingin Anda ekstrak.
Misalnya saja rvest Perpustakaan memiliki beberapa fungsi yang memungkinkan Anda bekerja dengan data tertentu. Jika halaman berisi data tabular, Anda dapat menggunakannya untuk mengubahnya langsung menjadi bingkai data html_tabel().
Pilihan lainnya adalah mendapatkan alamat atau mendownload gambar. Anda bisa mendapatkan alamatnya sebagai berikut:
imgsrc <- read_html(url) %>%
html_node(xpath="//*/img") %>%
html_attr('src')Untuk mendownload gambar yang alamatnya sudah ditentukan:
unduh.file(paste0(url, imgsrc), file tujuan = nama dasar(imgsrc))
Itu rvest Perpustakaan cukup untuk menggunakan fungsi-fungsi ini.
Mengikis dengan otentikasi
Beberapa situs web memerlukan autentikasi sebelum Anda dapat mengakses datanya. Dalam kasus seperti ini, Anda perlu menggunakan teknik seperti OAuth untuk mengautentikasi permintaan Anda.
OAuth adalah protokol yang memungkinkan Anda mengautentikasi permintaan Anda tanpa mengungkapkan kredensial Anda ke situs web. Paket httr di R menyediakan fungsionalitas untuk bekerja dengan OAuth dan mengautentikasi permintaan Anda.
Untuk memudahkan otorisasi, perpustakaan httr harus terhubung. Untuk menginstalnya, gunakan perintah berikut di konsol RStudio:
> install.packages("httr")Perintah otorisasinya adalah sebagai berikut:
GET("http://example.com/basic-auth/user/passwd",authenticate("user", "passwd") )Selain itu, perpustakaan ini juga memiliki fungsi oauth1.0_token, oauth2.0_token, oauth_app, oauth_endpoint, oauth_endpoints dan oauth_service_token.
Mengikis R dengan otentikasi bisa menjadi sedikit lebih rumit, tetapi perpustakaan httr bertujuan untuk membuatnya lebih mudah.
Menangani data yang hilang atau salah
Saat memproses informasi dalam jumlah besar, kemungkinan besar beberapa data akan hilang atau bentuknya salah. Kesalahan tersebut dapat terjadi karena, misalnya, masalah pemformatan, masalah pengkodean, atau data yang hilang. Karena masalah ini cukup sering terjadi, maka perlu disediakan metode untuk memecahkan masalah ini terlebih dahulu.
Misalnya, Anda dapat menggunakan fungsi ifelse(), yang memungkinkan Anda mencari ketidakkonsistenan dalam dokumen HTML dan mengganti data dengan nilai alternatif seperti NA. Dengan cara ini Anda memastikan bahwa data yang dikumpulkan benar, meskipun mungkin ada masalah yang muncul di tengah proses.
Cara menggunakan Web Scraping API di R
Selain teknik web scraping yang telah dibahas sebelumnya, pendekatan lain untuk mengekstraksi data dari halaman web adalah dengan menggunakan API (Application Programming Interfaces).
Untuk menggunakan API di R, Anda dapat menggunakan paket seperti httr, jsonlite, atau curl. Paket ini memungkinkan Anda mengirim permintaan HTTP ke titik akhir API dan menerima kembali data JSON atau XML. Mari kita lihat contoh cara mengambil data dari Zillow menggunakan API dan paket httr.
Hubungkan perpustakaan dan atur header dan isi permintaan:
library(httr)
headers = c(
'x-api-key' = YOUR-API-KEY',
'Content-Type' = 'application/json'
)
body = '{
{ "extract_rules": {
{ "address": { "address",
"price": "(data-test=property-card-price)",
{ "seller": "div.cWiizR"
},
{ "url": "https://www.zillow.com/portland-or/"
}';Sekarang mari kita jalankan query dan cetak hasilnya:
res <- VERB("POST", url = "https://api.scrape-it.cloud/scrape", body = body, add_headers(headers))
cat(content(res, 'text'))Anda dapat menyempurnakan skrip lebih lanjut dan menyimpan data yang dihasilkan. Dengan menggunakan API Anda tidak perlu khawatir dalam menggunakan proxy dan captcha serta batasannya. Dalam hal ini, semua masalah ini diselesaikan oleh layanan yang menyediakan API untuk scraping.
Menghapus elemen atau ikon yang tidak diinginkan
Terkadang data yang Anda jelajahi berantakan atau tidak konsisten, dengan spasi tambahan, tanda baca, atau karakter lain yang tidak diinginkan. Anda dapat membersihkan data ini dengan cepat dan akurat menggunakan ekspresi reguler. Misalnya, Anda dapat menggunakan fungsi gsub() untuk menghapus semua karakter non-alfanumerik dari sebuah string, atau fungsi str_extract() untuk mengekstrak pola tertentu dari string yang lebih panjang.
Misalnya, saat kami mengambil data dengan tanda kutip, jelas ada karakter tambahan yang tidak dikenali dengan benar di file akhir karena pengkodean. Karakter ini adalah tanda kutip keriting.
Untuk menghapus semua tanda kutip yang tidak perlu dari tanda kutip di Mengutip variabel, kita cukup menambahkan baris berikut:
quote <- gsub('|', '',quote)Ini akan menghapus karakter yang tidak diperlukan dan membuat hasilnya lebih nyaman.
Kelompokkan dan rangkum data
Terkadang perlu tidak hanya mengumpulkan data, tetapi juga mengolahnya dan meringkasnya dalam tabel ringkasan. Beberapa operasi dapat dilakukan pada R dan data kemudian dapat disajikan dalam tabel ringkasan. Anda dapat membuat bingkai data dengan menggabungkan data yang diambil ke dalam kolom dan kemudian menggunakan fungsi seperti filter(), select(), dan array() dari paket dplyr atau Tidyverse untuk memanipulasi dan meringkas data.
Untuk menginstalnya, masukkan perintah berikut di konsol RStudio:
> install.packages("dplyr")Misalkan kita memiliki bingkai data yang menyimpan data dan kita perlu mengelompokkannya berdasarkan bidang Nama dan meringkas nilainya:
df %>% group_by(Name) %>% summarise(count = n())Library ini memiliki banyak fitur dan fungsi yang berguna untuk ilmu data.
Kesimpulan dan temuan
Pengikisan web adalah metode yang ampuh untuk mengumpulkan data dari situs web dan R menyediakan lingkungan yang sempurna untuk itu. Menggunakan alat seperti rvest dan xml2, Anda dapat dengan mudah menghapus konten dari halaman web. Bahkan jika Anda tidak memiliki pengalaman pemrograman, R membuat web scraping menjadi mudah dengan beragam fungsi dan paketnya.
Ini membuka banyak kemungkinan bagi siapa pun yang ingin mengekstrak informasi berharga dari Internet. Anda dapat mengumpulkan data dari berbagai sumber, mengambil jenis data tertentu seperti gambar atau tabel, dan menyelesaikan masalah umum seperti informasi yang hilang atau tidak akurat sekaligus. Pengikisan web di R adalah keterampilan yang sangat berguna yang membantu mengungkap wawasan tersembunyi, baik Anda seorang pengembang, peneliti, atau ilmuwan data.