
Web Scraping ist eine automatisierte Technik zum Extrahieren von Daten von Websites. Es hat in den letzten Jahren immer mehr an Bedeutung gewonnen, da die Menge der verfügbaren Online-Daten exponentiell wächst. Web Scraping kann für verschiedene Zwecke eingesetzt werden, darunter Markt- und Wettbewerbsforschung, Preisüberwachung und Datenanalyse.
R ist eine unglaublich leistungsstarke Programmiersprache, die es Benutzern ermöglicht, mit speziell für diesen Zweck entwickelten Paketen und Tools ganz einfach Informationen von Websites zu extrahieren. Mit den richtigen Kenntnissen können Sie mit R schnell große Datenmengen aus Webquellen sammeln, ohne dies manuell tun zu müssen.
In diesem Artikel untersuchen wir, wie Web Scraping in R funktioniert. Dies reicht von der Einrichtung der erforderlichen Pakete bis hin zur Strukturierung und Bereinigung gelöschter Datensätze. Wir werden über grundlegende Techniken wie das Extrahieren statischer Inhalte sprechen und uns mit fortgeschritteneren Methoden wie der Handhabung dynamischer Inhalte oder der Verwendung von APIs mit R-Web-Scraping-Funktionen befassen.
Egal, ob Sie Forscher, Analyst, Entwickler oder Wissenschaftler sind: Wenn Sie die Vorteile der automatischen Website-Extraktion nutzen möchten, bietet dieser Leitfaden genügend Informationen, um erfolgreich zu sein.
Erste Schritte mit Web Scraping in R
Um zu beginnen, müssen wir die Umgebung und die Tools vorbereiten, die wir in diesem Tutorial verwenden werden. Als Erstes müssen Sie R herunterladen und installieren. Gehen Sie dazu auf die offizielle Website von R und laden Sie das erforderliche Paket herunter, abhängig von Ihrem Betriebssystem (Windows, Linux, MacOS).
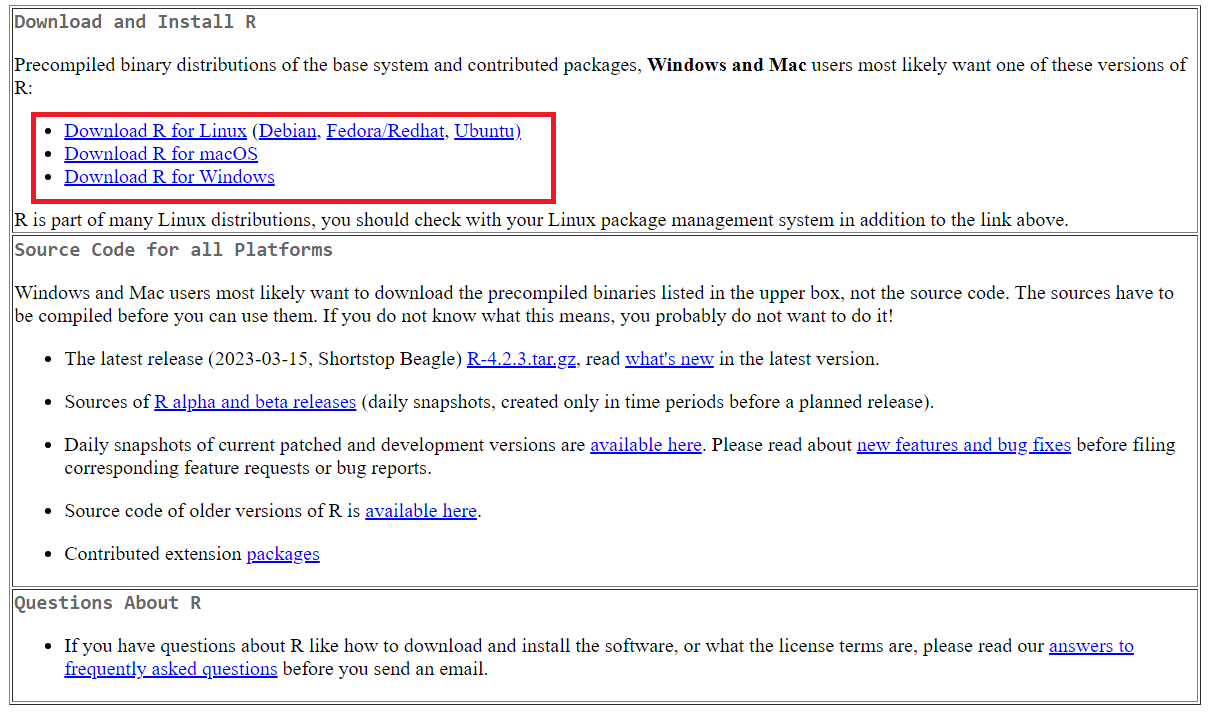
Laden Sie dann die Entwicklungsumgebung herunter und installieren Sie sie. Tatsächlich ist die Auswahl ziemlich groß: Visual Studio Code, PyCharm oder jede andere, die die R-Sprache unterstützt. Wir empfehlen jedoch RStudio, das speziell für die Arbeit mit dieser Programmiersprache entwickelt wurde, sehr funktional ist und über viele nützliche integrierte Funktionen verfügt. Wir werden diese Entwicklungsumgebung in diesem Tutorial verwenden.
Gehen Sie zur Installation auf die offizielle RStudio-Website und laden Sie die Installationsdatei herunter. Es ist wichtig, sich daran zu erinnern, dass die Installation in einer strengen Reihenfolge durchgeführt werden muss: zuerst R, dann RStudio.
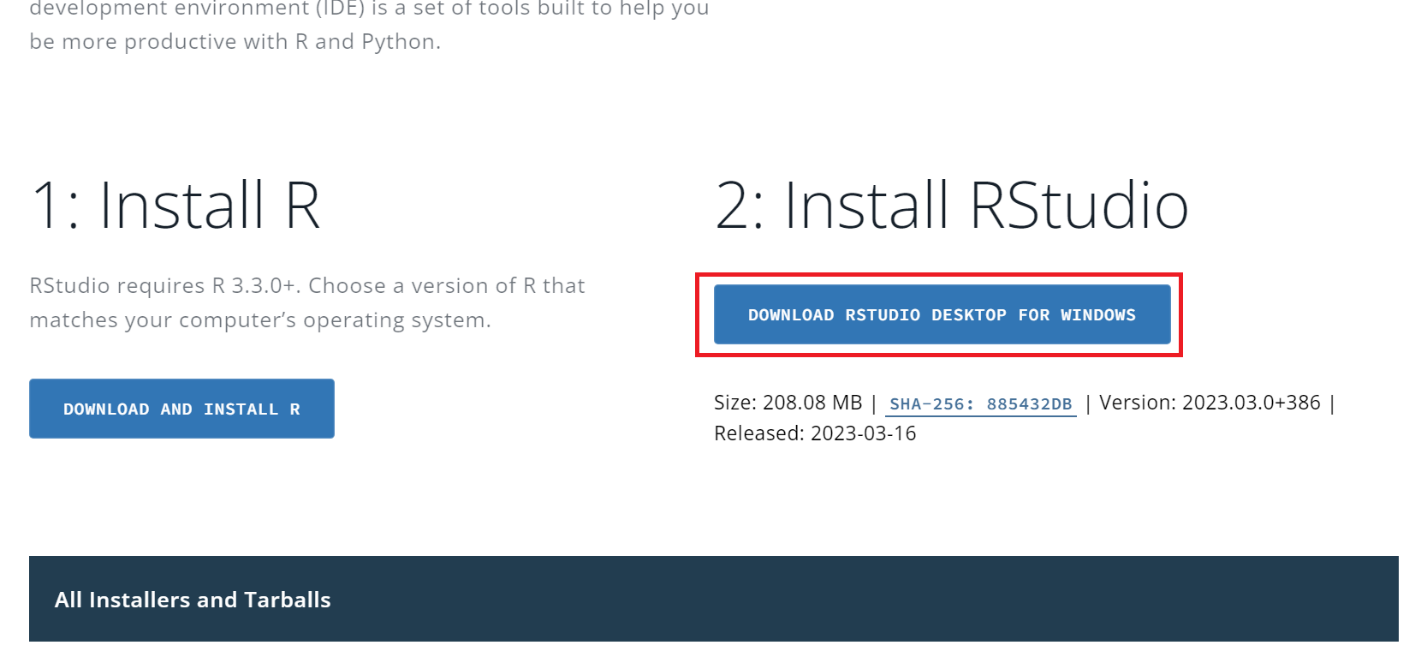
Bei anderen Betriebssystemen finden Sie die Installationsdateien unten auf der Seite.
Da Sie Pakete in der RStudio-Umgebung selbst installieren können, werden wir dies etwas später tun, da wir sie verwenden. Lassen Sie uns zunächst die Website erkunden, von der wir Daten sammeln werden.
Recherche der Struktur der Website
Bevor Sie einen Scraper schreiben, müssen Sie unabhängig von der Programmiersprache die Struktur der Site recherchieren und verstehen, wo und in welcher Form sich die erforderlichen Daten befinden.
Nehmen wir das quotes.toscrape.com Website als Beispiel, um das schrittweise Schreiben des Skripts zu betrachten. Gehen wir zunächst zur Website und öffnen den Seitencode. Um den HTML-Seitencode zu öffnen, gehen Sie zu DevTools (drücken Sie F12 oder klicken Sie mit der rechten Maustaste auf eine leere Stelle auf der Seite und gehen Sie zu „Inspizieren“).

Wie wir sehen können, befinden sich alle Anführungszeichen im
Lassen Sie uns die Struktur genauer untersuchen:
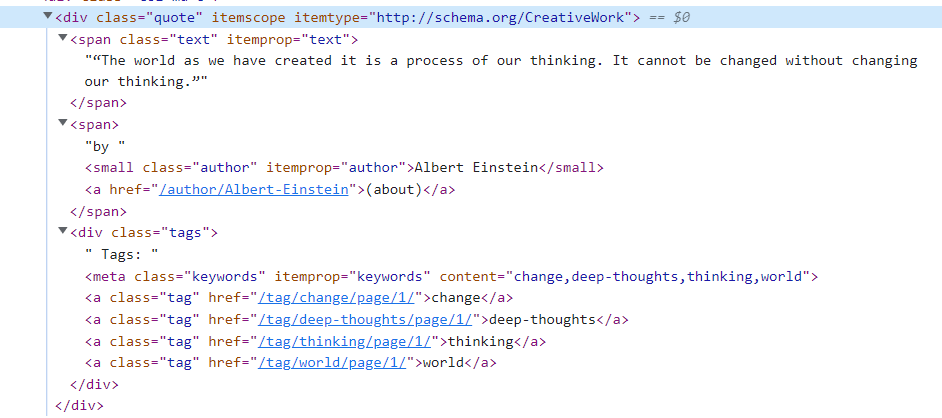
Jetzt sehen wir, dass sich das Zitat selbst im -Tag mit der Klasse „text“ befindet, der Autor im -Tag mit der Klasse „author“ und die Zitat-Tags im -Tag mit der Klasse „Etikett“. Wenn diese Struktur vorhanden ist, können Sie mit dem Schreiben des Scrapers in R beginnen.
Abrufen von Daten von Webseiten
Schauen wir uns das Extrahieren von Daten aus Seiten mit unterschiedlichen Strukturen an: HTML, XML und JSON. Gehen wir zunächst in RStudio und erstellen ein neues Projekt:
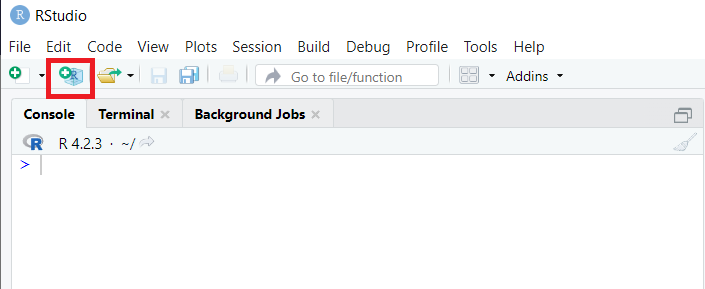
Wir können aus drei Optionen wählen: einen neuen Ordner erstellen, unser Projekt in einem vorhandenen Ordner platzieren oder die Versionskontrolle verwenden, um das Projekt zu verwalten.
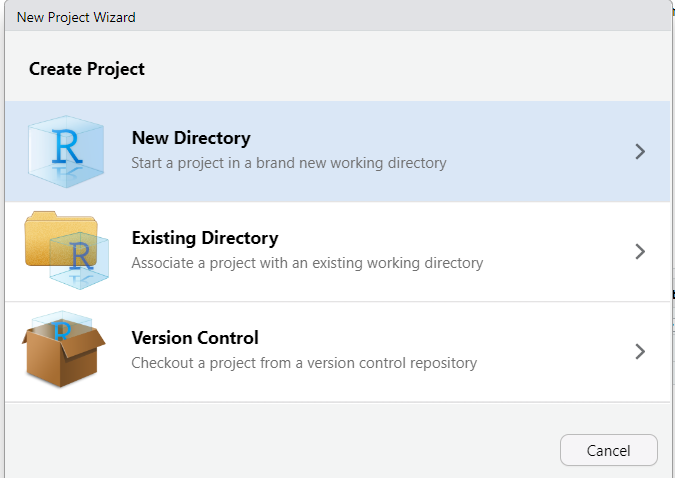
Erstellen Sie einen neuen Ordner, um die Verwaltung der Dateien zu erleichtern, wählen Sie dann „Neues Projekt erstellen“ und geben Sie seinen Namen ein. Danach ist der Arbeitsbereich vollständig an das neue Projekt angepasst.
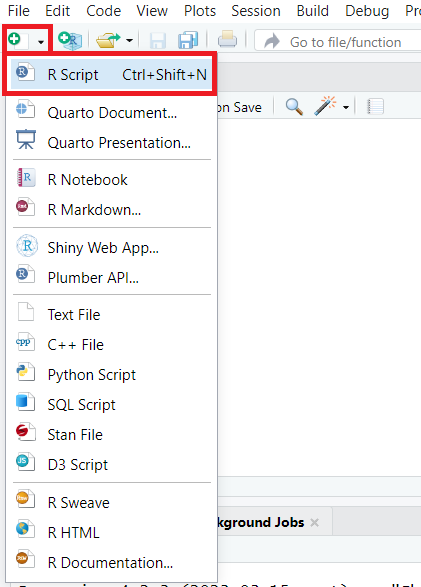
Erstellen wir außerdem ein neues Skript und speichern es in unserem Projekt:
An diesem Punkt sind die Vorbereitungen abgeschlossen und Sie können mit der Erstellung des Schabers fortfahren.
Scraping von HTML-Seiten
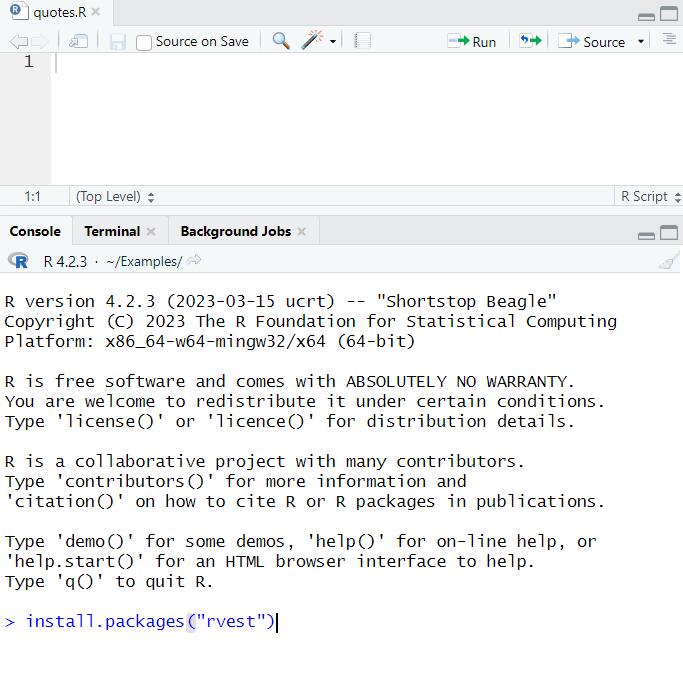
Um einen einfachen Scraper zum Extrahieren von Daten aus Webseiten zu schreiben, benötigen wir das Paket rvest. Um es zu installieren, führen Sie den folgenden Befehl in der RStudio-Konsole aus:
install.packages("rvest")Warten Sie danach auf den Download, entpacken und installieren Sie die Pakete und gehen Sie zum oberen Fenster – wir werden das Skript darin schreiben.
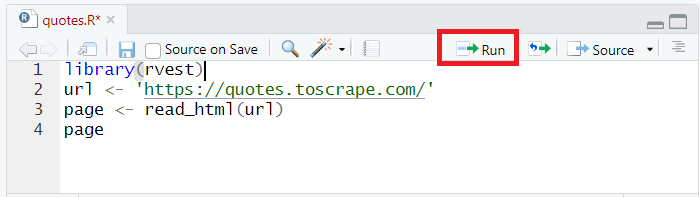
Zuerst verbinden wir die Bibliothek, die wir gerade installiert haben, mit dem Projekt:
library(rvest)Lassen Sie uns quotes.toscrape.com abfragen und den gesamten Seitencode mit dem abrufen read_html Befehl und platzieren Sie es in der Seite Variable:
url <- 'https://quotes.toscrape.com/'
page <- read_html(url)Um die Daten an die Konsole auszugeben, geben wir einfach den Namen der Variablen an:
Seite
Stellen Sie sicher, dass alles in Ordnung ist, und führen Sie das resultierende Skript aus. Drücken Sie dazu Strg+Eingabetaste oder klicken Sie auf die Schaltfläche „Ausführen“.
Beachten Sie, dass der Code Zeile für Zeile ausgeführt wird. Platzieren Sie den Cursor daher auf der ersten Zeile.
Das Skript ruft den gesamten Code auf der Seite ab und zeigt ihn an:

Wie bereits erwähnt, werden die Daten auf quotes.toscrape.com im
quotes <- page %>%
html_nodes("div.quote")Jetzt haben wir eine Liste, die Daten zu allen Angeboten auf der Seite speichert. Lassen Sie uns aus diesen Daten nur die Zitate selbst extrahieren:
quote <- quotes %>%
html_nodes("span.text")%>%
html_text()Hier haben wir das verwendet html_text Befehl. Geschieht dies nicht, enthält die Quote-Variable zusätzliche Informationen, die nicht benötigt werden. Der Befehl html_text wird verwendet, um nur Text aus HTML-Tags abzurufen.
Ebenso erhalten wir Daten über die Verfasser von Zitaten und fügen diese ebenfalls in eine Variable ein:
author <- quotes %>%
html_nodes("small.author")%>%
html_text()Lassen Sie uns nun den Inhalt der Variablen auf dem Bildschirm anzeigen:
quote
authorErgebnis:
>quote
(1) "The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.
(2) "It is our choices, Harry, that show what we truly are, far more than our abilities."
(3) "There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle."
(4) "The person, be it gentleman or lady, who has no pleasure in a good novel, must be intolerably stupid.
(5) "Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.
(6) "Try not to become a man of success. Rather become a man of value."
(7) "It is better to be hated for what you are than to be loved for what you are not.
(8) "'I have not failed. I've just found 10,000 ways that won't work."
(9) "A woman is like a tea bag; you never know how strong it is until it's in hot water."
(10) "A day without sunshine is like, you know, night.
> author
(1) "Albert Einstein" "J.K. Rowling"
(3) "Albert Einstein" "Jane Austen"
(5) "Marilyn Monroe" "Albert Einstein"
(7) "André Gide" "Thomas A. Edison"
(9) "Eleanor Roosevelt" "Steve Martin"
> Der ganze Code:
library(rvest)
url <- 'https://quotes.toscrape.com/'
page <- read_html(url)
quotes <- page %>%
html_nodes("div.quote")
quote <- quotes %>%
html_nodes("span.text")%>%
html_text()
author <- quotes %>%
html_nodes("small.author")%>%
html_text()
quote
authorWir werden etwas später auf dieses Beispiel zurückkommen, um das Ergebnis zu bereinigen, wo wir im Detail beschreiben, wie man zusätzliche Zeichen entfernt und andere zusätzliche Vorgänge durchführt. Lassen Sie uns die Daten strukturieren und zunächst in einer CSV-Datei speichern.
Um eine Struktur zu erstellen, verwenden wir Datenrahmen, eine Standardmethode zum Speichern von Daten. Zunächst erstellen wir einen Datenrahmen, in den wir die Daten einfügen Zitat Und Autor Variablen:
all_quotes <- data.frame(quote, author)Legen Sie nun die Spaltenüberschriften der zukünftigen Tabelle fest:
names(all_quotes) <- c("quote", "author")Und zum Schluss speichern wir die Daten in einer CSV-Datei:
write.csv(all_quotes, file = "./quotes.csv")Die Datei quotes.csv wird im Projektordner gespeichert. Öffnen wir es, ordnen den Text in Spalten an und sehen uns das Ergebnis an:
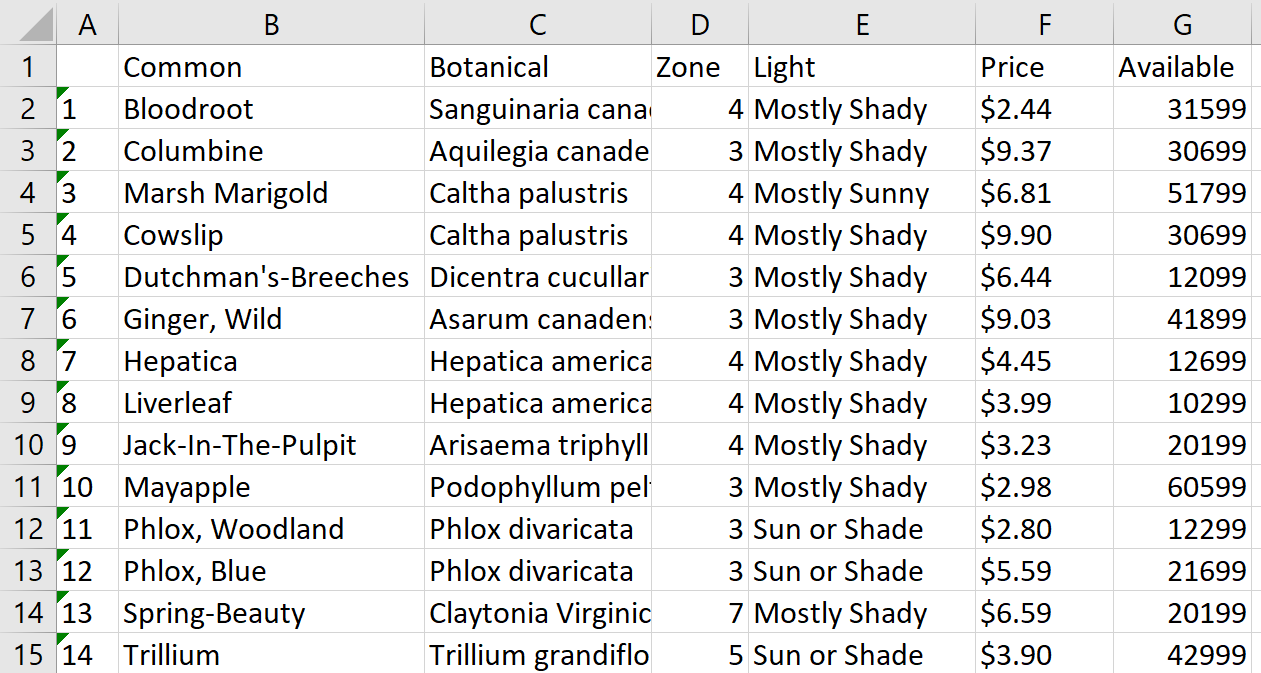
Wie wir sehen können, gibt es in der Anführungszeichenspalte zusätzliche Zeichen, die wir jedoch etwas später entfernen werden.
Scraping von XML- und JSON-Daten
Beim Scrapen von Daten von Websites arbeiten Sie oft mit Daten im XML- oder JSON-Format. Diese Formate werden üblicherweise zum Datenaustausch zwischen Webanwendungen und auch zum Speichern und Transportieren von Daten verwendet. Glücklicherweise gibt es in beiden Formaten viele Tools für Web Scraping mit R.
Scraping von XML-Daten
XML steht für „Extensible Markup Language“ und ist ein beliebtes Format für den Datenaustausch. XML-Daten sind ähnlich wie HTML strukturiert, wobei Elemente in anderen Elementen verschachtelt sind. Zum Scrapen von XML-Daten in R können wir das Paket XML oder xml2 verwenden, das Funktionen zum Parsen und Navigieren in XML-Dokumenten bereitstellt.
Um zu demonstrieren, wie man mit der XML-Struktur arbeitet, erstellen wir eine Datei im *.xml-Format und fügen darin ein Beispiel einer solchen Datei ein. Nehmen wir einen Beispielcode von dieser Website und schauen wir uns die Verwendung der XML- und xml2-Bibliotheken nacheinander an.
XML mit der XML2-Bibliothek analysieren
Lassen Sie uns die Konsole verwenden und das xml2-Paket mit dem Befehl installieren:
install.packages("xml2")Danach erstellen wir ein neues Skript im Projekt, in dem wir die xml2-Bibliothek verbinden:
library(xml2)Fügen Sie den Inhalt der gesamten XML-Datendatei in eine Variable ein:
doc <- read_xml("./example.xml")Jetzt müssen wir uns um die Struktur dieses Dokuments kümmern und die Daten mithilfe von Attributen in Variablen einfügen:
plant <- xml_find_all(doc, ".//PLANT")
common <- xml_find_all(plant, ".//COMMON")
botanical <- xml_find_all(plant, ".//BOTANICAL")
zone <- xml_find_all(plant, ".//ZONE")
light <- xml_find_all(plant, ".//LIGHT")
price <- xml_find_all(plant, ".//PRICE")
avail <- xml_find_all(plant, ".//AVAILABILITY") Um die Daten als Tabelle zu speichern, fügen wir die Daten in einen Datenrahmen ein, legen die Spaltenüberschriften fest und speichern sie in der Datei Pflanzen.csv:
all_plants <- data.frame(xml_text(common), xml_text(botanical), xml_text(zone), xml_text(light), xml_text(price), xml_text(avail))
names(all_plants) <- c("Common", "Botanical", "Zone", "Light", "Price", "Available")
write.csv(all_plants, file = "./plants.csv")Öffnen wir die Datei, legen den Text über die Spalten und sehen uns das Ergebnis an:

Auf diese Weise erhalten wir eine einfach zu verarbeitende CSV-Datei aus einer XML-Struktur. Diese Methode eignet sich zur Verarbeitung lokaler Dateien und Webseiten im XML-Format. Bei Webseiten ist die Angabe der Seitenadresse anstelle der Dateiadresse erforderlich:
doc <- read_xml("URL")Der vollständige Code:
library(xml2)
doc <- read_xml("./example.xml")
plant <- xml_find_all(doc, ".//PLANT")
common <- xml_find_all(plant, ".//COMMON")
botanical <- xml_find_all(plant, ".//BOTANICAL")
zone <- xml_find_all(plant, ".//ZONE")
light <- xml_find_all(plant, ".//LIGHT")
price <- xml_find_all(plant, ".//PRICE")
avail <- xml_find_all(plant, ".//AVAILABILITY")
all_plants <- data.frame(xml_text(common), xml_text(botanical), xml_text(zone), xml_text(light), xml_text(price), xml_text(avail))
names(all_plants) <- c("Common", "Botanical", "Zone", "Light", "Price", "Available")
write.csv(all_plants, file = "./plants.csv")Das war die erste Option, die Verwendung der XML2-Bibliothek. Schauen wir uns das Gleiche an, aber mit der XML-Bibliothek.
XML mit der XML-Bibliothek verarbeiten
Wir werden das verwenden xml Bibliothek mit der Methoden Bibliothek, die unseren Code verkürzt und vereinfacht. Zuerst installieren wir die XML-Bibliothek in der Konsole:
> install.packages("XML")Importieren Sie die erforderlichen Bibliotheken in das neue Skript:
library("XML")
library("methods")Fügen Sie nun die Daten aus der XML-Datei direkt in den Datenrahmen ein:
all_plants <- xmlToDataFrame("./example.xml")Fügen wir Spaltenüberschriften hinzu und speichern sie in einer CSV-Datei:
names(all_plants) <- c("Common", "Botanical", "Zone", "Light", "Price", "Available")
write.csv(all_plants, file = "./plants2.csv")Schauen wir uns den vollständigen Code an:
library("XML")
library("methods")
all_plants <- xmlToDataFrame("./example.xml")
names(all_plants) <- c("Common", "Botanical", "Zone", "Light", "Price", "Available")
write.csv(all_plants, file = "./plants2.csv")Somit hatten wir die gleiche Option, jedoch viel schneller und einfacher.
Scraping von JSON-Daten
JSON steht für „JavaScript Object Notation“ und ist ein leichtes Format für den Datenaustausch. JSON-Daten sind als Sammlung von Schlüssel-Wert-Paaren strukturiert, wobei die Werte Zeichenfolgen, Zahlen, Arrays oder andere Objekte sein können. Um JSON-Daten in R zu extrahieren, können wir die verwenden jsonlite Paket, das Funktionen zum Parsen und Bearbeiten von JSON-Daten bereitstellt.
Lassen Sie uns zunächst die Konsole verwenden und die erforderliche Bibliothek installieren:
> install.packages("jsonlite")Jetzt importieren wir es in das Projekt:
library(jsonlite)Als Beispiel verwenden wir die folgende JSON-Datei:
{
"squadName": "Super hero squad",
"homeTown": "Metro City",
"formed": 2016,
"secretBase": "Super tower",
{ "active": true,
{ "members": (
{
"name": "Molecule Man",
"age": 29,
"secretIdentity": "Dan Jukes"
},
{
"name": "Madame Uppercut",
{ "age": 39,
"secretIdentity": "Jane Wilson"
},
{
"name": "Eternal Flame",
"age": 1000000,
"secretIdentity": "Unknown"
}
)
}Wie im Fall der xml Bibliothek, die jsonlite Die Bibliothek hat die Möglichkeit, Daten sofort im Datenrahmen zu speichern. Nutzen wir diese Funktion und holen wir uns die Daten, die für die weitere Verarbeitung praktisch sind:
heroes <- fromJSON("./example.json")Speichern wir diesen Datenrahmen in einer CSV-Datei:
write.csv(heroes, file = "./heroes.csv")Als Ergebnis erhalten wir eine Tabelle mit folgendem Inhalt:

Jetzt ändern wir die Aufgabe ein wenig. Angenommen, wir möchten nur die in den Attributelementen eingebetteten Daten in der Tabelle speichern. Dazu geben wir im Speicherbefehl nicht nur den Datenrahmen an, sondern auch das Attribut, dessen Inhalt wir speichern möchten:
write.csv(heroes$members, file = "./heroes.csv")Wenn wir uns nun die Datei ansehen, sieht sie anders aus:
Das Scrapen von Daten im XML- oder JSON-Format kann komplexer sein als das Scrapen von HTML-Daten, ist aber in R mit den richtigen Tools und Techniken nicht schwierig.
Dynamische Inhalte mit RSelenium ausführen
Wir haben bereits über das Scraping mit Selenium in Python geschrieben. Diese Bibliothek hat auch ein Gegenstück für die R-Sprache – RSelenium. Dies ist für das Scraping dynamischer Daten und die Verwendung eines Headless-Browsers erforderlich, der es Ihnen ermöglicht, das Verhalten eines echten Benutzers zu simulieren und so das Risiko einer Blockierung zu verringern.
Um RSelenium verwenden zu können, müssen Sie das Paket installieren und einen Treiber für den Webbrowser herunterladen, den Sie verwenden möchten. Wir werden den Chromium-Webtreiber verwenden. Um die Bibliothek zu installieren, führen Sie den Befehl in der RStudio-Konsole aus:
> install.packages("RSelenium")Sie können den Webtreiber von der offiziellen Website herunterladen und müssen ihn dann im Projektordner ablegen. Um ordnungsgemäß zu funktionieren, müssen Sie über einen Webtreiber derselben Version wie der installierte Chrome-Browser verfügen.
Wir benötigen einen Serverteil und einen Clientteil, um zu funktionieren. Um den Serverteil auszuführen, benötigen wir Java. Wenn es also nicht auf dem Computer installiert ist, muss es installiert werden.
Laden Sie jetzt Selenium-Server-Stadalone von der offiziellen Website herunter. Jede Version reicht aus, aber es ist besser, die neueste herunterzuladen. Wir werden Selenium-Server-Standalone-4.0.0-Alpha-2 verwenden. Es sollte heruntergeladen und im Projektordner abgelegt werden.
Wenn alle Vorbereitungen abgeschlossen sind, gehen Sie zum Projektordner und geben Sie in der Adresszeile cmd ein, um die Befehlszeile unter dem ausgewählten Ordner auszuführen. Wir müssen den Server starten. Verwenden Sie dazu den Befehl:
java -jar selenium-server-standalone-VERSION.jarIn unserem Fall würde der Befehl beispielsweise so aussehen:
java -jar selenium-server-standalone-4.0.0-alpha-2.jarDas Ergebnis seiner Ausführung wird, wenn alles richtig gemacht wurde, den Server starten (achten Sie auf den Server-Port, wir werden ihn später brauchen):
C:\Users\user\Documents\Examples>java -jar selenium-server-standalone-4.0.0-alpha-2.jar
17:16:24.873 INFO (GridLauncherV3.parse) - Selenium server version: 4.0.0-alpha-2, revision: f148142cf8
17:16:25.029 INFO (GridLauncherV3.lambda$buildLaunchers$3) - Launching a standalone Selenium Server on port 4444
17:16:25.529 INFO (WebDriverServlet.<init>) - Initialising WebDriverServlet
17:16:26.061 INFO (SeleniumServer.boot) - Selenium Server is up and running on port 4444Gehen Sie nun zurück zu RStudio und erstellen Sie ein neues Skript im Projekt. Importieren Sie die RSelenium-Bibliothek hinein:
library(RSelenium)Als nächstes legen wir die Webtreibereinstellungen fest: den Namen des Browsers, den Serverport und die Version des Webtreibers. In unserem Fall sehen die Einstellungen so aus:
rdriver <- rsDriver(browser = "chrome",
port = 4444L,
chromever = "112.0.5615.28",
)Erstellen Sie einen Client, der durch Seiten navigiert und Daten durchsucht:
remDr <- rdriverGehen Sie zu der Website, von der wir Daten sammeln werden:
remDr$navigate("https://quotes.toscrape.com/")Nachdem Sie die Website aufgerufen haben, sammeln wir alle Anführungszeichen in einer Variablen:
html_quotes <- remDr$findElements(using = "css selector", value = "div.quote")Lassen Sie uns Variablen erstellen von Liste Geben Sie Zitate und Autoren ein und fügen Sie sie ein:
quotes <- list()
authors <- list()
for (html_quote in html_quotes) {
quotes <- append(
quotes,
html_quote$findChildElement(using = "css selector", value = "span.text")$getElementText()
)
authors <- append(
authors,
html_quote$findChildElement(using = "css selector", value = "small.author")$getElementText()
)
}Geben wir nun wie zuvor die Daten in den Datenrahmen ein, erstellen Spaltenüberschriften und speichern die Daten im CSV-Format:
all_qoutes <- data.frame(
unlist(quotes),
unlist(authors)
)
names(all_quotes) <- c("quote", "author")
write.csv(all_quotes, file = "./quotes.csv")Schließen Sie am Ende den Webtreiber:
remDr$close()Als Ergebnis erhielten wir genau die gleiche Datei wie zuvor, jedoch mit der Möglichkeit, Elemente auf der Webseite zu steuern, einen Headless-Browser auszuführen, das Verhalten eines echten Benutzers zu emulieren und die Wahrscheinlichkeit einer Blockierung zu verringern.
Vollständiger Skriptcode:
library(RSelenium)
rdriver <- rsDriver(browser = "chrome",
port = 4444L,
chromever = "112.0.5615.28",
)
remDr <- rdriver
remDr$navigate("https://quotes.toscrape.com/")
html_quotes <- remDr$findElements(using = "css selector", value = "div.quote")
quotes <- list()
authors <- list()
for (html_quote in html_quotes) {
quotes <- append(
quotes,
html_quote$findChildElement(using = "css selector", value = "span.text")$getElementText()
)
authors <- append(
authors,
html_quote$findChildElement(using = "css selector", value = "small.author")$getElementText()
)
}
all_quotes <- data.frame(
unlist(quotes),
unlist(authors)
)
names(all_quotes) <- c("quote", "author")
write.csv(all_quotes, file = "./quotes.csv")
remDr$close()Insgesamt ist RSelenium ein leistungsstarkes Tool zum Scrapen von Daten aus Webseiten mit dynamischen Inhalten und eröffnet eine völlig neue Welt an Möglichkeiten für das Web Scraping in R.
Angenommen, Sie möchten Daten von einer Webseite extrahieren, bei der Sie auf die Schaltfläche „Mehr laden“ klicken müssen, um zusätzlichen Inhalt anzuzeigen. Ohne RSelenium müssten Sie jedes Mal manuell auf die Schaltfläche klicken, wenn Sie weitere Daten laden möchten. Mit RSelenium können Sie diesen Prozess jedoch automatisieren.
Tipps und Tricks für effektives Web Scraping in R
Hier finden Sie einige Tipps und Tricks, die Ihnen helfen, Ihre Fähigkeiten beim Web Scraping mit R zu verbessern. Diese Tipps helfen Ihnen, mehrere Seiten und Websites zu scrapen, bestimmte Datentypen zu extrahieren, die Authentifizierung zu handhaben, mit fehlenden oder falschen Daten umzugehen und unerwünschte Daten zu entfernen Elemente oder Symbole.
Verwenden Sie Verzögerungen zum Scrapen mehrerer Seiten und Websites
Wenn Sie Daten von mehreren Websites extrahieren, ist es wichtig, den Websitebesitzern gegenüber respektvoll zu sein und eine Überlastung ihrer Server zu vermeiden. Dazu können Sie die verwenden Sys.sleep() Funktion in R, um eine Verzögerung zwischen Anfragen hinzuzufügen. Es empfiehlt sich jedoch, die Verzögerungszeit zufällig festzulegen. Dies verringert die Wahrscheinlichkeit, dass Ihr Scraper erkannt und Ihre IP-Adresse blockiert wird.
Der runif(n,x,y) Die Funktion gibt eine Zufallszahl in R zurück, die zum Festlegen von Verzögerungen zwischen Anforderungen verwendet werden kann:
Sys.sleep(runif(1, 0.3, 10))Dieser Code fügt eine Verzögerung zwischen 0,3 und 10 Sekunden hinzu, bevor eine weitere Anfrage gestellt wird. N (hier gleich 1) gibt an, wie viele Werte vorhanden sind runif sollte als Ausgabe zurückkehren.
Manchmal sind Sie möglicherweise daran interessiert, bestimmte Datentypen aus einer Webseite zu extrahieren, beispielsweise Bilder oder Tabellen. Dazu müssen Sie die spezifischen HTML-Tags oder Funktionen identifizieren, die mit den Daten verknüpft sind, die Sie extrahieren möchten.
Zum Beispiel die rvest Die Bibliothek verfügt über einige Funktionen, mit denen Sie mit bestimmten Daten arbeiten können. Wenn die Seite tabellarische Daten enthält, können Sie diese mit direkt in einen Datenrahmen konvertieren html_table().
Eine andere Möglichkeit besteht darin, eine Adresse zu erhalten oder ein Bild herunterzuladen. Die Adresse erhalten Sie wie folgt:
imgsrc <- read_html(url) %>%
html_node(xpath="//*/img") %>%
html_attr('src')So laden Sie ein Bild herunter, dessen Adresse bereits ermittelt wurde:
download.file(paste0(url, imgsrc), destfile = basename(imgsrc))
Der rvest Die Bibliothek reicht aus, um diese Funktionen zu nutzen.
Scraping mit Authentifizierung
Einige Websites erfordern eine Authentifizierung, bevor Sie auf ihre Daten zugreifen können. In solchen Fällen müssen Sie Techniken wie OAuth verwenden, um Ihre Anfragen zu authentifizieren.
OAuth ist ein Protokoll, mit dem Sie Ihre Anfragen authentifizieren können, ohne Ihre Anmeldedaten der Website preiszugeben. Das httr-Paket in R bietet Funktionen für die Arbeit mit OAuth und die Authentifizierung Ihrer Anfragen.
Für eine einfache Autorisierung muss die httr-Bibliothek angeschlossen sein. Um es zu installieren, verwenden Sie den folgenden Befehl in der RStudio-Konsole:
> install.packages("httr")Der Autorisierungsbefehl lautet dann wie folgt:
GET("http://example.com/basic-auth/user/passwd",authenticate("user", "passwd") )Darüber hinaus verfügt diese Bibliothek auch über die Funktionen oauth1.0_token, oauth2.0_token, oauth_app, oauth_endpoint, oauth_endpoints und oauth_service_token.
Das Scraping in R mit Authentifizierung kann etwas komplexer sein, aber die httr-Bibliothek soll es einfacher machen.
Umgang mit fehlenden oder falschen Daten
Bei der Verarbeitung großer Informationsmengen besteht eine hohe Wahrscheinlichkeit, dass einige Daten verloren gehen oder in falscher Form vorliegen. Solche Fehler können beispielsweise aufgrund von Formatierungsproblemen, Kodierungsproblemen oder fehlenden Daten auftreten. Da dieses Problem recht häufig auftritt, ist es notwendig, im Voraus Methoden zur Lösung dieses Problems bereitzustellen.
Sie können beispielsweise die Funktion ifelse() verwenden, mit der Sie in HTML-Dokumenten nach Inkonsistenzen suchen und die Daten durch einen alternativen Wert wie NA ersetzen können. Auf diese Weise stellen Sie sicher, dass die erfassten Daten korrekt sind, auch wenn es unterwegs zu Problemen kommen kann.
Verwendung der Web Scraping API in R
Zusätzlich zu den zuvor behandelten Web-Scraping-Techniken besteht ein weiterer Ansatz zum Extrahieren von Daten aus Webseiten in der Verwendung von APIs (Application Programming Interfaces).
Um eine API in R zu verwenden, können Sie Pakete wie httr, jsonlite oder curl verwenden. Mit diesen Paketen können Sie HTTP-Anfragen an den API-Endpunkt senden und JSON- oder XML-Daten zurückempfangen. Sehen wir uns ein Beispiel dafür an, wie man mithilfe der API und des httr-Pakets Daten von Zillow abruft.
Verbinden Sie die Bibliothek und legen Sie den Header und den Text der Anfrage fest:
library(httr)
headers = c(
'x-api-key' = YOUR-API-KEY',
'Content-Type' = 'application/json'
)
body = '{
{ "extract_rules": {
{ "address": { "address",
"price": "(data-test=property-card-price)",
{ "seller": "div.cWiizR"
},
{ "url": "https://www.zillow.com/portland-or/"
}';Lassen Sie uns nun die Abfrage ausführen und das Ergebnis ausdrucken:
res <- VERB("POST", url = "https://api.scrape-it.cloud/scrape", body = body, add_headers(headers))
cat(content(res, 'text'))Sie können das Skript weiter verfeinern und die resultierenden Daten speichern. Durch die Verwendung der API müssen Sie sich keine Gedanken über die Verwendung von Proxys und Captchas und Einschränkungen machen. In diesem Fall werden alle diese Probleme durch den Dienst gelöst, der die API für das Scraping bereitstellt.
Entfernen unerwünschter Elemente oder Symbole
Manchmal sind die Daten, die Sie durchsuchen, unordentlich oder inkonsistent, mit zusätzlichen Leerzeichen, Satzzeichen oder anderen unerwünschten Zeichen. Mithilfe regulärer Ausdrücke können Sie diese Daten schnell und genau bereinigen. Sie können beispielsweise die Funktion gsub() verwenden, um alle nicht alphanumerischen Zeichen aus einer Zeichenfolge zu entfernen, oder die Funktion str_extract(), um ein bestimmtes Muster aus einer längeren Zeichenfolge zu extrahieren.
Als wir beispielsweise Daten mit Anführungszeichen erfassten, lagen offensichtlich zusätzliche Zeichen vor, die aufgrund der Kodierung in der endgültigen Datei nicht richtig erkannt wurden. Diese Zeichen waren geschweifte Anführungszeichen.
Um alle unnötigen Anführungszeichen aus Anführungszeichen im zu entfernen Zitat Variable könnten wir einfach die folgende Zeile hinzufügen:
quote <- gsub('|', '',quote)Dadurch würden unnötige Zeichen entfernt und das Ergebnis komfortabler gestaltet.
Daten gruppieren und zusammenfassen
Manchmal ist es notwendig, Daten nicht nur zu sammeln, sondern sie auch zu verarbeiten und in Übersichtstabellen zusammenzufassen. Einige Operationen können auf R ausgeführt werden und die Daten dann in Übersichtstabellen dargestellt werden. Sie können einen Datenrahmen erstellen, indem Sie die gescrapten Daten in Spalten kombinieren und dann Funktionen wie filter(), select() und array() aus dem dplyr- oder Tidyverse-Paket verwenden, um die Daten zu bearbeiten und zusammenzufassen.
Um es zu installieren, geben Sie den folgenden Befehl in die RStudio-Konsole ein:
> install.packages("dplyr")Angenommen, wir haben einen Datenrahmen, der Daten speichert, und wir müssen sie nach dem Feld „Name“ gruppieren und die Werte zusammenfassen:
df %>% group_by(Name) %>% summarise(count = n())Diese Bibliothek verfügt über viele Features und Funktionen, die für die Datenwissenschaft nützlich sein werden.
Fazit und Erkenntnisse
Web Scraping ist eine leistungsstarke Methode zum Sammeln von Daten von Websites und R bietet die perfekte Umgebung dafür. Mit Tools wie rvest und xml2 können Sie Inhalte problemlos von Webseiten entfernen. Auch wenn Ihnen Programmiererfahrung fehlt – R macht Web Scraping mit seinem breiten Funktions- und Paketumfang einfach.
Es eröffnet jedem, der wertvolle Informationen aus dem Internet extrahieren möchte, eine Welt voller Möglichkeiten. Sie können Daten aus mehreren Quellen sammeln, bestimmte Typen wie Bilder oder Tabellen abrufen und häufige Probleme wie fehlende oder ungenaue Informationen auf einmal lösen. Web Scraping in R ist eine unglaublich nützliche Fähigkeit, die dabei hilft, verborgene Erkenntnisse aufzudecken, unabhängig davon, ob Sie Entwickler, Forscher oder Datenwissenschaftler sind.
